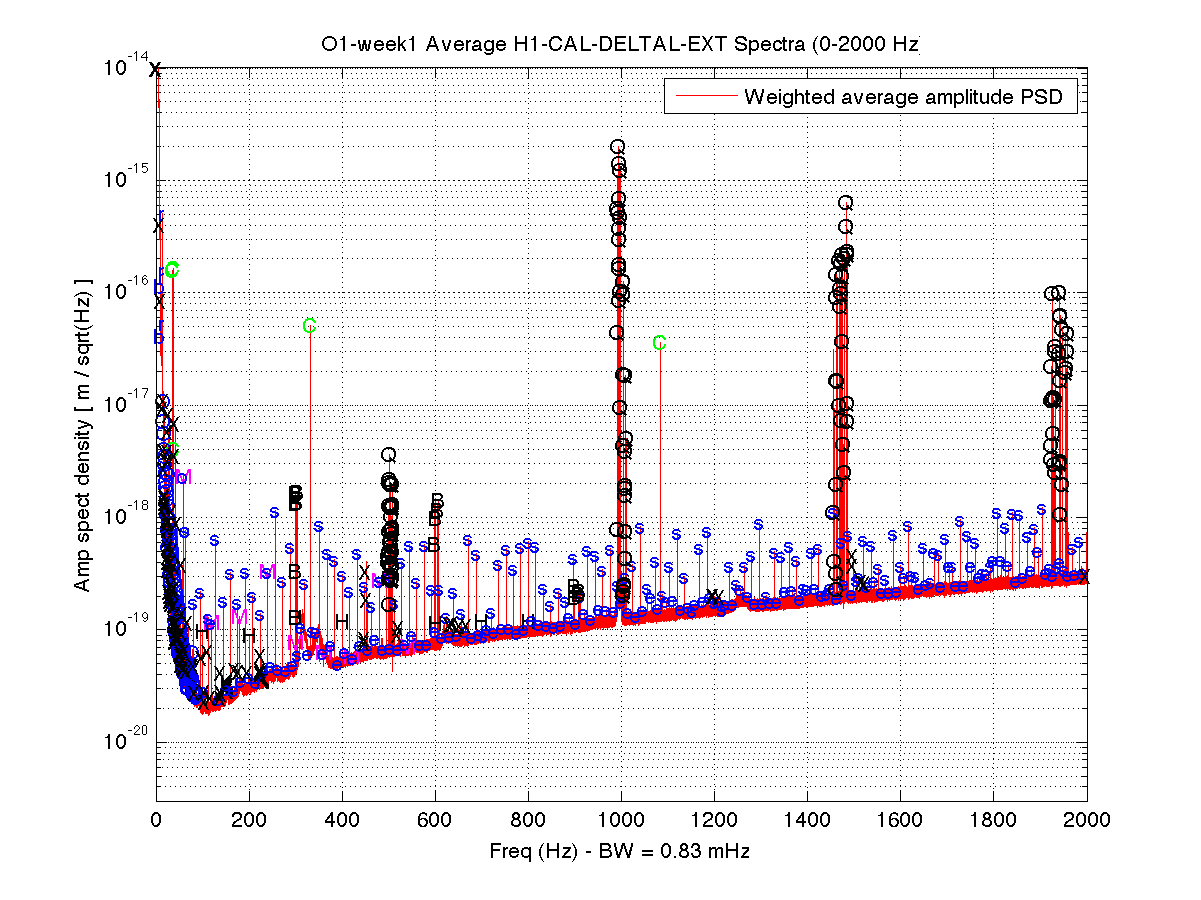
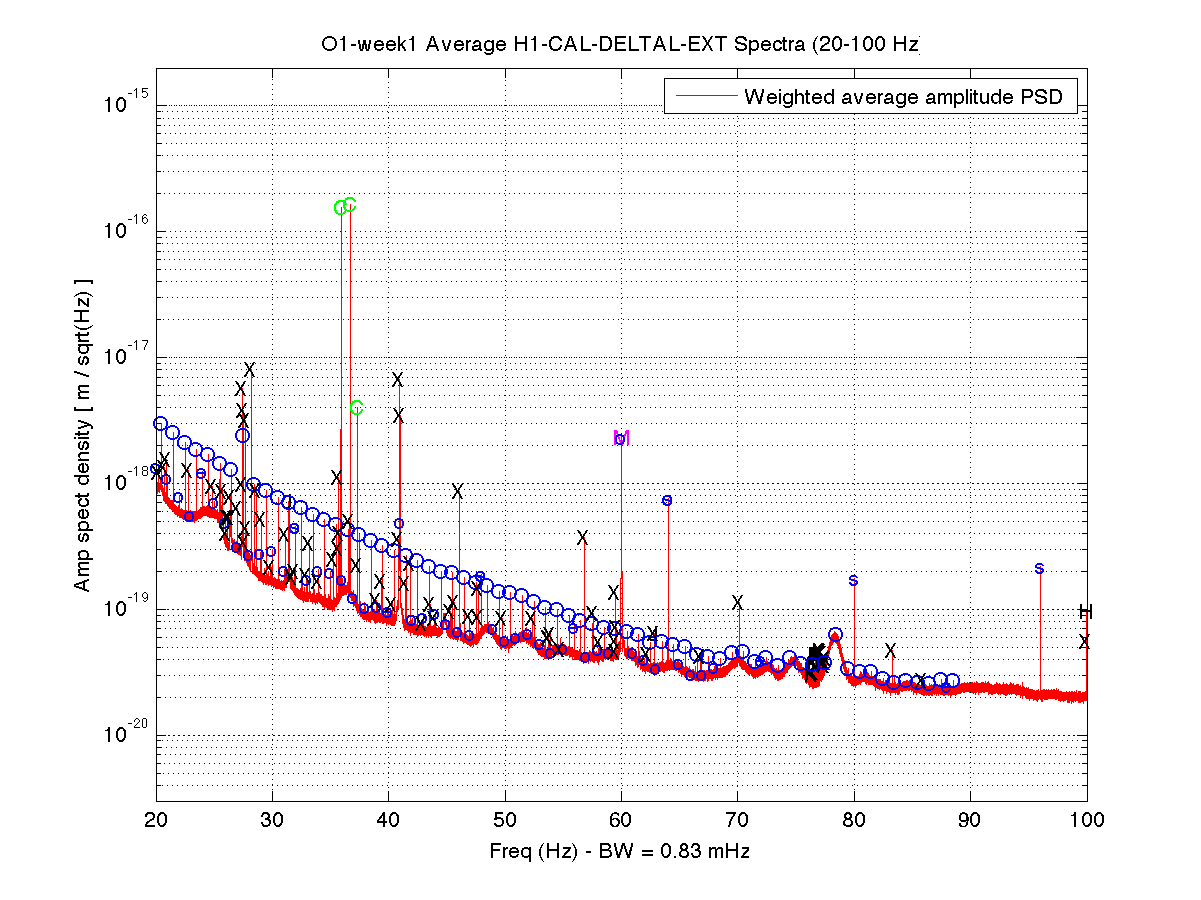
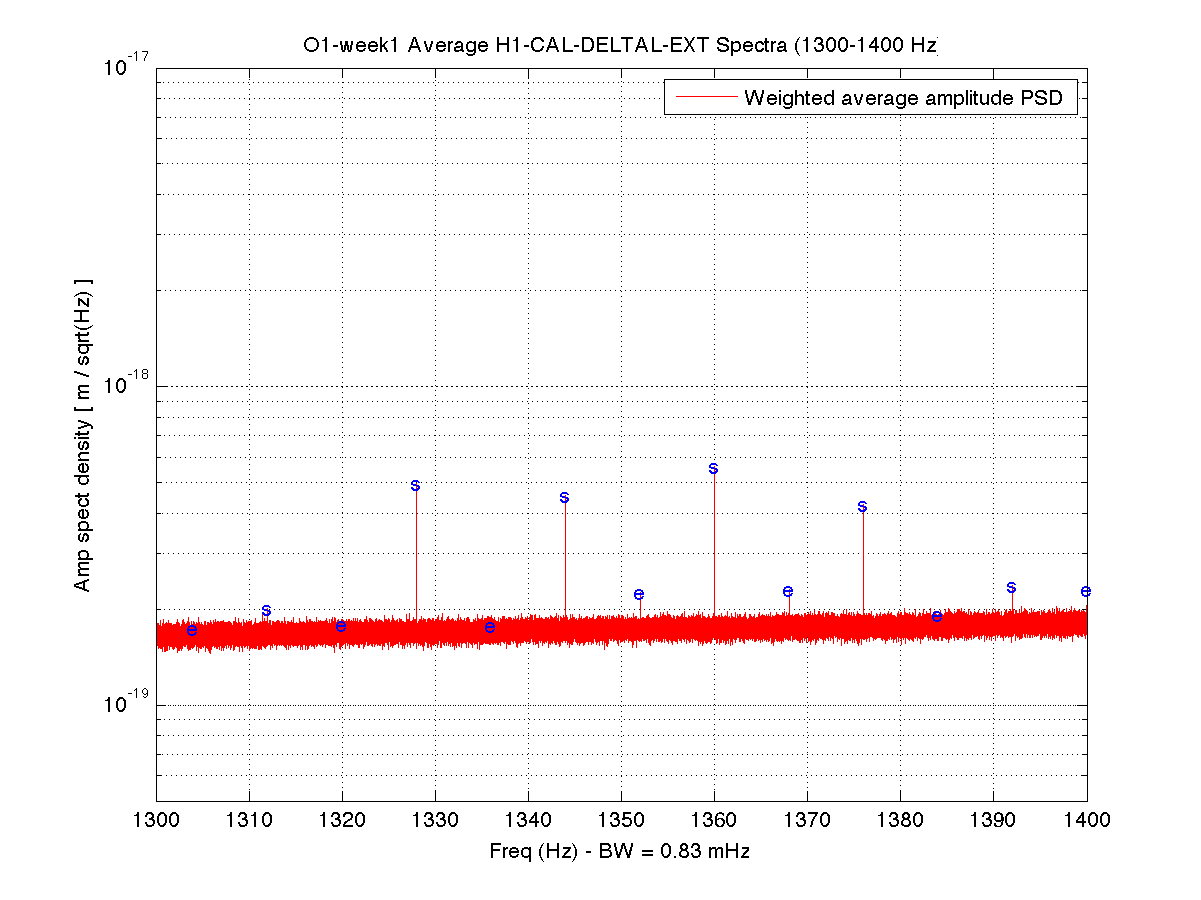
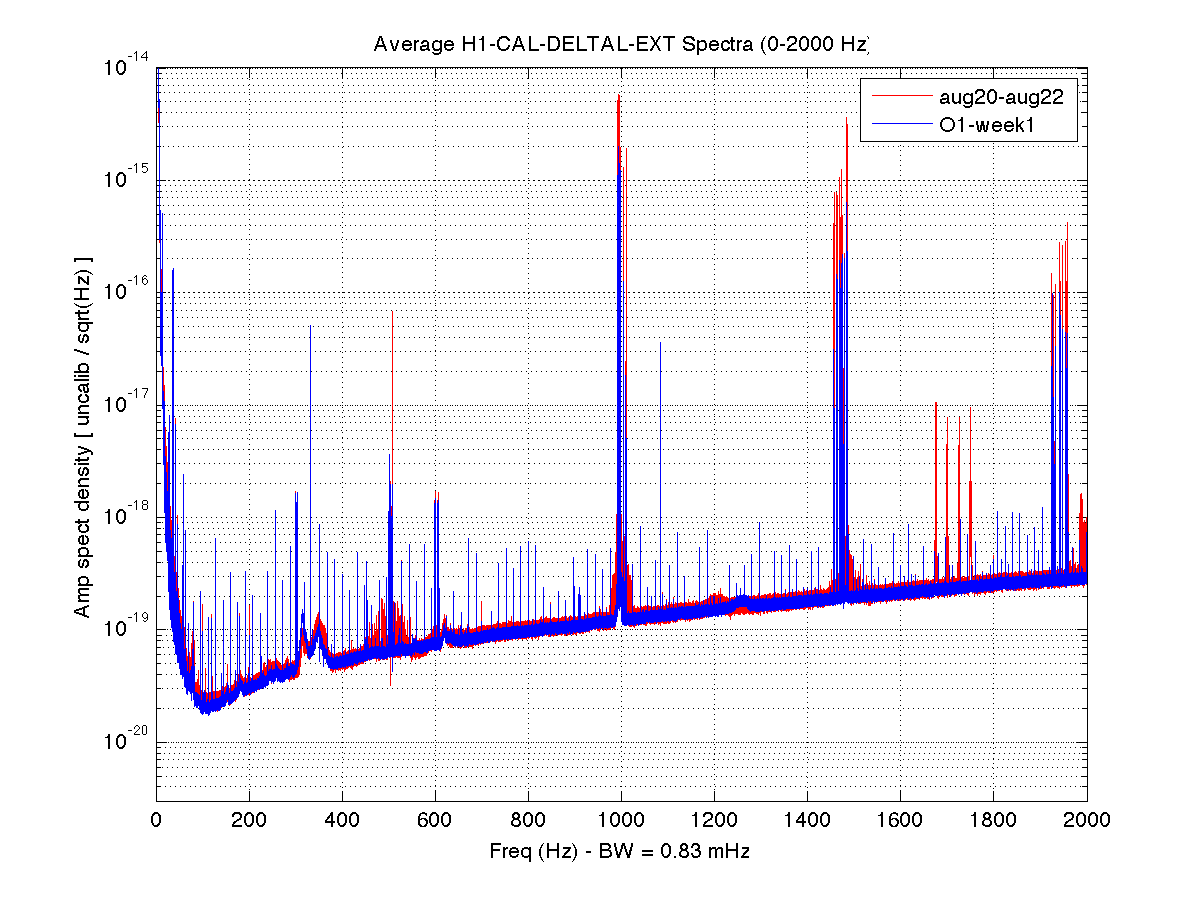
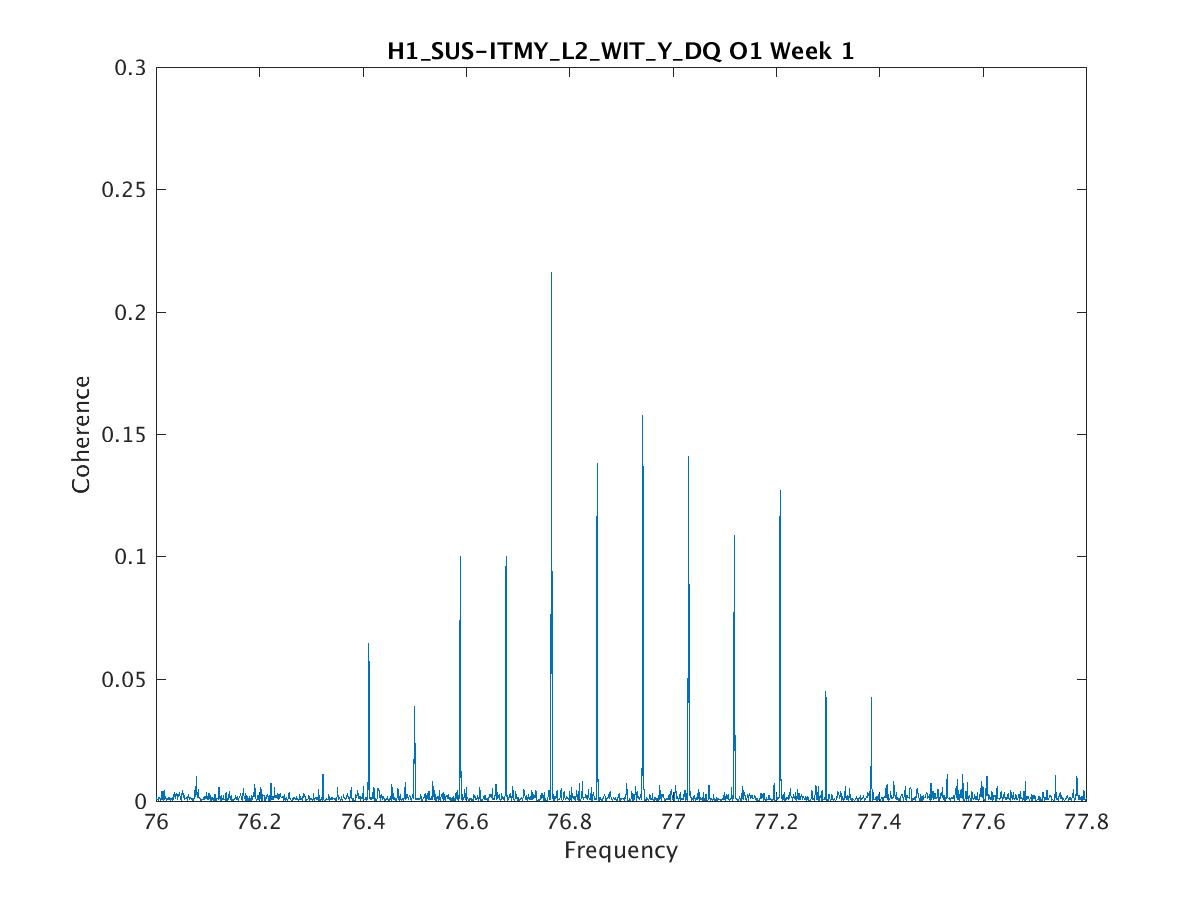
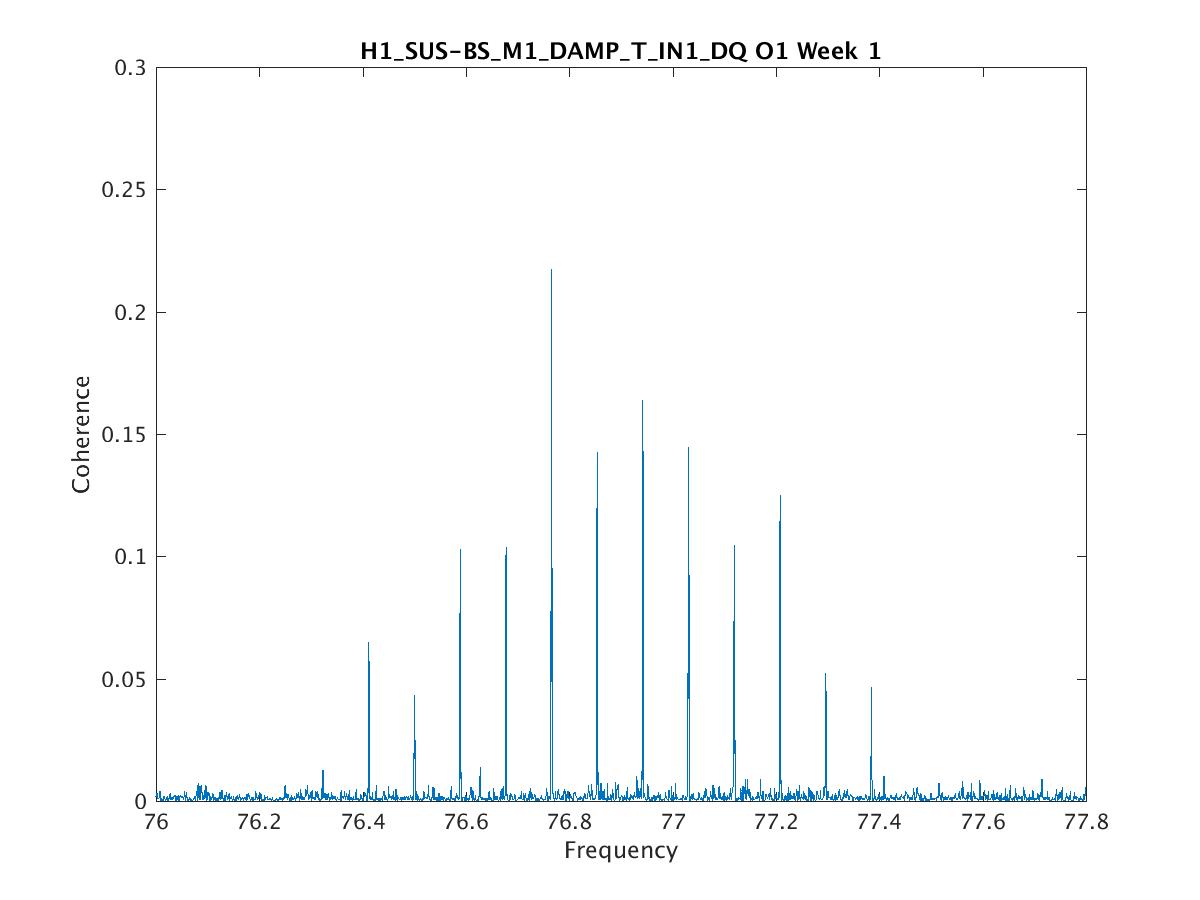
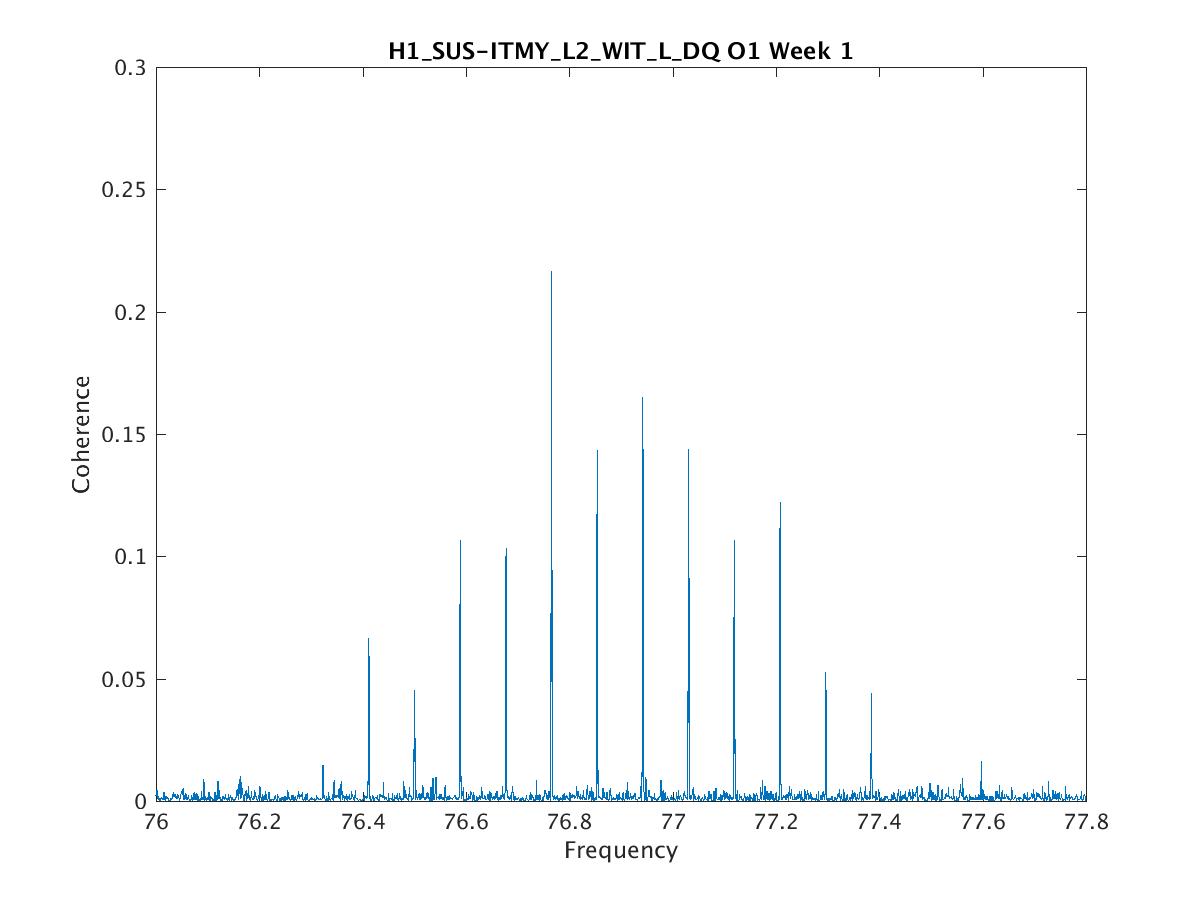
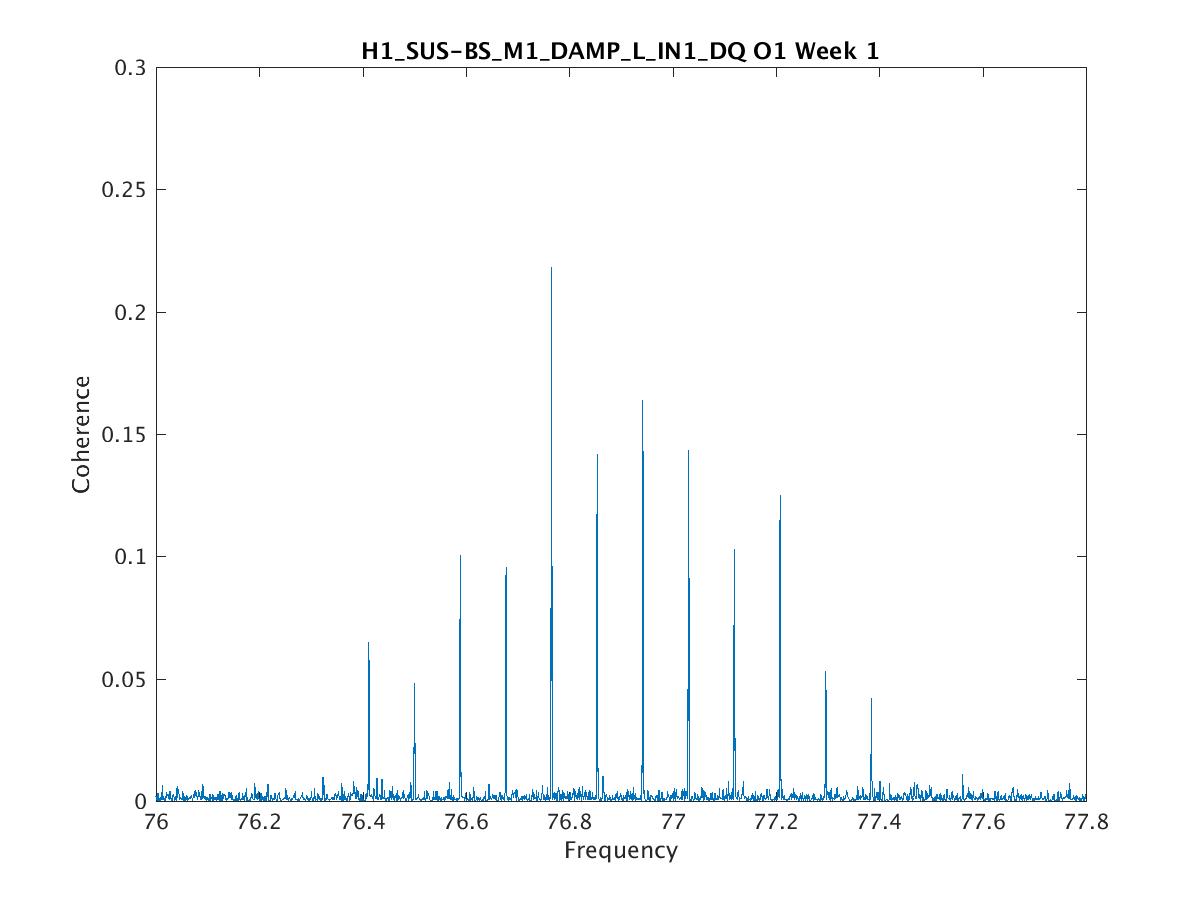
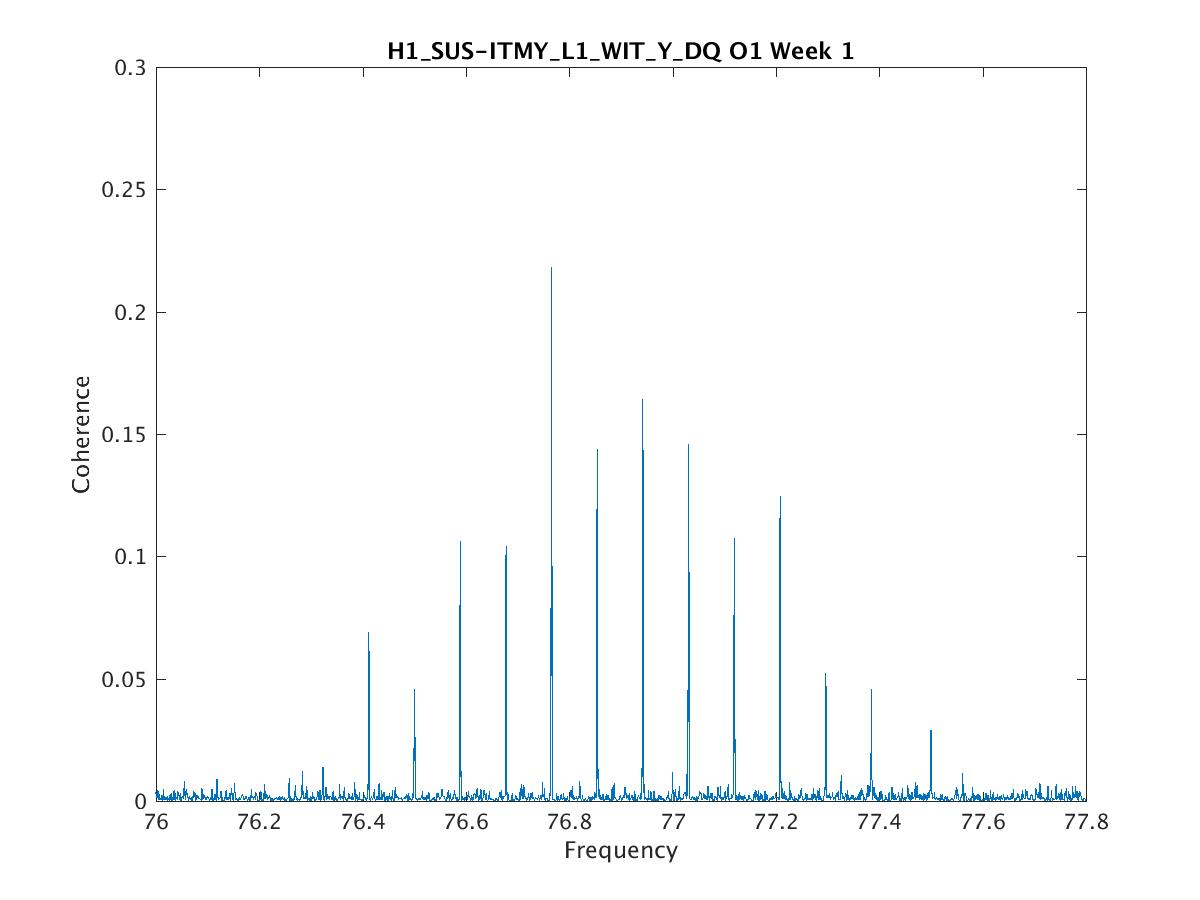
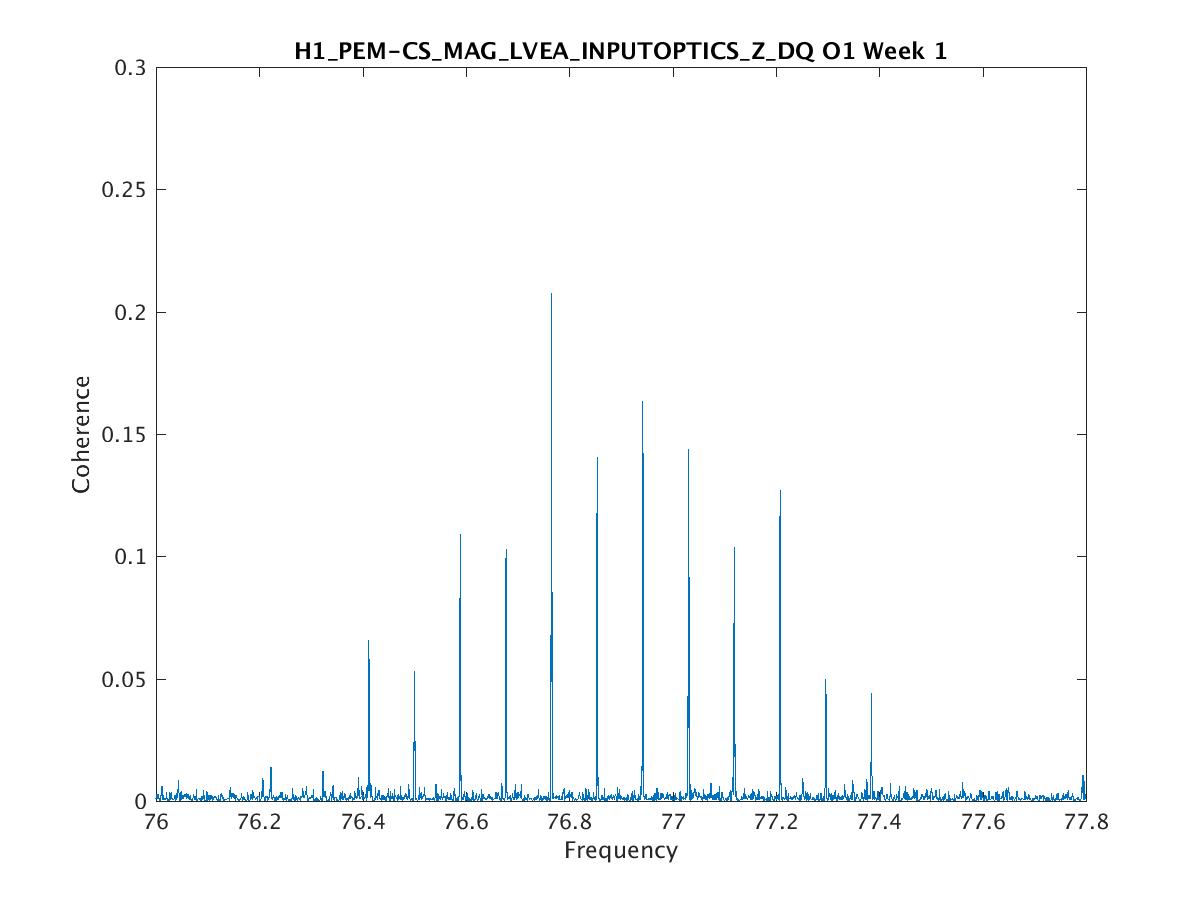
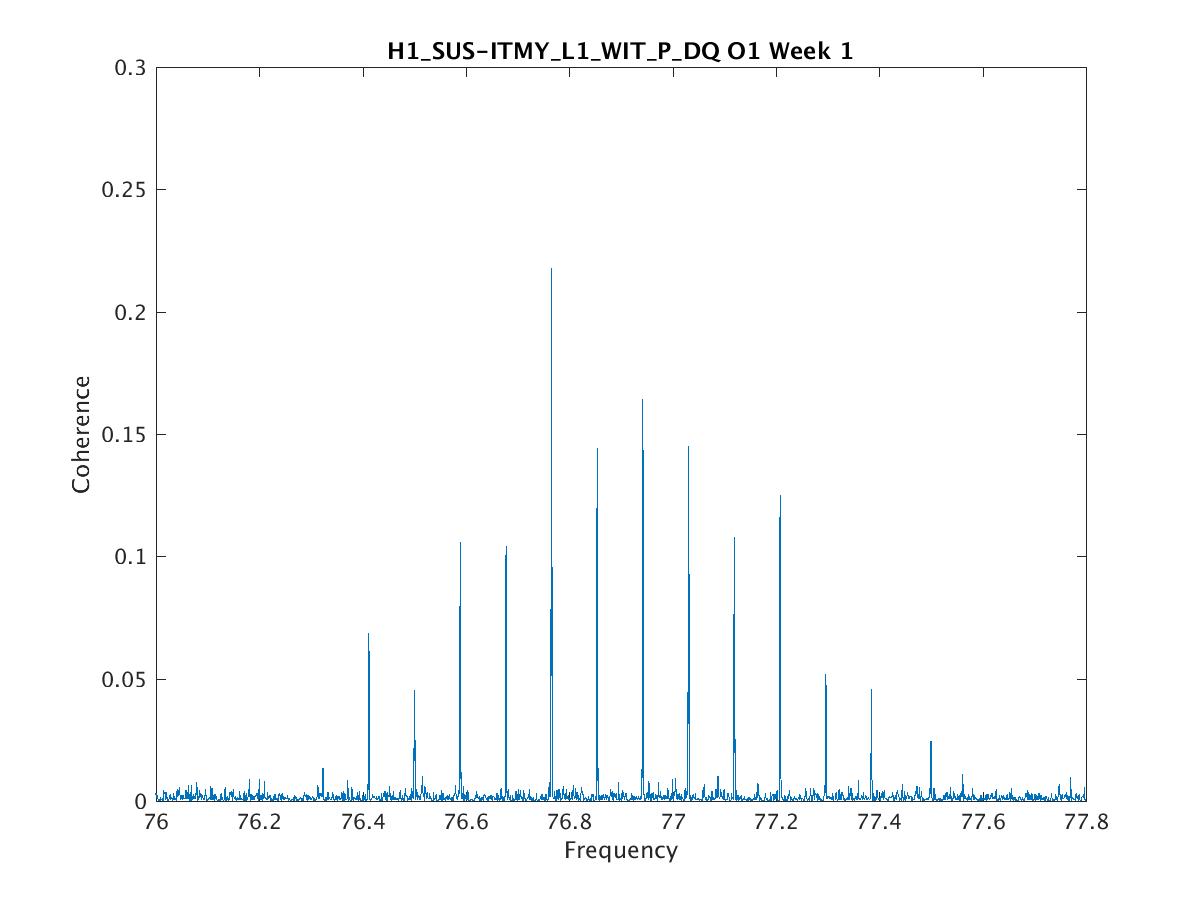
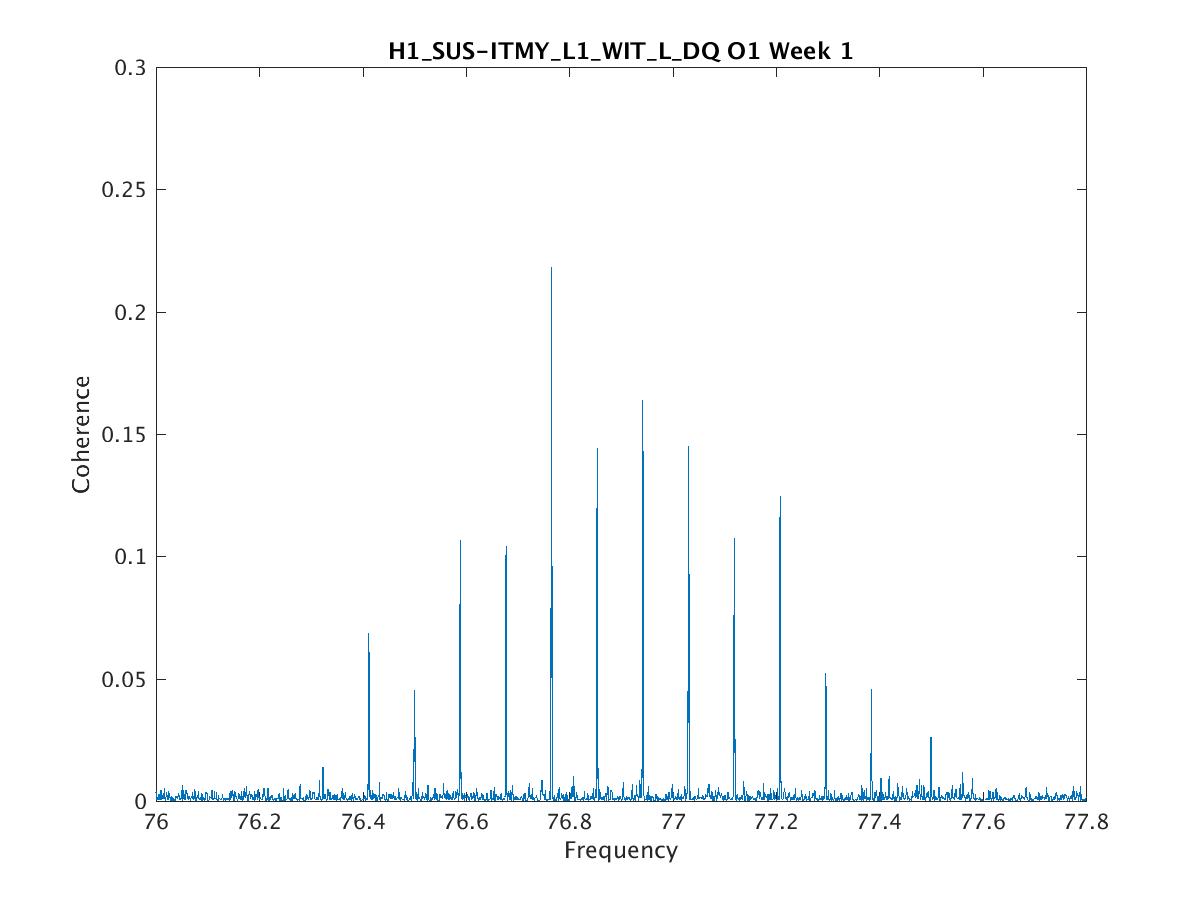
Parameters:
GPS Start Time = 1127333892 # Beginning of time span, in GPS seconds, to search for injections
GPS End Time = 1127420292 # Ending of time span, in GPS seconds, to search for injections
Check Hanford IFO = True # Check for injections in the Hanford IFO frame files.
Check Livingston IFO = True # Check for injections in the Livingston IFO frame files.
IFO Coinc Time = 0.01 # Time window, in seconds, for coincidence between IFO injection events.
Check ODC_HOFT = True # Check ODC-MASTER_CHANNEL_OUT_DQ channel in HOFT frames.
Check ODC_RAW = True # Check ODC-MASTER_CHANNEL_OUT_DQ channel in RAW frames.
Check ODC_RDS = True # Check ODC-MASTER_CHANNEL_OUT_DQ channel in RDS frames.
Check GDS_HOFT = True # Check GDS-CALIB_STATE_VECTOR channel in HOFT frames.
Report Normal = True # Include normal (IFO-coincident, consistent, and scheduled for network injections and consistent and scheduled for IFO injections) injections in report
Report Anomalous = True # Include anomalous (non-IFO-coincident, inconsistent, or unscheduled) injections in report
No injections found. No scheduled injections within the time span checked.