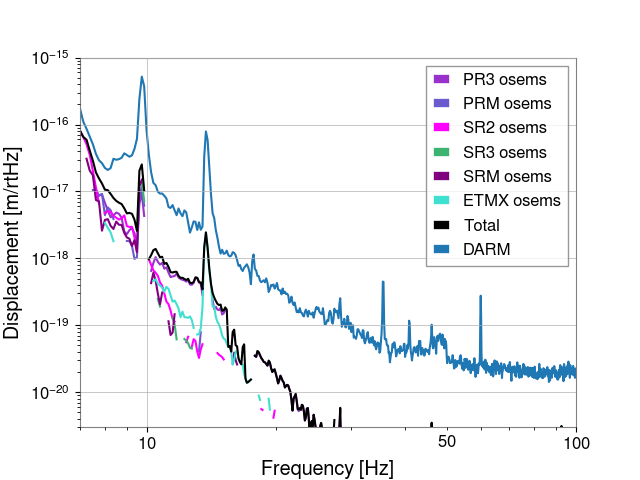
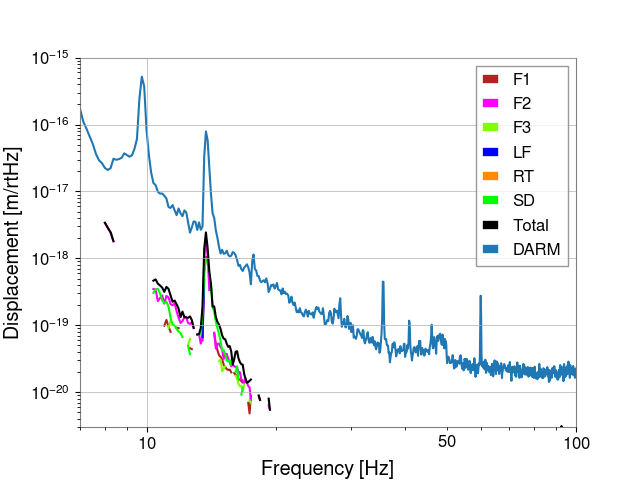
Sheila, Matt Todd
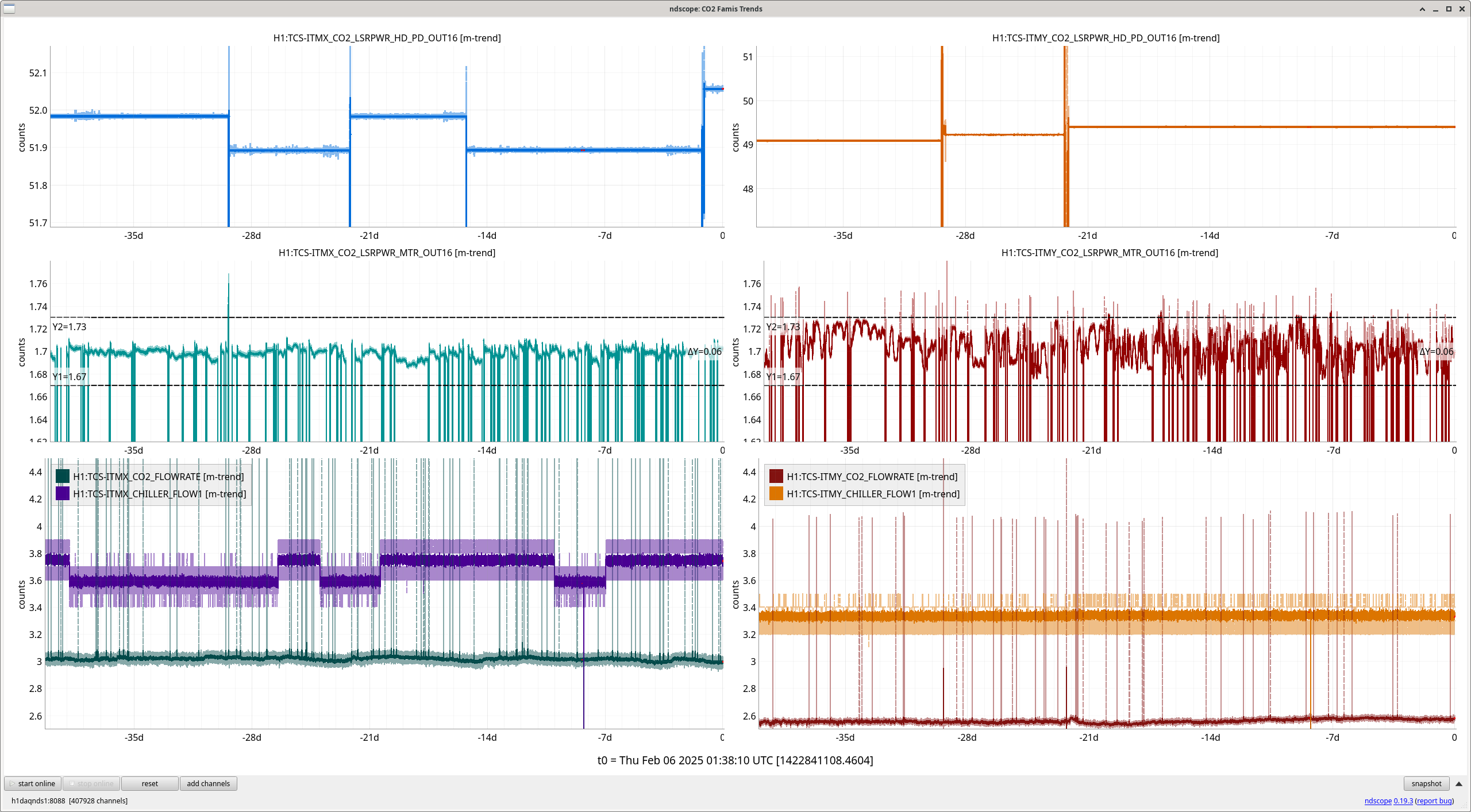
We are having more incidences of the nonstationary noise 20-60 Hz that correlates with the CO2 ISS channel.
Here's a collection of links related to this issue in the past:
- Derek lasso run for time of sudden turn off: 81764,
- detchar git issue 306
- detchar git issue about running lasso for max: 246
- detchar git issue when sqz seemed to be involved in this noise: 237
- correlation with filter cavity control signal 78485
- Last May noise seemed to go away when the squeezer was blocked: 78033
- Other alogs from last May, this seemed urelated to PR3 moves but did happen at the same times: 77980
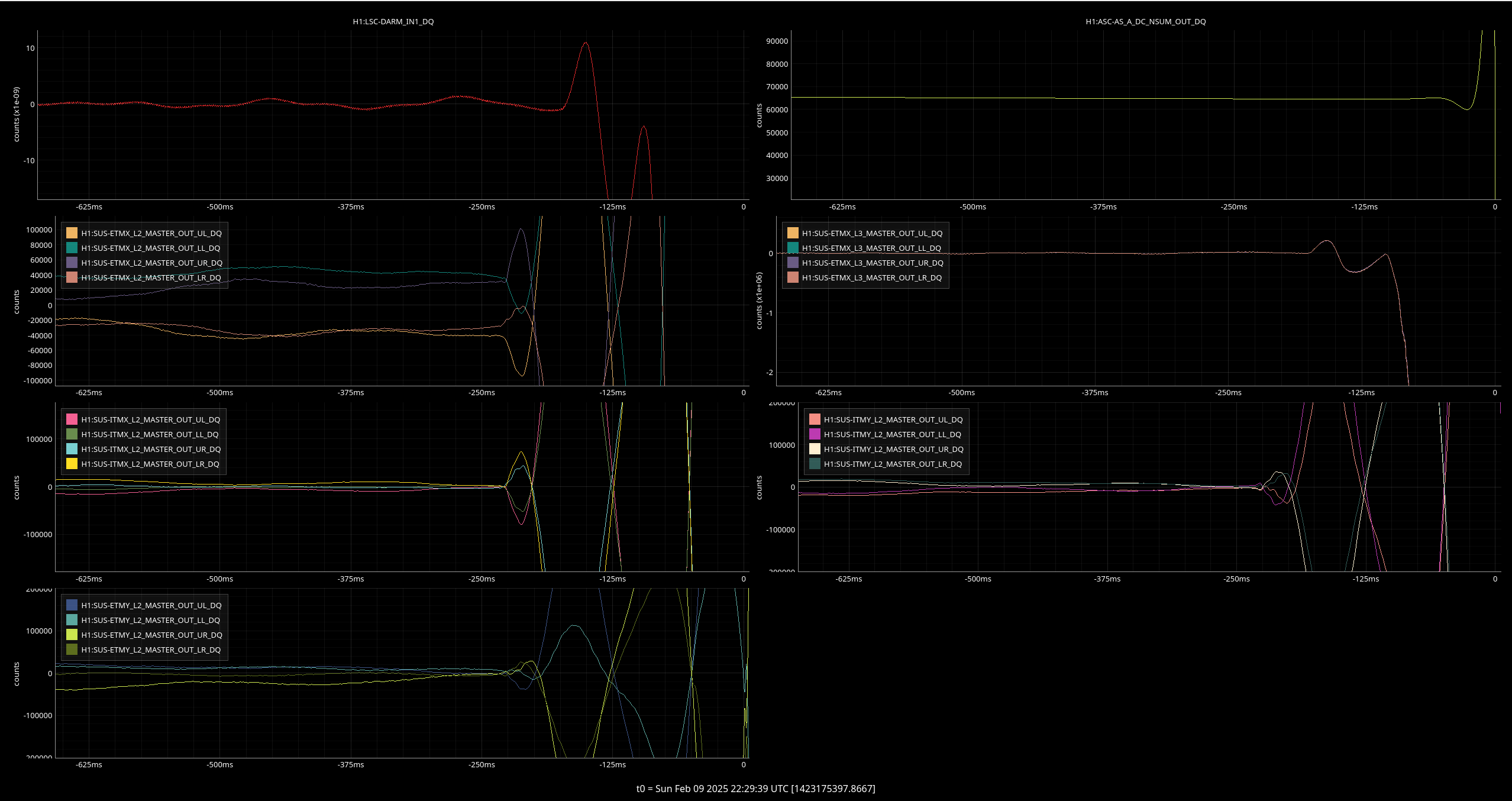
Here is a Lasso result for the noisy lock from this weekend: lasso Feb 9. Jane Glanzer is working on running lasso for some of the recent noisy times including the max as well as mean channels, so that may provide additional clues. We still see the ITMX CO2 ISS channel correlated with range. Note, on Feb 7th Lasso chooses H1:IOP-OAF_L0_MADC2_EPICS_CH15 which is the same thing as ITMX_CO2_ISS_CTRL2_INMON,
For the 9th the Rayleigh statistic also clearly shows this issue: summary page for Feb 9th, but comparing this to one of our normal days (range just below 160 and stable on Feb 4th) we also see nonstationarity at these frequencies. So, it is possible that we normally have this non stationary noise at a lower level and it is always limiting our sensitivity.
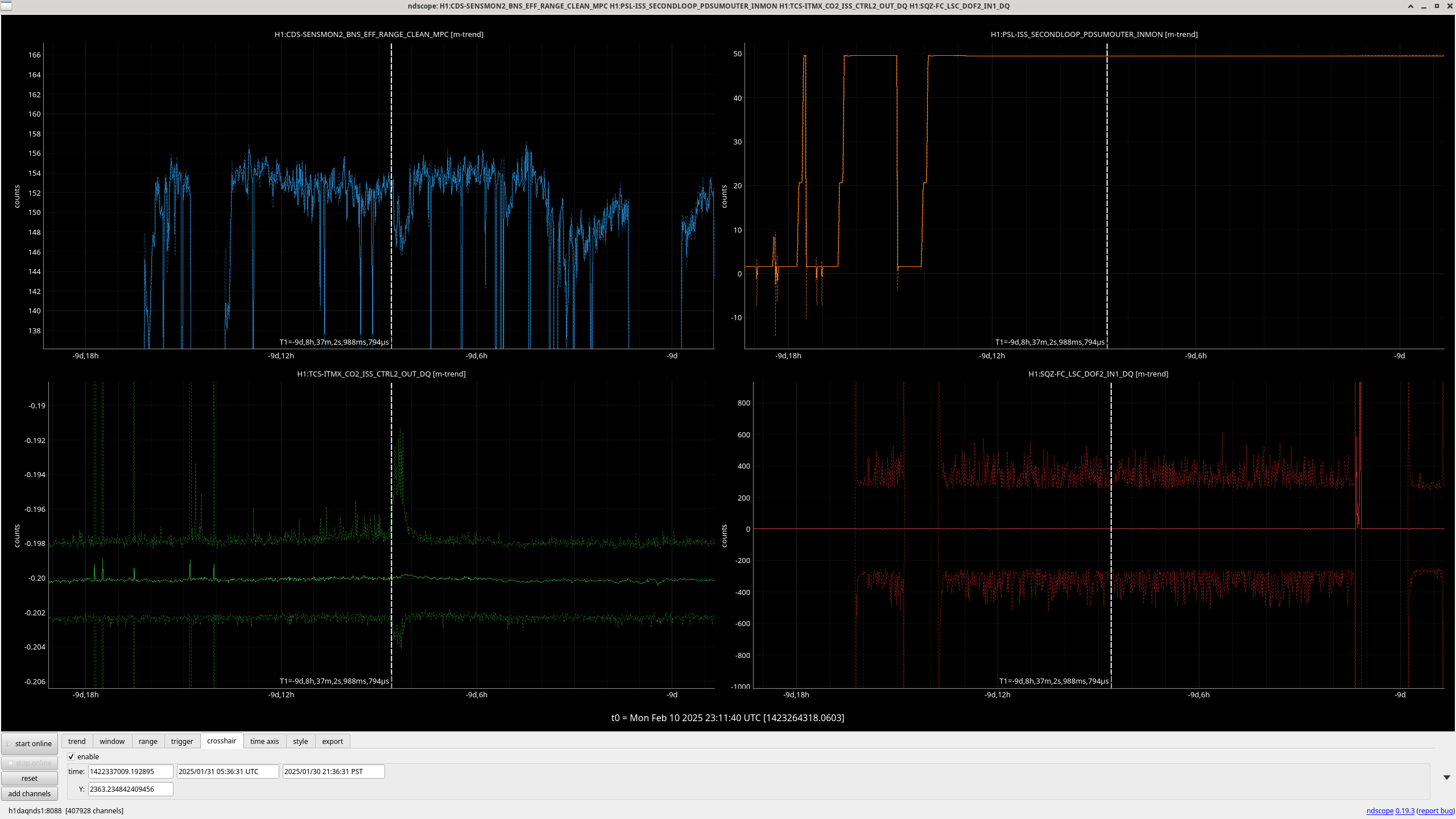
Feb st we had an incident where the ISS CO2 channel was correlated with the range, screenshot. Feb 1st there was also a remarkable change in the FC length control signal peak to peak, which has not shown any correlation with these range drops in the last week and a half, but did last may (78485). Matt found this alog about squeezer issues on the 1st, 82581, we adjusted the SHG temperature, and fiber polarization, and there was a temperature excursion in the FCES. The FC length control signal was noisy from Jan 2nd to Feb 1st, and has been back to normal since.
Operator request: If operators see the range fluctuating with lots of noise between 20-40 Hz, (similar to Feb 9th), could you drop out of observing and go to no squeezing for 10 minutes or so? We would like to see if this problem comes and goes with squeezing as it did last May.
I have run lasso for four different time periods as suggested by Sheila. As mentioned, these lasso runs differ from a traditional run in that I am using .max trends of the auxiliary channels to model the bns range. Below are links to each run, along with brief comments on what I saw.
Feb 1st 10:20 - 18:40: The top channel is a SQZ channel, H1:SQZ-PMC_TRANS_DC_NORMALIZED. H1:ASC-POP_X_RF_Q4_OUTPUT and H1:TCS-ITMX_CO2_ISS_CTRL2_OUT_DQ were also picked out. The CO2 channel is correlated with the bigger dip around ~15 UTC.
Feb 7th 12:21:58 - 15:17:03: For some reason, lasso only runs until 15 UTC, when I have specified it run until 18:30 UTC. I am not 100% sure why this happens. I think it may be because of a large range drop around 15 UTC. I have still included what lasso found for the initial 3 hours or so. Some top channels picked out are H1:SUS-ITMY_M0_OSEMINF_F2_OUT16 & H1:ASC-AS_A_RF45_Q2_OUT16. These are new channels that I don't think have been picked out before. I will say that farther down the list of correlated channels H1:PSL-ISS_SECONDLOOP_QPD_SUM_OUT16.
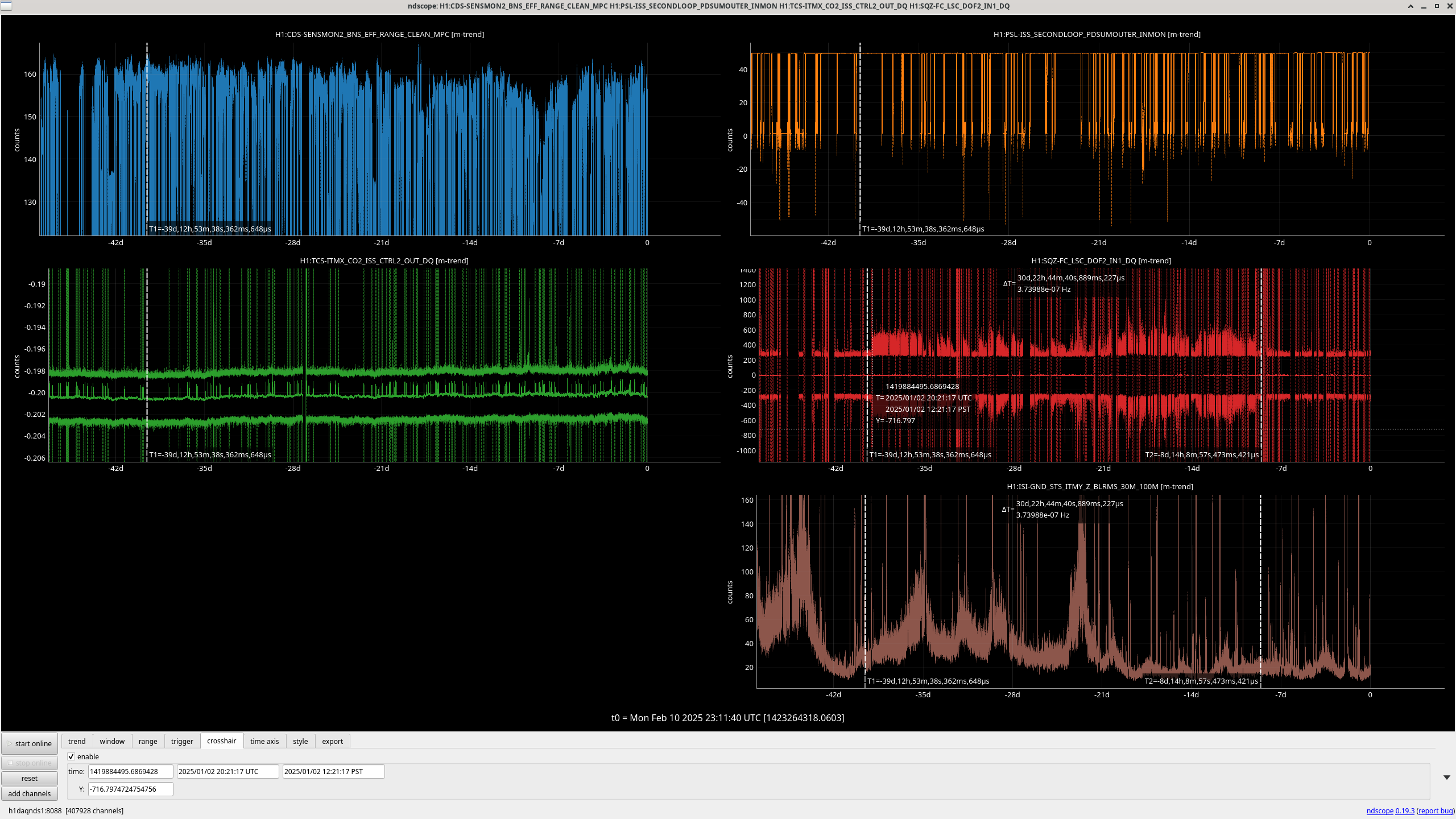
Feb 7th 21:55:32 - Feb 8th 01:40:00: Top channel is H1:TCS_ITMX_CO2_ISS_CTRL2_OUT_DQ.
Feb 9th 07:04:07 - 11:59:26: Top correlated channels are H1:PSL-ISS_SECONDLOOP_PDSUMOUTER_INMON & H1:TCS-ITMX_CO2_ISS_CTRL2_OUT_DQ. These are also the top two channels from the regular lasso run (with .mean trends) as viewed from the summary pages.
The most consistently picked out channel is the ITMX_CO2 channel, but the .max trend method also seems to pick up some PSL, SQZ, SUS, and ASC channels as well.