david.barker@LIGO.ORG - posted 13:30, Tuesday 04 October 2016 (30208)
CDS model and DAQ restart report, Friday 30th September, Saturday, Sunday, Monday 1st, 2nd, 3rd October 2016
model restarts logged for Mon 03/Oct/2016
2016_10_03 09:23 h1ioplsc0
2016_10_03 09:23 h1lsc
2016_10_03 09:23 h1omc
2016_10_03 09:24 h1ioplsc0
2016_10_03 09:24 h1lscaux
2016_10_03 09:24 h1lsc
2016_10_03 09:24 h1omc
2016_10_03 09:24 h1omcpi
h1lsc0 restart to fix power switch on IO Chassis in CER.
model restarts logged for Sun 02/Oct/2016 None reported
model restarts logged for Sat 01/Oct/2016 None reported
model restarts logged for Fri 30/Sep/2016
Site power outage at 06:08PDT, all machines rebooted between that time and 08:30.
2016_09_30 13:58 h1fw2
upgrade daqd code for minor bug fix found at llo.
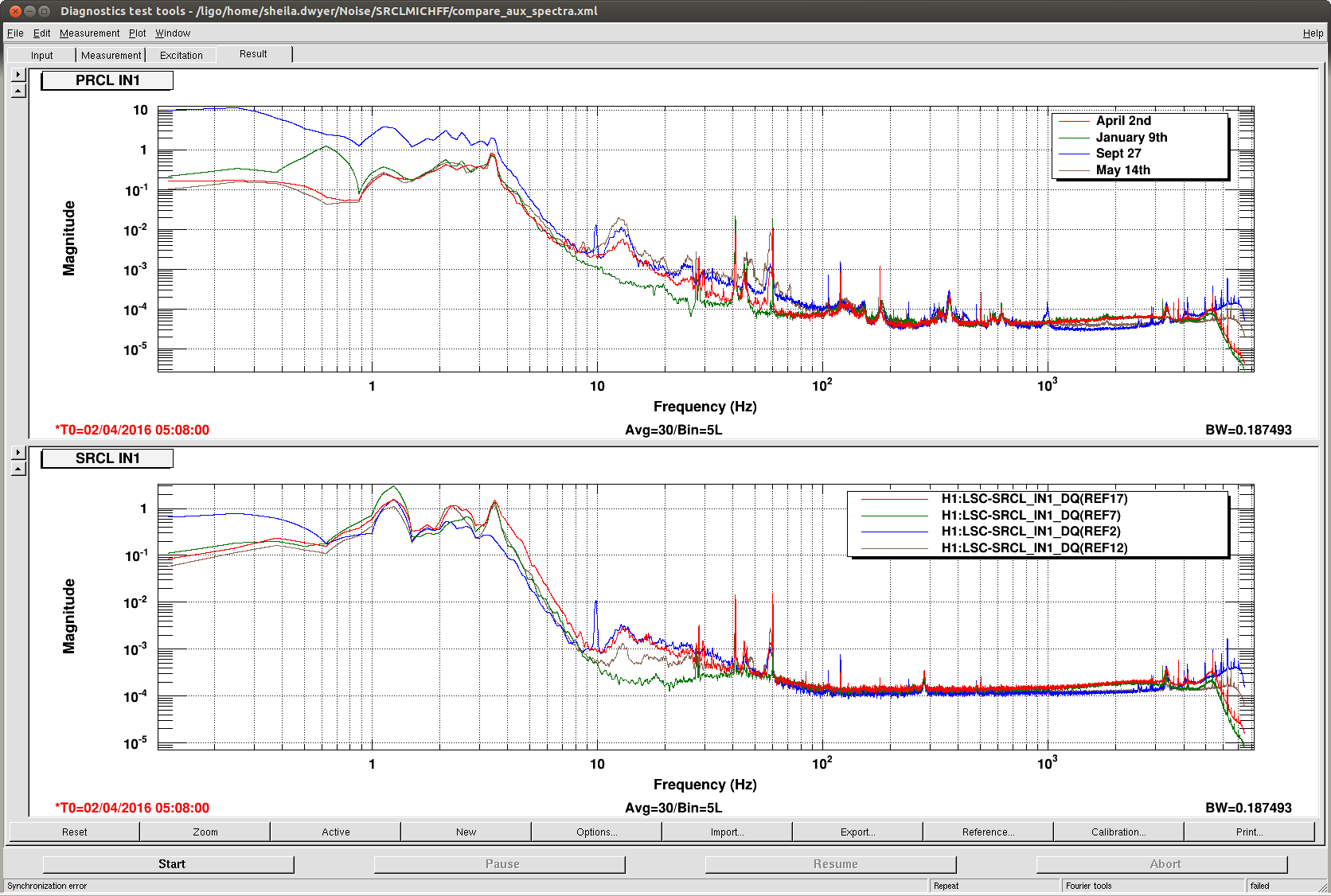


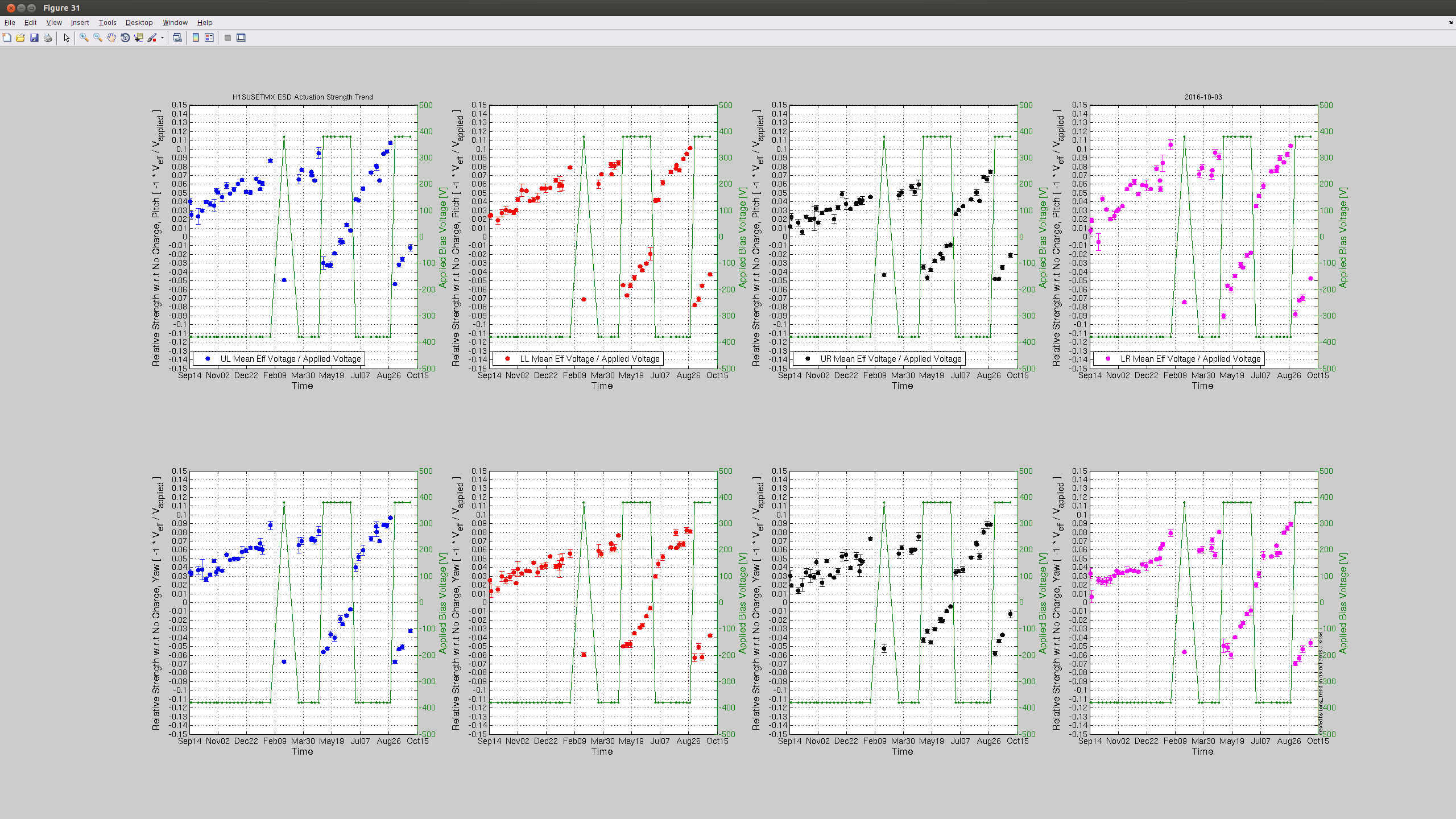
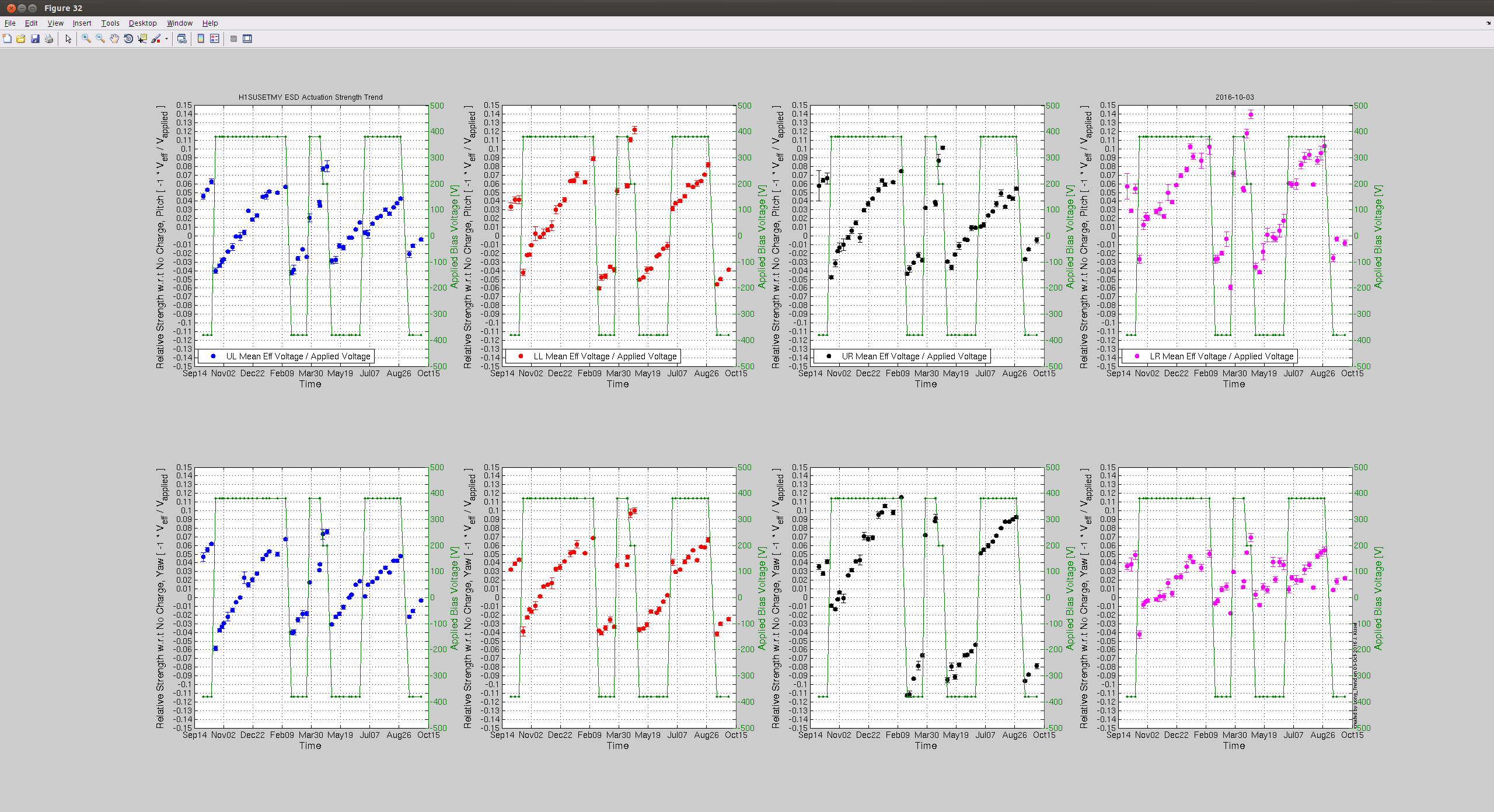







I have keyed off the TCSY laser in order to check the chiller reservoir further.
I turned the TCSY laser back on. Not much more to say on the chiller story - we're still adding a little water every day. I'll let another few days go and trend fill data to see if we're tapering off.