patrick.thomas@LIGO.ORG - posted 09:03, Saturday 22 October 2016 - last comment - 10:12, Saturday 22 October 2016(30746)
Ops Owl Shift Summary
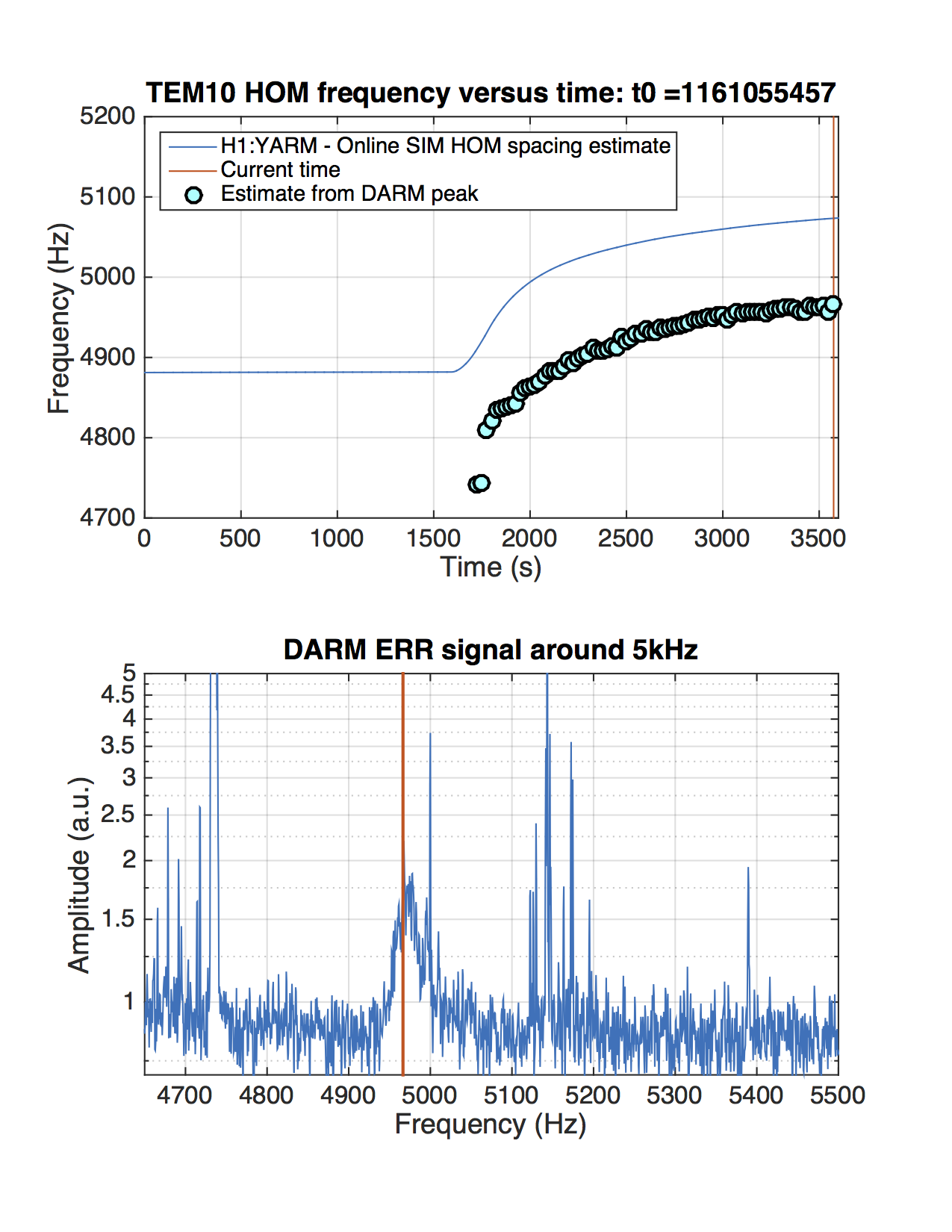
I kept losing lock from NLN at 26 W after a fairly constant amount of time. Each time ETMY would saturate and the whole DARM spectrum would jump up for a while before hand. I have begun to suspect that it might be related to a fairly broad hump seen in Terra's PI DTT template that grows in height and width as the lock progresses. It is centered somewhere around 15008 Hz and the peak grows from around 100 to 10000 before the lock loss. I tried sitting at DC_READOUT and then INCREASE_POWER and playing around with a bunch of PI settings, assuming it was related to either mode 18 or mode 26. I tried various filters in the H1SUSPROCPI_PI_PROC_COMPUTE_MODE26_BP filter bank, different phases and gains and even turned off and back on the entire PI output to ETMY (H1:SUS-ETMY_PI_ESD_DRIVER_PI_DAMP_SWITCH). Nothing really seemed to have any effect and it eventually broke lock again. Relocking has been fairly robust. The IR transmission at CHECK_IR has been kind of poor towards the end of the shift, but it doesn't seem to hinder further locking. At the beginning of the last lock at NLN I changed the TCS ITMX CO2 power by a small amount per Sheila's request. 07:40 UTC NLN at 26 W 07:50 UTC Damped PI mode 27 by flipping sign of gain 07:56 UTC Played around with damping PI mode 18 and 26. Not sure if they just came down on their own. 08:10 UTC Damped PI mode 27 by flipping sign of gain 09:05 UTC Lock loss. EY constantly saturating and PI modes 9, 18 and 26 ringing up. Attempts to damp these by changing their phases did not seem to help. 09:30 UTC Lock loss immediately upon reaching DC_READOUT. IFO got that far without intervention. OMC SUS and HAM6 ISI tripped. 09:35 UTC X arm IR transmission is ~ .4 at CHECK_IR. Able to bring it to ~ .7 by adjusting H1:ALS-C_COMM_VCO_CONTROLS_SETFREQUENCYOFFSET from 0 to ~ -156. This dropped Y arm transmission. Brought back by moving H1:ALS-C_DIFF_PLL_CTRL_OFFSET. 10:00 UTC Pausing at ROLL_MODE_DAMPING. Waiting for ITM roll modes to damp. 10:12 UTC DC_READOUT_TRANSITION. Stable here. 10:13 UTC DC_READOUT. 10:17 UTC Stable at DC_READOUT. Moving on. 10:25 UTC NLN at 26 W 10:35 UTC Flipped sign of PI mode 27 for third time since NLN. 10:57 UTC Flipped sign of PI mode 27 again 11:18:50 UTC Changed TCS ITMX CO2 power using rotation stage. Changed requested power from 0.200 W to 0.201 W. 0.195 W measured out at 42.2733 deg changed to 0.195 - 0.196 W measured out at 42.3040 deg. 11:24 UTC EY saturating again 11:25 UTC Tried dropping power to 10 W by going to manual -> adjust power -> auto, power request through guardian. Lock loss. Peak on PI DTT at 15008.9 got really broad. HAM6 ISI and OMC SUS tripped. 11:45 UTC Having hard time on CHECK_IR getting stable transmission. Moving on. 12:06 UTC Pausing at DC_READOUT. 12:12 UTC Stable. Moving on. Various large optics saturating until reaching ~ NOISE_TUNINGS. 12:20 UTC NLN at 25.9 W 12:22 UTC Changed TCS ITMX CO2 power using rotation stage: req .200 W -> .198 W meas .196 W -> .194 W meas 42.2800 deg -> 42.2483 deg 12:30 UTC Flipped sign of PI mode 27 gain 12:46 UTC Flipped sign of PI mode 27 gain 13:18 UTC Lock loss. 13:46 UTC Pausing at DC_READOUT. Played around with various settings for mode 18 and 26. 15008 Hz line seemed to come down a little, but not sure it was anything I did. 14:12 UTC Going to INCREASE_POWER. Sitting at INCREASE_POWER trying lots of different things to damp mode 26. No effect.
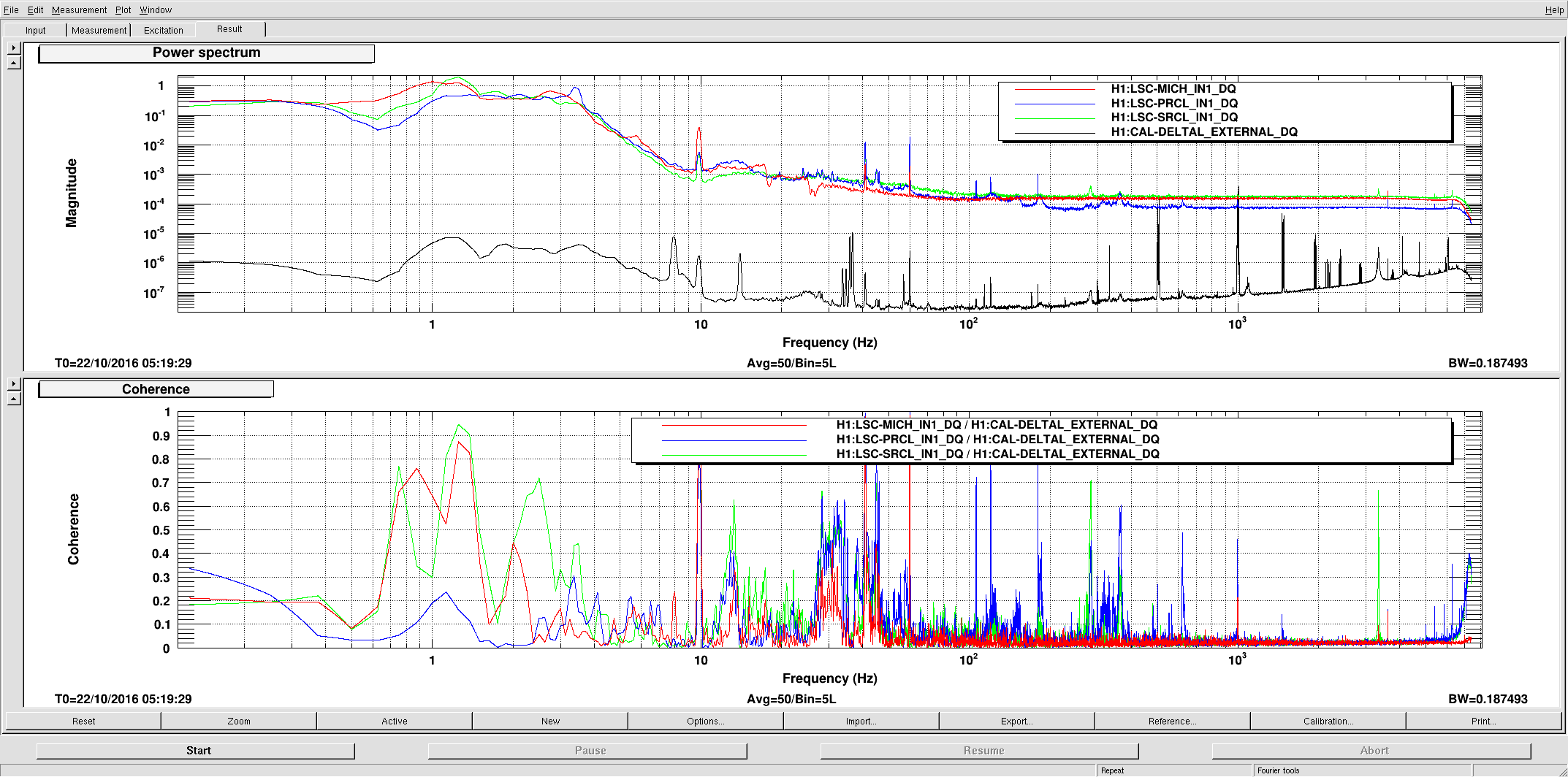
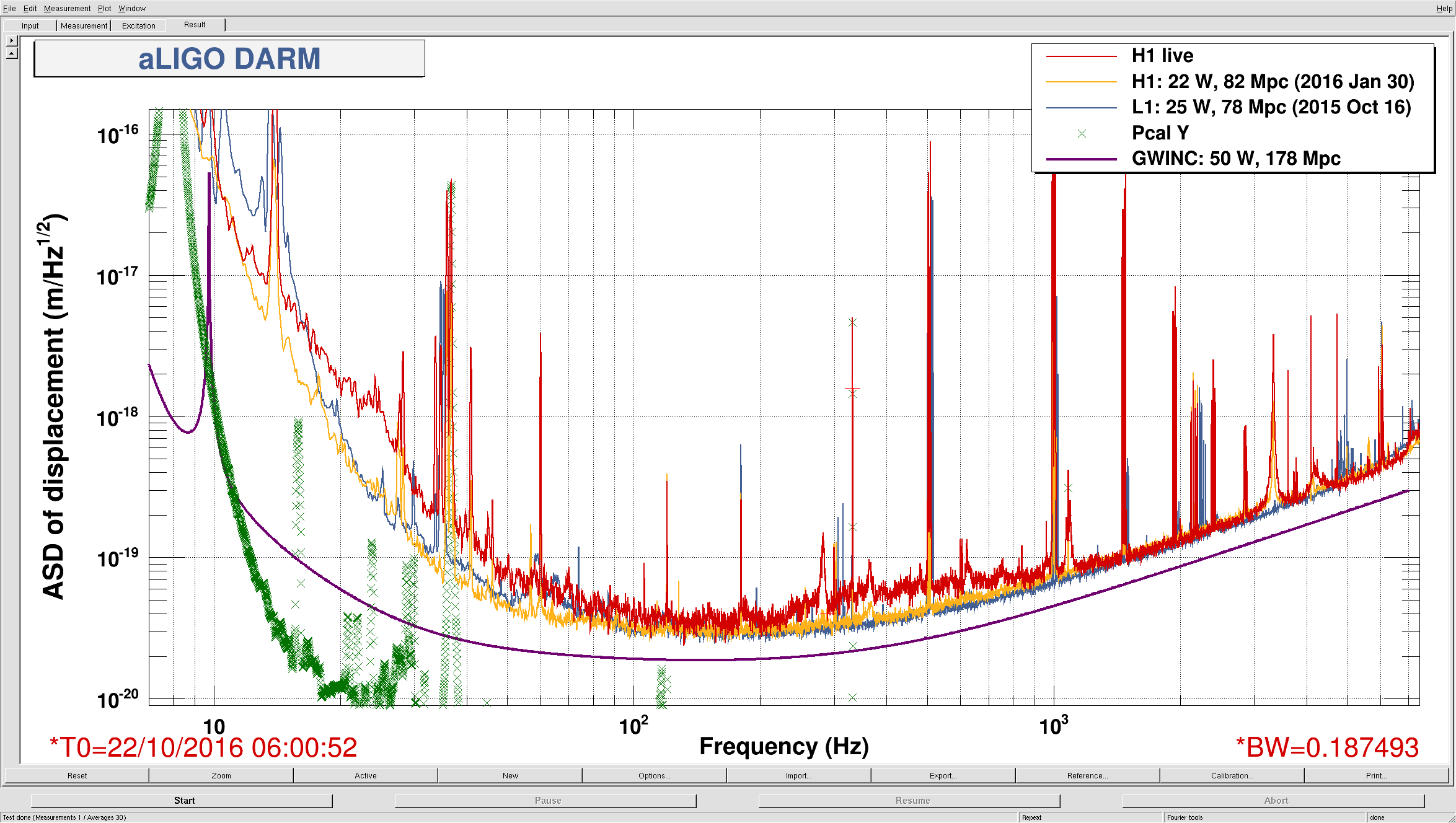
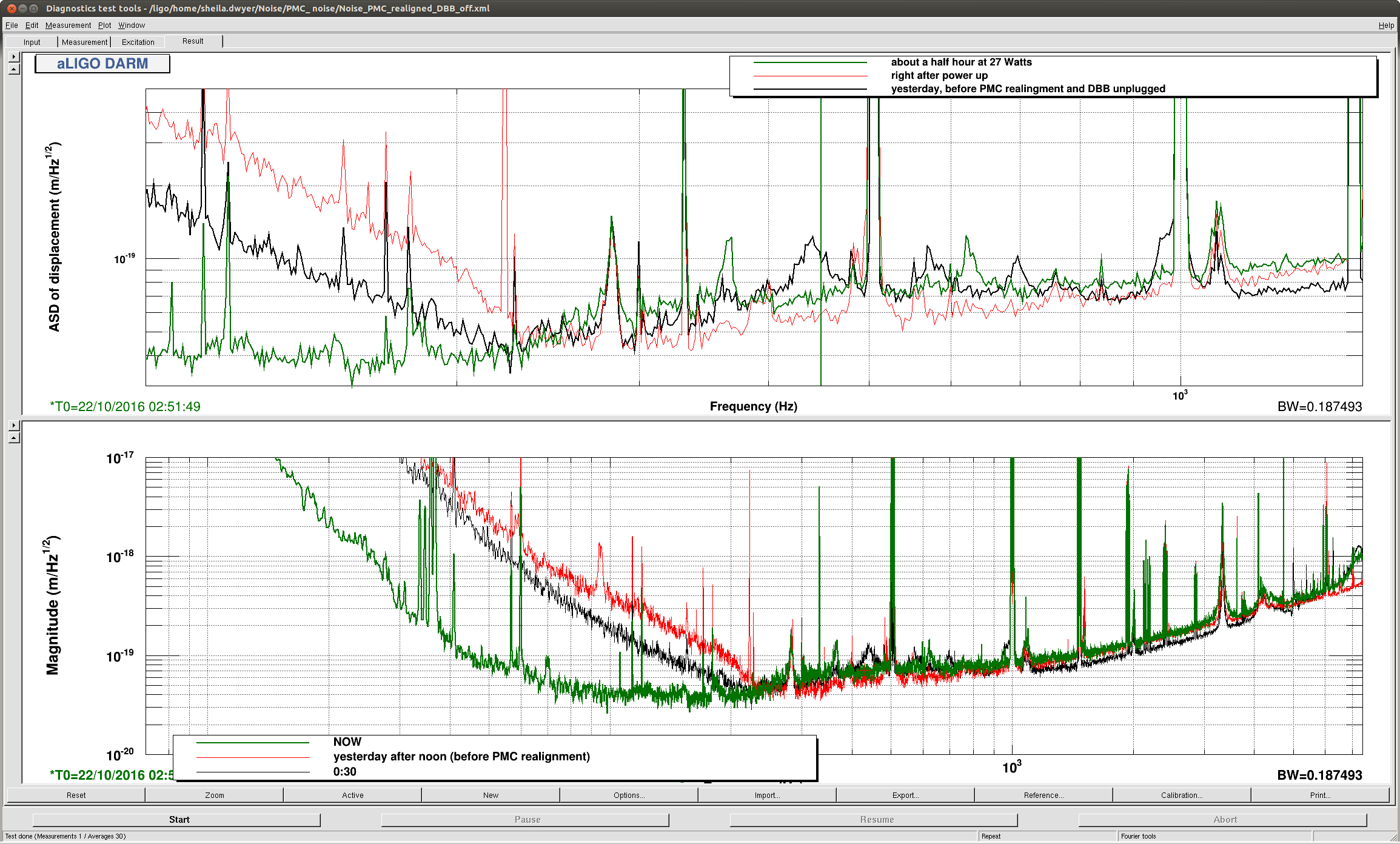
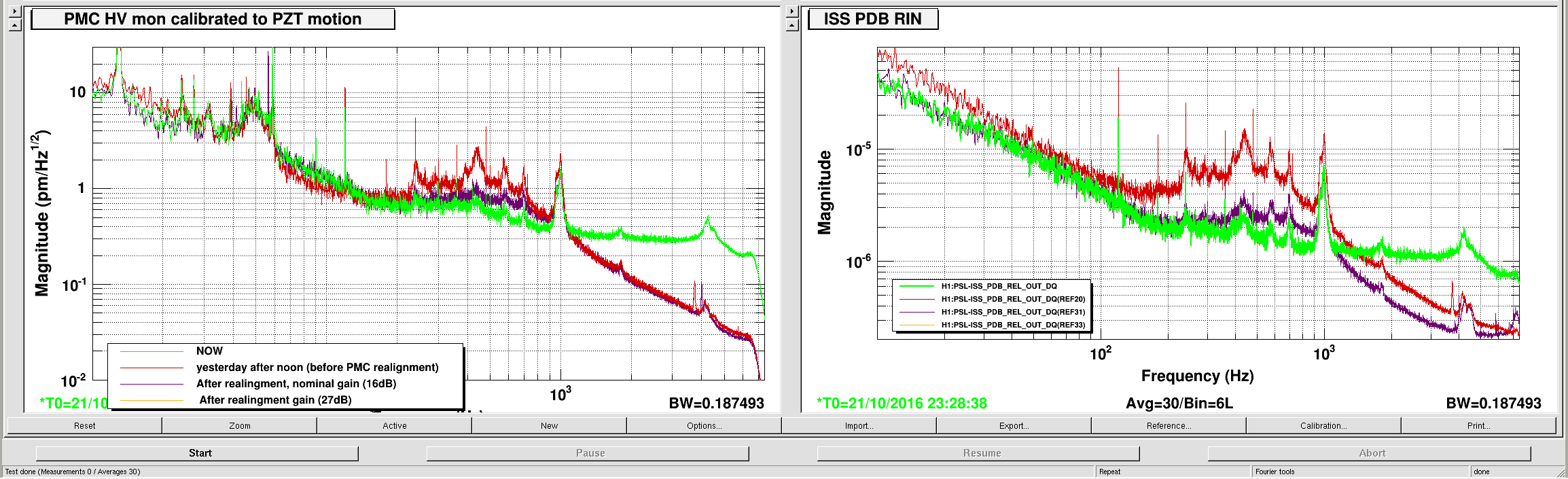
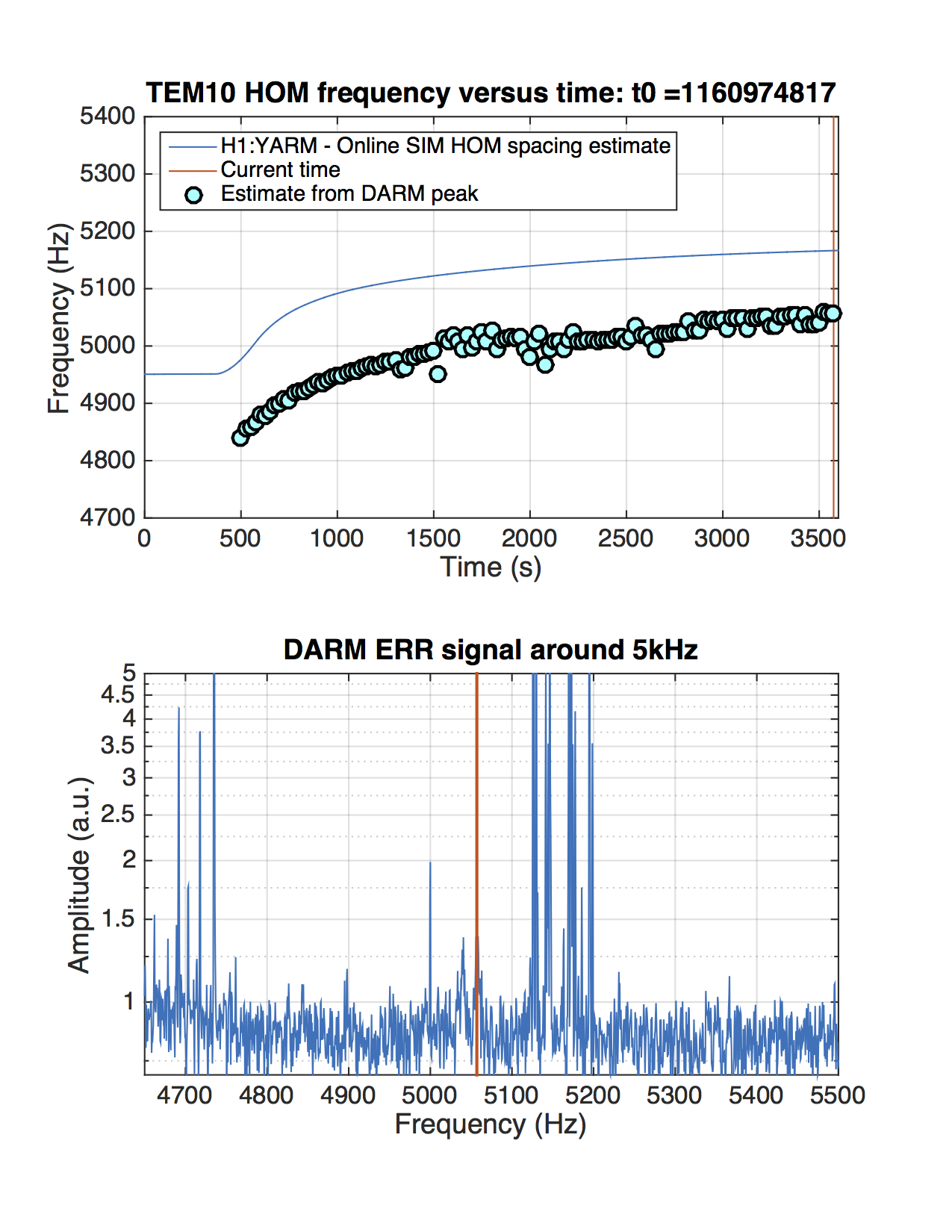







{kind=link}
I believe this was all due to a different BP filter on Mode26 needing to be engaged (one outside those that are currently controlled by guardian) in light of frequency shift due to recent RH changes. I have called and told Ed which to turn on. I repeat: please call me at anytime if there is persistant PI trouble. Often a simple fix might save a night of not locking/stress and I'm happy to be woken up. PI Help Desk phone number is on control room whiteboard.