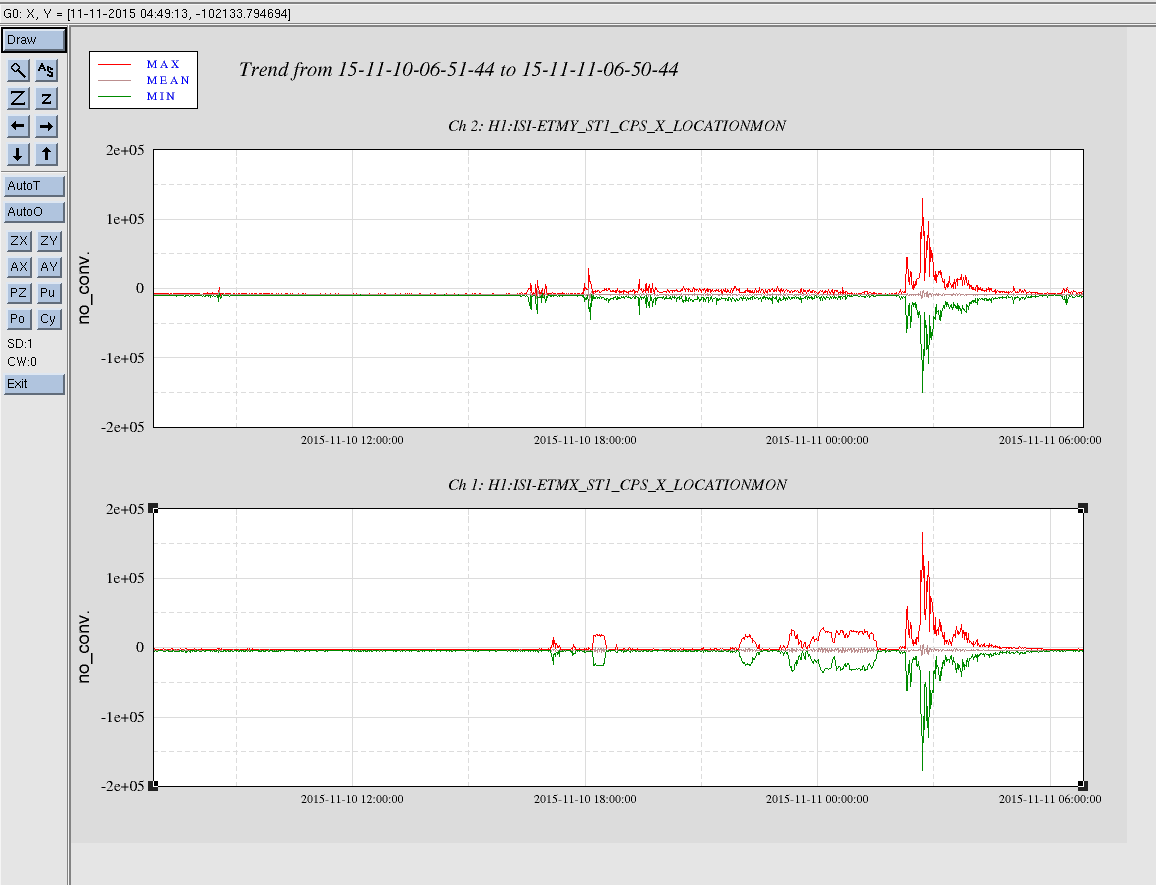
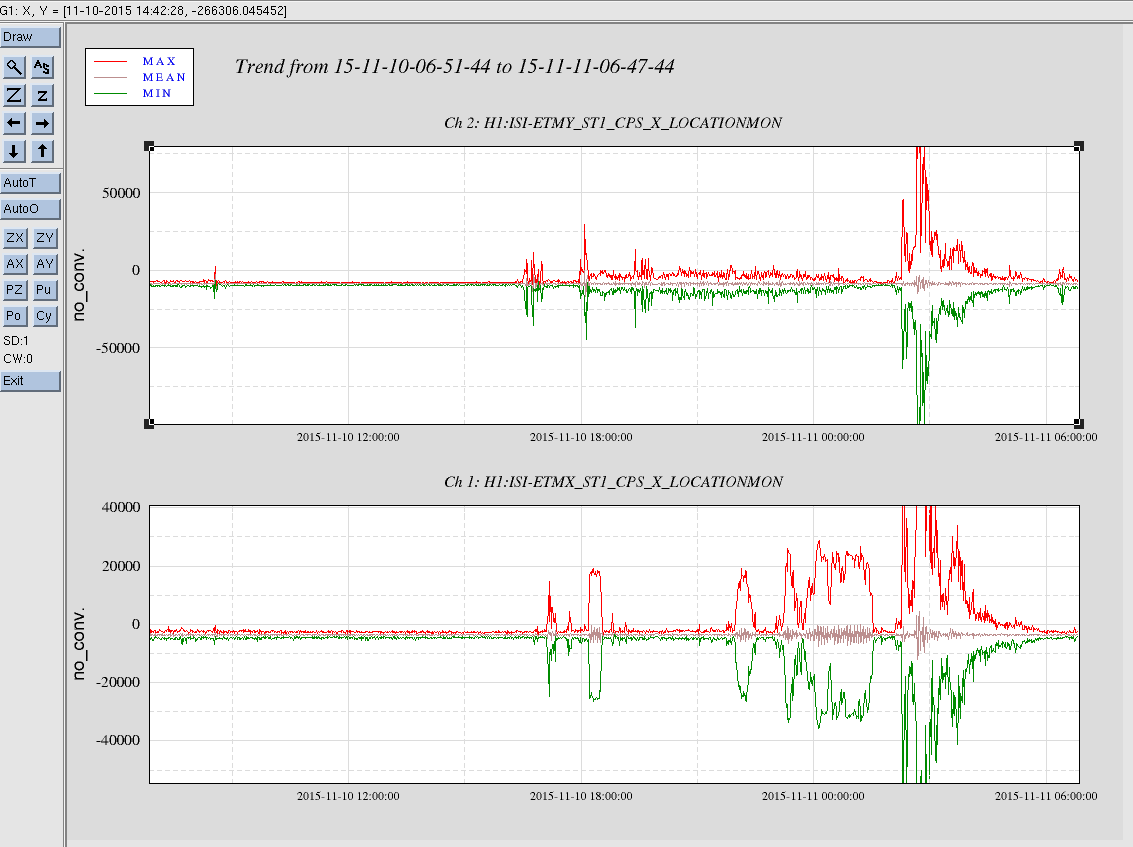
Still down after the lockloss earlier due to high winds. Winds are in the 30s with gusts to over 40 mph, and the forecast predicts it won't get better for the rest of the day. But who believes the weathermen anyways?? (According to the NWS, they are off by a factor of 2 in their prediction at the moment, however in the wrong direction for GW science. It is supposed to be 15 mph with gusts to 20.)
I had to call Keita at 4am PST to walk me through an ALS fiber polarization adjustment since I had never done one and could not find a procedure to do so (it is on my list to add to the OPS Wiki). The wind did its typical thing where it calms just enough to lull you into the sense that you should begin locking again before it picks back up. Sorry Keita, you should sleep in this morning or get a nice breakfast or something.

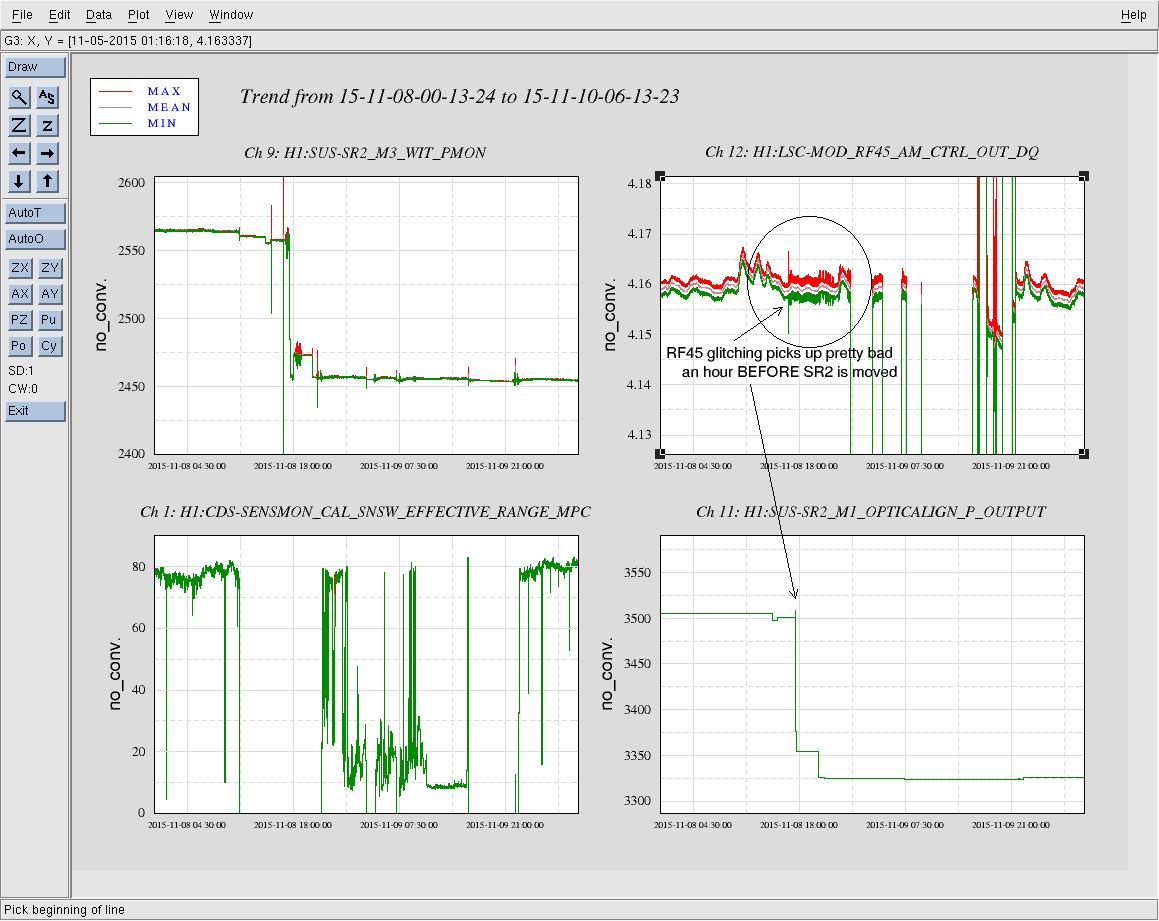
The SDF diffs that Jeff accepted were from the dark offset scripts that I ran at 23:28 UTC.