[Aidan, Cao]
In the online TCS simulation, I updated the absorption coefficients for ITMX, ETMX and ETMY to reflect actual measured values: https://dcc.ligo.org/LIGO-T1400685
- H1:TCS-SIM_XARM_POWER_WATTS_PER_INPUT_UNIT 2.606
- H1:TCS-SIM_YARM_POWER_WATTS_PER_INPUT_UNIT 2.378
- ETMY_SURF_ABSORPTION: 253E-9
- ETMX_SURF_ABSORPTION: 160E-9
- ITMX_SURF_ABSORPTION: 520E-9
-
H1:TCS-SIM_ITMX_SURF_ABSORPTION 520E-9 # alog 16578caput H1:TCS-SIM_ITMX_SURF_ABSORPTION 520E-9 # alog 16578caput H1:TCS-SIM_ITMY_SURF_ABSORPTION 250E-9caput H1:TCS-SIM_ETMX_SURF_ABSORPTION 160E-9 # aLOG 19867caput H1:TCS-SIM_ETMY_SURF_ABSORPTION 253E-9 # aLOG 19835
Additionally, I rescaled the TR_X and TR_Y values to reflect the arm powers, courtesy of some calibration work from Cao.
I have a script (copied below) I've been using to update these values as this allows me to store references to measurements and calibrations.
load_IFO_SIM_COEFFICIENTS.sh
caput H1:TCS-SIM_IFO_XARM_LENGTH 3994.47 # aLOG 20149
caput H1:TCS-SIM_IFO_YARM_LENGTH 3994.47
caput H1:TCS-SIM_IFO_SILICA_REF_INDEX 1.44963 #Suprasil 3001, "Heraeus reports 1.44963 as the index at 1064", GLB email Sept 5, 2014
caput H1:TCS-SIM_XARM_POWER_WATTS_PER_INPUT_UNIT 2.606 # estimate of peak value of 105.9kW in arms (needs ref) between 1141200000 and 1141300000 coupled with measurements of TR
_X
caput H1:TCS-SIM_YARM_POWER_WATTS_PER_INPUT_UNIT 2.378
caput H1:TCS-SIM_IFO_cdsMuxMatrix1_1_1 0.5
caput H1:TCS-SIM_IFO_cdsMuxMatrix1_1_2 0.5
caput H1:TCS-SIM_IFO_cdsMuxMatrix1_2_1 1.0
caput H1:TCS-SIM_IFO_cdsMuxMatrix1_2_2 -1.0
# PRC BLOCK
caput H1:TCS-SIM_IFO_PRC_ITM_R3 24.3931 #T0900043-v11, Table 1
caput H1:TCS-SIM_IFO_PRC_R3_R2 16.1558
caput H1:TCS-SIM_IFO_PRC_R2_RM 16.6037
caput H1:TCS-SIM_IFO_PRC_R3_ROC 36.021 # https://galaxy.ligo.caltech.edu/optics/ PR3-01
caput H1:TCS-SIM_IFO_PRC_R2_ROC -4.543 # https://galaxy.ligo.caltech.edu/optics/ PR2-04
caput H1:TCS-SIM_IFO_PRC_RM_ROC -10.948 # https://galaxy.ligo.caltech.edu/optics/ PRM-04
# SRC BLOCK
caput H1:TCS-SIM_IFO_SRC_ITM_R3 24.1176 #T0900043-v11, Table 1
caput H1:TCS-SIM_IFO_SRC_R3_R2 15.4607
caput H1:TCS-SIM_IFO_SRC_R2_RM 15.726
caput H1:TCS-SIM_IFO_SRC_R3_ROC 36.013 # https://galaxy.ligo.caltech.edu/optics/ SR3-02
caput H1:TCS-SIM_IFO_SRC_R2_ROC -6.424 # https://galaxy.ligo.caltech.edu/optics/ SR2-04
caput H1:TCS-SIM_IFO_SRC_RM_ROC -5.638 # https://galaxy.ligo.caltech.edu/optics/ SRM-05 ????? - CHECK
# SPRING CONSTANTS
caput H1:TCS-SIM_IFO_YARM_PEND_SPR_CNST 1.0 # ??????
caput H1:TCS-SIM_IFO_XARM_PEND_SPR_CNST 1.0 # ??????
# ACOS PRC BLOCK
caput H1:TCS-SIM_IFO_ACOS_PRC_A_D_OFFSET 0.87
caput H1:TCS-SIM_IFO_ACOS_PRC_A_D_A0 0.5155940062460905
caput H1:TCS-SIM_IFO_ACOS_PRC_A_D_A1 -2.0281847857870914
caput H1:TCS-SIM_IFO_ACOS_PRC_A_D_A2 -3.6292076586482307
caput H1:TCS-SIM_IFO_ACOS_PRC_A_D_A3 -14.378615634122346
caput H1:TCS-SIM_IFO_ACOS_PRC_A_D_A4 -69.29856186065047
caput H1:TCS-SIM_IFO_ACOS_PRC_A_D_A5 -373.821577053177
# ACOS SRC BLOCK
caput H1:TCS-SIM_IFO_ACOS_SRC_A_D_OFFSET 0.87
caput H1:TCS-SIM_IFO_ACOS_SRC_A_D_A0 0.5155940062460905
caput H1:TCS-SIM_IFO_ACOS_SRC_A_D_A1 -2.0281847857870914
caput H1:TCS-SIM_IFO_ACOS_SRC_A_D_A2 -3.6292076586482307
caput H1:TCS-SIM_IFO_ACOS_SRC_A_D_A3 -14.378615634122346
caput H1:TCS-SIM_IFO_ACOS_SRC_A_D_A4 -69.29856186065047
caput H1:TCS-SIM_IFO_ACOS_SRC_A_D_A5 -373.821577053177
# ACOS YARM BLOCK
caput H1:TCS-SIM_IFO_ACOS_XARM_SQRT_G_OFFSET 0.87
caput H1:TCS-SIM_IFO_ACOS_XARM_SQRT_G_A0 0.5155940062460905
caput H1:TCS-SIM_IFO_ACOS_XARM_SQRT_G_A1 -2.0281847857870914
caput H1:TCS-SIM_IFO_ACOS_XARM_SQRT_G_A2 -3.6292076586482307
caput H1:TCS-SIM_IFO_ACOS_XARM_SQRT_G_A3 -14.378615634122346
caput H1:TCS-SIM_IFO_ACOS_XARM_SQRT_G_A4 -69.29856186065047
caput H1:TCS-SIM_IFO_ACOS_XARM_SQRT_G_A5 -373.821577053177
# ACOS XARM BLOCK
caput H1:TCS-SIM_IFO_ACOS_YARM_SQRT_G_OFFSET 0.87
caput H1:TCS-SIM_IFO_ACOS_YARM_SQRT_G_A0 0.5155940062460905
caput H1:TCS-SIM_IFO_ACOS_YARM_SQRT_G_A1 -2.0281847857870914
caput H1:TCS-SIM_IFO_ACOS_YARM_SQRT_G_A2 -3.6292076586482307
caput H1:TCS-SIM_IFO_ACOS_YARM_SQRT_G_A3 -14.378615634122346
caput H1:TCS-SIM_IFO_ACOS_YARM_SQRT_G_A4 -69.29856186065047
caput H1:TCS-SIM_IFO_ACOS_YARM_SQRT_G_A5 -373.821577053177
# OPTICS gains
caput H1:TCS-SIM_ITMX_SUB_DEFOCUS_RH_GAIN -9.0E-6
caput H1:TCS-SIM_ITMY_SUB_DEFOCUS_RH_GAIN -9.0E-6
caput H1:TCS-SIM_ETMX_SUB_DEFOCUS_RH_GAIN -9.0E-6
caput H1:TCS-SIM_ETMY_SUB_DEFOCUS_RH_GAIN -9.0E-6
caput H1:TCS-SIM_ITMX_SUB_DEFOCUS_CO2_GAIN 62.3E-6
caput H1:TCS-SIM_ITMY_SUB_DEFOCUS_CO2_GAIN 62.3E-6
caput H1:TCS-SIM_ITMX_SUB_DEFOCUS_SELF_GAIN 4.8709E-4
caput H1:TCS-SIM_ITMY_SUB_DEFOCUS_SELF_GAIN 4.8709E-4
caput H1:TCS-SIM_ETMX_SUB_DEFOCUS_SELF_GAIN 3.8577E-4
caput H1:TCS-SIM_ETMY_SUB_DEFOCUS_SELF_GAIN 3.8577E-4
caput H1:TCS-SIM_ITMX_SURF_DEFOCUS_RH_GAIN 1.066E-6
caput H1:TCS-SIM_ITMY_SURF_DEFOCUS_RH_GAIN 1.066E-6
caput H1:TCS-SIM_ETMX_SURF_DEFOCUS_RH_GAIN 1.066E-6
caput H1:TCS-SIM_ETMY_SURF_DEFOCUS_RH_GAIN 1.066E-6
caput H1:TCS-SIM_ITMX_SURF_DEFOCUS_SELF_GAIN -3.652E-5
caput H1:TCS-SIM_ITMY_SURF_DEFOCUS_SELF_GAIN -3.652E-5
caput H1:TCS-SIM_ETMX_SURF_DEFOCUS_SELF_GAIN -2.931E-5
caput H1:TCS-SIM_ETMY_SURF_DEFOCUS_SELF_GAIN -2.931E-5
caput H1:TCS-SIM_ITMX_SURF_ROC_NOM 1939.3
caput H1:TCS-SIM_ITMY_SURF_ROC_NOM 1939.2
caput H1:TCS-SIM_ETMX_SURF_ROC_NOM 2241.54
caput H1:TCS-SIM_ETMY_SURF_ROC_NOM 2238.9
caput H1:TCS-SIM_ITMX_SUB_DEFOCUS_STATIC -1.2467E-5
caput H1:TCS-SIM_ITMY_SUB_DEFOCUS_STATIC 1.7479E-6
caput H1:TCS-SIM_ITMX_SURF_ABSORPTION 520E-9 # alog 16578
caput H1:TCS-SIM_ITMY_SURF_ABSORPTION 250E-9
caput H1:TCS-SIM_ETMX_SURF_ABSORPTION 160E-9 # aLOG 19867
caput H1:TCS-SIM_ETMY_SURF_ABSORPTION 253E-9 # aLOG 19835
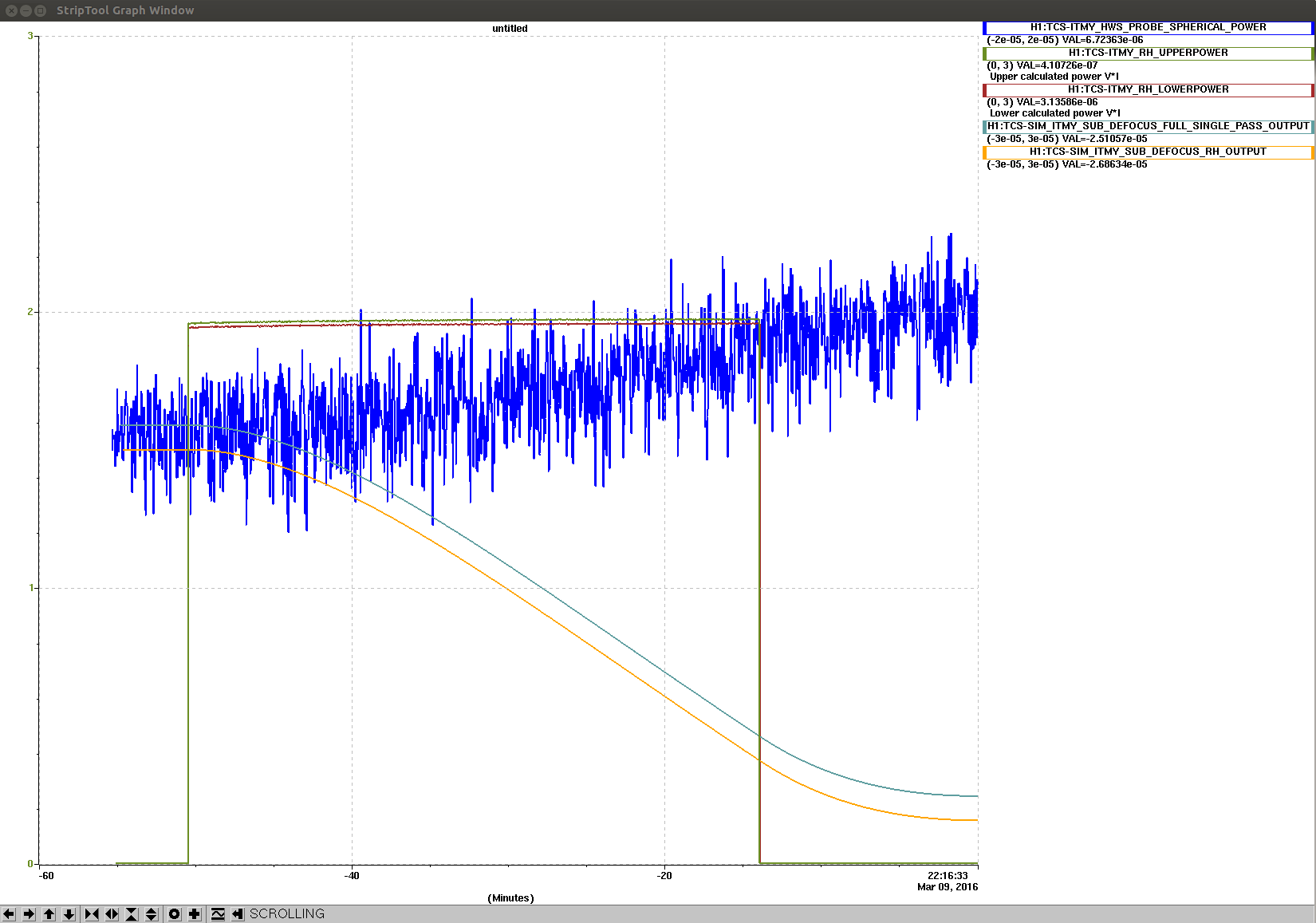
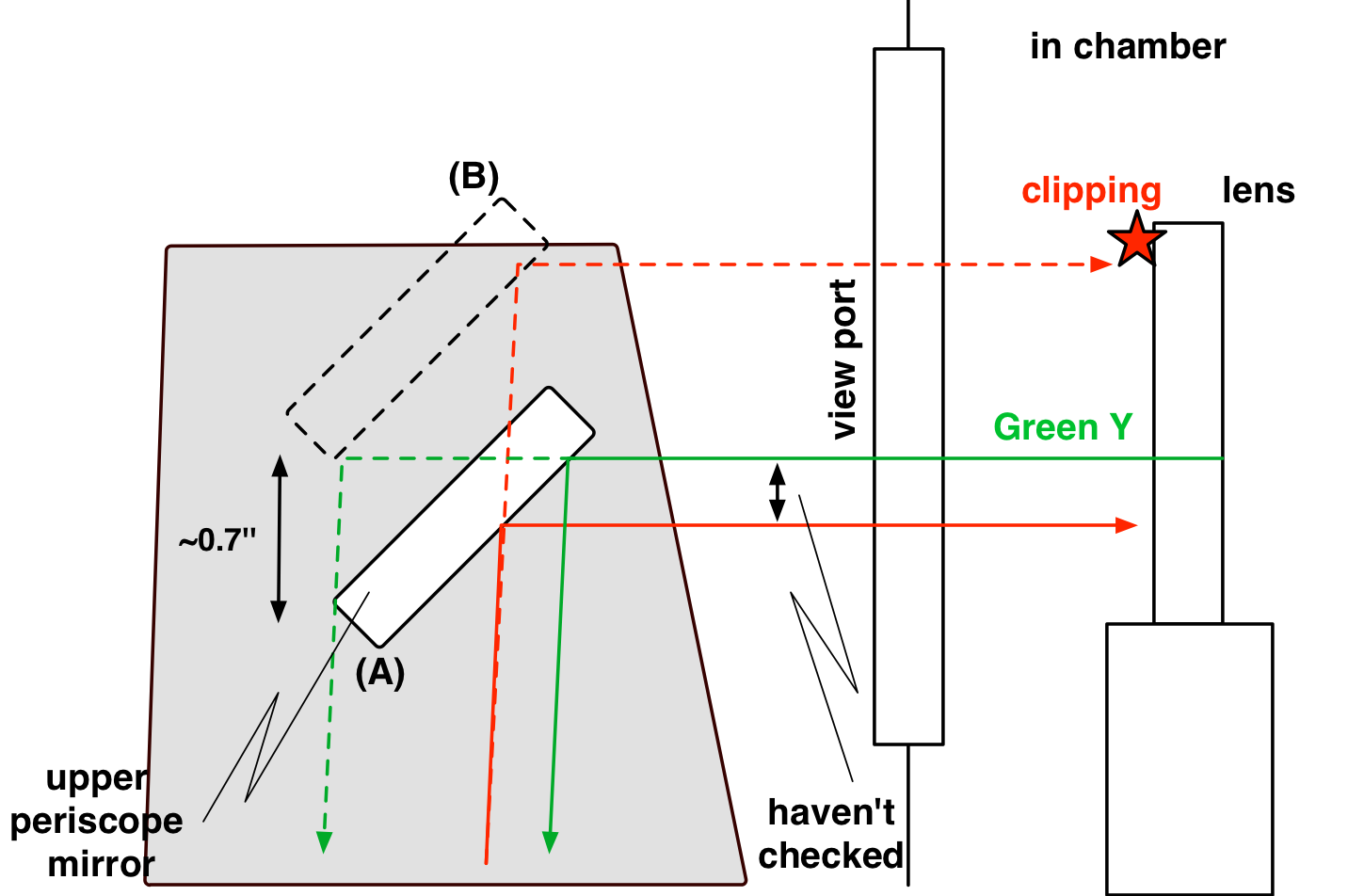
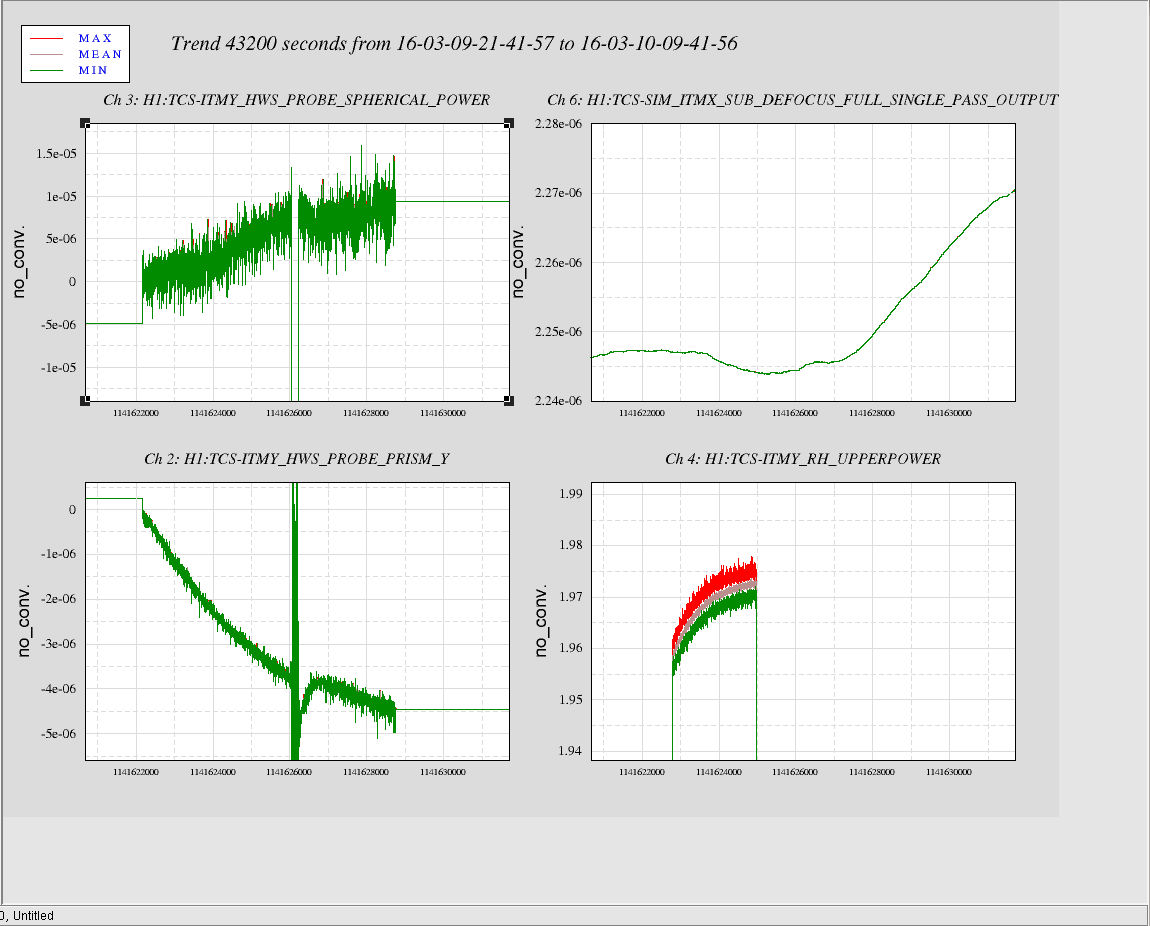
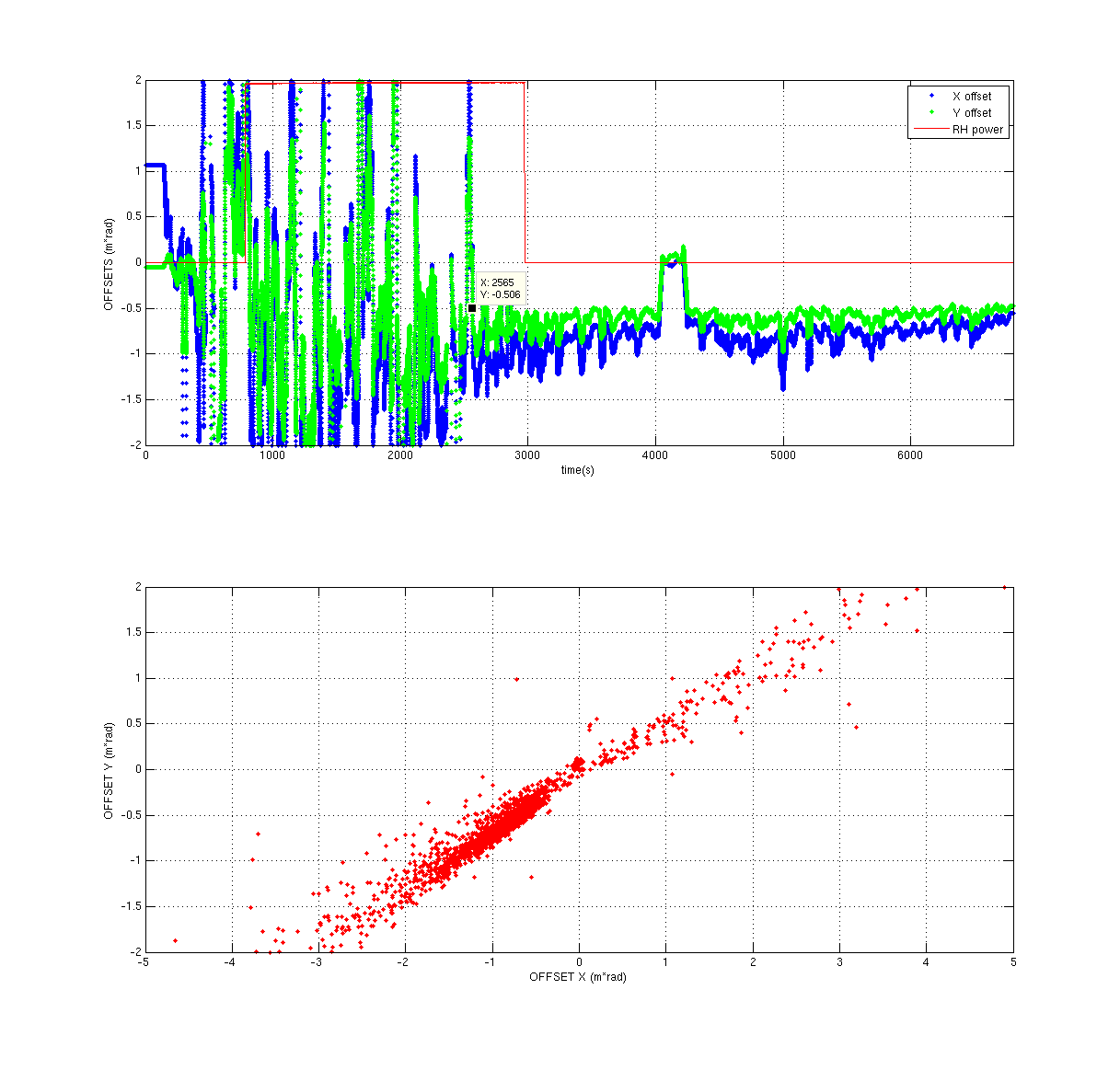





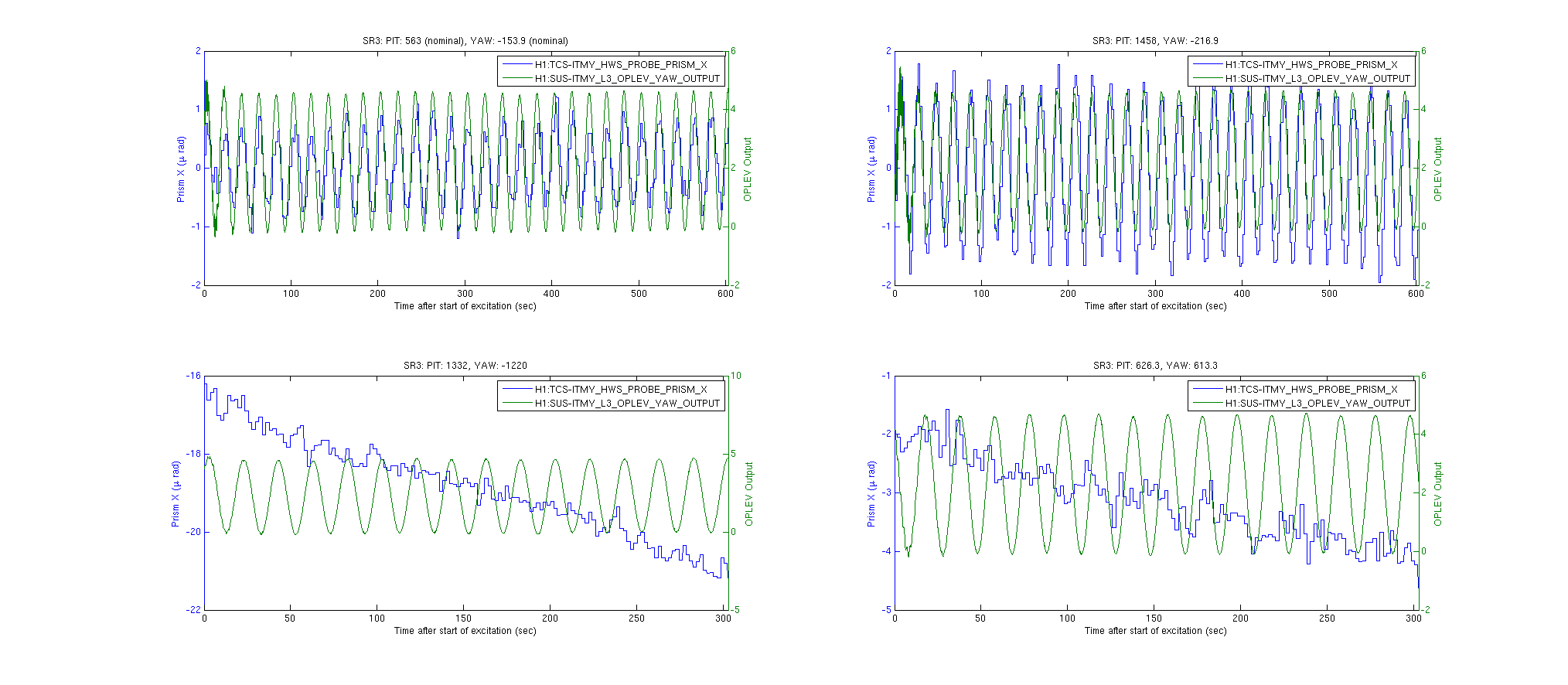
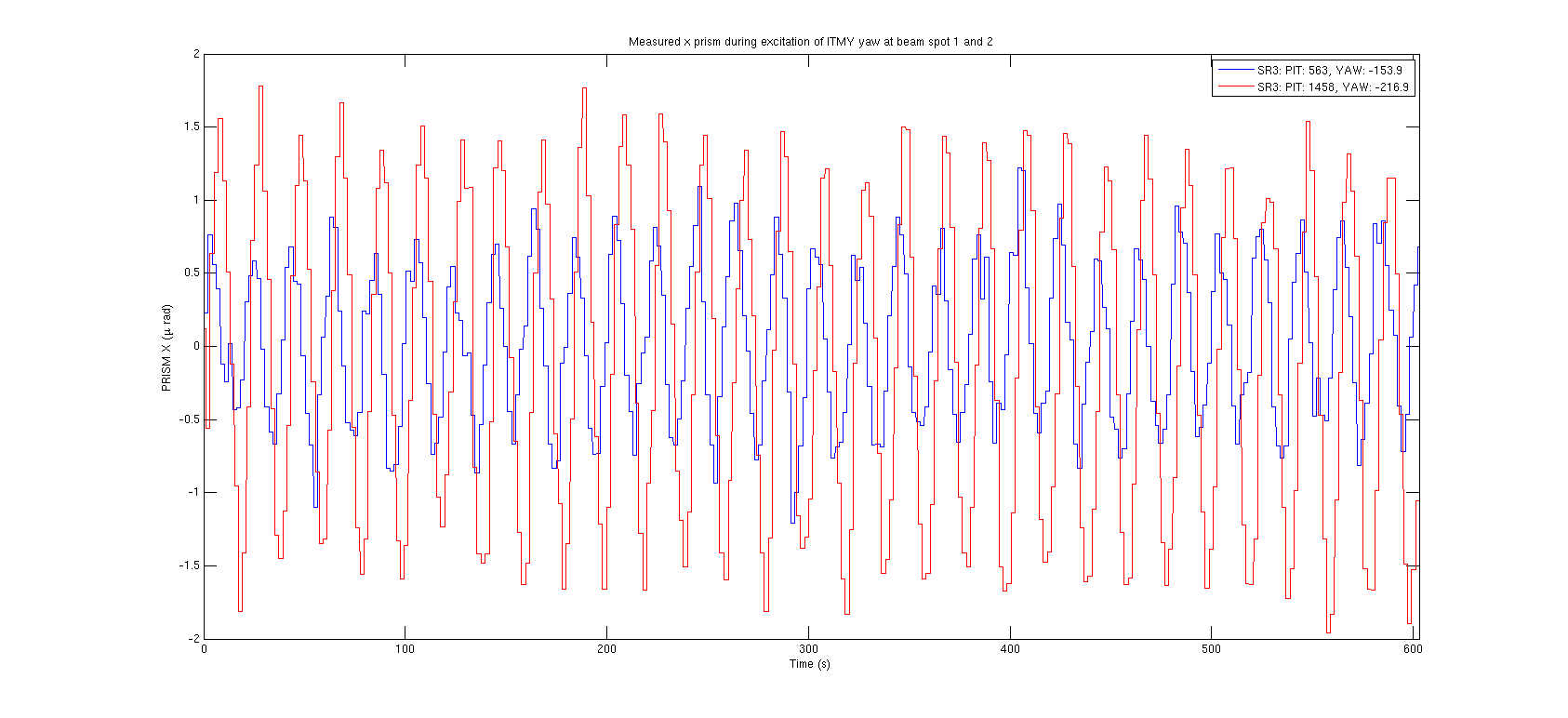
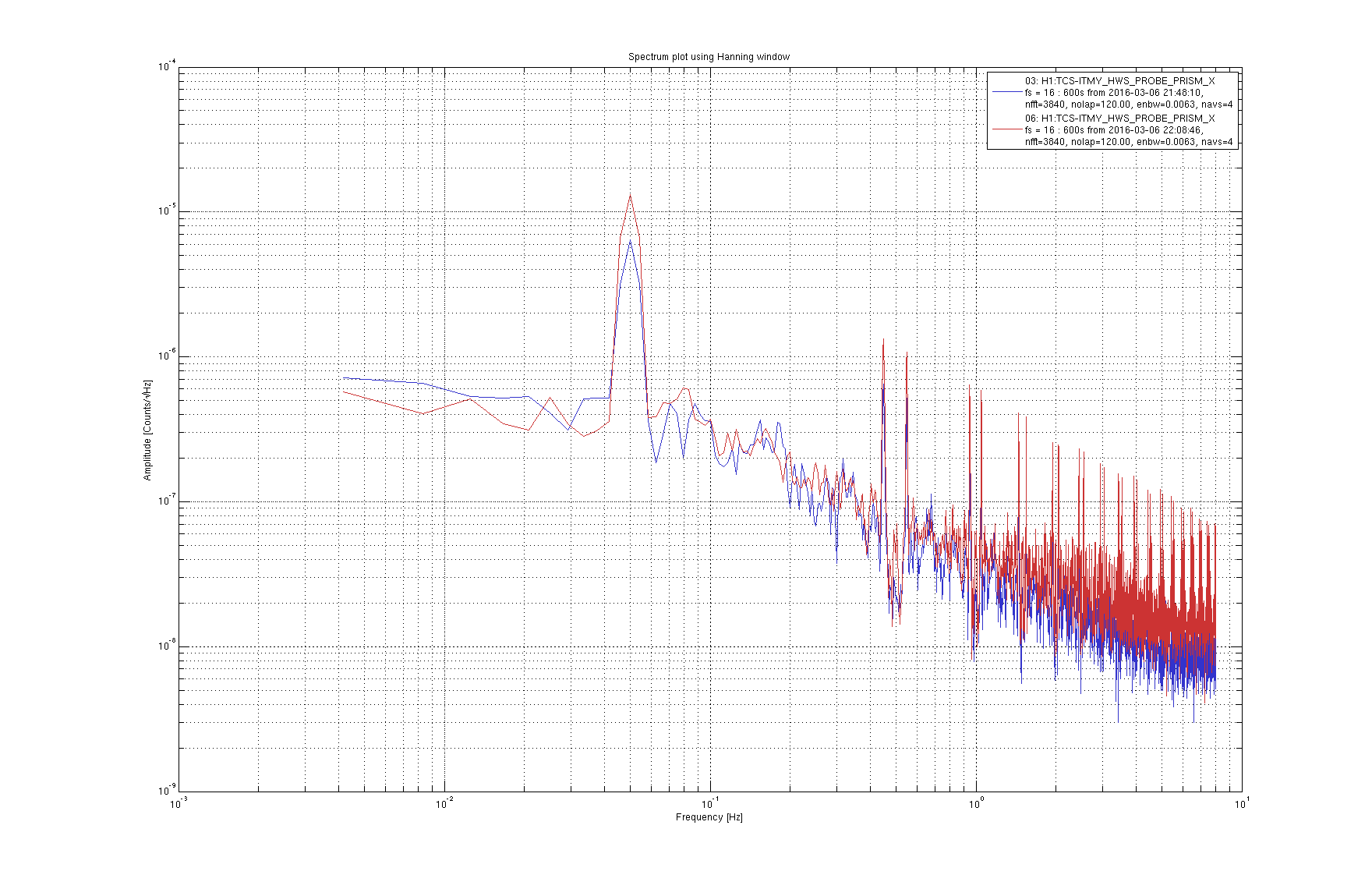
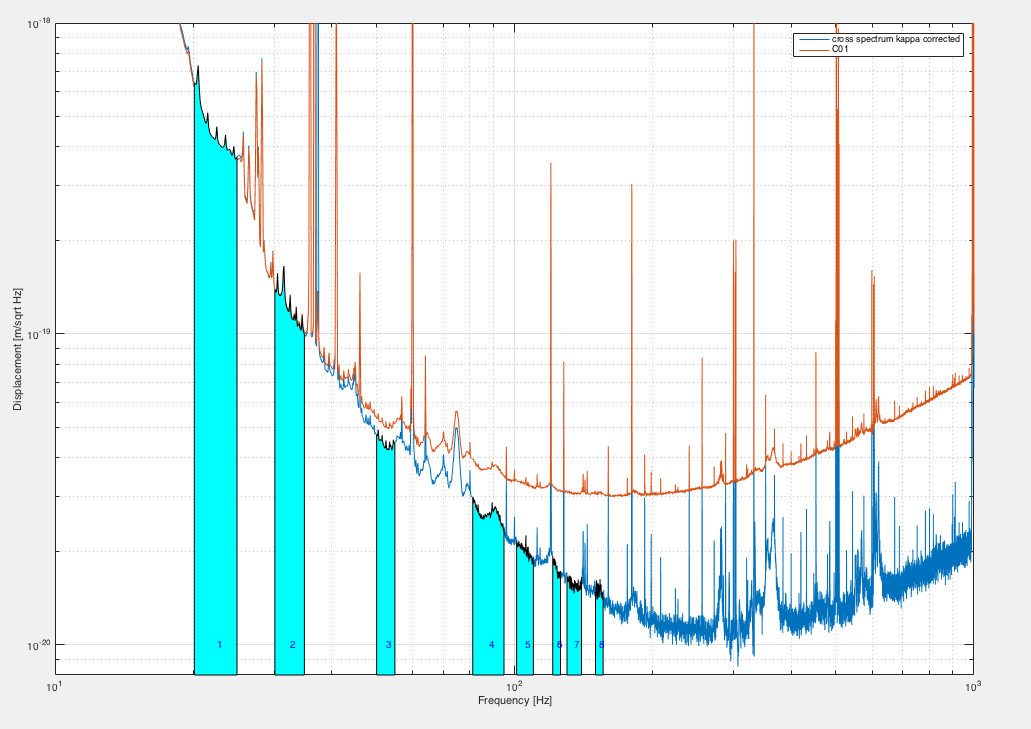{kind=link}
{kind=link}