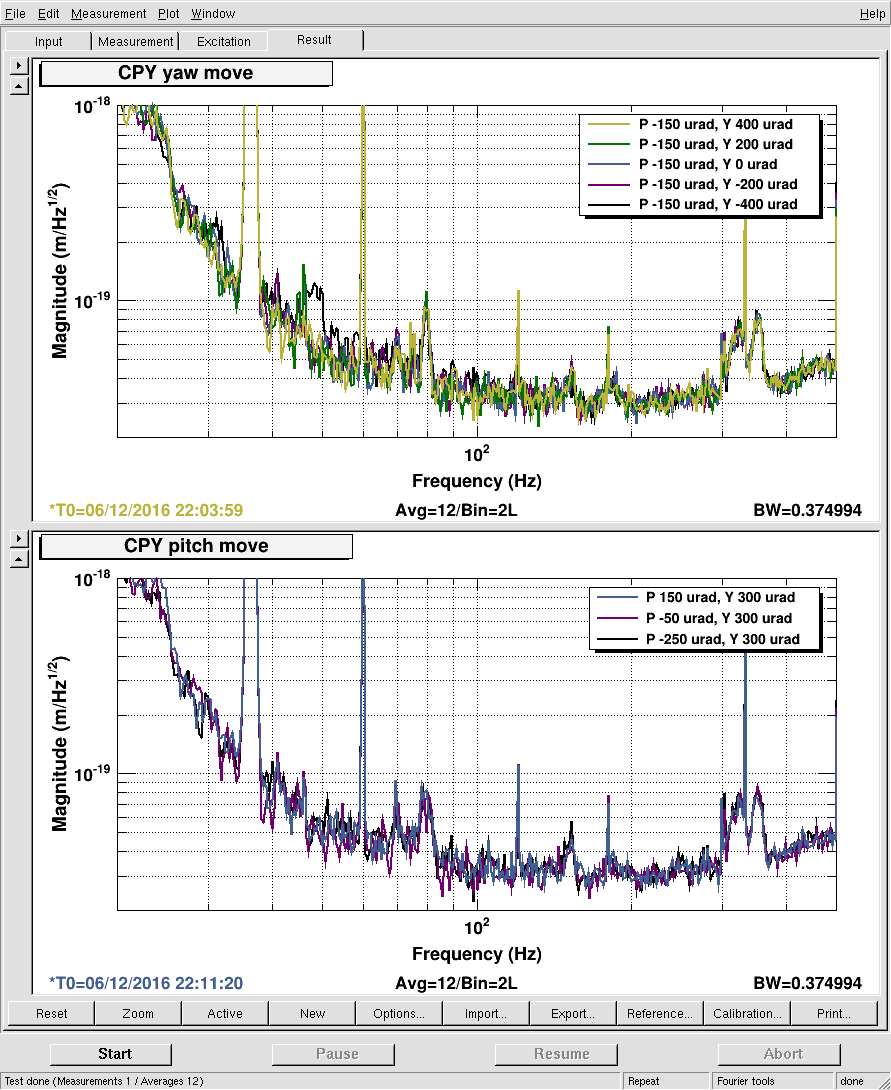
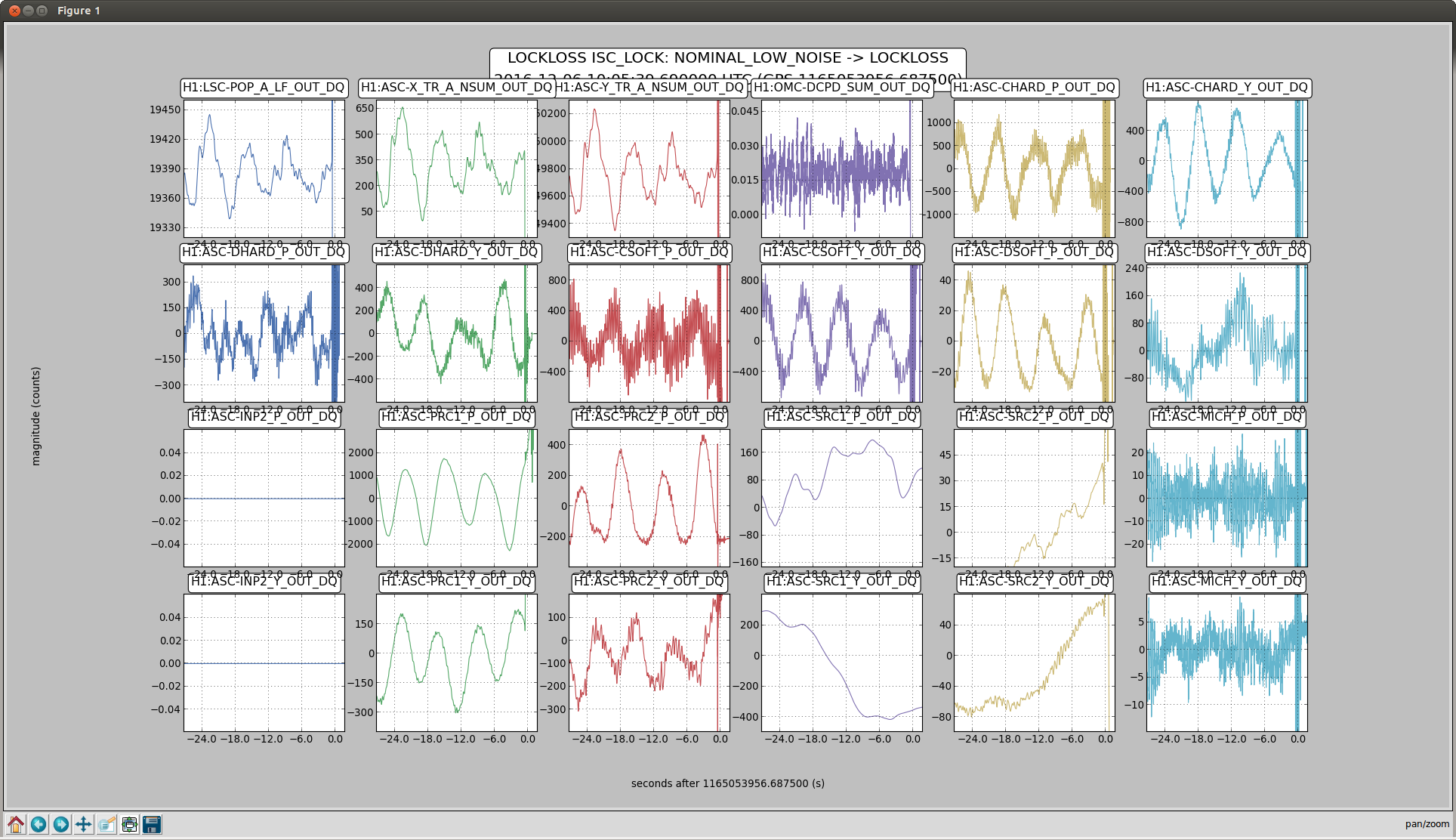
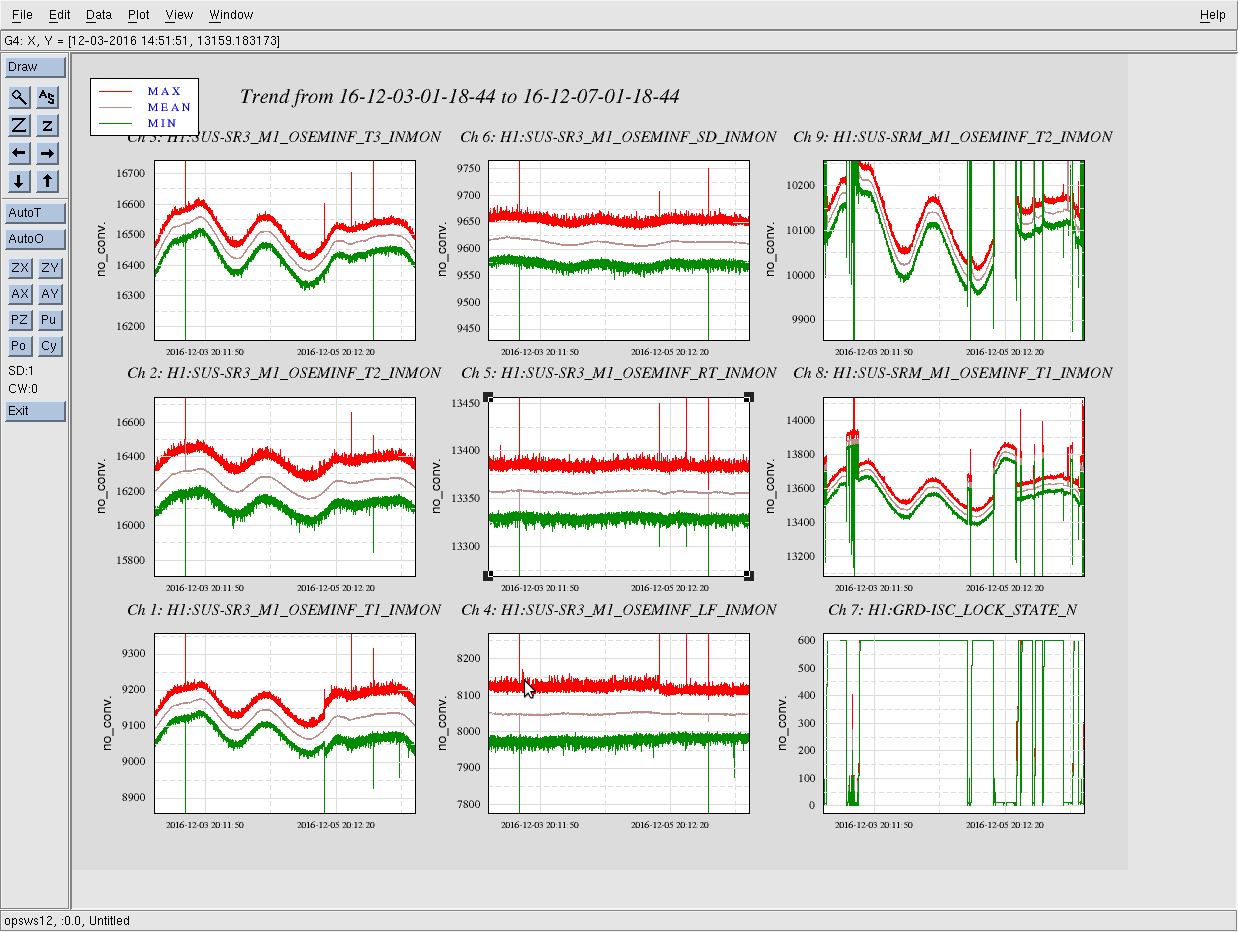
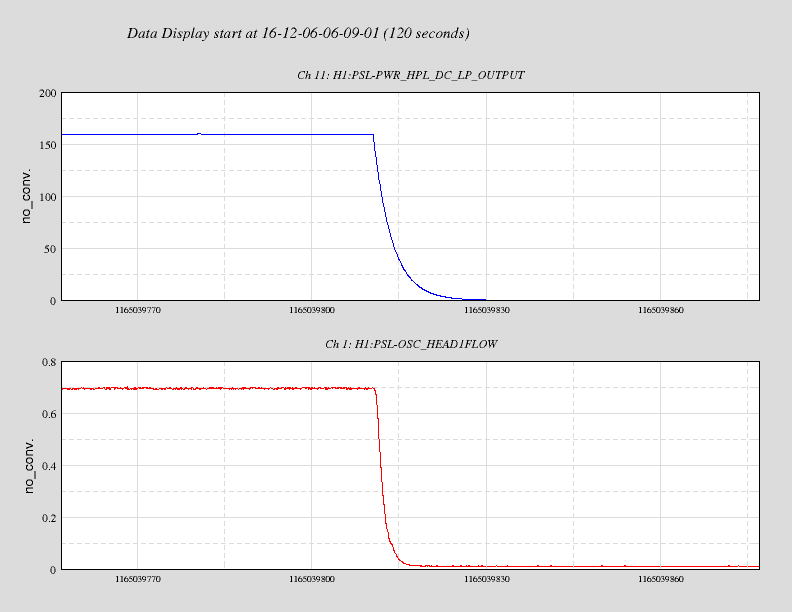
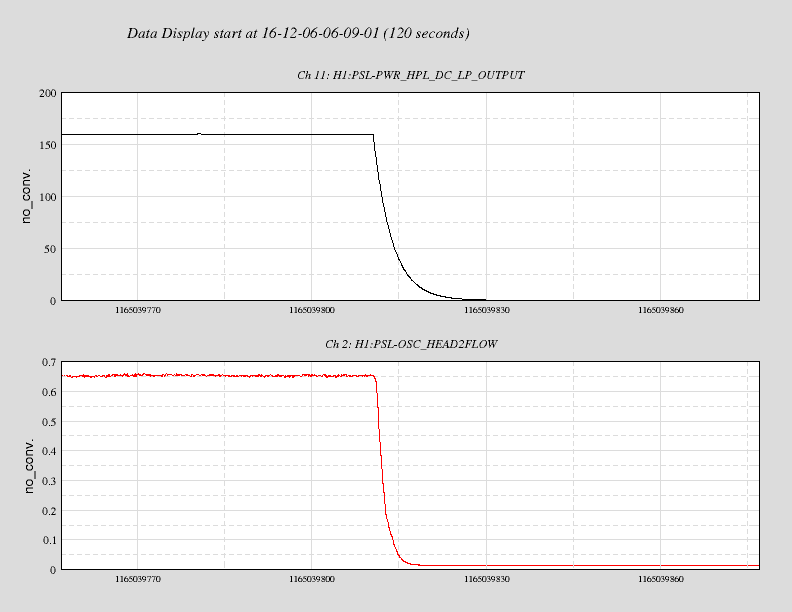
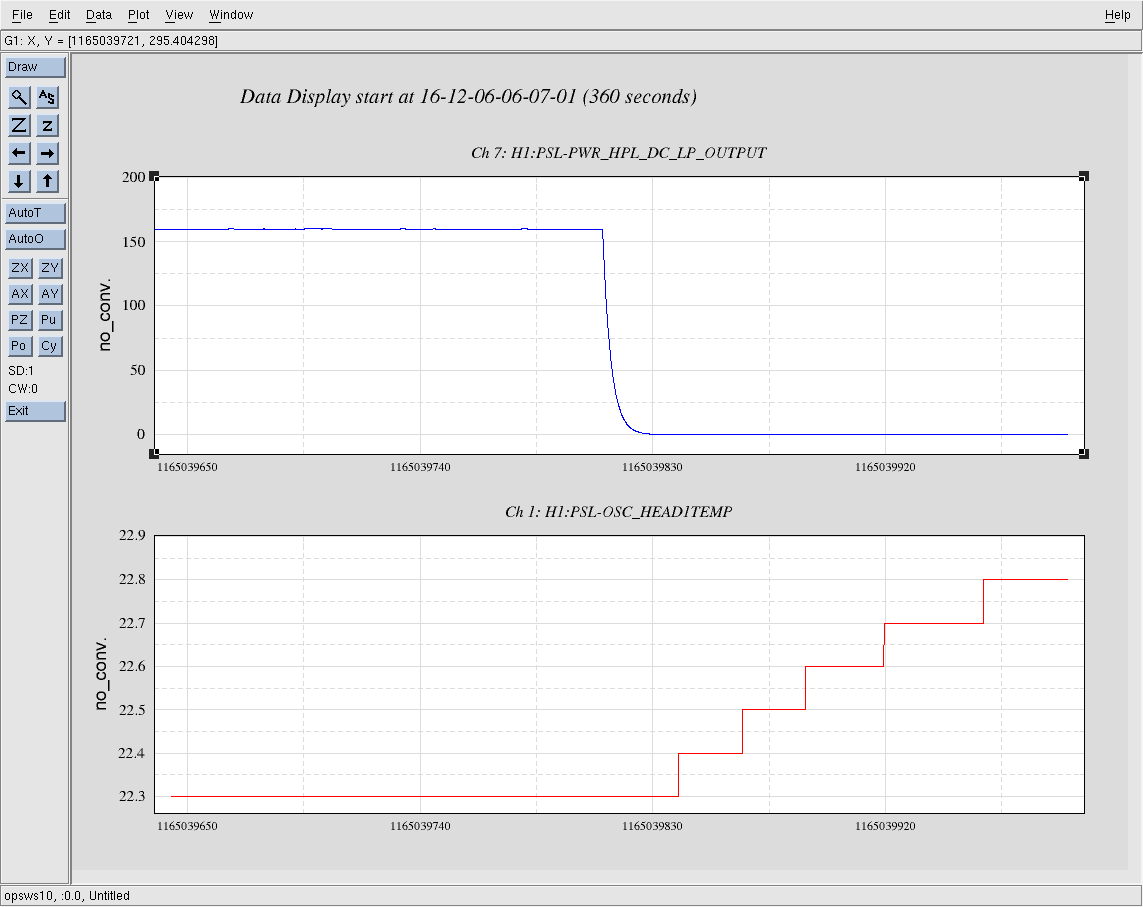
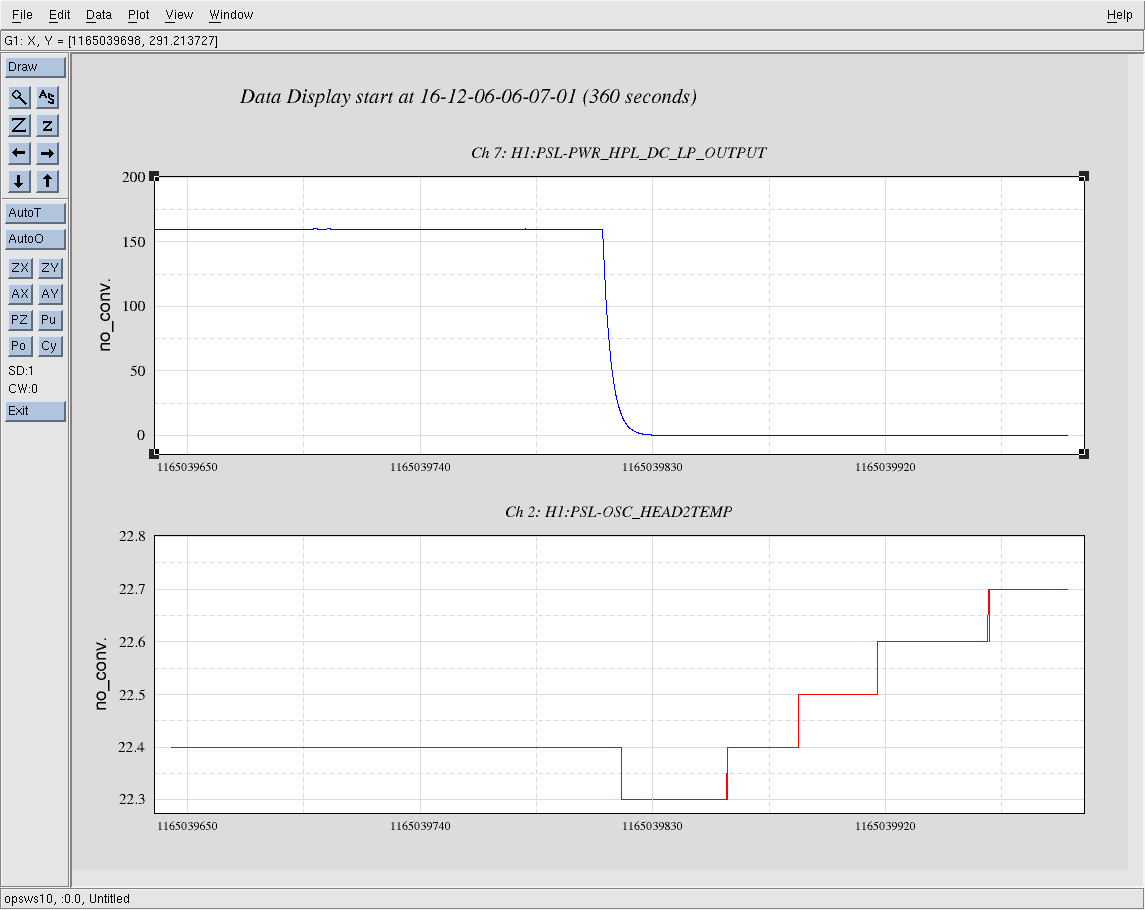
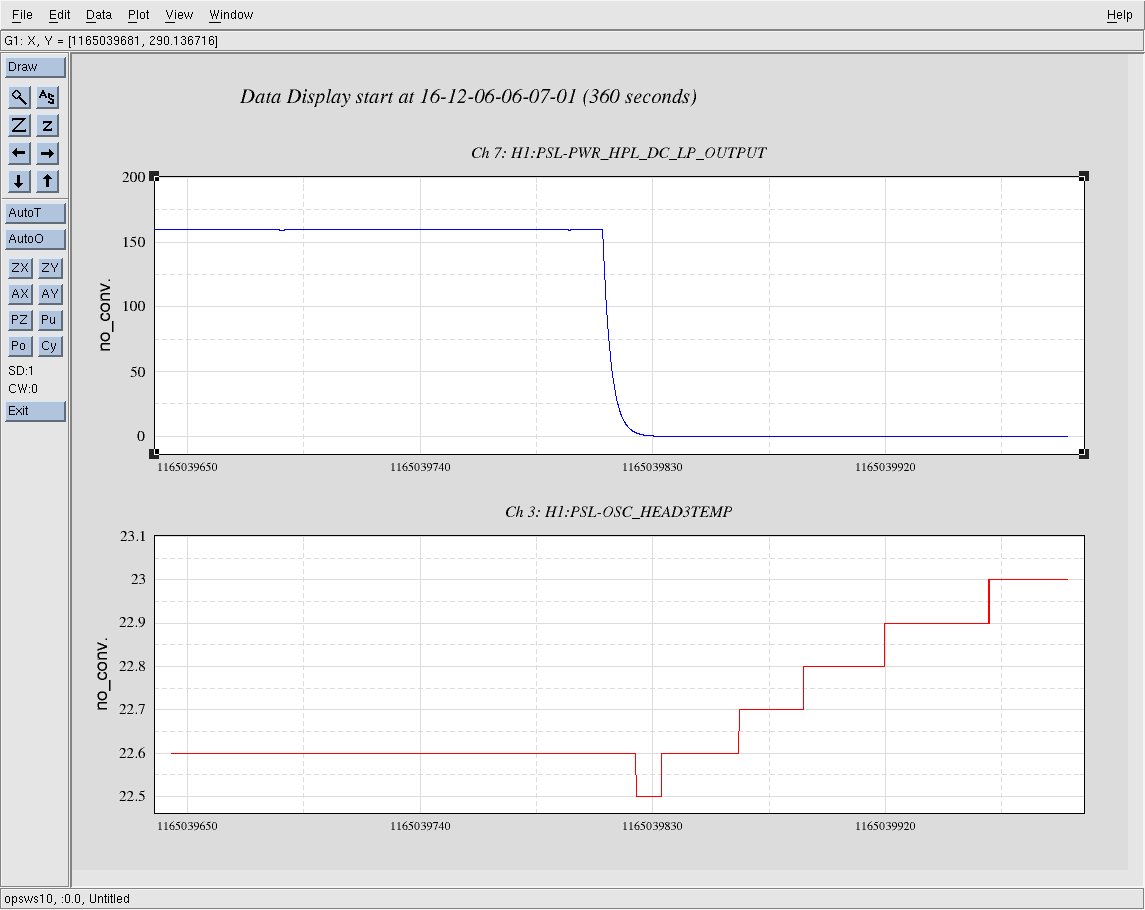
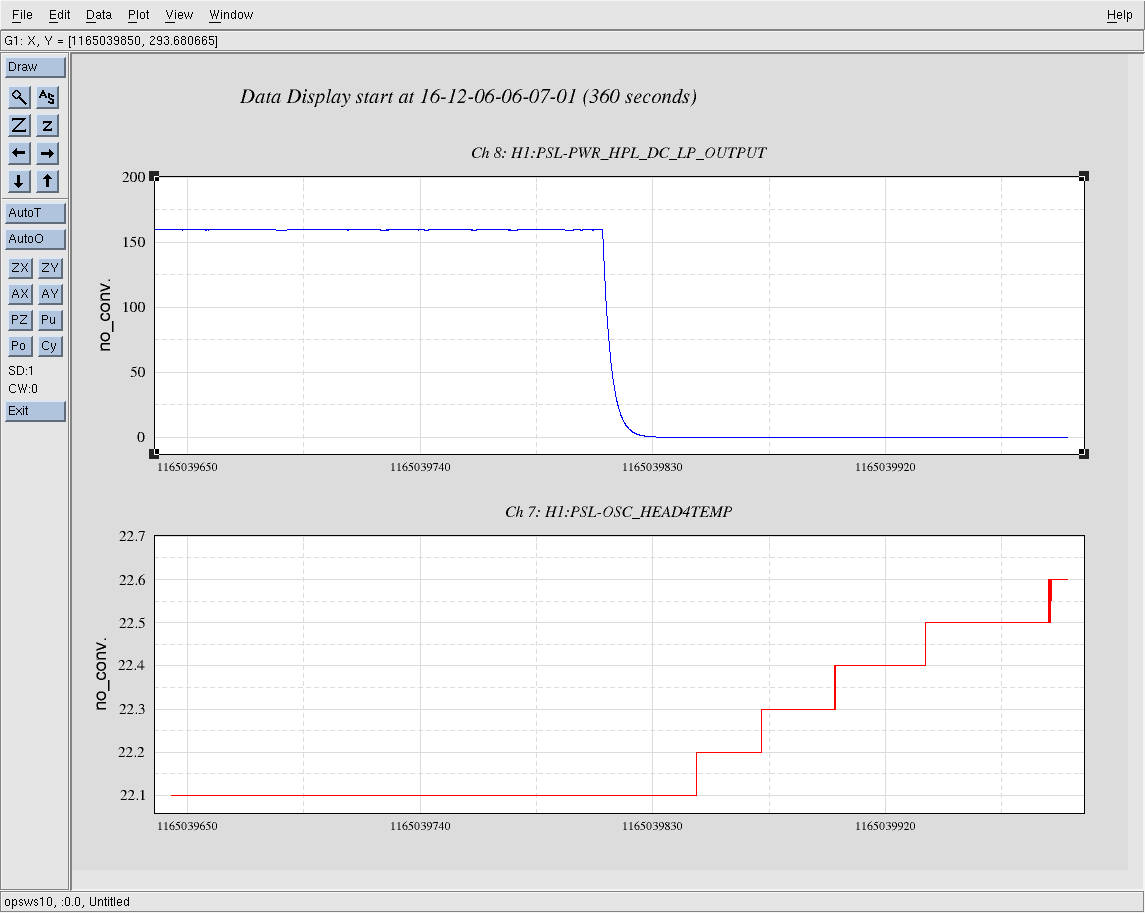
kyle.ryan@LIGO.ORG - posted 14:59, Tuesday 06 December 2016 - last comment - 16:42, Tuesday 06 December 2016(32260)
Rotating shaft vacuum pumps running @ BSC8 past maintenance day
(see WP #6377) Having not asked for permission, I am now asking for forgiveness! It was my intention to shut down the temporary pump setup @ BSC8 at the end of maintenance today. Instead, I have left the setup running. Obviously, we will shut it down if/when directed to do so. As is, we have just this morning entered in to the "pressure region of interest" for our long-term gauge drift data collection. The nature of the problem doesn't lend itself to 4 hours per week of data collecting. Recall that ON/OFF tests of this setup while in a locked "Low Noise" IFO state produced nothing of interest to the PEM folks just prior to the start of O2.
Comments related to this report