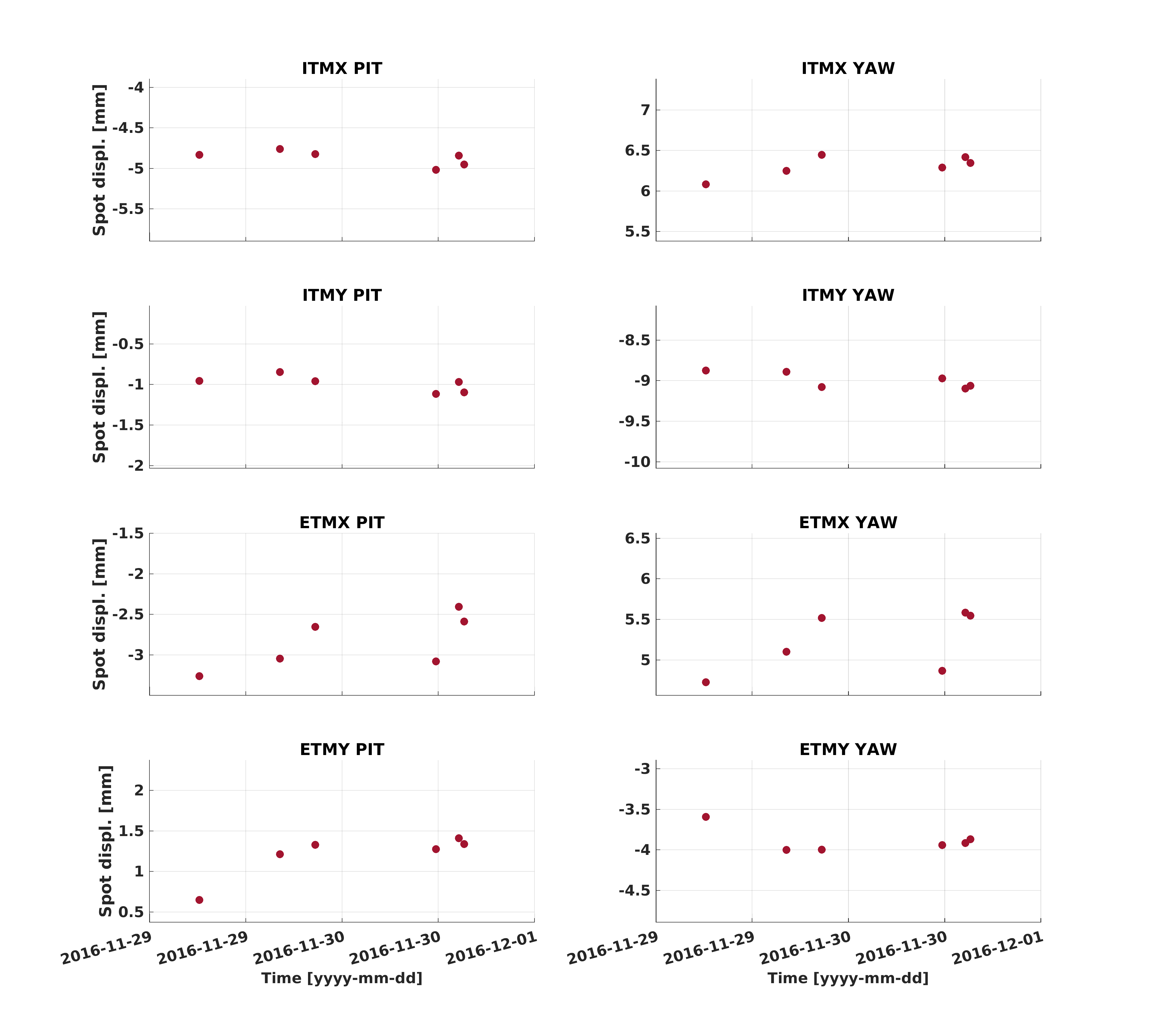
jeffrey.kissel@LIGO.ORG - posted 11:16, Wednesday 30 November 2016 - last comment - 09:17, Wednesday 29 March 2017(32021)
SUS PR2 Frame Rate Differences -- Understood; Let's Leave It Be
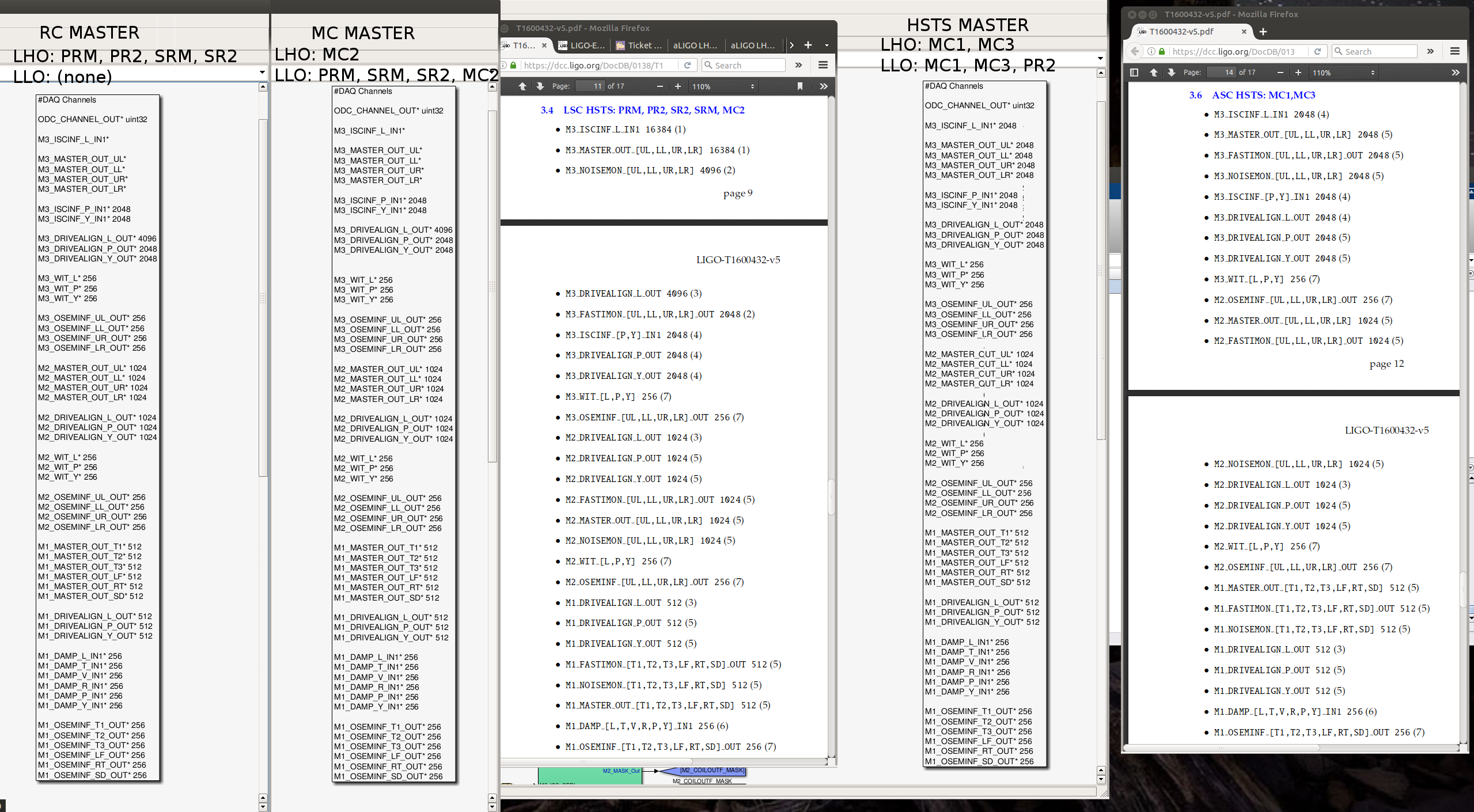
J. Kissel, S. Aston, P. Fritschel Peter was browsing through the list of frame channels and noticed that there are some differences between H1 and L1 on PR2 (an HSTS), even after we've both gone through and made the effort to revamp our channel list -- see Integration Issue 6463, ECR E1600316, LHO aLOG 30844, and LLO aLOG 29091. What difference he found is the result of the LHO-ONLY ECR E1400369 to increase the drive strength of the lower states *some* of the HSTSs. This requires the two sites to have a different front-end model library part for different types of the same suspension because the BIO control each stage is different depending on the number of drivers that have been modified; At LHO the configuration is Library Part Driver Configuration Optics HSTS_MASTER.mdl No modified TACQ Drivers MC1, MC3 MC_MASTER.mdl M2 modified, M3 not modified MC2 RC_MASTER.mdl M2 and M3 modified PRM, PR2, SRM, SR2 At LLO, the configuration is Library Part Driver Configuration Optics HSTS_MASTER.mdl No modified TACQ Drivers MC1, MC3, PR2 MC_MASTER.mdl M2 modified, M3 not modified MC2, PRM, SR2, SRM RC_MASTER.mdl M2 and M3 modified none This model's DAQ channel list for the MC and RC masters is the same. The HSTS master is different, and slower, because these SUS are used for angular control only: HSTS (Hz) MC or RC (Hz) M3_ISCINF_L_IN1 2048 16384 M3_MASTER_OUT_UL 2048 16384 M3_MASTER_OUT_LL 2048 16384 M3_MASTER_OUT_UR 2048 16384 M3_MASTER_OUT_LR 2048 16384 M3_DRIVEALIGN_L_OUT 2048 4096 Since LLO's PR2 does not have any modifications to its TACQ drivers, it uses the HSTS_MASTER model, which means that PR2 alone is going to show up as a difference in the channel list between the sites that seemed odd Peter -- that L1 had 6 more 2048 Hz channels than H1. Sadly, it *is* used for longitudinal control, so LLO suffers the lack of stored frame rate. In order to "fix" this difference, we'd have to create a new library part for LLO's PR2 alone that has the DAC channel list of an MC or RC master, but have the BIO control logic of an HSTS master (i.e. to operate M2 and M3 stages with an unmodified TACQ driver). That seems excessive given that we already have 3 different models due to differing site preferences (and maybe range needs), so I propose we leave things as is, unless there's dire need to compare the high frequency drive signals to the M3 stage of PR2 at LLO. I attach a screenshot that compares the DAQ channel lists for the three library parts, and the two types of control needs as defined by T1600432.
Images attached to this report
Comments related to this report
Just to trace out the history HSTS TACQ drivers at both sites: Prototype of L1200226 increase MC2 M2 stage at LLO: LLO aLOG 4356 >> L1 MC2 becomes MC_MASTER. ECR to implement the L1200226 on MC2, PRM, and SRM M2 stages for both sites: E1200931 >> L1 PRM, SRM become MC_MASTERs >> H1 MC2, PRM, SRM become MC_MASTERs LLO temporarily changes both PR2 and SR2 M2 drivers for an L1200226 driver: LLO aLOG 16945 And then reverted two days later: LLO aLOG 16985 ECR to increase the drive strength SR2 M2 stage only at LLO: E1500421 >> L1 SR2 becomes MC_MASTER ECR to increase the drive strength of SR2 and PR2 M2 and PRM, PR2, SRM, SR2 M3 at LHO only: E1400369 >> H1 SRM, SR2, SRM, SR2 become RC_MASTERs.