
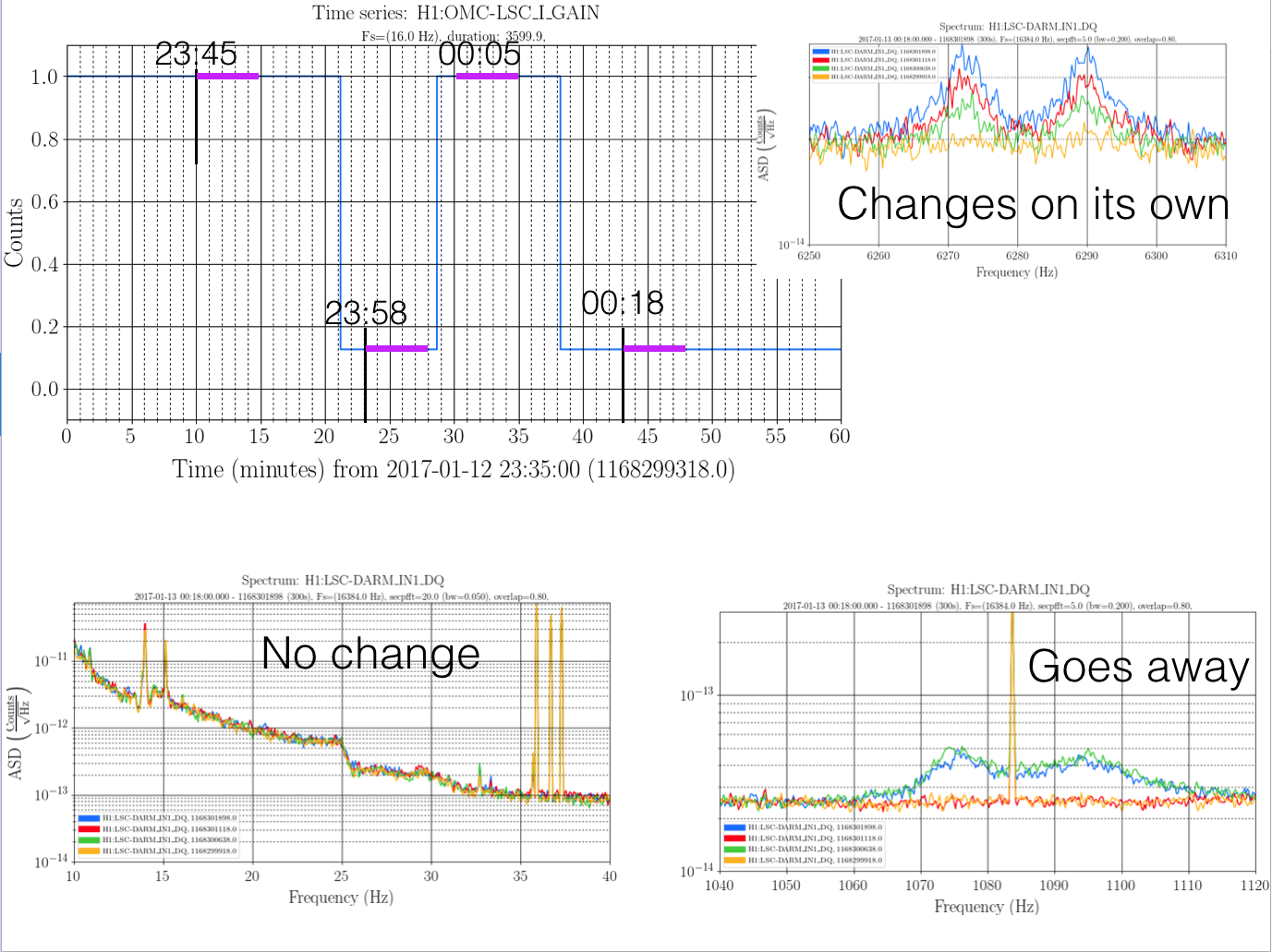
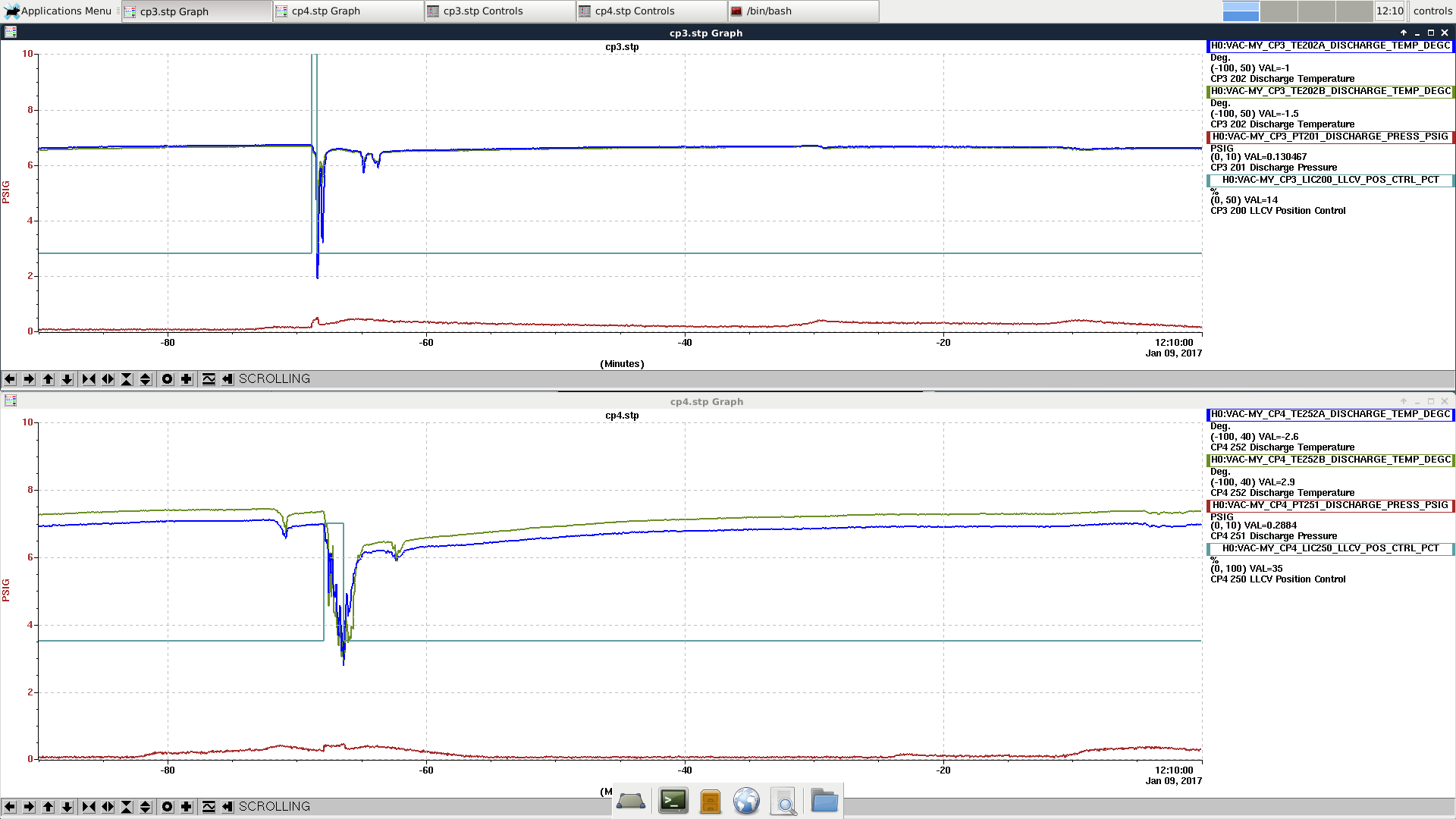
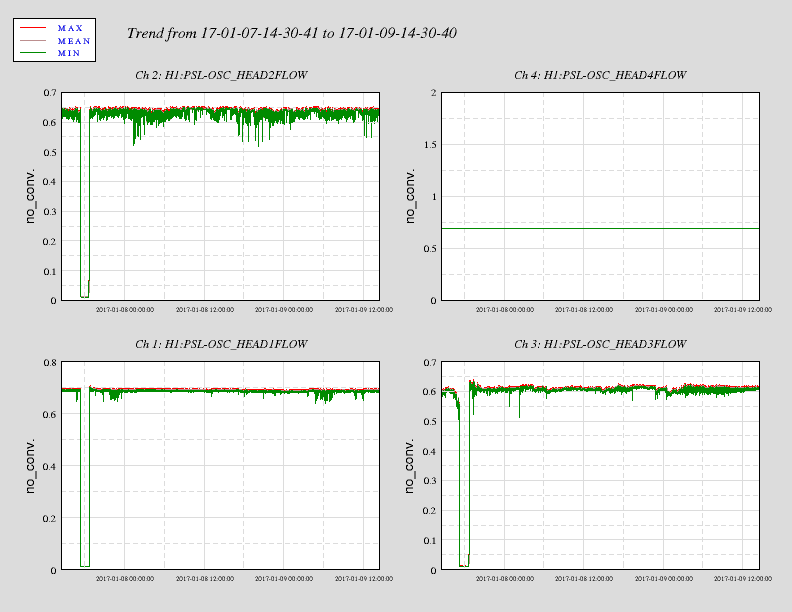
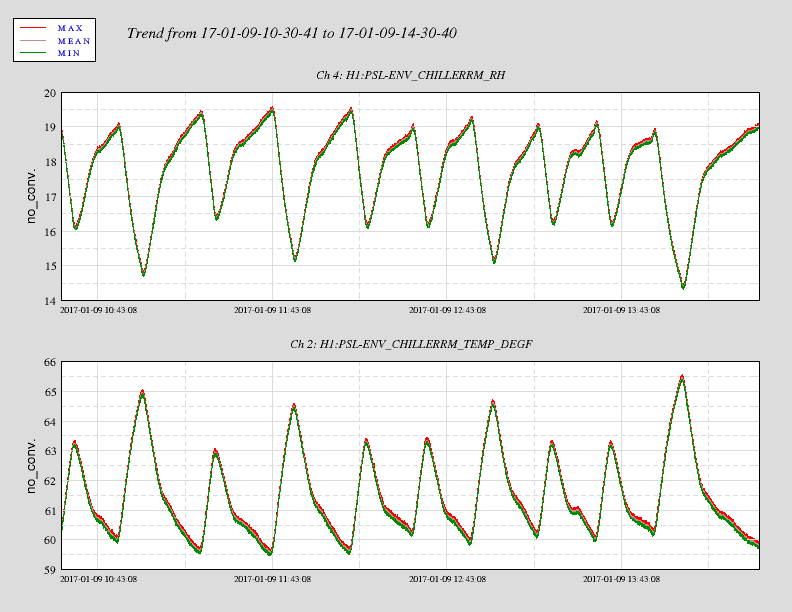
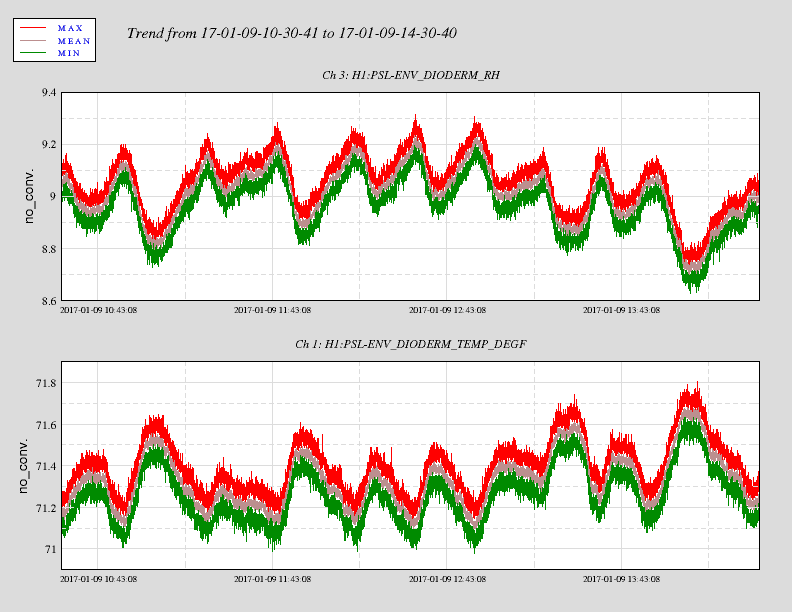
... Winter Weather Advisory remains in effect until 7 am PST Monday... * locations... Connell... Prosser... Tri-Cities. * Ice accumulations... less than a tenth of an inch. * Snow accumulations... 1 to 2 inches of snow and sleet. * Timing... wintry will continue through 4 PM. Another round of precip is expected during the early morning hours of Monday. * Impacts... snow and ice will make roadways hazardous. * Winds... north 5 to 10 mph. * Temperatures... in the lower 20s... rising into the upper 20s and lower 30s Sunday evening. * Snow level... basin floor rising to 1000 feet Sunday evening. * Web page: for a detailed view of the hazard area visit http://www.Wrh.NOAA.Gov/map/?Wfo=pdt. Precautionary/preparedness actions... A Winter Weather Advisory means that periods of snow... sleet... or freezing rain will cause travel difficulties. Be prepared for slippery roads and limited visibilities... and use caution while driving.
|
Updated message
Sunday, January 8th at 1:00 p.m. This message will be updated if conditions change. Due to potential adverse road conditions, Hanford employees will be released from work immediately. Only essential employees needed to maintain minimum safe operations are to remain at work through the remainder of shift. Employees must check with their manager prior to leaving. In addition, swing and graveyard shifts are cancelled for today. Only essential employees needed to maintain minimum safe operations are to report to work at the usual time. Hanford site road crews will be plowing and sanding roads throughout the rest of day. Winter driving conditions should be anticipated during your commute. Employees are urged to use caution and plan for longer commute times. Conditions can change quickly. To get the latest update, please call the Hanford Hotline at 376-9999 before you leave home and tune your car radio to 530 AM as you near the Hanford Site.
For specific questions regarding company policy contact your manager. |



{kind=link}
{kind=link}