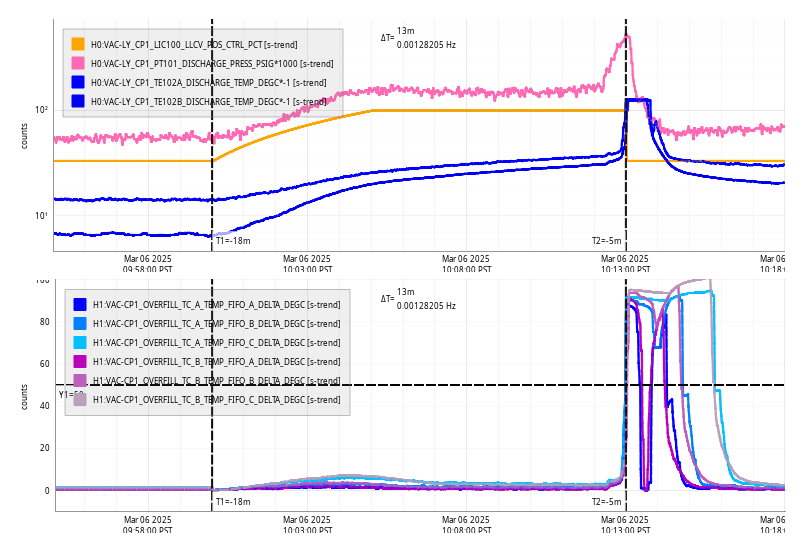
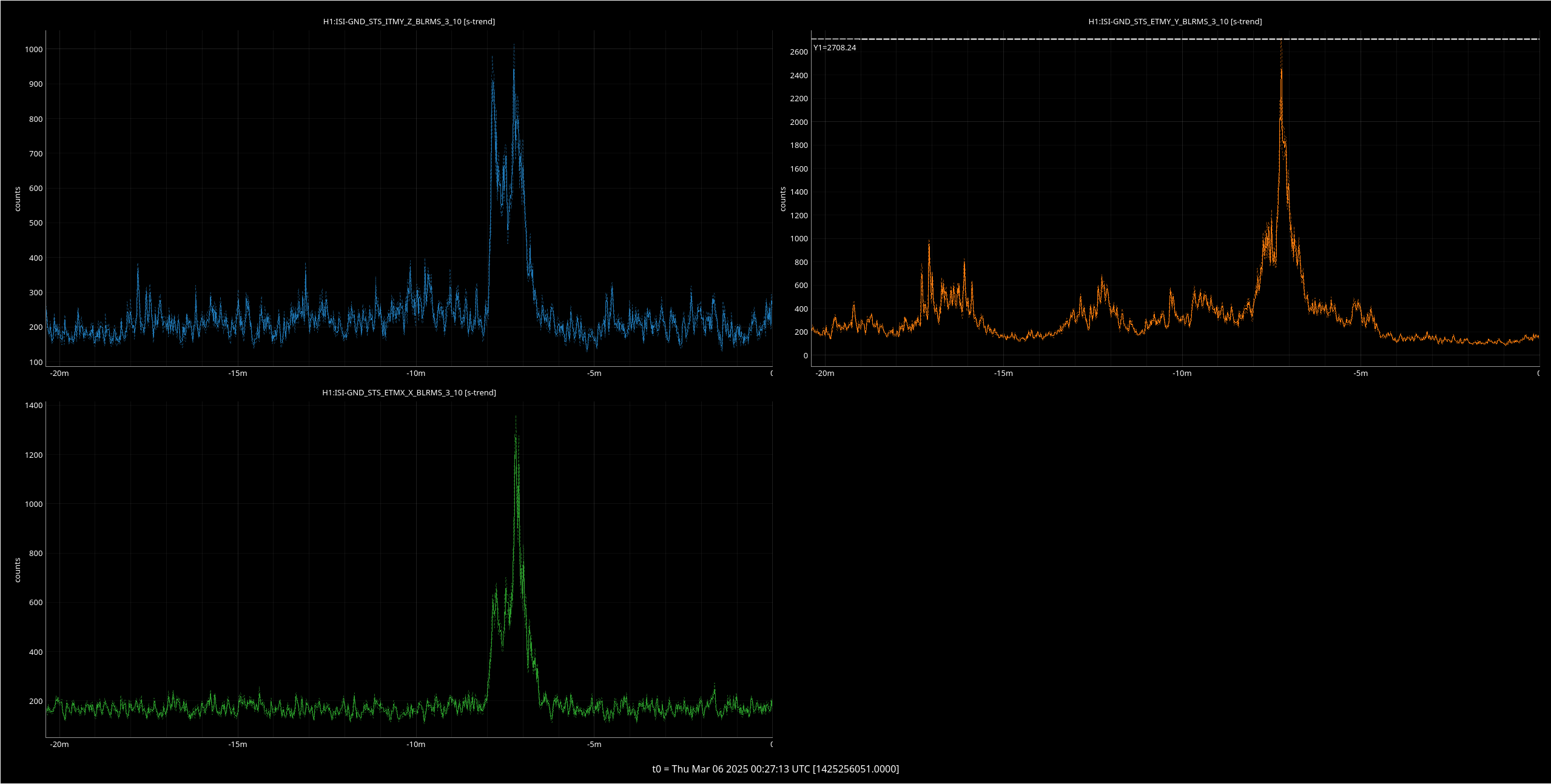
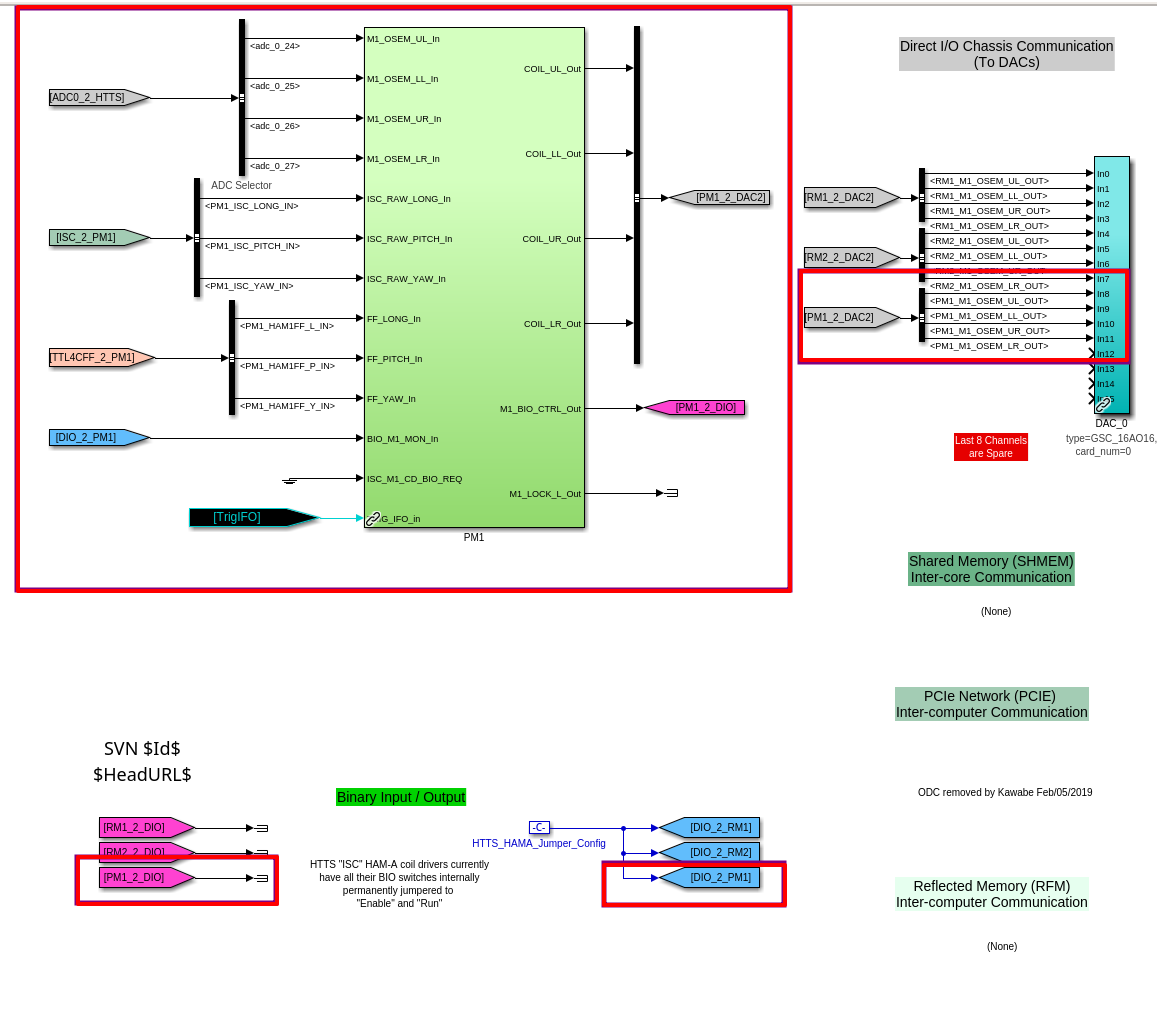
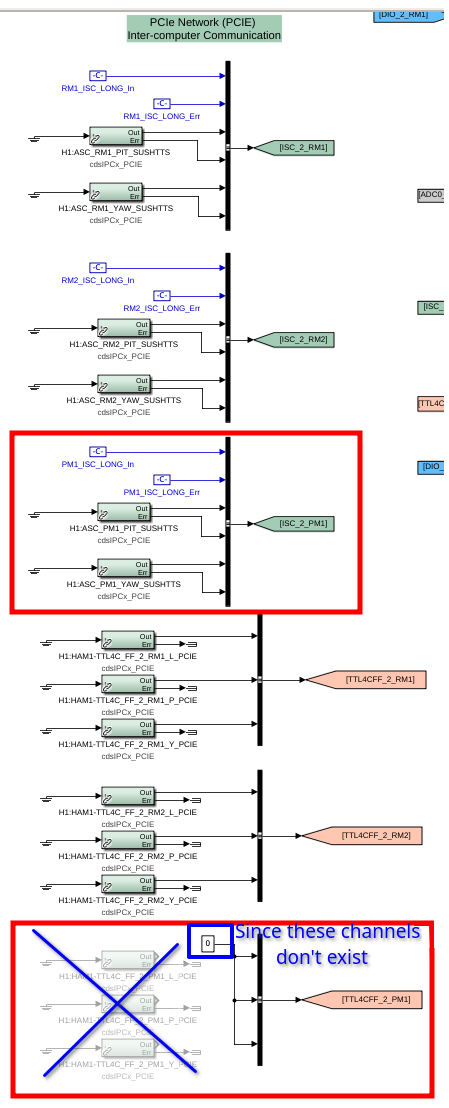
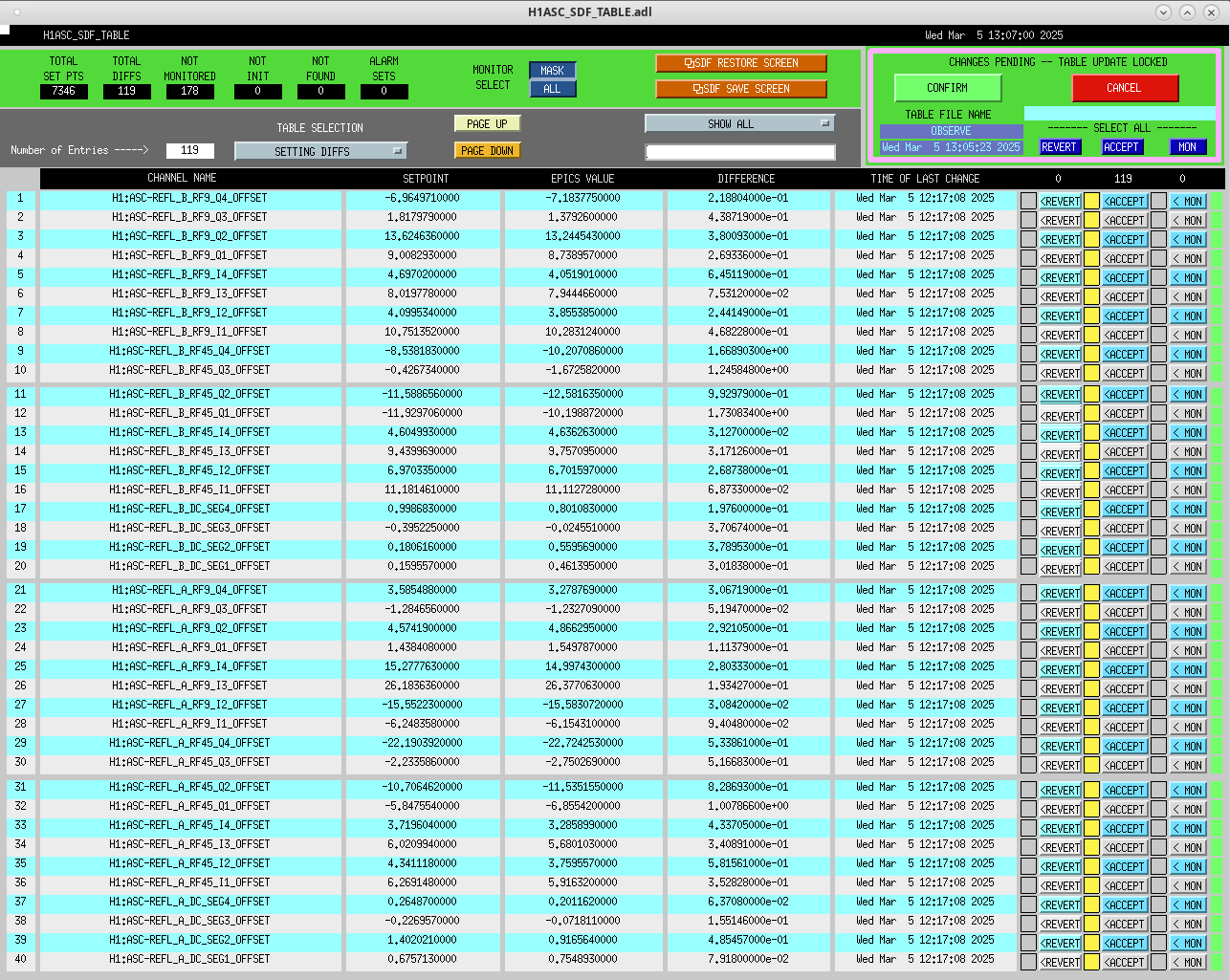
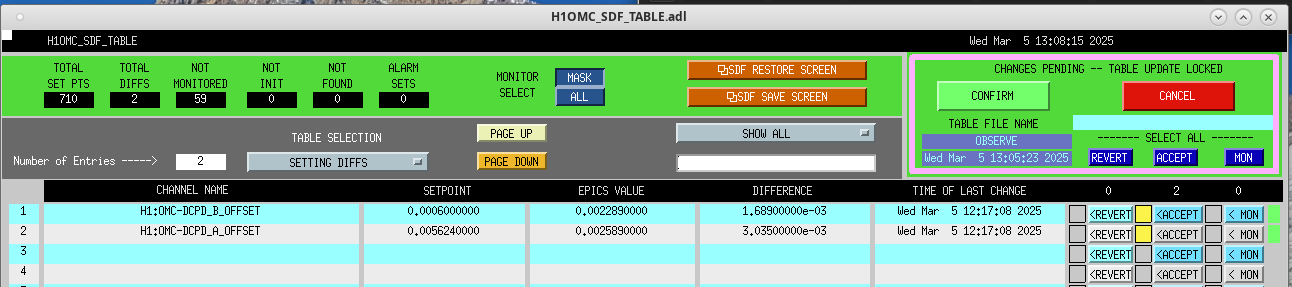
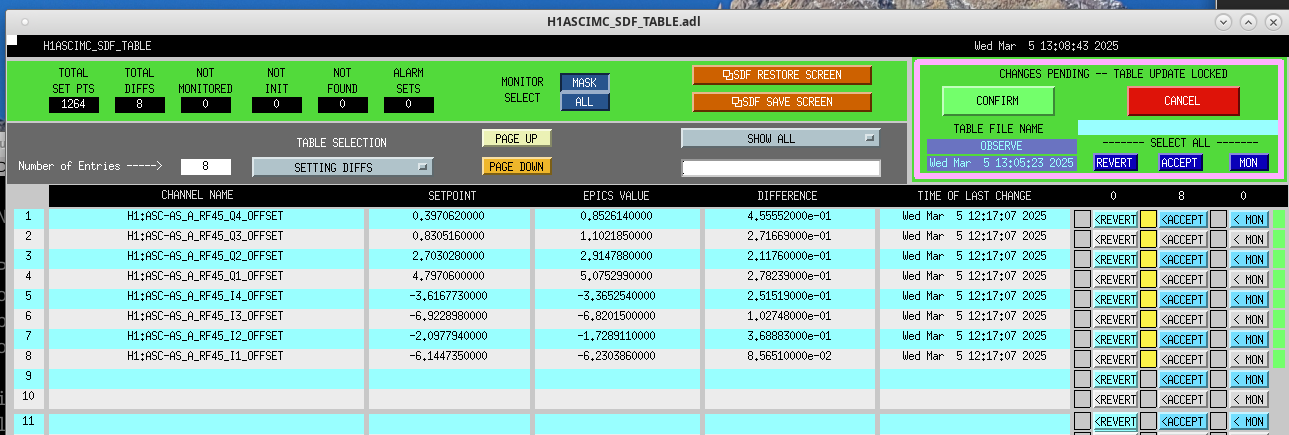
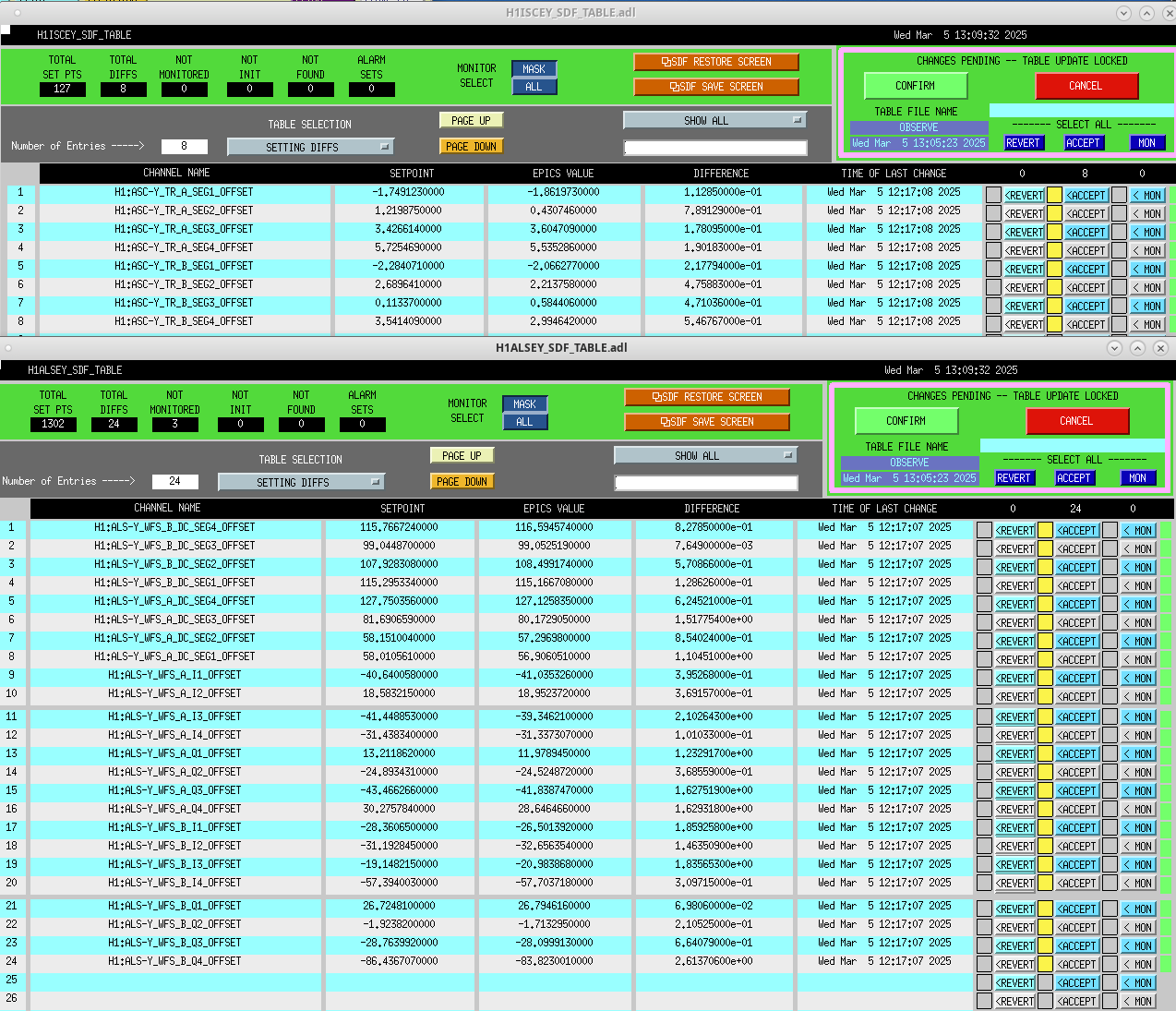
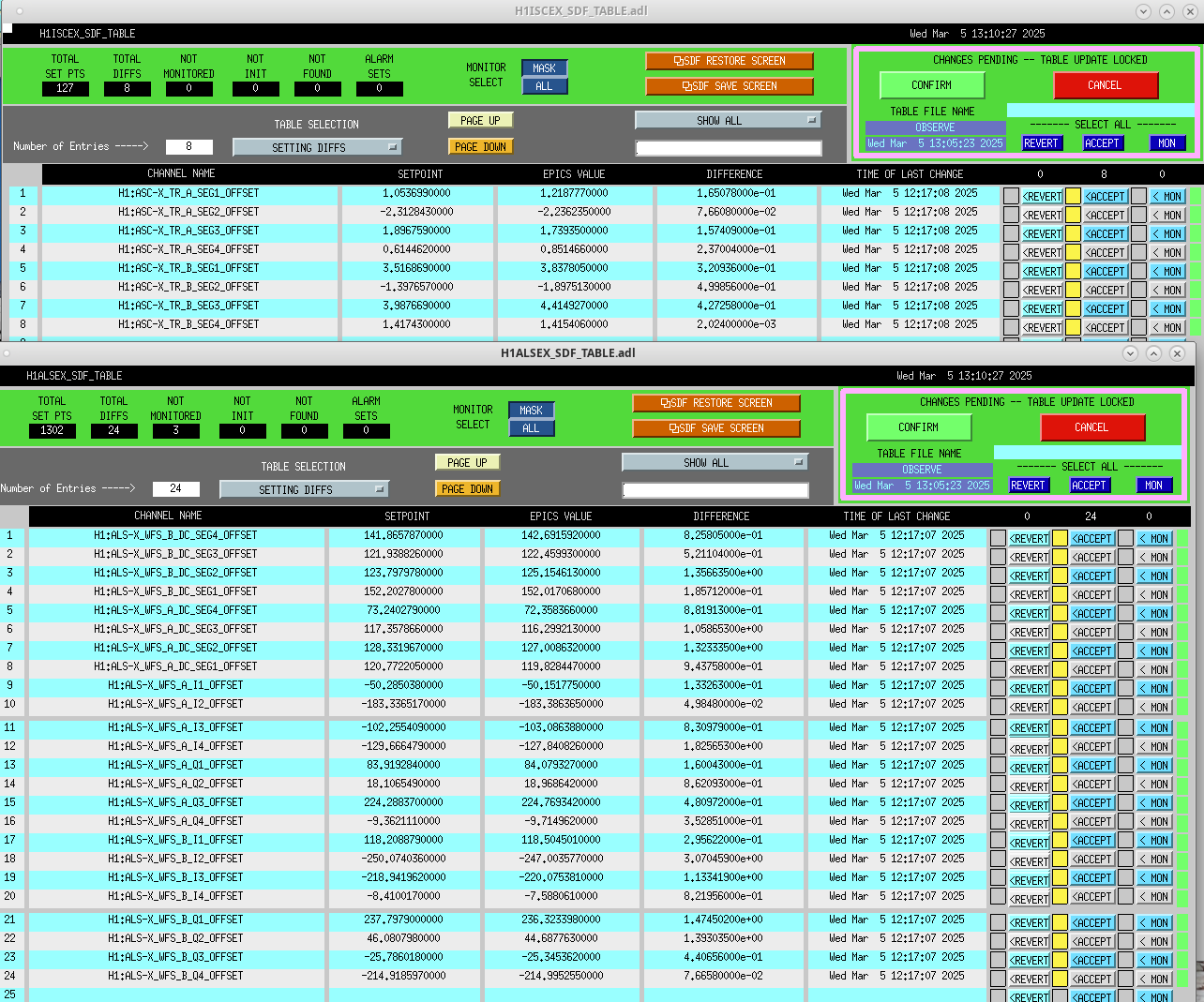
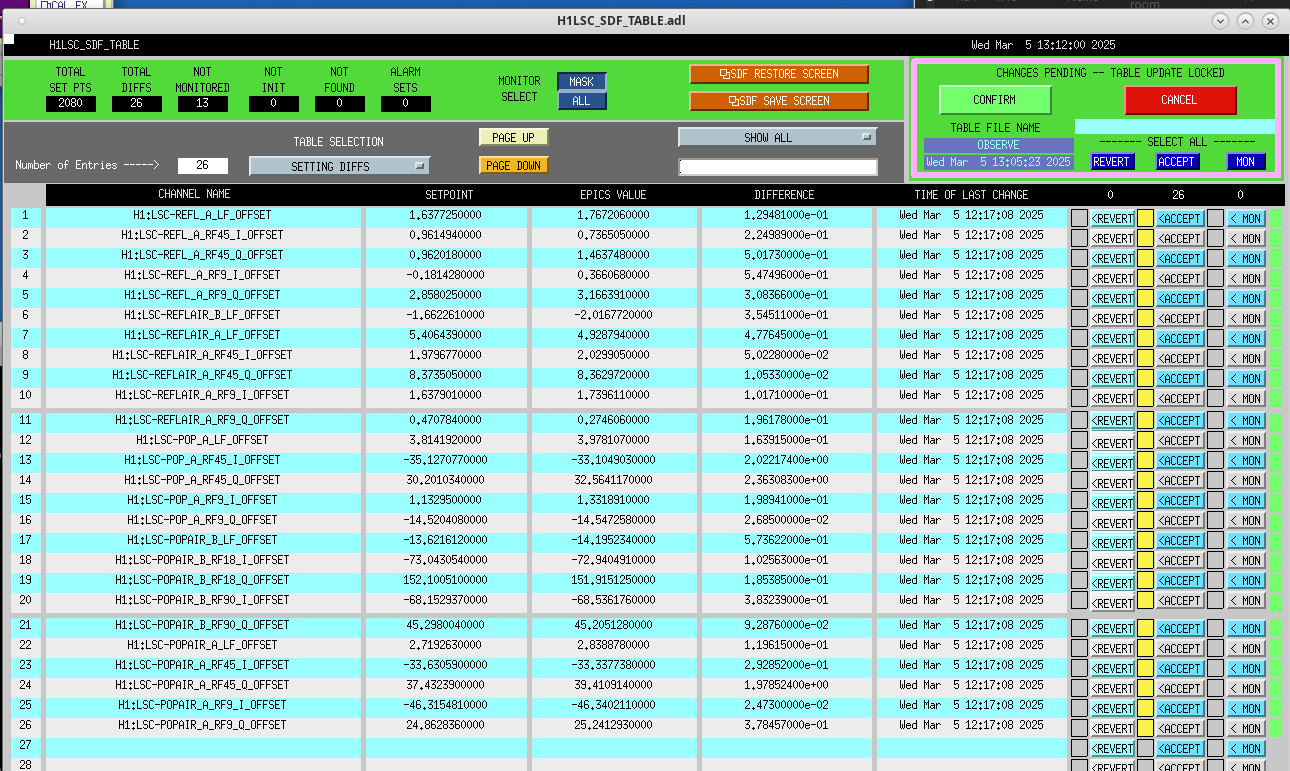
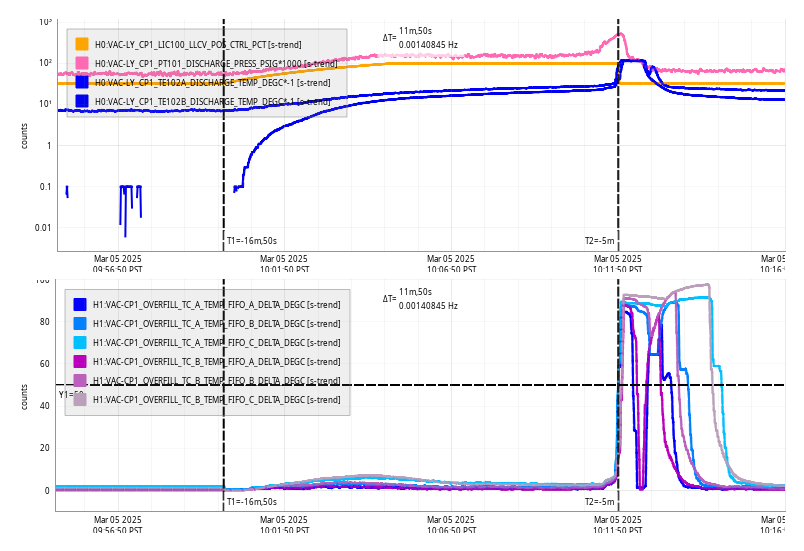
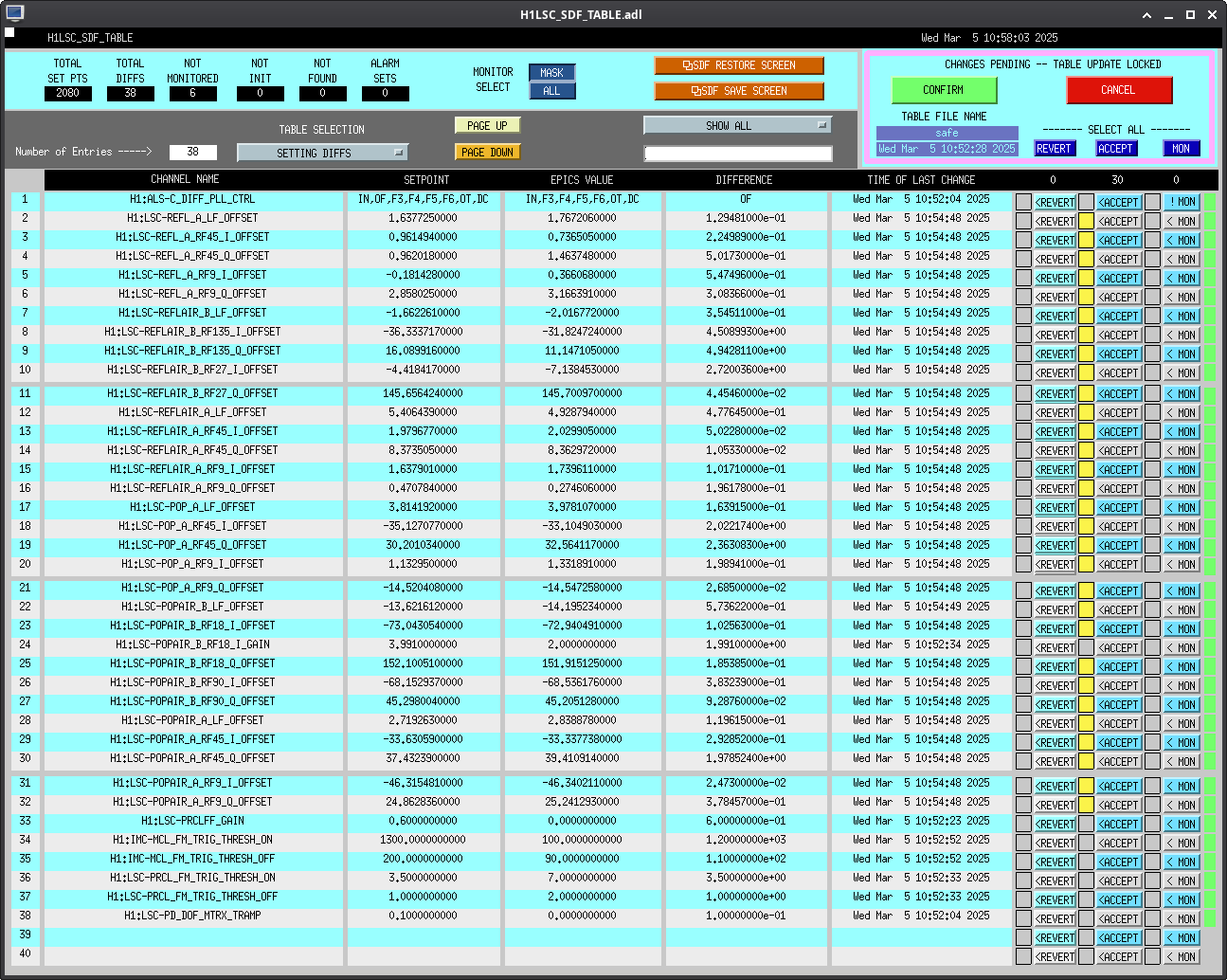
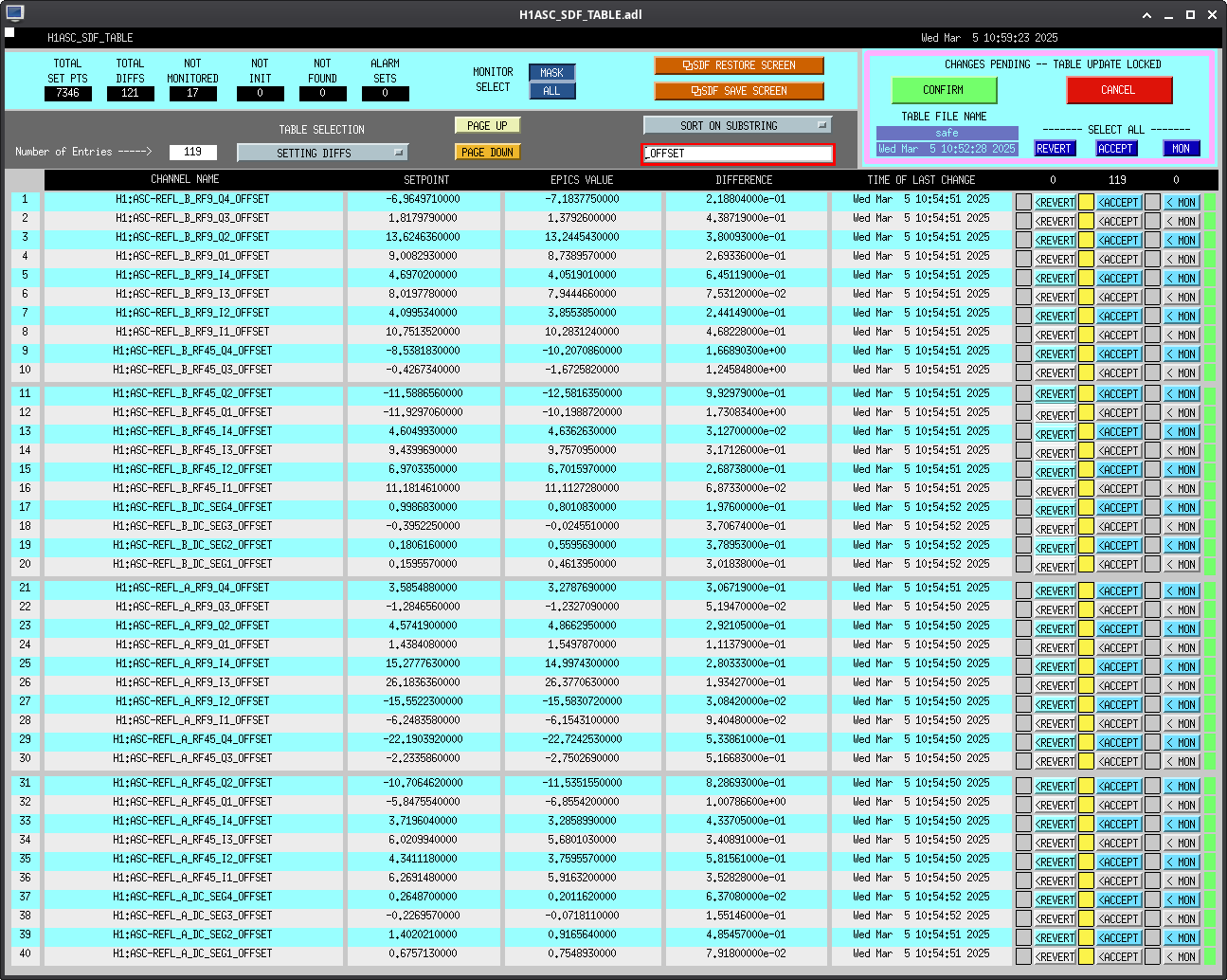
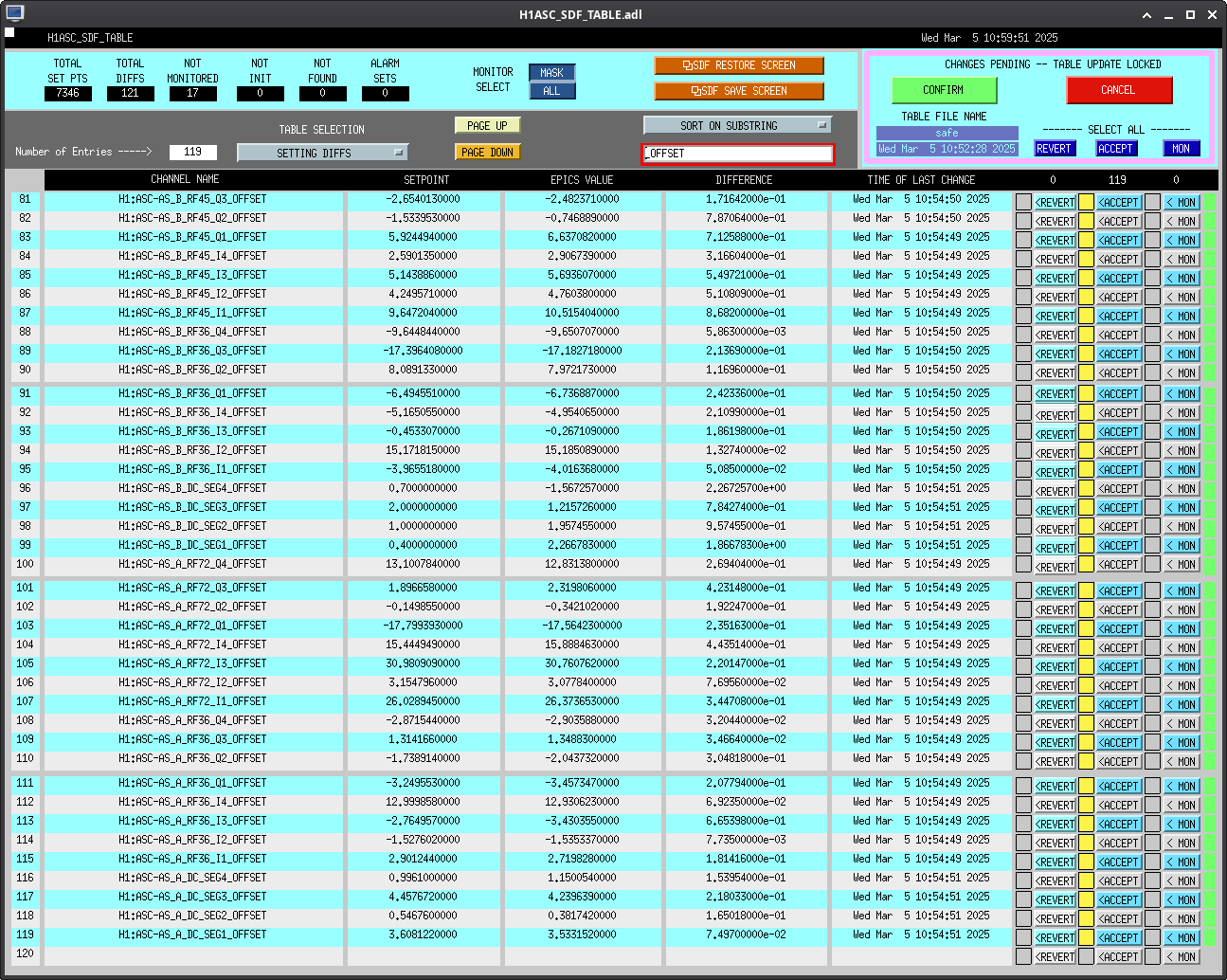
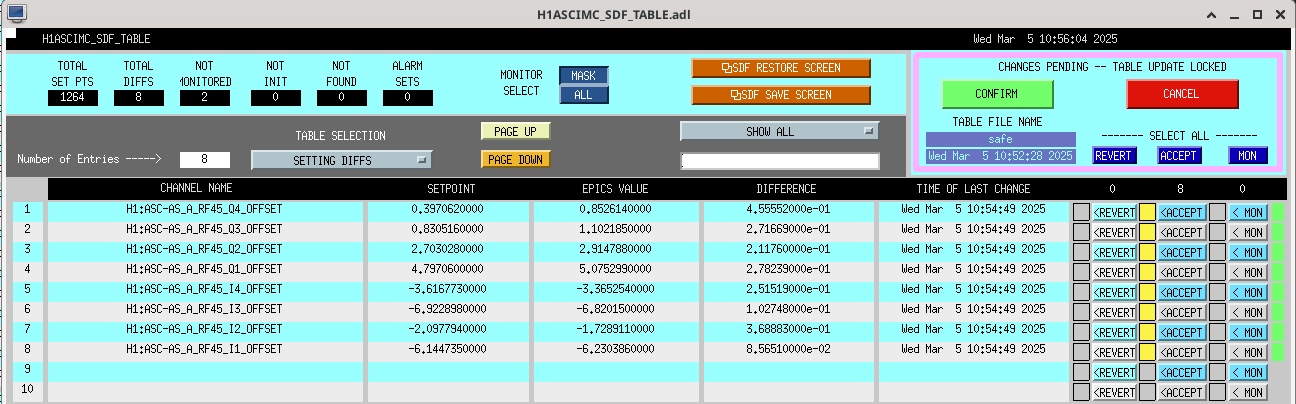
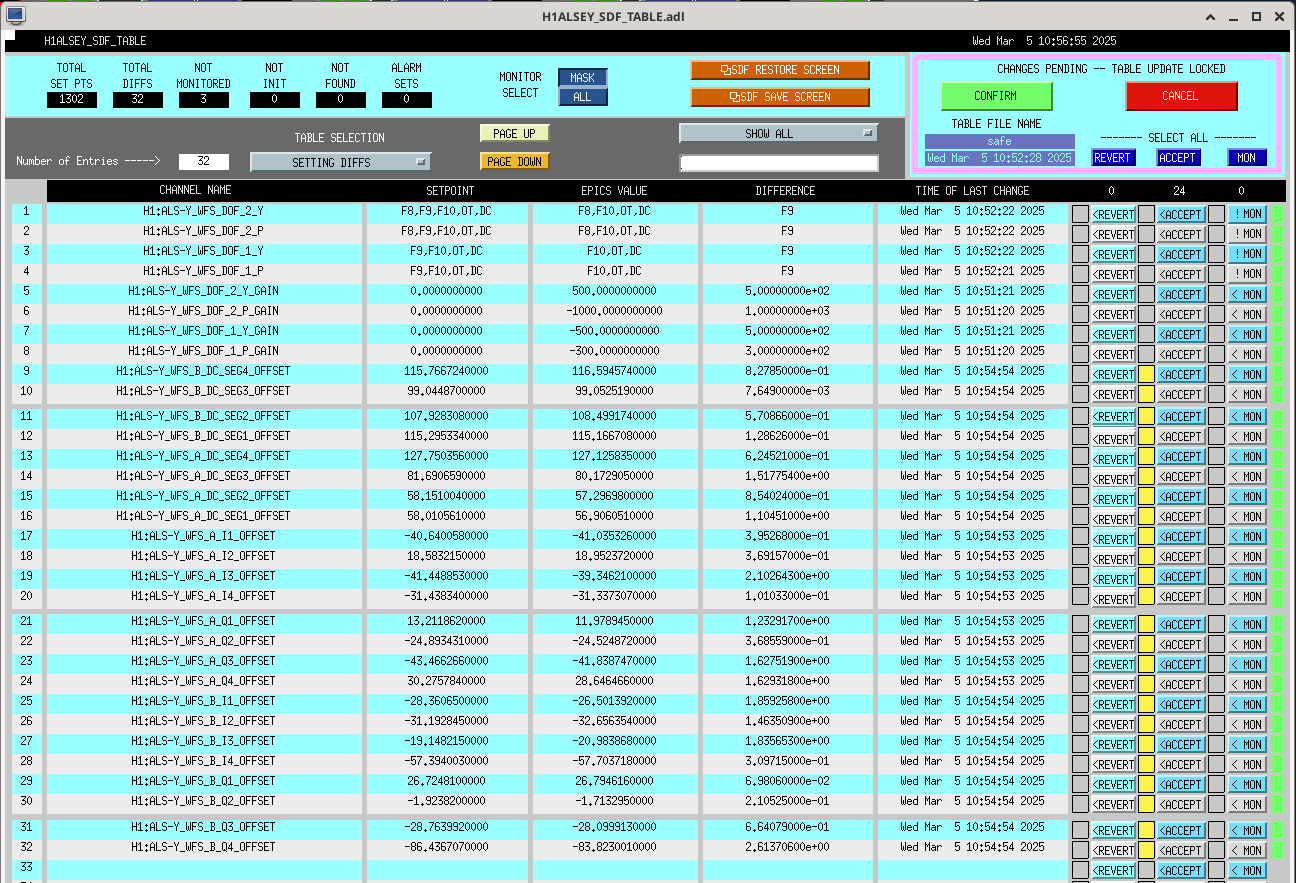
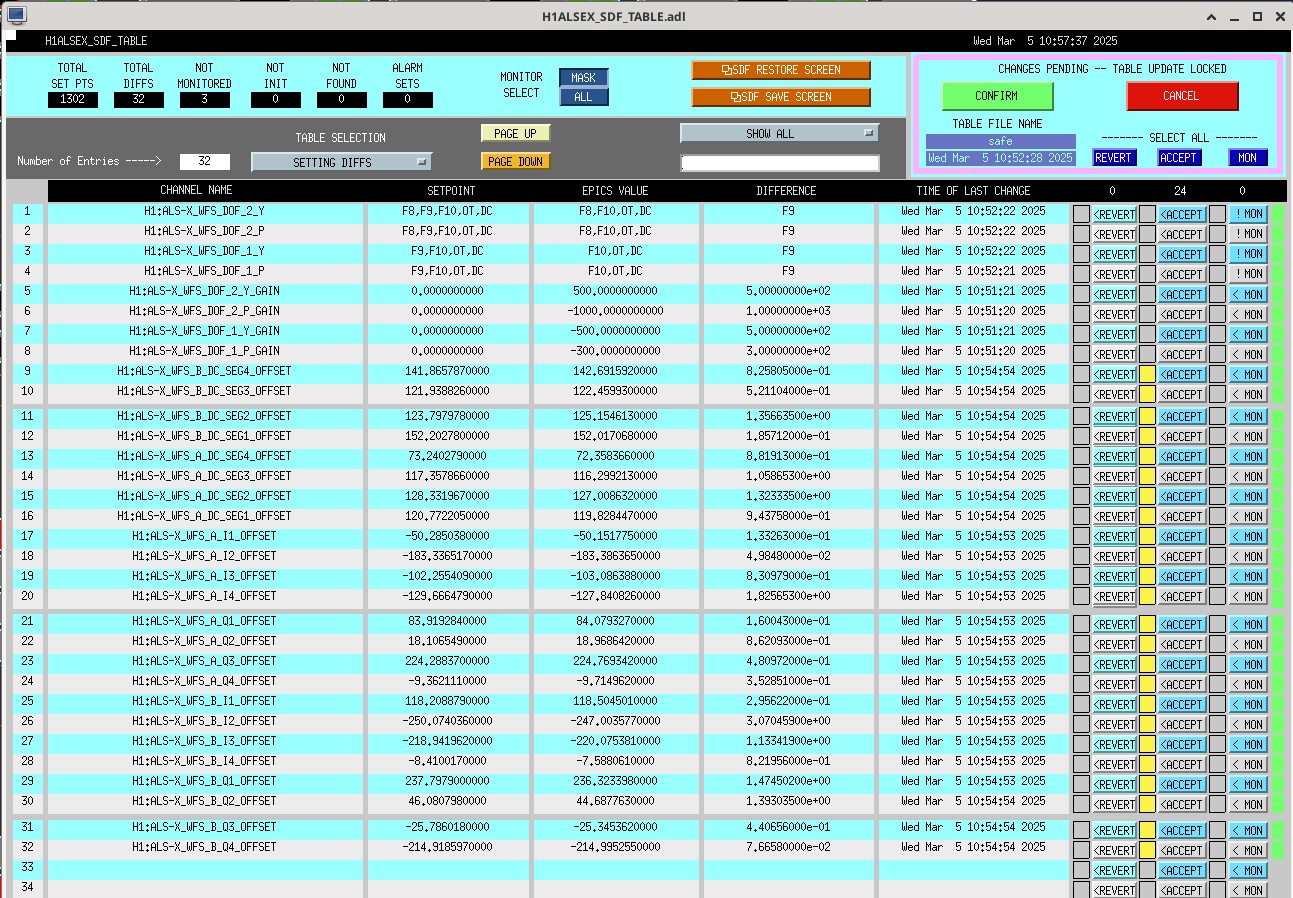
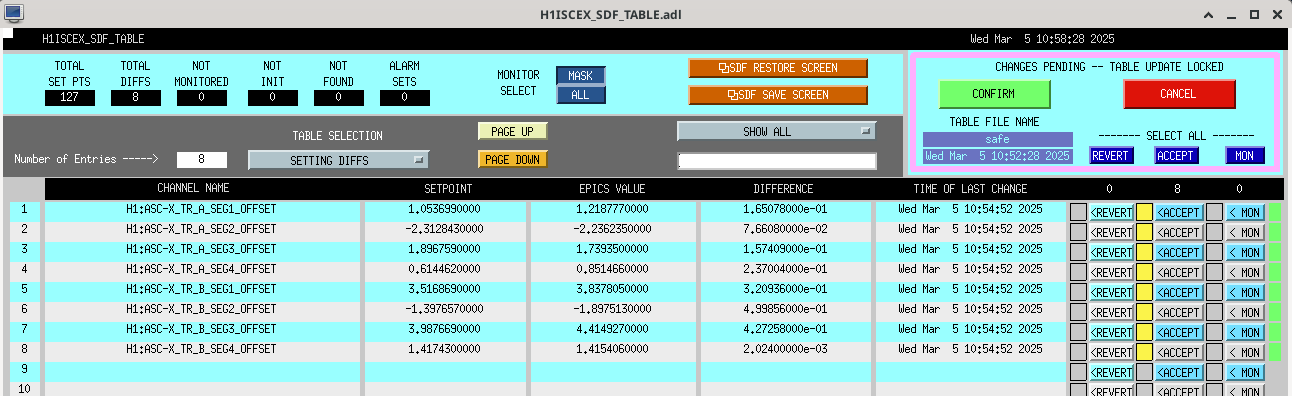
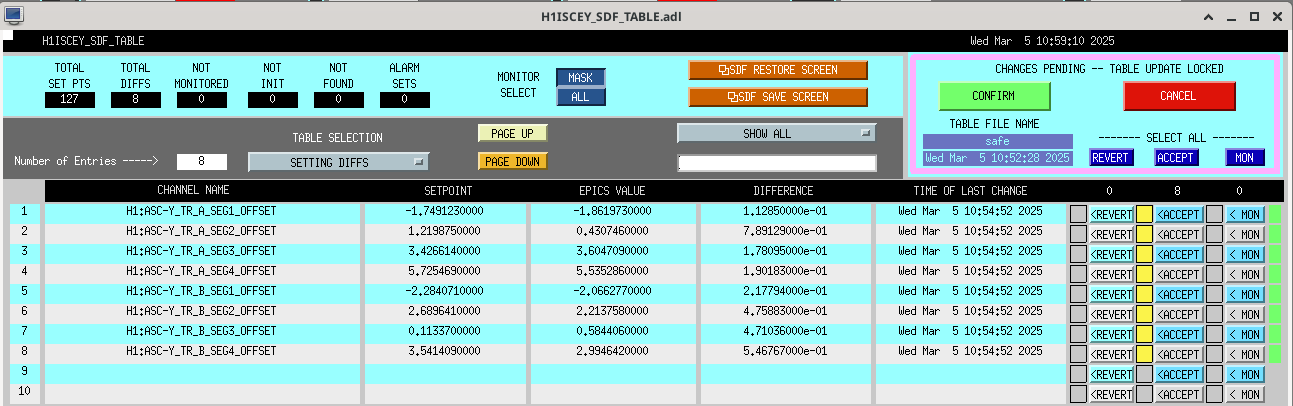
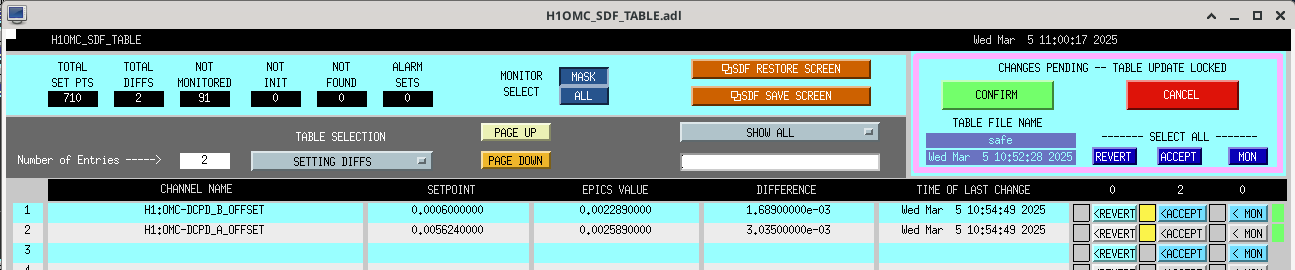
Following the usual Cal meas wiki instructions , I ran a calibration broadband and simulines measurement, but the IFO lost lock near the very end of simulines. All test points were cleared with the script wrapup.
Simulines start:
PST: 2025-03-06 12:12:00.699516 PST
UTC: 2025-03-06 20:12:00.699516 UTC
GPS: 1425327138.699516
Simulines output near end:
2025-03-06 20:35:04,501 | INFO | Drive, on DARM_OLGTF, at frequency: 1083.3, and amplitude 1e-09, is finished. G
PS start and end time stamps: 1425328503, 1425328518
2025-03-06 20:35:04,502 | INFO | Scanning frequency 1200.0 in Scan : DARM_OLGTF on PID: 861436
2025-03-06 20:35:04,502 | INFO | Drive, on DARM_OLGTF, at frequency: 1200.0, is now running for 23 seconds.
2025-03-06 20:35:05,621 | INFO | Drive, on L2_SUSETMX_iEXC2DARMTF, at frequency: 43.6, and amplitude 0.40648, is
finished. GPS start and end time stamps: 1425328503, 1425328518
2025-03-06 20:35:05,622 | INFO | Scanning frequency 51.05 in Scan : L2_SUSETMX_iEXC2DARMTF on PID: 861446
2025-03-06 20:35:05,622 | INFO | Drive, on L2_SUSETMX_iEXC2DARMTF, at frequency: 51.05, is now running for 23 se
conds.
2025-03-06 20:35:06,760 | INFO | Drive, on L3_SUSETMX_iEXC2DARMTF, at frequency: 289.84, and amplitude 0.49024,
is finished. GPS start and end time stamps: 1425328503, 1425328518
2025-03-06 20:35:07,271 | INFO | 4 still running.
2025-03-06 20:35:11,138 | INFO | Drive, on PCALY2DARMTF, at frequency: 7.68, and amplitude 16534, is finished. G
PS start and end time stamps: 1425328496, 1425328523
2025-03-06 20:35:11,279 | INFO | 3 still running.
2025-03-06 20:35:11,721 | ERROR | IFO not in Low Noise state, Sending Interrupts to excitations and main thread.
2025-03-06 20:35:11,721 | ERROR | Ramping Down Excitation on channel H1:LSC-DARM1_EXC
2025-03-06 20:35:11,721 | ERROR | Aborting main thread and Data recording, if any. Cleaning up temporary file st
ructure.
Process Process-12:
Traceback (most recent call last):
File "/var/opt/conda/base/envs/cds/lib/python3.10/multiprocessing/process.py", line 314, in _bootstrap
self.run()
File "/var/opt/conda/base/envs/cds/lib/python3.10/multiprocessing/process.py", line 108, in run
self._target(*self._args, **self._kwargs)
File "/ligo/groups/cal/src/simulines/simulines/simuLines.py", line 340, in checkIfLocked
os.kill(pid,signal.SIGINT)
ProcessLookupError: [Errno 3] No such process
2025-03-06 20:35:24,341 | INFO | Drive, on L1_SUSETMX_iEXC2DARMTF, at frequency: 12.86, and amplitude 19.723, is
finished. GPS start and end time stamps: 1425328522, 1425328538
Process Process-9:
Traceback (most recent call last):
File "/var/opt/conda/base/envs/cds/lib/python3.10/multiprocessing/process.py", line 314, in _bootstrap
self.run()
File "/var/opt/conda/base/envs/cds/lib/python3.10/multiprocessing/process.py", line 108, in run
self._target(*self._args, **self._kwargs)
File "/ligo/groups/cal/src/simulines/simulines/simuLines.py", line 678, in generateSignalInjection
results[scan] = tempObj
File "", line 2, in __setitem__
File "/var/opt/conda/base/envs/cds/lib/python3.10/multiprocessing/managers.py", line 817, in _callmethod
conn.send((self._id, methodname, args, kwds))
File "/var/opt/conda/base/envs/cds/lib/python3.10/multiprocessing/connection.py", line 206, in send
self._send_bytes(_ForkingPickler.dumps(obj))
File "/var/opt/conda/base/envs/cds/lib/python3.10/multiprocessing/connection.py", line 411, in _send_bytes
self._send(header + buf)
File "/var/opt/conda/base/envs/cds/lib/python3.10/multiprocessing/connection.py", line 368, in _send
n = write(self._handle, buf)
BrokenPipeError: [Errno 32] Broken pipe
2025-03-06 20:35:30,666 | INFO | Drive, on L2_SUSETMX_iEXC2DARMTF, at frequency: 51.05, and amplitude 0.34489, i
s finished. GPS start and end time stamps: 1425328529, 1425328544
Process Process-10:
Traceback (most recent call last):
File "/var/opt/conda/base/envs/cds/lib/python3.10/multiprocessing/process.py", line 314, in _bootstrap
self.run()
File "/var/opt/conda/base/envs/cds/lib/python3.10/multiprocessing/process.py", line 108, in run
self._target(*self._args, **self._kwargs)
File "/ligo/groups/cal/src/simulines/simulines/simuLines.py", line 678, in generateSignalInjection
results[scan] = tempObj
File "", line 2, in __setitem__
File "/var/opt/conda/base/envs/cds/lib/python3.10/multiprocessing/managers.py", line 817, in _callmethod
conn.send((self._id, methodname, args, kwds))
File "/var/opt/conda/base/envs/cds/lib/python3.10/multiprocessing/connection.py", line 206, in send
self._send_bytes(_ForkingPickler.dumps(obj))
File "/var/opt/conda/base/envs/cds/lib/python3.10/multiprocessing/connection.py", line 411, in _send_bytes
self._send(header + buf)
File "/var/opt/conda/base/envs/cds/lib/python3.10/multiprocessing/connection.py", line 368, in _send
n = write(self._handle, buf)
BrokenPipeError: [Errno 32] Broken pipe
ICE default IO error handler doing an exit(), pid = 861402, errno = 32
PST: 2025-03-06 12:35:30.912878 PST
UTC: 2025-03-06 20:35:30.912878 UTC
GPS: 1425328548.912878

22:10UTC Back to Observing after lockloss