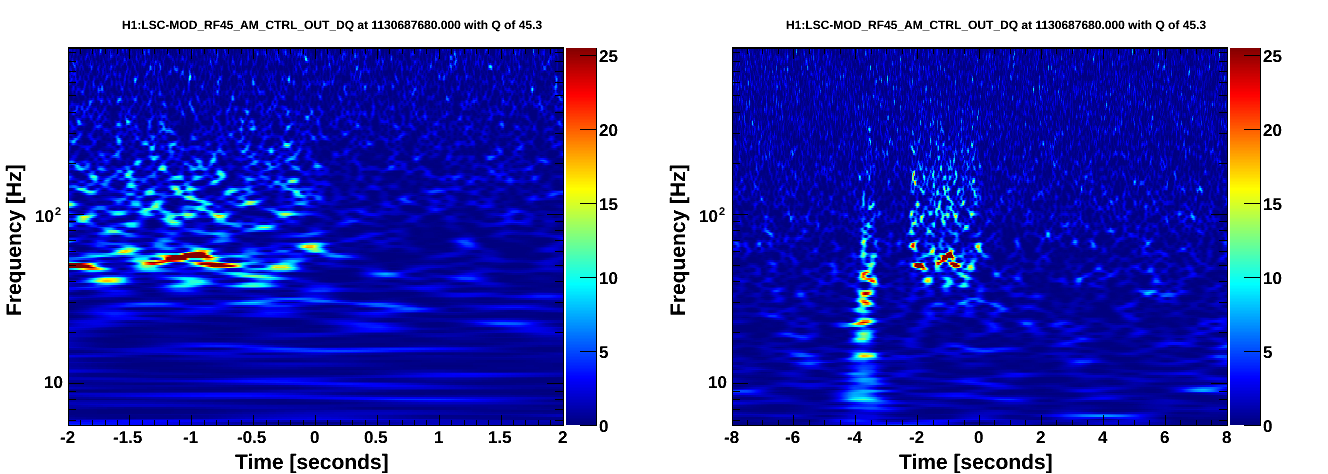
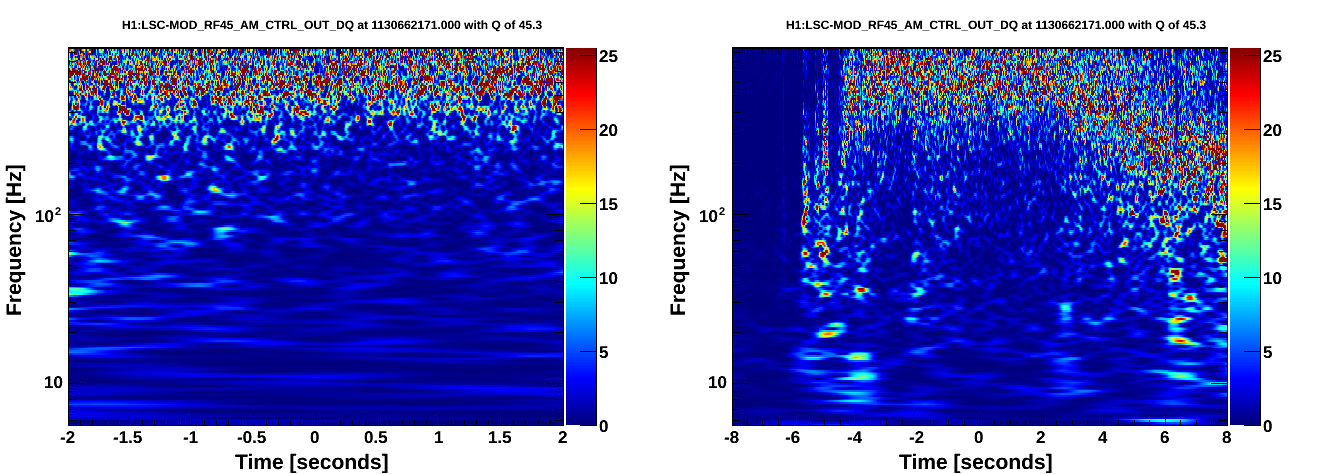
Our range was shown to be limited by the HVAC (Link). Since then Bubba and John have reduced air and water flow rates. Today I repeated the experiment to see how well we are doing. It looks like the HVAC is costing us about 3 Mpc now instead of about 5 before. I started some experiments to narrow down the dominant source but the microseism came up so high that I have stopped and will complete them later. Here are the ranges of time in which the HVAC was not in a steady state (the changes were made during science mode).
Sitewide shutdown of turbines and chiller pumps.
Nov. 7 UTC
Turn off 19:15:00 19:23:34
Turn on 19:30:00 to 19:36:40
Turn off 19:45:00 to 19:48:40
Turn on 20:00:00 to 20:04:45
Turn off 20:15:00 to 20:18:40
Turn on 20:30:00 to 20:35:05
CS experiments
Nov. 8 UTC
SF 5 & 6 off 00:34:00 to 00:34:10 seis about normal, no change in range
SF 5 & 6 on 00:44:10 to 00:44:30
Turbines off but chiller pump on 1:10:00 to 1:10:10
All on 1:20:00 to 1:20:20
Chiller pump off 1:30:00 to 1:30:15
Chiller pump on 1:40:00 to 1:40:30