Evan and I spent most of the day trying to investigate the sudden locklosses we've had over the last 3 days.
1) We can stay locked for ~20 minutes with ALS and DRMI if we don't turn on the REFL WFS loops. If we turn these loops on we loose lock within a minute or so. Even with these loops off we are still not stable though, and saw last night that we can't make it through the lock acquisition sequence.
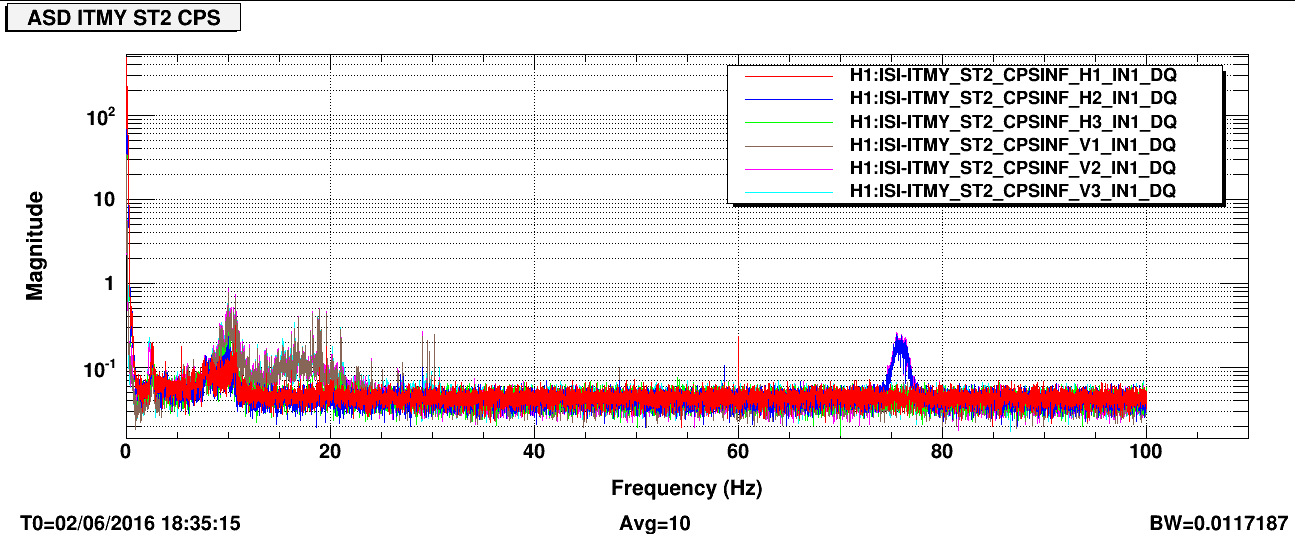
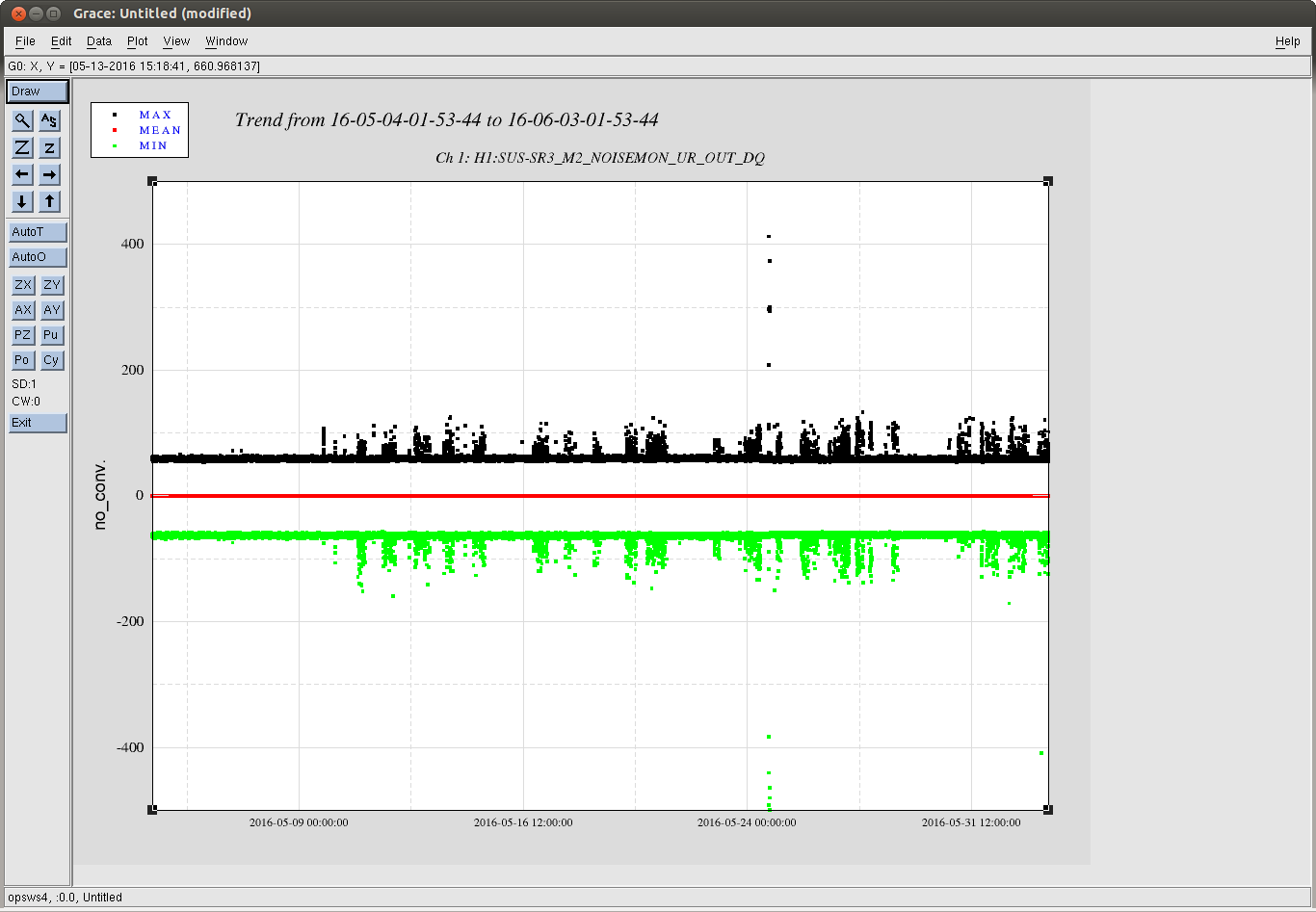
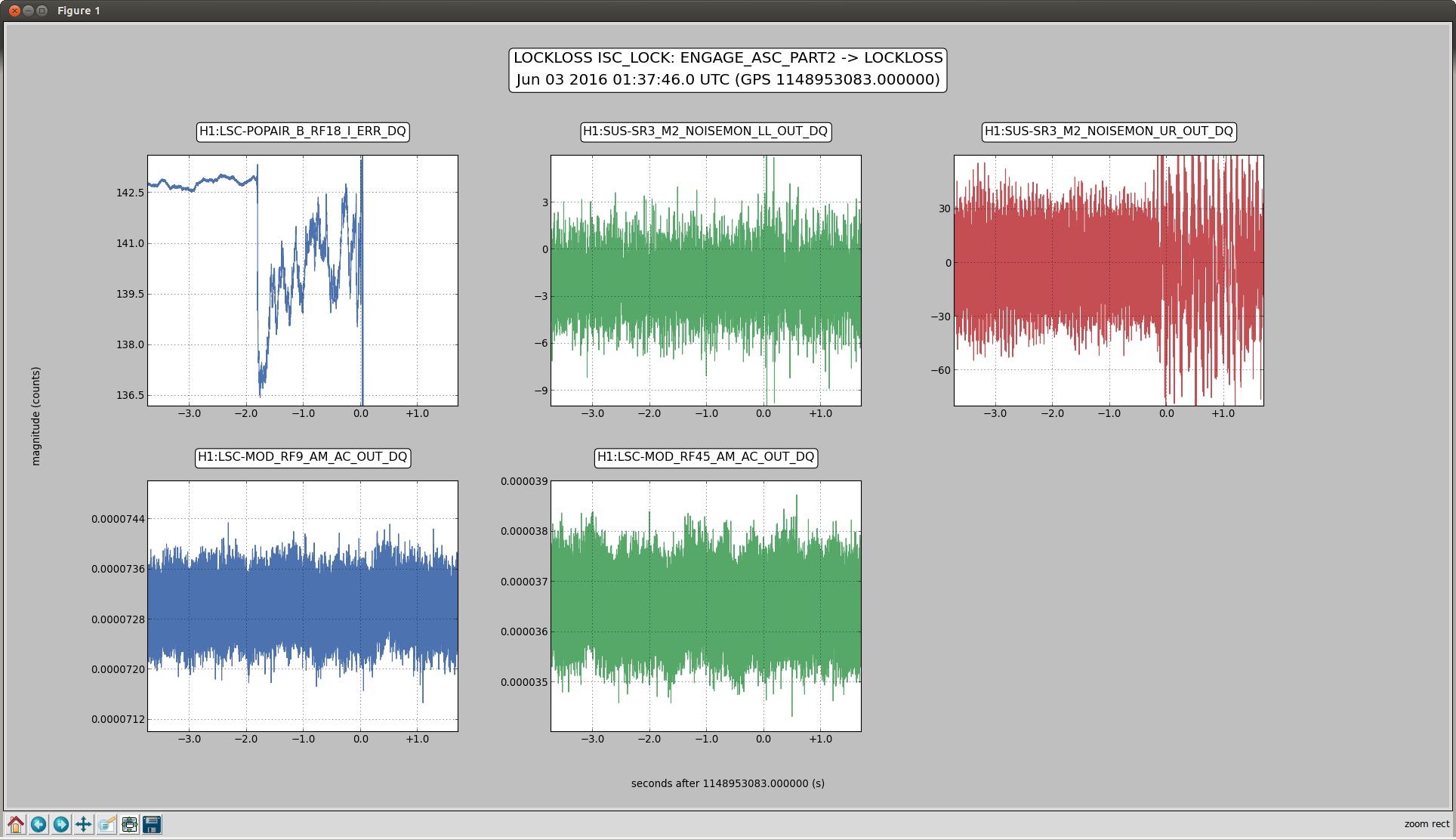
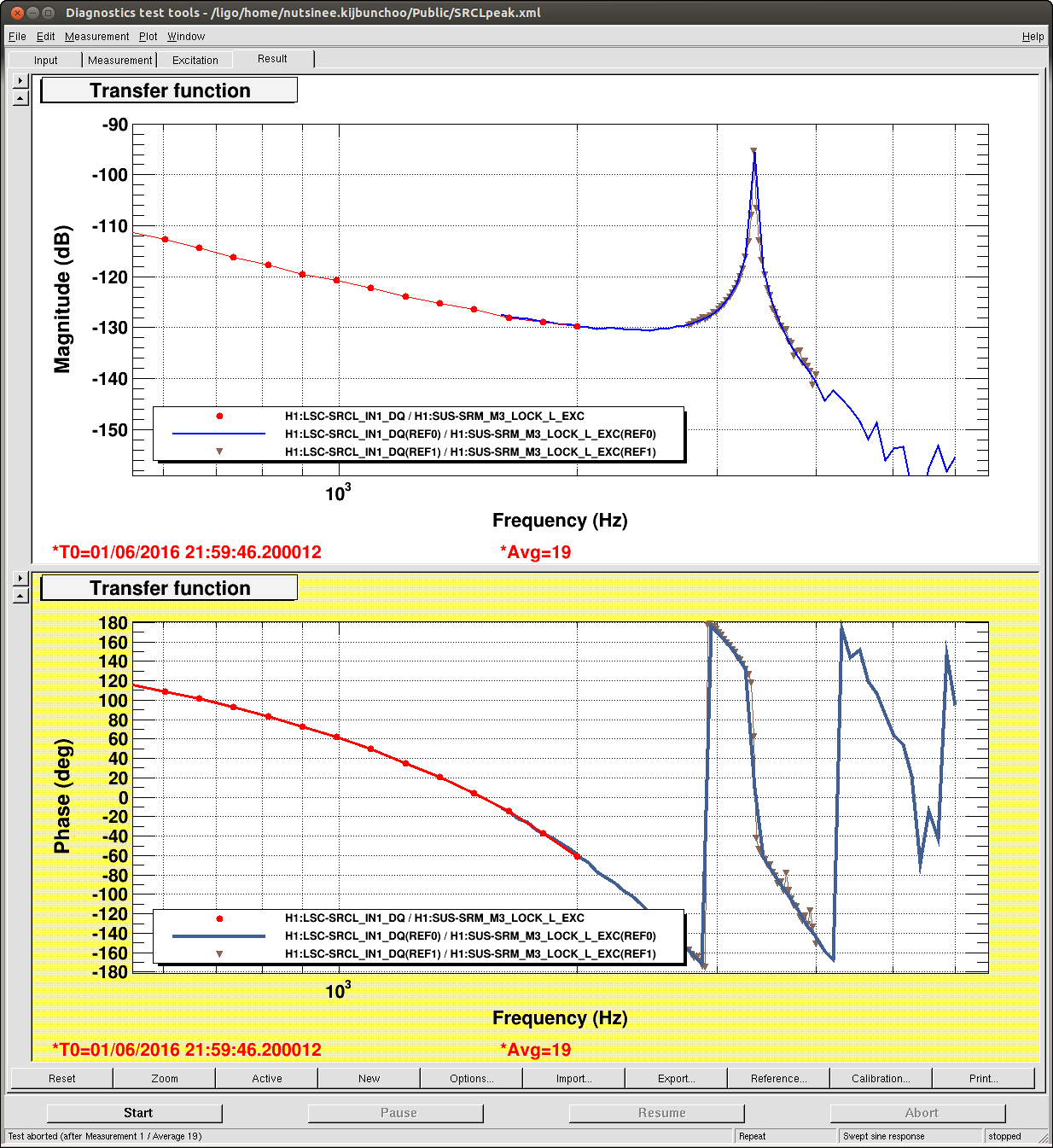
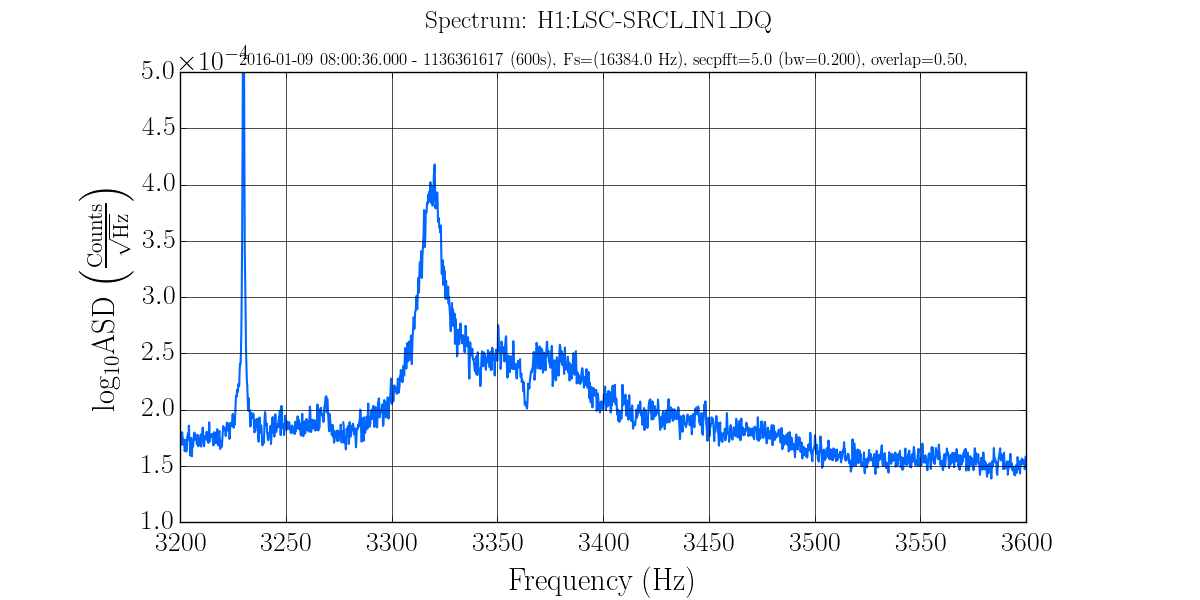
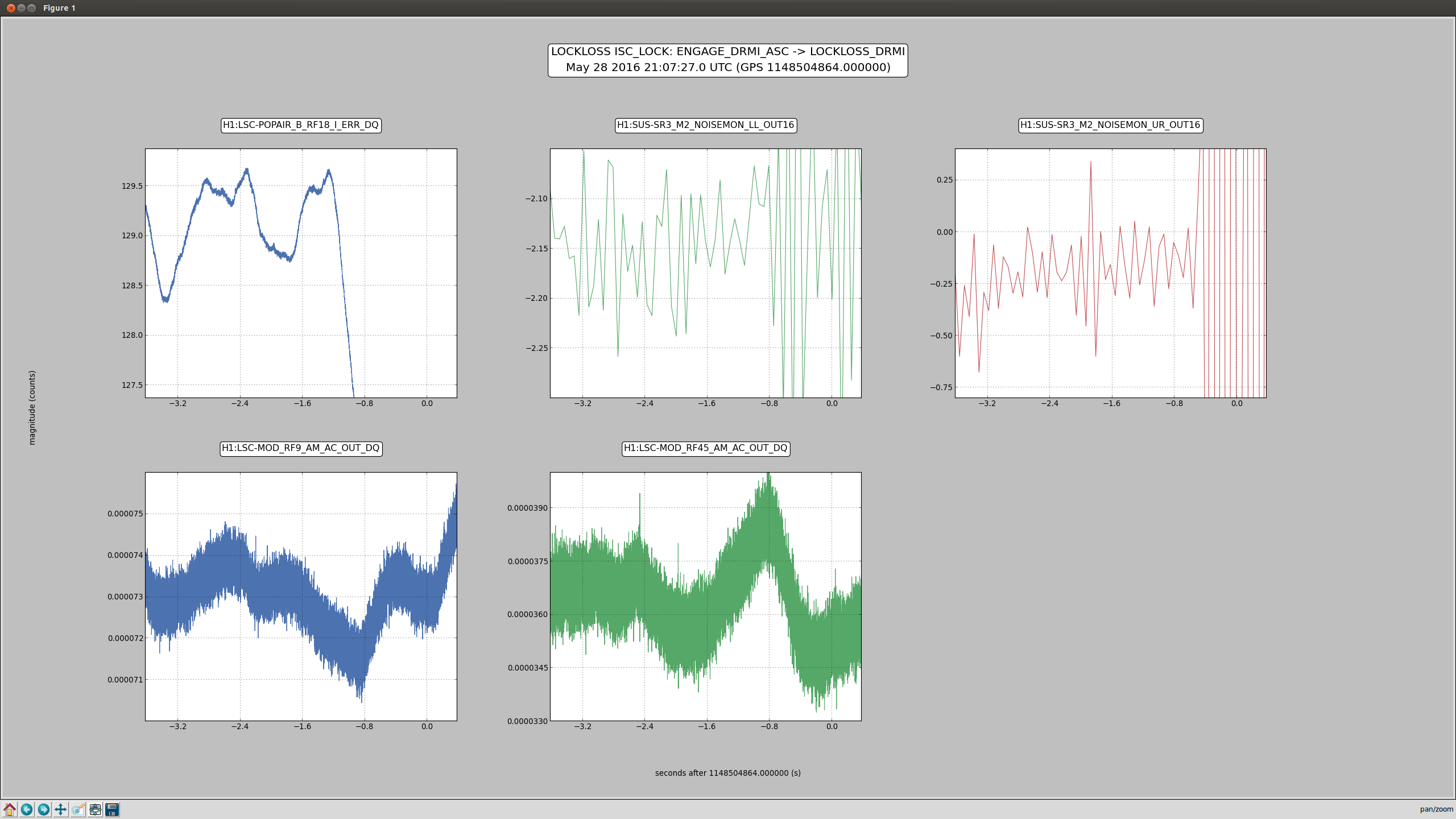
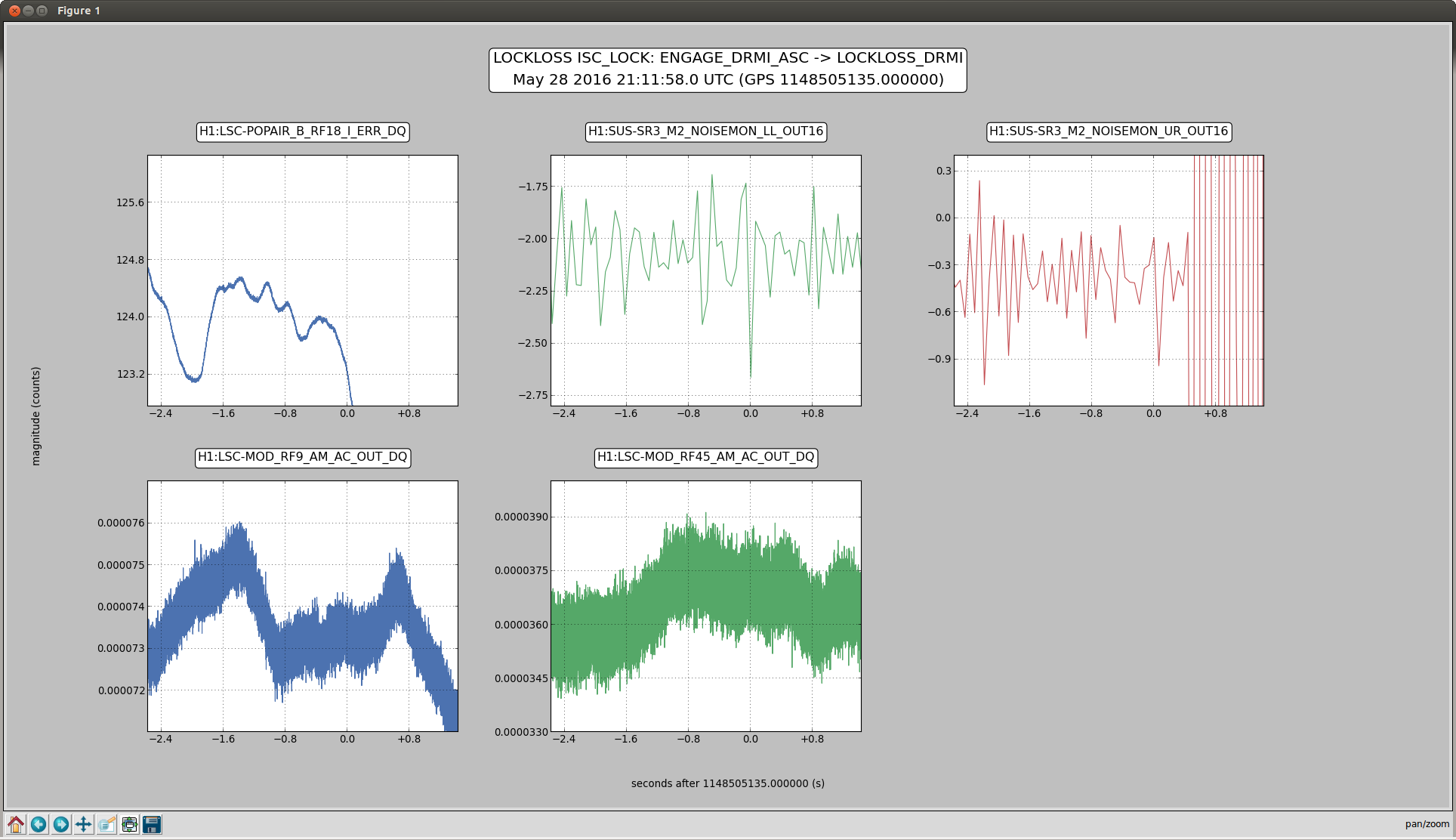
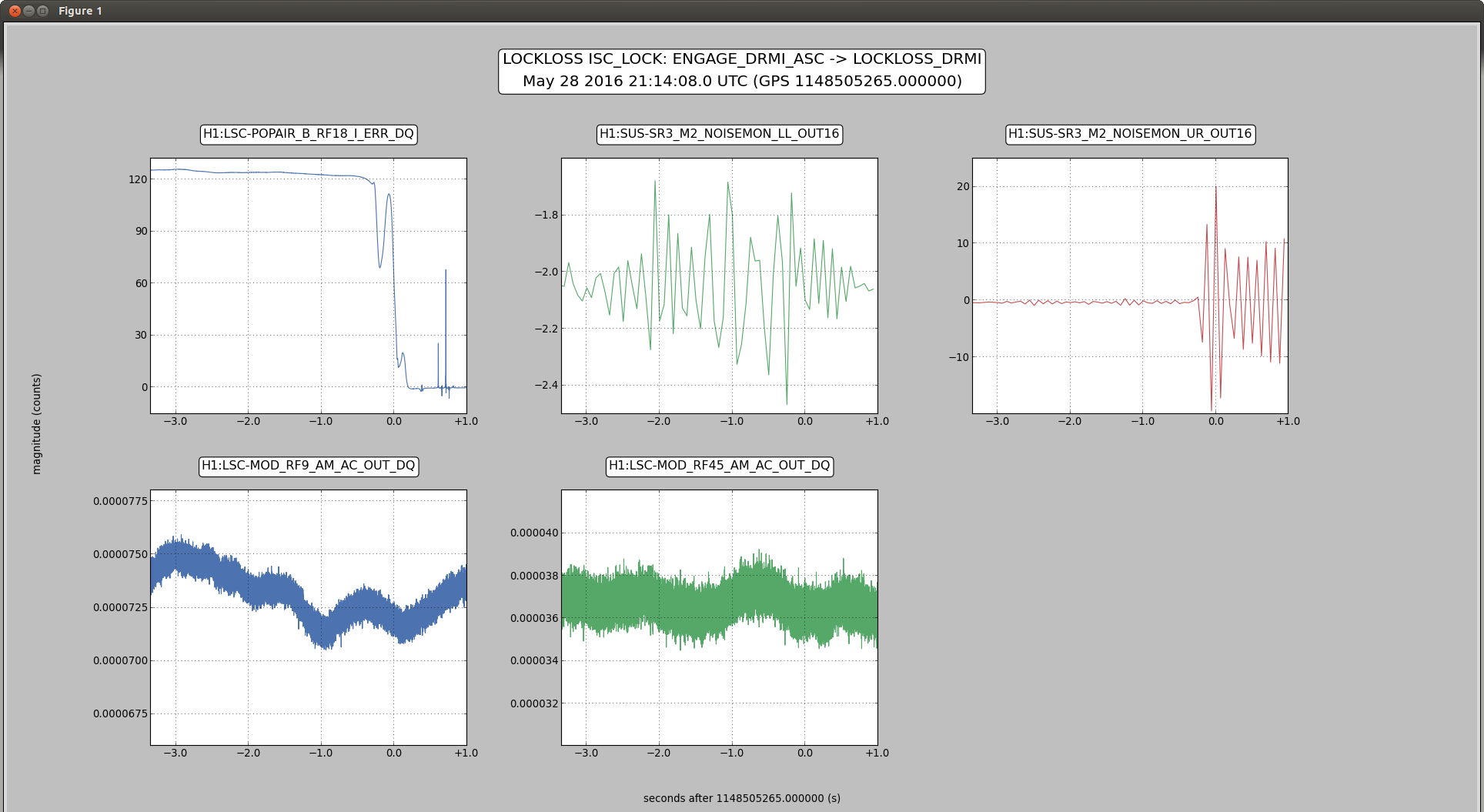
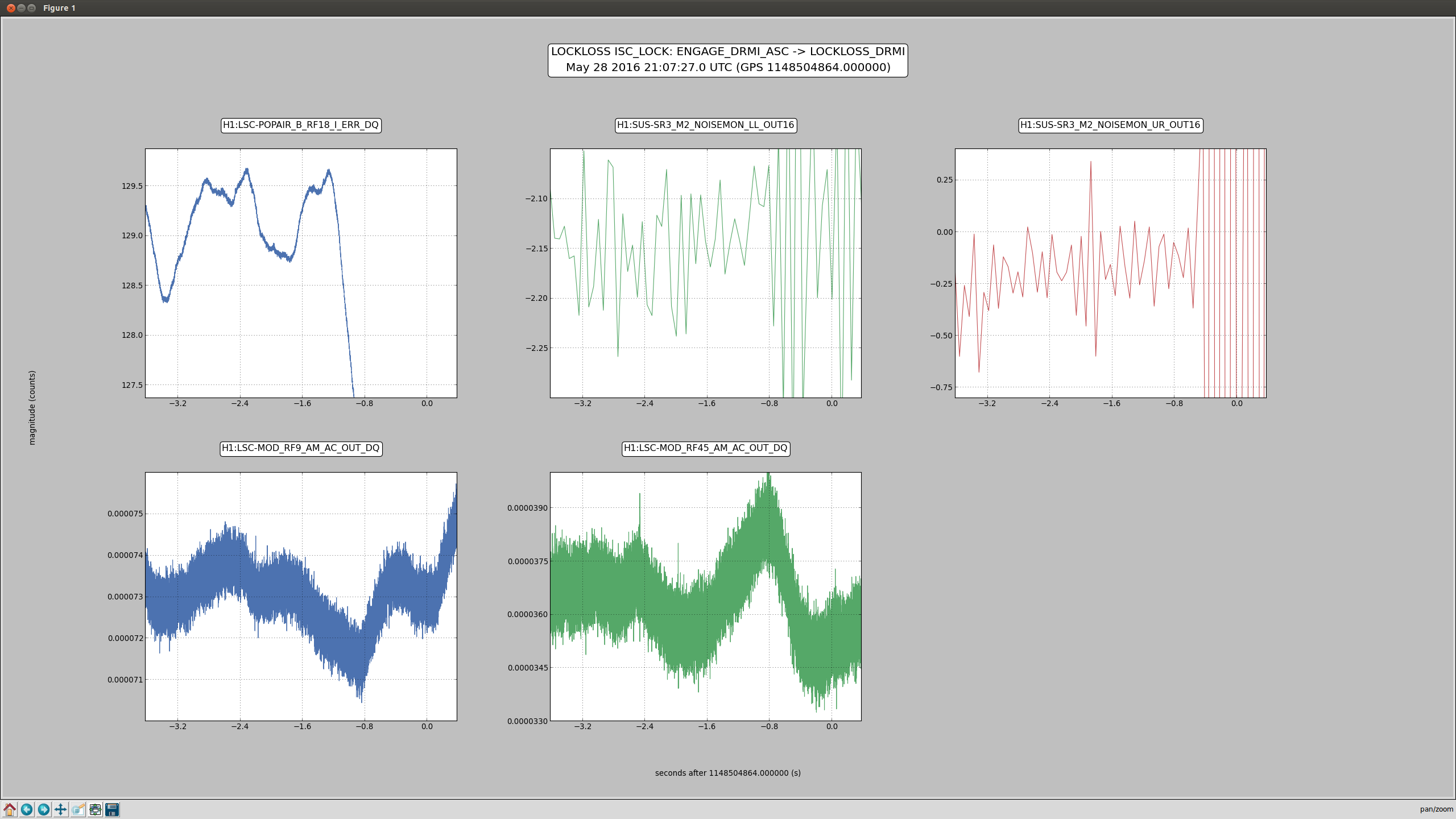
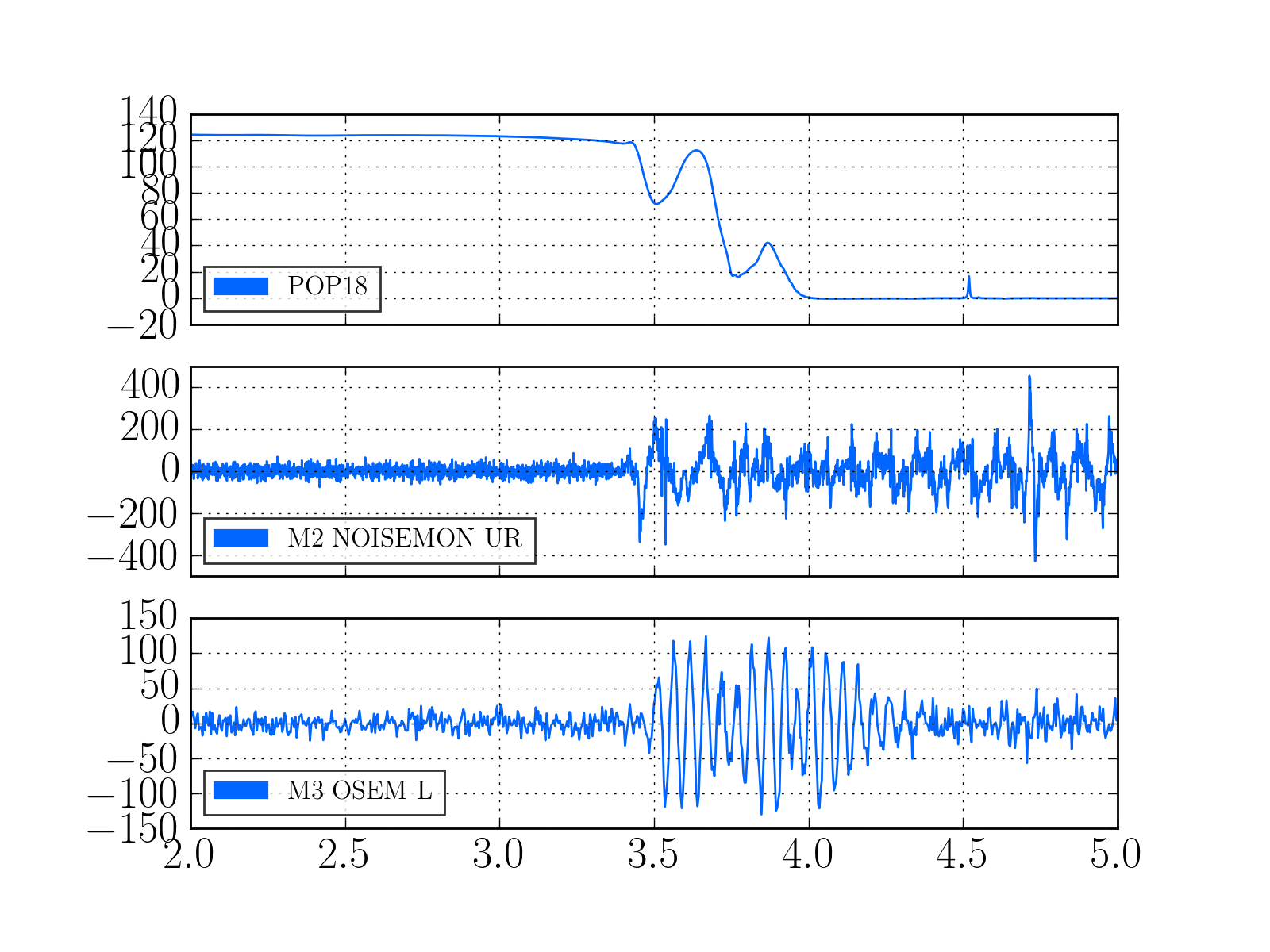
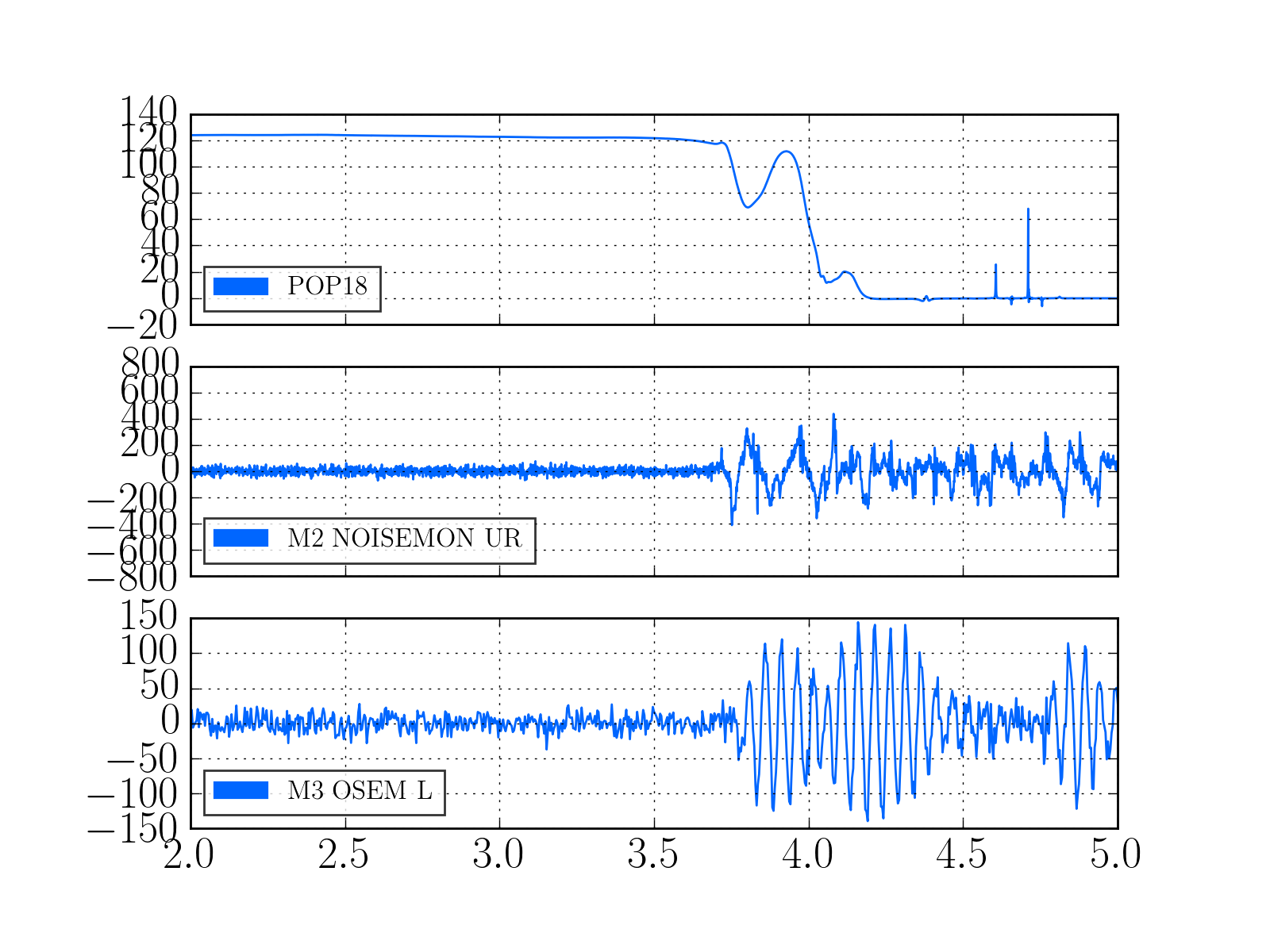
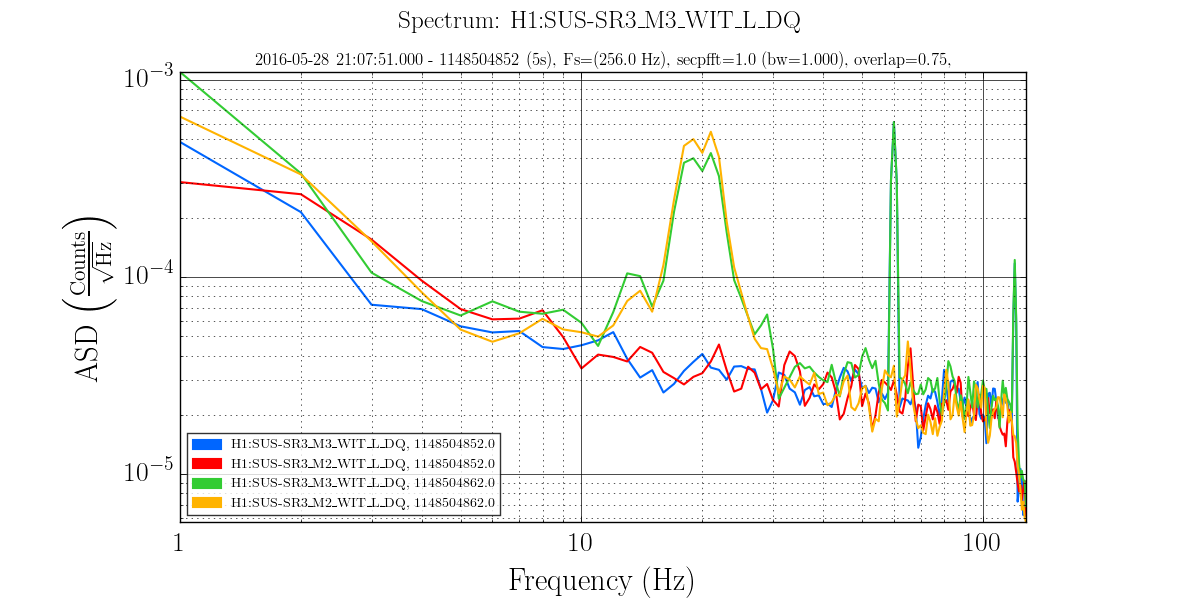
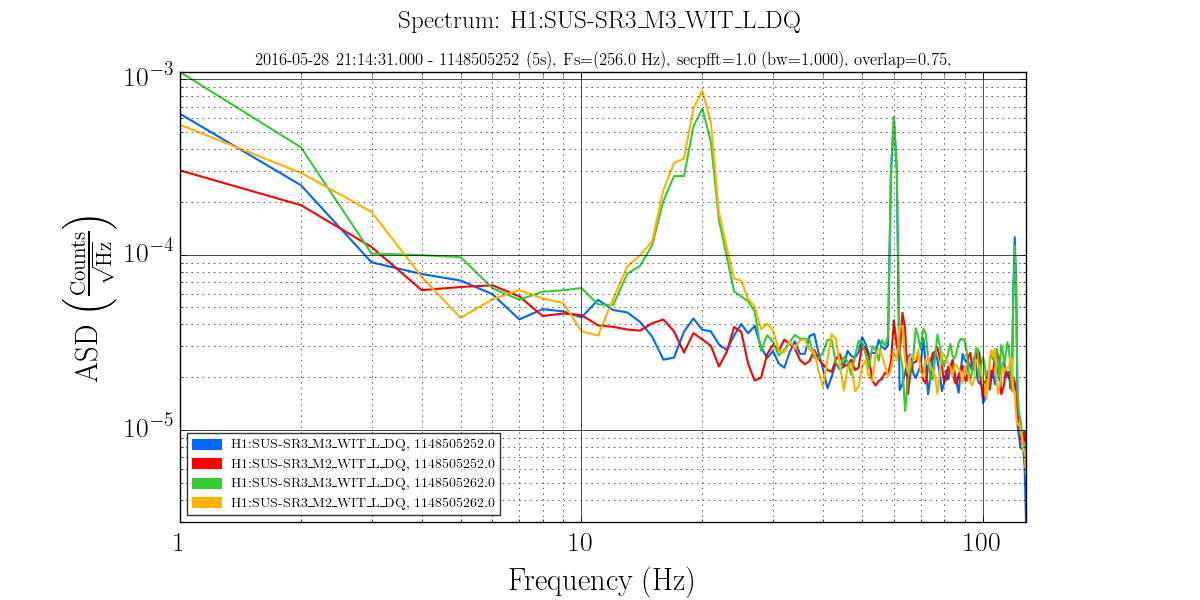
2)In almost every lockloss, you can see a glitch in SR3 M2 UR and LL noisemons just before the lockloss, which lines up well in time with glitches in POP18. Since the UR noisemon has a lot of 60 Hz noise, the glitches can only be seen there in the OUT16 channel, but the UR glitches are much larger. (We do not actuate on this stage at all). However, there are two reasons to be skeptical that this is the real problem:
-
There is nothing in the witness sensor or OpLev to indicate that the optic is really moving. These just might not be sensitive enough, but last time we had sus electronics problems with SR3 there was a clear disturbance on the OpLev and witness sensor (21095 and 21081)
-
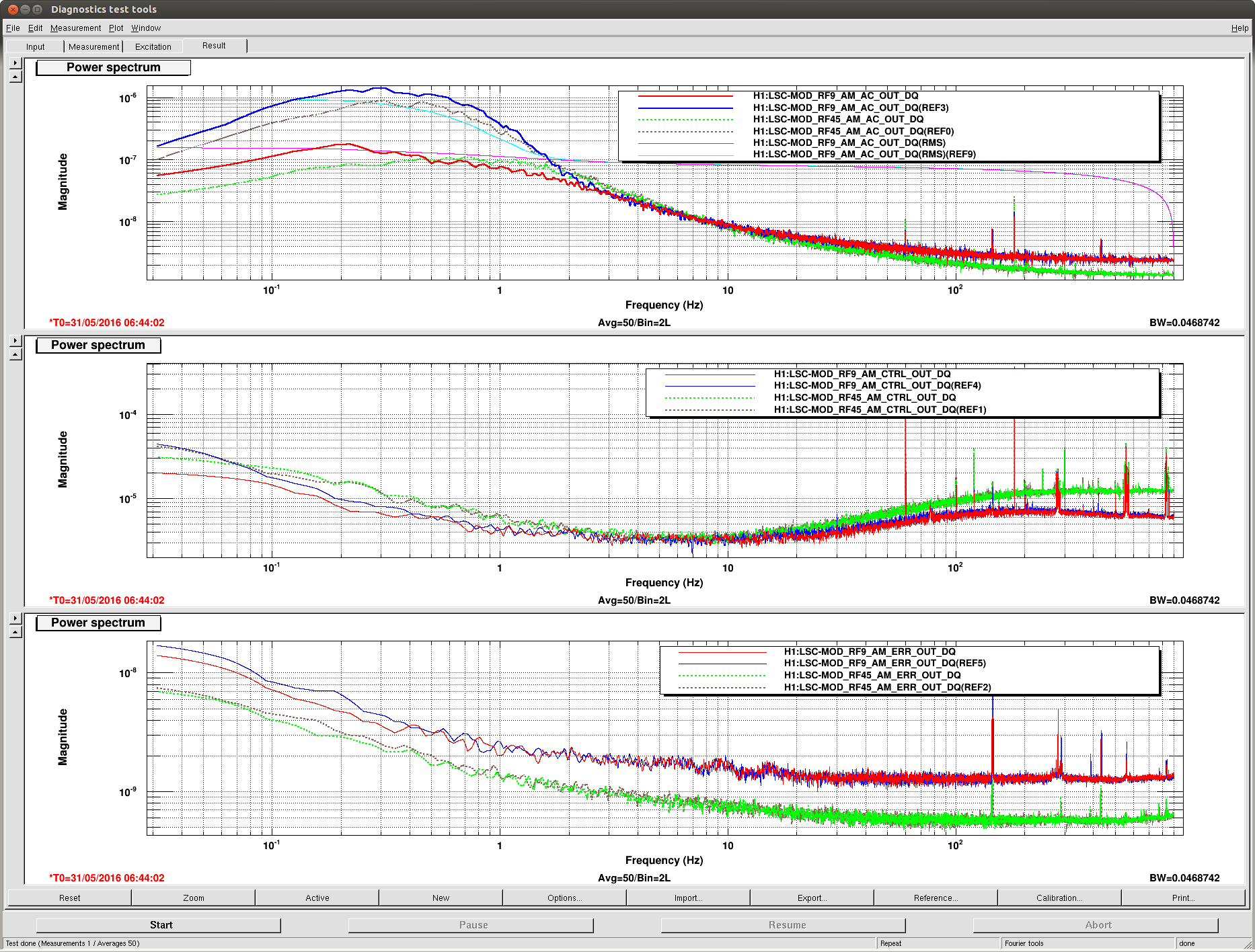
These large glitches have been happening since May10th or so, and we have only started having locking problems in the last 3 days. The RF problem of the last few days seems to corespond better to our locking difficulties, although there aren't signs of problems in the RF readbacks at the exact lockloss times.
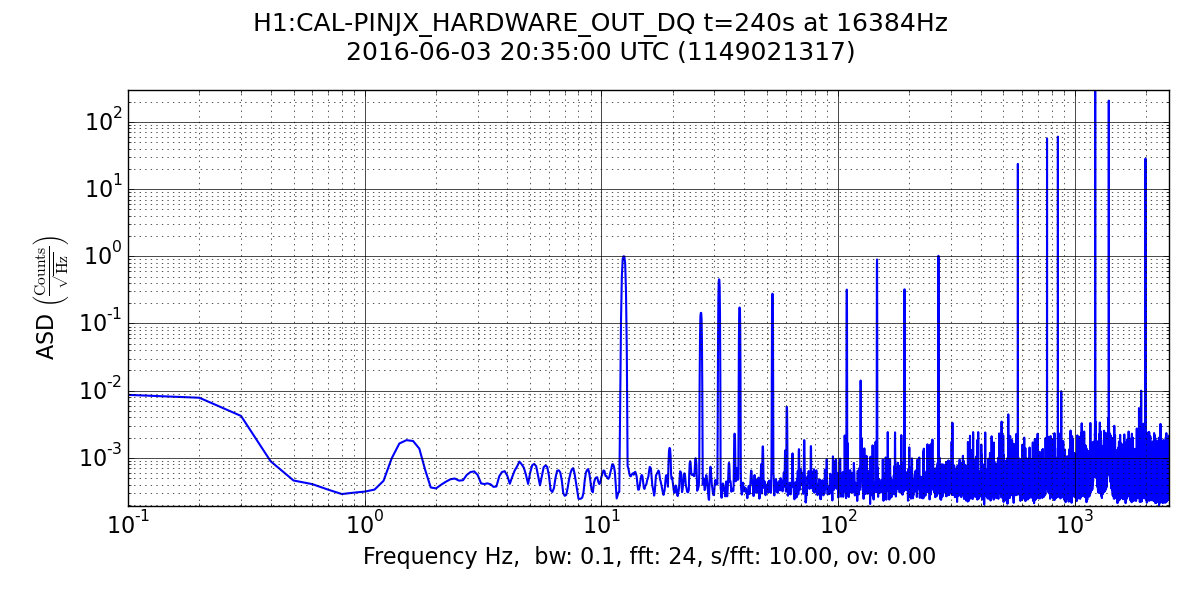
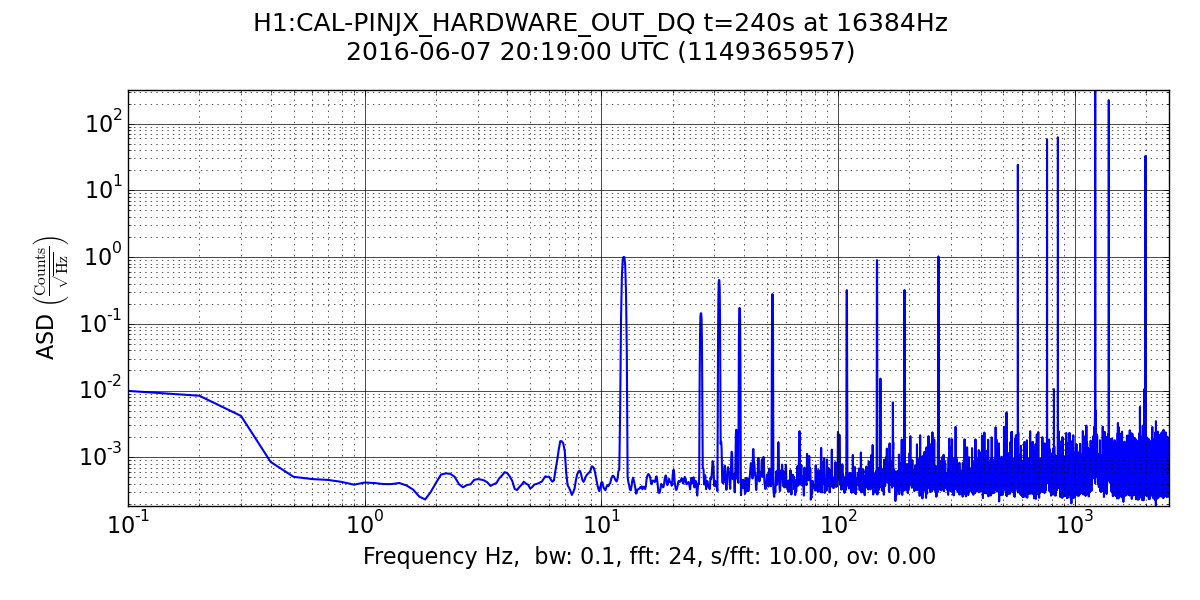
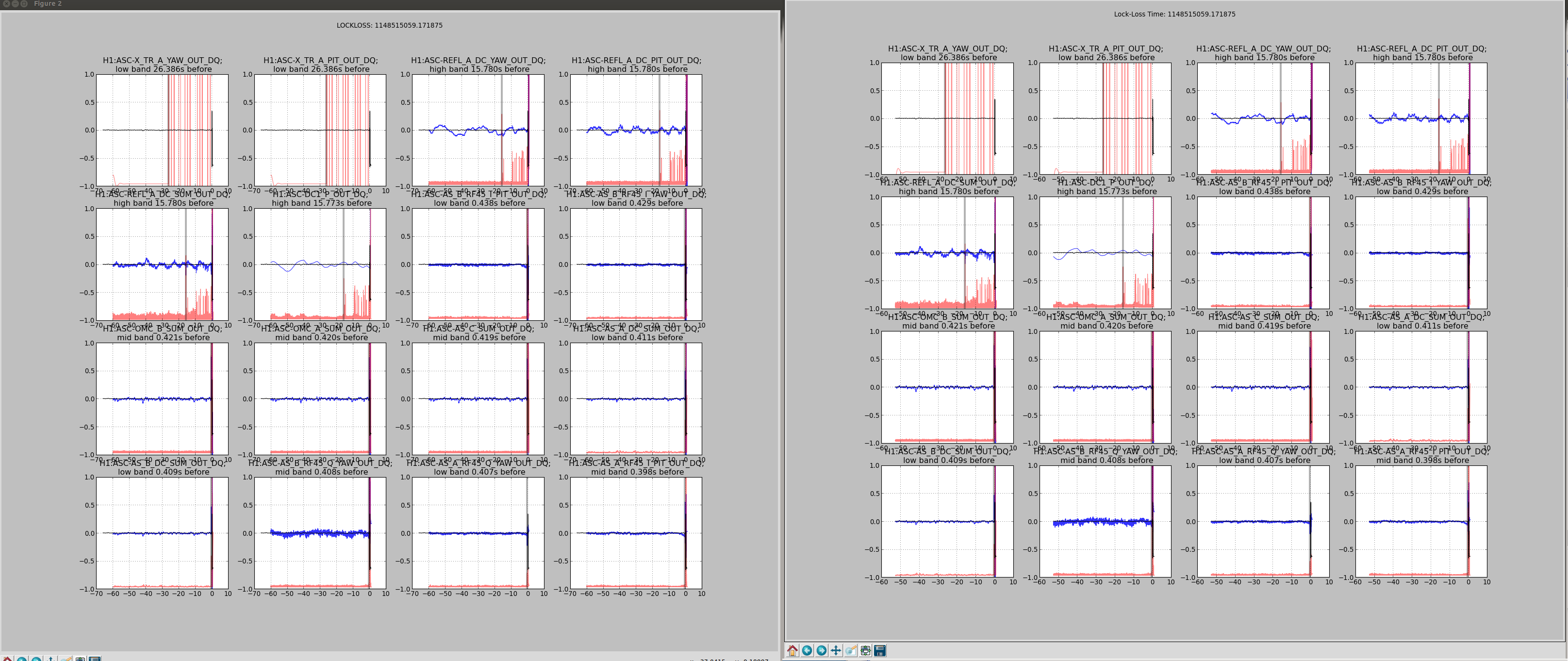
It could be that the RF problem that started in the last few days somehow makes us more senstive to loosing lock because of tiny SR3 glitches, or that the noisemons are just showing some spurious signal which is related to the lockloss/ RF problems. Some lockloss plots are attached.
It seems like the thing to do would be trying to fix the RF problem, but we don't have many ideas for what to do.
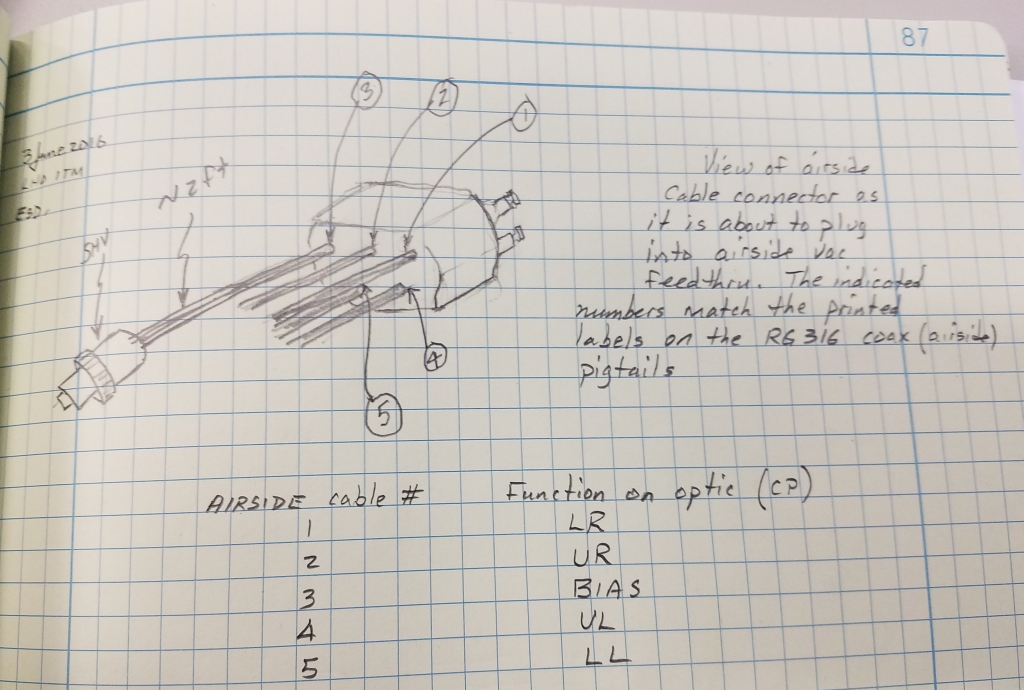













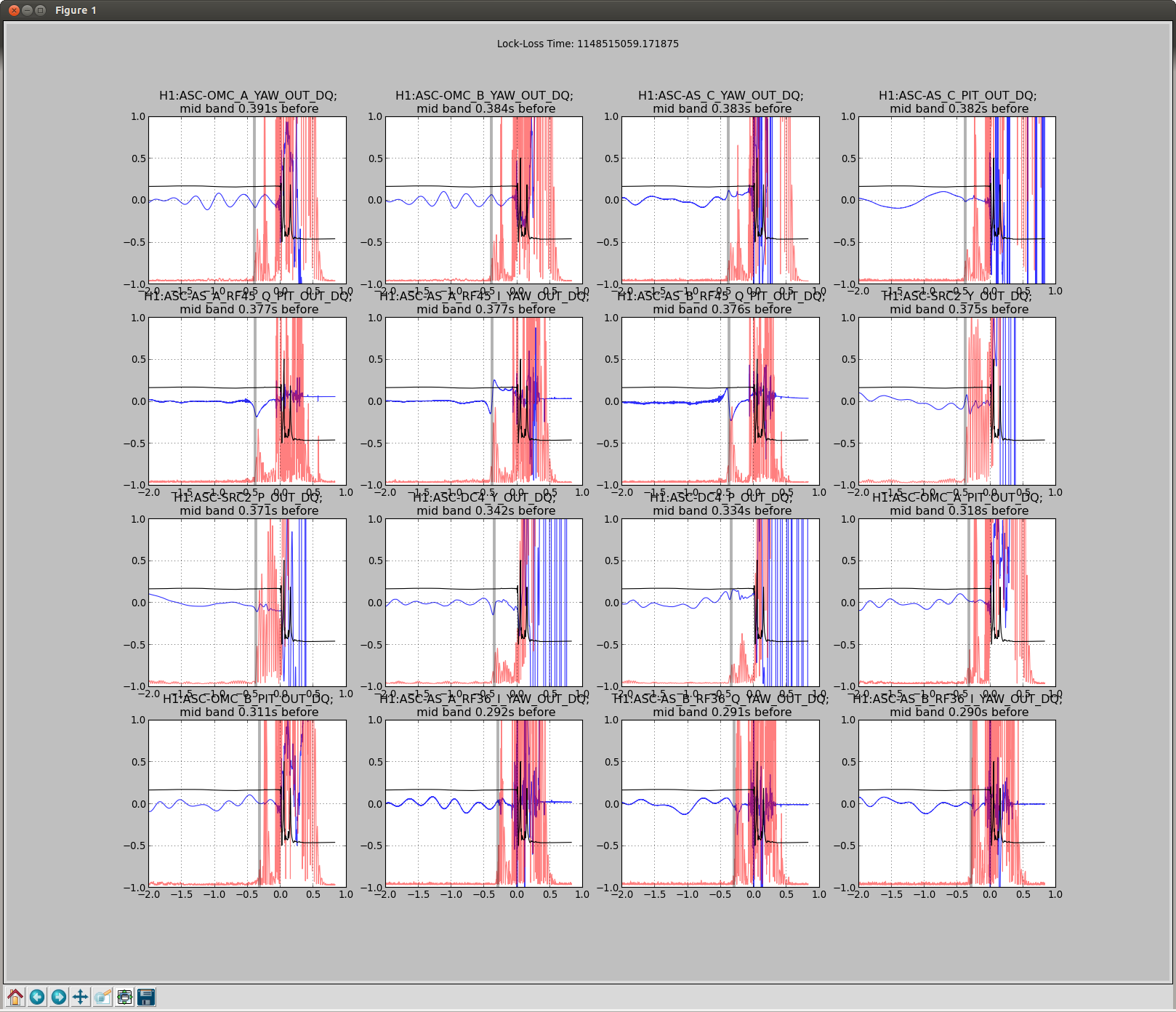
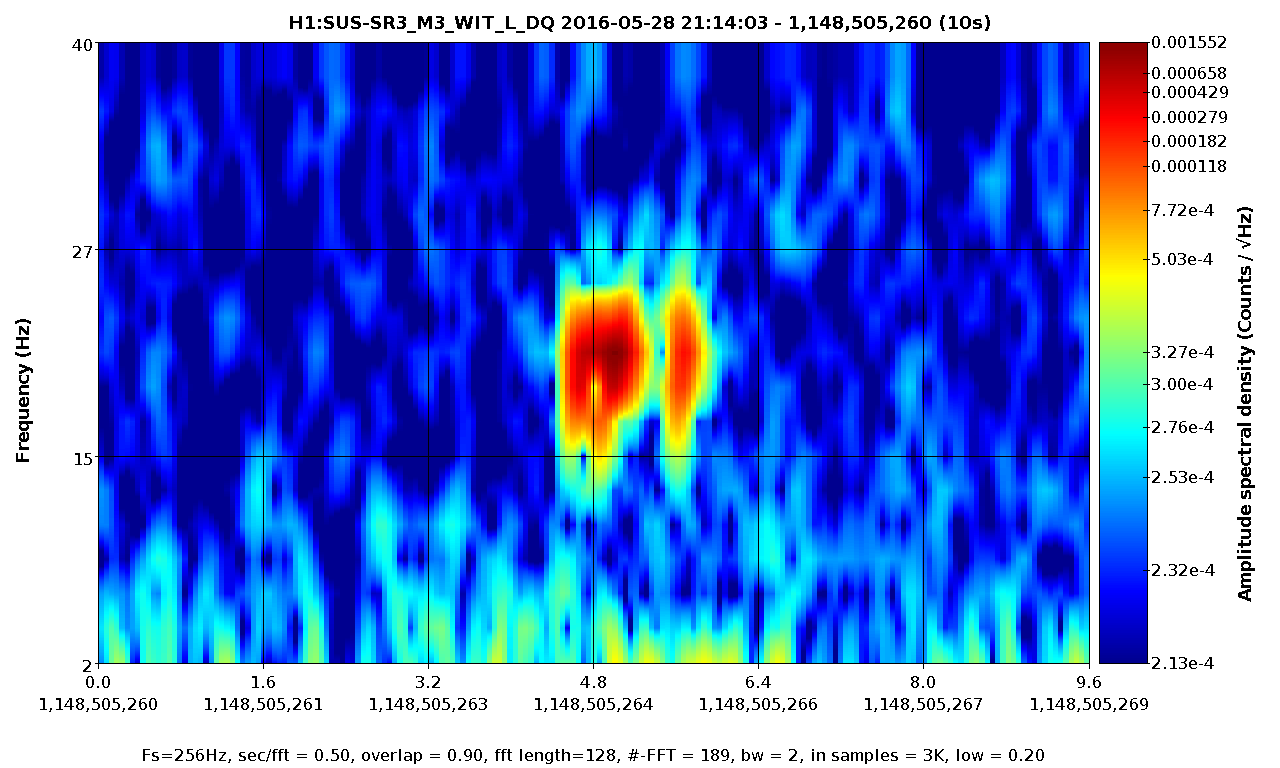
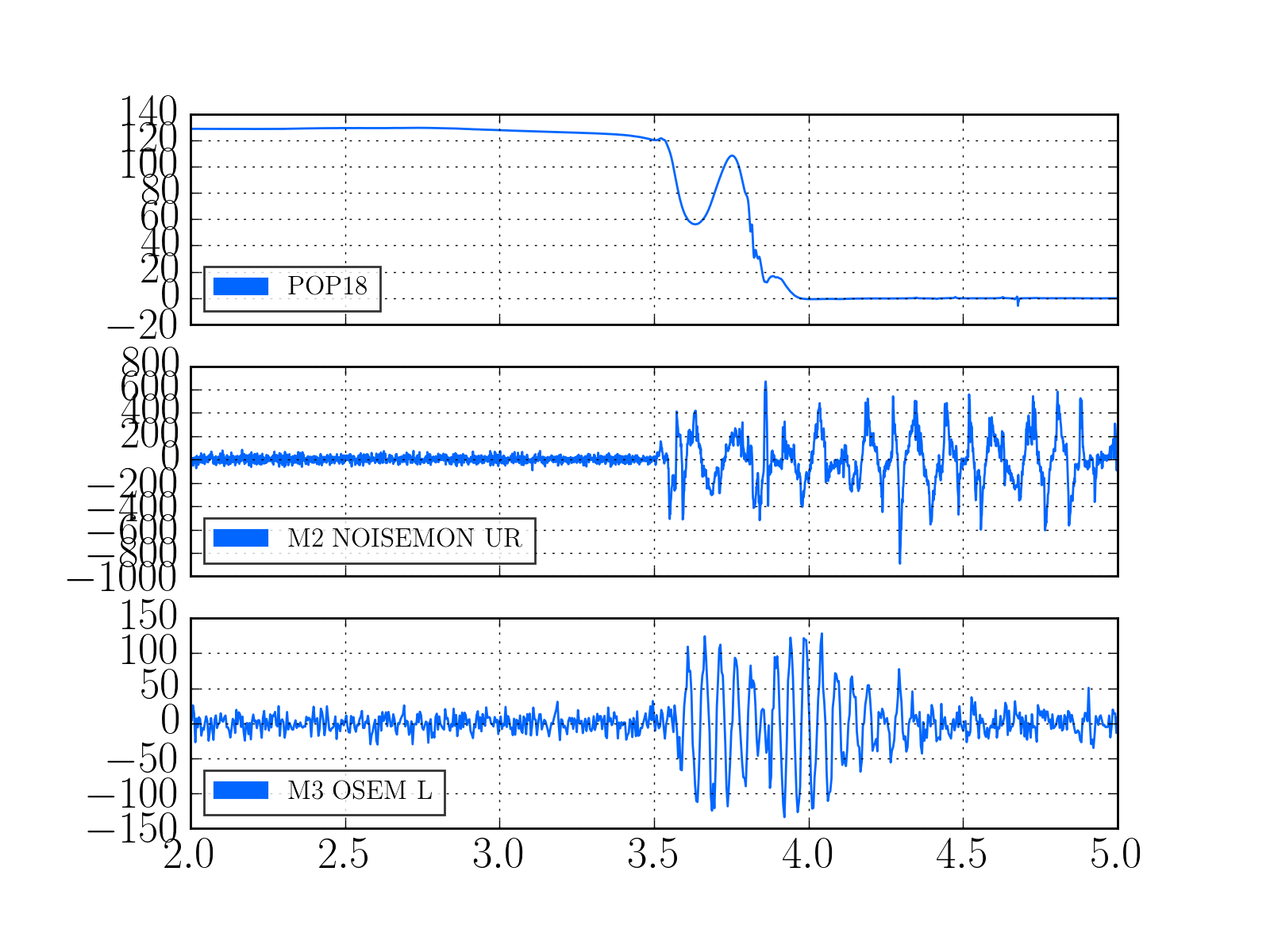
Step 6.3: LVEA Network Switches
This box appeared to be running (green lights & no errors).
Step 6.4 Work Station Computers
Work Stations powered in Control Room-----> But BEFORE these were powered up, The NFS File Server should have been checked in the MSR before powering anything up. This needs to be added to the procedure.
We have found several issues due to computers being started before the NFS File Server was addressed. These items had to be brough up again:
----->And the items above allow us to run Dataviewer now and also bring up the Vacuum Overview
Step 6.5 Wiki & alog & CDS Overview MEDM
They are back. Overview on the wall (thanks, Kissel).
Update: The wiki was actually NOT back since it was started before the NFS File Server was started. So the wiki was restarted.
Sec 8: EX (Richard & TJ)
They have run through the document & are moving on to other outbuildings. On the overview for EX, we see Beckhoff & SUSAUX are back.
Sec 10: MX (Richard & TJ)
Haven't heard from them, but we see that PEMMX is back on the Overview.
Sec 9: EY (Richard & TJ)
This is backonline. So now we can start front ends in the Corner Station!
They are now heading to MY now.....
Sec 11: MY (Richard & TJ)
...but it looks like MY is already back according to the CDS Overview.
STATUS at 10AM (after an hour of going through procedure):
Most of the CDS Overview is GREEN, -except- the LSC. Dave said there were issues with bring the LSC front end back up and will need to investigate in the CER.
End Stations: (TJ, Richard)
7.5 Front Ends (Updated from Kissel)
Everything is looking good on the CDS Overview
Sec 7.8: Guardian (updated from Kissel)
Working on bringing this back. Some of these nodes need data from LDAS (namely, ISC); so some of these may take a while.
BUT, basic nodes such as SUS & SEI may be ready fairly sooner.
7.1 CORNER STATION DC POWER SUPPLIES
These have all been powered ON (Richard).
(Still holding off on End Stations for VAC team to let us know it's ok.)
EY (Richard)
High Power voltage & ESD are back (this step is not in recovery document).
EX (Richard)
High Power voltage & ESD are back (this step is not in recovery document).
There appear to be some order issues here. (Jeff, Nutsinee, and others are working on fixing the order in the document.)
1) We held off on addressing DC high power because of wanting to wait for Vacuum System Team at the LVEA (for vacuum gauge) and at the End Stations (for vacuum gauge & the ESD).
2) We held off on some Corner Station items, because of them being on the Dolphin Network. So to address End Stations FIRST, Assigned Richard & TJ to head out to start the End Station sections of the document & get their Dolphin Network items online. Once they were done, Dave started on cornter station Front Ends on the Dolphin network.
Extraneous items:
Sec 7.6 LVEA HEPI Pump Station Controller
After Hugh's HEPI Maintenance, Jim brought this back.
Sec 8.5 EX HEPI Pump Station Controller
After Hugh's HEPI Maintenance, Jim brought this back.
Sec 9.5 EY HEPI Pump Station Controller
After Hugh's HEPI Maintenance, Jim brought this back.
UPDATE:
At this point (11:42am), we appear to be mostly restored with regard to the CDS side. Most of the operations subsystems are back (we are mostly green on the Ops Overview). The VAC group's Annulus Ion Pumps are back to using site power.
Lingering CDS/Operations items: