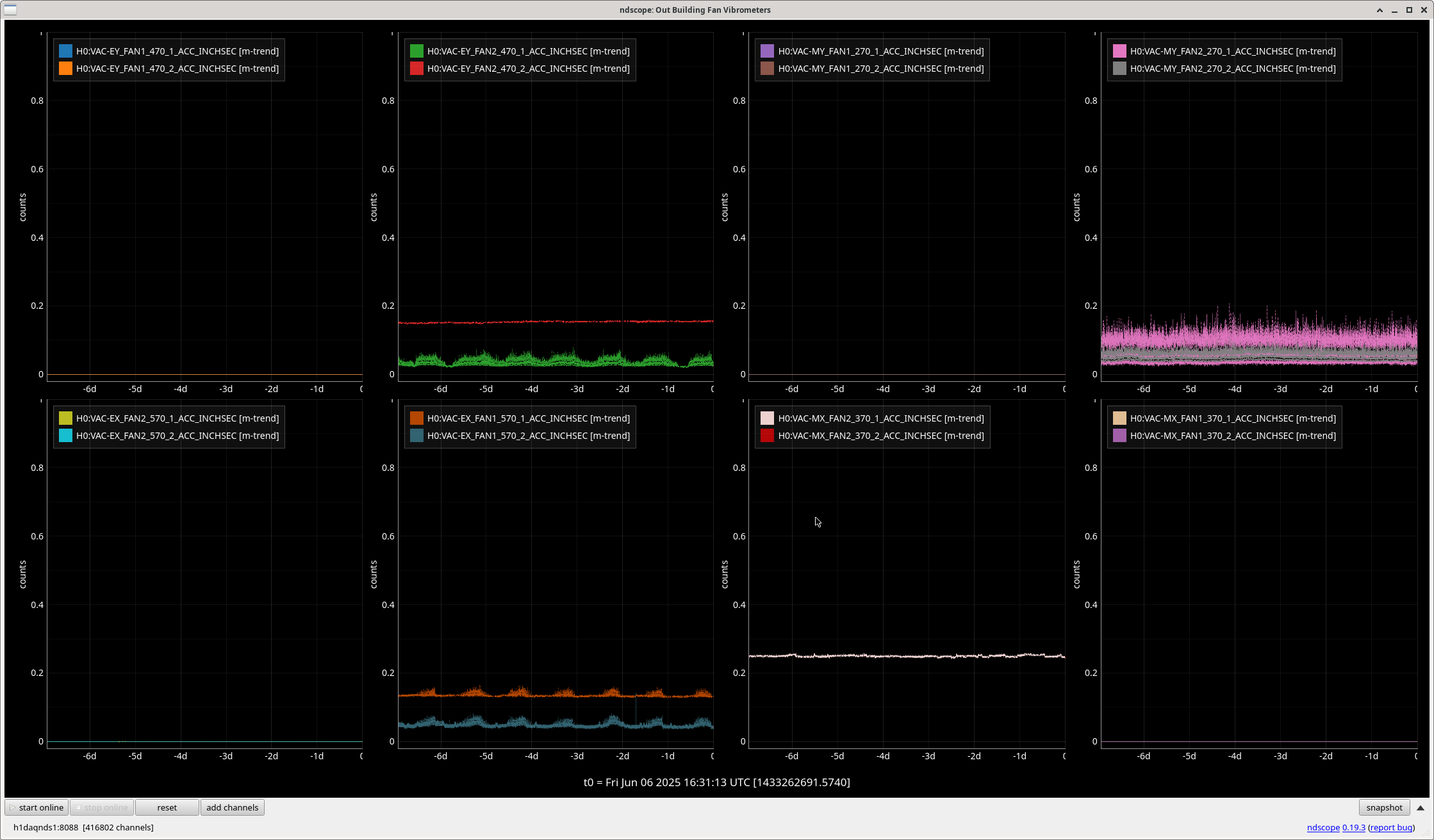
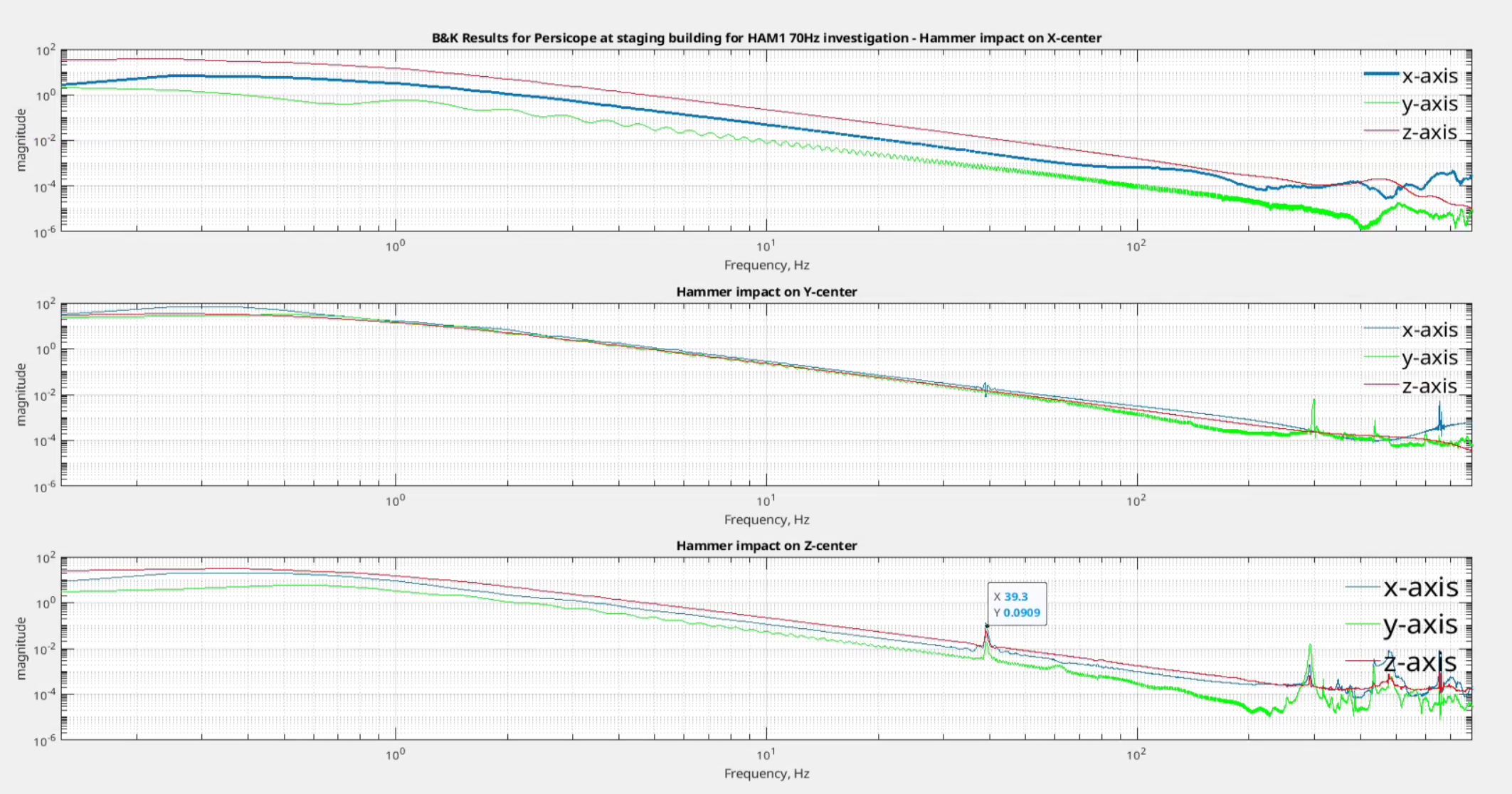
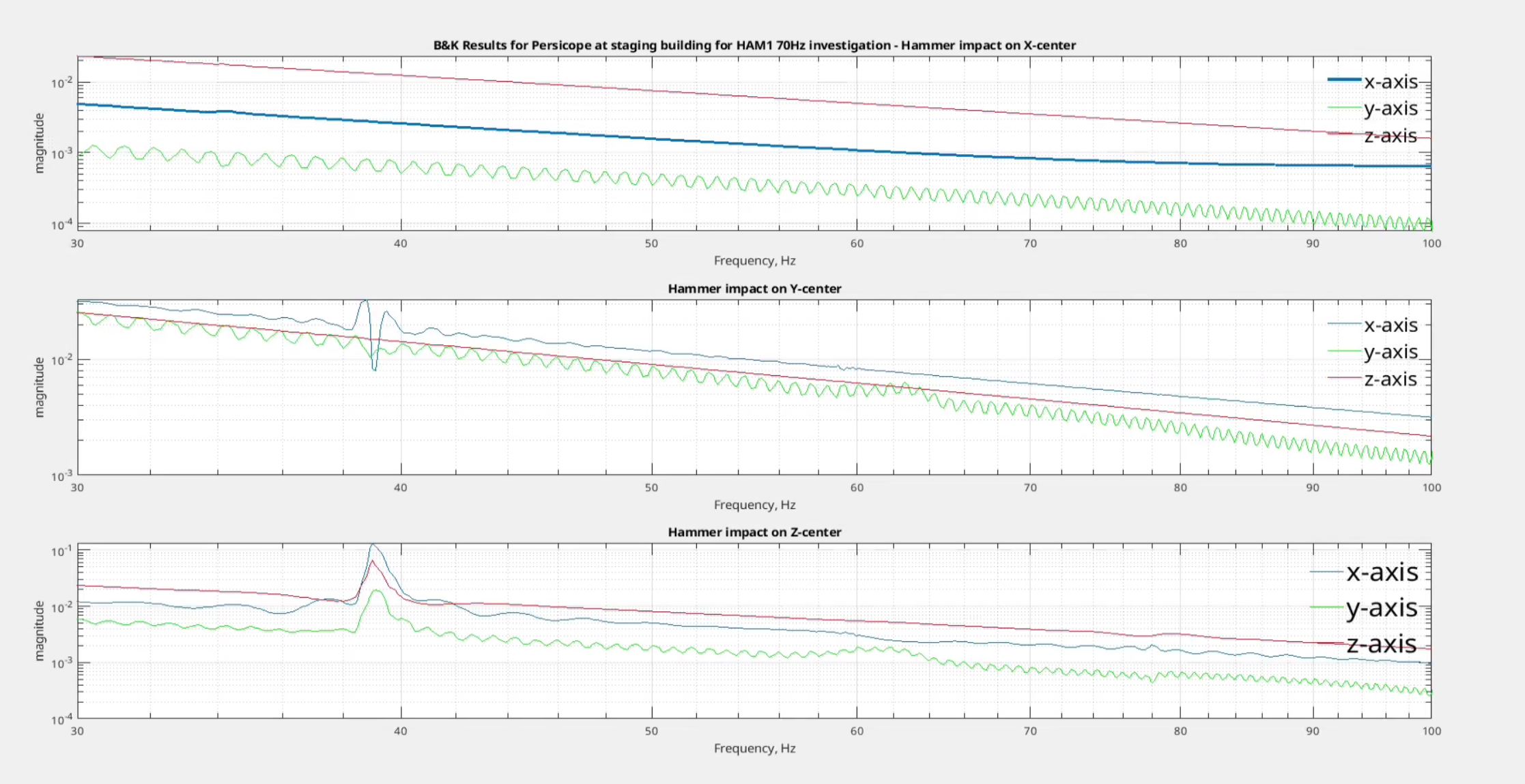
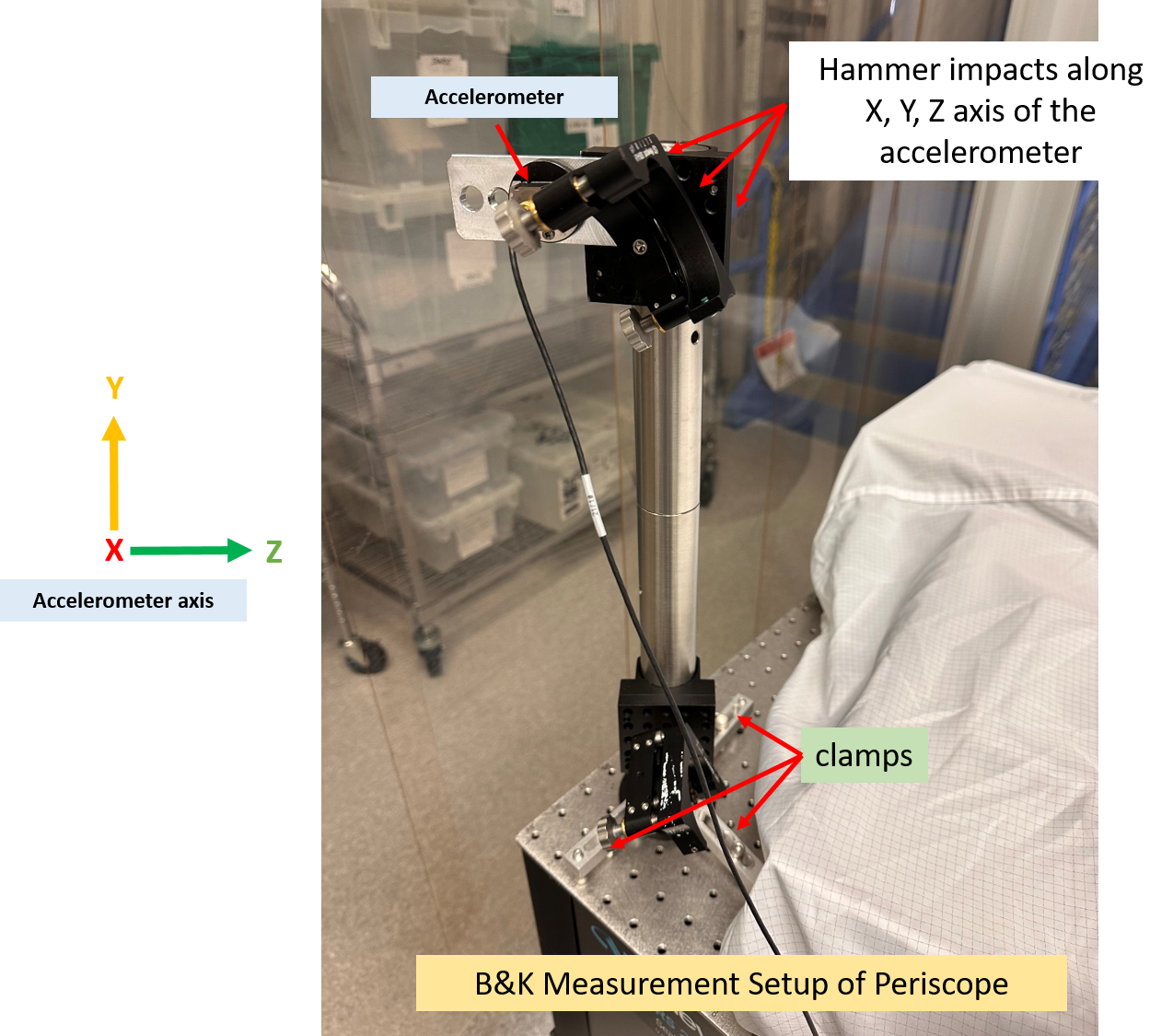
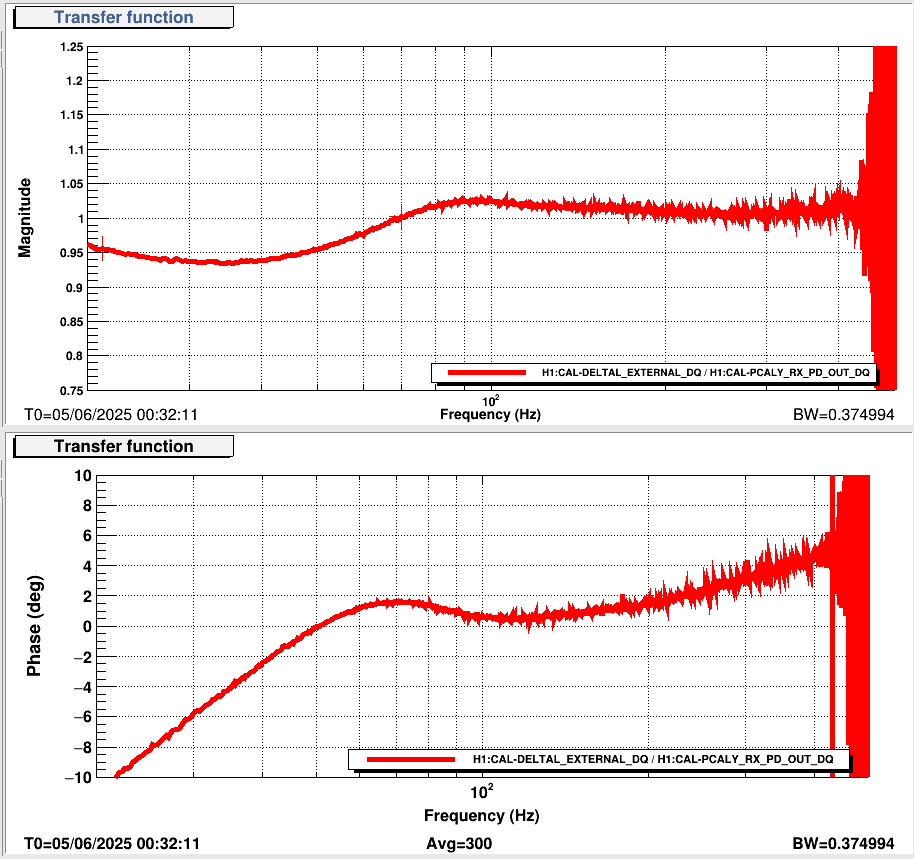
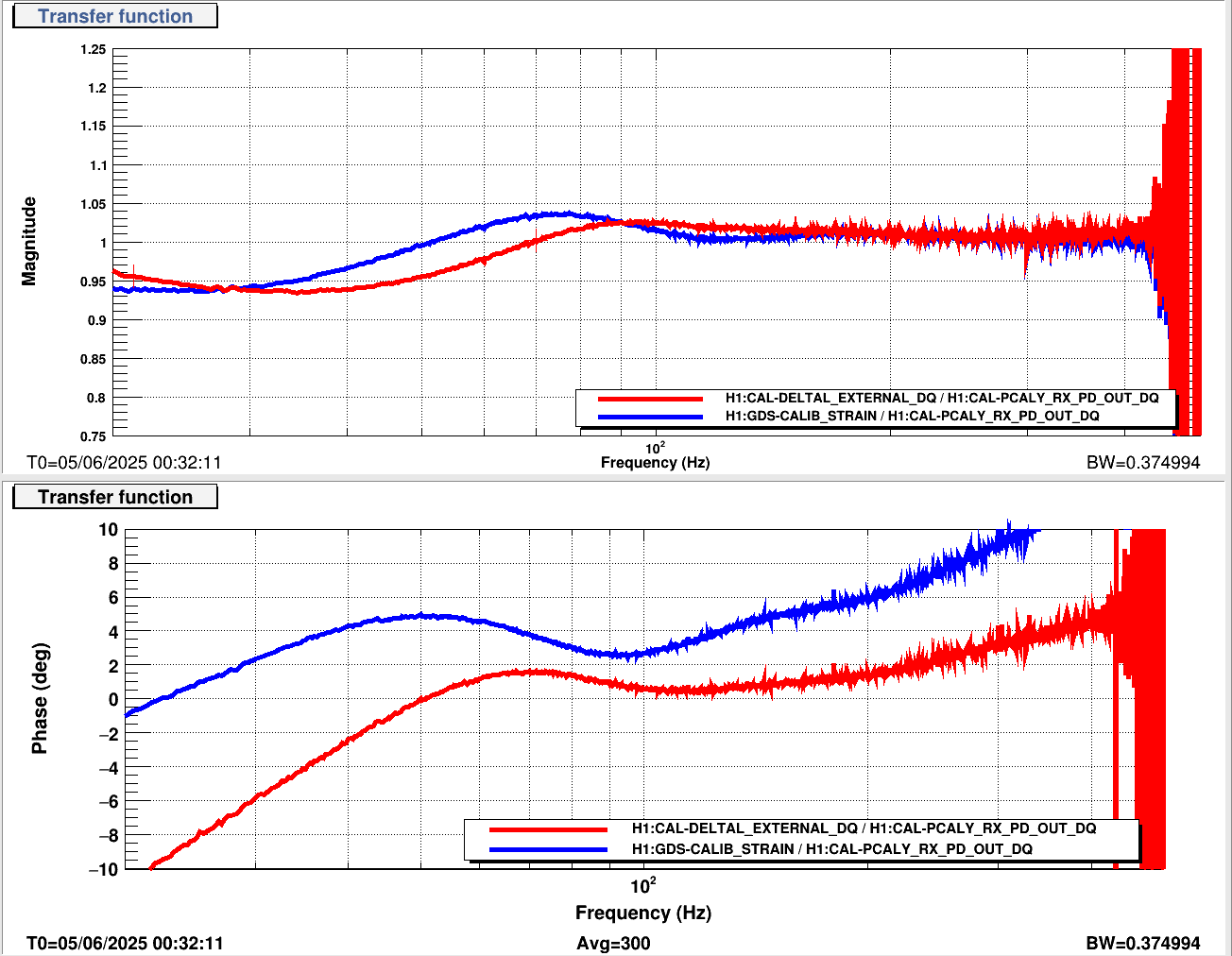
robert.schofield@LIGO.ORG - posted 13:15, Friday 06 June 2025 - last comment - 09:00, Thursday 03 July 2025(84868)
Periscope damped on ISCT1
Jim, TJ, Robert
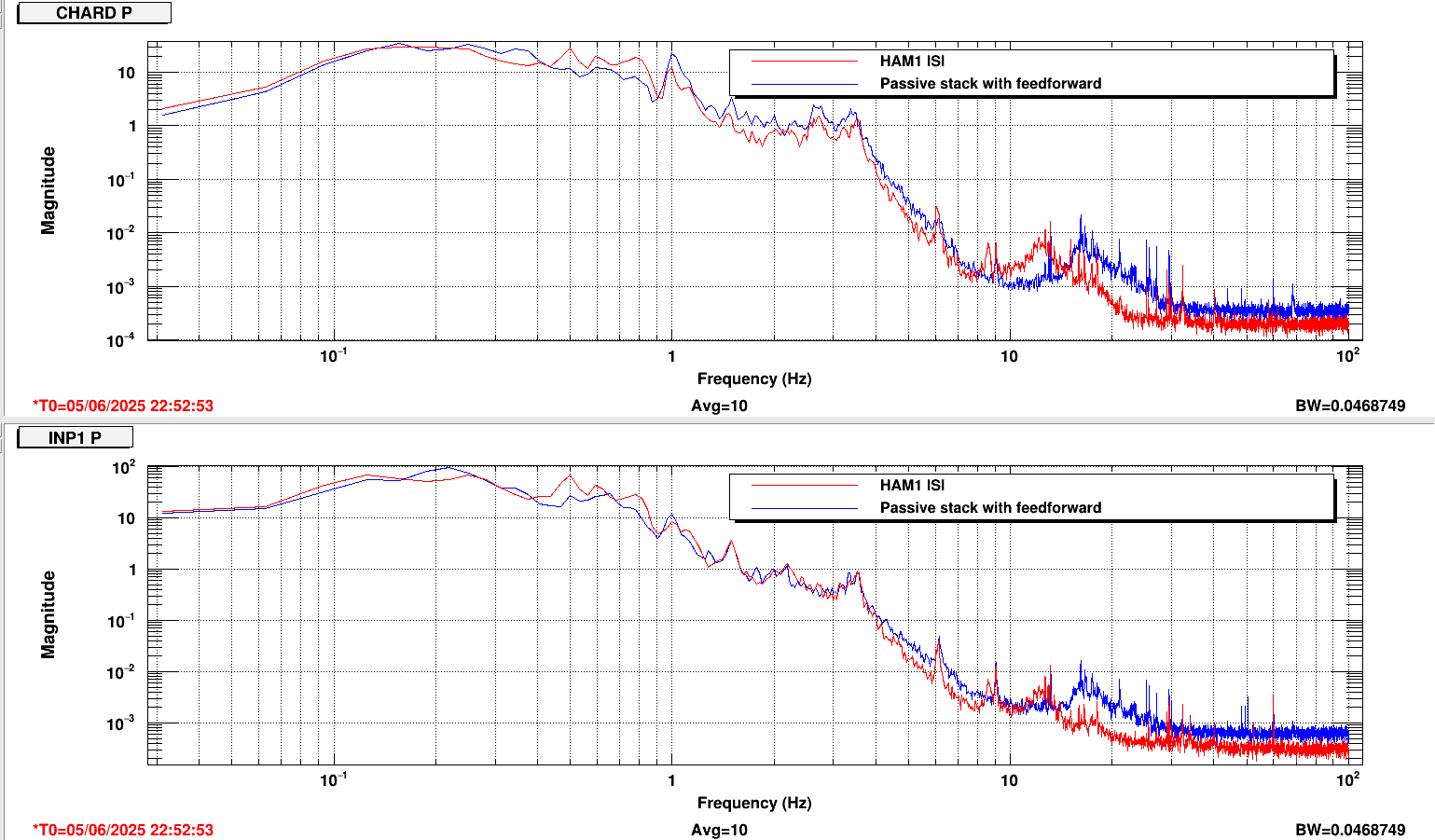
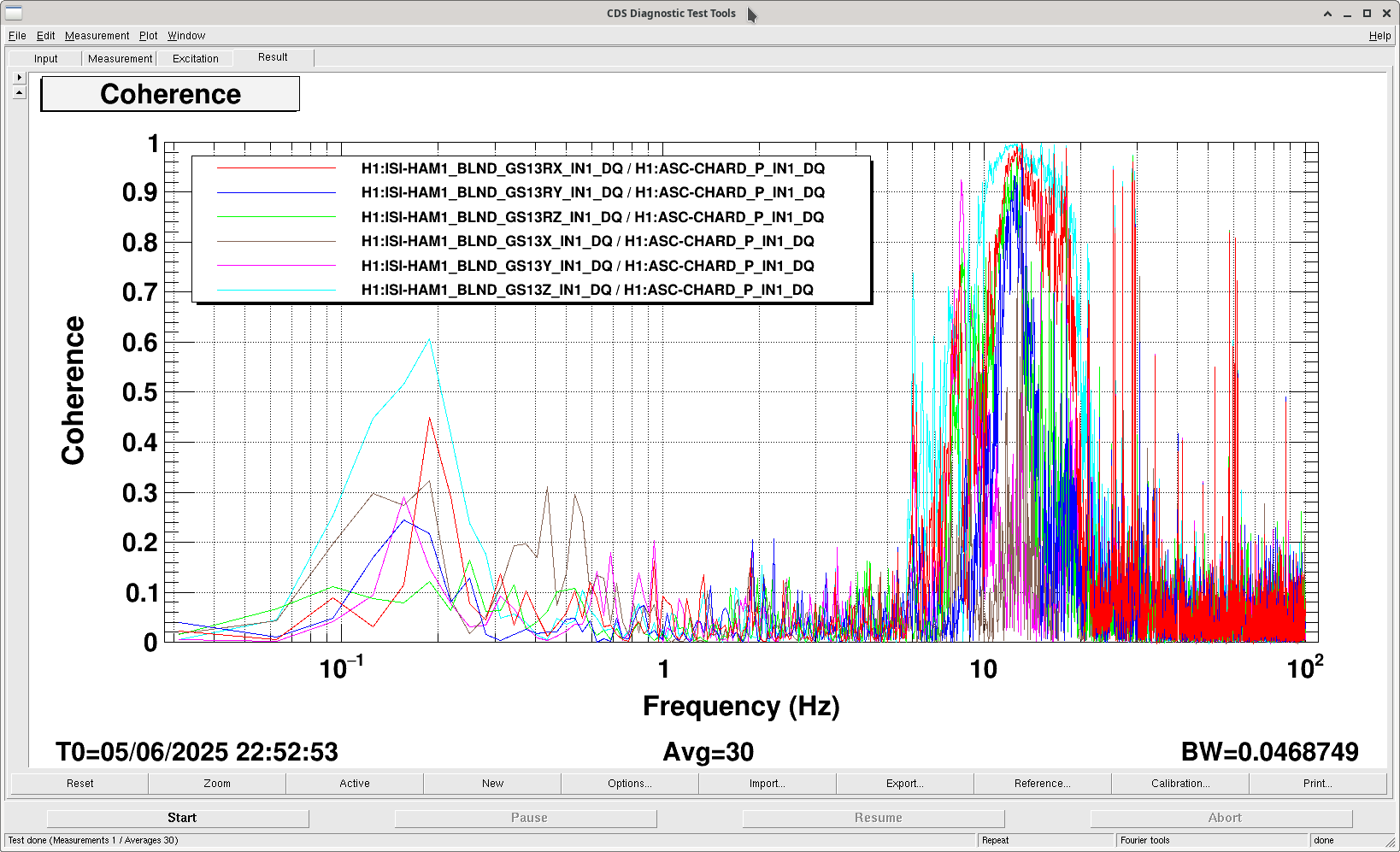
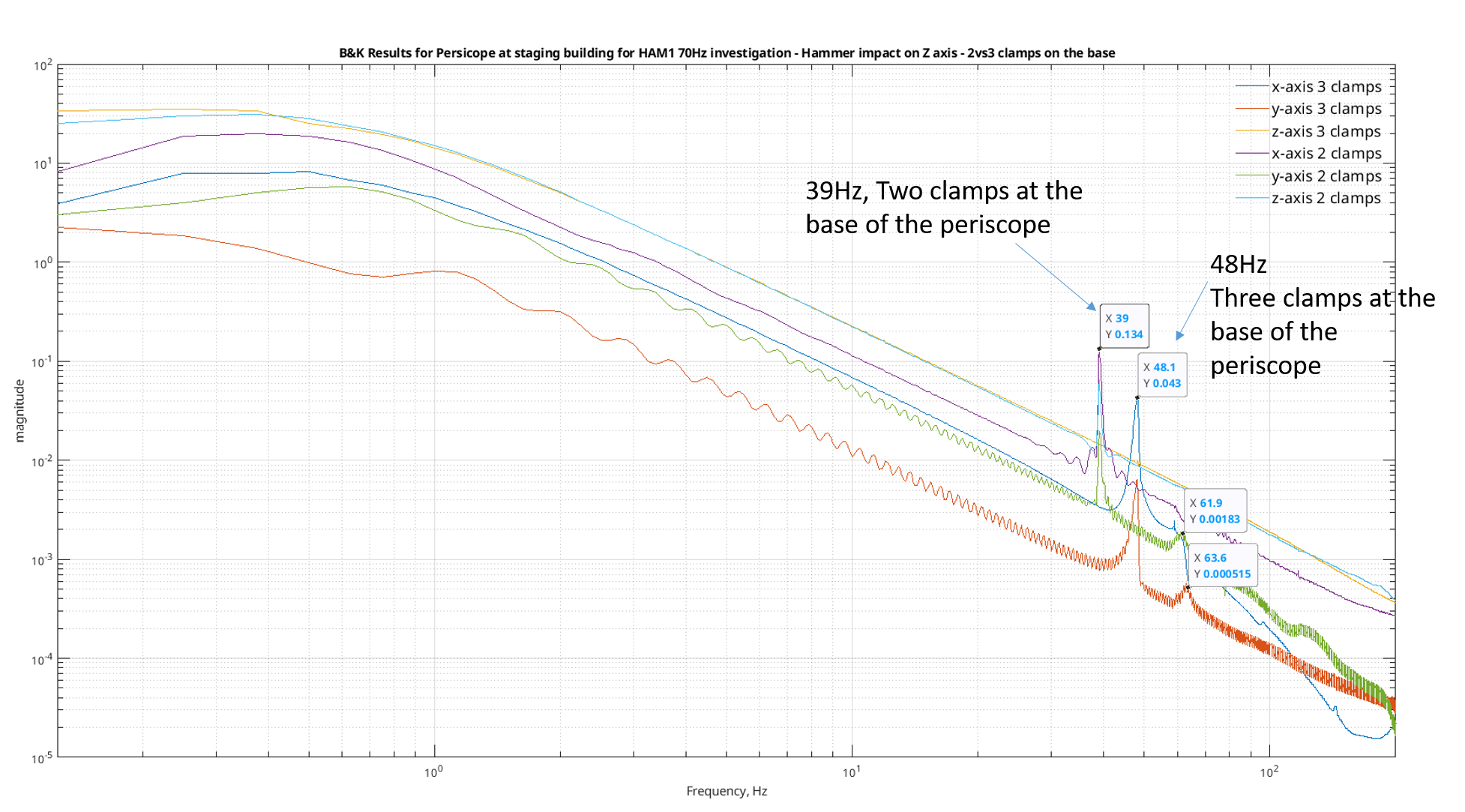
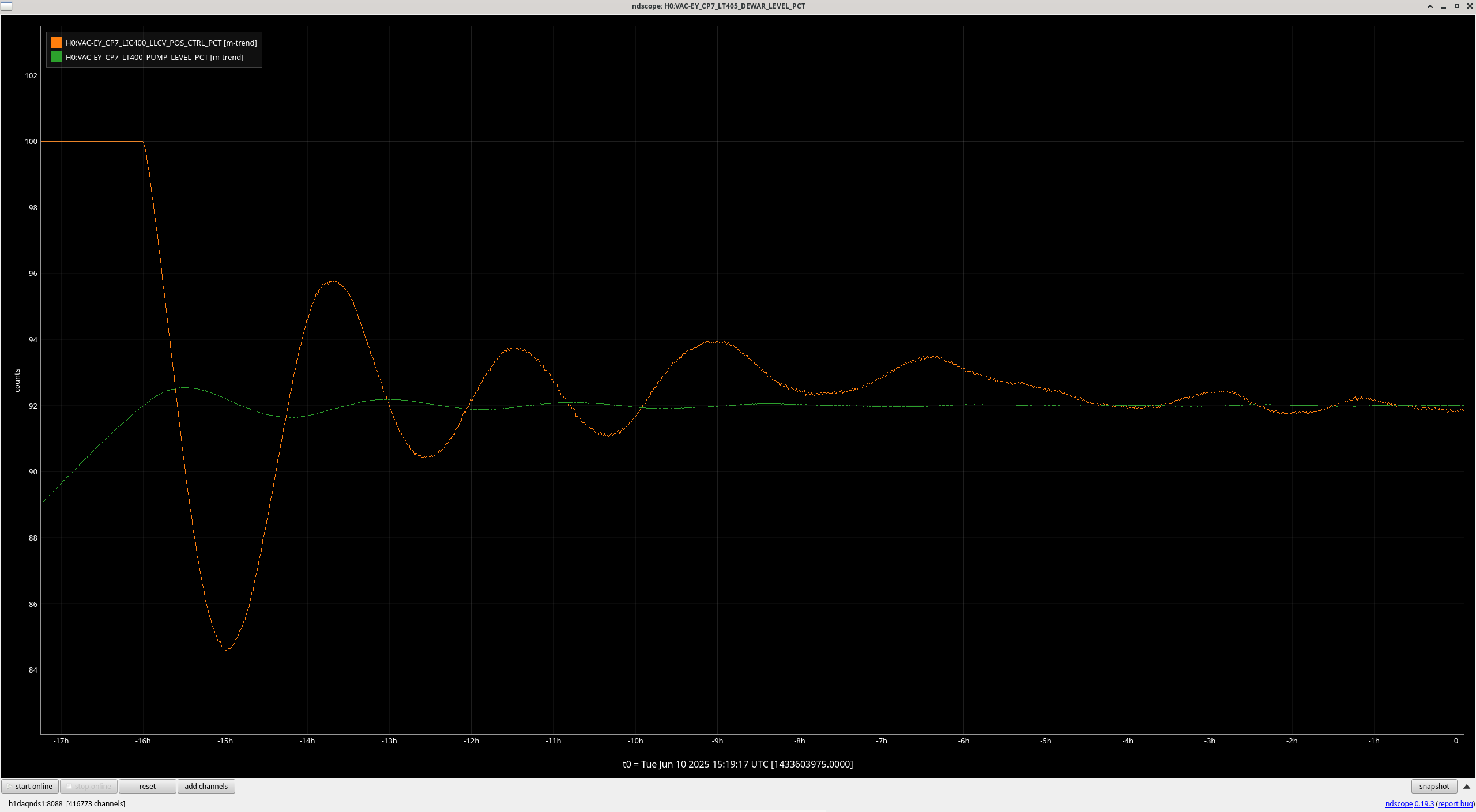
We damped the periscope on ISCT1 by removing the dog clamps one by one and inserting a strip of 1/16" viton between the dog clamp and the base of the periscope before retightening, making sure that the strips crossed the corner of the base. This is not the most effective way of damping the periscope but it was the fastest, safest and most simple damping we could do. Jim measured the Q to be around 1000, so we didn't have to do much to get an improvement. In Jim's first transfer functions after the damping, the peak looked a little wider.
Images attached to this report


Comments related to this report
This was HAM1 not ISCT1