[Corey Jeff Betsy Travis Arnaud]
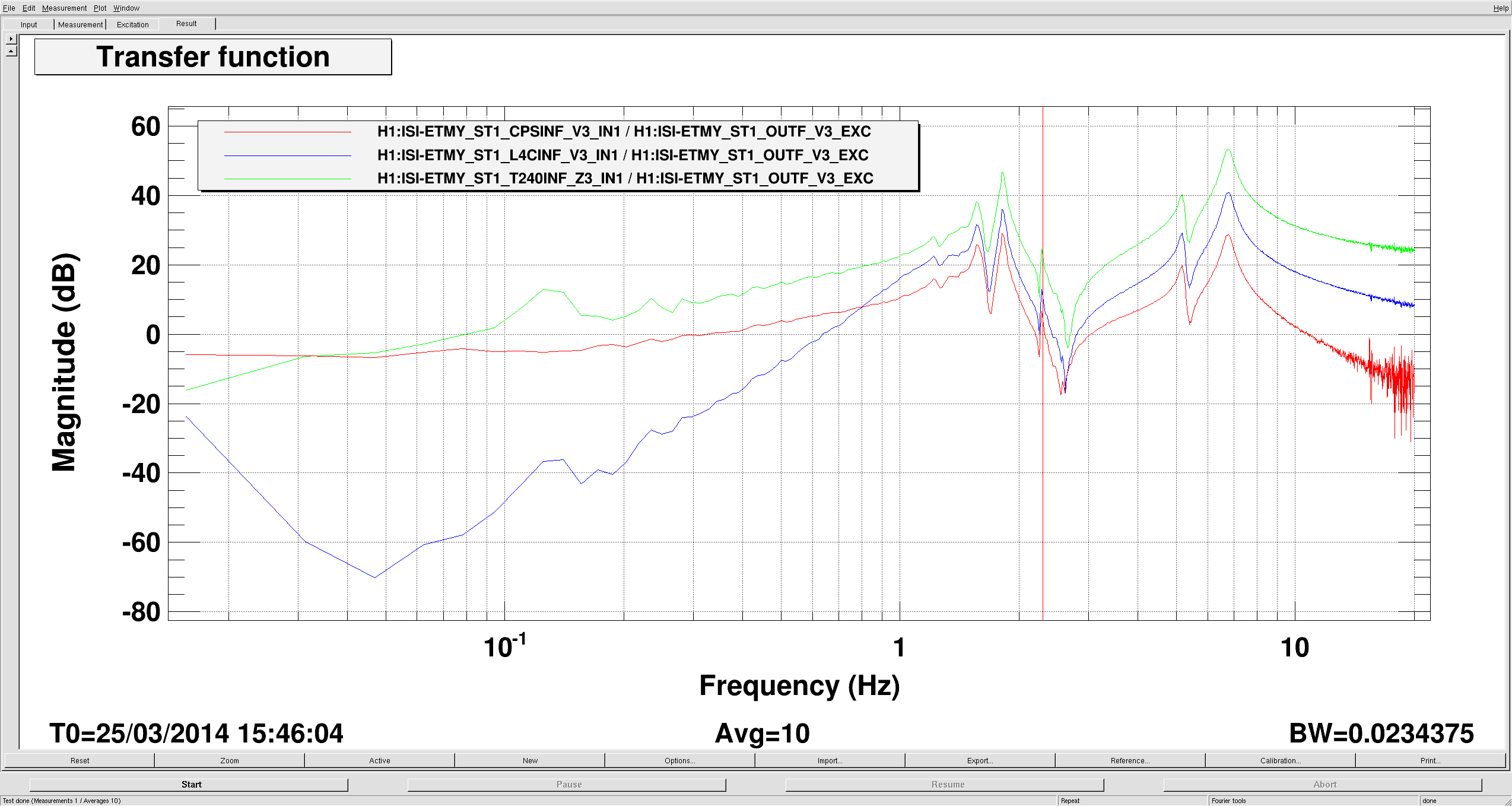
Today, we had several in chamber rounds in order to improve the roll/vertical transfer functions of the TMSY suspension. Results from last thursday night attached were still showing badness, especially in the roll degree of freedom with an extra mode at 0.89Hz (first pdf), but no TF has been ran between Friday's work, and this morning. The pdf attached shows TF comparison of TMSY in April last year (orange, used as "reference"), TMSY March 11th (black, first in chamber TF, before alignment work), and TMSY last thursday, march 20th, (pink)
In chamber work from today :
1) Corey and Jeff started by moving some of the earthquake stops (quick dtt tf was ran after, cf green curve of TMSY.png). No change, since 0.89Hz still present
2) Betsy tried centering some of the flags close from the edge of their osem (cf blue curve, taken after the work). No change
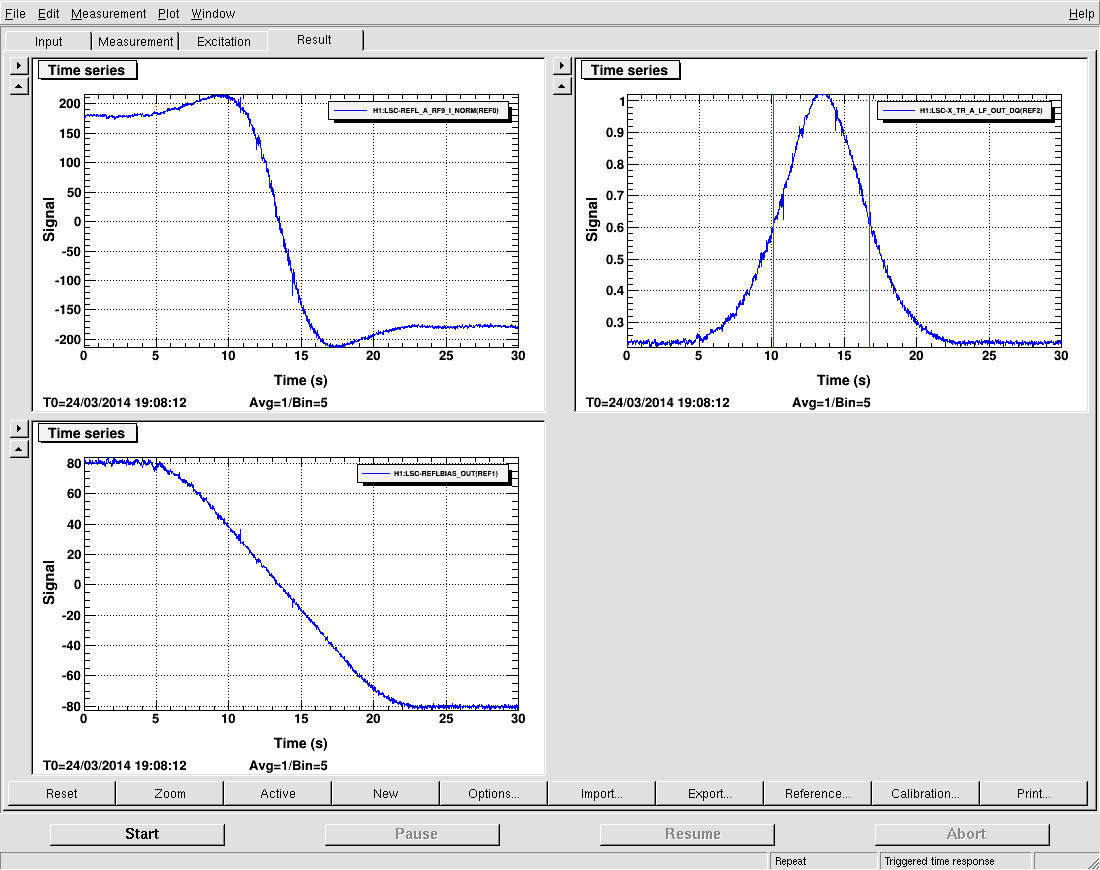
3) Finally, Travis and I modified the cable routing. First we gave some slack to the cable between ISI and top mass by changing the orientation of the clamp. This significantly moved the top mass, that was probably beeing hold by those cables. Some of the osems went completely out (cf Screenshot) so we had to recenter them. We took a quick dtt TF, but it still looked somehow not good enough. We then loosened the cablings between the table and the top mass. The red curve shows how the 0.89Hz moved to 0.8Hz after the overal work.
I will run long measurements overnight, to have an idea of what's happening on the other degrees of freedom, but it sounds like their will be more cable routing work, as well as alignments to check.
Note that LLO recently had the go through the same process, cf Stuart's alog, and mitigated the issue by modifying the cables routing.
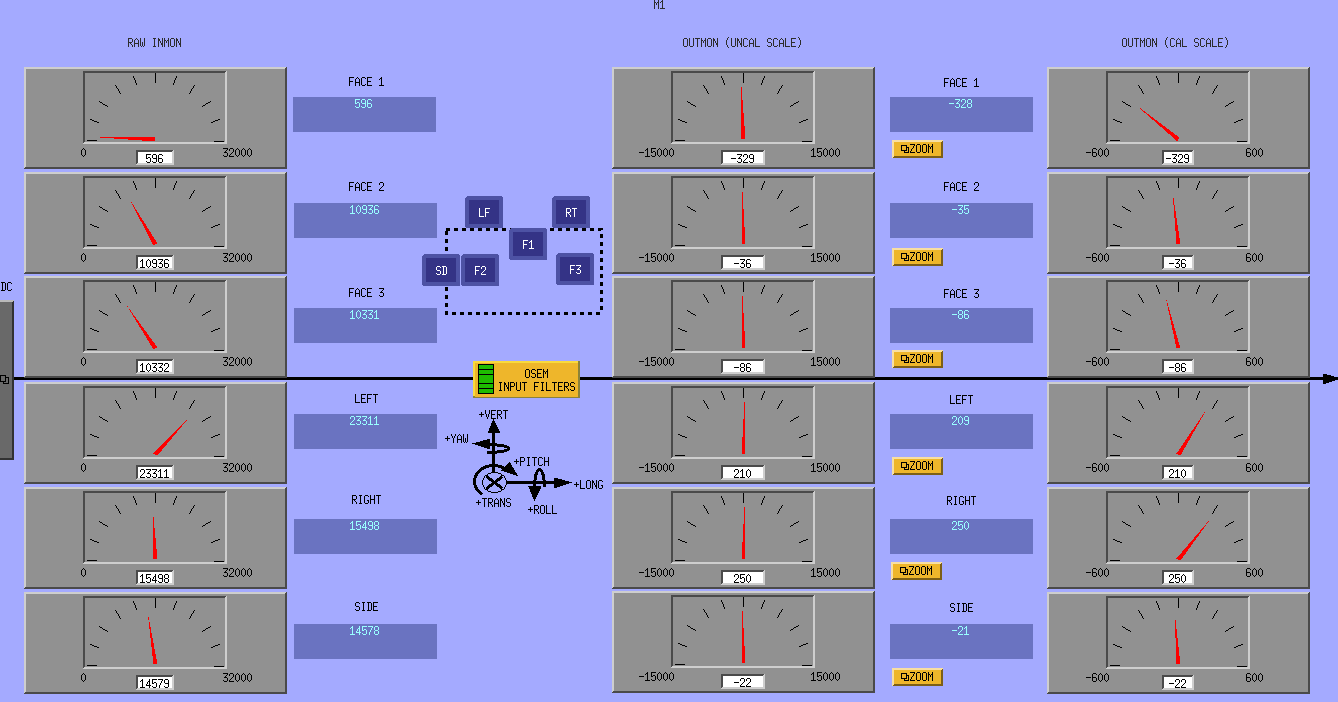

Here are some additional notes about in-chamber work today.
In-Chamber Notes:
Round 1 (Jeff & Corey)
With news of ugly peaks over the weekend from SEI TFs, Jeff & I went out to inspect the TMS for any issues (Jim locked up the ISI prior to us going in). There was nothing obvious. But Jeff did notice an internal EQ Stop being close to a wire (one from upper spring to Upper Mass); so he screwed it in a little. He then tightened all the EQ Stop screws. That was all that was done. (Jim then un-locked the ISI again)
We came back to the Control Room and were going to run some measurements, but noticed that the BOSEMs were no longer centered (!). We went out to the TMS again and centered the BOSEMs yet again (locking & unlocking the ISI as needed). We then had Arnaud run a few measurements at this point.
(as for the BOSEMs moving around....chatted with Keita, and he suspected it was due to the ISI being unlocked.)
NOTE: while inspecting the TMS, Jeff noticed the quad of magnets on some of the BOSEMs. He was surprised to see them, since other suspensions replaced them with metal blocks, per Robert Schofield's request.
Round 2 (Betsy & Corey)
Since Arnaud's measurements still showed ugly peaks at 0.88 & ~2.5Hz, Betsy & I went out yet again for inspection. She noticed Flags low for F1 & F2 (so the BOSEM Adjustment Plate was moved up). She also noticed the quad of magnets off-center for the Left BOSEM, so adjustment plate was moved forward. I re-centered BOSEMs. (ISI was locked/unlocked accordingly).
NOTE: Betsy & Arnaud said I should use the "calibrated speedometer" signals to center BOSEMs vs the BOSEM inputs, so I did this (Keita mentioned we should use the BOSEM inputs instead.
Chalking Up To Hindsight. For Future End Station Work: OK TMS Bill Of Health Immediately AFTER In-Chamber Close-Out Work
Even it takes more time, we should add the checking of the TMS & posting the ACCEPTED Free Swing spectra and/or transfer function before handing off to SEI, just to help rule out TMS if there are any questionable SEI TFs. In other words, if there are any issues with the TMS, we'll be address them faster and will be able to hand over to the SEI crew and know "for sure" TMS can't be a culprit.
...Well, I guess if when unlocking the ISI, there's the chance ISI Optics Table could have a different level compared to its locked state. (this is something Keita suggested we saw when see our BOSEMs not centered after the ISI was unlocked today).
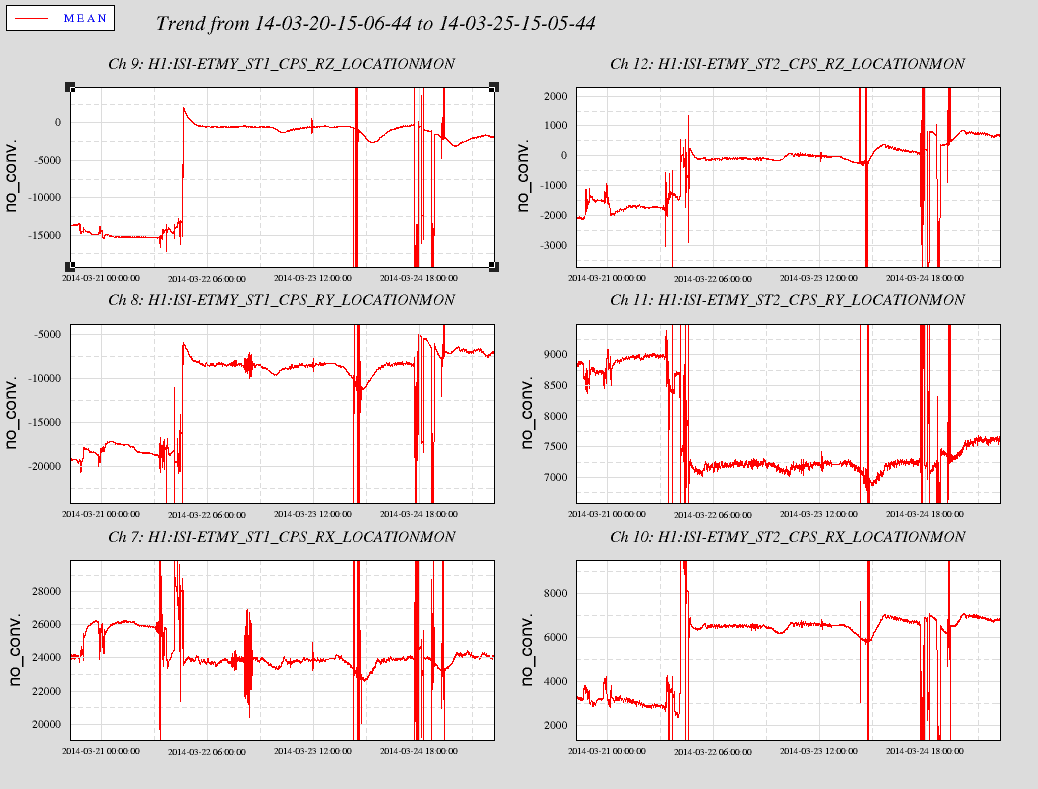
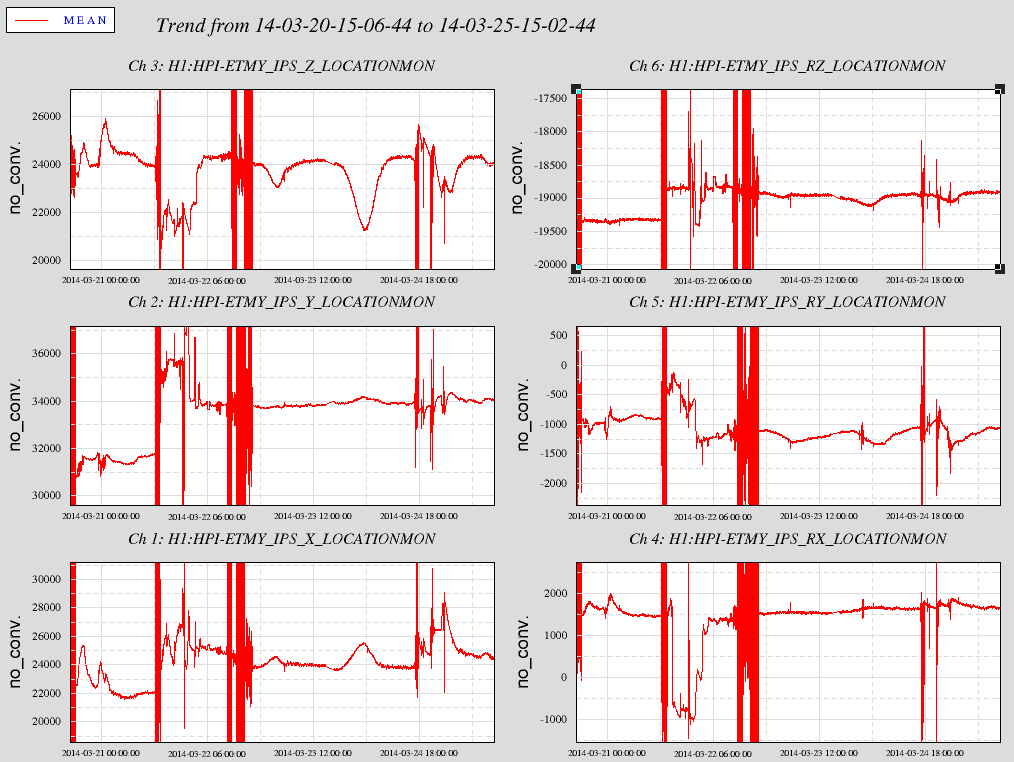
attached are trends of the HEPI and ISI IPS & CPS positions for the past 5 days.
The unlock of the ISI on Friday is seen on the trends where there are measurable shifts. Since then the positions have been fairly stable and repeatable. The worst thing I see in this data is ~9urads tilt in the ISI Ry. This amount of motion at the CPS is in the scale of 10s of counts and is not out of our lock/unlock tolerance. Don't know if this is significant to the TMS alignment etc.
The first plot is the CPS rotations: There is a 17urad Rz, 9urad Ry & 1urad Rx. The second plot is all the HEPIs which are all insignificant.
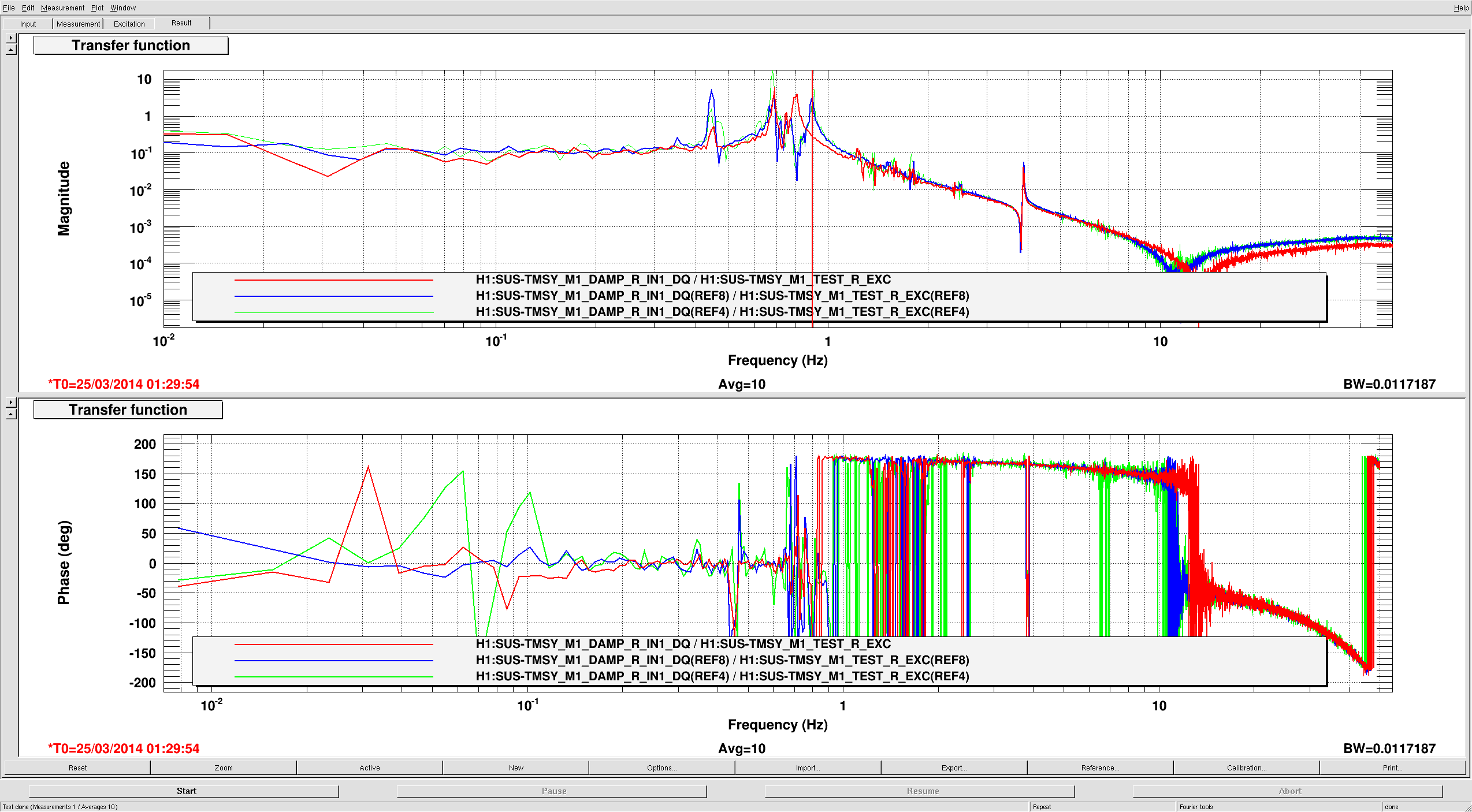
After all the TMS work yesterday, I took a quick DTT tf this morning. No change on the SEI side. The added peak is at 2.3 hz (not a change, I just hadn't gotten around to getting a precise measurement).
NOTE: Betsy & Arnaud said I should use the "calibrated speedometer" signals to center BOSEMs vs the BOSEM inputs, so I did this (Keita mentioned we should use the BOSEM inputs instead).
Both methods are similar :
1-The BOSEM inputs can be used if trying to reach half of the open light value (corresponding to -1*the offset value).
2-The calibrated signal can be used if trying to reach 0
for the record, calibrated signal (osem output) = [(osem input - open light/2)*15000/(open light/2)]*calibration_from_cts_to_um
in other words, when osem input varies from 0 to max (cts), the uncalibrated signal varies from -15000 to 15000 (cts) and the calibrated signal from -345 to 345 (um)