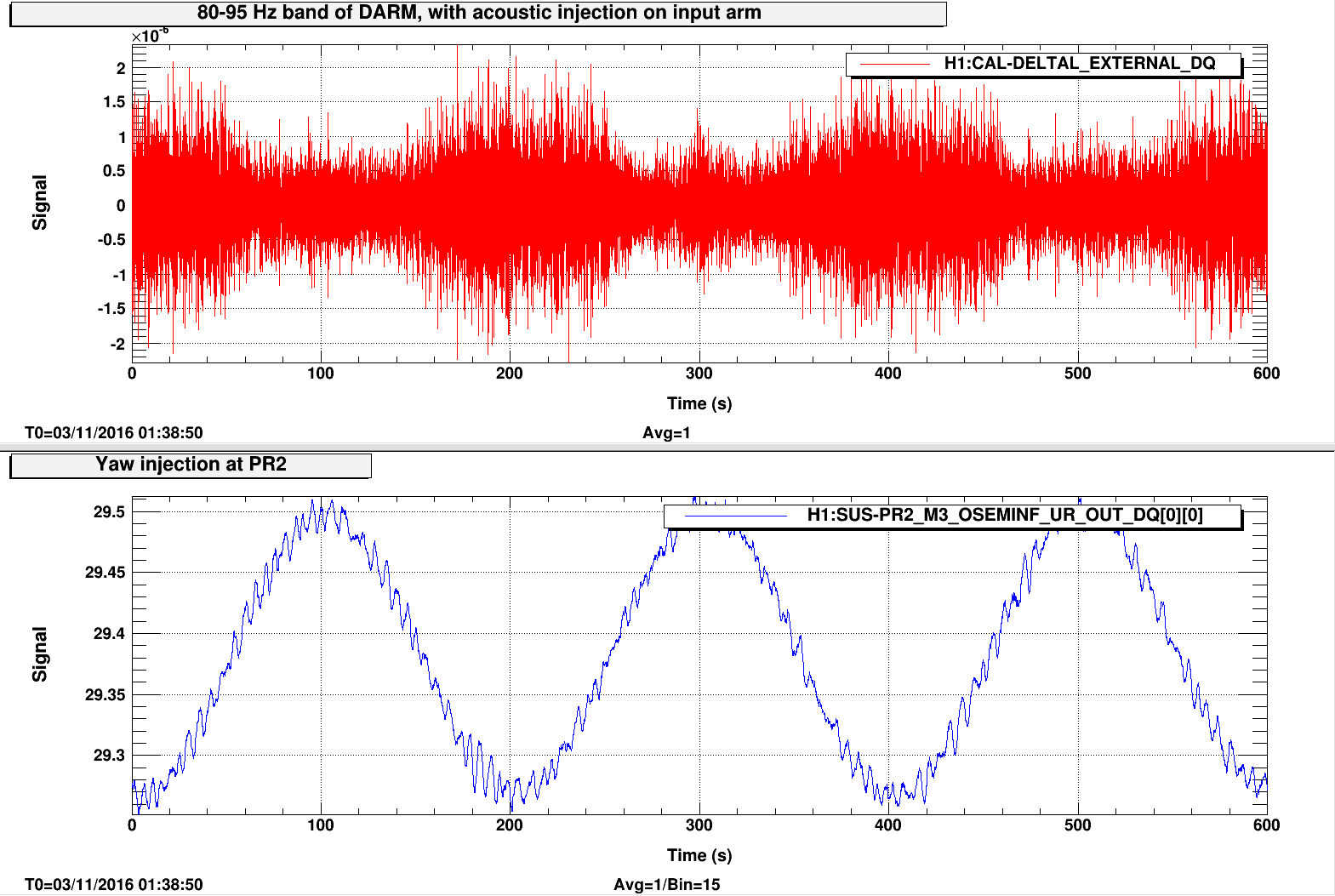
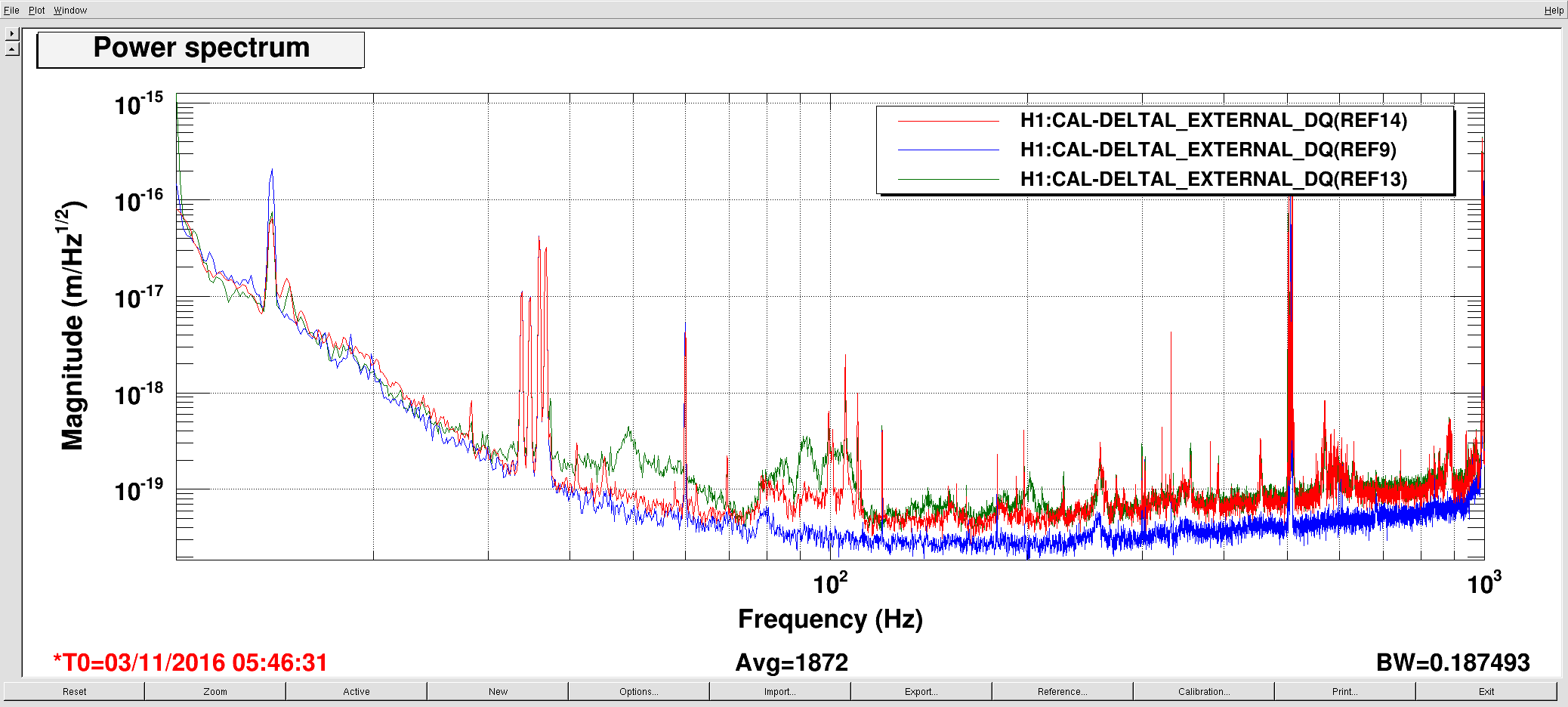
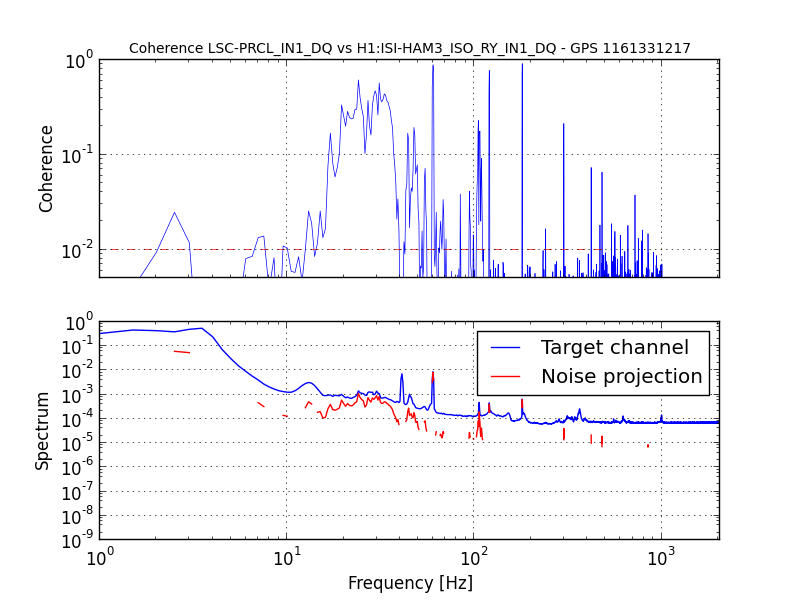
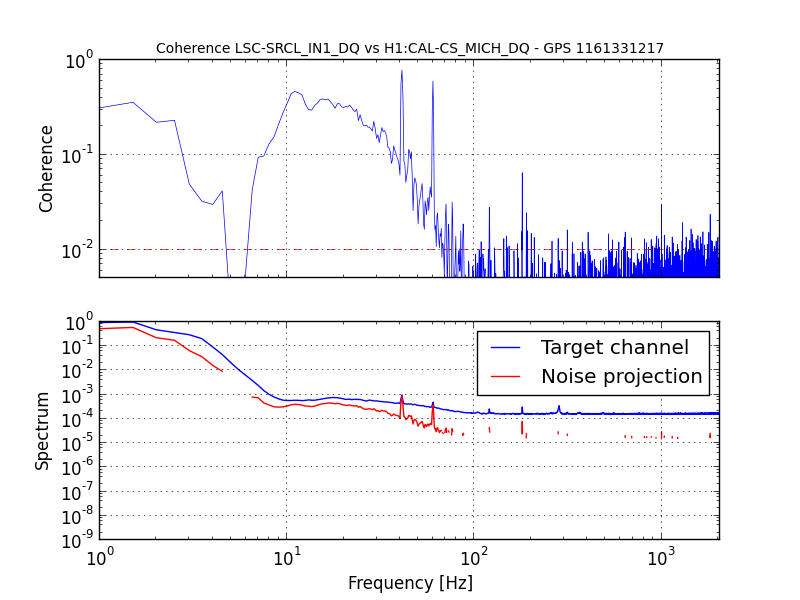
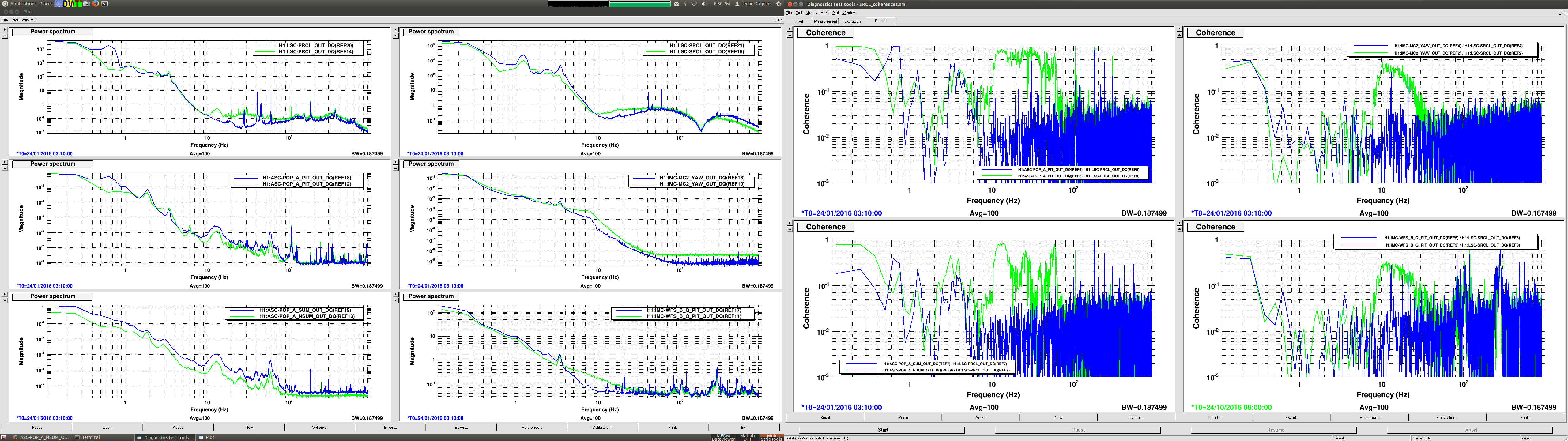
jeffrey.kissel@LIGO.ORG - posted 12:54, Thursday 03 November 2016 - last comment - 09:18, Friday 04 November 2016(31165)
SDF Issues with SUSITMPI Model Upon Unplanned Restart Were the Cause of PI Problems; Now Resolved
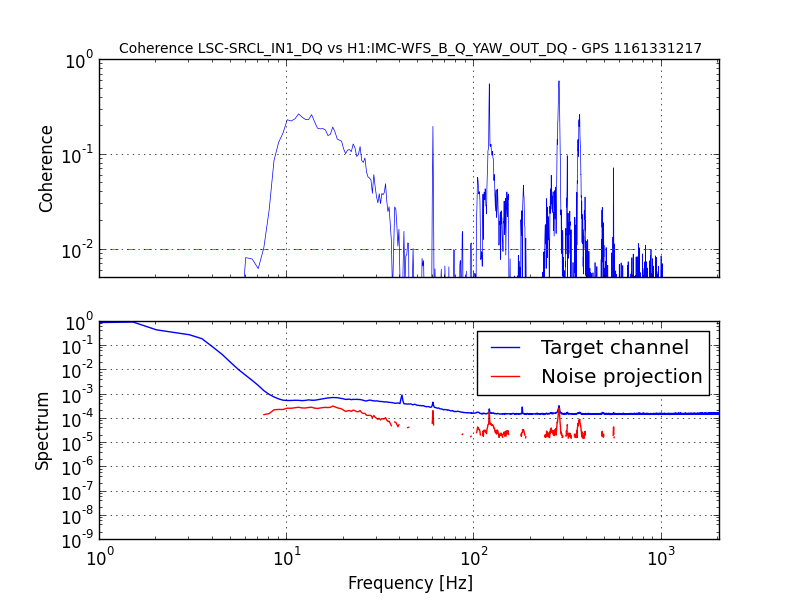
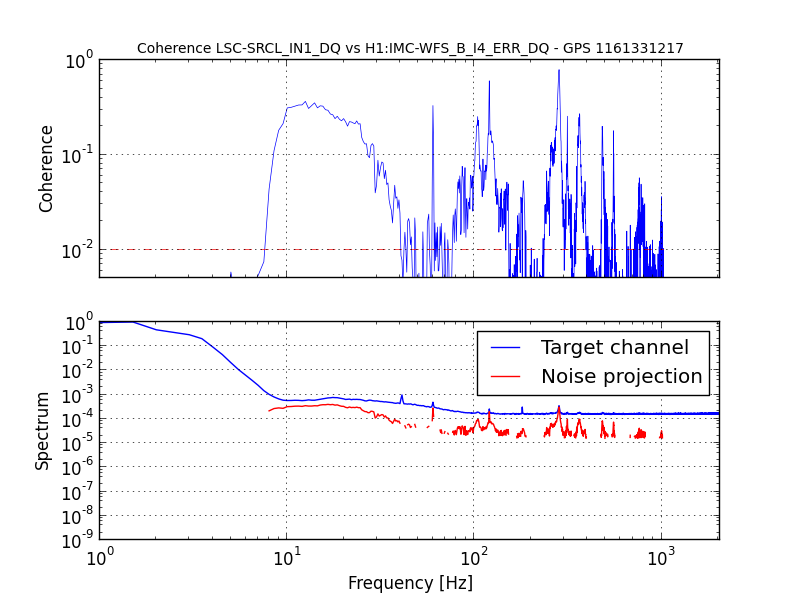
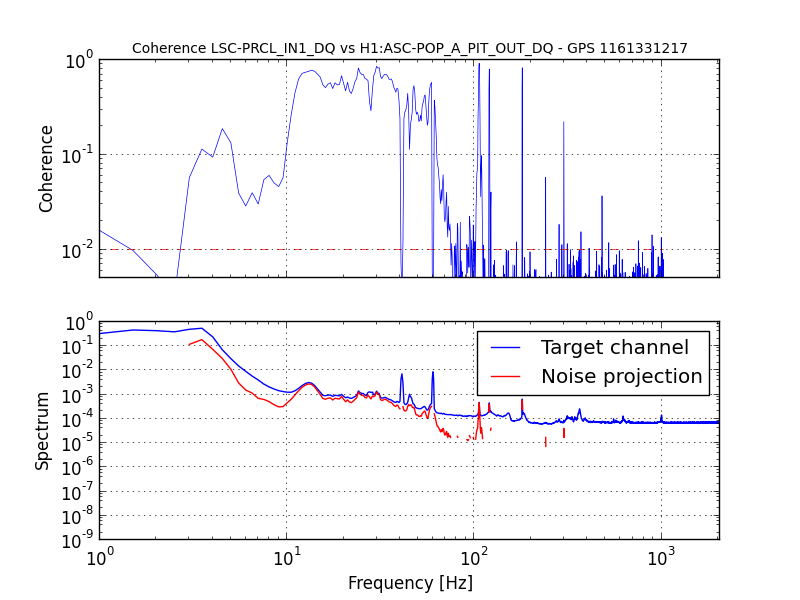
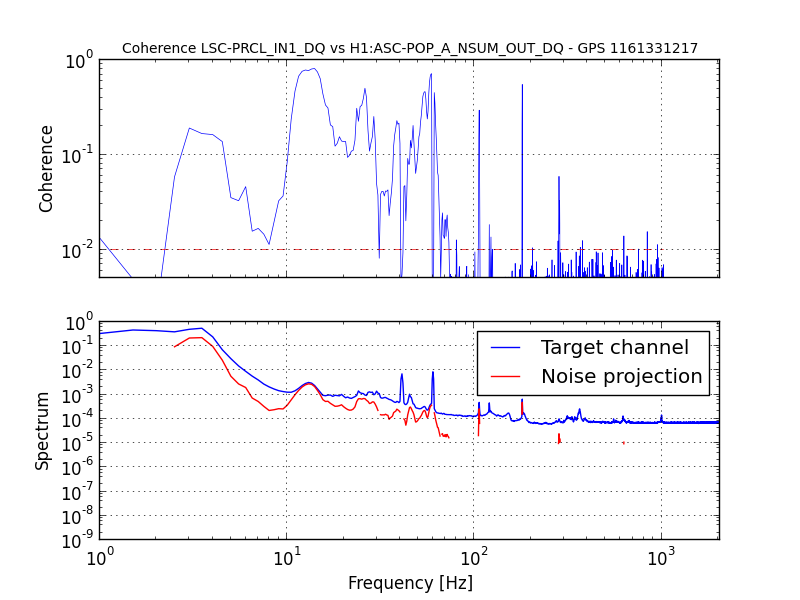
J. Kissel, M. Evans, D. Barker, H. Radkins A confusing bit of settings wrangling* after the unplanned corner station computer restarts on Tuesday (LHO aLOG 31075) in the SUSITMPI model meant that a large fraction of the EPICs records in the ITM PI system were wrong. As such, we believe this was the cause of battles with Mode 27's PI a few nights ago (LHO aLOG 31111). In order to fix the problem, we used the hourly burt backups in /ligo/cds/lho/h1/burt/yyyy/mm/dd/hh:mm/ to restore settings all settings to Monday (2016/10/31), before the computer restarts. Further, Matt performed a few spot checks on the system, and suspected it good. *Settings wrangling: There were several compounding problems with the SDF system which meant that (1) The front-end did not use the safe.snap file upon reboot, and restored bogus values (2) The safe.snap file, which we'd thought had been kept up to date, had not been so since May. Why? (2) The safe.snap file for SUSITMPI used upon restart, /opt/rtcds/lho/h1/target/h1susitmpi/h1susitmpiepics/burt/safe.snap, is a softlink to /opt/rtcds/userapps/release/sus/h1/burtfiles/h1susitmpi_safe.snap. Unfortunately, *only* that model's safe.snap that had its permissions mistakenly set to a single user (coincidentally me, because I was the one who'd created the softlink from the target directory to the userapps repo.), and *not* the controls working group. That means Terra Hardwick, who had been custodian of the settings for this system, was not able to write to this file, and the settings to be restored upon computer reboot had not been updated since May 2016. Unfortunately, the only way to find out that this didn't work is to look in the log file, which lives in /opt/rtcds/lho/h1/log/${modelname}/ioc.log and none of us (save Dave) remember this file existed, let along looked at it before yesterday **. There are other files made (as described in Hugh's LHO aLOG 31163), but those files are not used by the front-end upon reboot. I've since fixed the permissions on this file, and we can now confirm that anyone can write to this file (i.e. accept & confirm DIFFs). We've also confirmed that there are no other safe.snap files that have their write permissions incorrectly restricted to a single user. ** Even worse, it looks like there's a bug in the log system -- even when we confirm that we have written to the file, the log reports a failure, e.g. *************************************************** Wed Nov 2 16:39:10 2016 Save TABLE as SDF: /opt/rtcds/lho/h1/target/h1susitmpi/h1susitmpiepics/burt/safe_161102_163910.snap *************************************************** Wed Nov 2 16:39:10 2016 ERROR Unable to set group-write on /opt/rtcds/lho/h1/target/h1susitmpi/h1susitmpiepics/burt/safe.snap - Operation not permitted *************************************************** Wed Nov 2 16:39:10 2016 FAILED FILE SAVE /opt/rtcds/lho/h1/target/h1susitmpi/h1susitmpiepics/burt/safe.snap *************************************************** (1) This is quite alarming. Dave has raised an FRS ticket (see LHO aLOG 6588) and fears it may be an RCG bug. I wish I could give you mode information on this, but I just don't know it. In summary, we believe the issues with SUSITMPI have been resolved, but there's a good bit of scary stuff left in the SDF system. We'll be working with the CDS team to find a path forward.
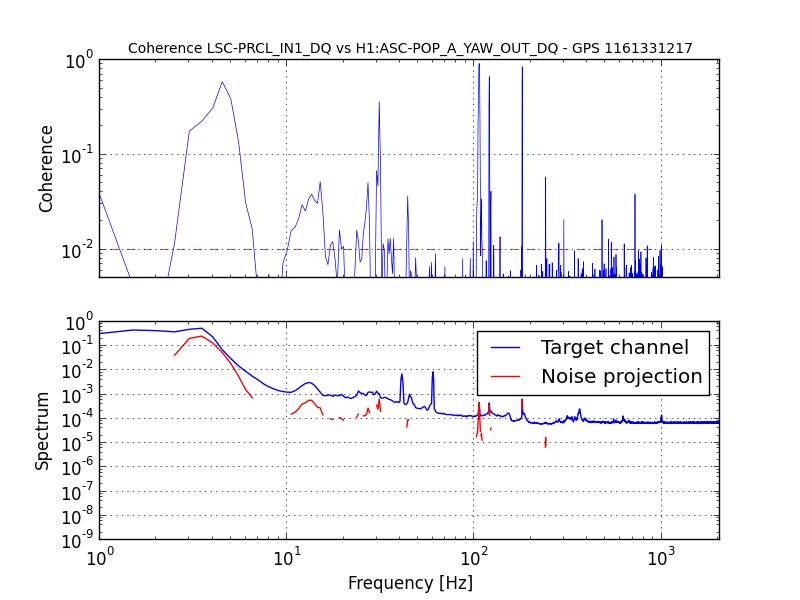
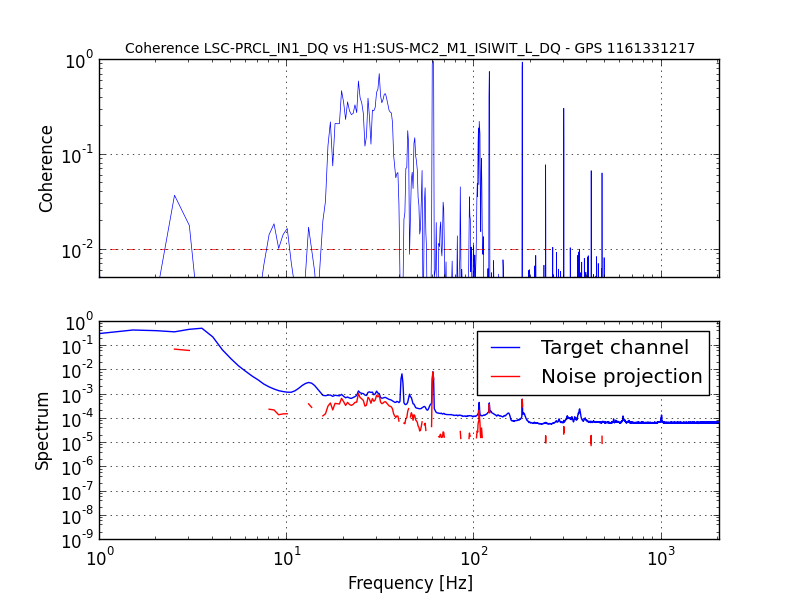
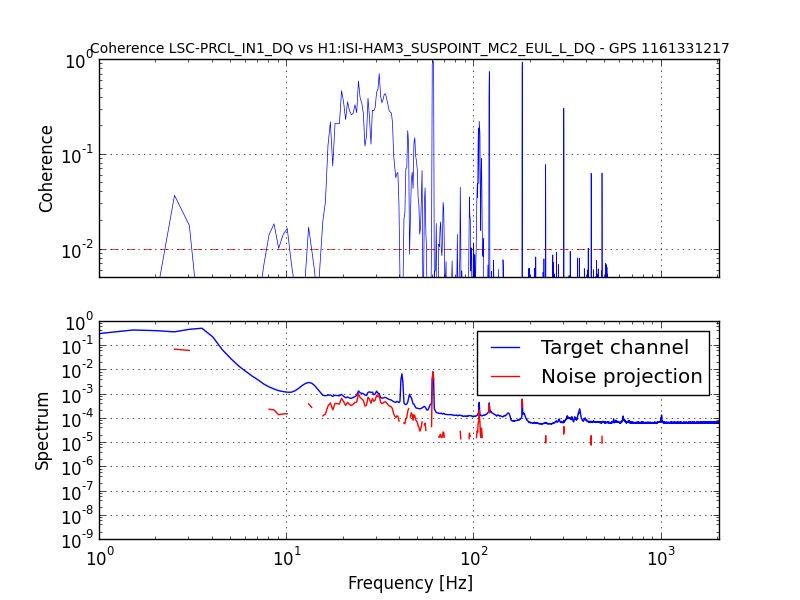
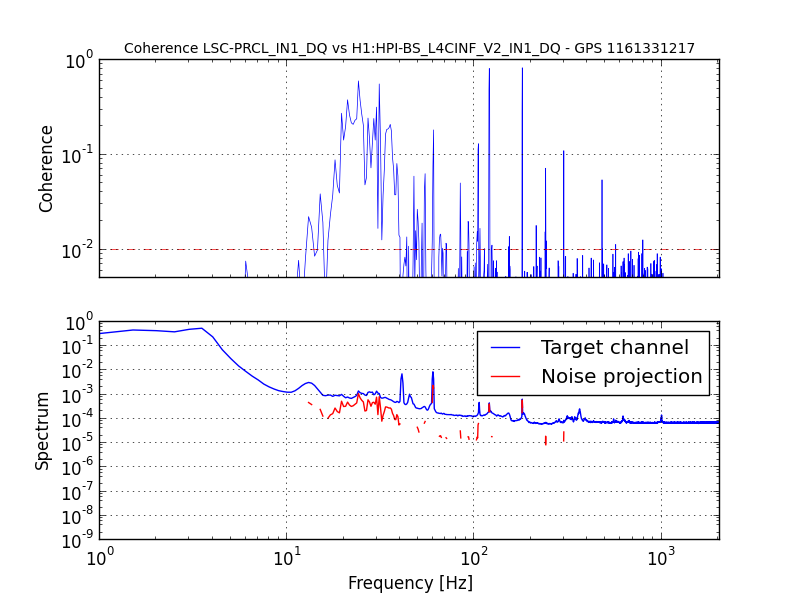

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
I've opened FRS6596 to do the same snap file permissions checking as LLO.