Ops Shift Log: 12/06/2016, Day Shift 16:00 – 00:00 (08:00 - 16:00) Time - UTC (PT)
State of H1: IFO locked in NOMINAL_LOW_NOISE for past 22 hours. Power at 29.1W. Range is 74.1MPc
Intent Bit: Observing
Support: N/A
Incoming Operator: Travis
Shift Summary: IFO has been locked in NOMINAL_LOW_NOISE and Observing mode for the entire shift. Things have been quite and stable. Took IFO to Commissioning for 2 minutes to restart the Guardian Scheduled Injections. In Stand-Down from 20:05 to 21:50 for two GRB Alerts.
Activity Log: Time - UTC (PT)
16:00 (08:00) Take over from TJ
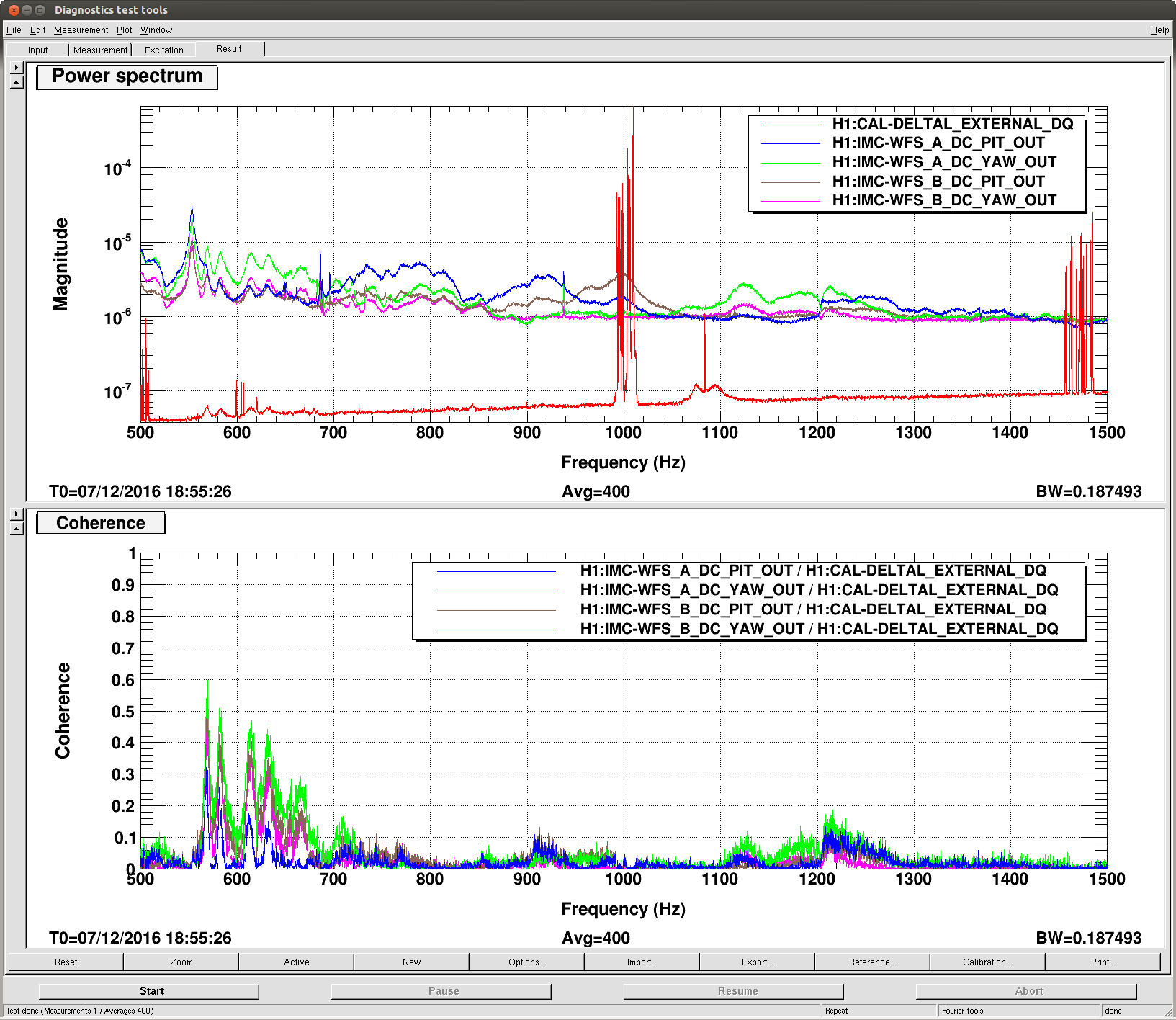
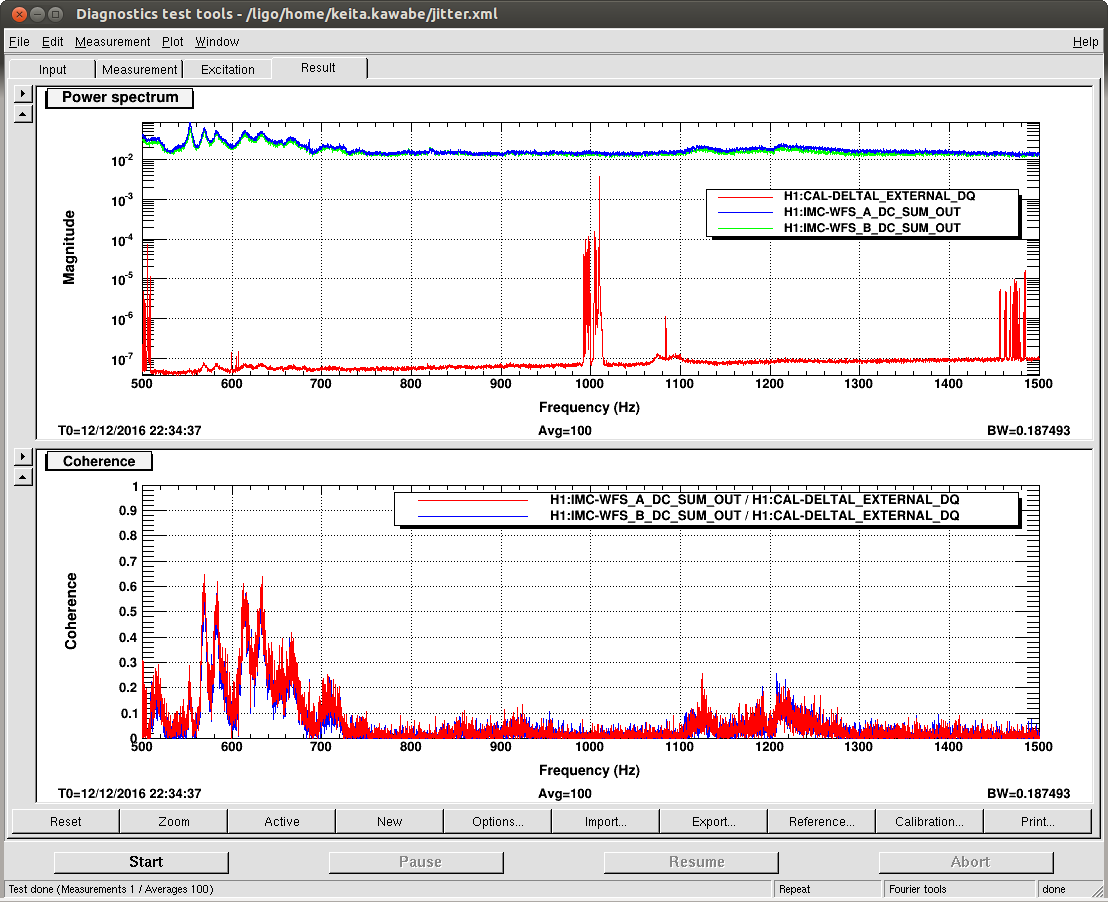
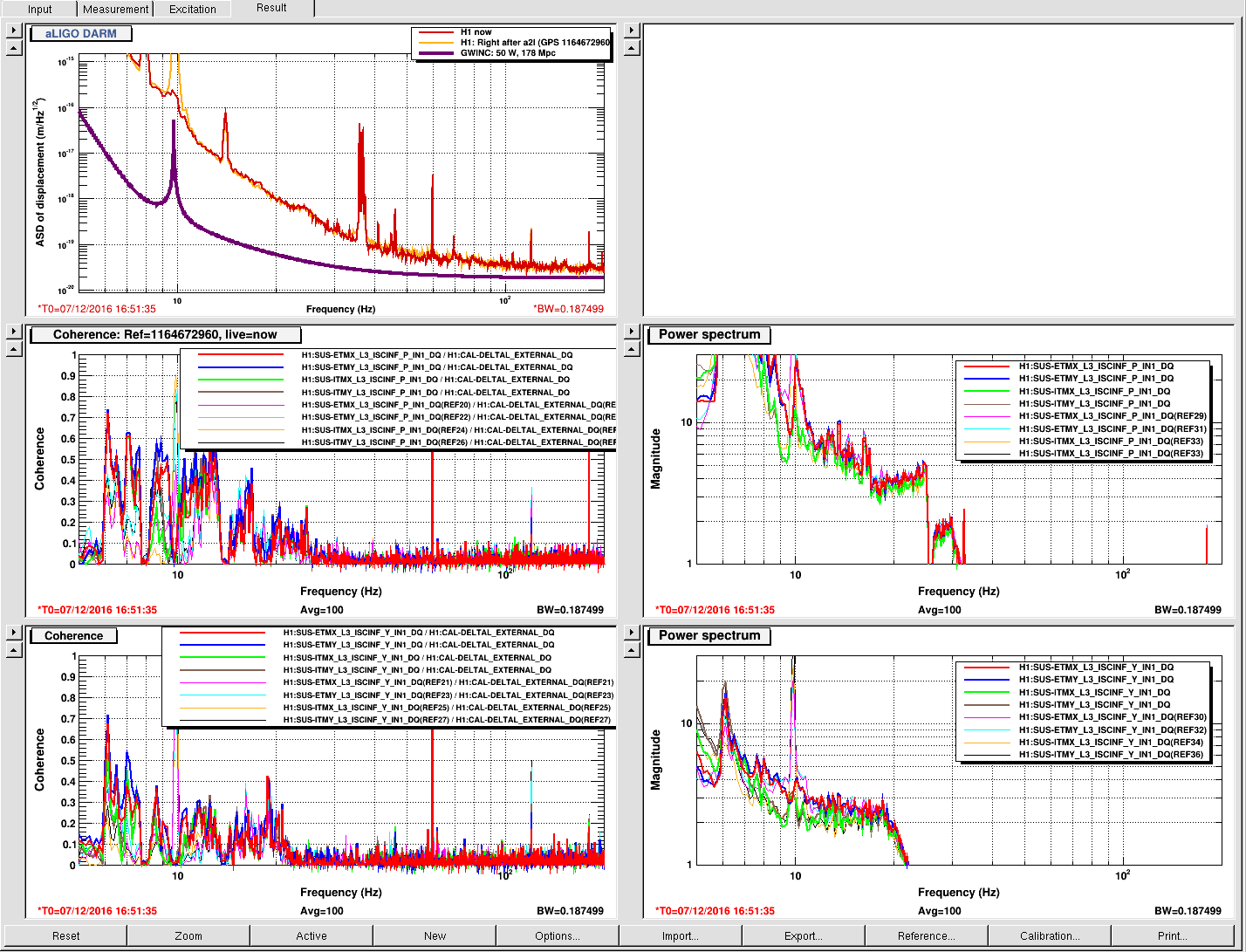
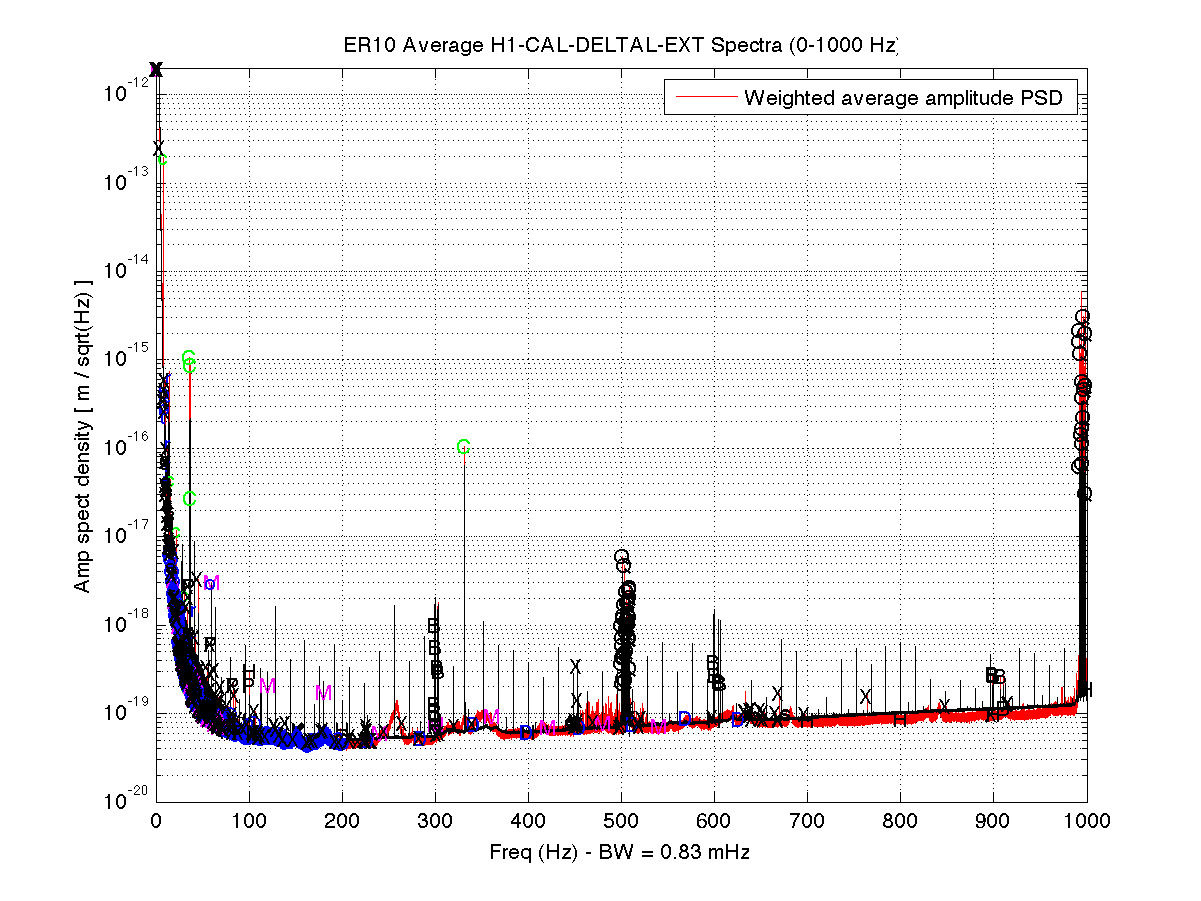
16:50 (08:50) Run A2L check – Coherence is good
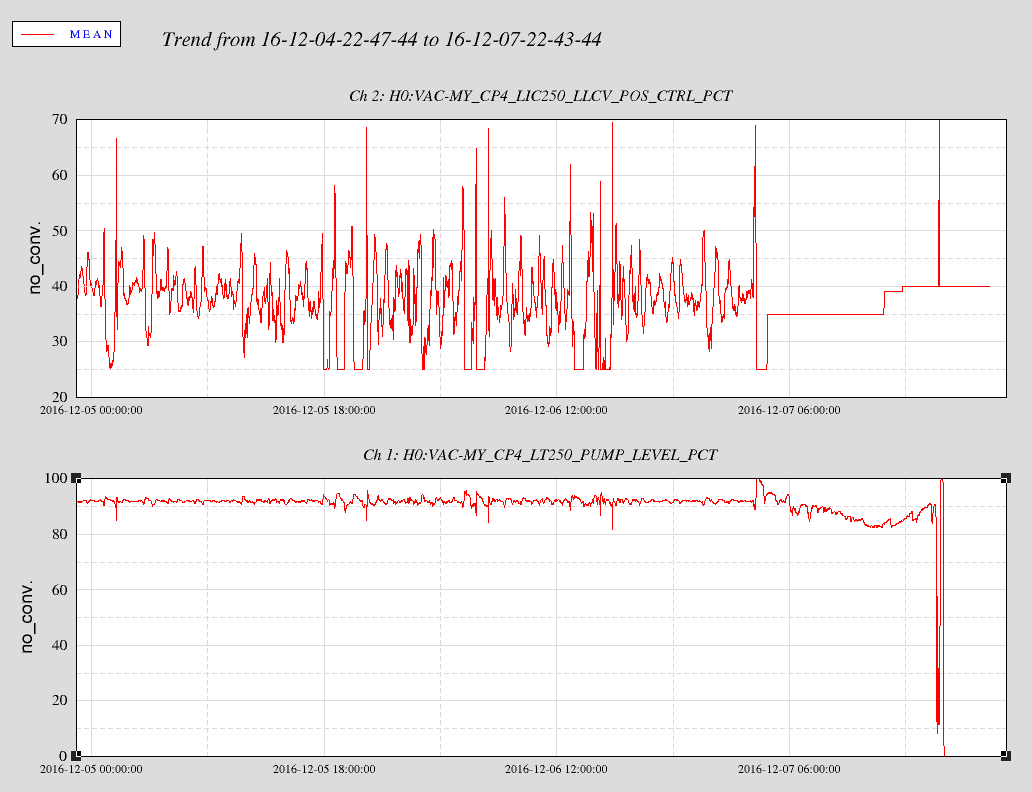
17:08 (09:08) Chandra & Kyle – Going to Mid-Y to work on CP4
18:50 (10:50) Jeff K. – Drop out of Observing to restart Scheduled Injections
18:52 (10:52) Back into Observing
20:00 (12:00) Chandra & Kyle – Back from Mid-Y
20:05 (12:05) GRB Alert – On stand down until 21:05
20:50 (12:50) GRB Alert – On stand down until 21:50
22:10 (14:27) Marc & Filiberto – Going down X-Arm (before Mid Station) transformer room
22:27 (14:27) Marc & Filiberto – Back from X-Arm
22:39 (14:39) Kyle – Going to Mid-Y
23:54 (15:54) Chandra – Going to Mid-X and Mid-Y
00:00 (16:00) Turn over to Travis