patrick.thomas@LIGO.ORG - posted 08:47, Monday 16 January 2017 - last comment - 08:38, Tuesday 17 January 2017(33336)
Ops Day Shift Transition
ISC_LOCK at DOWN and observatory mode in corrective maintenance upon arrival. The HAM6 ISI is tripped. I will attempt to lock but given the alogs from last night it sounds like I may need help from a commissioner. Running 'ops_auto_alog -t Day' reported an error: patrick.thomas@operator0:~$ ops_auto_alog.py -t Day Traceback (most recent call last): File "/opt/rtcds/userapps/release/cds/h1/scripts/ops_auto_alog.py", line 300, inalog.main(Transition,shift) File "/opt/rtcds/userapps/release/cds/h1/scripts/ops_auto_alog.py", line 218, in main operator = self.get_oper_w_date('{day}-{month_name}'.format(day=lday, month_name=self.all_months[lmonth]), 'Owl') File "/opt/rtcds/userapps/release/cds/h1/scripts/ops_auto_alog.py", line 130, in get_oper_w_date date_ln = self.get_date_linum(date) - 1 TypeError: unsupported operand type(s) for -: 'NoneType' and 'int'


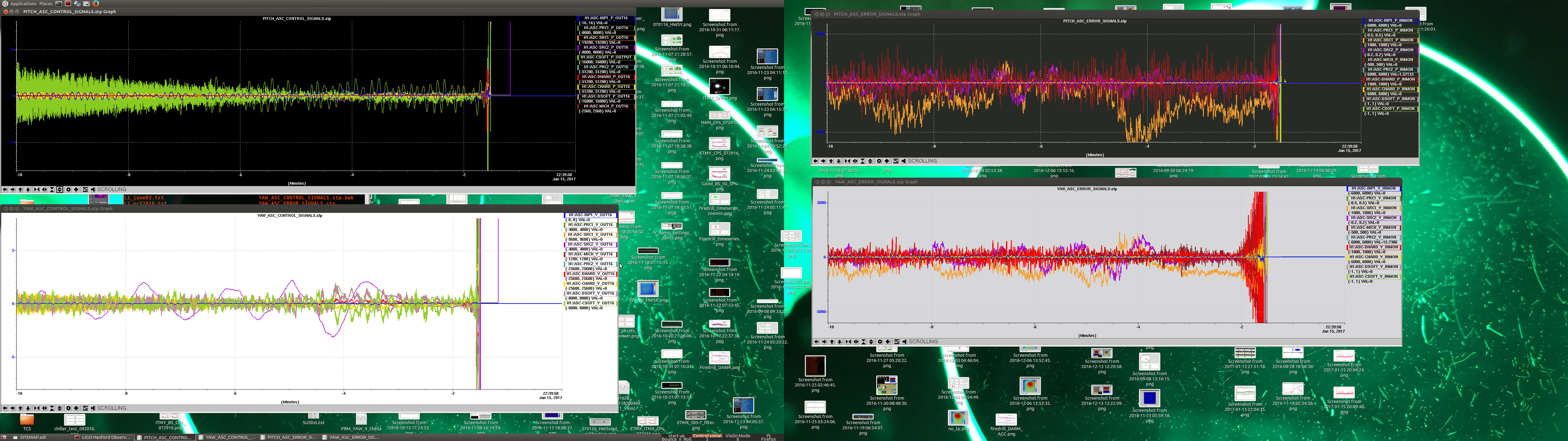
The ops_auto_alog.py error seems to be an issue with only the ops account, I can et it to work on other accounts on both the operator0 machine and opsws12. Jim Batch mentioned some issues with the ops account this morning so they may be related.