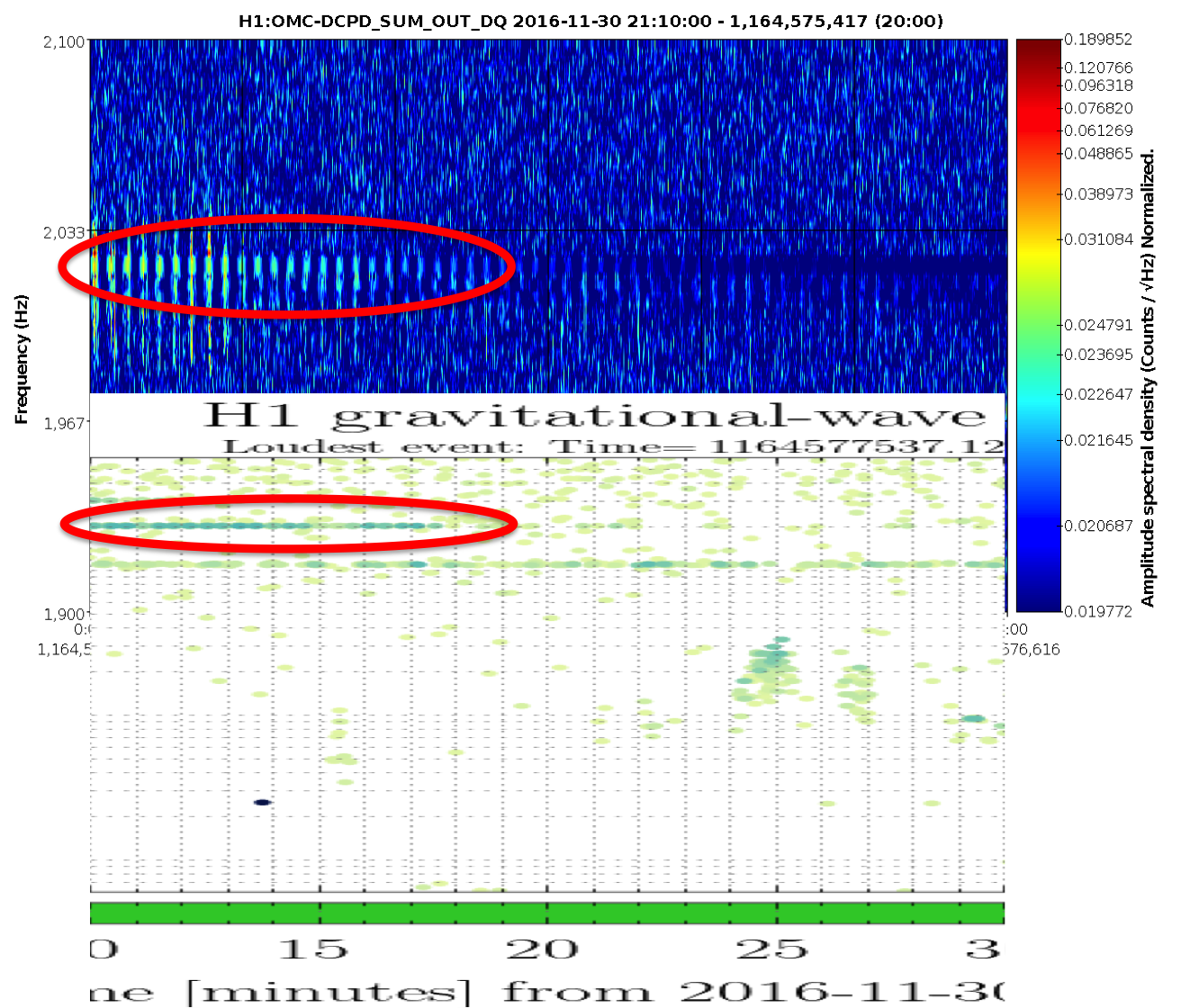
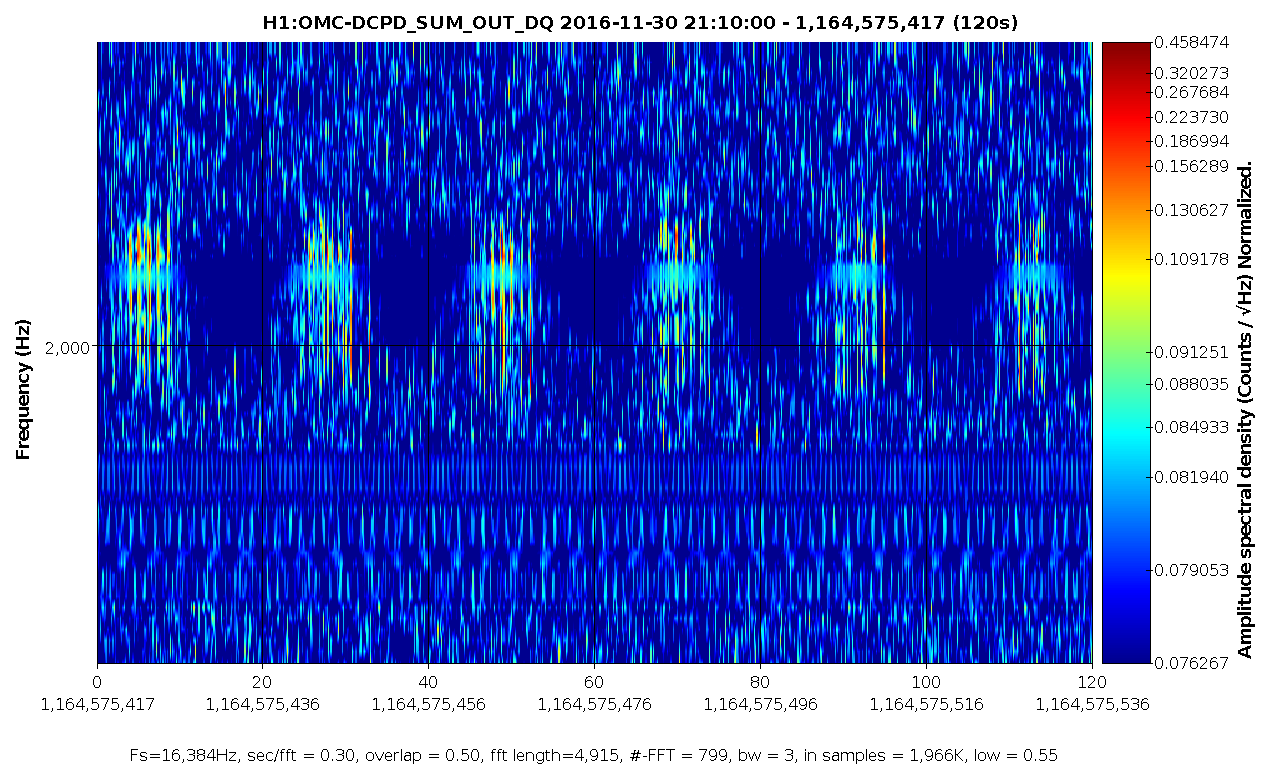
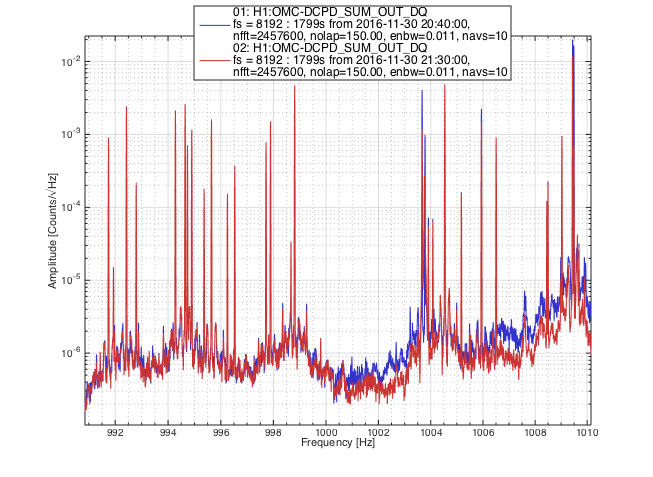
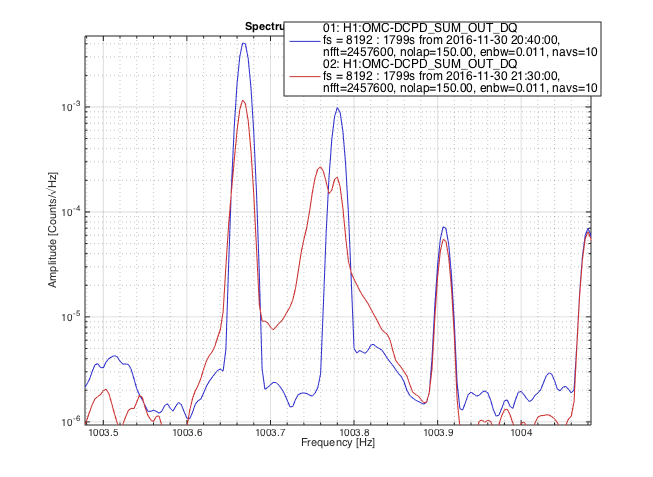
patrick.thomas@LIGO.ORG - posted 11:16, Sunday 15 January 2017 - last comment - 15:47, Sunday 15 January 2017(33306)
Still attempting to lock ALSY
I have run the dither alignment twice for both TMSY and ITMY. This improved things to the point that I can now get flashes and lock at around .28. However I am still struggling to improve on this.
Comments related to this report

{kind=link}
{kind=link}