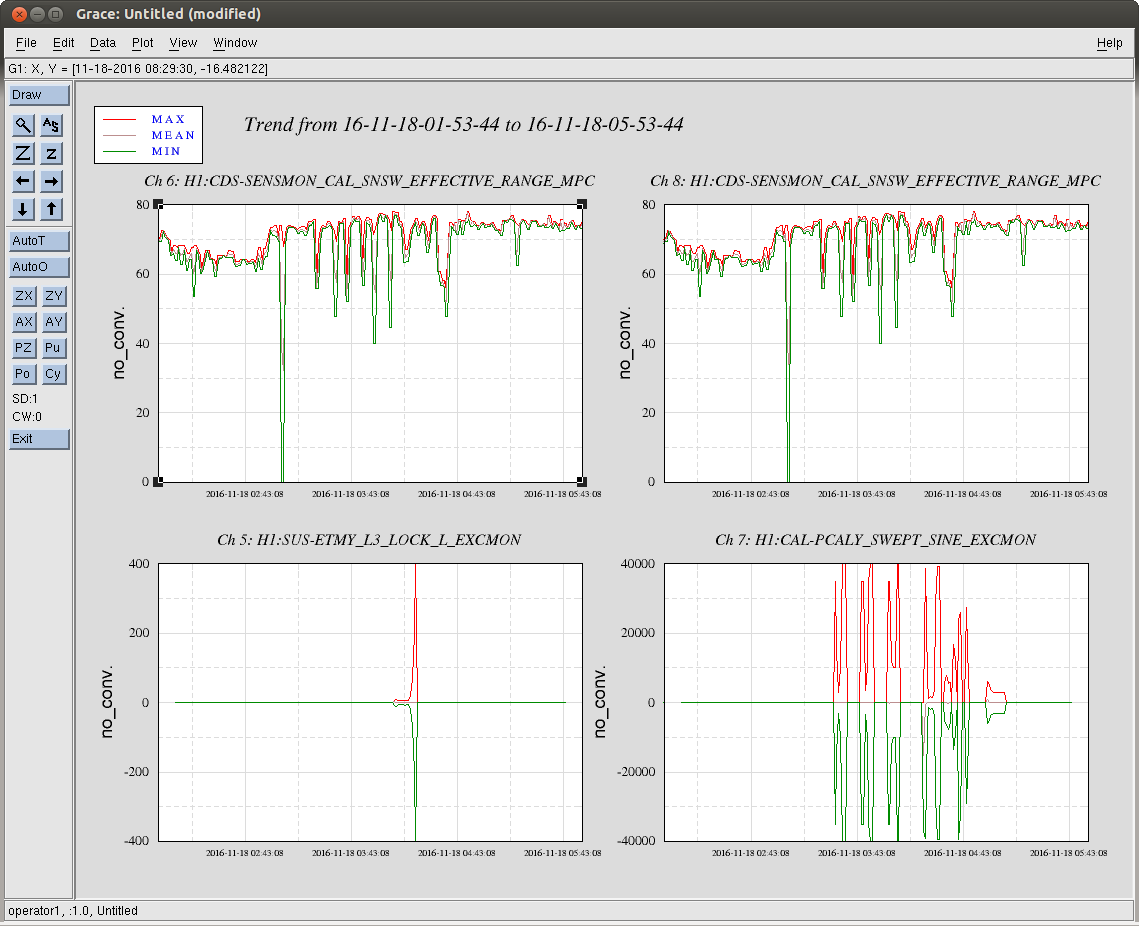
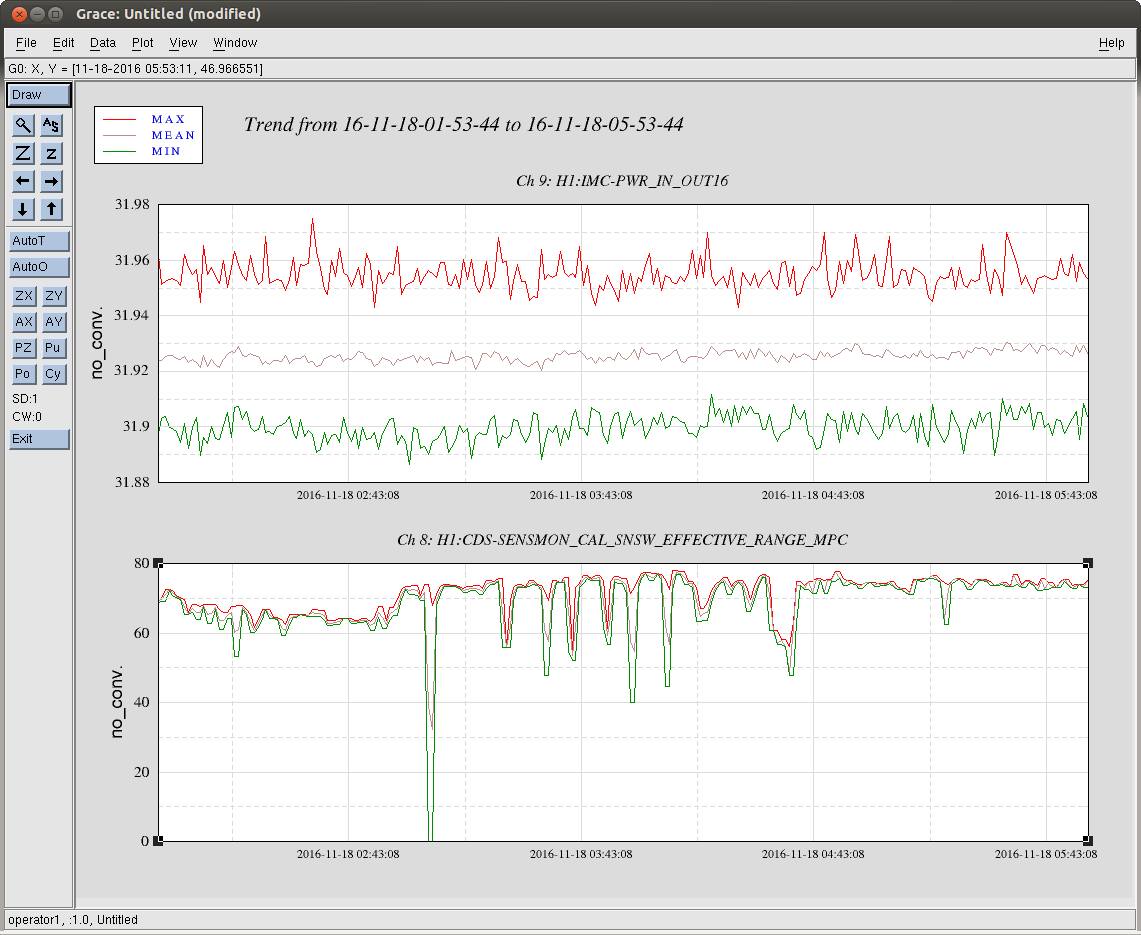
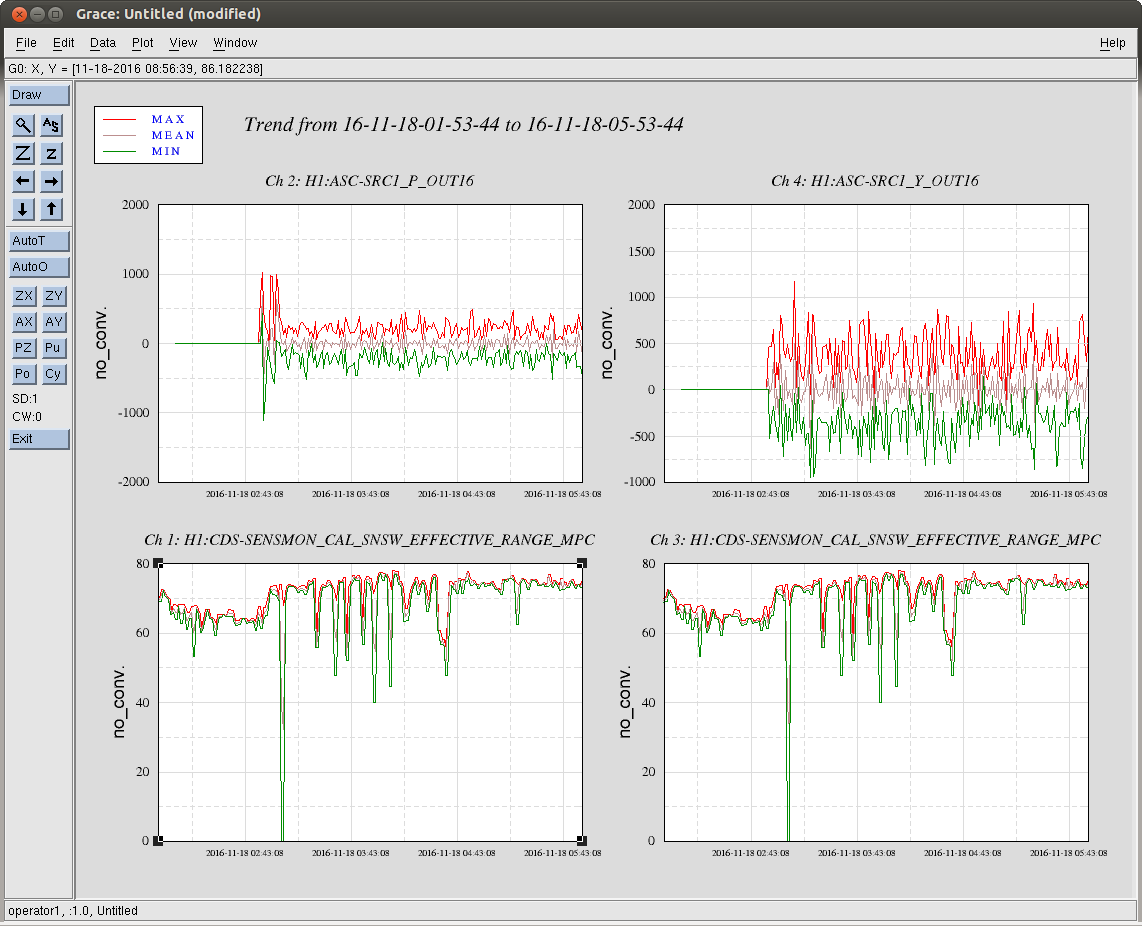
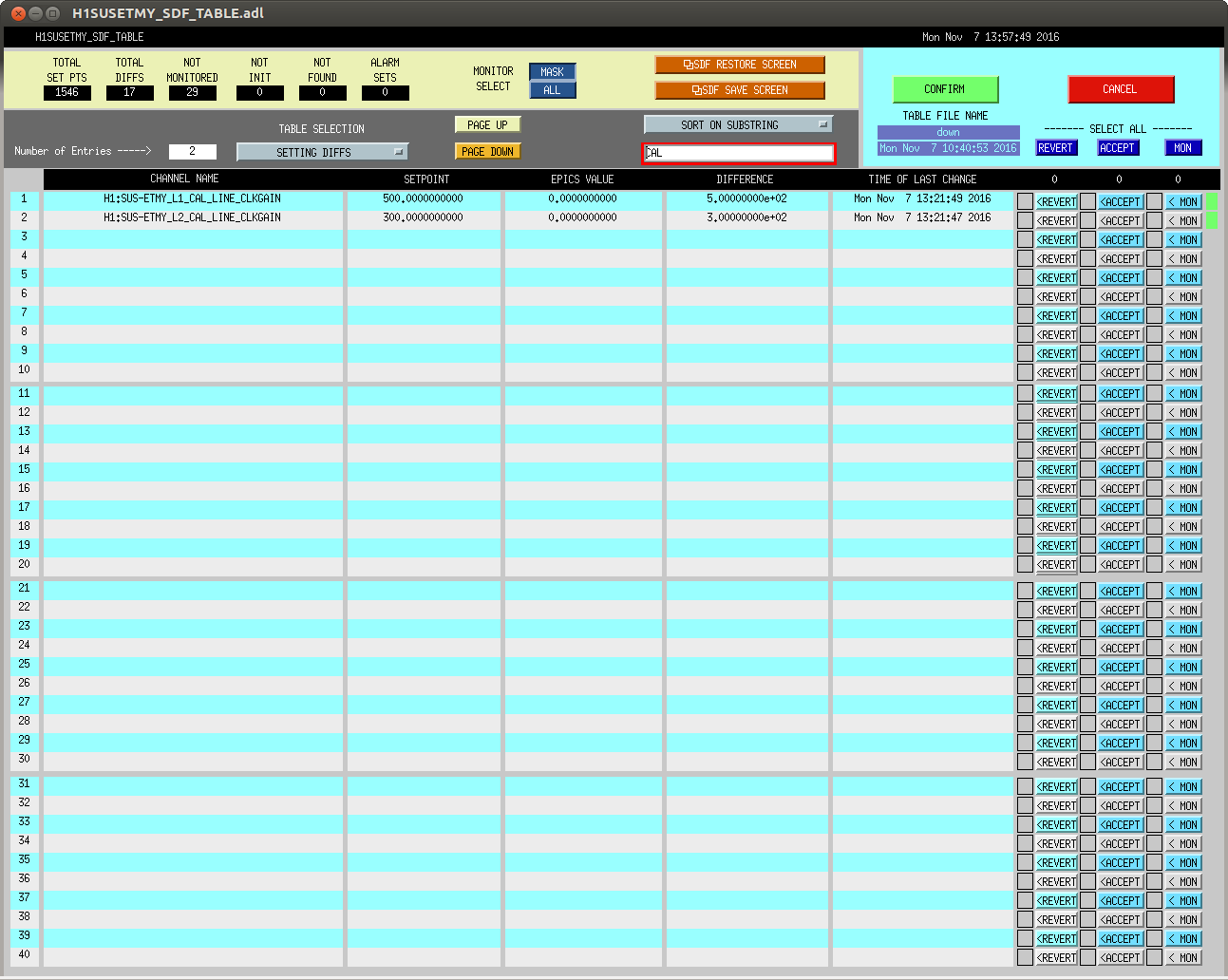
jim.warner@LIGO.ORG - posted 09:46, Monday 21 November 2016 (31682)
PSL Weekly Status
Laser Status:
SysStat is good
Front End power is 34.539993463W (should be around 30 W)
Frontend Watch is GREEN
HPO Watch is GREEN
PMC:
It has been locked 4.0 days, 13.0 hr 15.0 minutes (should be days/weeks)
Reflected power is 12.7175809387 Watts and PowerSum = 74.0388560218 Watts.
FSS:
It has been locked for 0.0 days 8.0 h and 2.0 min (should be days/weeks)
TPD[V] = 3.54349908377V (min 0.9V)
ISS:
The diffracted power is around 5.1059646249% (should be 5-9%)
Last saturation event was 0.0 days 8.0 hours and 1.0 minutes ago (should be days/weeks)
Possible Issues:
(Be sure to look into these, as they will not be printed in the report)
PMC reflected power is high