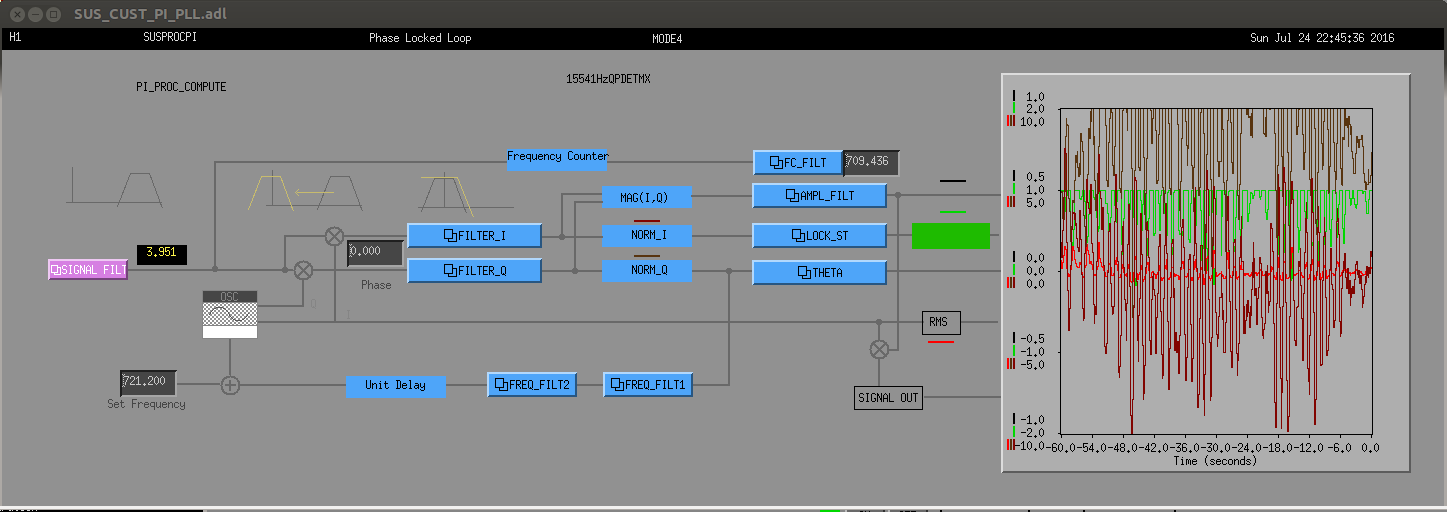
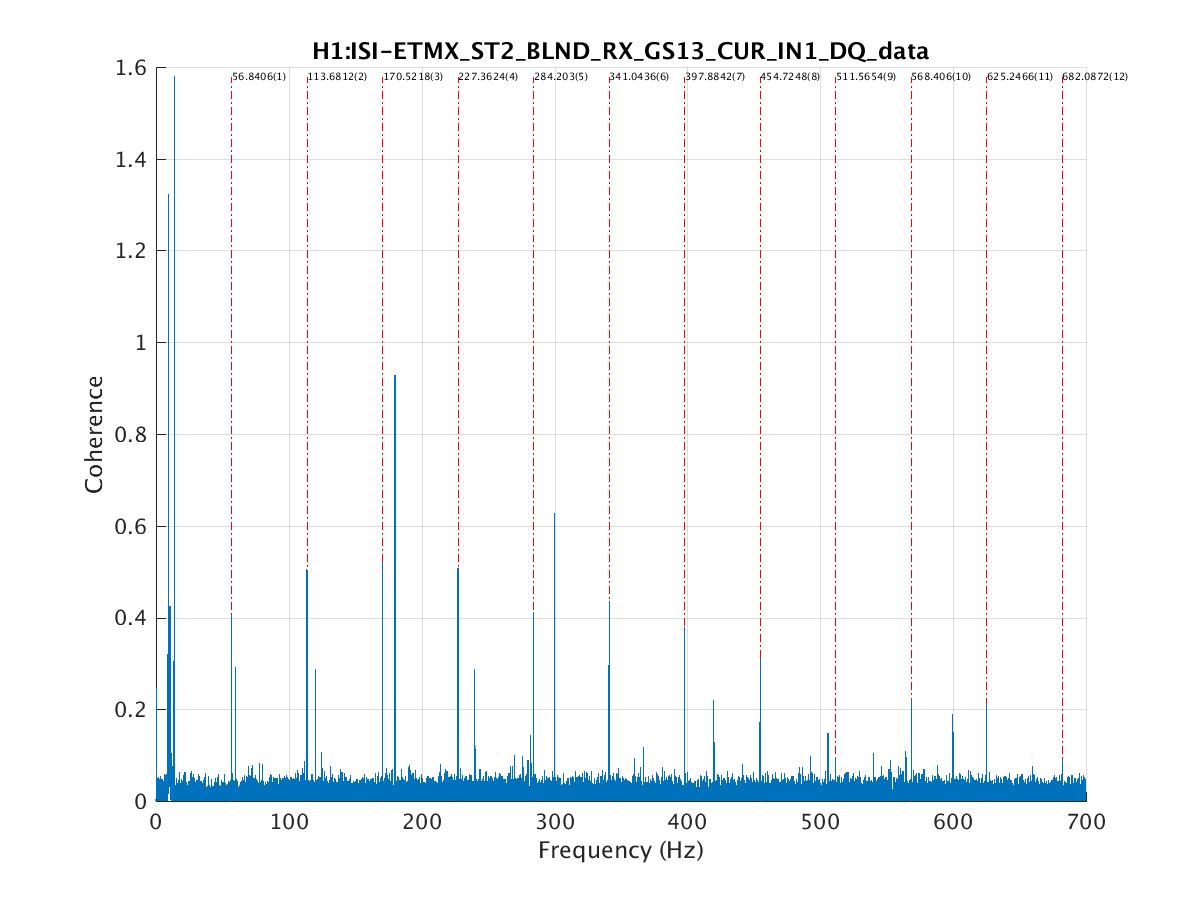
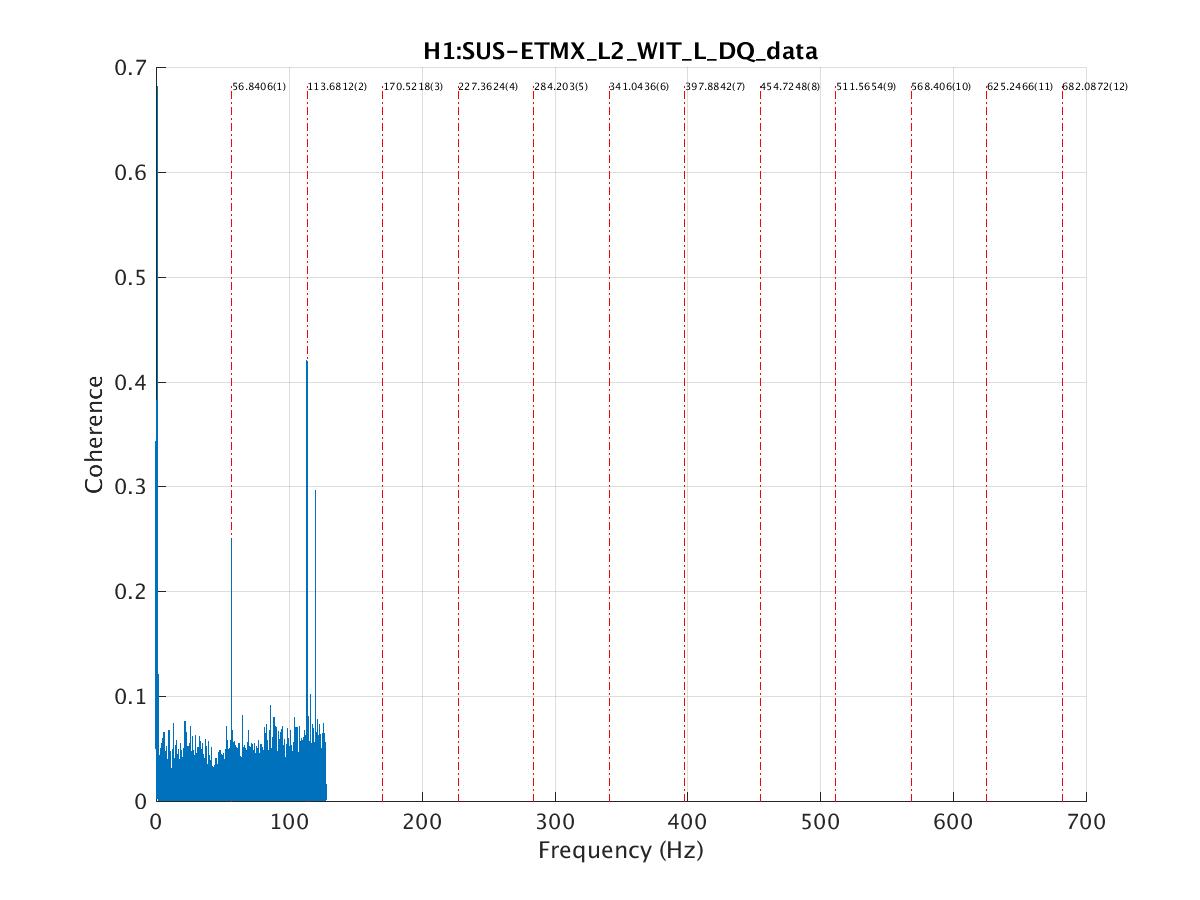
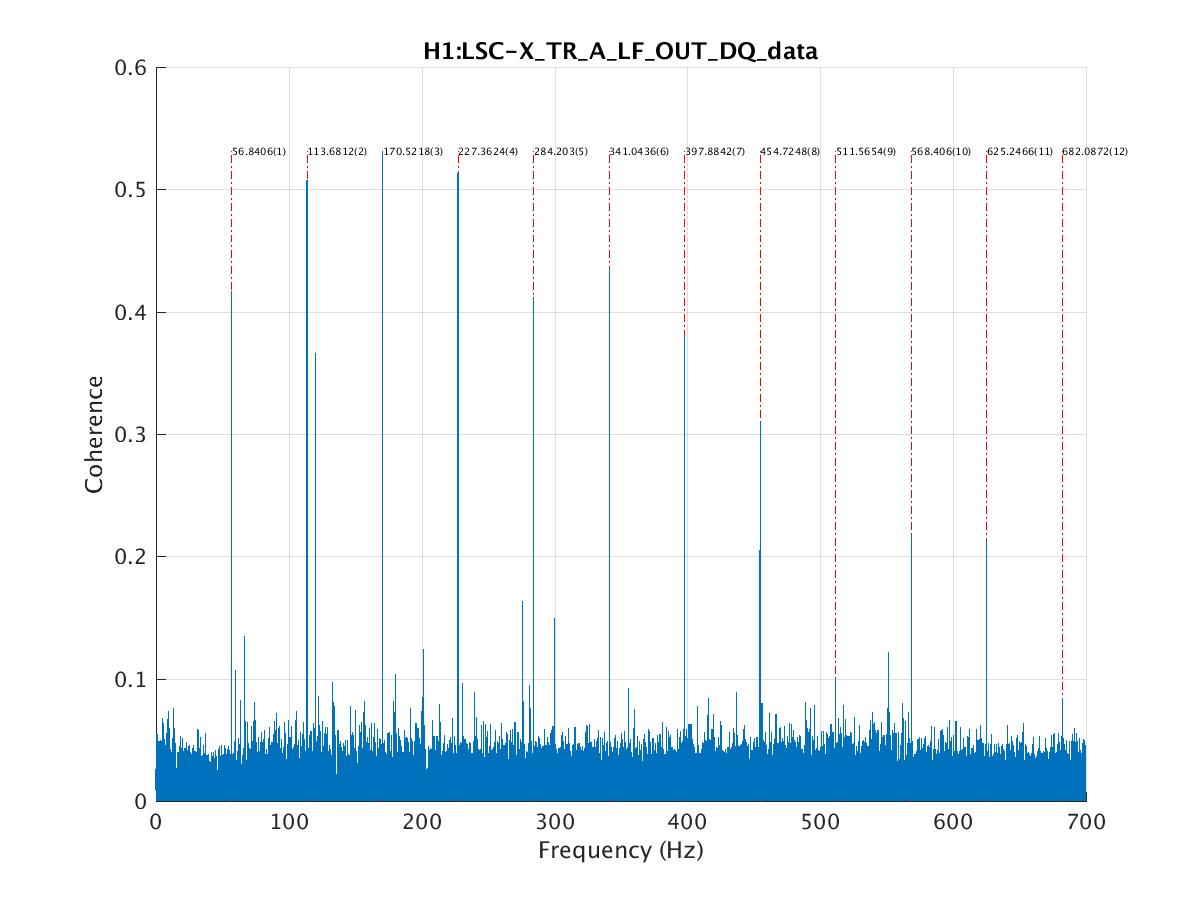
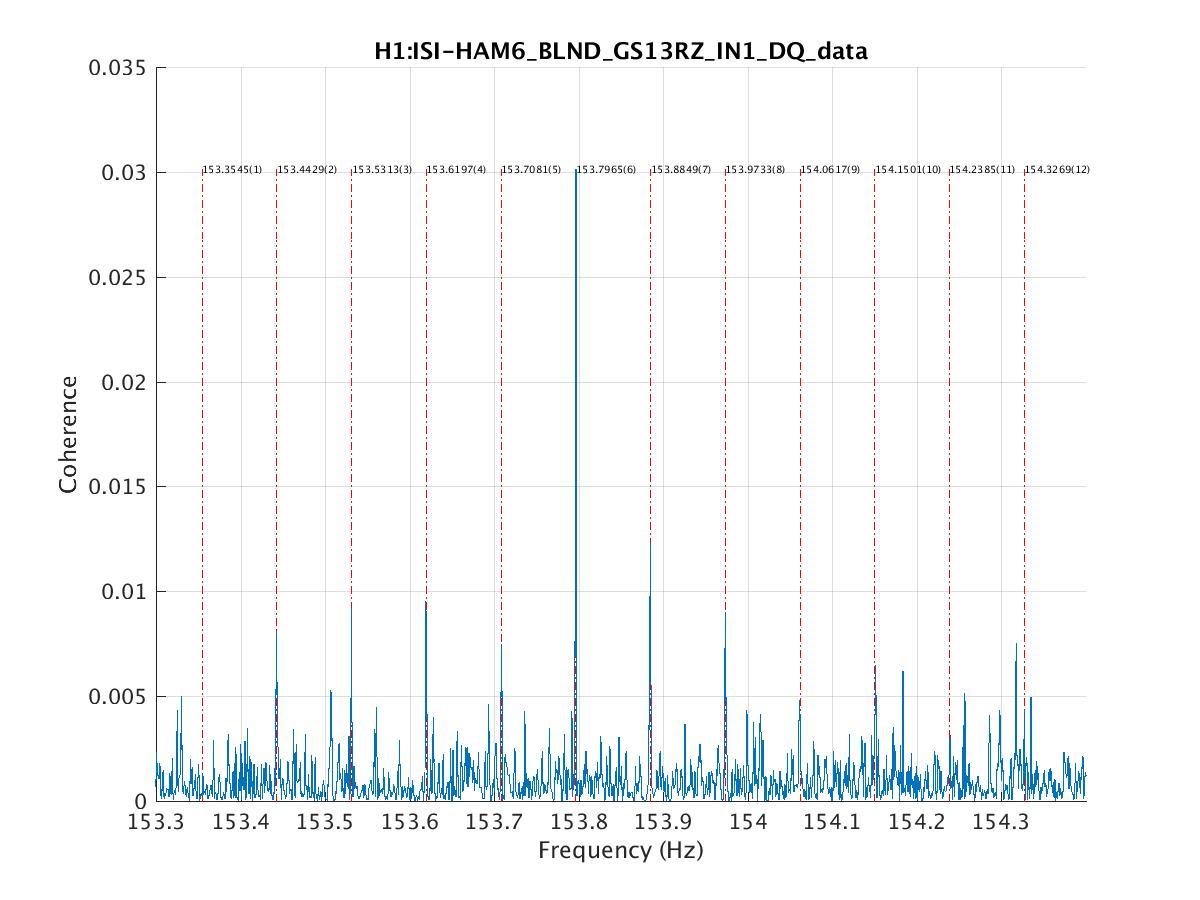
peter.king@LIGO.ORG - posted 09:03, Tuesday 26 July 2016 - last comment - 10:06, Tuesday 26 July 2016(28637)
Flow sensor and filter replacement
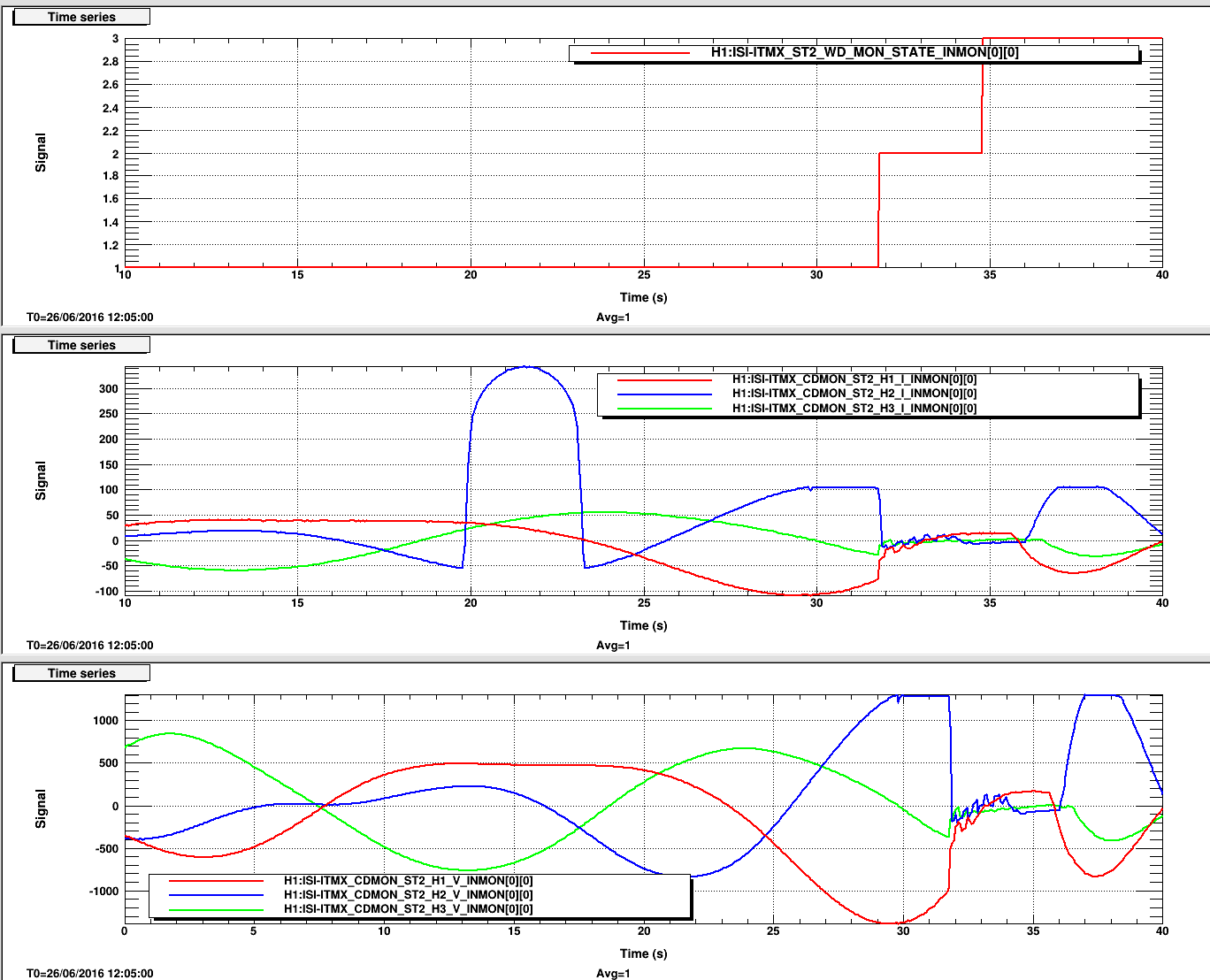
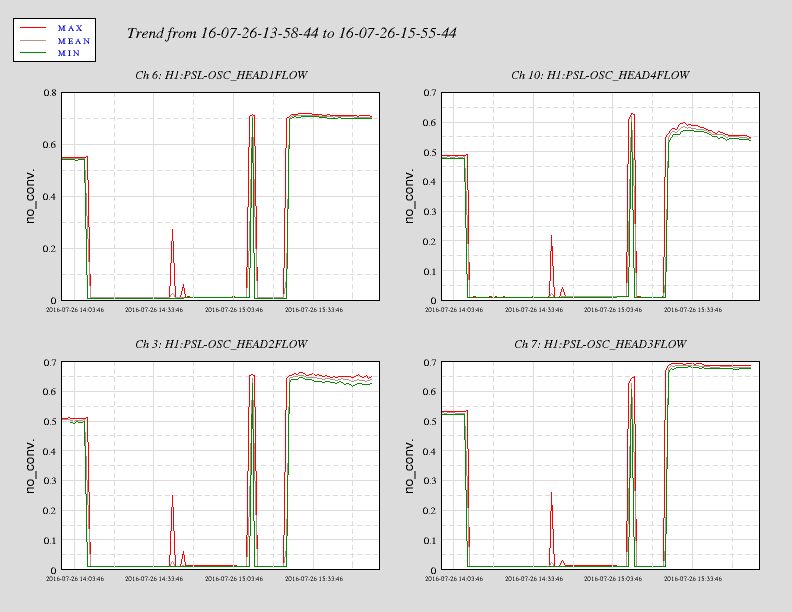
The flow sensor in the crystal chiller was replaced. The water filters in the chiller room were also replaced as per work permit ... 6008 Power cycled both the diode and crystal chillers. Rebooted the Beckhoff computer. Right away an increase in the flow rate of the crystal chiller was observed. The error message also disappeared. A plot of the before/after flow rates is attached. The exception delay in the crystal chiller was set back to 000 s. JeffB/Jason/Peter
Images attached to this report
Comments related to this report
I also happened to notice that the pump current for head 3 is now correctly reporting 50.2 A on the MEDM screen as opposed to 100+ A yesterday (and possibly a number of days before).
The sensor replacement does not appear to have fixed the problem.