Chris, Keita, Evan
Today we were able to lock the outer ISS loop with the modecleaner at 20 W (and no interferometer). We looked at several PSL/IOO PD signals (the FSS transmission PD, the ISS inner-loop PDs, the IM4 transmission PD, and the ISS outer-loop PDs) and tried to understand their behavior in different ISS configurations.
Naively one would expect all these signals (except the in-loop ISS PDs) to agree with each other, since they should all be out-of-loop sensors for the RIN leaving the PMC. Together, these signals monitor three of the four PMC ports: the FSS transmission sees the RIN of one port, the out-of-loop inner-loop ISS PD sees the RIN of another port, and IM4 trans and the out-of-loop outer-loop ISS PD sees the RIN of yet another port.
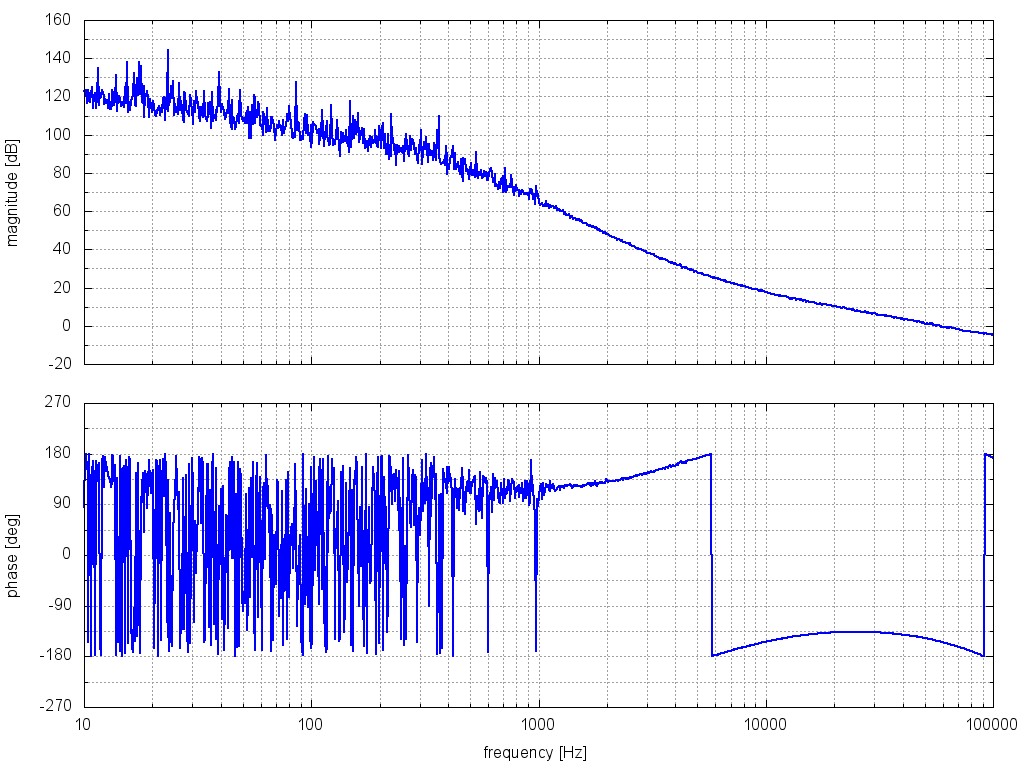
These are the behaviors we observed (see attached pdf):
-
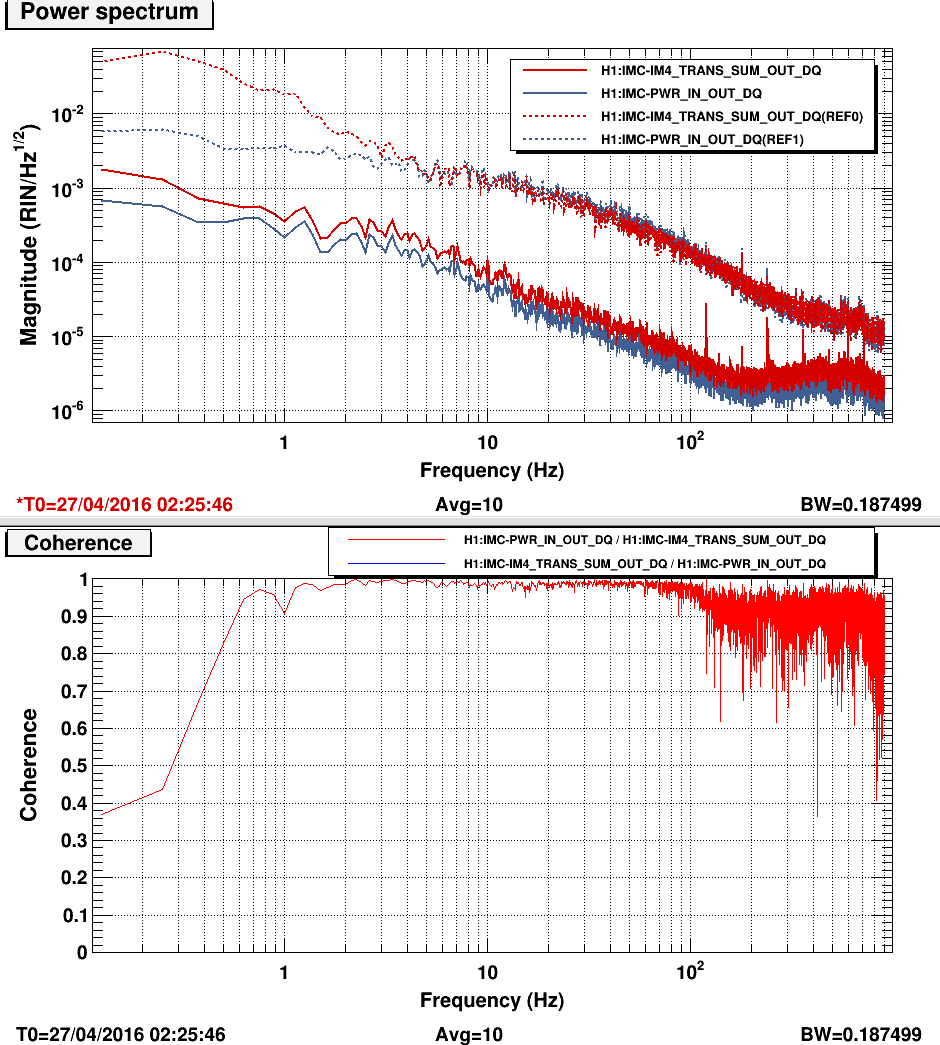
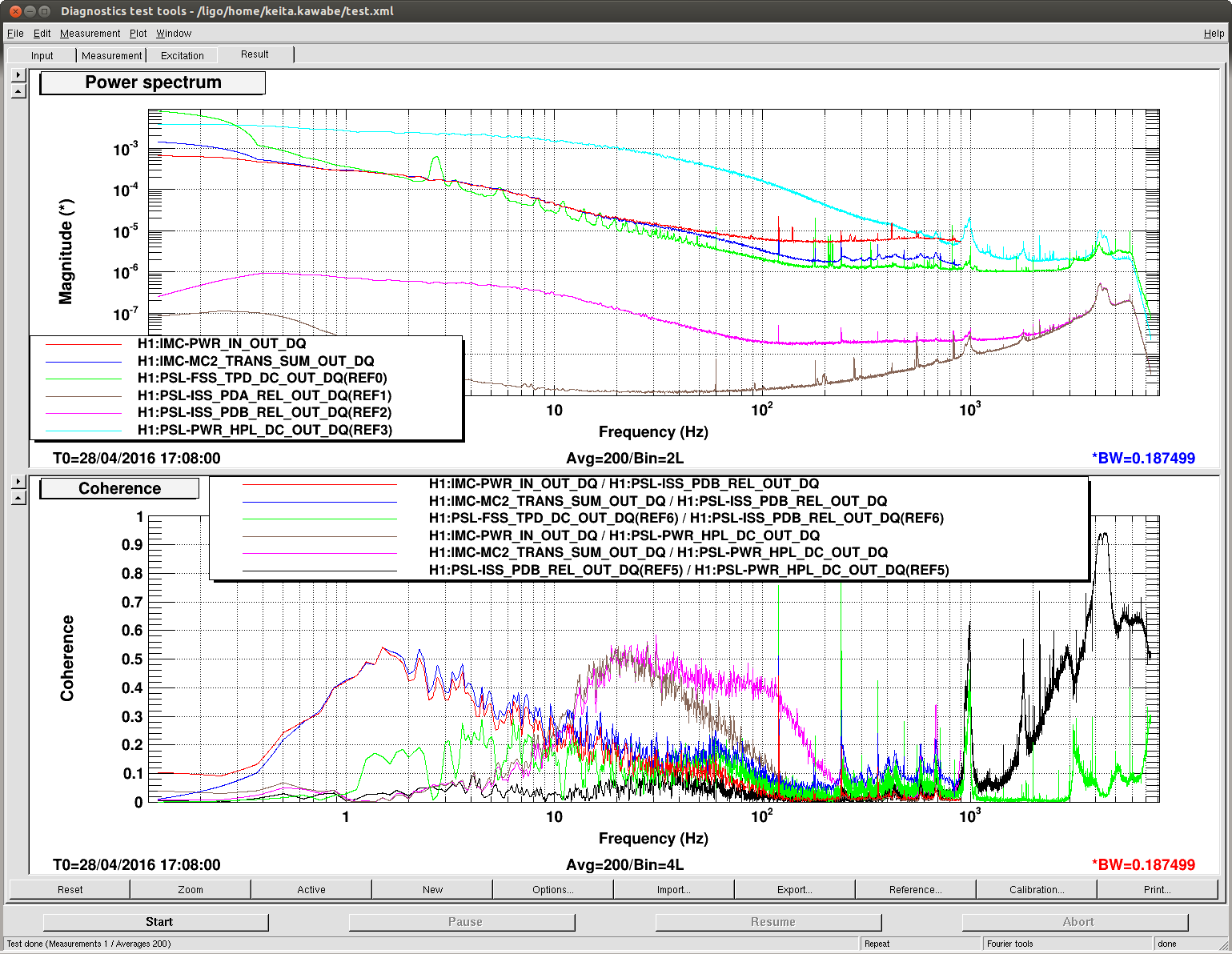
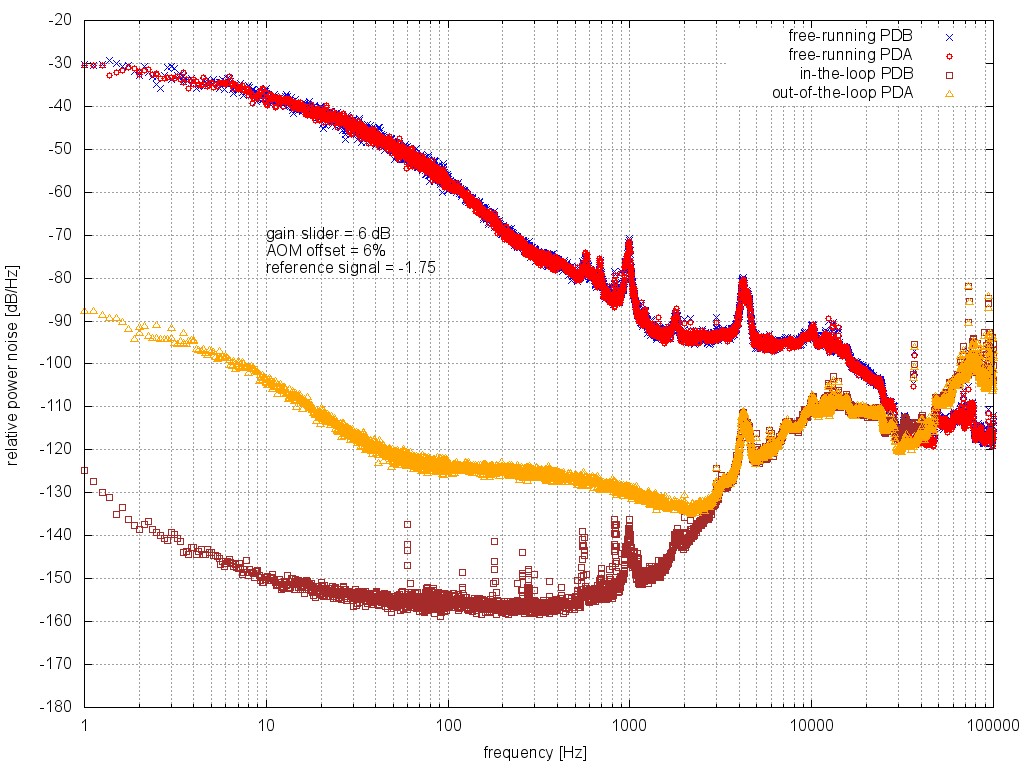
When neither ISS loop is closed, both the FSS and IM4 transmission PDs see the noise of the HPO (about 1×10−3/Hz1/2 at 10 Hz). From 10 to 100 Hz, these PDs are coherent with each other and with the HPO PD. All four of the ISS PDs are swinging rail-to-rail in this configuration, so they are not useful. [Apricot traces.]
-
When the inner ISS loop is closed, the FSS PD, IM4 PD, and outer-loop ISS PDs see a RIN that is a few times 10−5/Hz1/2 at 10 Hz, with a 1/f slope. These three signals are coherent with each other between 10 and 100 Hz. However, the inner-loop PDs are in some parallel universe in which the inner-loop appears to be happily stabilizing the laser RIN to better than 10−6/Hz1/2 at 10 Hz. The inner-loop PD signals have low coherence with the FSS, IM4, or outer-loop PDs between 10 and 100 Hz. [Red and blue traces.]
-
When the inner and outer ISS loops are closed, the outer-loop PDs seem to behave sensibly. The out-of-loop RIN is slightly better than 10−7/Hz1/2 at 10 Hz. The IM4 PD more or less agrees. However, the FSS RIN seems to show no change from the previous measurement (inner ISS loop only), and no longer has very much coherence with the IM4 and outer-loop PDs. The FSS has some coherence above 100 Hz with the outer-loop PDs. The inner-loop PDs now see the 1/f RIN of the FSS PD, and they are coherent with this PD. [Purple and green traces.]
We think that a possible explanation for these effects is that both ISS PDs are seeing some correlated noise that is not seen by either the FSS PD or the post-IMC PDs. In this scenario, the inner-loop ISS would suppress the HPO noise but impress this correlated noise on the light entering the PMC.
Briefly we entertained the idea that the light circulating in the PMC could be multimoded (either from the NPRO or the HPO), but judging from the RIN before and after the IMC, this seems to not be the case (png attachment).
One other idea is that some of the 808 nm light is getting through the PMC and onto the ISS.