WP12131 h1tcscs model, add FMs and Voltage slow channels
Daniel, Vicky, Dave:
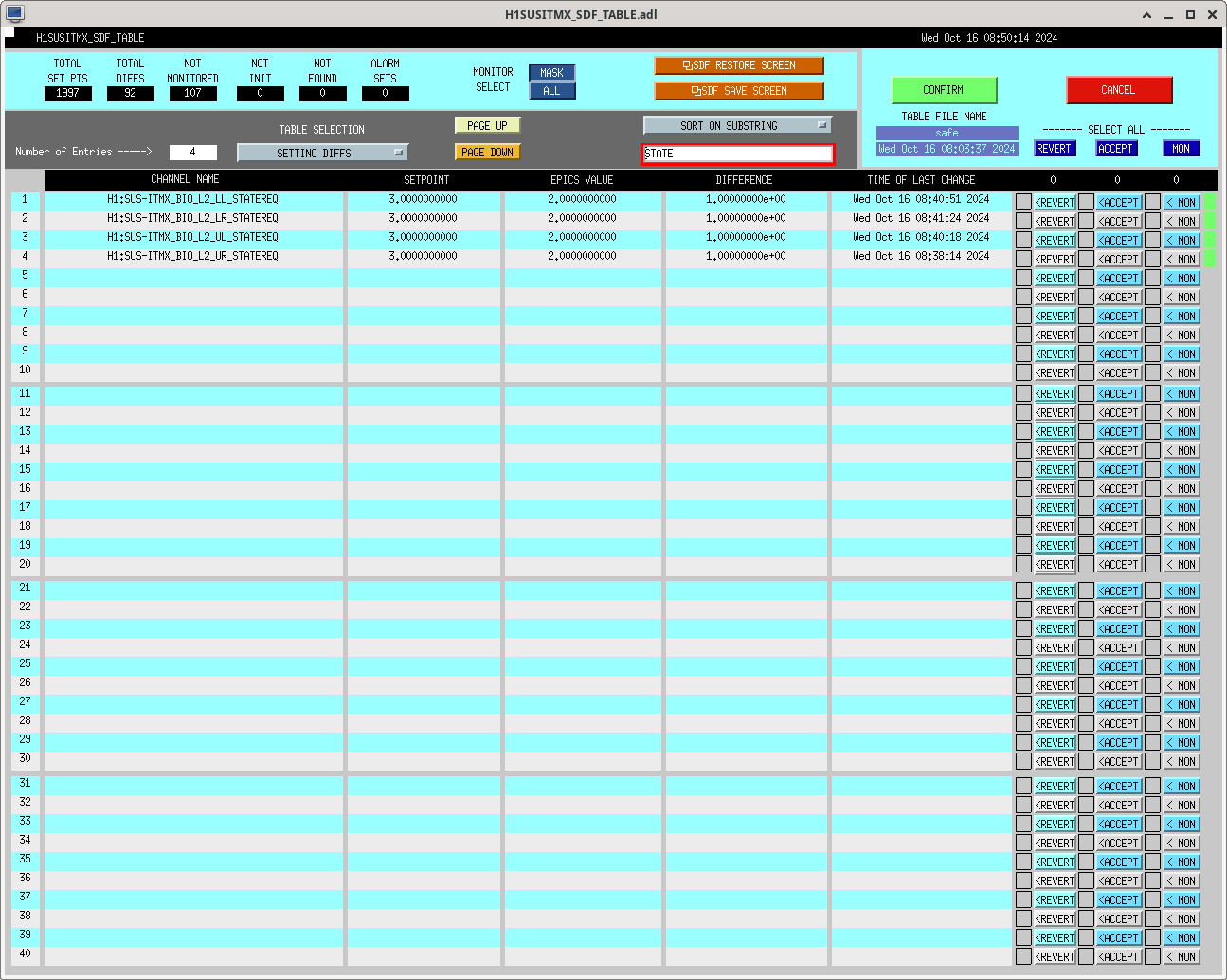
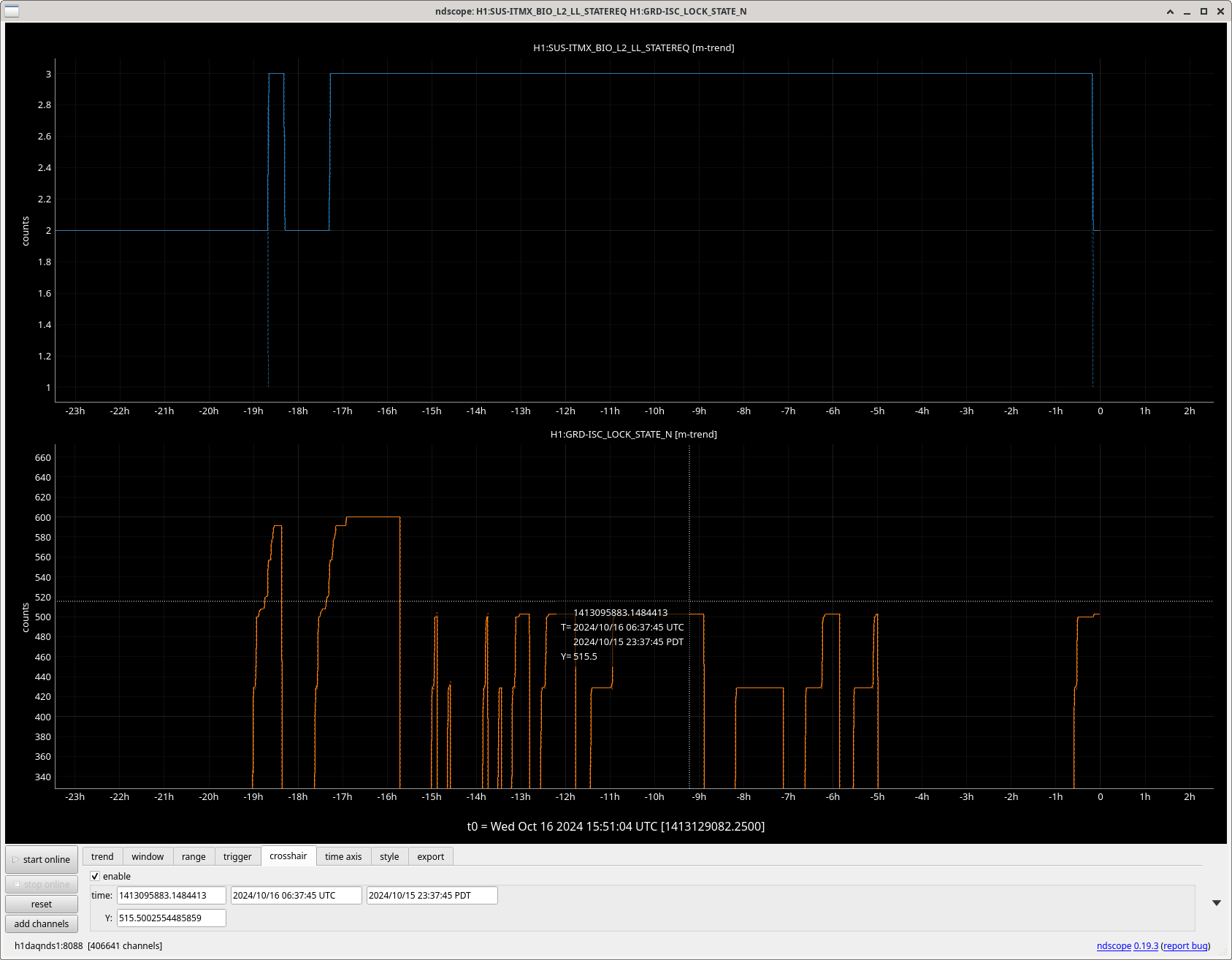
A new h1tcscs model was installed when h1oaf0 was rebooted this morning. DAQ restart was required, the addition of 51 slow channels.
WP12132 New Dolphin adapter card Firmware.
Keith, Jonathan, Erik, EJ, Tony, Dave:
Downgraded firmware was loaded onto the Dolphin IX-611 adapter cards in h1sush7, h1cdsh8 and h1oaf0. This is to prevent sponteneous PCI level switching which is possibly the cause of some O4 cornerstation Dolphin glitches.
Procedure was:
- safe the systems running on the frontend
- fence the frontend from the Dolphin fabric
- stop all the models
- run the script to load the new firmware
- power down the frontend, then pull the two power cords out for about a minute
- plug the power cords in, power up, let it boot and start the models.
WP12134 DAQ Restart Script, Restart rts-nds.service
Jonathan, Erik, Dave:
To prevent /run/nds/jobs filling, the scripts to restart the DAQ was modified to restart the rts-nds.service on the nds machines as well as restarting their rts-daqd.services.
This allows systemd to empty the /run/nds/jobs directory, which was over 50% full on h1daqnds1. We tested this as part of this morning's DAQ restart, it worked well.
WP12087 Add VACSTAT gauge PVs to DAQ
Dave:
My first attempt to add the VACSTAT PVs relating to vacuum gauge monitoring failed because the channel names exceeded the DAQ length limit of 54 characters.
I modified the VACSTAT code to drop the _PRESS_TORR from the PT channels names, which allowed these channels to be added to the DAQ.
A new H1EPICS_VACSTAT.ini file was created which added 368 channels to the EDC. DAQ and EDC restart was needed.
The new VACSTAT IOC was restarted, and the new MEDMs installed into production.
WP12143 Replace failed SDD in h1guardian1
Dave, Jonathan, Erik:
cds_report reported a failed disk in h1guardian1's md3 raid at noon today. Jonathan and Erik found a failed 230GB SDD which is part of the root file system on h1guardian1. It was replaced with a 1TB SSD (the smallest we have), resyning the new disk only took about an hour.
DAQ Restart
Jonathan, Erik, Dave:
We restarted the DAQ for the addition of h1tcscs slow channels and the new VACSTAT EDC channels. EDC was restarted, its channel count increased from 57061 to 57429.
This was the first test of the new restart script, which after doing the round of rts-daqd restarts then restarts rts-nds on the nds machines.
The only problem was a spontaneous retstart of framewriter 1 after it had written about 3 full frames. It came back by itself and has been stable since.