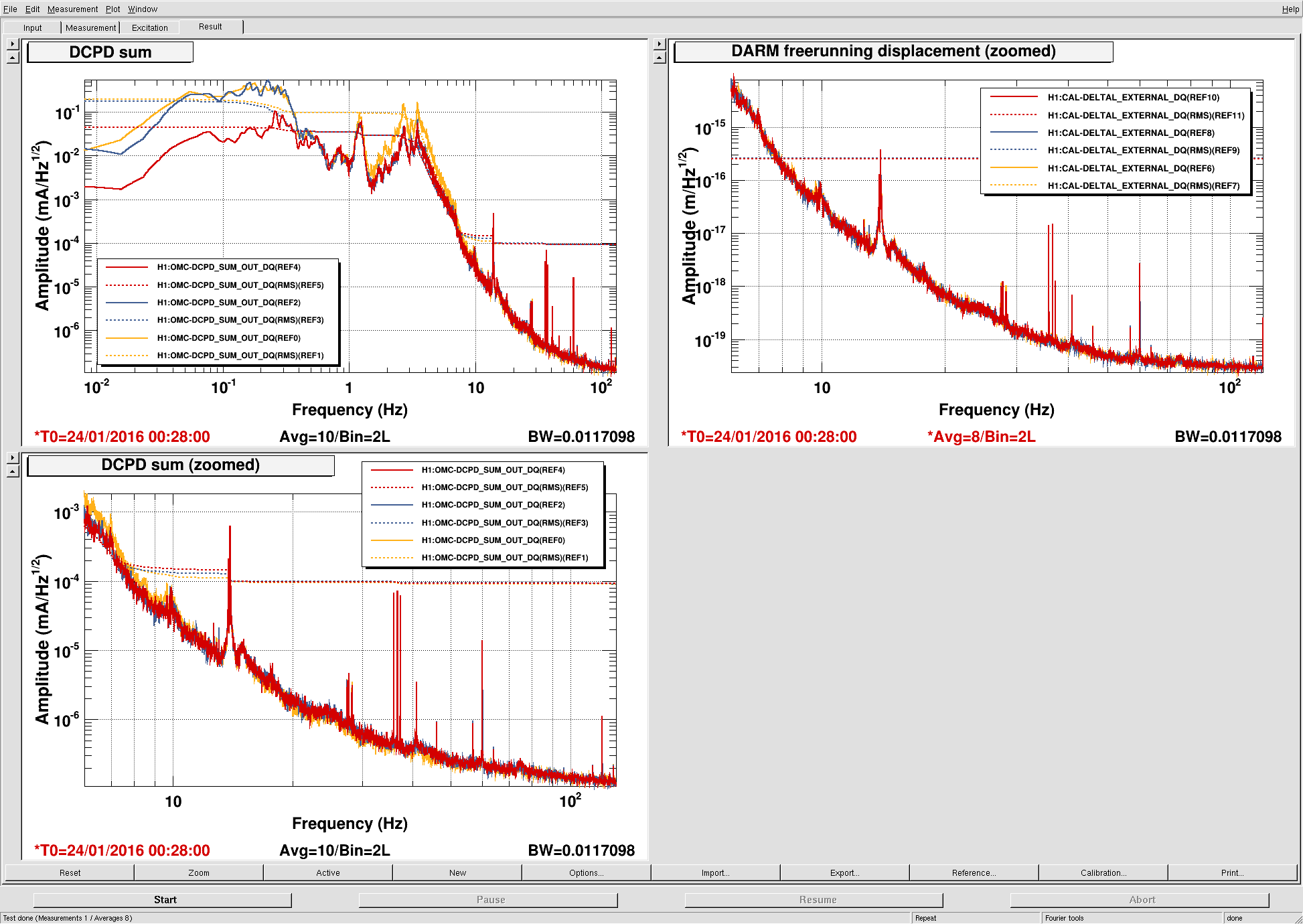
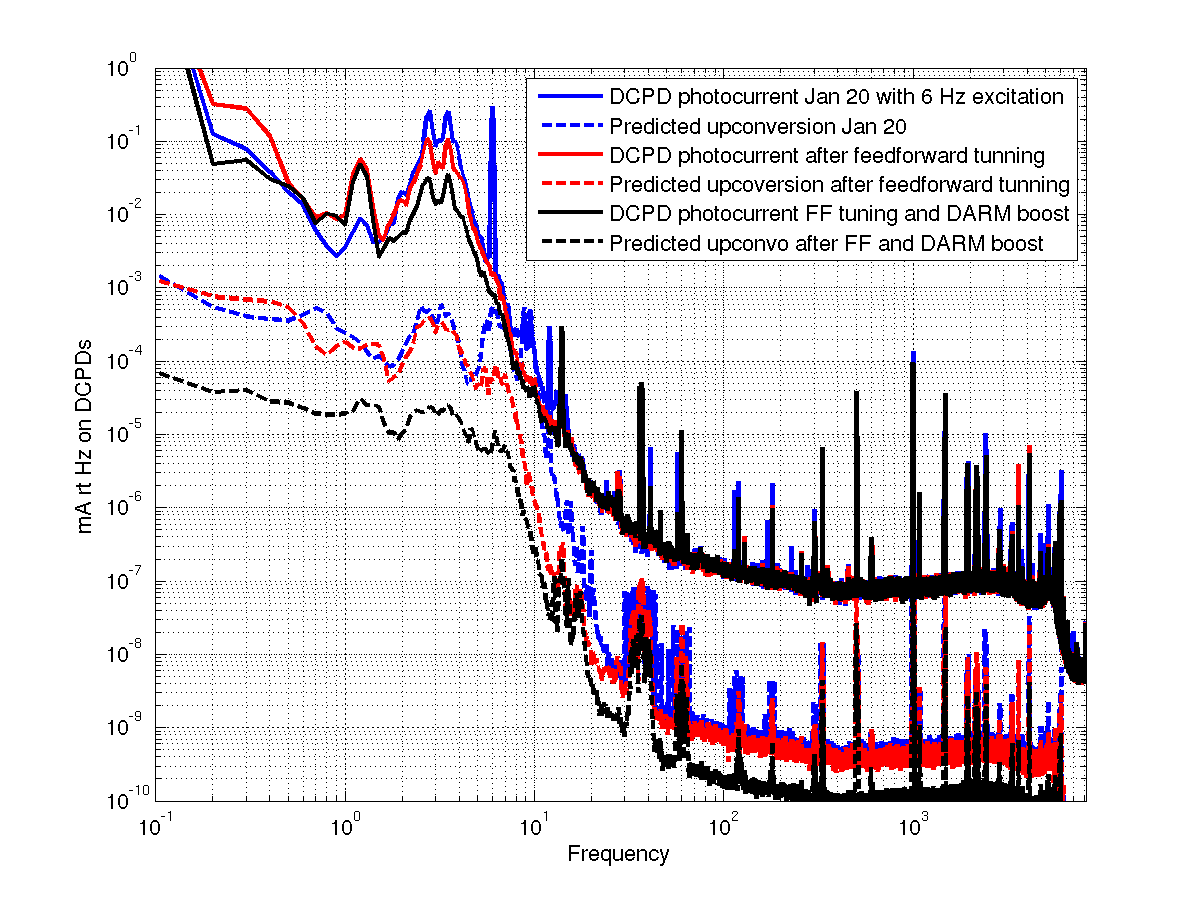
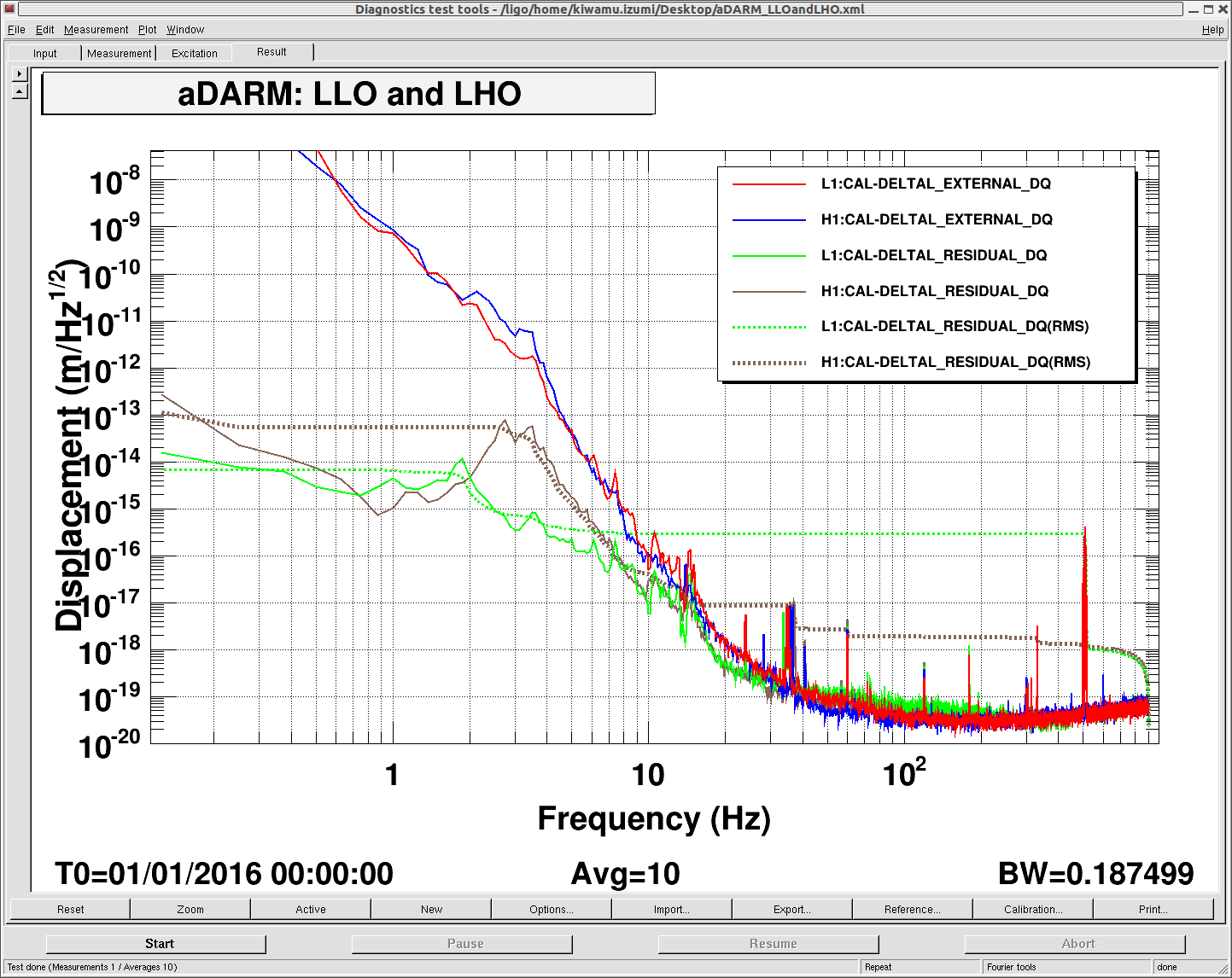
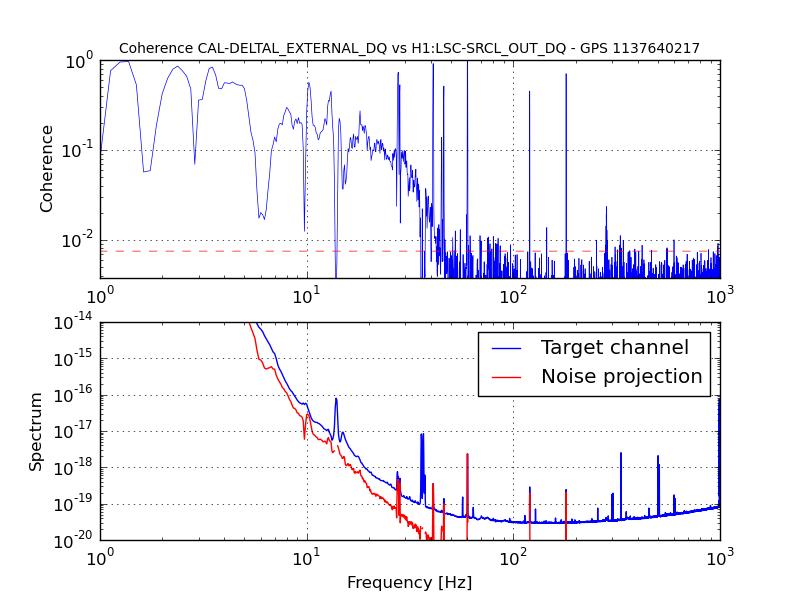
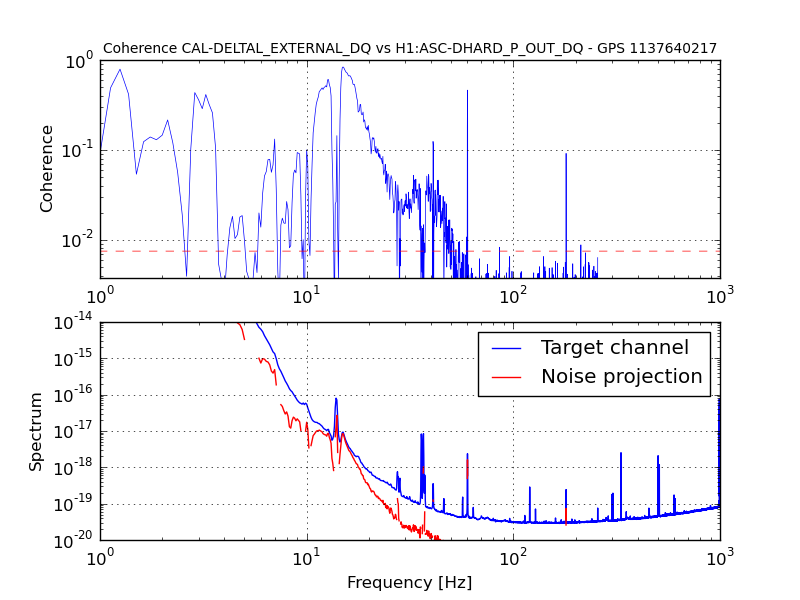
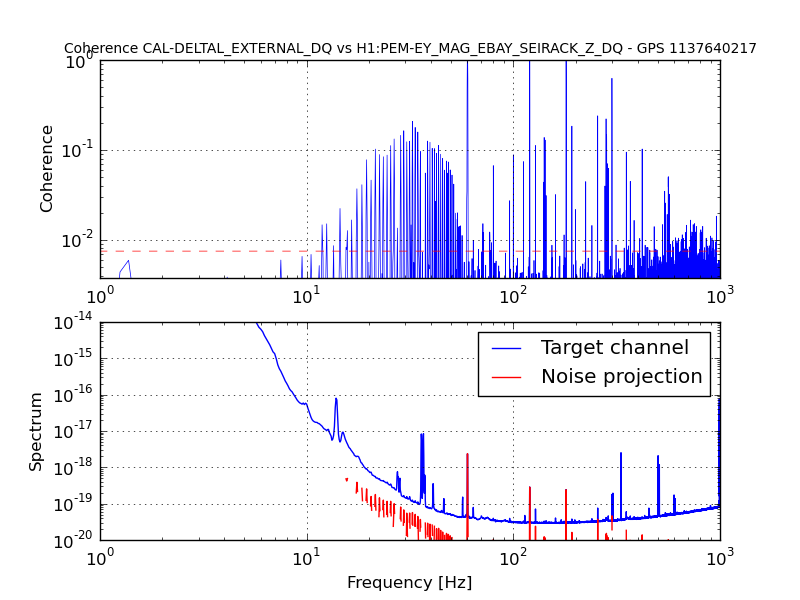
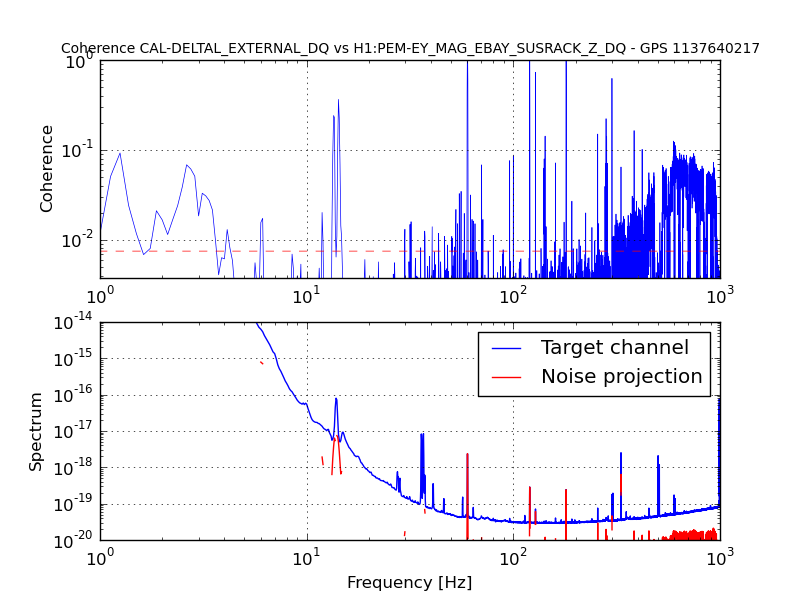
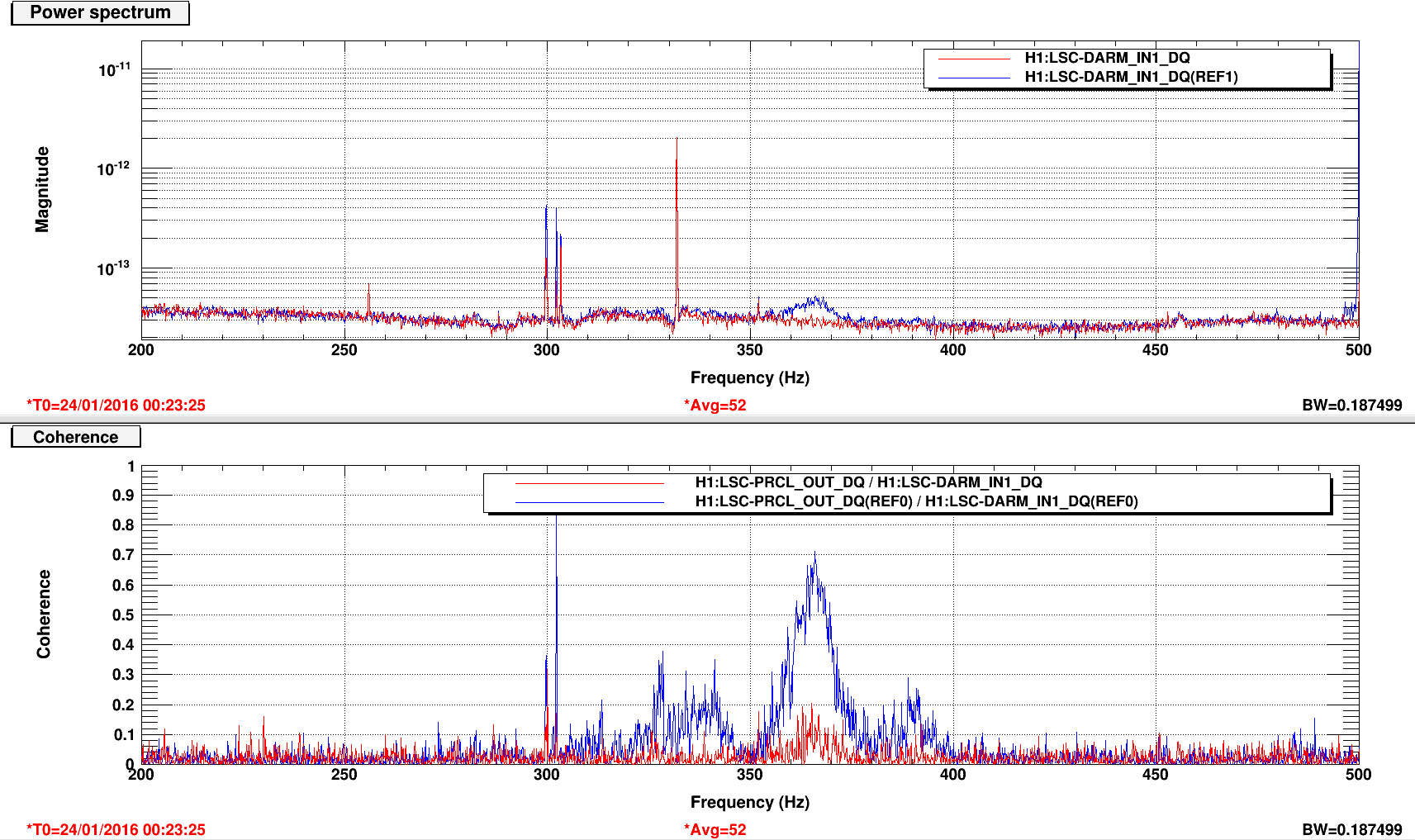
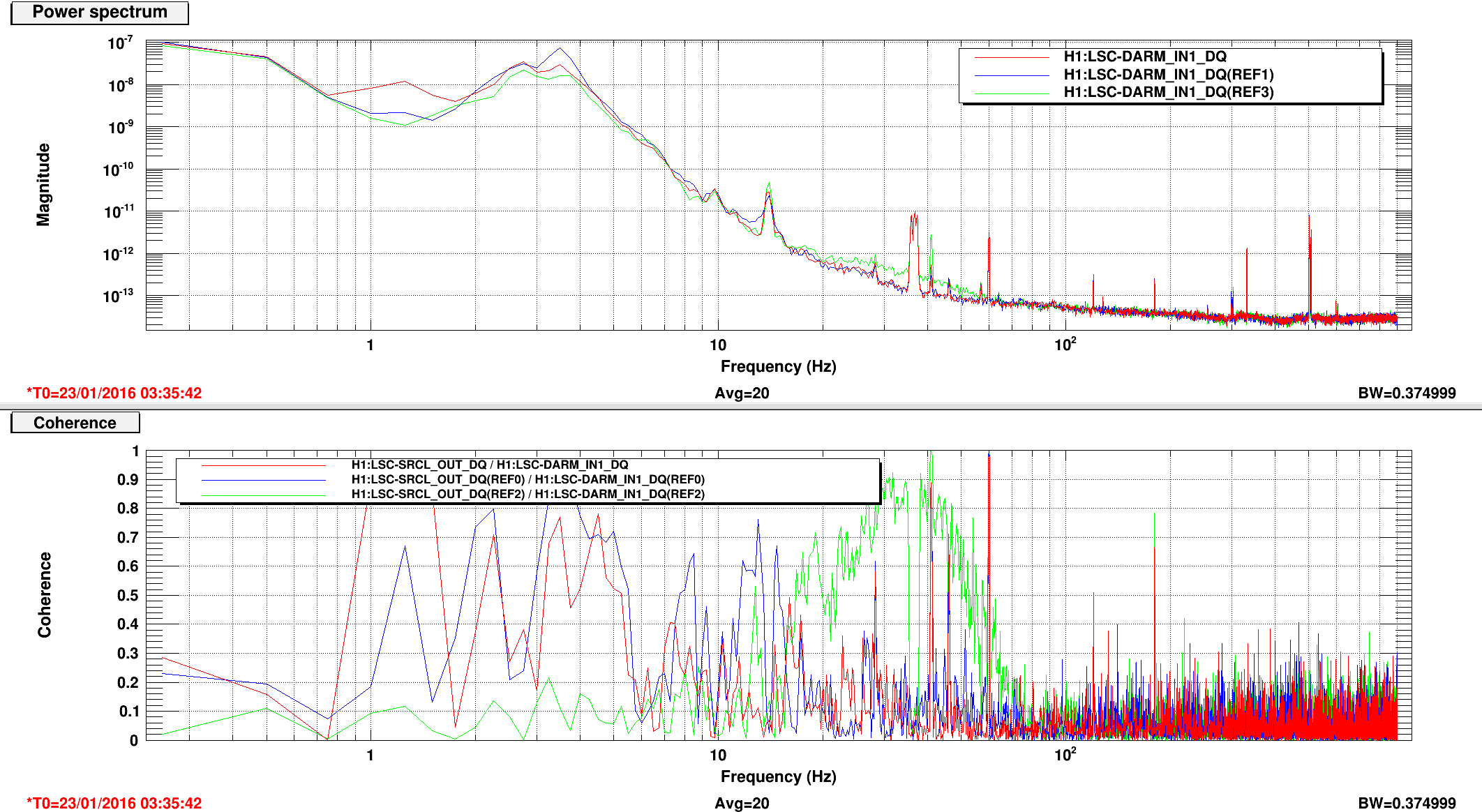
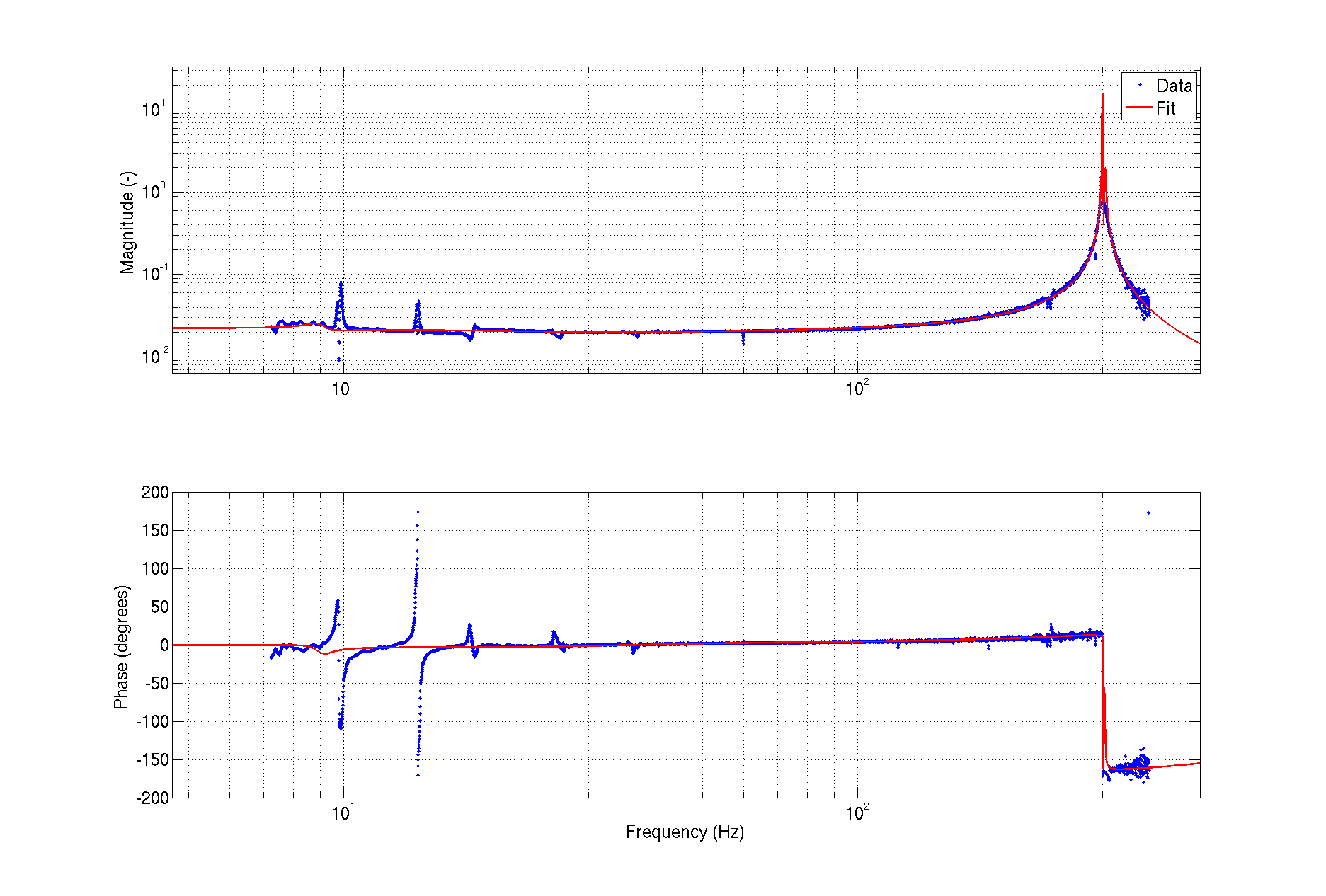
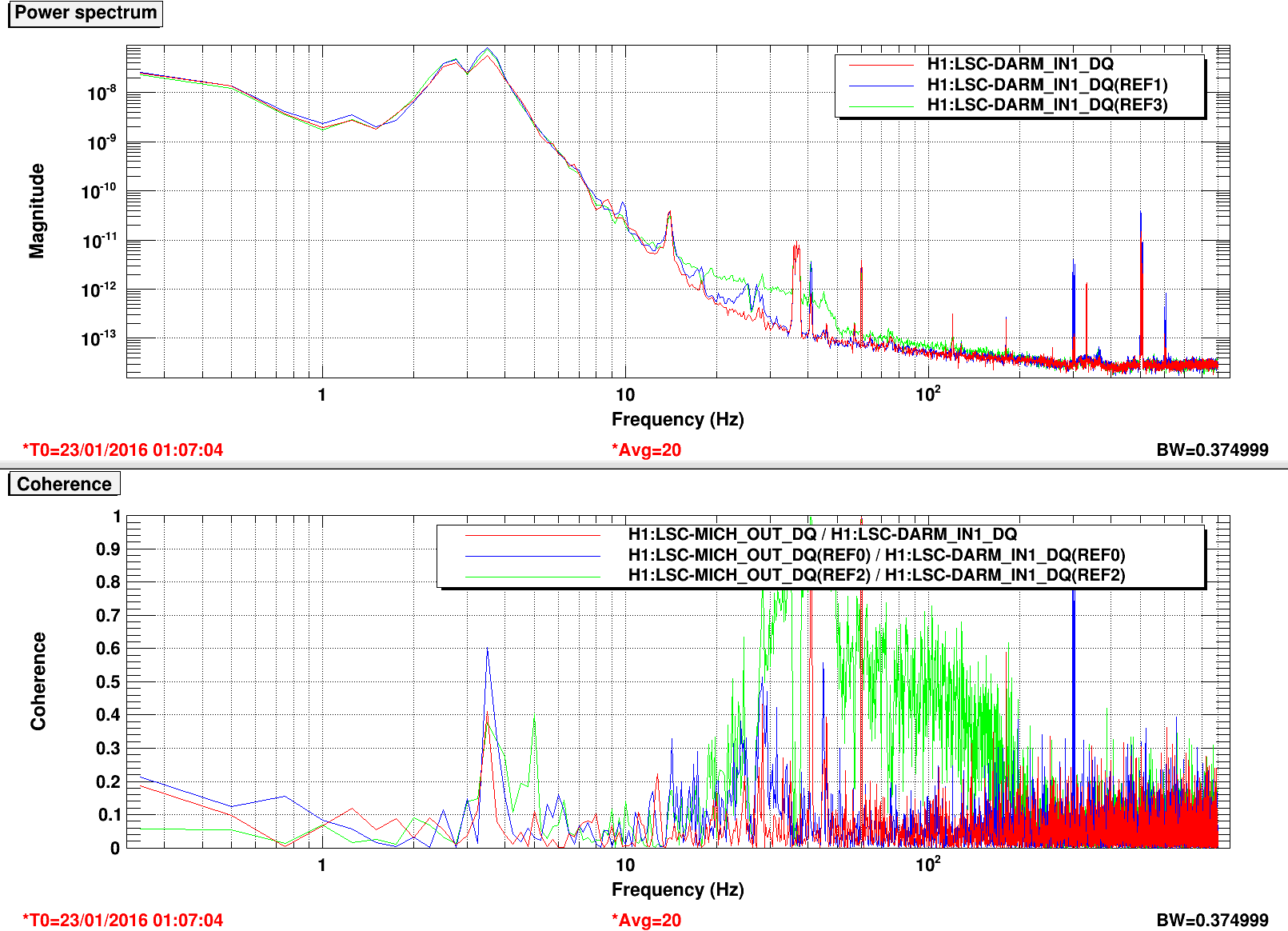
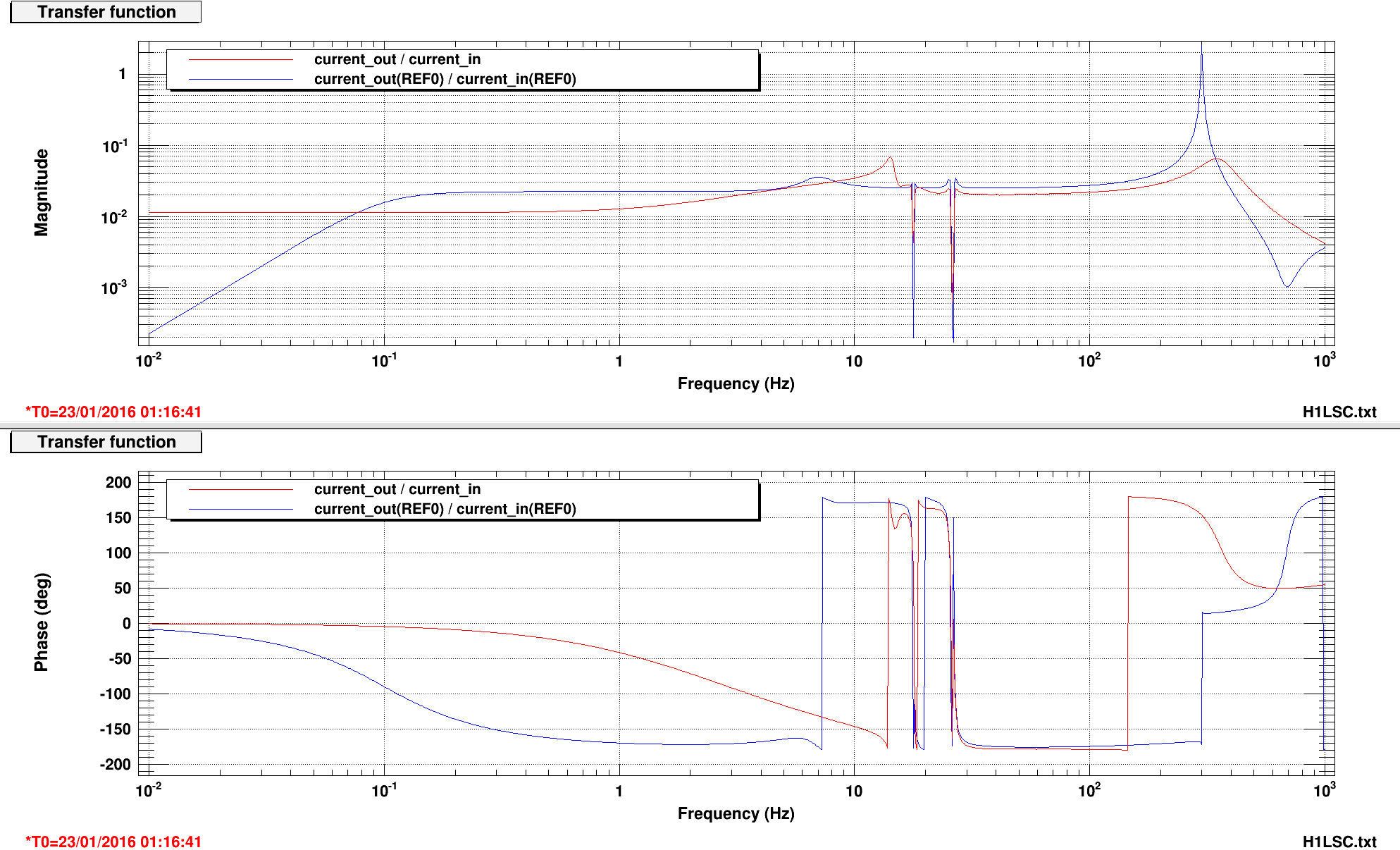
An electromagnetic shaker on the blue cross beams of the BS chamber produced greater upconversion than was produced by shaking of any other chamber or the PSL table (ITMY wasn’t shaken) (https://alog.ligo-wa.caltech.edu/aLOG/index.php?callRep=24194). I unsuccessfully tried to reproduce this upconversion using stage 2 ISI injections in X, Y and Z (I did not try RX, RY or RZ). Next I investigated the upconversion by injecting single lines with the EM shaker on the BS cross beams in order to find the most sensitive frequency band. Figure 1 shows the line injections that produced the most upconversion; they are located between 40 and 65 Hz. Lines injected with amplitudes between 1 and 2 orders of magnitude greater than normal produced broad features around the injection frequency and at harmonics, with amplitudes that were several times background in DARM. The next step will be to inject uniform bands in order to estimate the contribution of the 40-65 Hz vibration background to the DARM noise in the 80-200 Hz band.