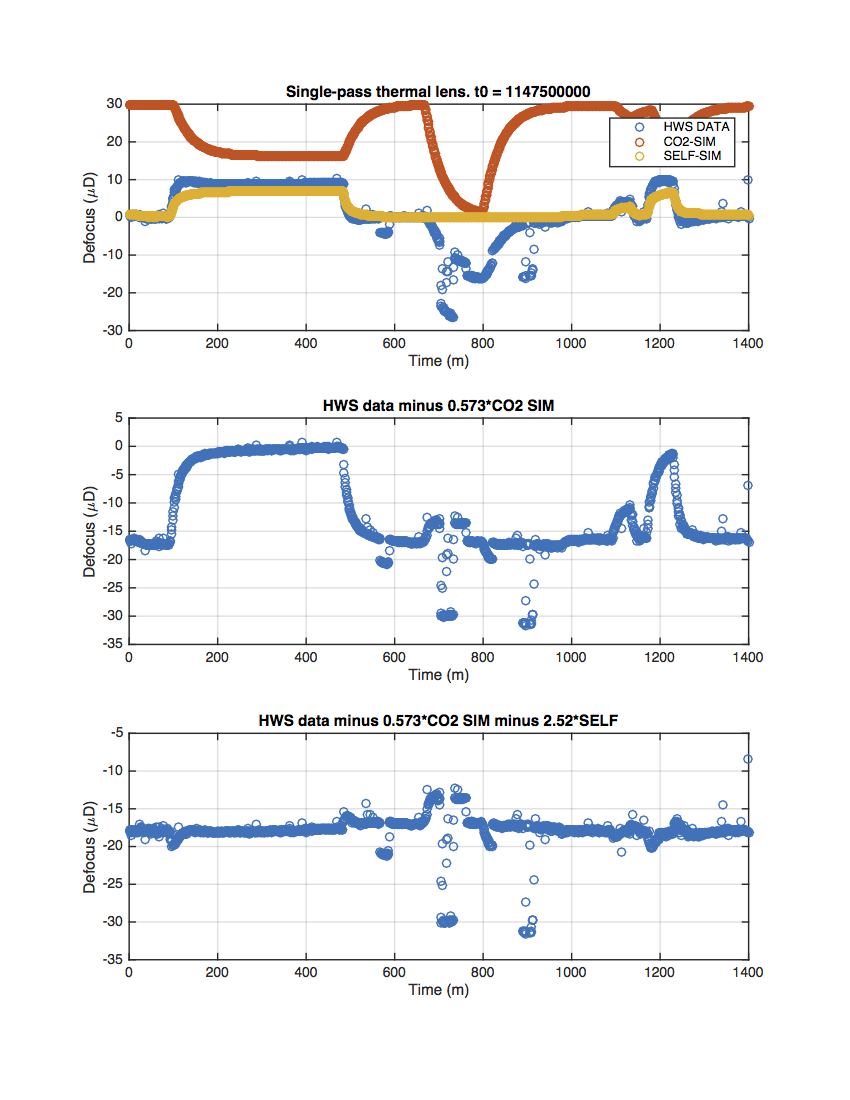
[Corey, Jenne, Kiwamu]
The DC Readout state checks whether the ISS first loop is on or not before allowing the IFO to increase power. However, the state_word value for the ISS isn't matching what is in the guardian (it wants 32700), so it doesn't pass this check. Both the integrator and the autolocker are on, which are the primary things that I thought were required.
Previously, the run state would check the ISS, and if it was okay, check ASC convergence, and then turn off the SRC1 loops. However, since we're not passing the ISS check, I had Corey go to manual mode and request IncreasePower, which ended up skipping the SRC1 turn-off step. This caused our friend the SRM-runs-away lockloss.
So, we have modified the run state of DC readout a little bit so that the ISS and ASC convergence checks are separate if statements, not an if/elif combo. If the ASC is converged, it will turn off the SRC1 loops, regardless of what the ISS is up to. If both the ASC and ISS are happy, it'll return True like normal, and carry on.
Operators: If you are stuck at DC Readout and the guardian log says "ASC converged" but you're getting the message that "ISS first loop may be off", then you should check on the ISS first loop*. If it's okay, then go to manual, and select Increase power. Go back to auto, and select whatever state you were trying to get to.
* I think that the only check for ISS first loop at this state that really needs to happen is that the "First Loop" light in the small blue box under the strip chart on the PSL_ISS screen is green (sorry Jim). This indicates that the integrator is on. If it's yellow, click the "On+Int" button on the ISS manual mode sub-screen. Clicking the "On+Int" button to ensure it's on shouldn't cause any trouble, so you can do that if there's any ambiguity.