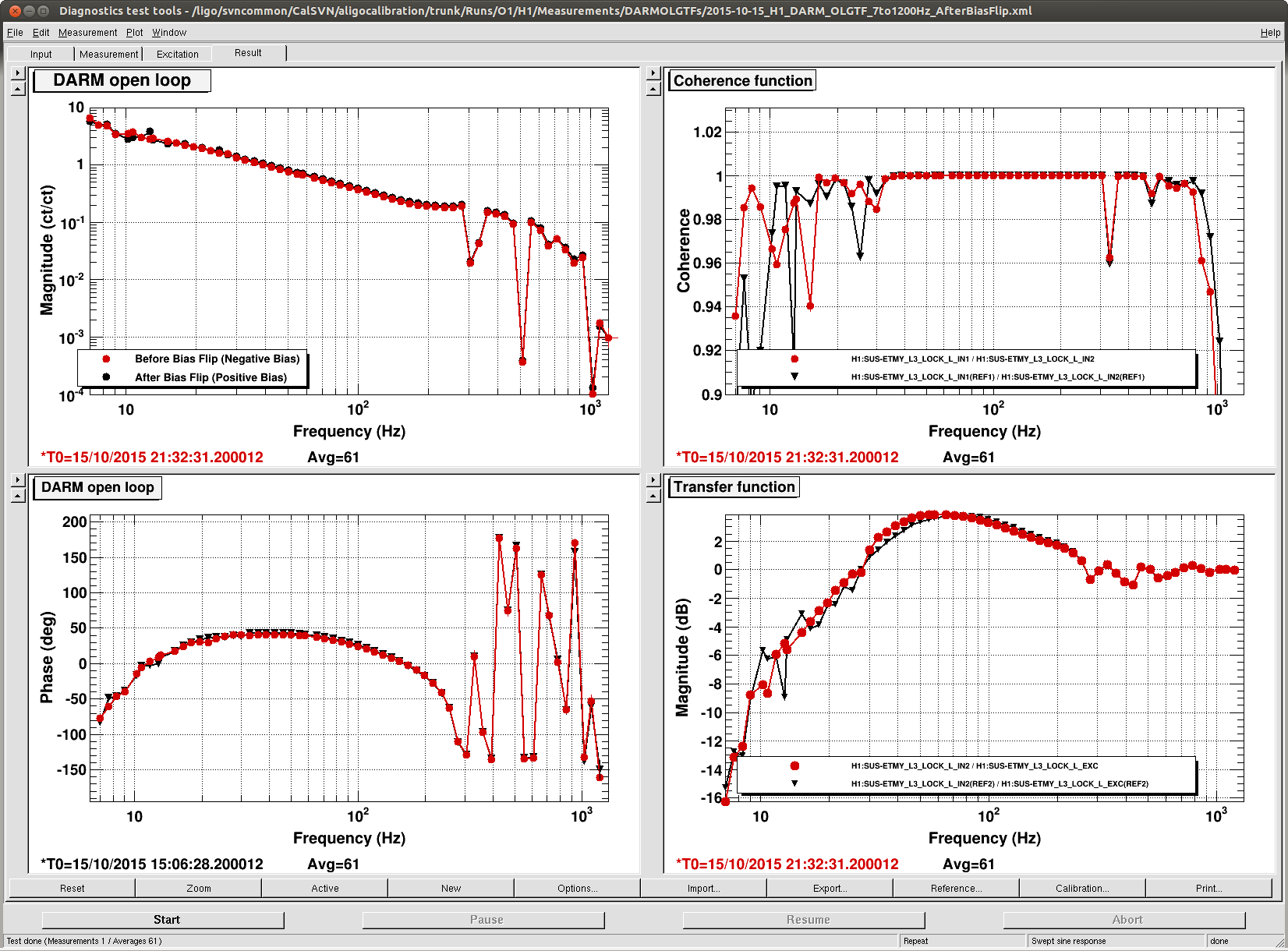
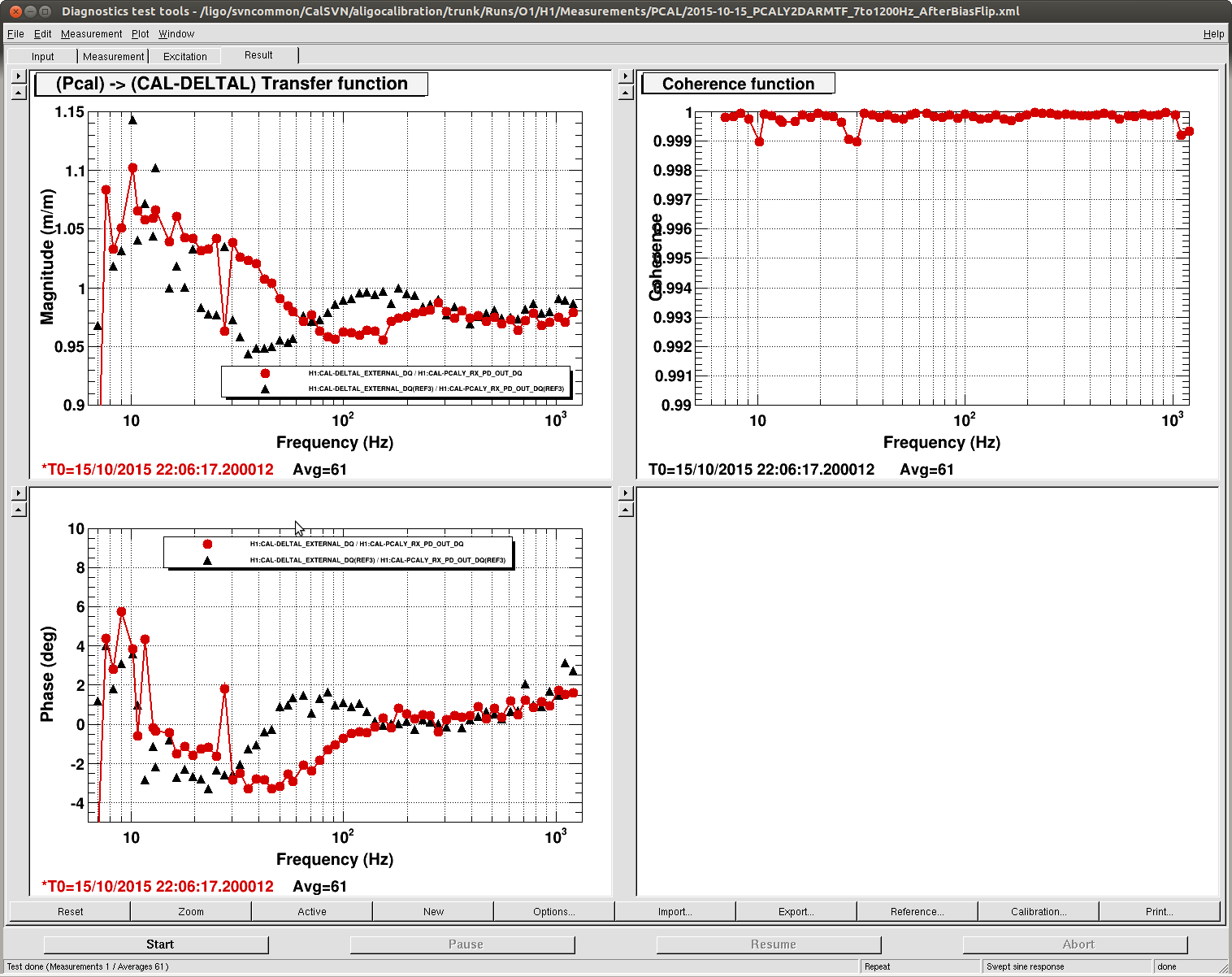
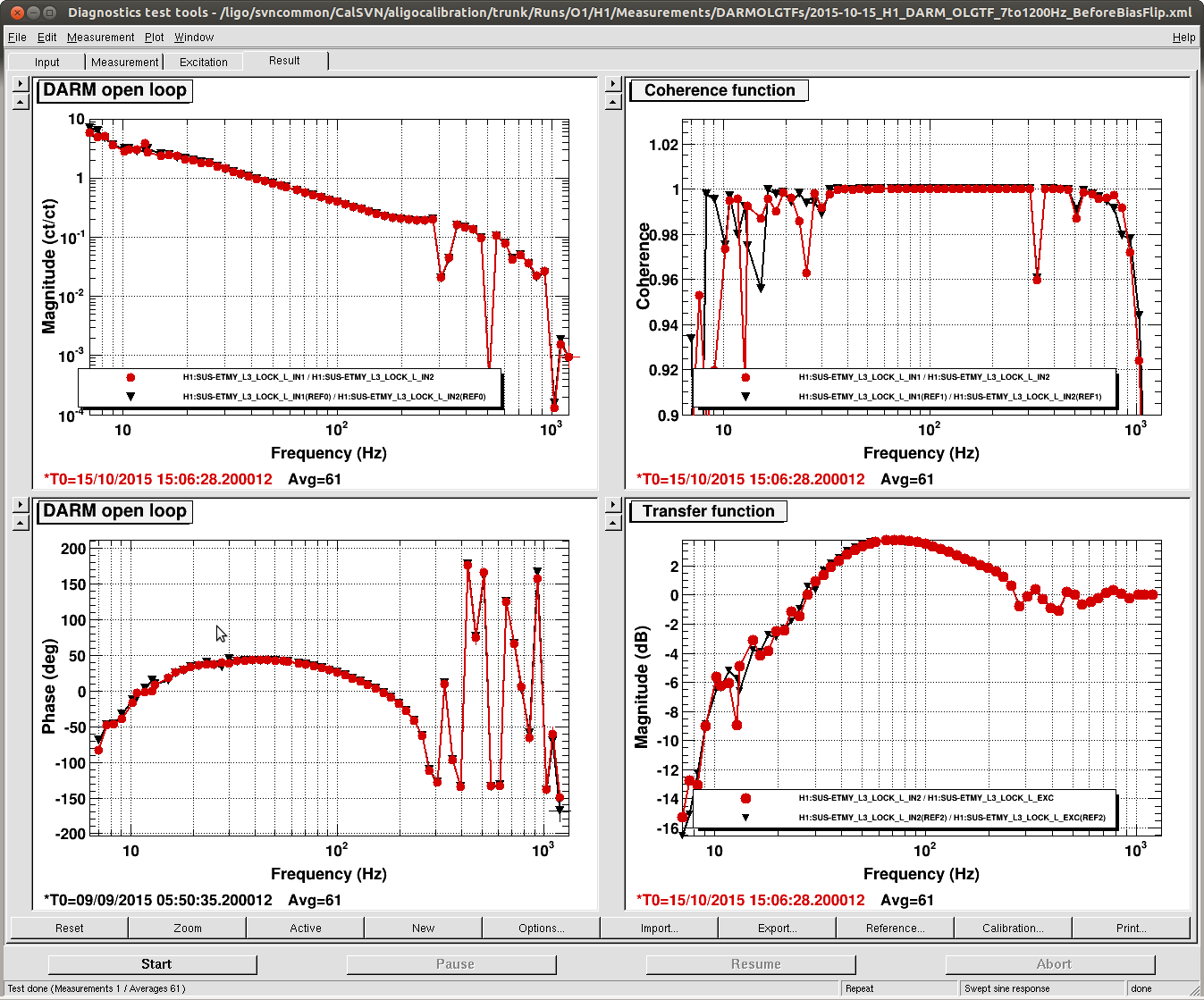
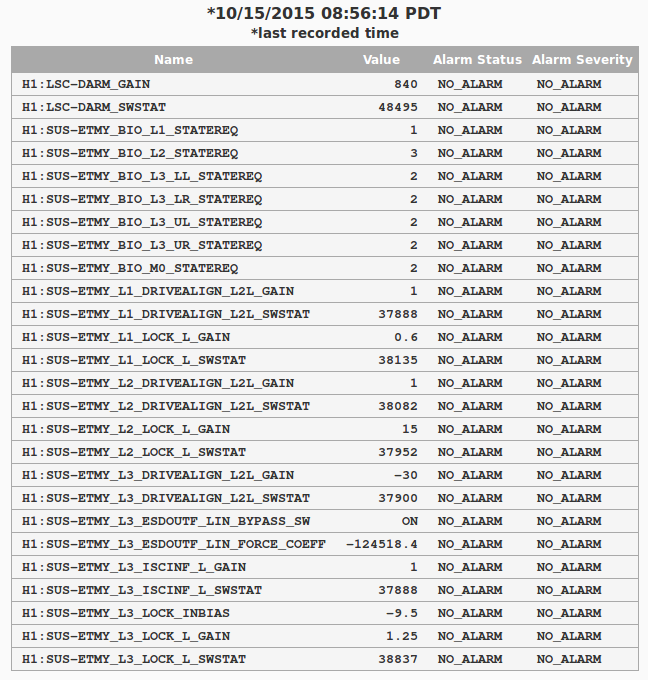
evan.hall@LIGO.ORG - posted 12:52, Tuesday 20 October 2015 (22684)
IM suspension point projections installed
The front-end projection matrix elements for propagating HAM2 table motion to the IMs' suspension points had apparently never been installed.
However, the projections have already been computed in userapps/isc/common/projections/ISI2SUS_projection_file.mat, and the displacement vectors used in the computation agree with the systems diagrams (D120062[3456]). So I propagated these projection matrix values to the front-end.
It would also be nice to make and install the projection matrices for the OMs as well, since these have not been computed yet.
Non-image files attached to this report