Summary of Tuesday's mainteance work:
h1calex model change for hardware injection
Jeff, Jim, Dave: WP5553, ECR1500386
h1calex model was modified to add CW and TINJ hardware injection filter modules. Also ODC channel names were changed from EX to PINJX. Three new channels were added to the science frame (HARDWARE_OUT_DQ and BLIND_OUT_DQ at 16k, ODC_CHANNEL_OUT_DQ at 256Hz)
The DAQ was restarted. Conlog was rescanned to capture the new ODC channel names.
Guardian DIAG_EXC node was modified to permit both calex and calcs excitations while in observation mode.
MSR SATABOY firmware upgrades
Carlos: WP5544
The two Sataboy RAID arrays used by h1fw1 had their controller cards firmware upgraded. Also the one Sataboy used by the DMT system was upgraded. No file system downtime was incurred.
Beckhoff SDF testing
Jonathan, Dave: WP5539
Tested Gentoo version of the SDF on h1build machine as user controls. For initial testing we are only connecting to h1ecatcaplc1. We discovered that this version of the sdf system set all the PLC1 setpoints each time it was restarted, so ECATC1PLC1 was reset several times between 10am and 1pm PDT Tuesday morning. This system was left running overnight for stability testing. We discovered that some string-out records cannot be changed. If we change the string for these records (when we accidentally applied the safe.snap strings on restarts) the PLC immediately (100uS later) reset to an internally defined string.
Long running CDS Server reboots, workstation updates
Carlos:
As part of our twice-yearly preventative maintenance, Carlos patched and rebooted some non-critical servers. CDS workstations were inventoried and updated.
Complete OBSERVE.snap install
Dave: WP5557
The models which were still running with safe.snap as their SDF reference were updated to us OBSERVE.snap. Models in the following systems were modifed: IOP, ODC, SUSAUX, PEM. Their initial OBSERVE.snap files were copied of their safe.snap.
Several systems had static OBSERVE.snap files in their target areas instead of a symbolic link to the userapps area. I copied these files over to their respective userapps areas and check them into SVN. During Wed morning non-locking time, I moved the target OBSERVE.snap file into an archive subdirectory and setup the appropriate symbolic links. I relinked within the 5 second monitor period, so no front end SDF reported a "modified file".

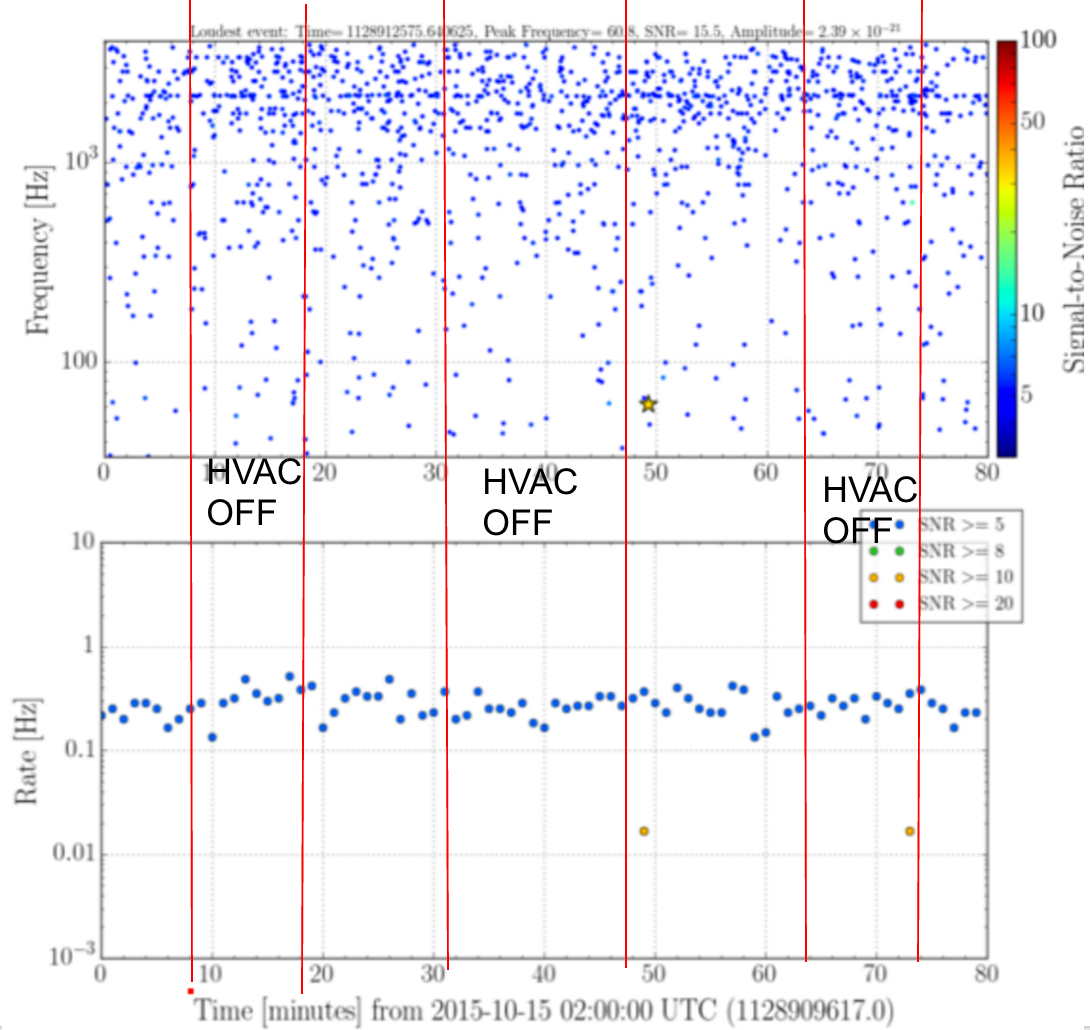
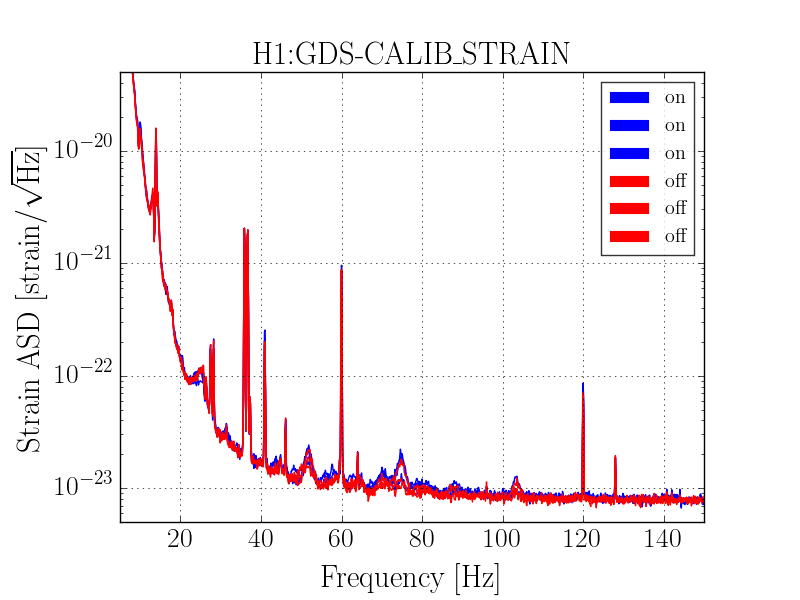
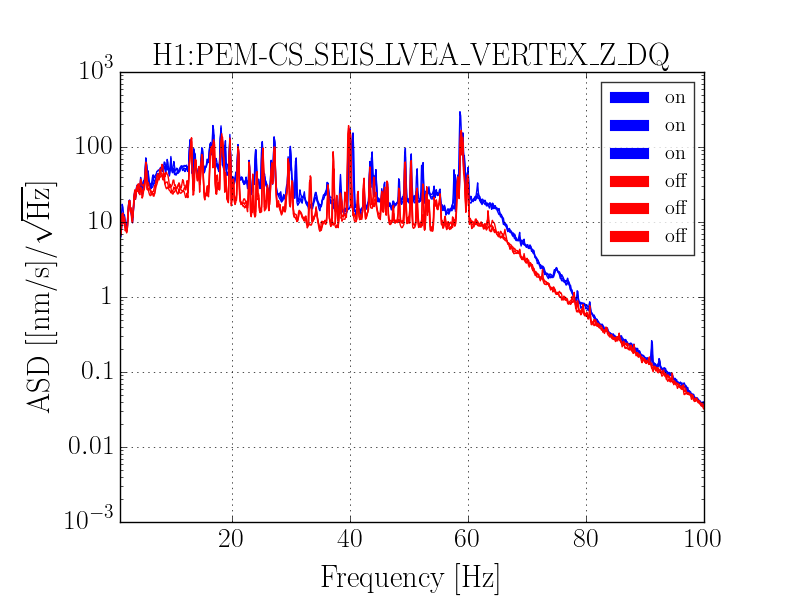
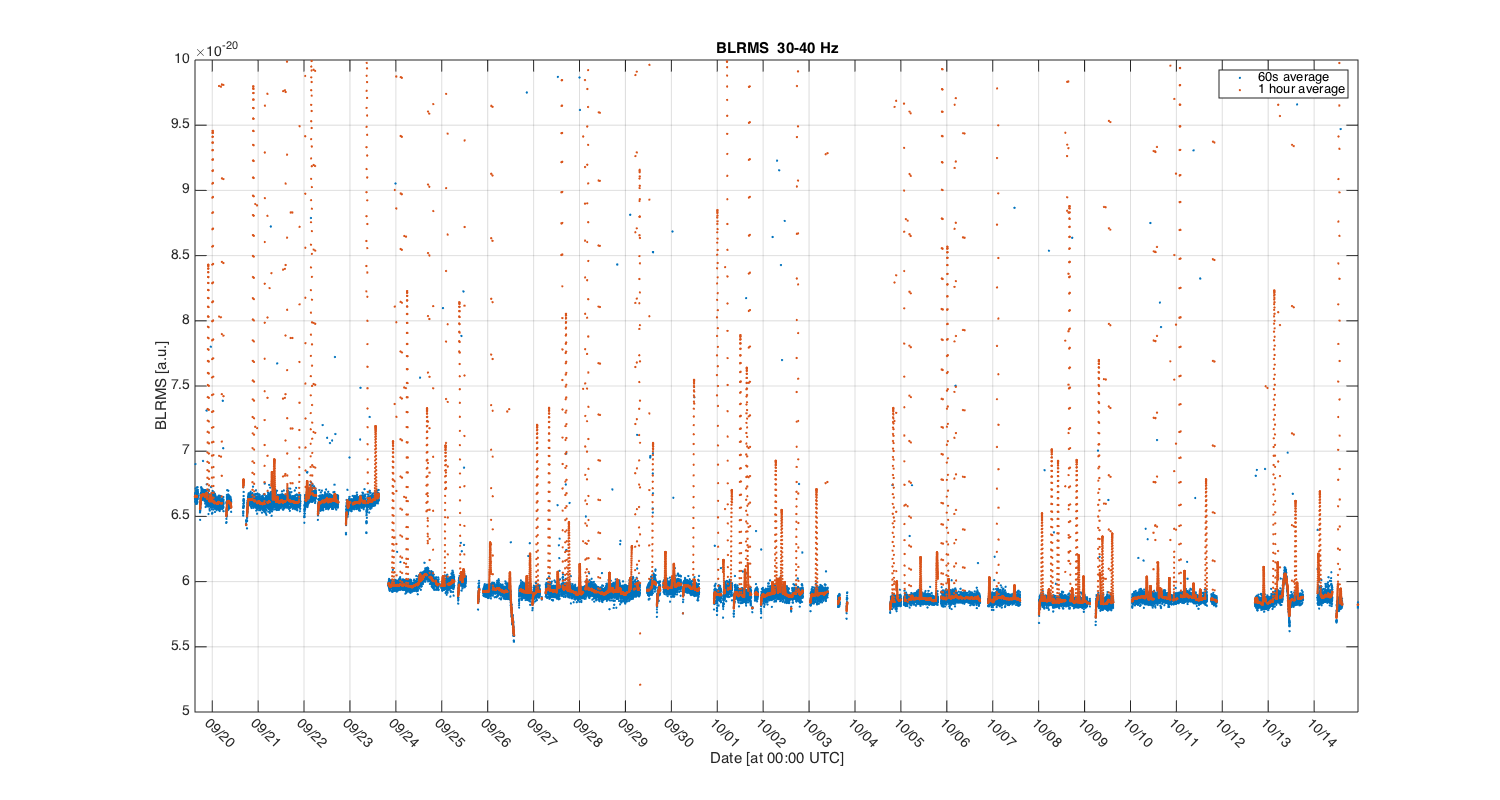
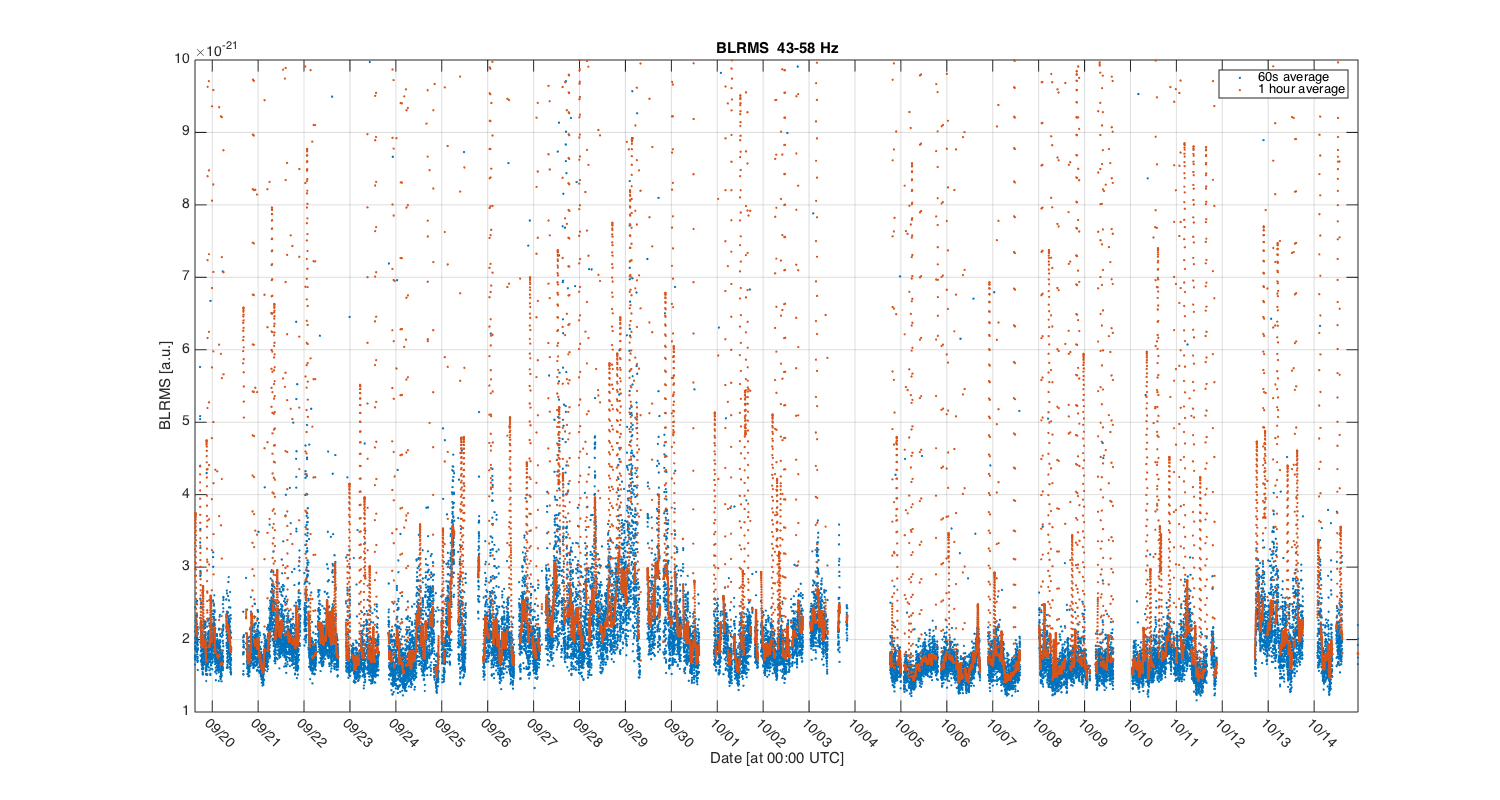
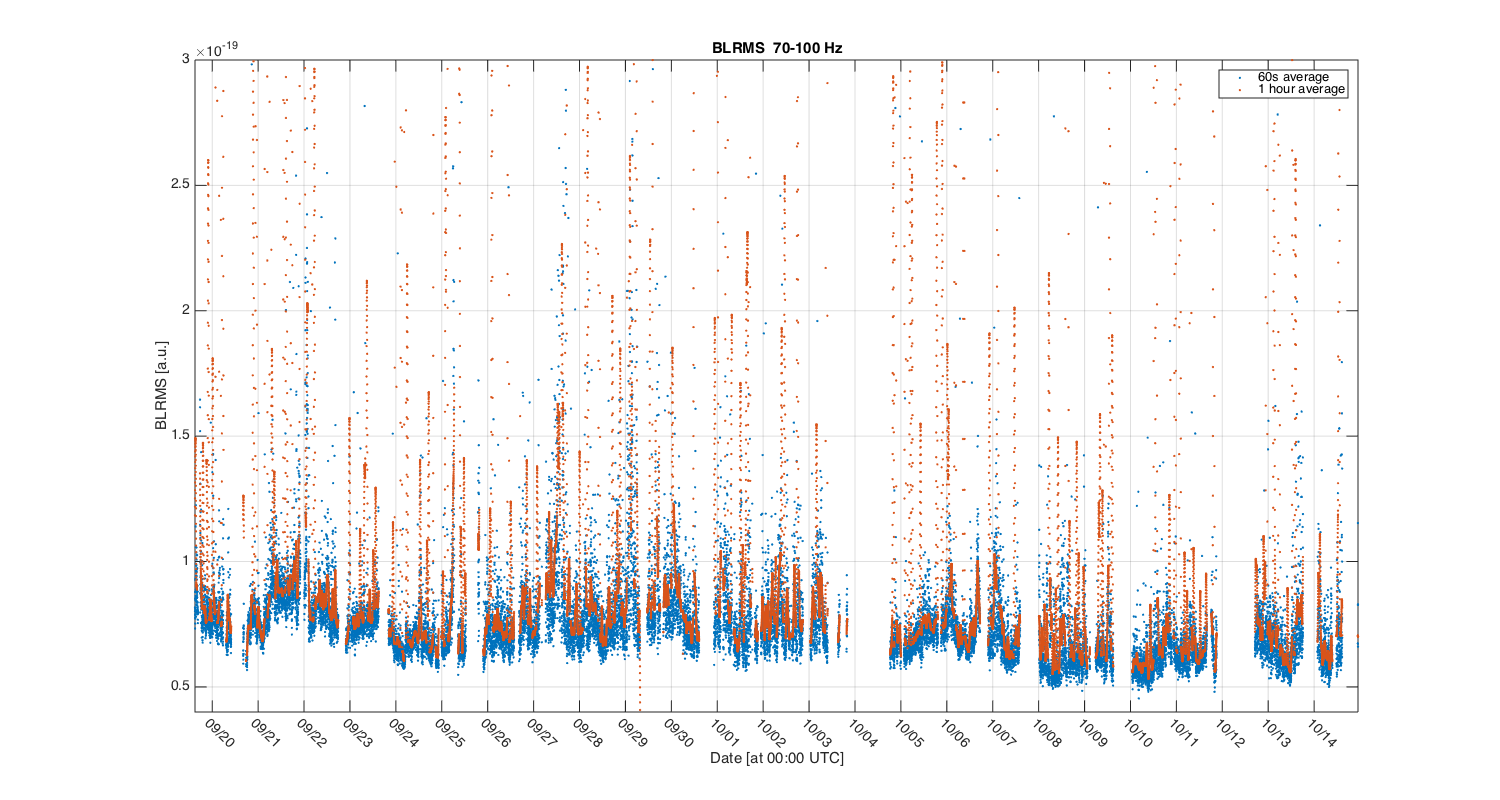
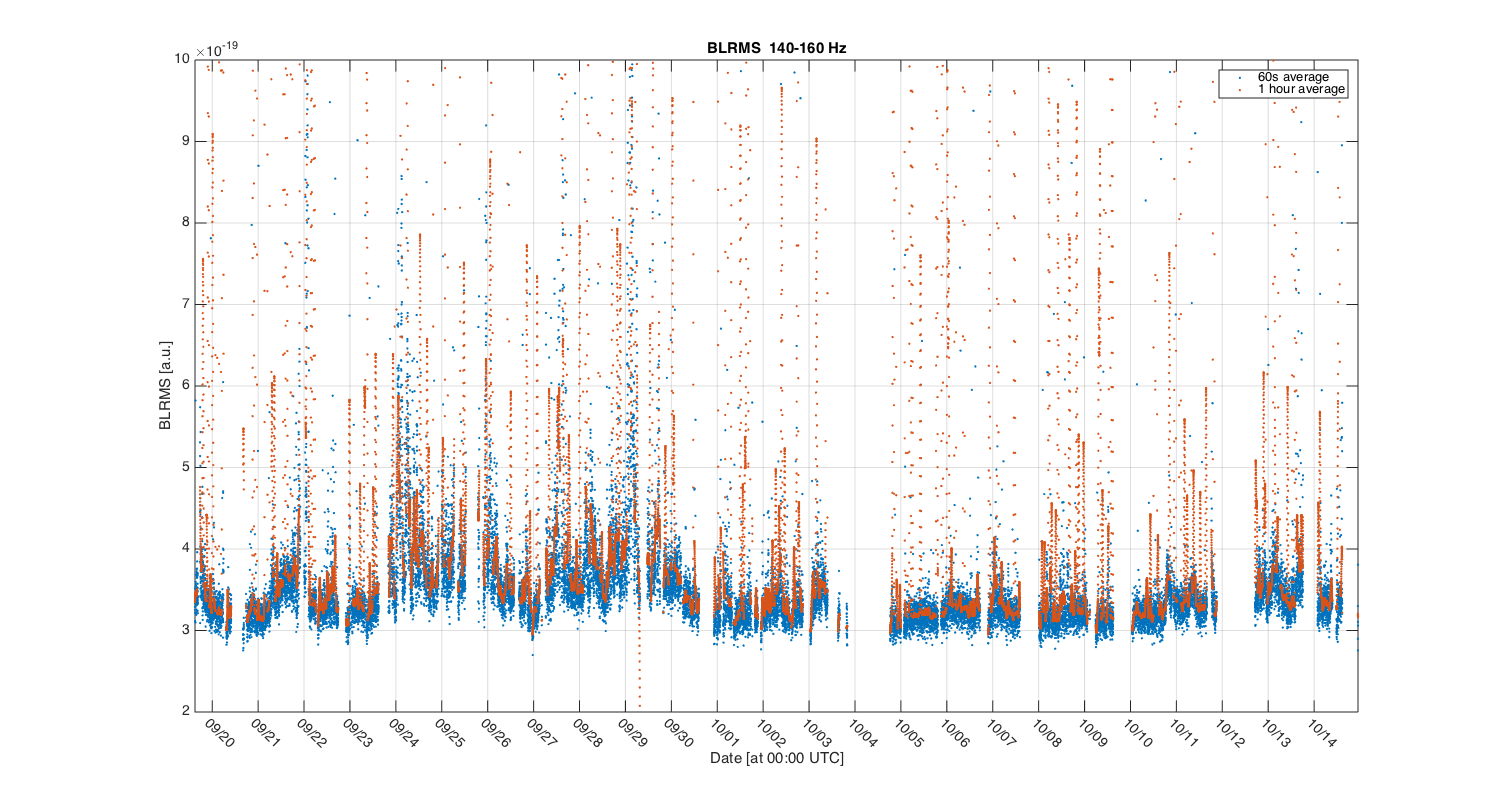
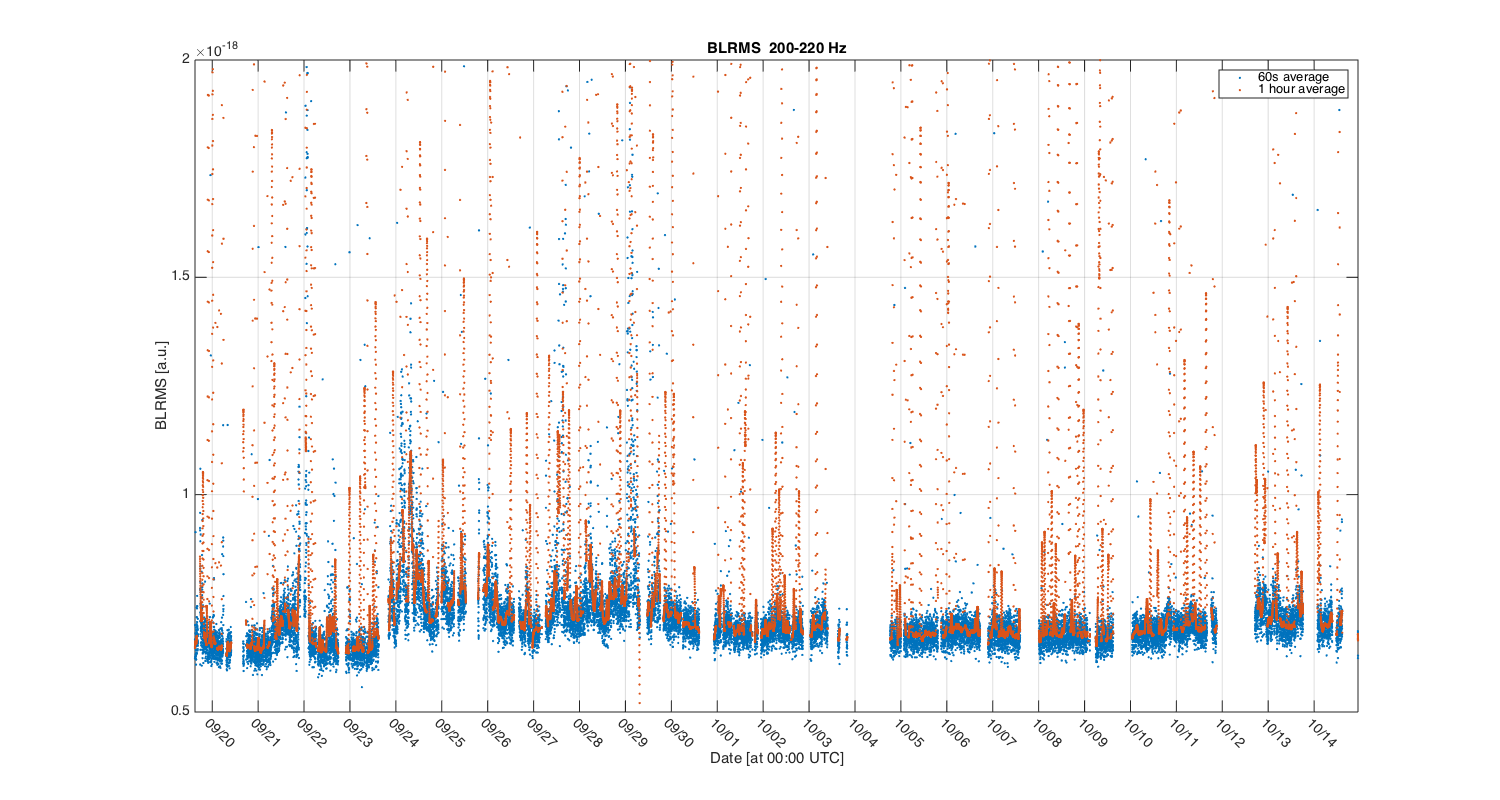
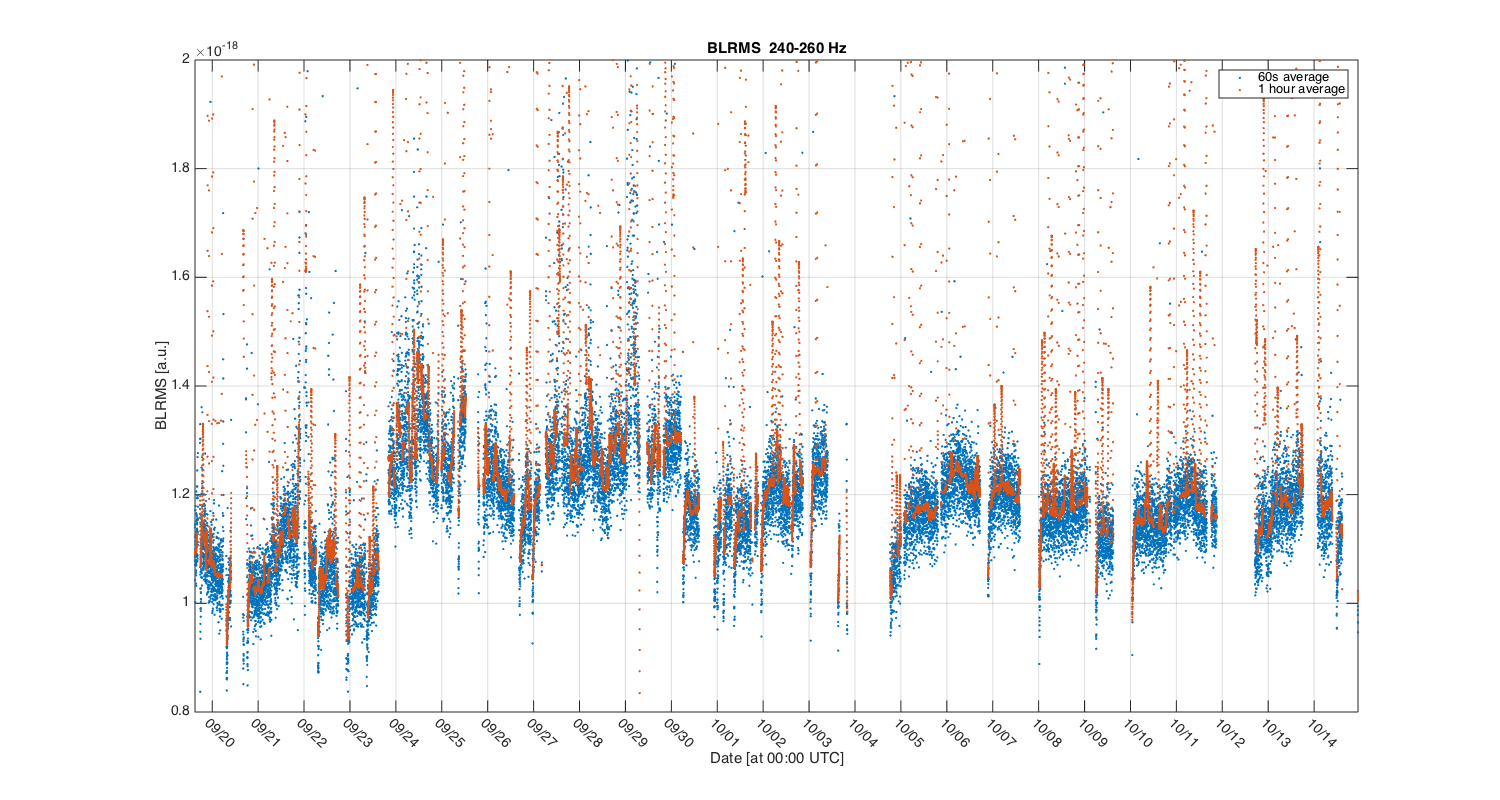
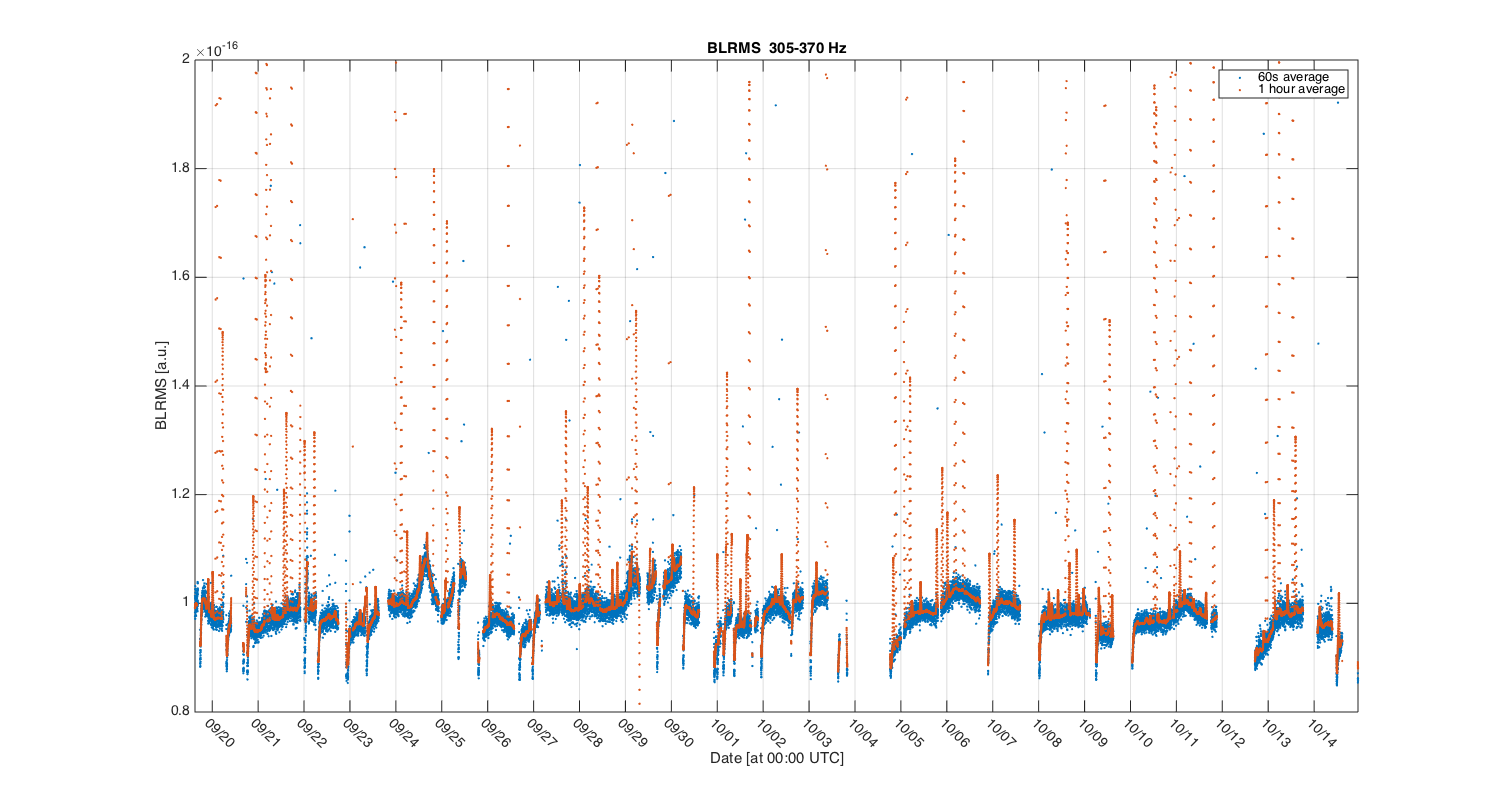
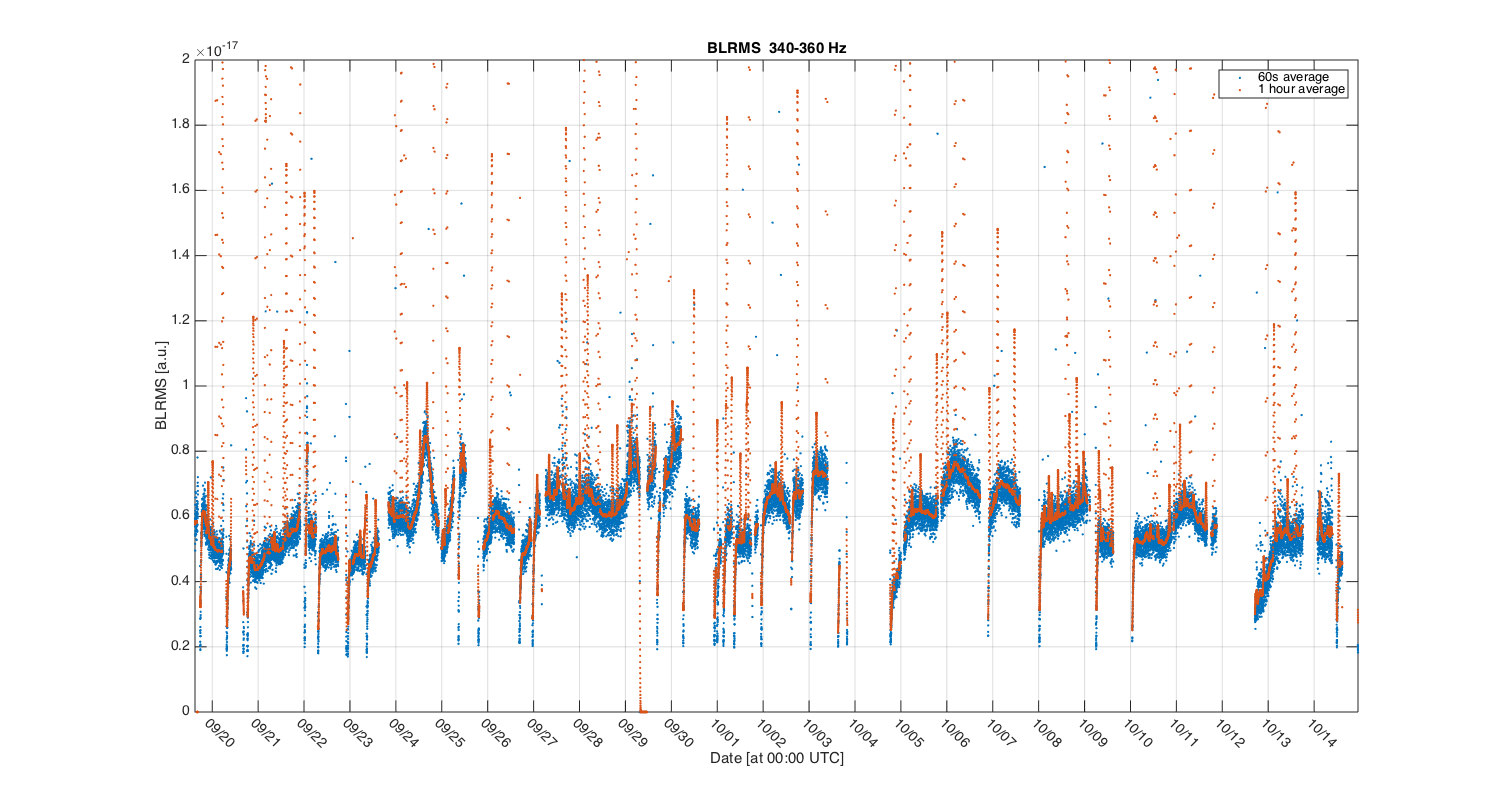



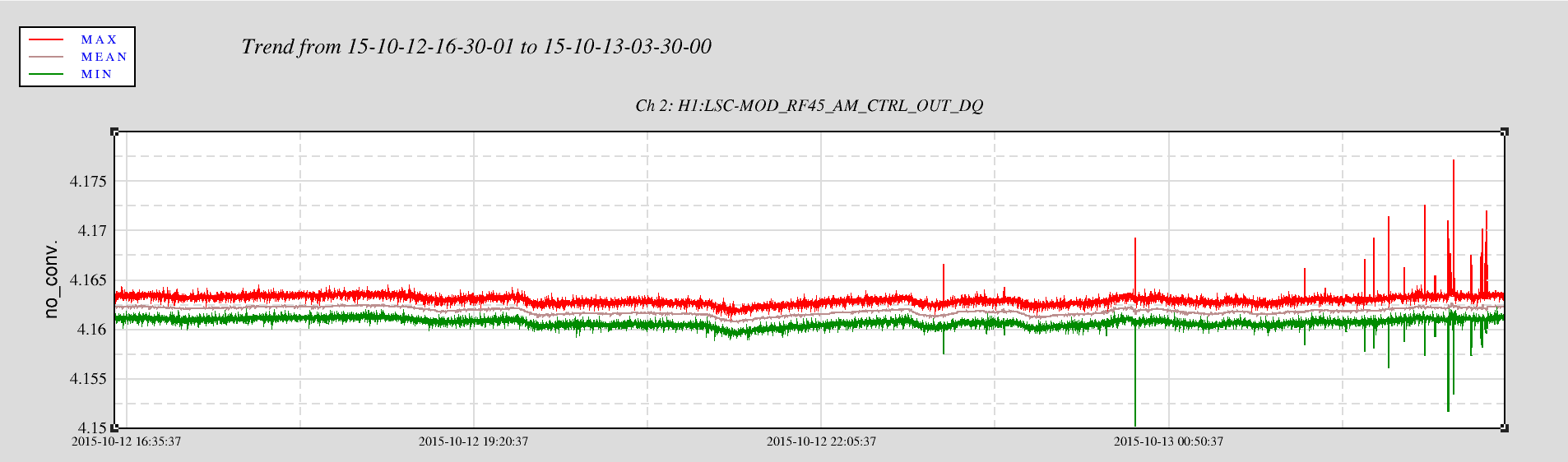
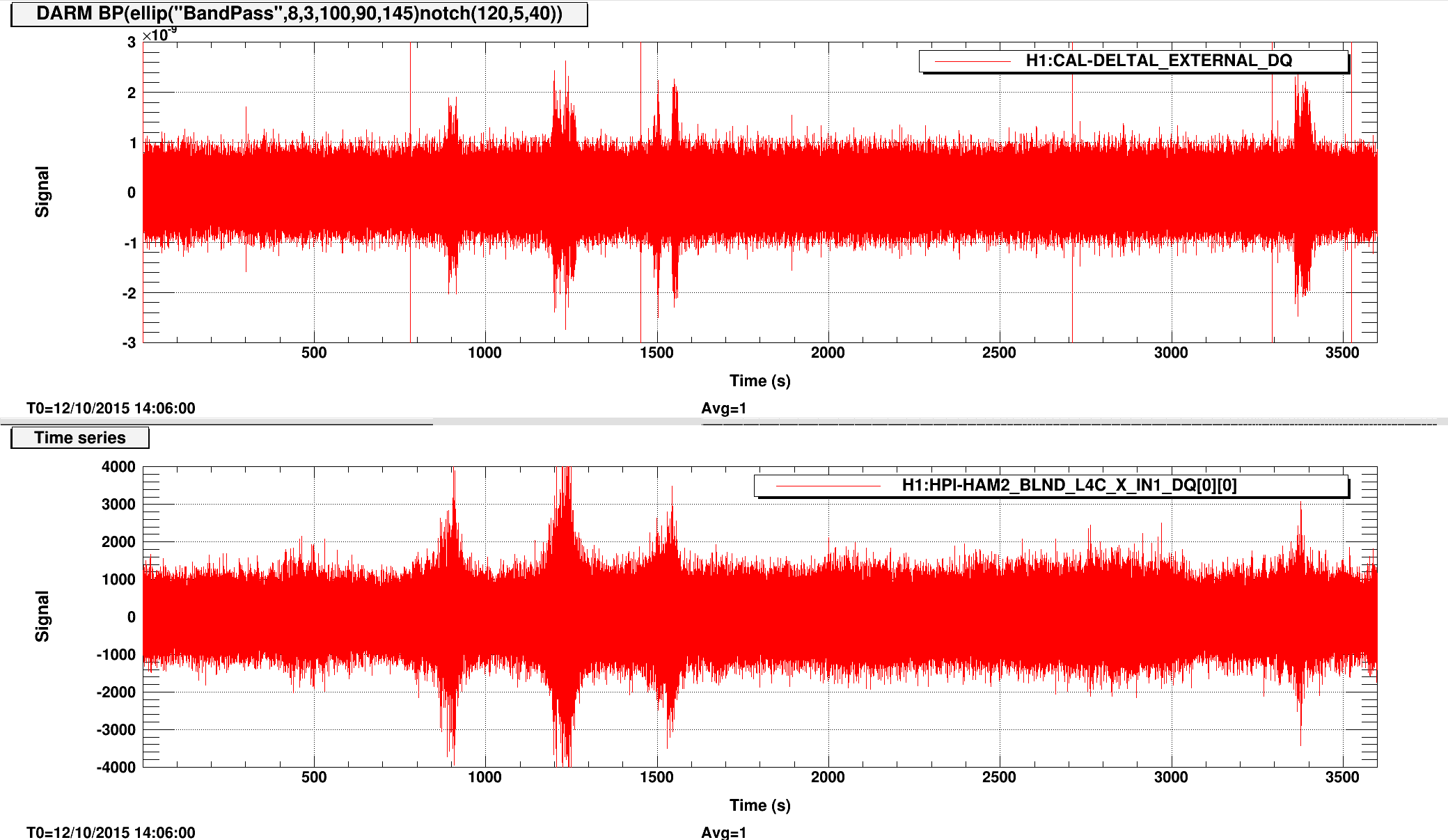
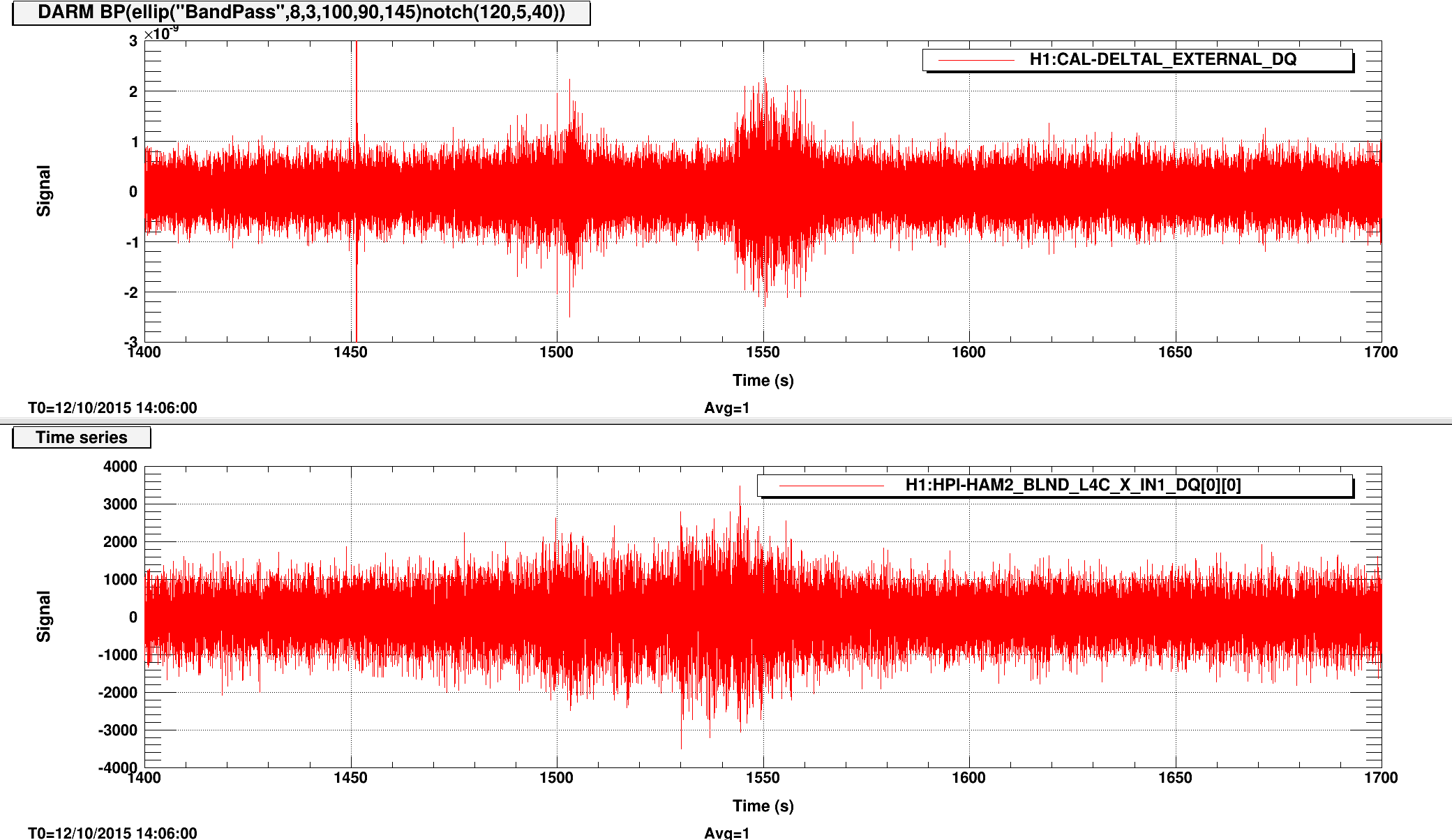
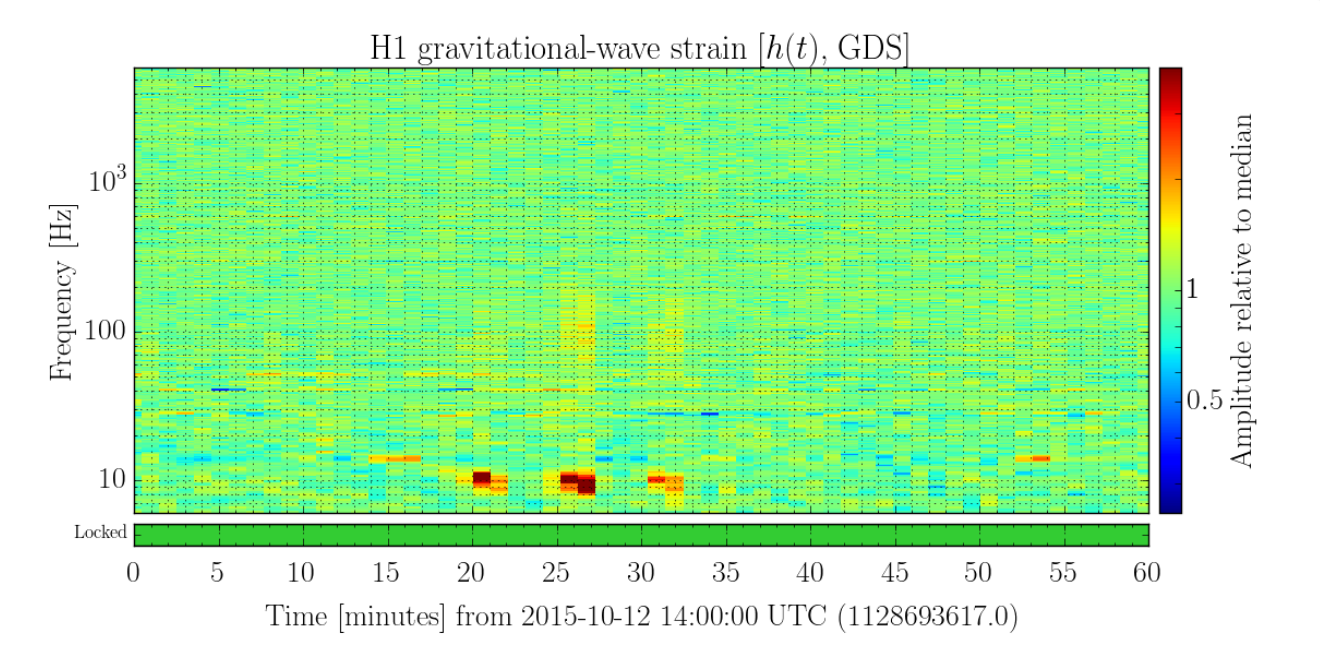
{kind=link}
{kind=link}
{kind=link}
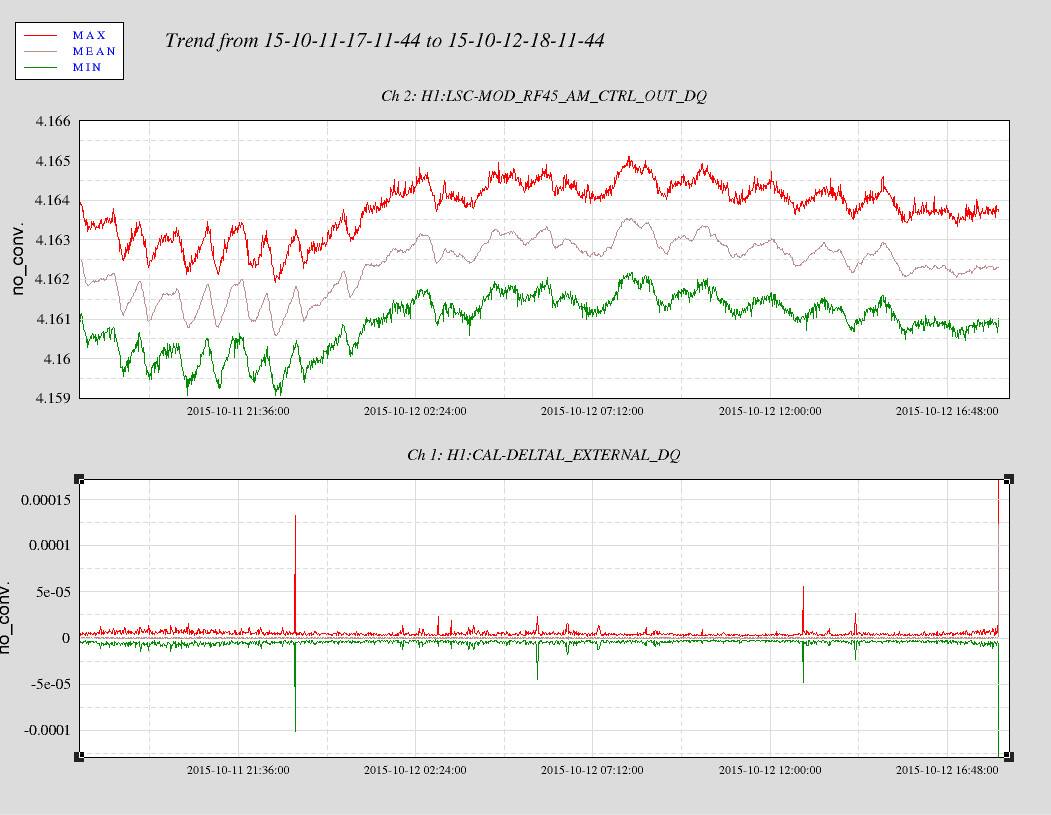
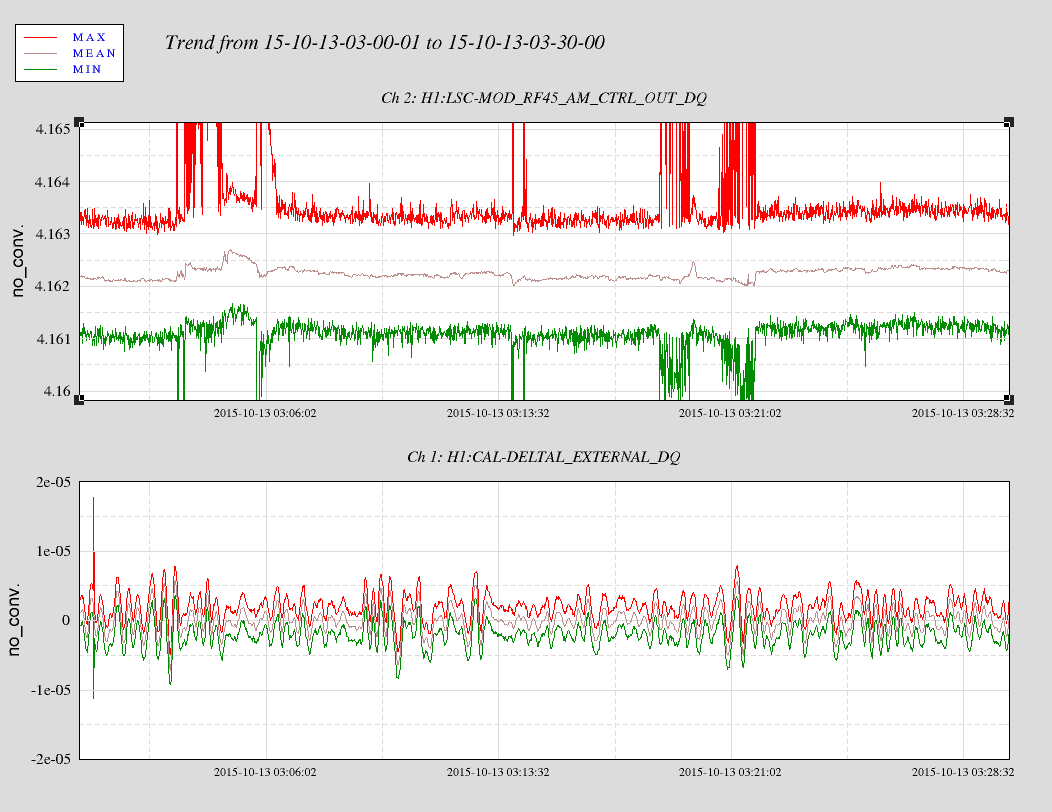
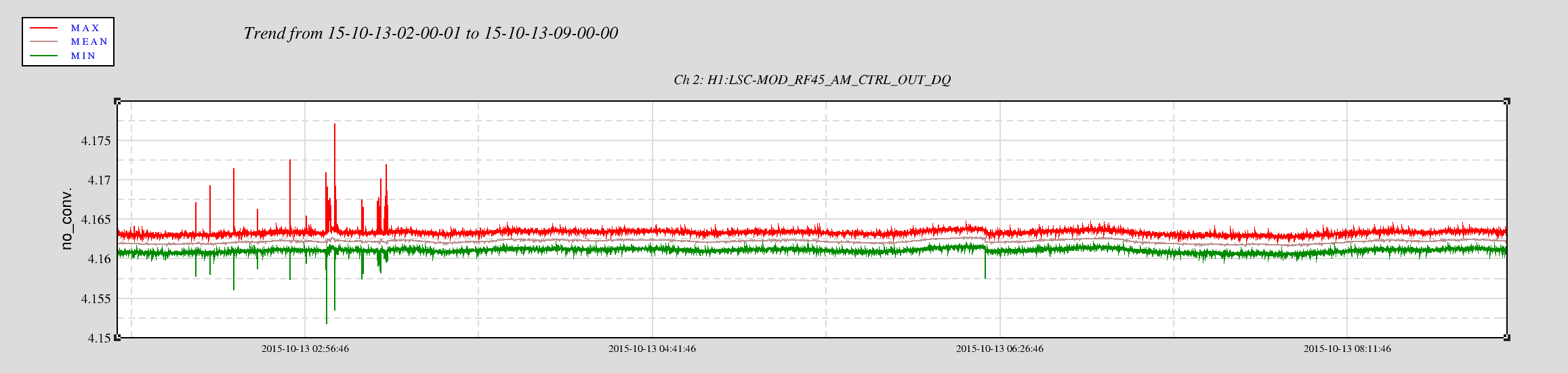
For reference here is a plot showing the temperature excursion which is believed to have caused a lockloss. 7 days shown.
BLUE is the YEND temperature, RED is XEND, and BLACK is the LVEA.
YEND experienced ~ +/- 1degree F of a swing.