edmond.merilh@LIGO.ORG - posted 20:29, Tuesday 01 November 2016 (31098)
Mid-Shift Summary - Eve
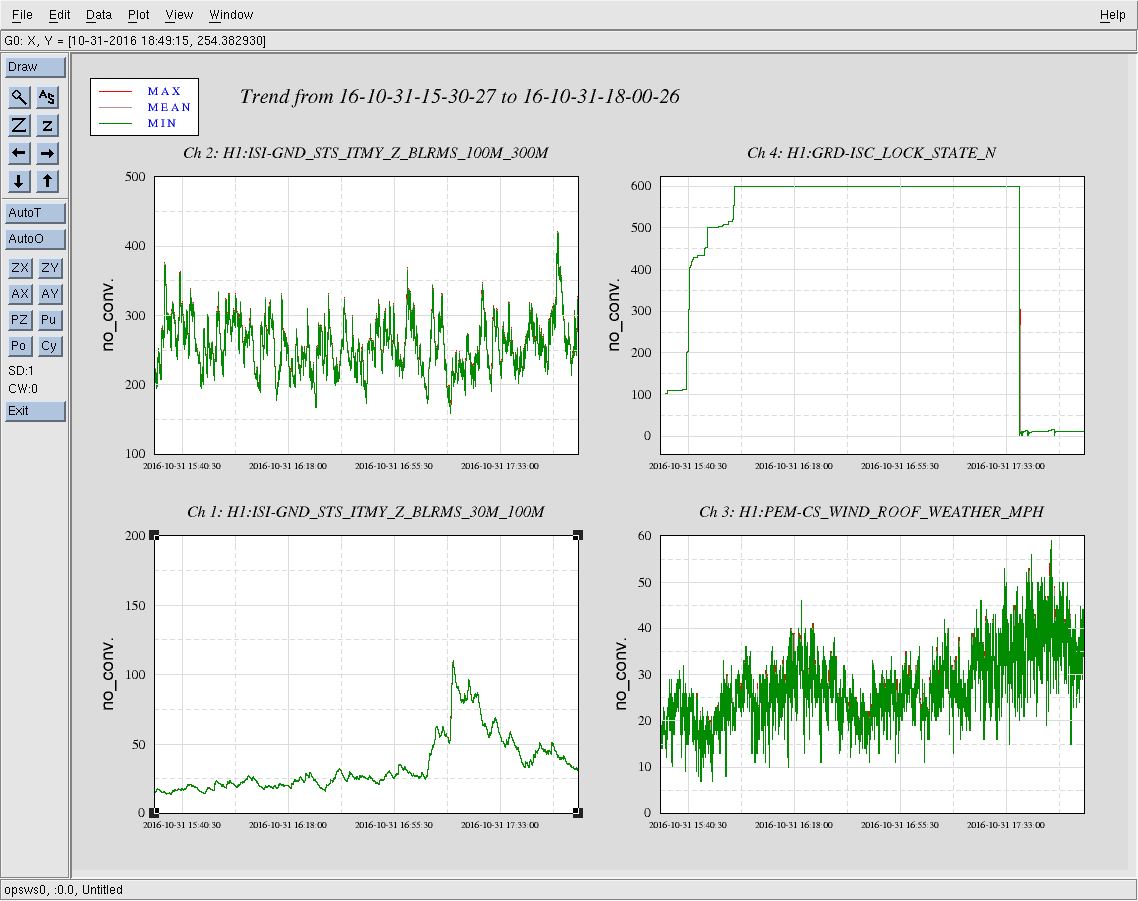
- After PSL team came out of the enclosure Jenne and I began initial alignment procedure
- Jenne tagged out and Jeff K joined me at ops. After a little difficulty with SRC. we began full locking only to break at PREP_TR_CARM
- Stefan found some bad offsets in the TR_CARM step, so he created a new step to mitigate.
- Locking made it to ENGAGE_ASC_PART2, at which time Sheila concluded that the arm alignment needed some attention.
- Another initial alignment is being done at this time.
- DMT seems to be locked-up
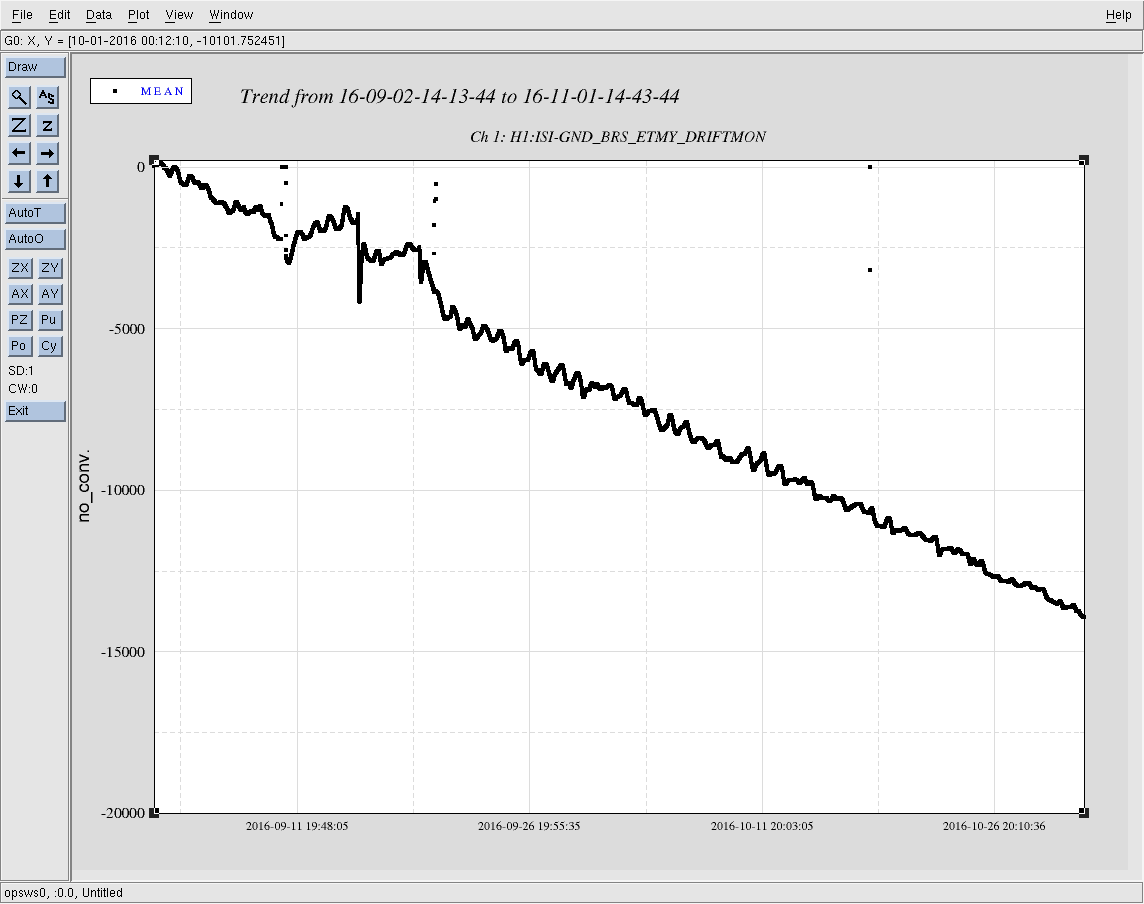
- Environmentally quiet with uSei trending back downward