J. Kissel
The message -- new recommendations:
- if and when we decide to vent the corner, let's run the ETMY ESD with a constant high requested bias of the opposite sign, so we recover back to zero then resume normal regular bias flipping operation. (And lets just make sure that the ETMX requested bias is OFF.)
OR
- if it looks like The Schmutz has been successfully removed from ITMX after the vent, there will likely be less SRC detuning, so we'll need to create a new calibration reference time and model. We'll use that opportunity to measure and reset the strength to which the ESD is relative as well.
---------------------
How I came to this conclusion:
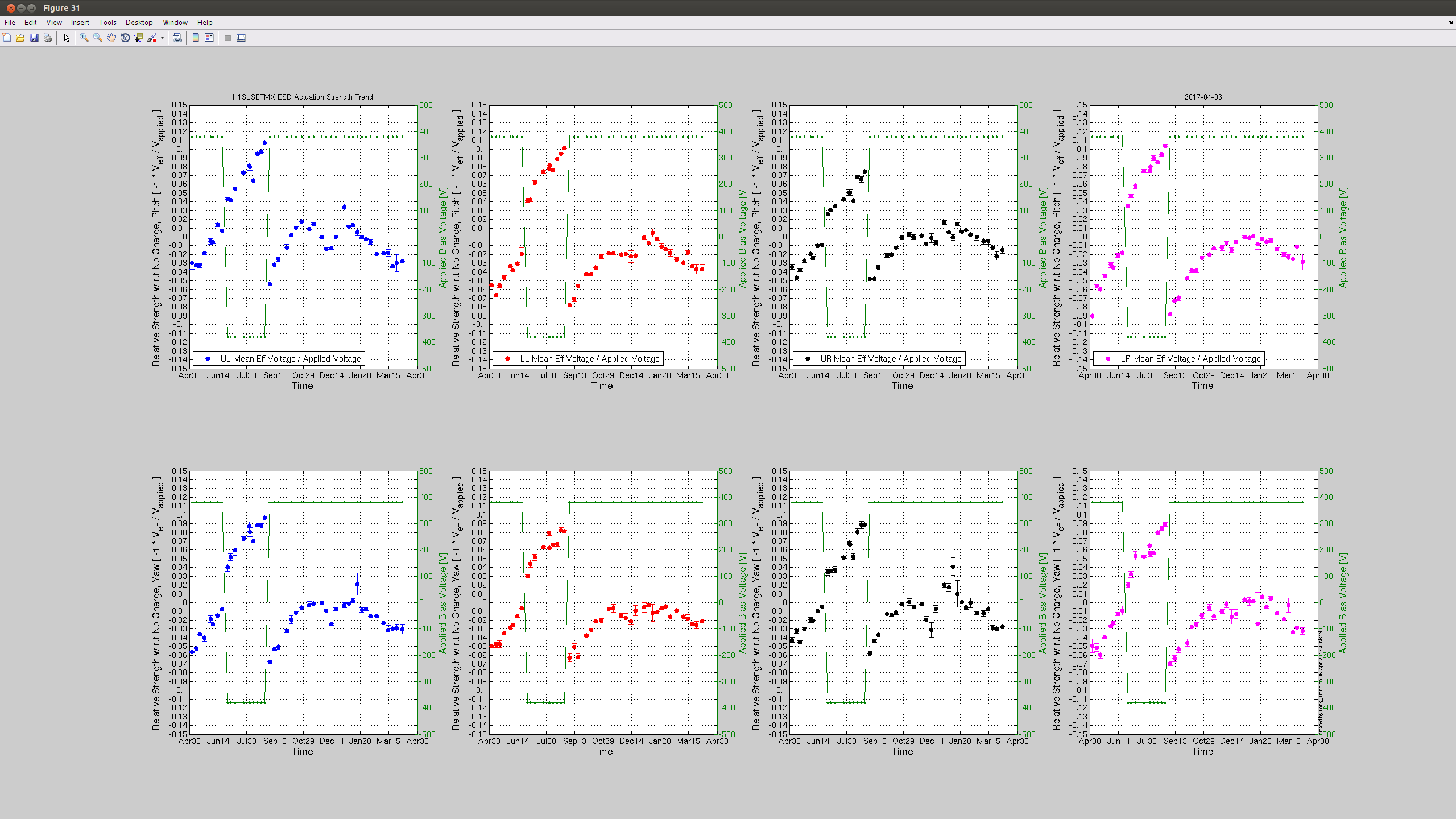
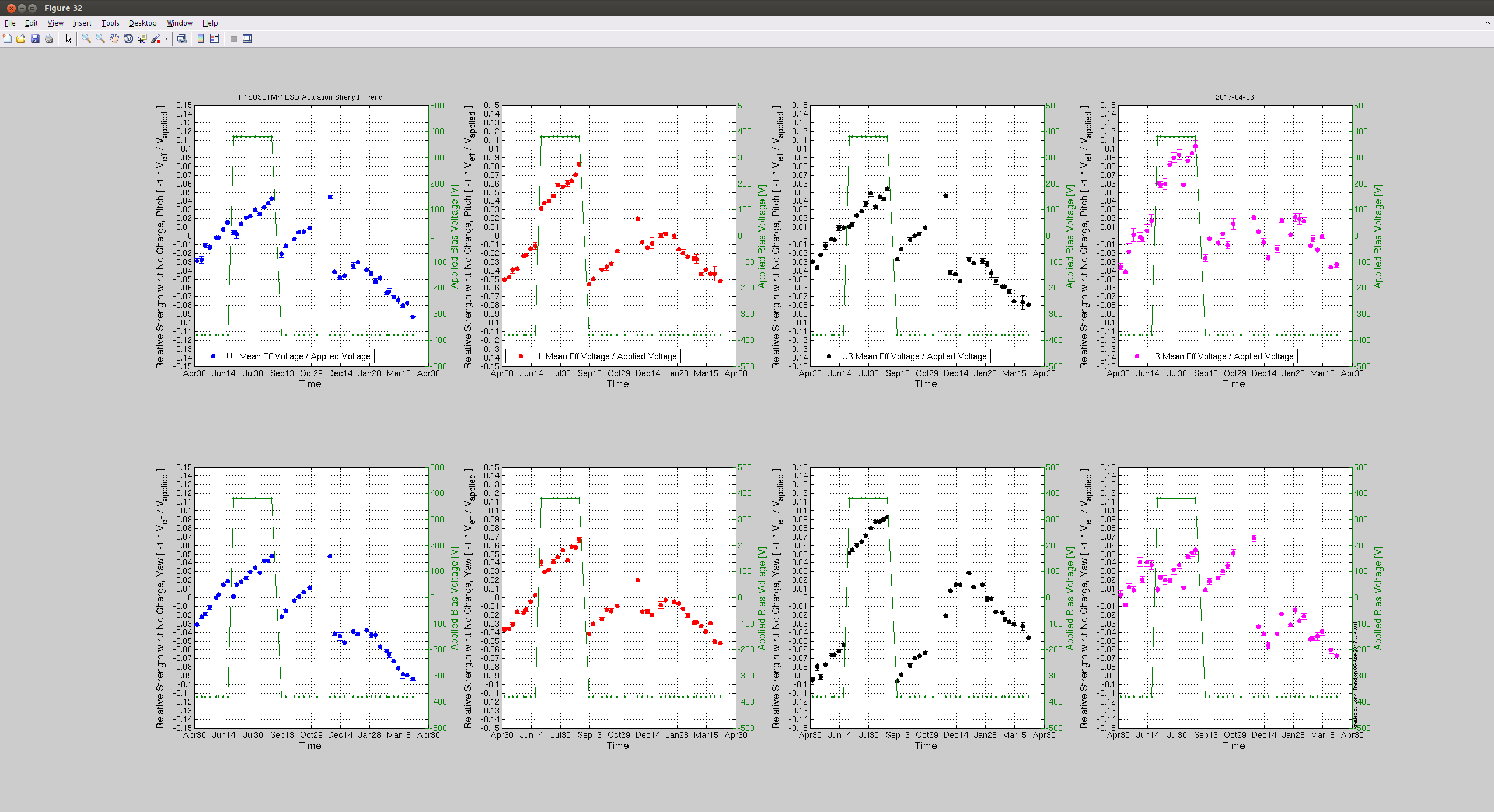
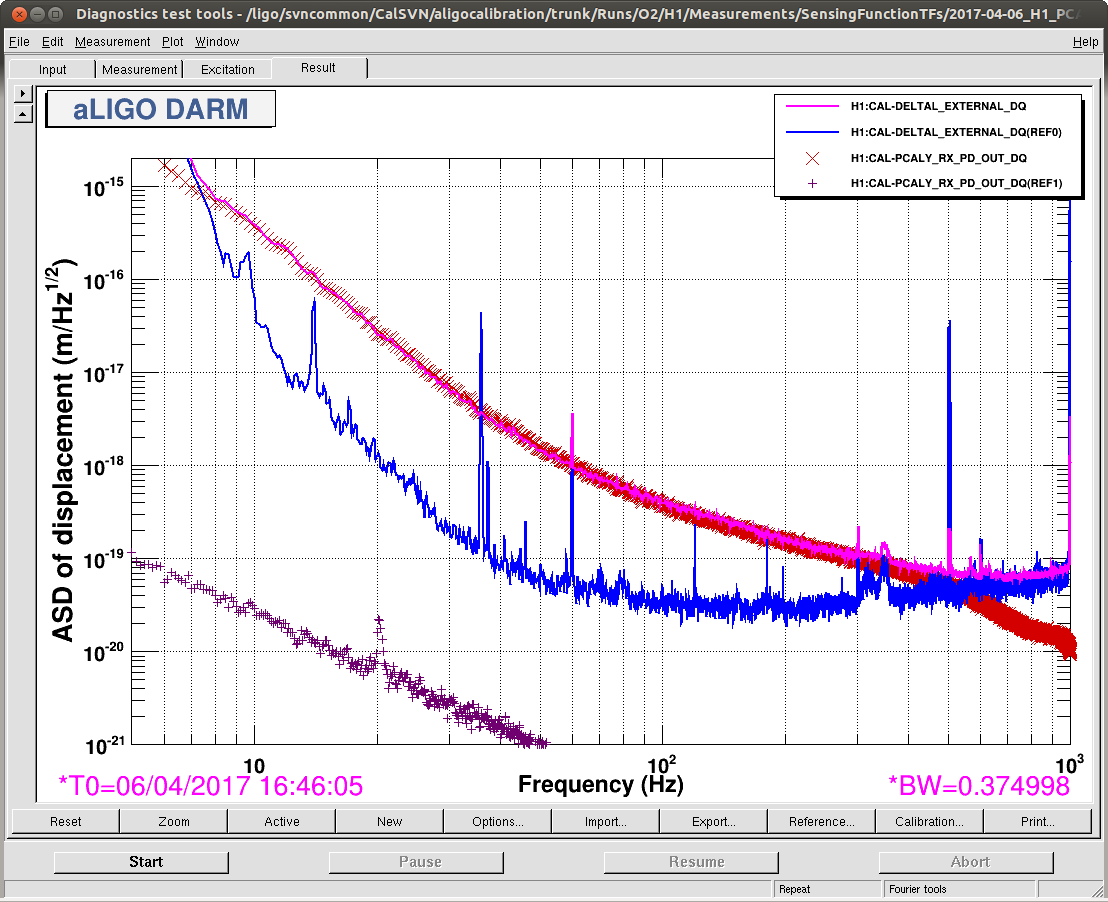
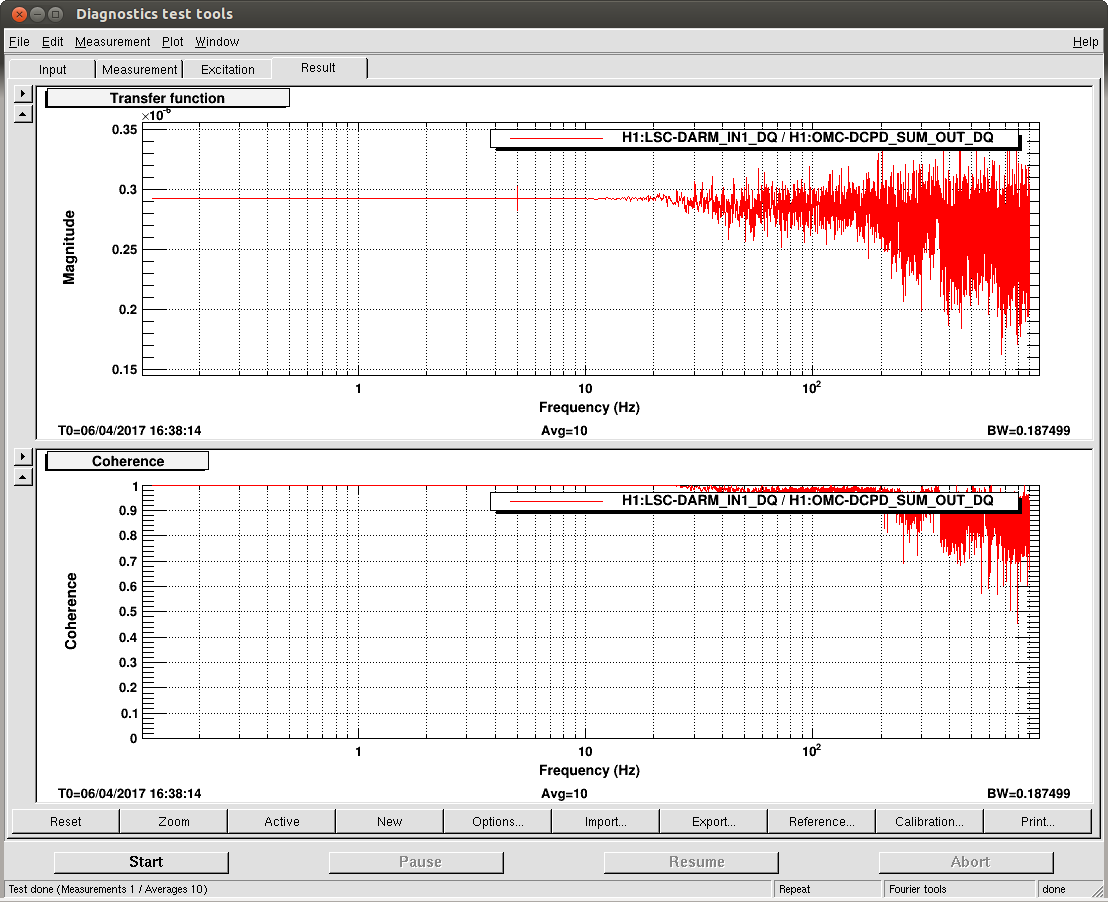
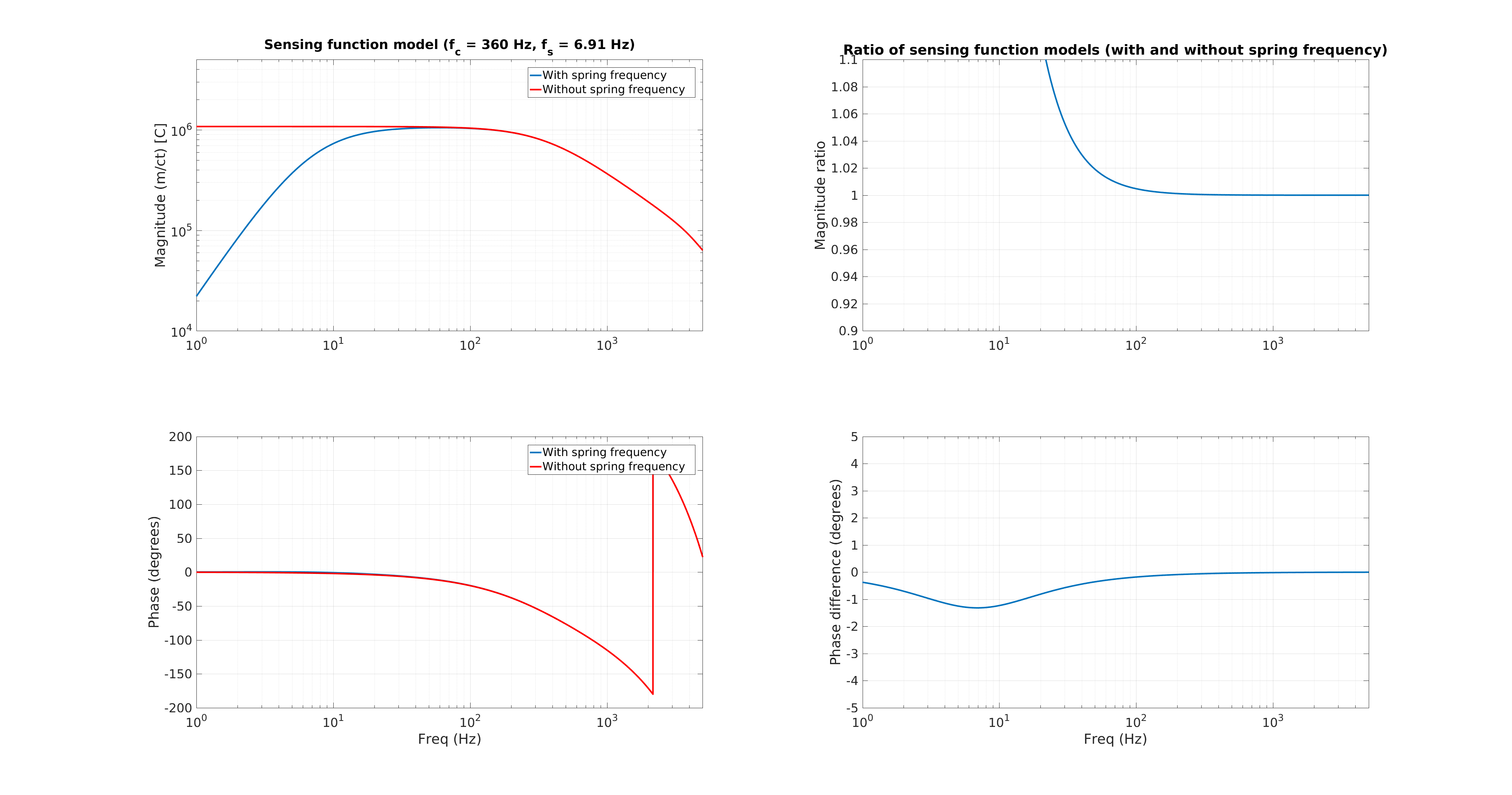
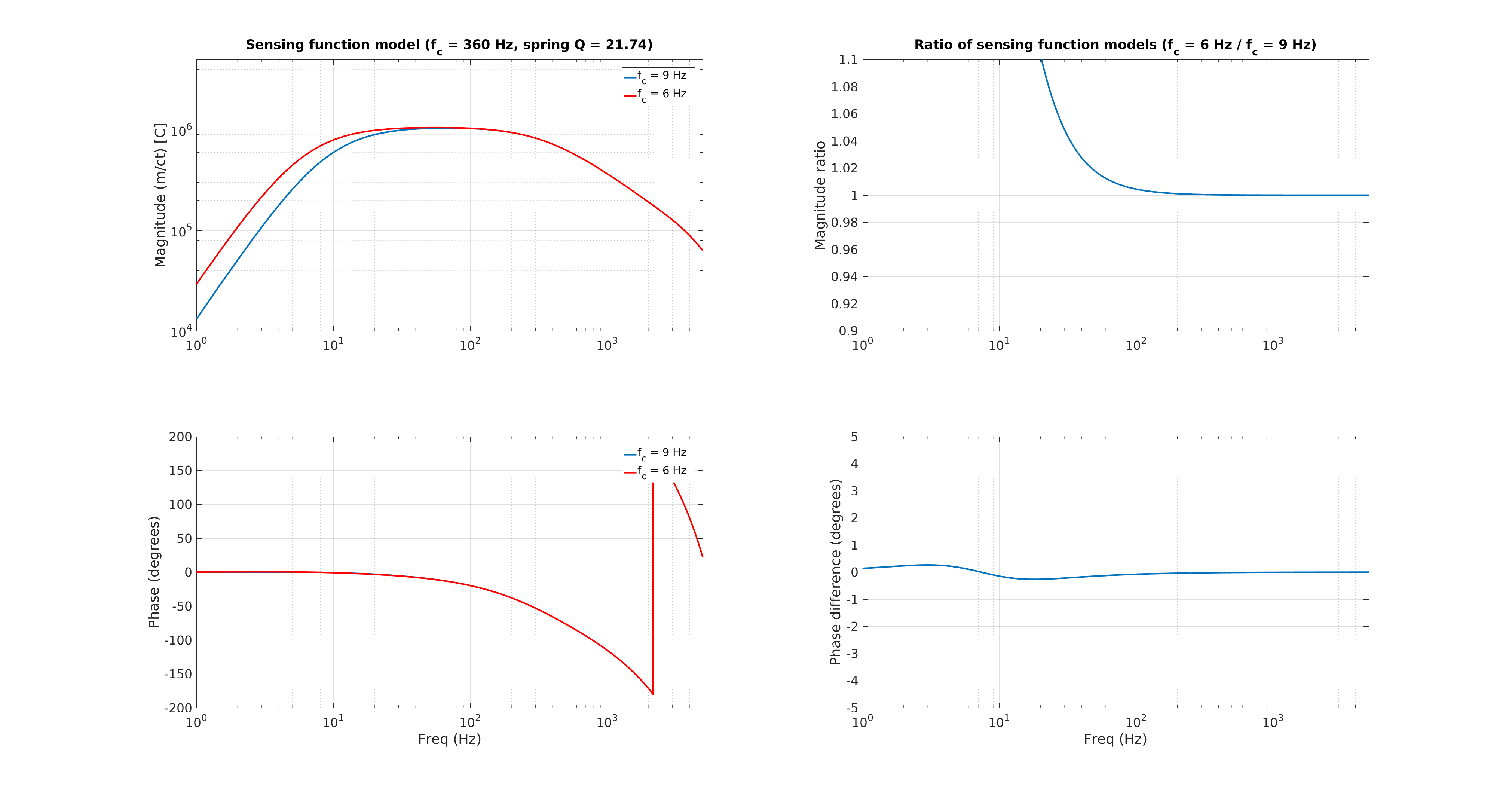
I've taken this week's charge measurements with the usual method -- drive each quadrant of the ESD, and measure the angular response in that test mass' optical lever Pitch and Yaw as a function of requested bias voltage. Where the angular actuation strength crosses zero actuation strength is the effective bias voltage, which we suspect is due to accumulated charge in / on / around the ESD system. In the past, we've used this as a proxy for the change in longitudinal ESD actuation strength, which influences / affects calibration of the DARM loop.
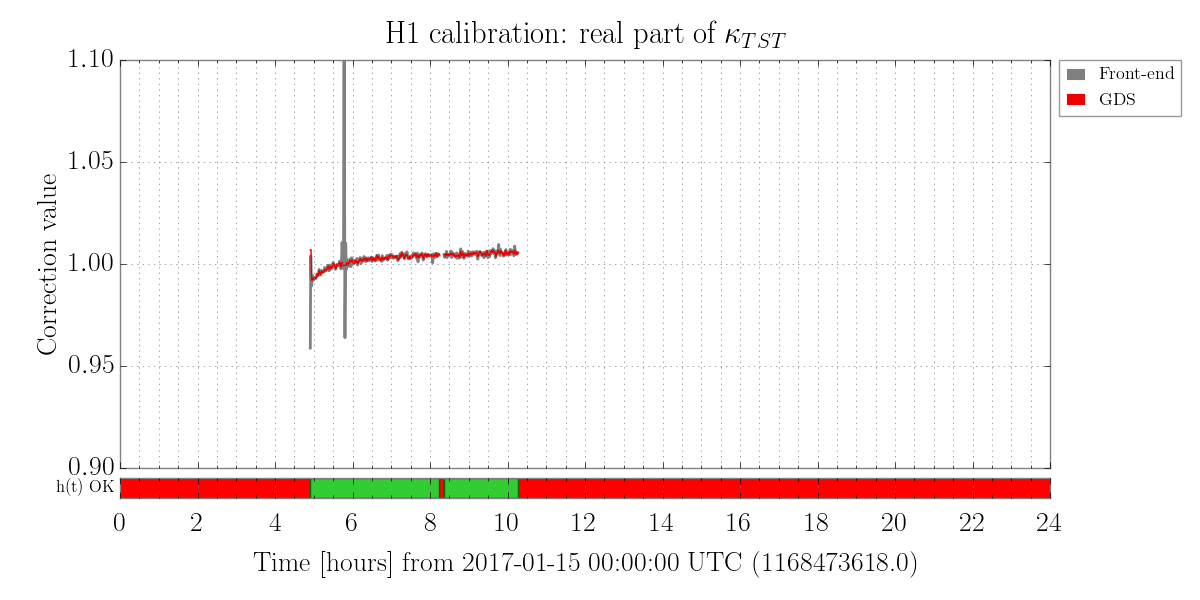
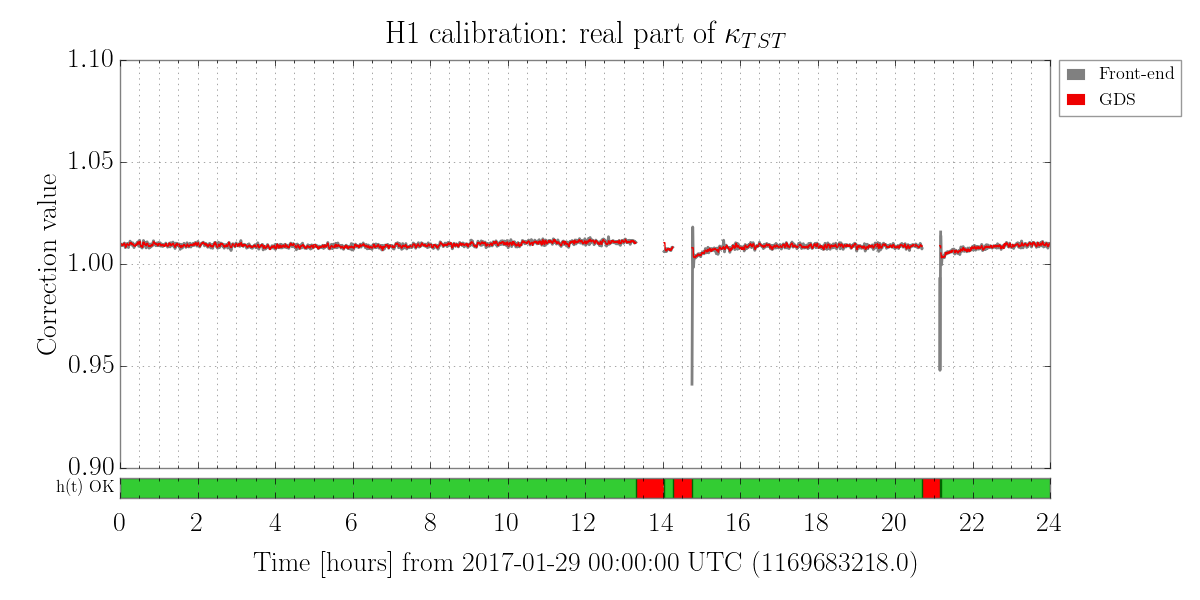
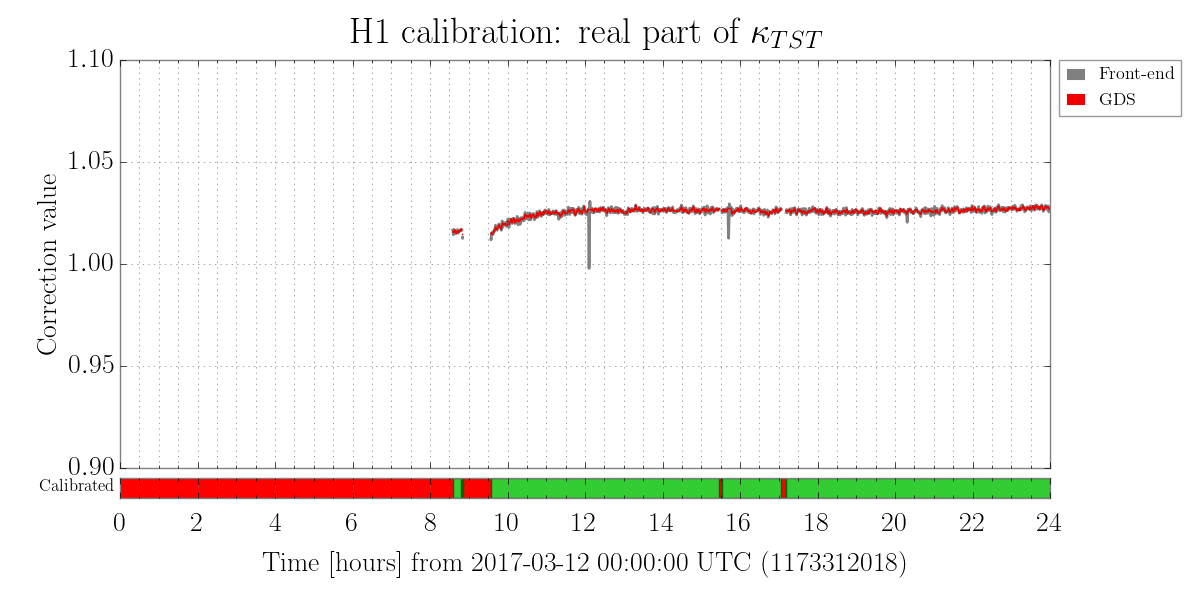
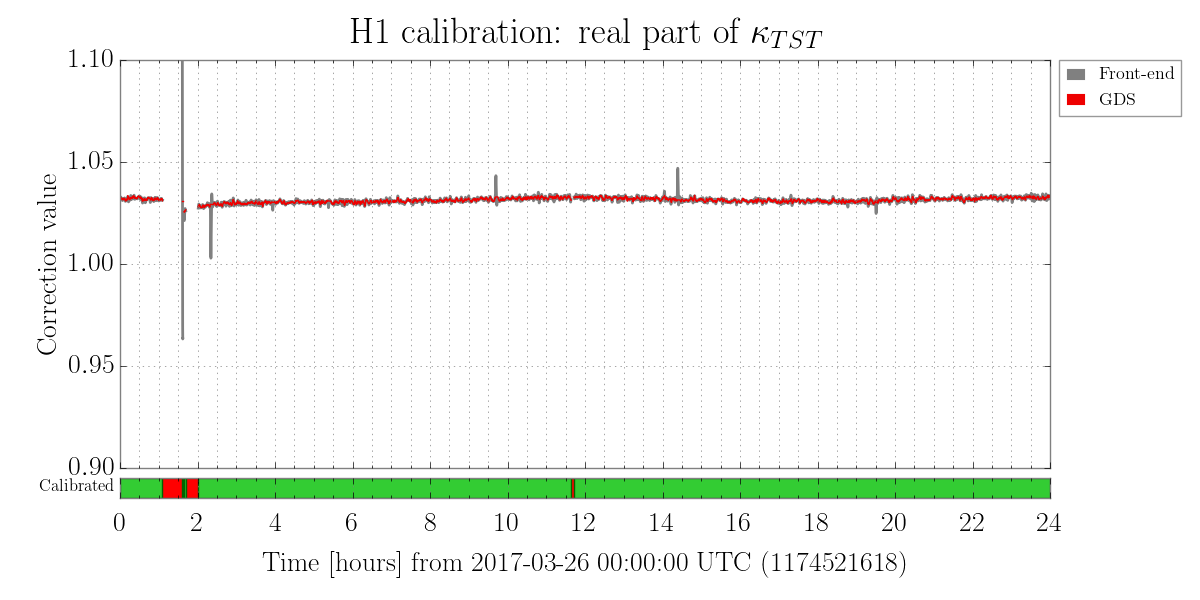
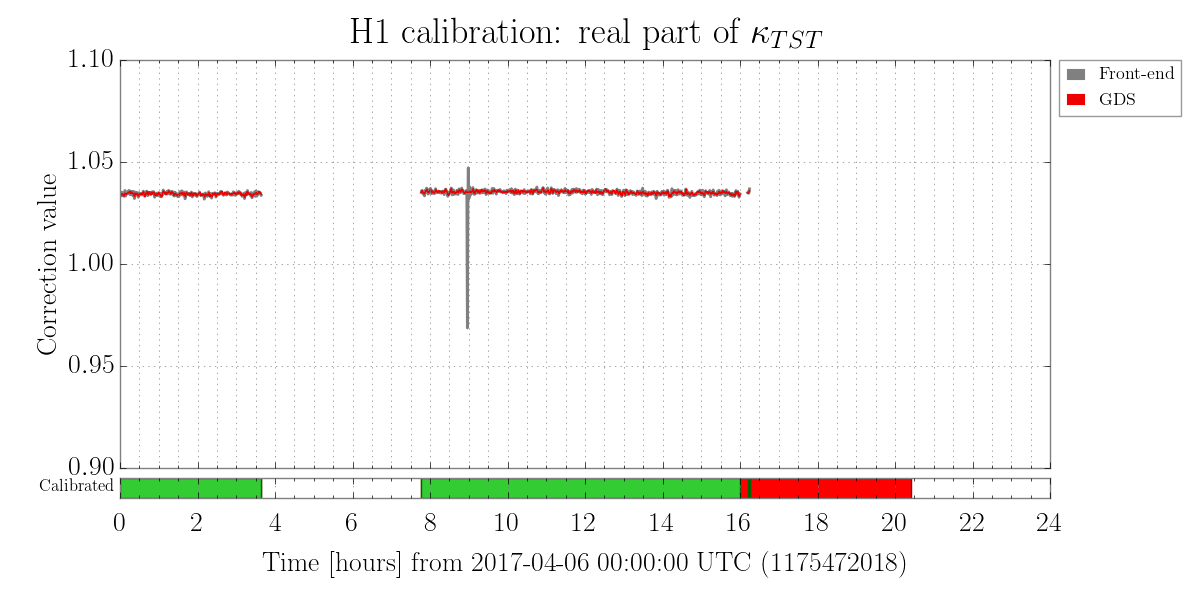
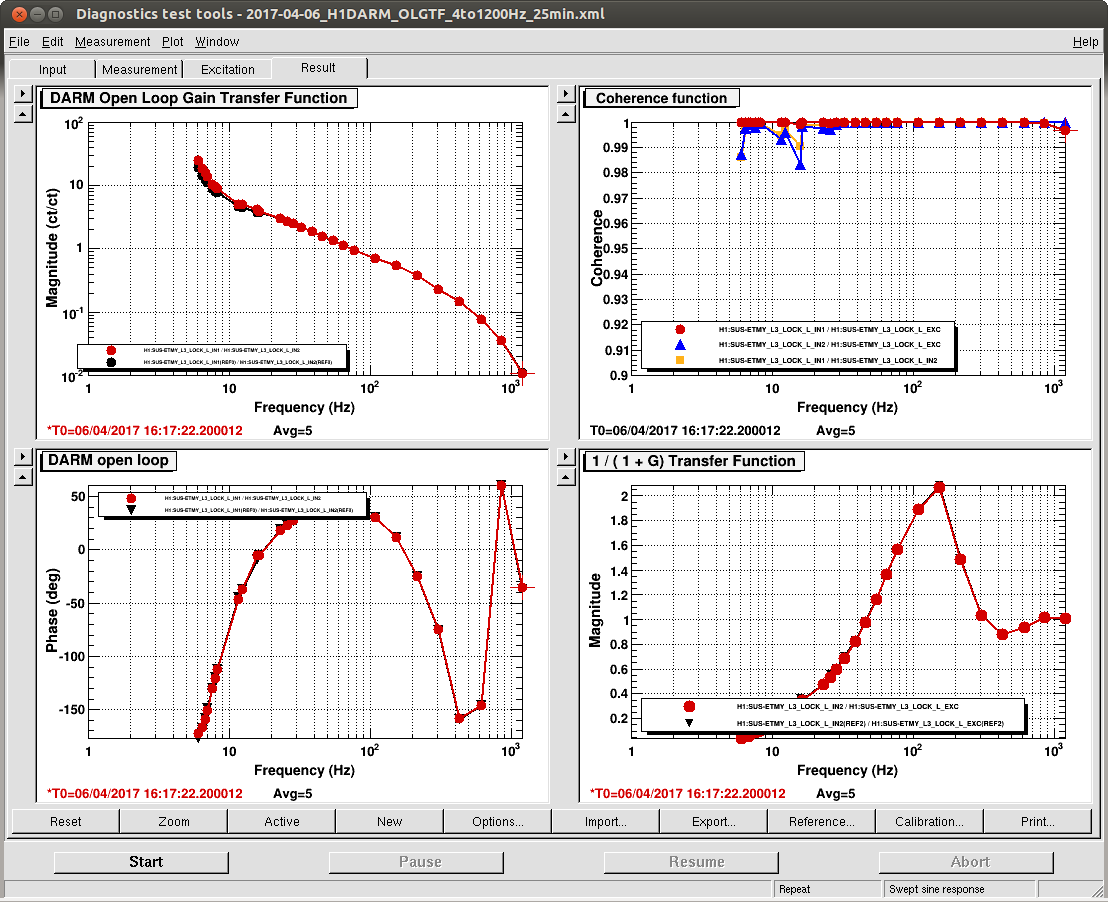
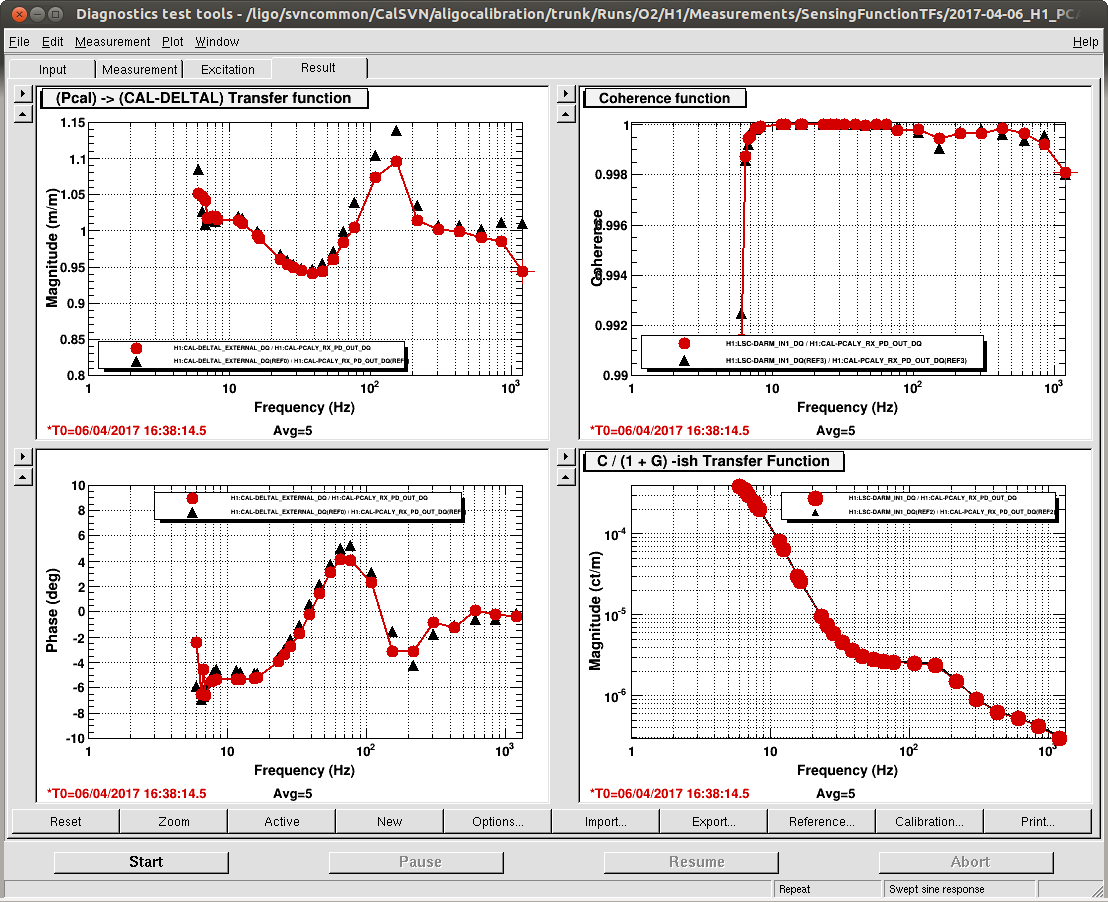
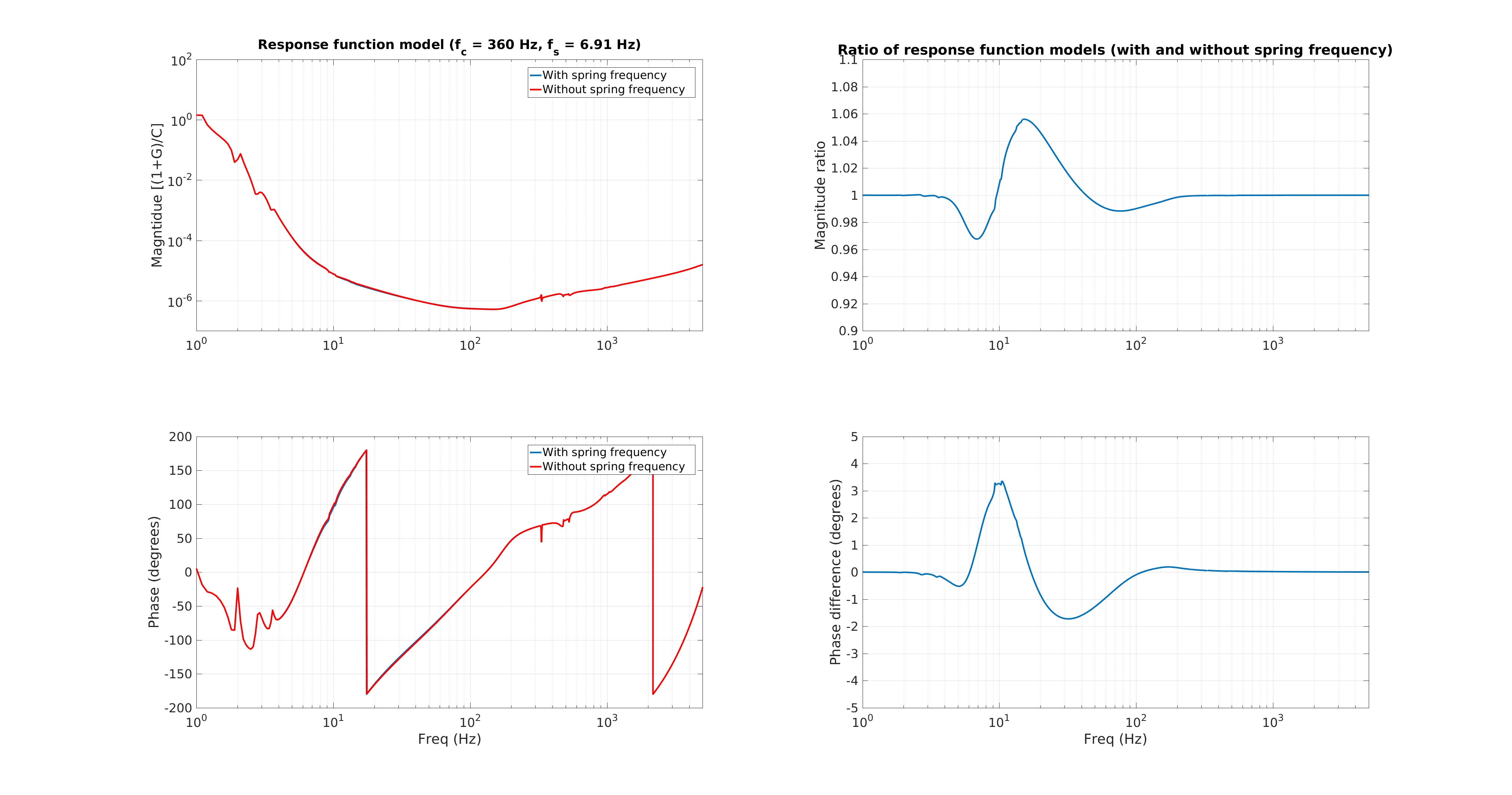
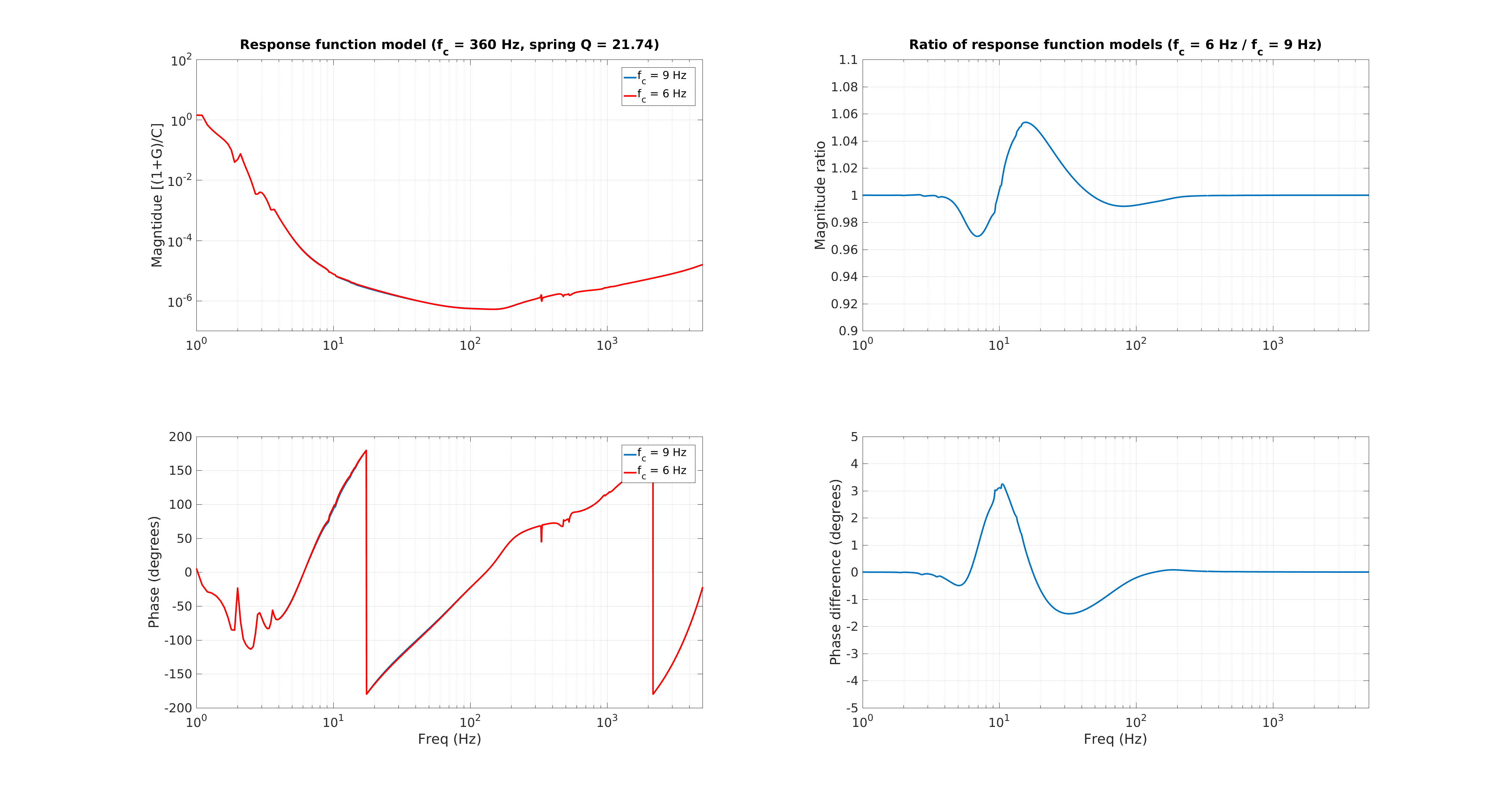
We also have a direct measure of the longitudinal actuation strength relative to a given reference time, as measured by the 35.9 Hz vs. 36.7 Hz ETMY SUS vs. PCALY calibration lines.
Traditionally, (i.e. in O1) when we were not correcting for longitudinal actuation strength change, we wished to keep the effective bias voltage (as measured by angular actuation strength) less than +/- 10-20 [V], because -- if interpreted as longitudinal actuation strength -- meant that any more would result in greater than a 10-20 [V] / 400 [V] = 2.5-5% strength change, which meant the low frequency DARM loop calibration was off by 2.5-5%.
Several things have happened since then (i.e. in O2):
- We regularly flip the bias when each ETMs ESD is not in use, so charge accumulates slower (assuming 50-60% IFO duty cycle, but that's worked less well in times of 80-90% duty cycle)
- We compensate for longitudinal actuation strength change
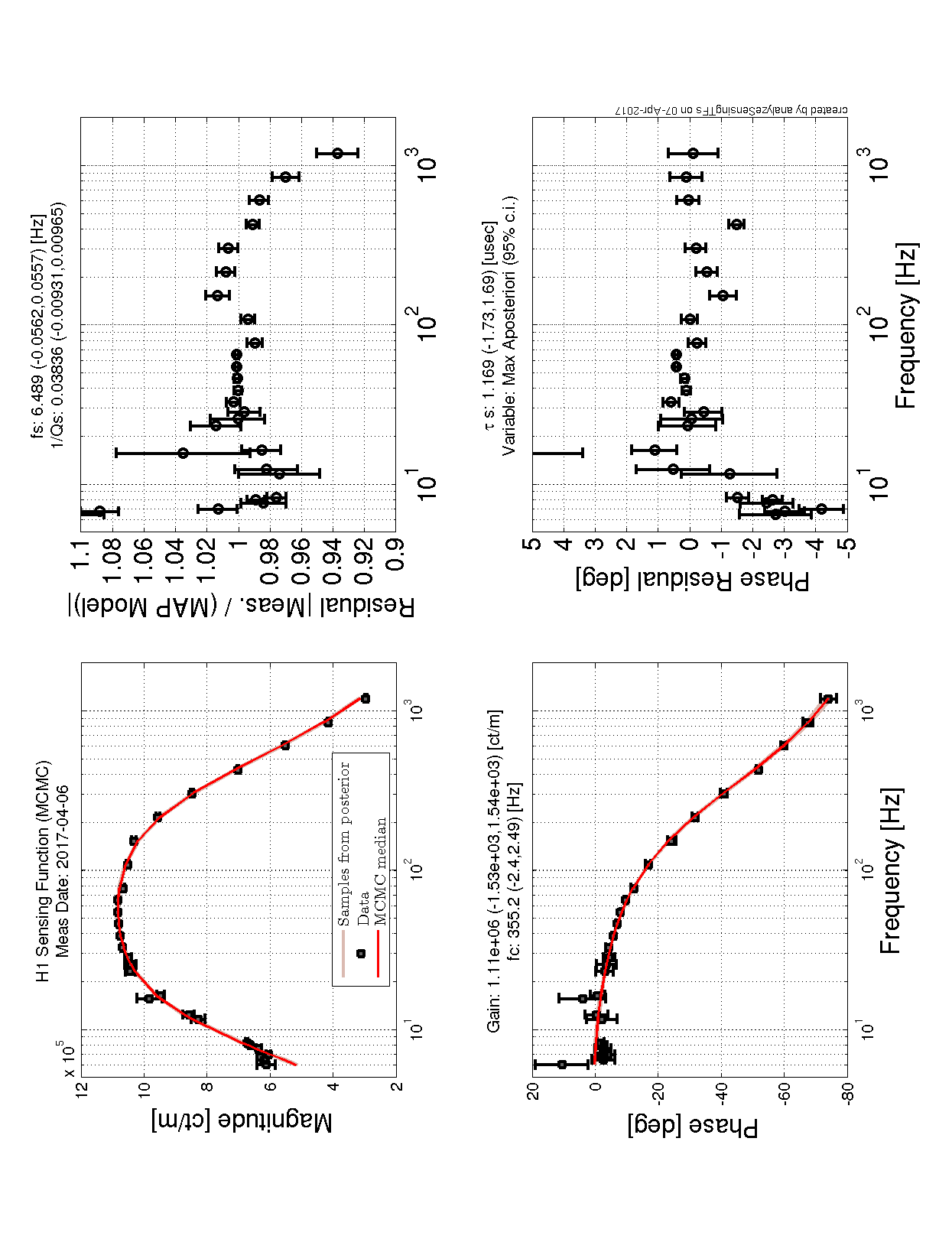
- We regularly create reference times that "reset" the model to which the longitudinal strength is relative
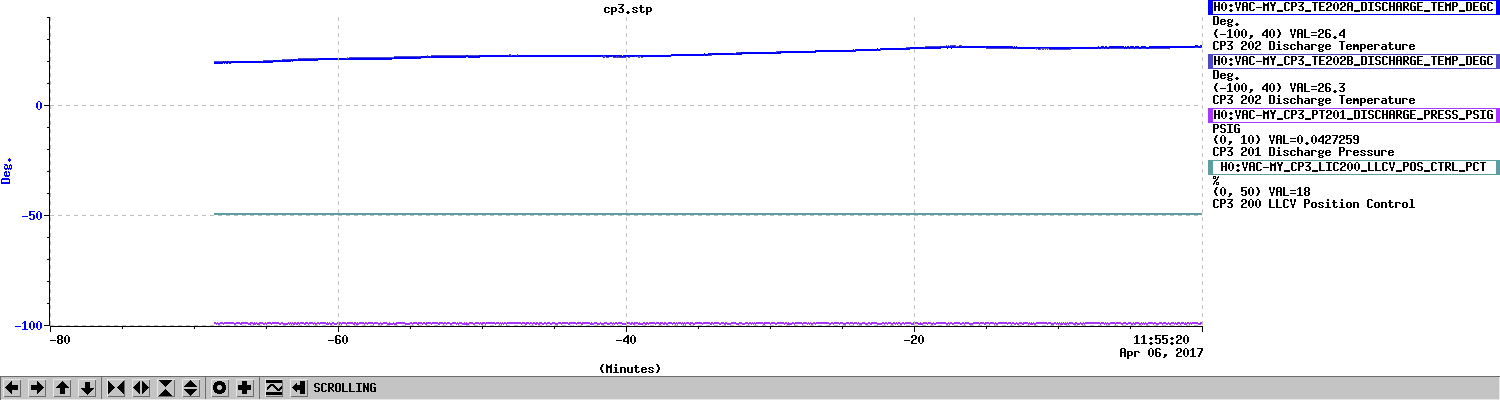
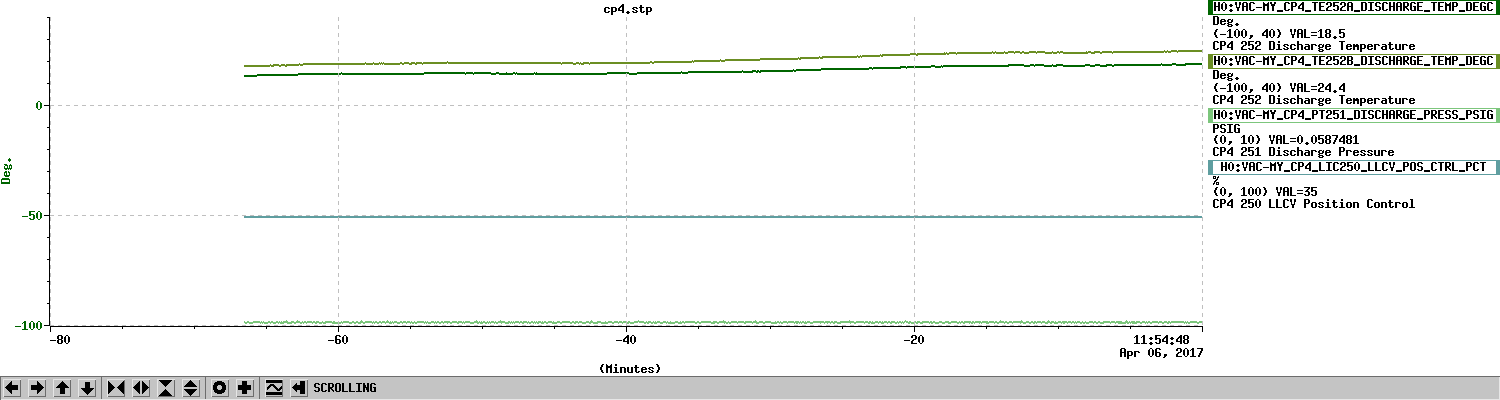
All of this is to set up the conclusion and plots attached.
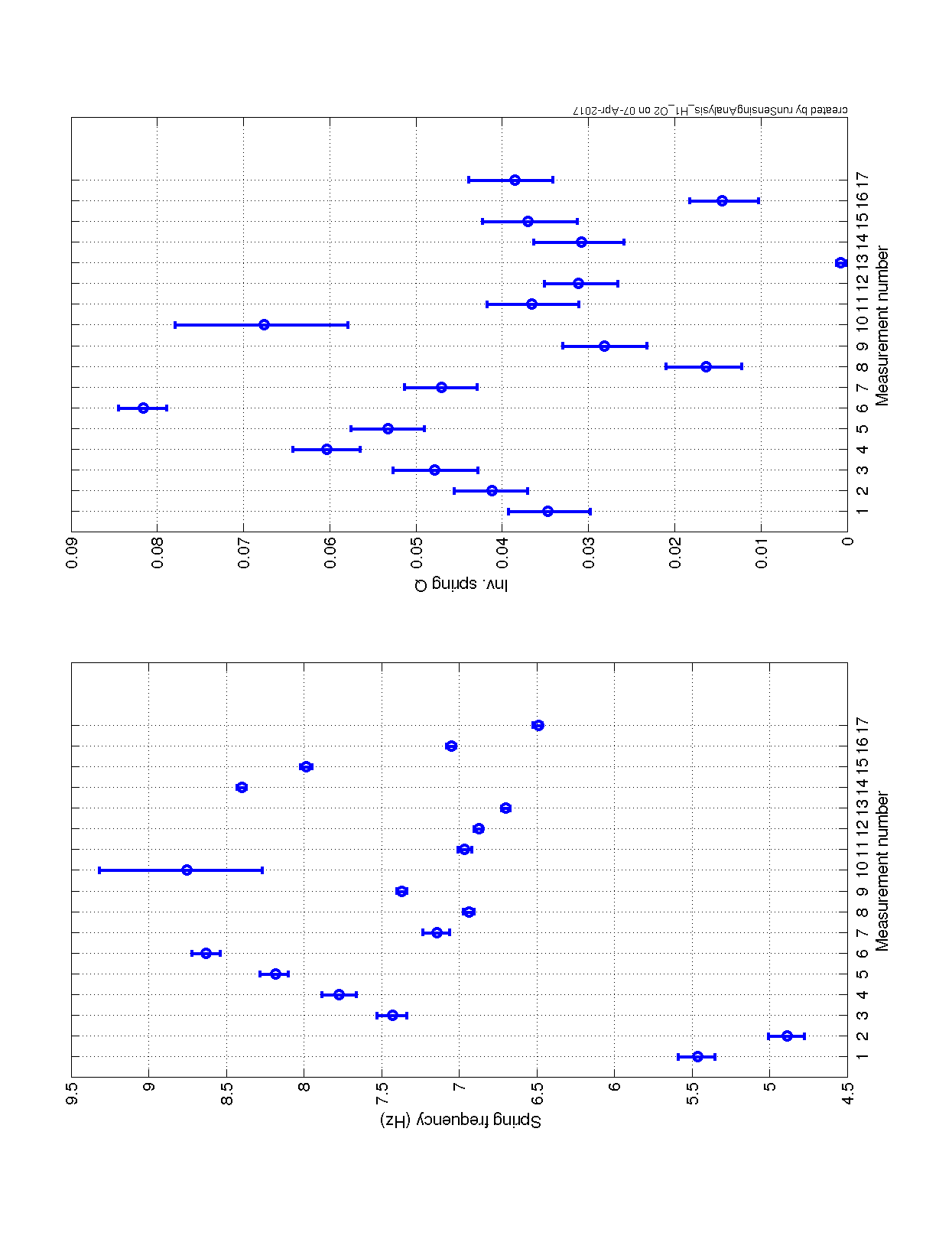
While we see that H1 SUS ETMY's effective bias voltage in each quadrant is at -40 [V] and trending more negative, and if mapped to longitudinal actuation strength relative to zero effective bias voltage is pushing 10%, we're not yet to the point where we need to consider doing anything because the longitudinal actuation strength relative to the 2017-01-04 reference time is only 3-4%. The last 7 plots show how the relative longitudinal actuation strength has slowly grown over the past 3 months (with a snap shot from the summary pages taken every 2 Saturdays, including today).
So -- new recommendation:
- if and when we decide to vent the corner, let's run the ETMY ESD with a constant high requested bias of the opposite sign, so we recover back to zero then resume normal operation.
OR
- if it looks like the schmutz has been successfully removed from ITMX after the vent, there will likely be less detuning, so we should create a new reference model, and reset the strength to which the ESD is relative.