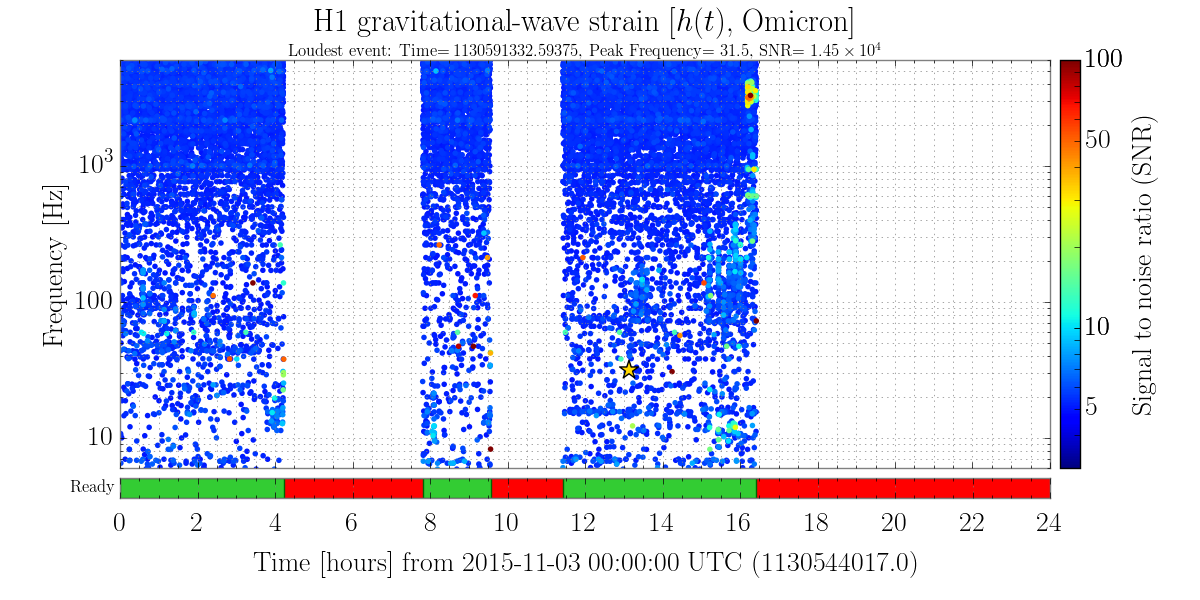
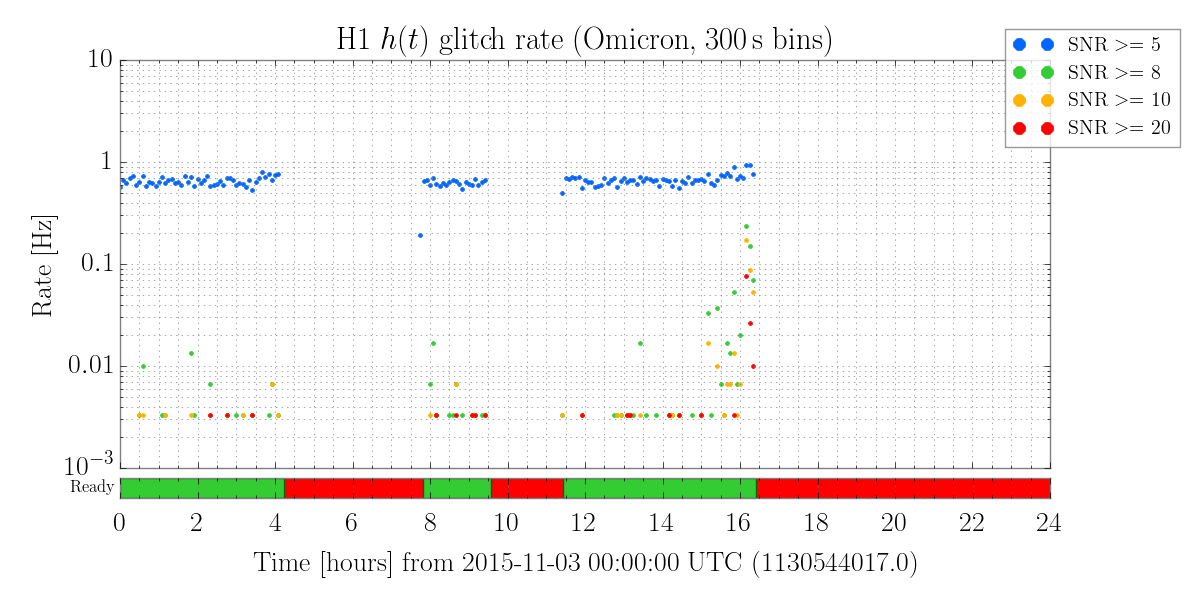
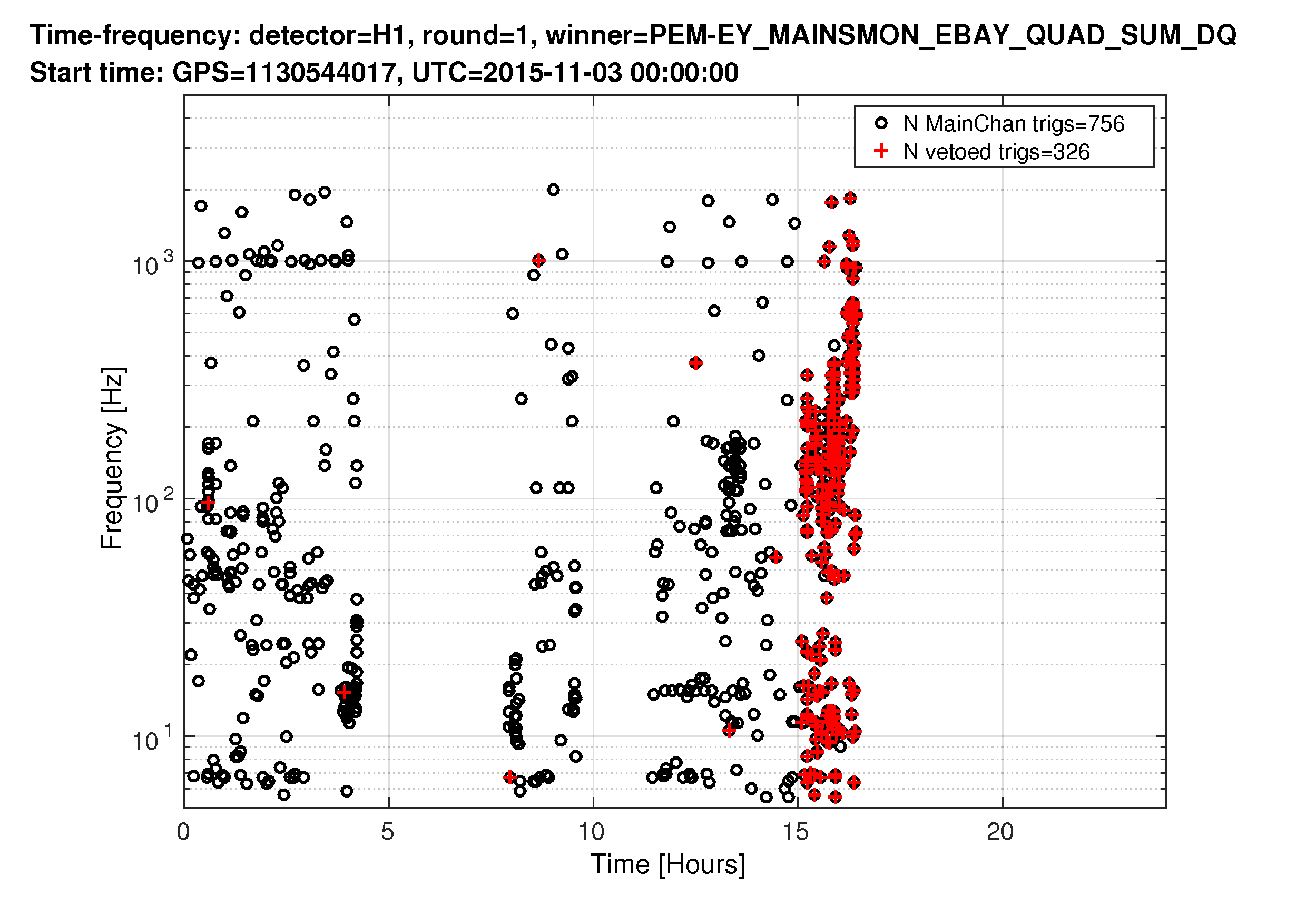
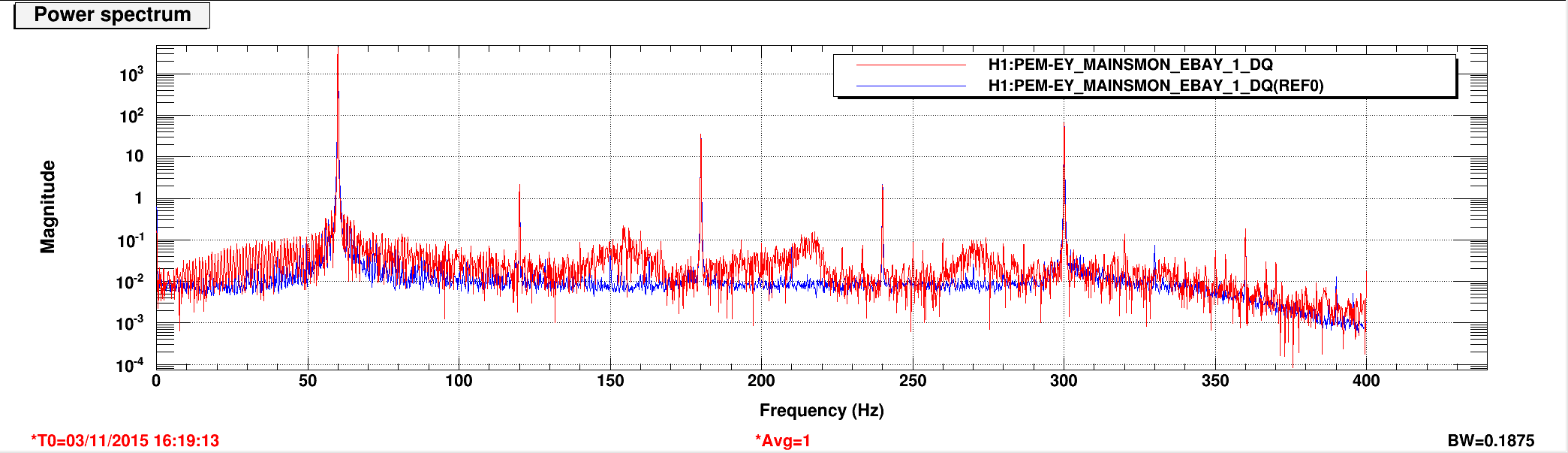
Here is the current list of source files which have outstanding local modifications which should be committed to the svn repository. Following Jeff's request, for each file with a local mod I've printed out the owner and date of the modification. I'm in contact with Hugh regarding the changes made to the BSC ISI observe.snap files.
david.barker@sysadmin0: ./check_h1_files_svn_status.bsh
SVN status of front end code source files...
done (list of files scanned can be found in /tmp/source_files_list.txt)
SVN status of filter module files...
M /opt/rtcds/userapps/release/sus/h1/filterfiles/H1SUSMC1.txt
sheila.dwyer Oct 6 12:33
M /opt/rtcds/userapps/release/sus/h1/filterfiles/H1SUSMC3.txt
sheila.dwyer Oct 6 12:32
M /opt/rtcds/userapps/release/sus/h1/filterfiles/H1SUSPRM.txt
sheila.dwyer Oct 6 12:14
M /opt/rtcds/userapps/release/sus/h1/filterfiles/H1SUSPR3.txt
sheila.dwyer Oct 6 12:44
M /opt/rtcds/userapps/release/sus/h1/filterfiles/H1SUSPR2.txt
sheila.dwyer Oct 6 12:15
M /opt/rtcds/userapps/release/sus/h1/filterfiles/H1SUSSR2.txt
sheila.dwyer Oct 6 12:16
M /opt/rtcds/userapps/release/sus/h1/filterfiles/H1SUSSRM.txt
sheila.dwyer Oct 6 12:17
M /opt/rtcds/userapps/release/sus/h1/filterfiles/H1SUSSR3.txt
sheila.dwyer Oct 6 12:44
M /opt/rtcds/userapps/release/sus/h1/filterfiles/H1SUSITMY.txt
evan.hall Oct 28 14:31
M /opt/rtcds/userapps/release/sus/h1/filterfiles/H1SUSITMX.txt
evan.hall Oct 28 13:39
M /opt/rtcds/userapps/release/isc/h1/filterfiles/H1OAF.txt
kiwamu.izumi Oct 25 21:14
M /opt/rtcds/userapps/release/cal/h1/filterfiles/H1CALCS.txt
jeffrey.kissel Oct 20 12:25
M /opt/rtcds/userapps/release/lsc/h1/filterfiles/H1LSC.txt
sheila.dwyer Oct 13 12:27
M /opt/rtcds/userapps/release/asc/h1/filterfiles/H1ASC.txt
sheila.dwyer Oct 10 14:01
M /opt/rtcds/userapps/release/sus/h1/filterfiles/H1SUSETMY.txt
evan.hall Oct 29 15:47
M /opt/rtcds/userapps/release/sus/h1/filterfiles/H1SUSETMX.txt
evan.hall Oct 29 13:36
M /opt/rtcds/userapps/release/cal/h1/filterfiles/H1CALEX.txt
sudarshan.karki Oct 27 12:29
done (list of filter module files scanned can be found in /tmp/full_path_filter_file_list.txt)
SVN status of safe.snap files...
done (list of safe.snap files scanned can be found in /tmp/safe_snap_files.txt)
SVN status of OBSERVE.snap files...
M /opt/rtcds/userapps/release/isi/h1/burtfiles/h1isiitmy_OBSERVE.snap
hugh.radkins Nov 3 03:25
M /opt/rtcds/userapps/release/isi/h1/burtfiles/h1isibs_OBSERVE.snap
hugh.radkins Nov 3 03:25
M /opt/rtcds/userapps/release/isi/h1/burtfiles/h1isiitmx_OBSERVE.snap
hugh.radkins Nov 3 03:25
M /opt/rtcds/userapps/release/isi/h1/burtfiles/h1isietmy_OBSERVE.snap
hugh.radkins Nov 3 03:25
M /opt/rtcds/userapps/release/isi/h1/burtfiles/h1isietmx_OBSERVE.snap
hugh.radkins Nov 3 03:25
done (list of observe.snap files scanned can be found in /tmp/observe_snap_files.txt)
SVN status of guardian files...
done