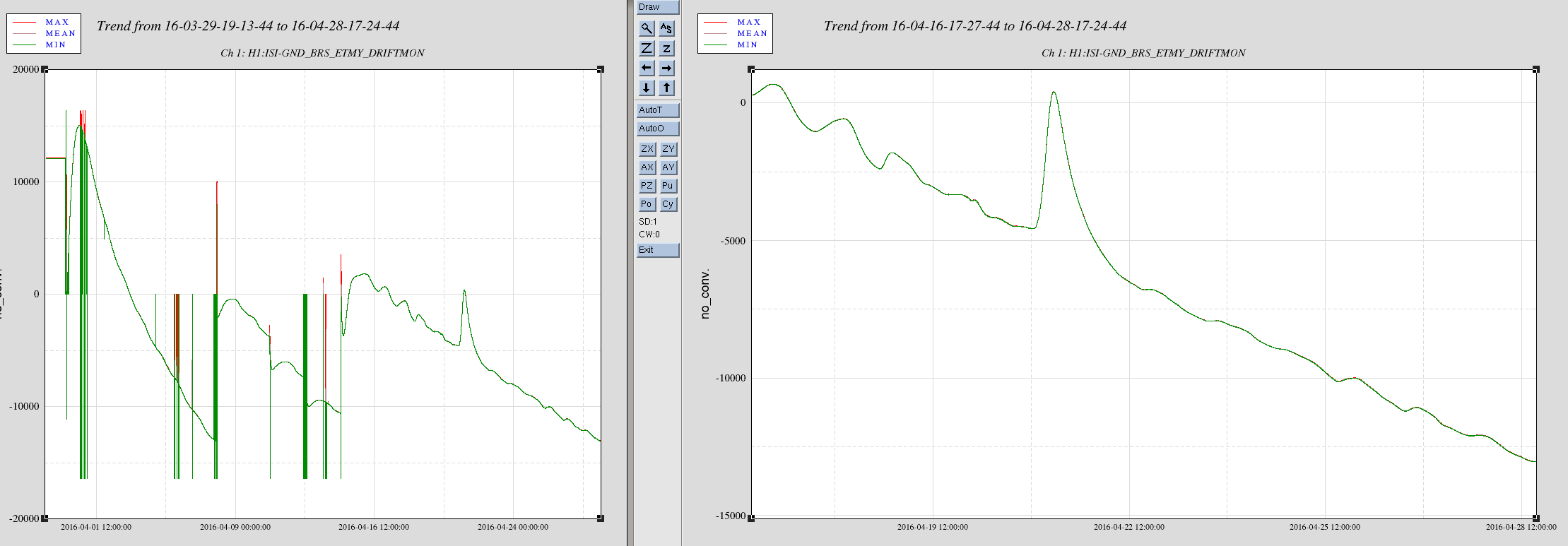
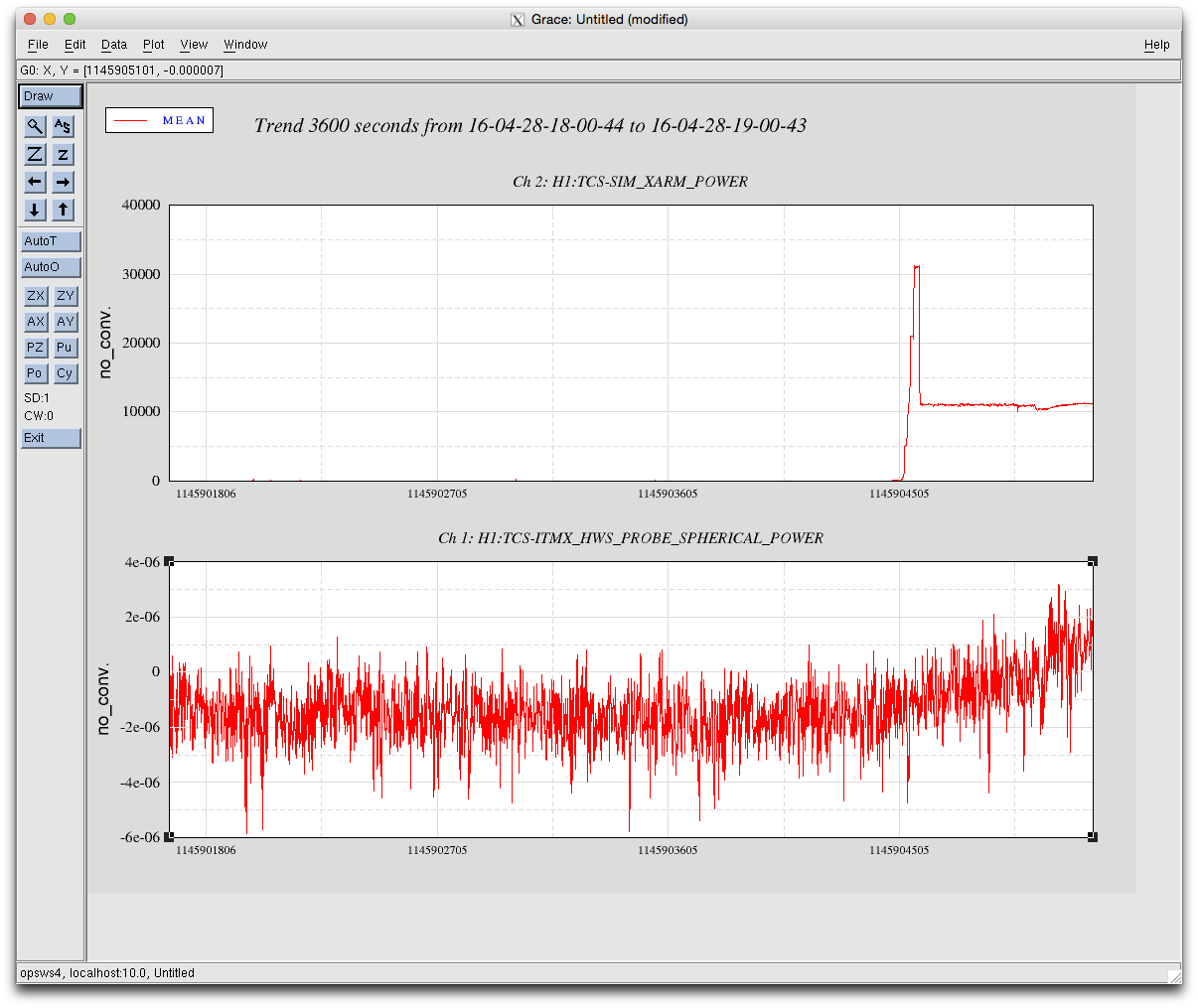
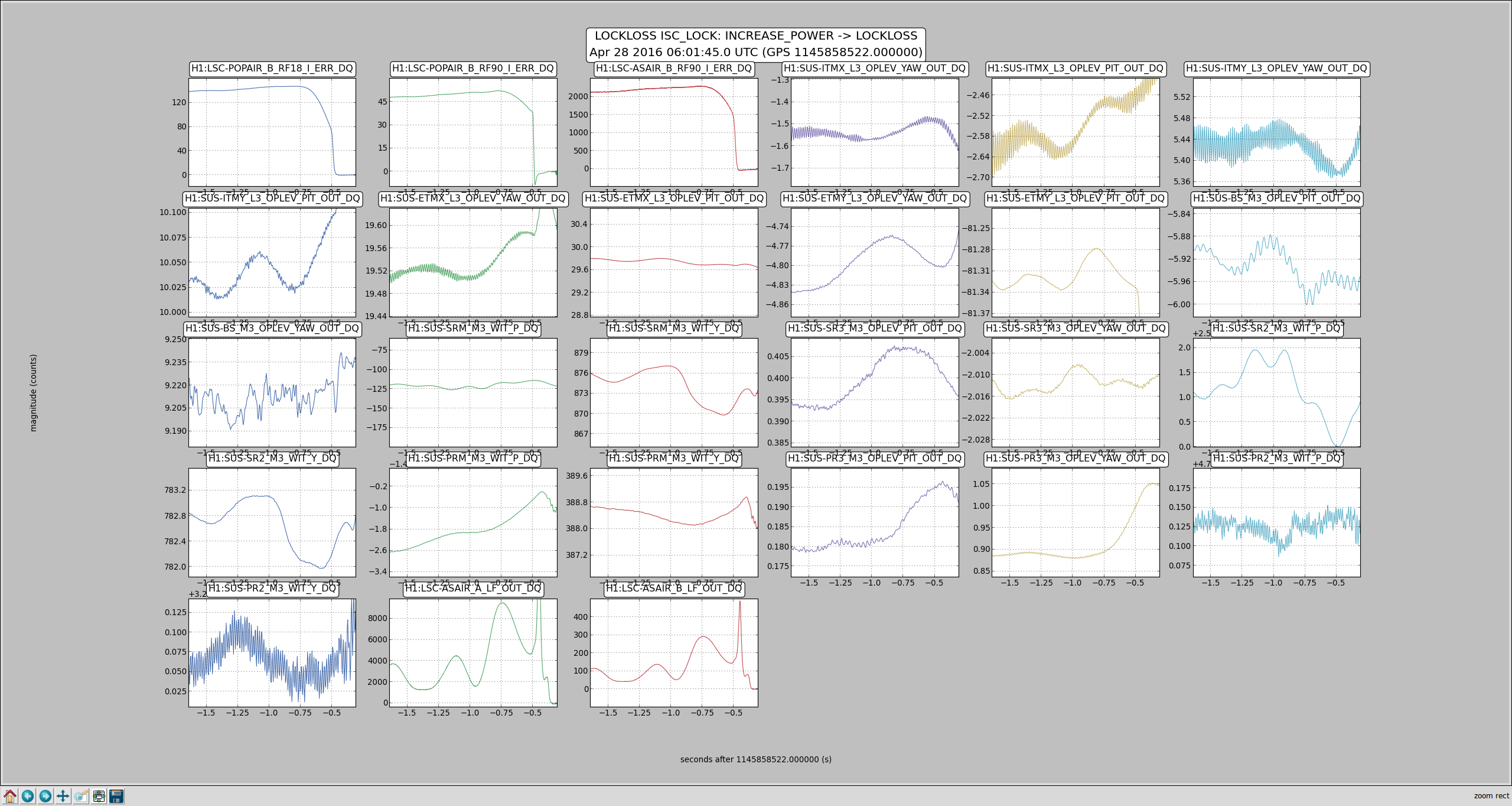
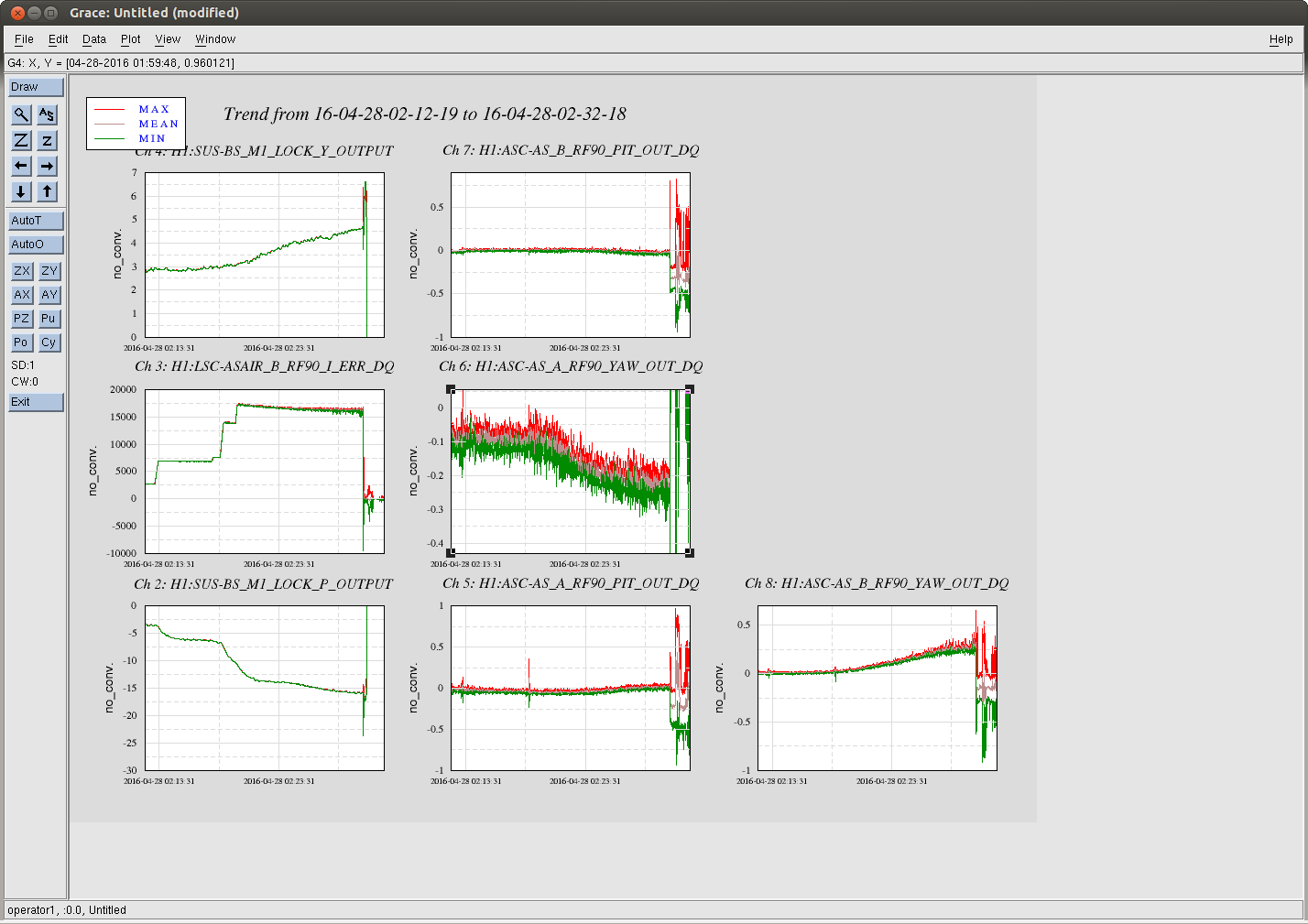
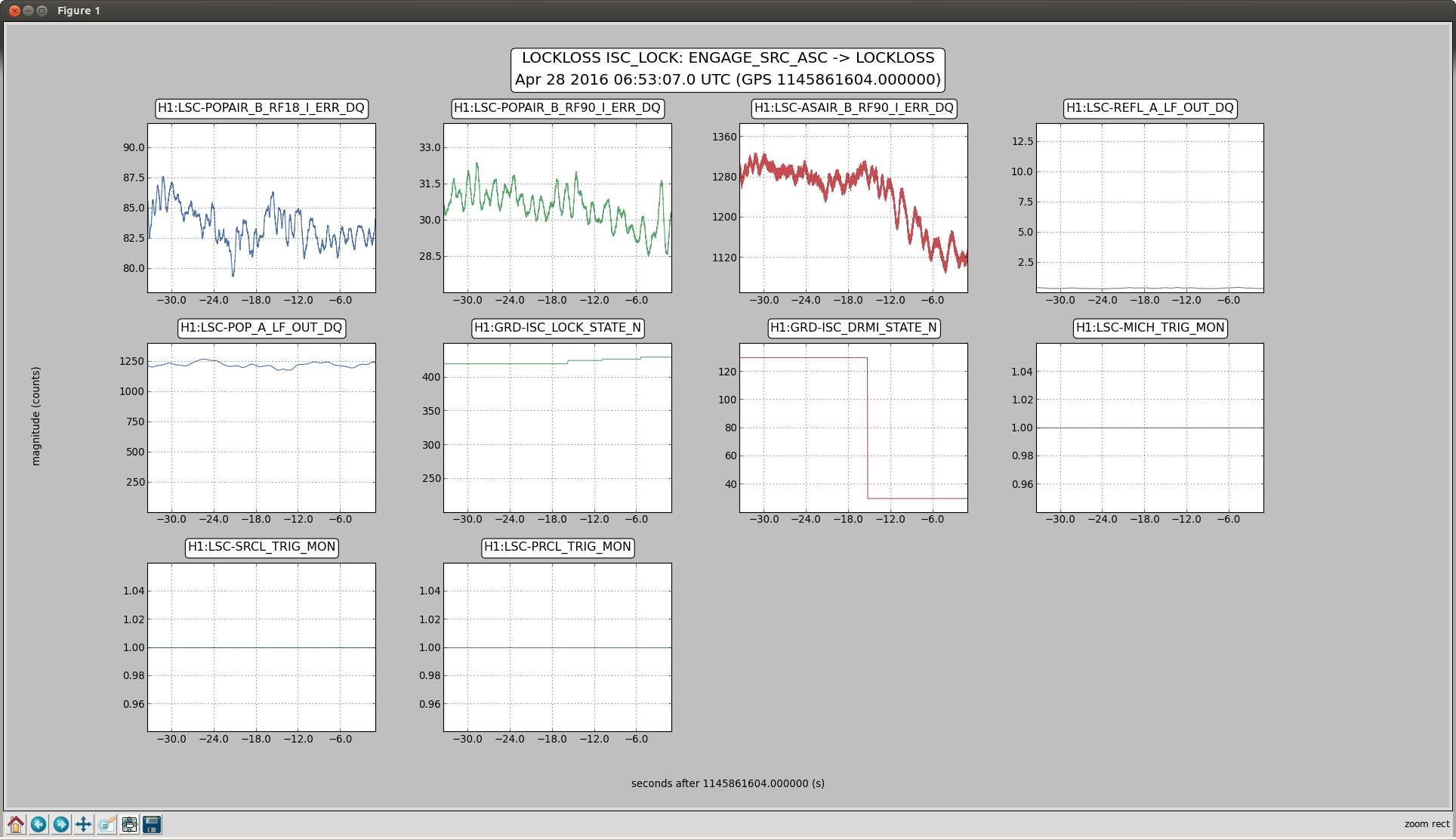
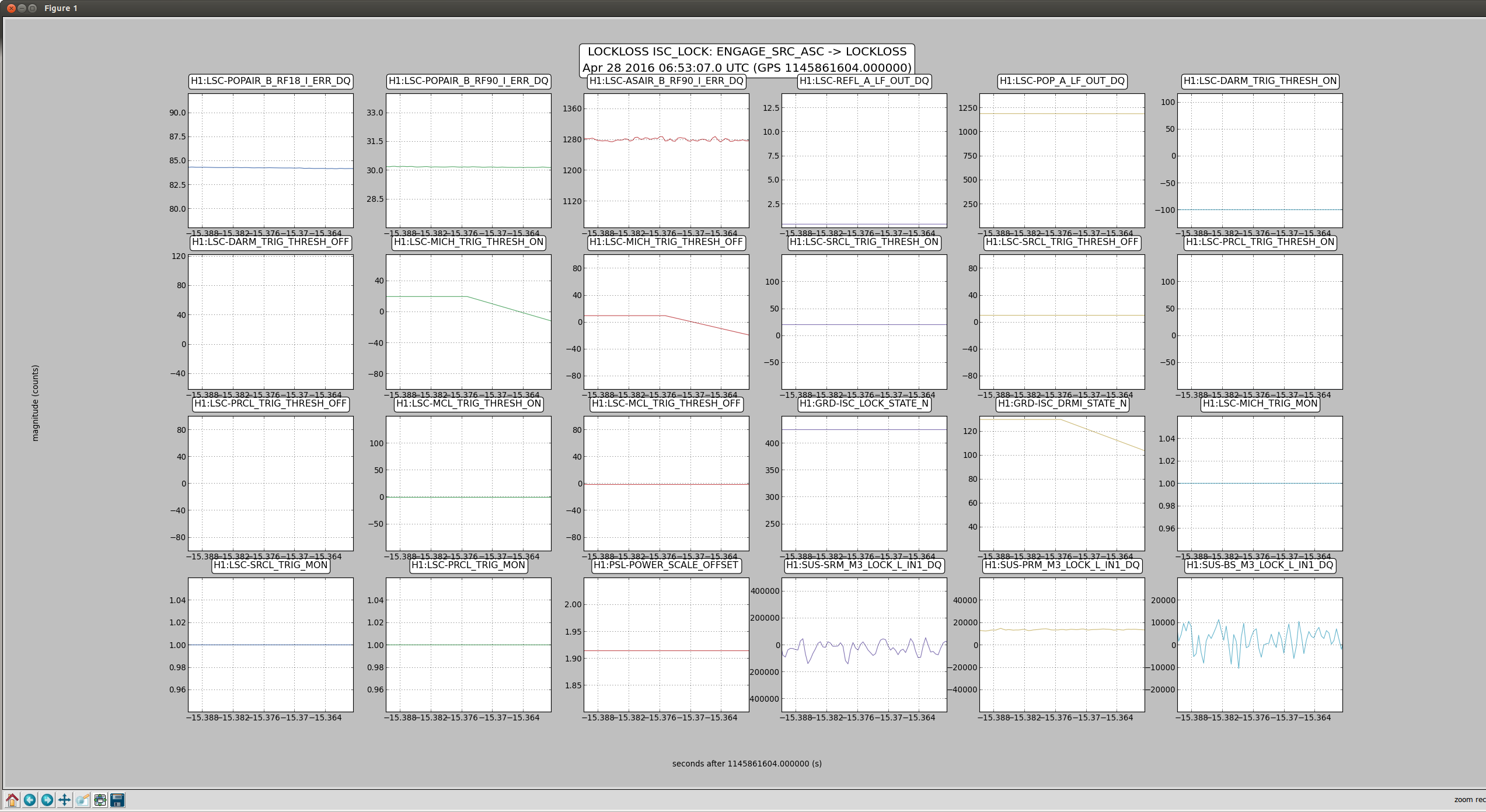
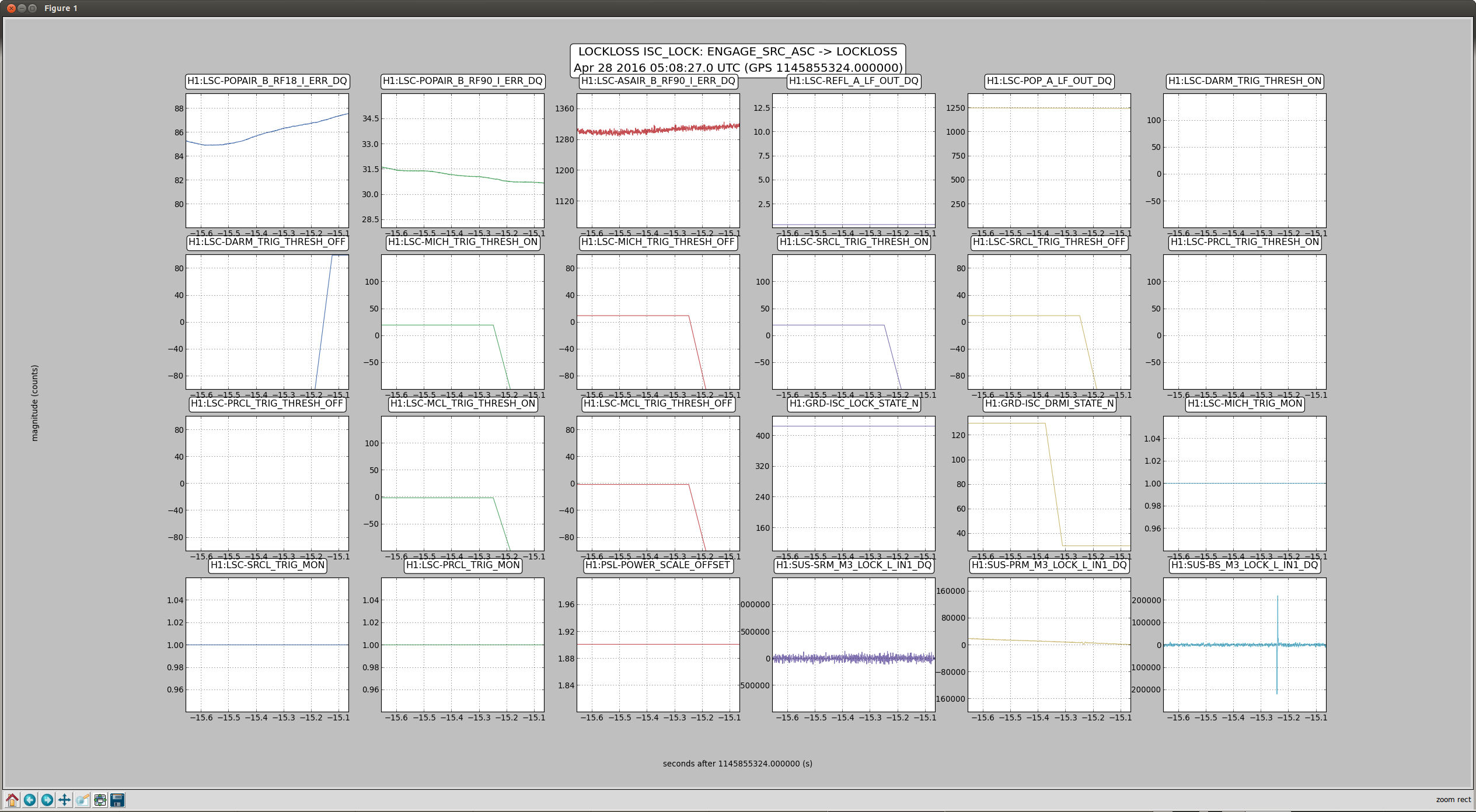
craig.cahillane@LIGO.ORG - posted 10:38, Thursday 28 April 2016 - last comment - 12:57, Thursday 28 April 2016(26847)
All of O1 LHO C02 Spectrograms and GPSTime = 1135136350 Calibration Uncertainty
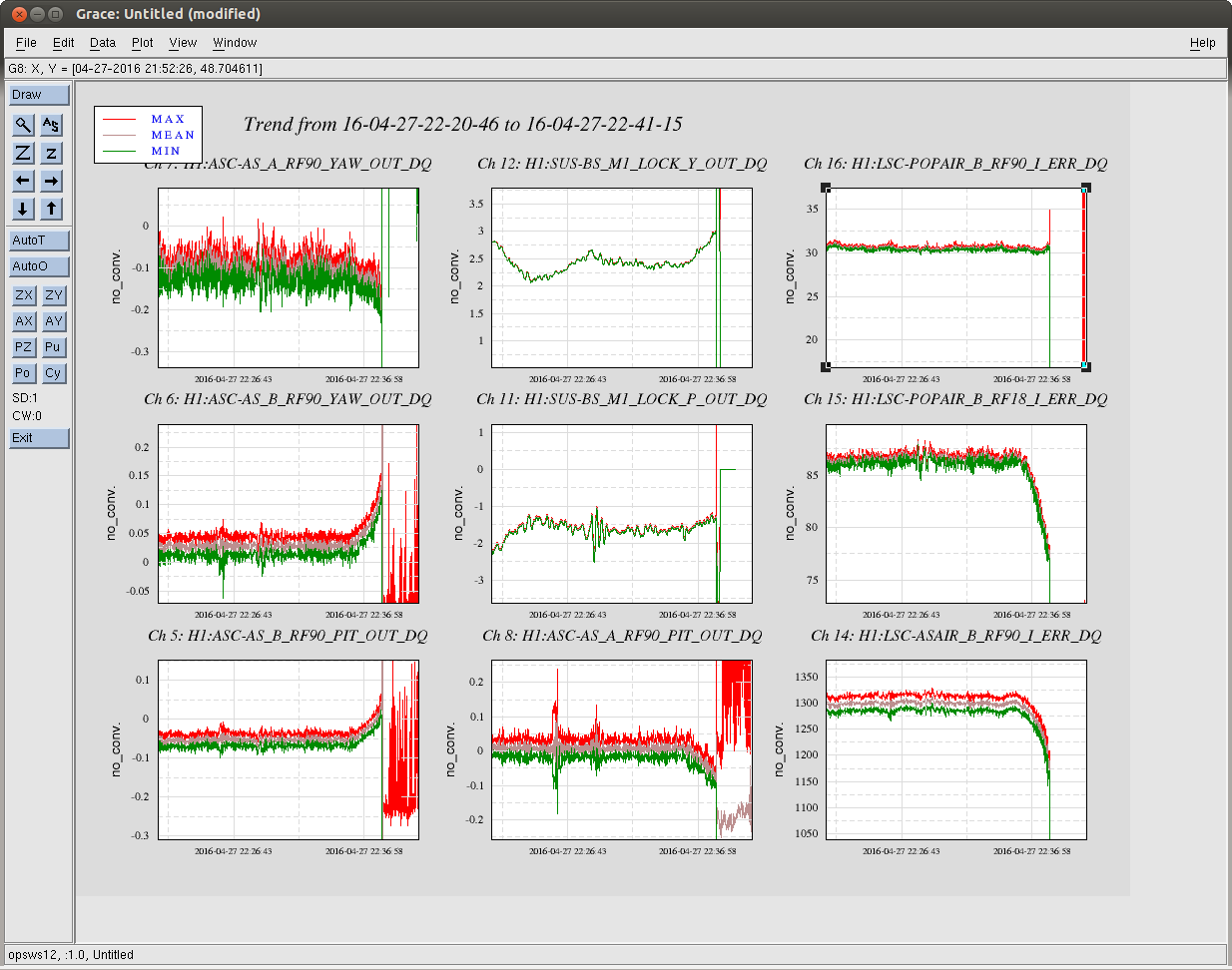
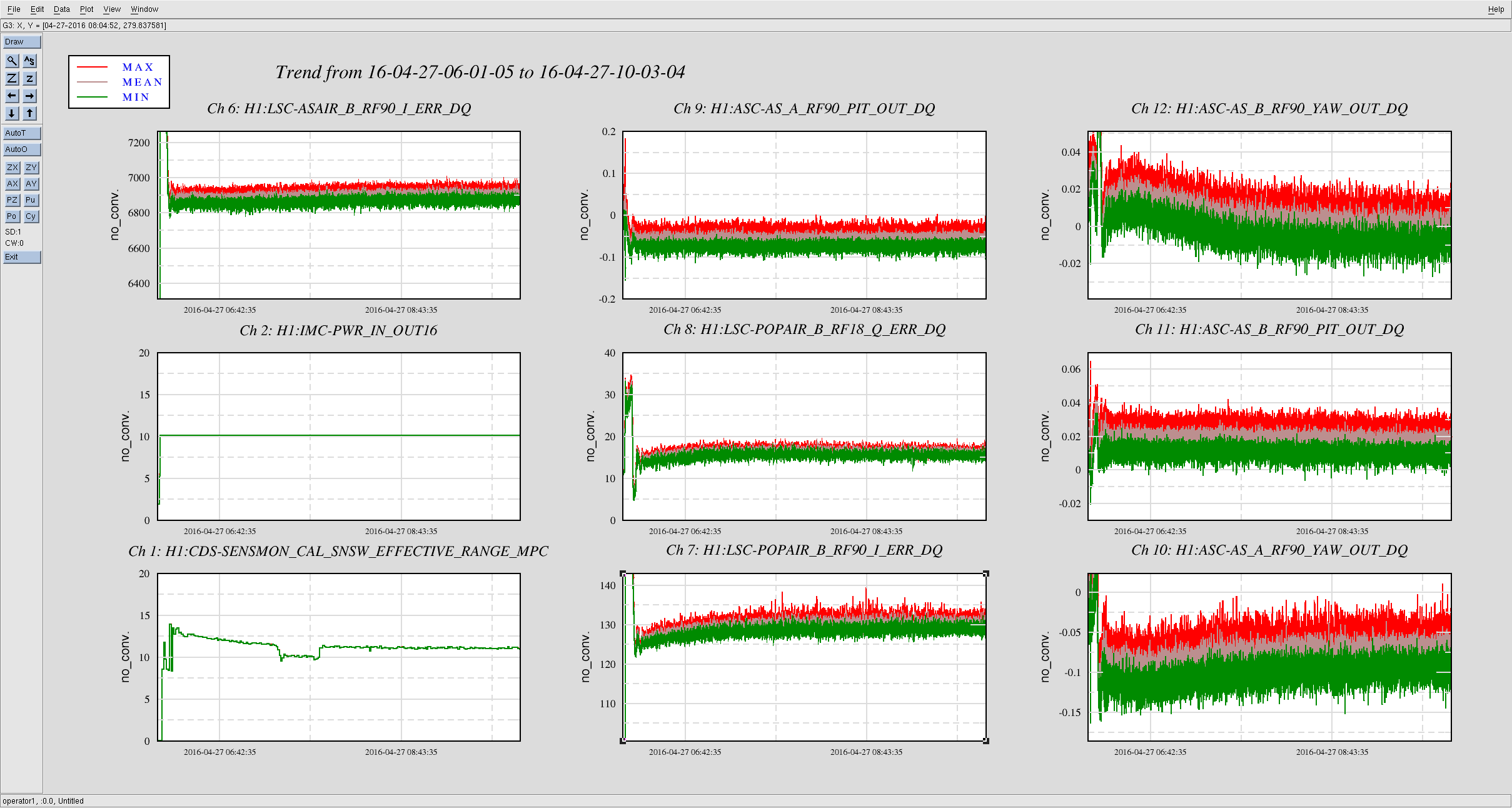
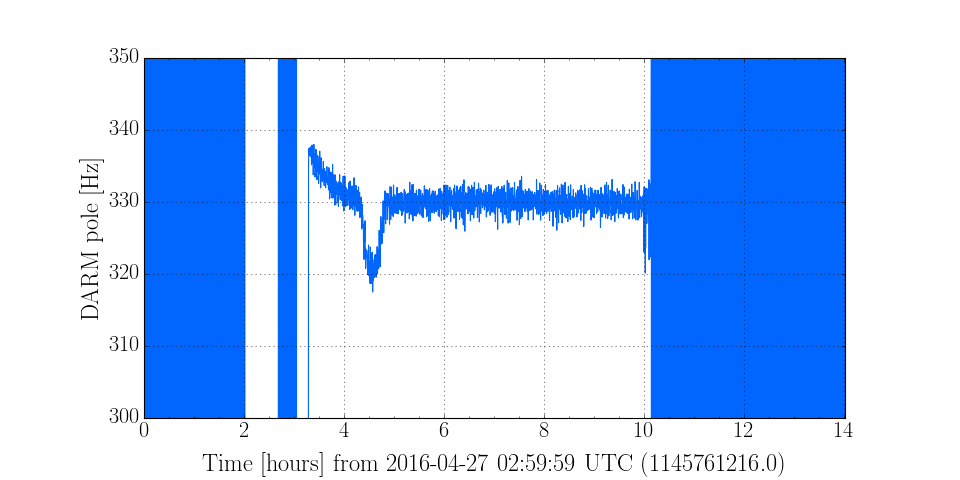
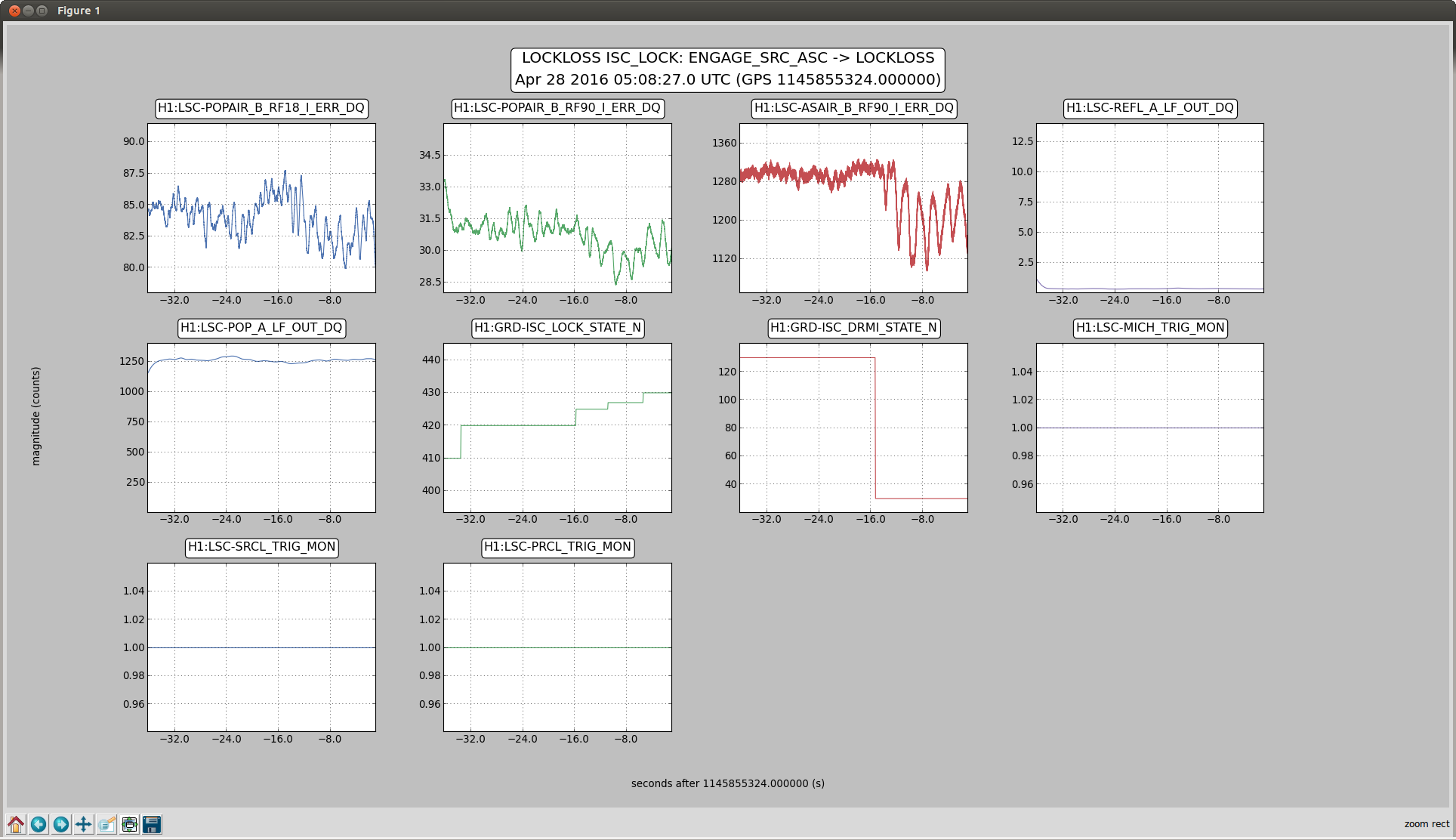
C. Cahillane I have attached remade systematic error and uncertainty spectrograms for all of O1, as well as some a specific calibration at GPSTime = 1135136350. These plots include uncertainty from detrended time-dependent kappas. I have also included the uncertainty components plots for ease of viewing what contributes to uncertainty. For LLO, see LLO aLOG 25914
Non-image files attached to this report

Comments related to this report
C. Cahillane I have also included the .txt files so anyone may make the LHO C02/C03 response function plus uncertainty plots at GPSTime = 1135136350.
Non-image files attached to this comment