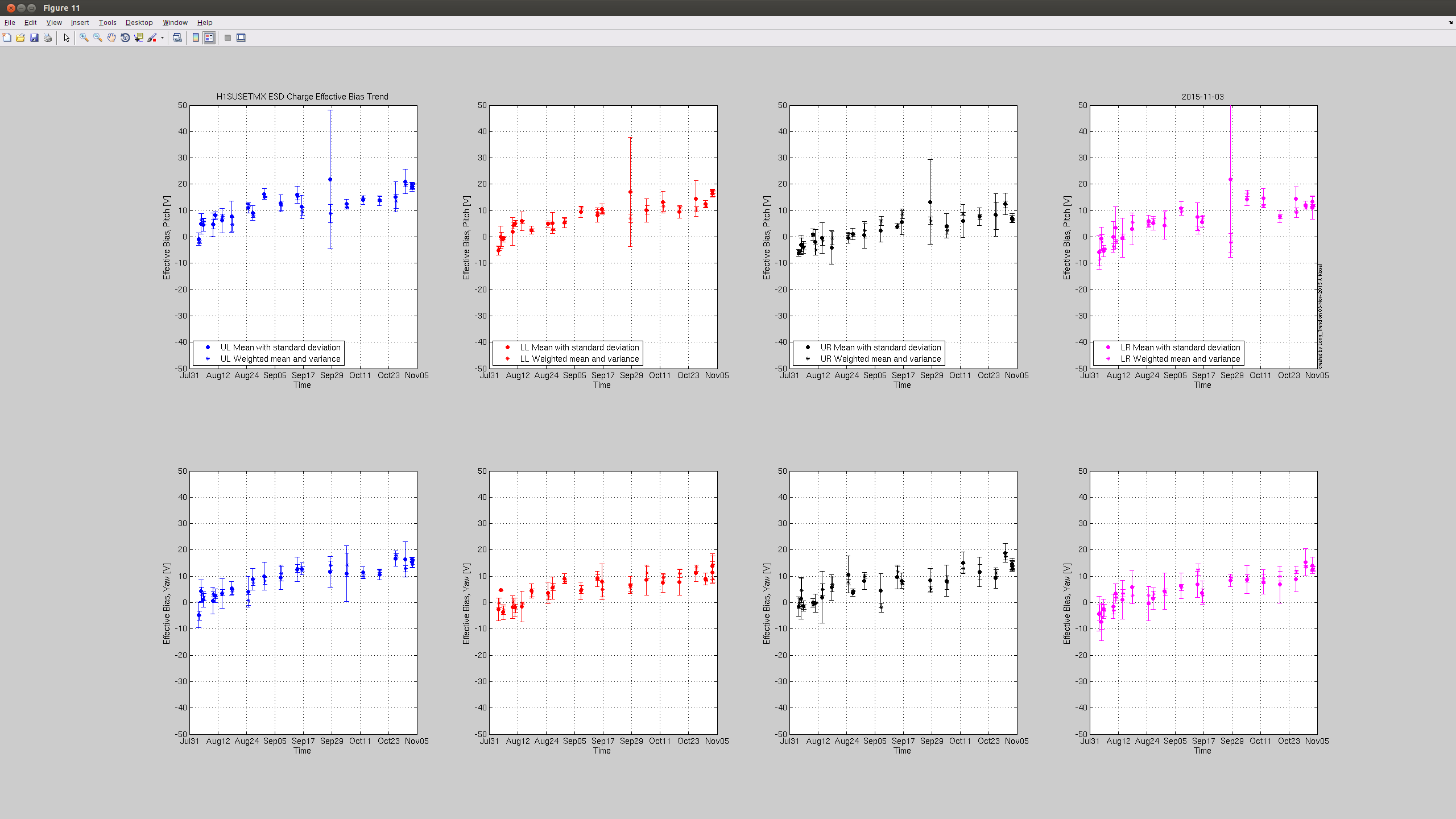
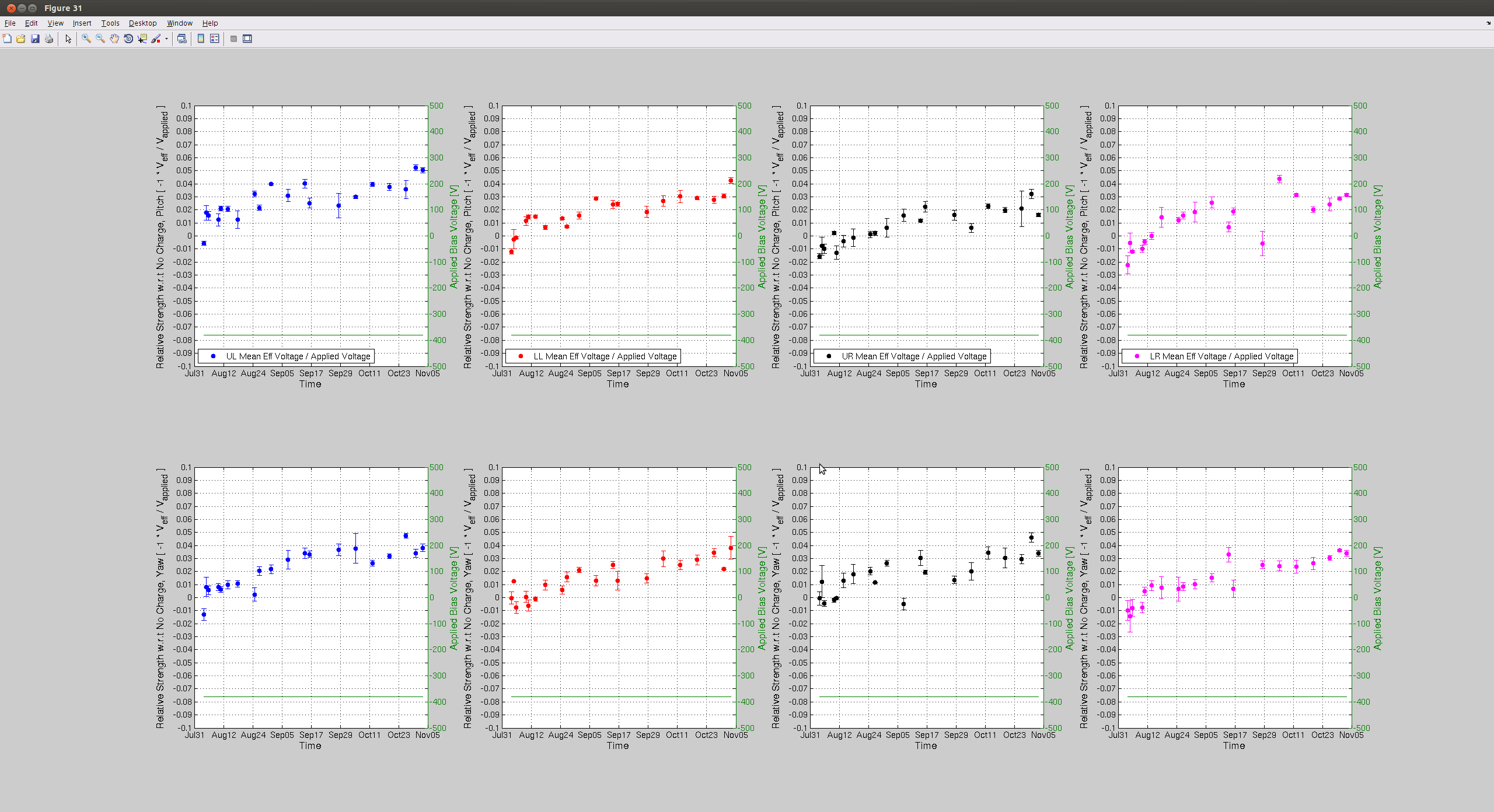
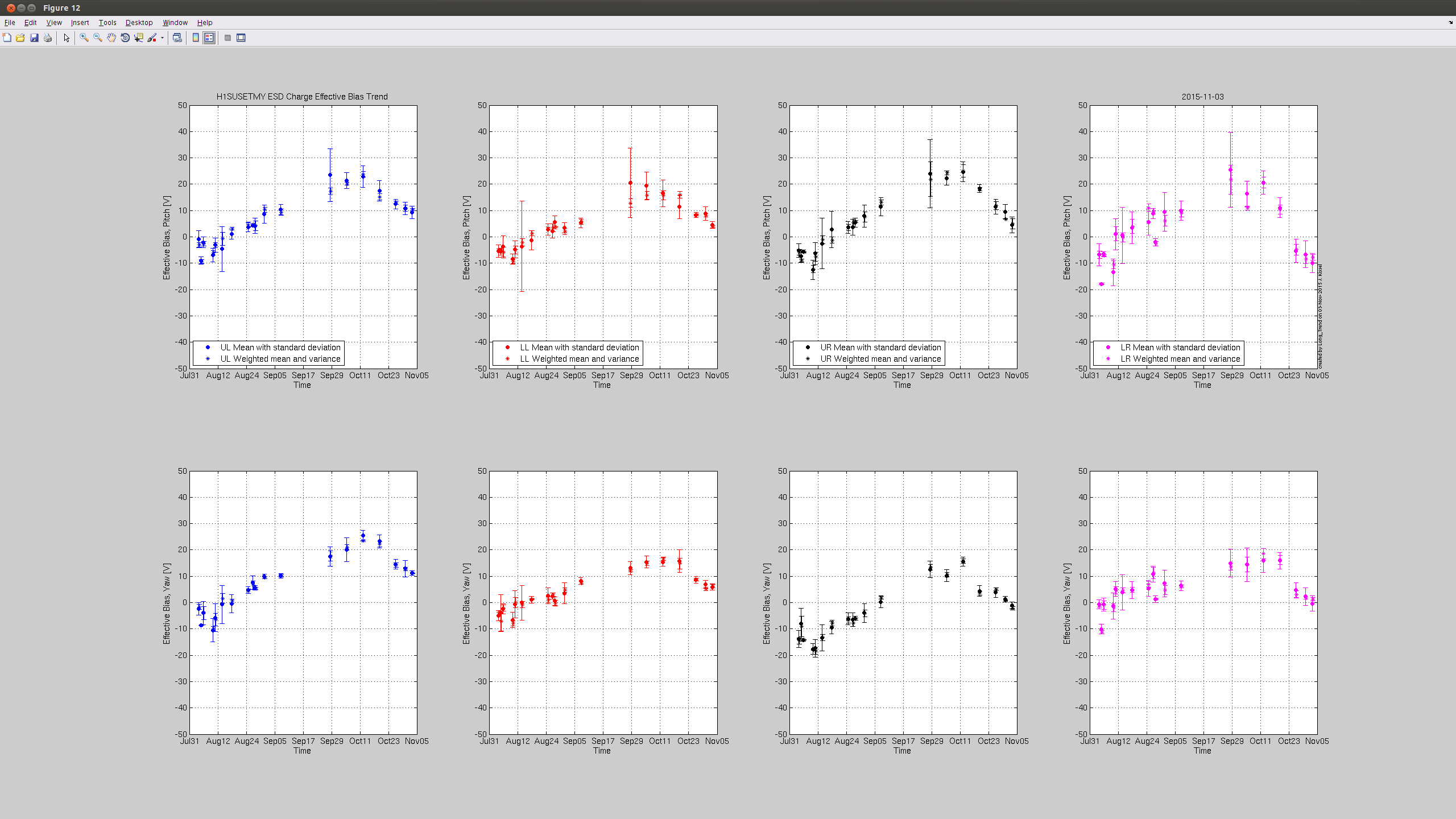
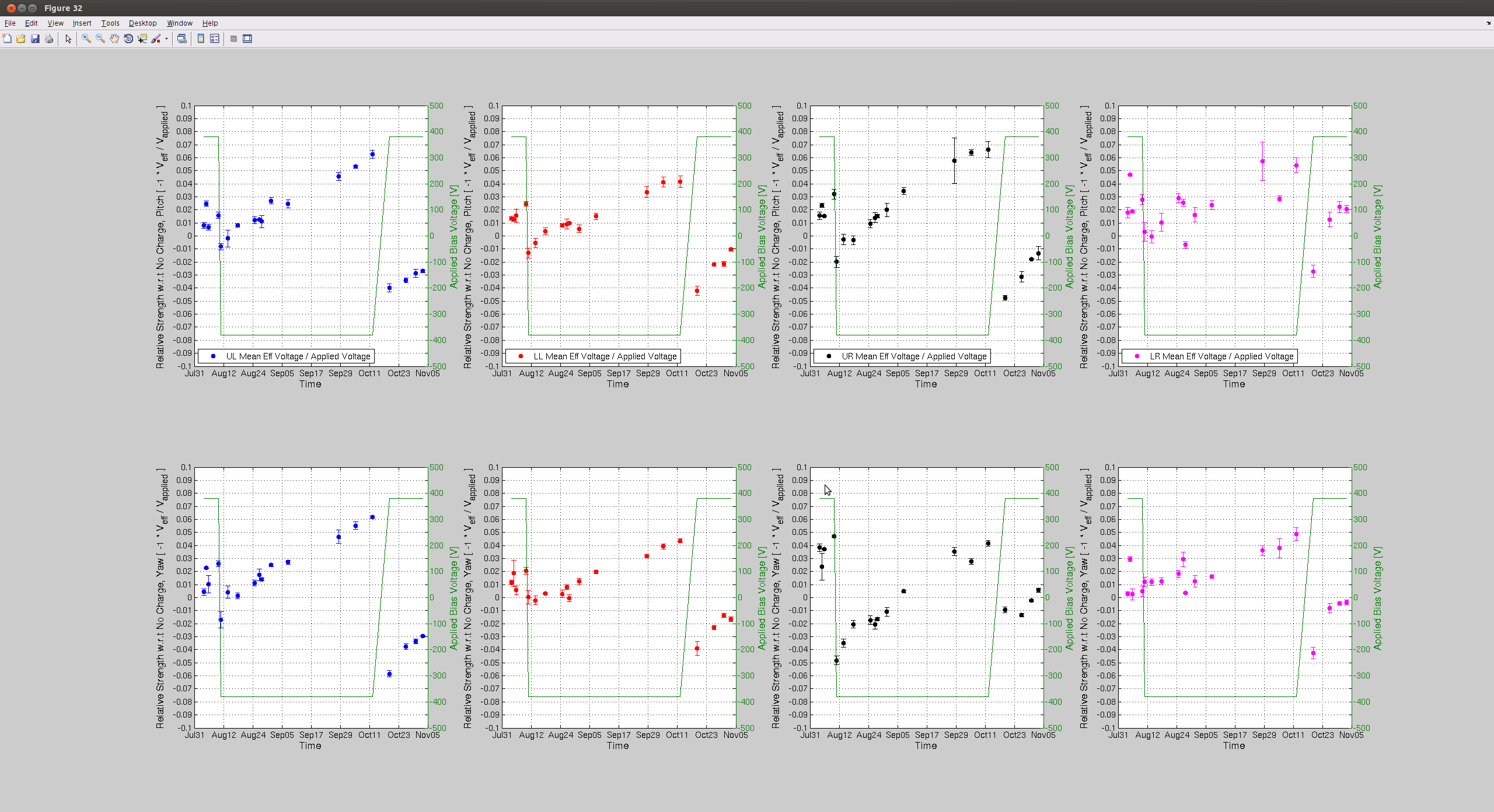
jeffrey.kissel@LIGO.ORG - posted 14:28, Tuesday 03 November 2015 (23074)
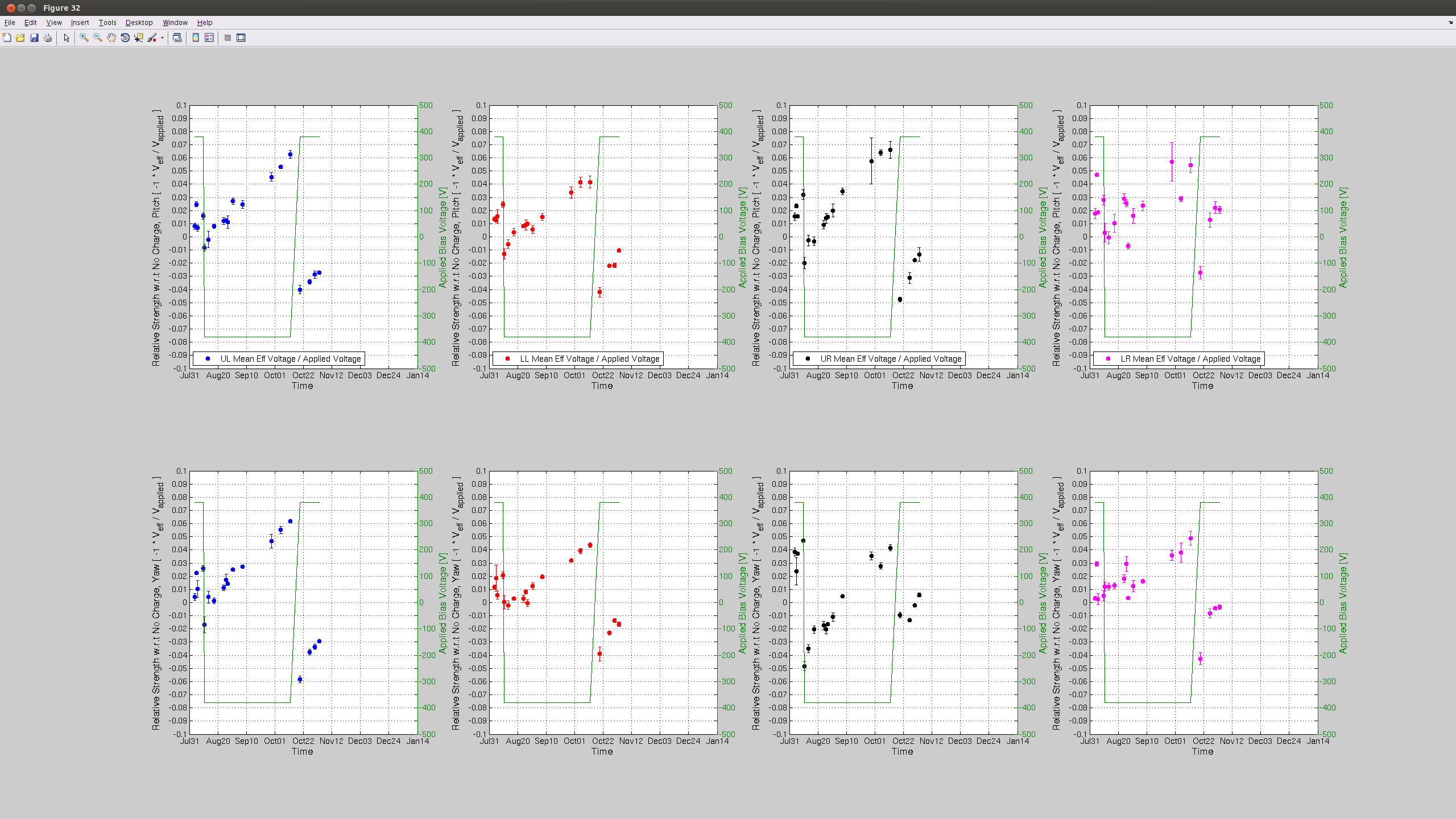
Charge Measurement Update; New Data Confirms H1SUSETMY May Need Another Bias Flip: Can Explore Other Options
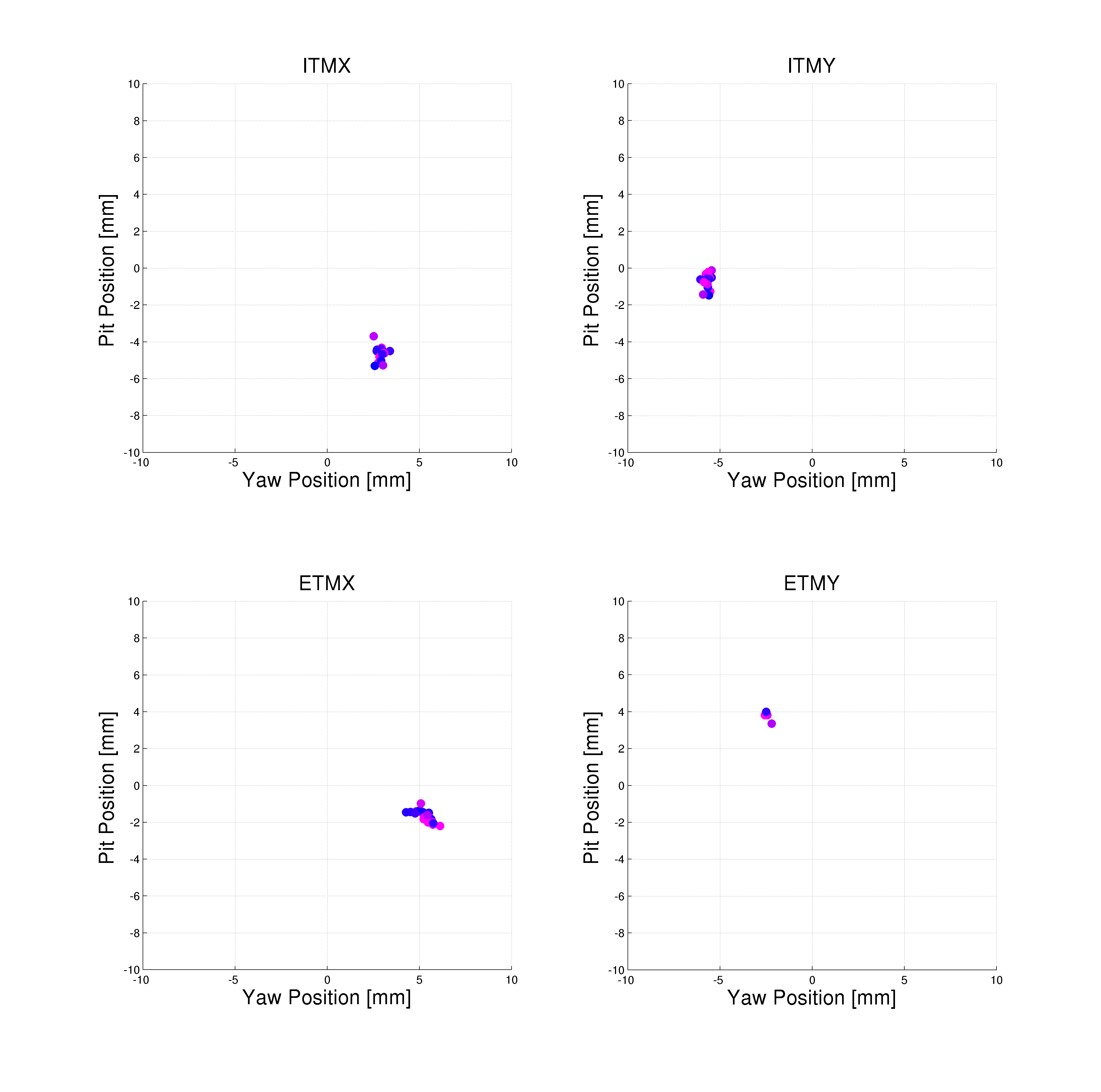
J. Kissel, J. Oberling Following the recently updated instructions, I've taught Jason how to measure charge today during the tail end of maintenance. We've gathered data today in hopes that with the bonus data that we'd gotten on Friday (LHO aLOG 22991), and last week's regular measurement (LHO aLOG 22903), we can make a more concrete conclusion about the current rate of charge accumulation on ETMY. This will help us predict whether we need to flip the ETMY bias voltage sign again before the (potential) end of the run on Jan 14. In short -- based on today's data I think we will need to flip ETMY's ESD bias voltage again before the run is over, unless we change how often we keep ETMY's bias ON, or reduce by half as LLO has done. I attach the usual trend plots for both test masses, showing the effective bias voltage as well as the trend in actuation strength (as measured by the optical lever; I hope to show the data with the last two weeks of kappa_TST as well, demostrating the longitudinal acutation strength. Stay tuned for future aLOG). Further, as the 5th attachment, I plot the same results for the actuation strength in ETMY, but with the X-Axis extended out to Jan 14th. If we take the last 4 dates worth of data points (and really the last three, since it appears the data just after the flip was anomolous), we can see, by-eye, we'll need a flip sometime around mid-to-late December 2015 if the trend continues as is. I'll call this Option (1). Alternatively, I can think of two options forward: (2) Reduce the bias voltage by 1/2 now-ish (again, as LLO has done), and take the same 8-hour shift duty-cycle hit to characterize the actuation strength at 1/2 the bias. Essentially taking the hit now or later. or (3) Edit the lock acuisition sequence in such a way that we turn OFF the H1 ETMY bias when we're not in low-noise. If we do (2), we're likely to slow down the charging rate continuously, and potentionally not have to flip the sign at all. It's essentially no different than a sign flip in characterization of its effects, but we'd *definitely* have to change the CAL-CS calibration where we did not before. In support of (3), The trends from ETMX confirm that turning OFF the ESD bias voltage for long periods of time (e.g. for 24+ hour-long observation segments [yeah!]) will reduce the charge accumulation rate. It's unclear (to my, right now) how *much* ETMY ESD OFF time we would get (though it is an answerable question by looking at a sort-of "anti"-duty-cycle pie chart), but I have a feeling that any little bit helps. This would require continued vigilance on charge measurements. Why bother changing anything, what's a well-known 10-20% systematic, if you're going to correct for it at the end of the run, you ask? The calibration group's stance on this is that we have many systematics of which we need to keep track, some of which we have no control over (unlike this one) and some of which we haven't yet identified. We believe we're within our required uncertainty budget, but unknown systematics are always killer. As such, we want to at least keep the controllable, known systematics as low as reasonable. If we can recover/reduce a slowly increasing 10% systematic in the instrument, without having to digitilly correct for it, chunk up the analysis segments into many "epochs" where you have to do this or that different thing over the course of the run, and/or they have different uncertainties, then we do so. It's essentially the "if you can, fix the fundamental problem" argument, especially considering the other known and unknown systematics over which we don't have control. As such, and because the accumulation is still sufficiently slow (~8 [V/week] or ~2 [% Act. Strength Change/week]) that we can decide when to make the change (and which of the options to persue) based on man-power avaibility of the next holiday-full two months. On a side-note: today's data set contains only contains 3 points per quadrant, where we normally get 4 to 5. This should not have a huge impact on accuracy, or our ability to make a statement about the trend, especially since the sqrt(weighted variance) uncertainty bars are so small. It might also mean, of pinched for maintanance day or bonus time, it may be OK to continue to get only 3 data points instead of 5.
Images attached to this report