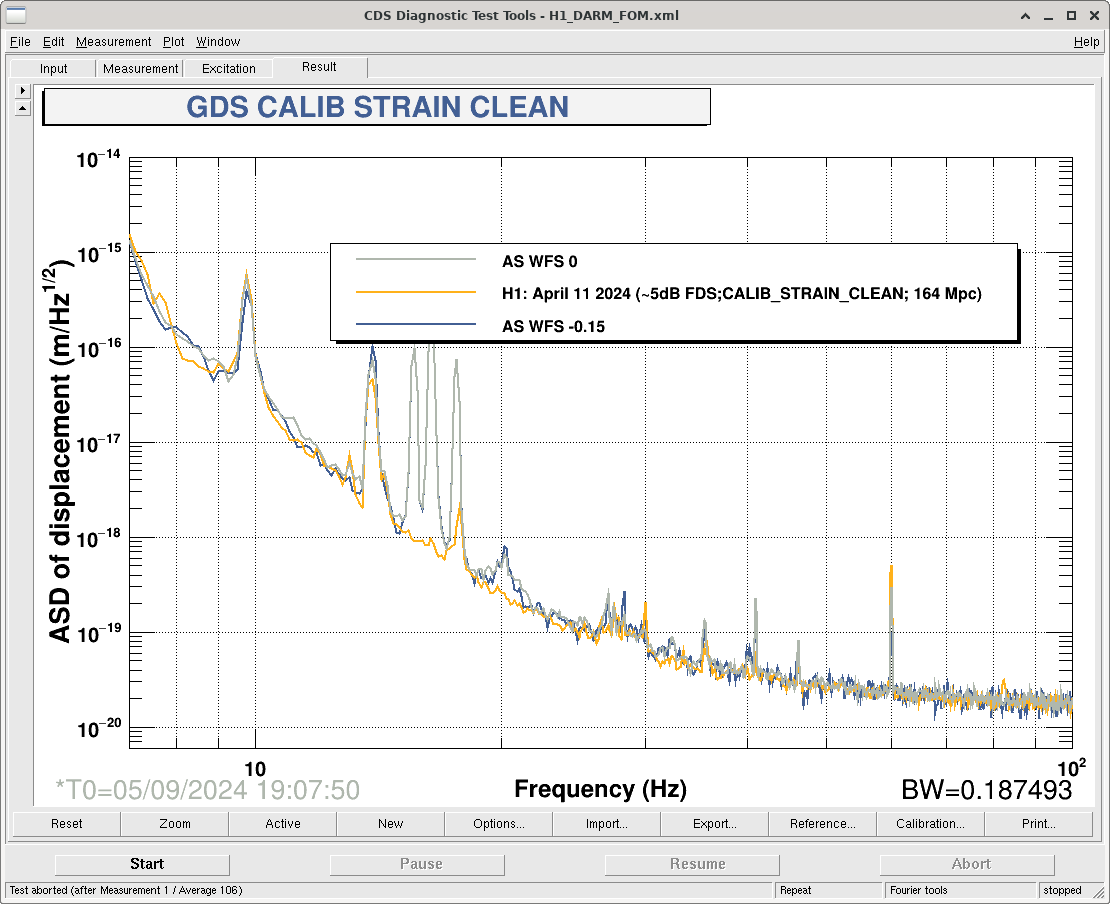
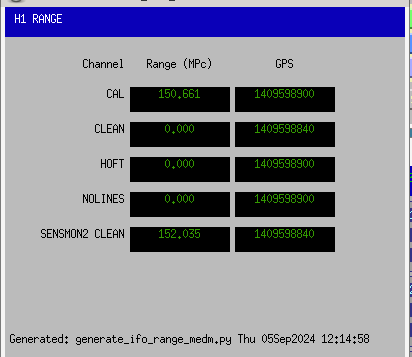
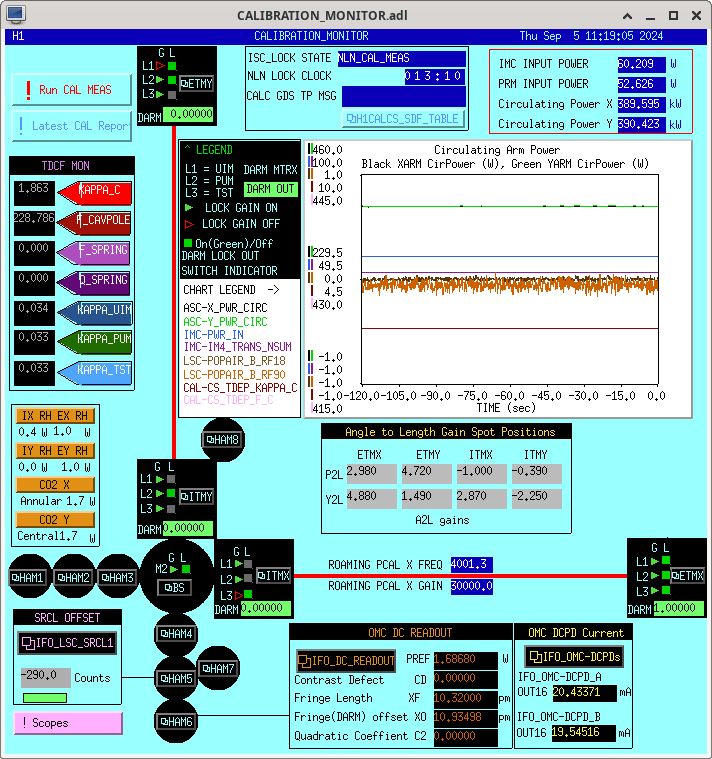
Ryan C, Rahul
We have finished the assembly of the 10th Ham Relay Triple Suspension (HRTS) for O5, which is being assembled and characterized in the stagings clean room lab upstairs. In June we reported the assembly and testing of first five Freestanding HRTS suspension (see LHO alog 78574 and 78711), since then we have built an additional five of them, thus bringing the total count to ten for both the sites (with two more to go, total twelve required between LHO & LLO which includes one spare at each site).
I have attached several pictures (attachment01, attachment02, attachment03, attachment04) below which shows the assembled & locked HRTS stored in the lab on the flow bench in the clean room. Picture01 shows an HRTS with BOSEMs and cables attached, ready to be characterized on test stand (reference pic is shown here).
In this round of HRTS assembly work we have assembled three Freestanding configuration, one Suspended version (shown in the attachment05 below) and one OM0 (attachment06). The Suspended version of HRTS will be attached to the new BBSS (beam splitter) in O5 and Om0 will have bottom mass (optic) actuation using AOSEMS.The top mass will be controlled by 6 BOSEMs which is common for all types of HRTS.
After finishing the assembly work, we balanced all three stages of the suspensions for all six degrees of freedom. This involved lowering and matching blade tip height and angle on the top stage (2 blade springs) and on the top mass (4 blade springs). In all the cases, optic's lowest edge was lowered to a height of 40.5mm (+-0.5mm) from the bottom of the cage. The PUM and Top Mass height was adjusted based on the scribe lines on the structure.
Given blow are the details (OLV, offsets and Gain) of the six BOSEMs attached the HRTS.
1. Structure no. 07, Configuration: Suspended
Suspended masses: Top Mass = 755gm, Penultimate mass = 802gm, Dummy optic = 300gm
BOSEMs s/n D060108-E. S1900741, S1900749, S1900622, S1900662, S1900637, S1900613.
| OLV | OFFSETS | GAIN |
| 30830 | -15415 | 0.973078 |
| 27619 | -13809.5 | 1.086209 |
| 25585 | -12792.5 | 1.172562 |
| 24300 | -12150 | 1.234568 |
| 26400 | -13200 | 1.136364 |
| 26872 | -13436 | 1.116404 |
2. Structure no. 06, Configuration: OM0
Suspended masses: Top Mass = 755gm, Penultimate mass = 802gm, Dummy optic = 301gm
BOSEMs s/n D060108-E. S1900726, S1900723, S1900746, S1900732, S1900742, S1900747
| OLV | OFFSETS | GAIN |
| 31111 | -15555.5 | 0.964289 |
| 30571 | -15285.5 | 0.981322 |
| 32384 | -16192 | 0.926383 |
| 24964 | -12482 | 1.20173 |
| 26685 | -13342.5 | 1.124227 |
| 26905 | -13452.5 | 1.115034 |
3. Structure no. 04, Configuration: Freestanding
Suspended masses: Top Mass = 758gm, Penultimate mass = 802gm, Dummy optic = 301gm
BOSEMs s/n D060108-E. S1900749, S1900722, S1900724, S1900735, S1900740, S1900744
| OLV | OFFSETS | GAIN |
| 30687 | 15343.5 | 0.977613 |
| 27768 | 13884 | 1.08038 |
| 28421 | 14210.5 | 1.055558 |
| 26807 | 13403.5 | 1.119111 |
| 26432 | 13216 | 1.134988 |
| 30319 | 15159.5 | 0.989479 |
4. Structure no. 05, Configuration: Freestanding
Suspended masses: Top Mass = 755gm, Penultimate mass = 803gm, Dummy optic = 300gm
BOSEMs s/n D060108-E. S1900730, S1900727, S1900750, S1900738, S1900743, S1900734
| OLV | OFFSETS | GAIN |
| 30534 | -15267 | 0.982511 |
| 29900 | -14950 | 1.003344 |
| 26531 | -13265.5 | 1.130753 |
| 26624 | -13312 | 1.126803 |
| 24670 | -12335 | 1.216052 |
| 29626 | -14813 | 1.012624 |
5. Structure no. 09, Configuration: Freestanding
Suspended masses: Top Mass = 758gm, Penultimate mass = 800gm, Dummy optic = 300gm
BOSEMs s/n D060108-E. S19007309 S1900725, S1900733, S1900736, S1900803, S1900728
| OLV | OFFSETS | GAIN |
| 31068 | -15534 | 0.965624 |
| 30716 | -15358 | 0.97669 |
| 27512 | -13756 | 1.090433 |
| 25864 | -12932 | 1.159913 |
| 26362 | -13181 | 1.138002 |
| 32378 | -16189 | 0.926555 |
********************************************
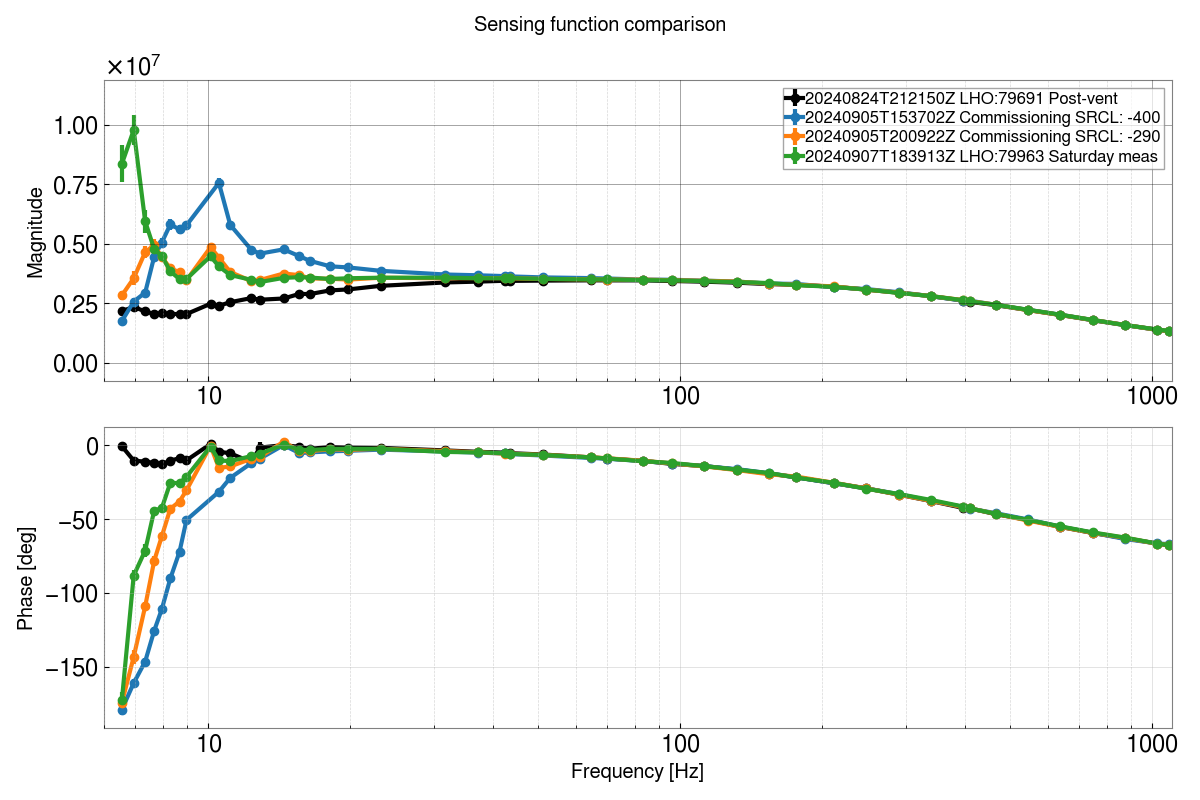
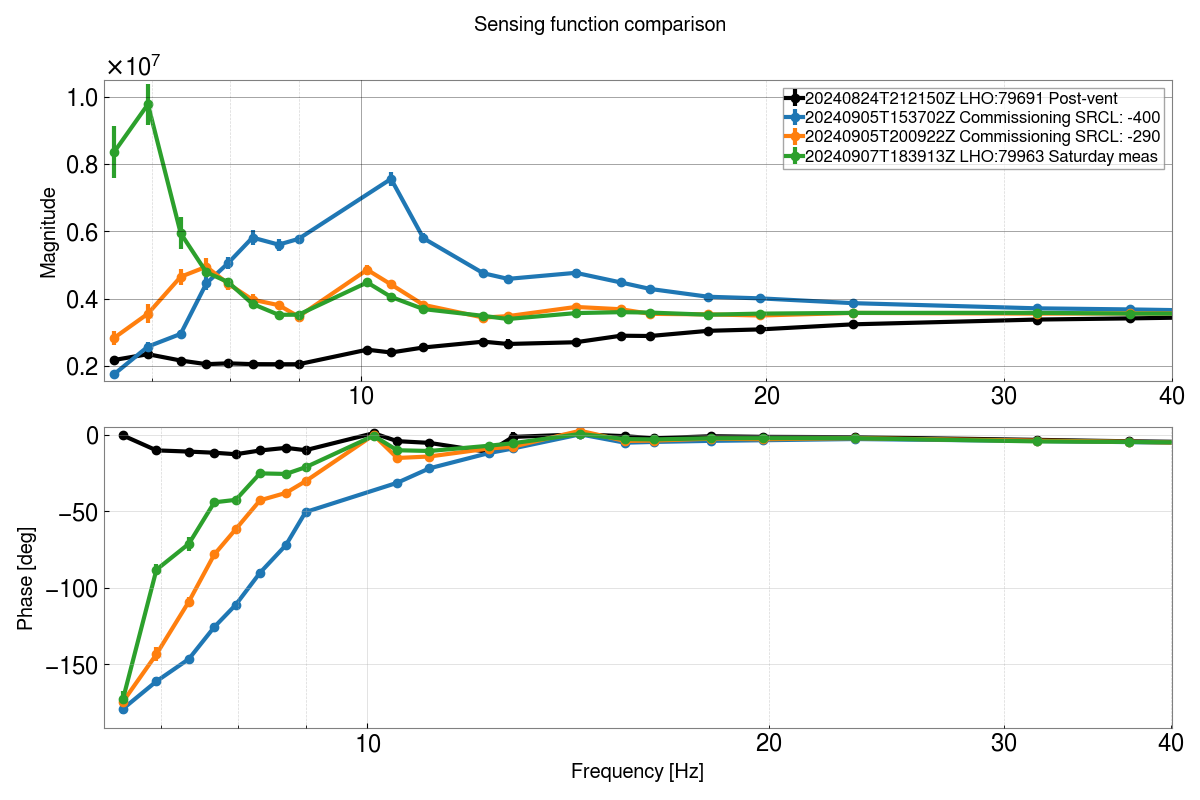
Note- The test results of the suspension will be posted below as comments.







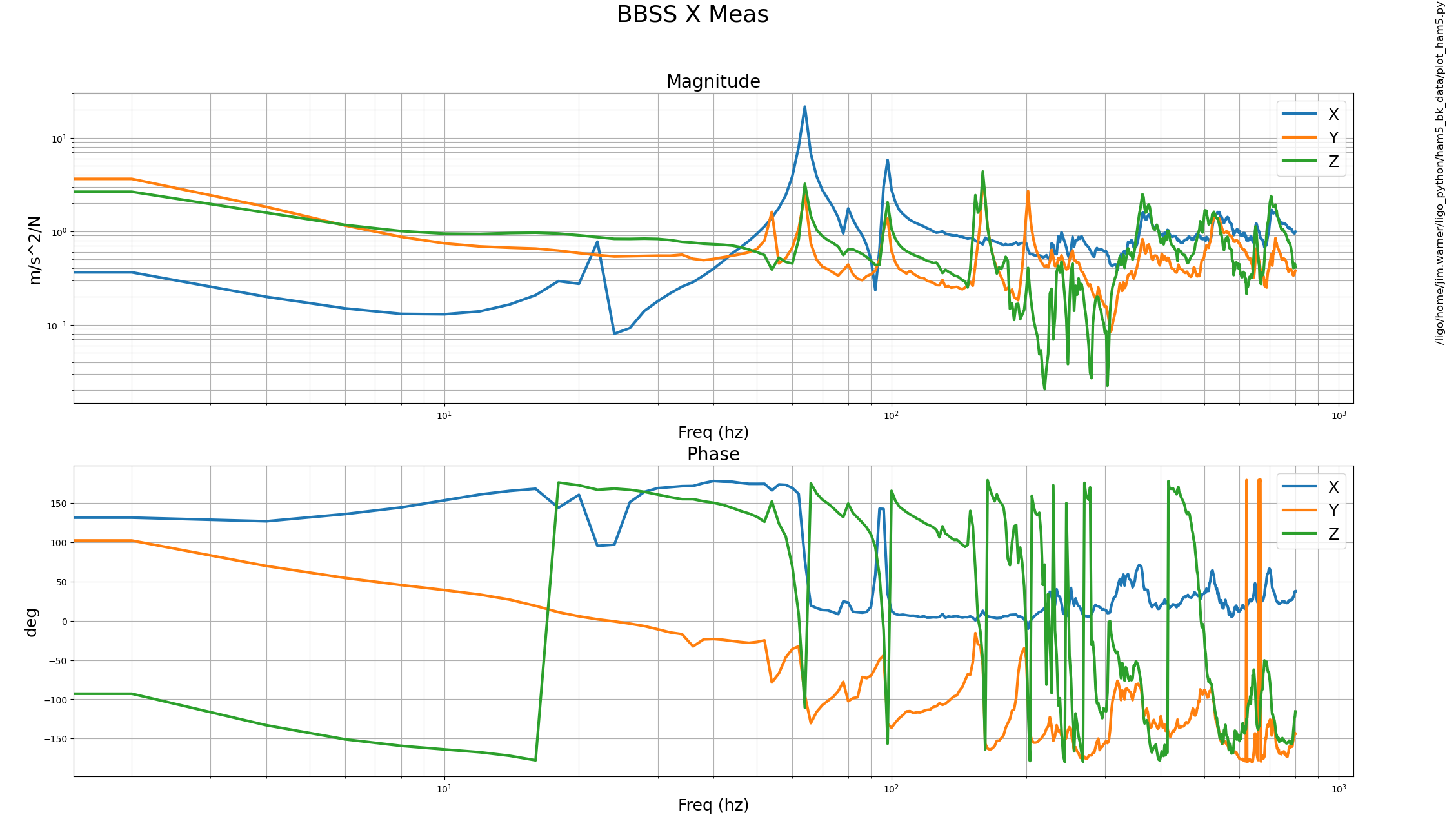
Test results for structure no. 07, Configuration:- Suspended
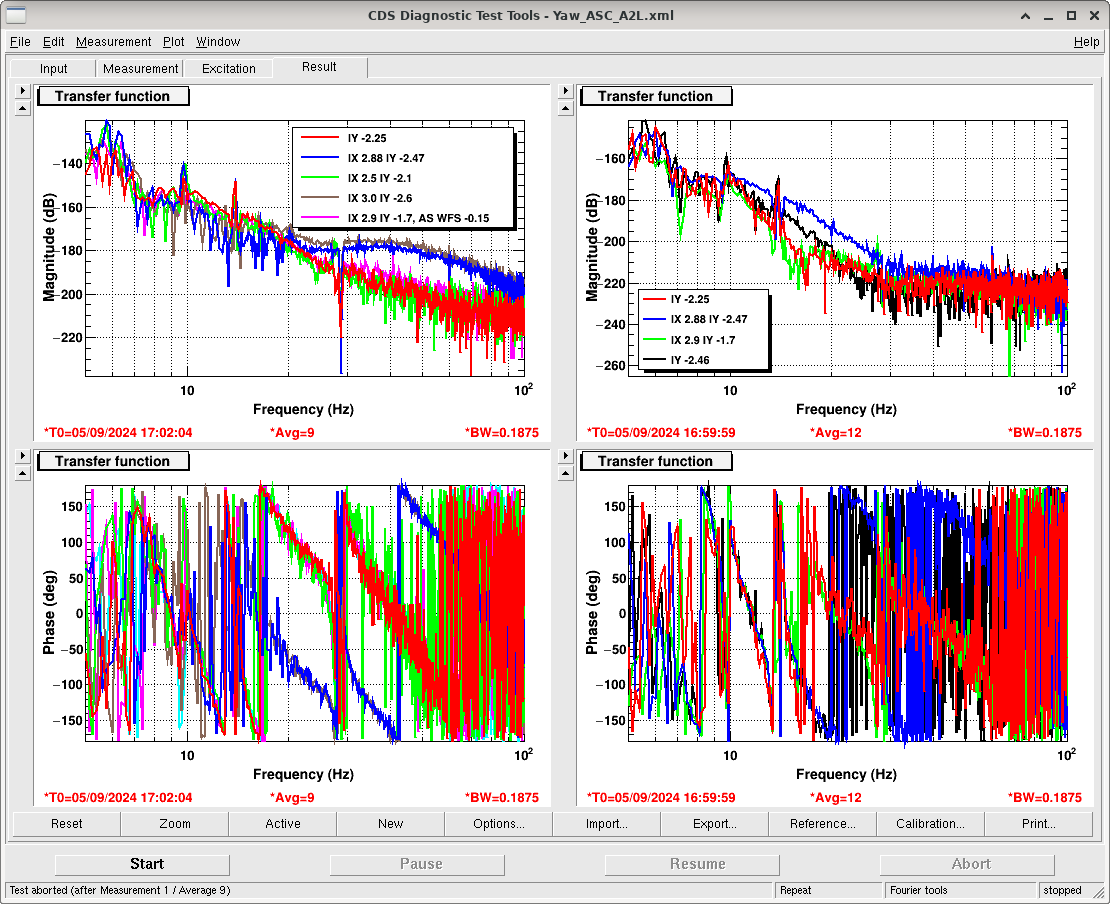
Attachment01 shows the transfer function results along with individual osem results, compared against the model
Attachment02 shows the top to top transfer function measurement results for all 6 dof and attachment03 is the zoomed in version of the same. The plots shows three measurements (taken on Aug 12, Aug 19 and Aug 21) after making mechanical changes to the suspension, which includes replacing the bottom wire loop to remove heaving pitch on the optic (caused due to faulty springs in the wire pulling jig). There is some low frequency (0.8Hz approx.) cross coupling in T dof from Yaw. V dof still has R coupling into it. The magnitude for R dof is slightly low when compared against the model.
We have tried to fine tune the suspension to remove cross coupling and improve the TF magnitude, how it looks like we still need to do so some work over here to further refine the results.This work is still ongoing.

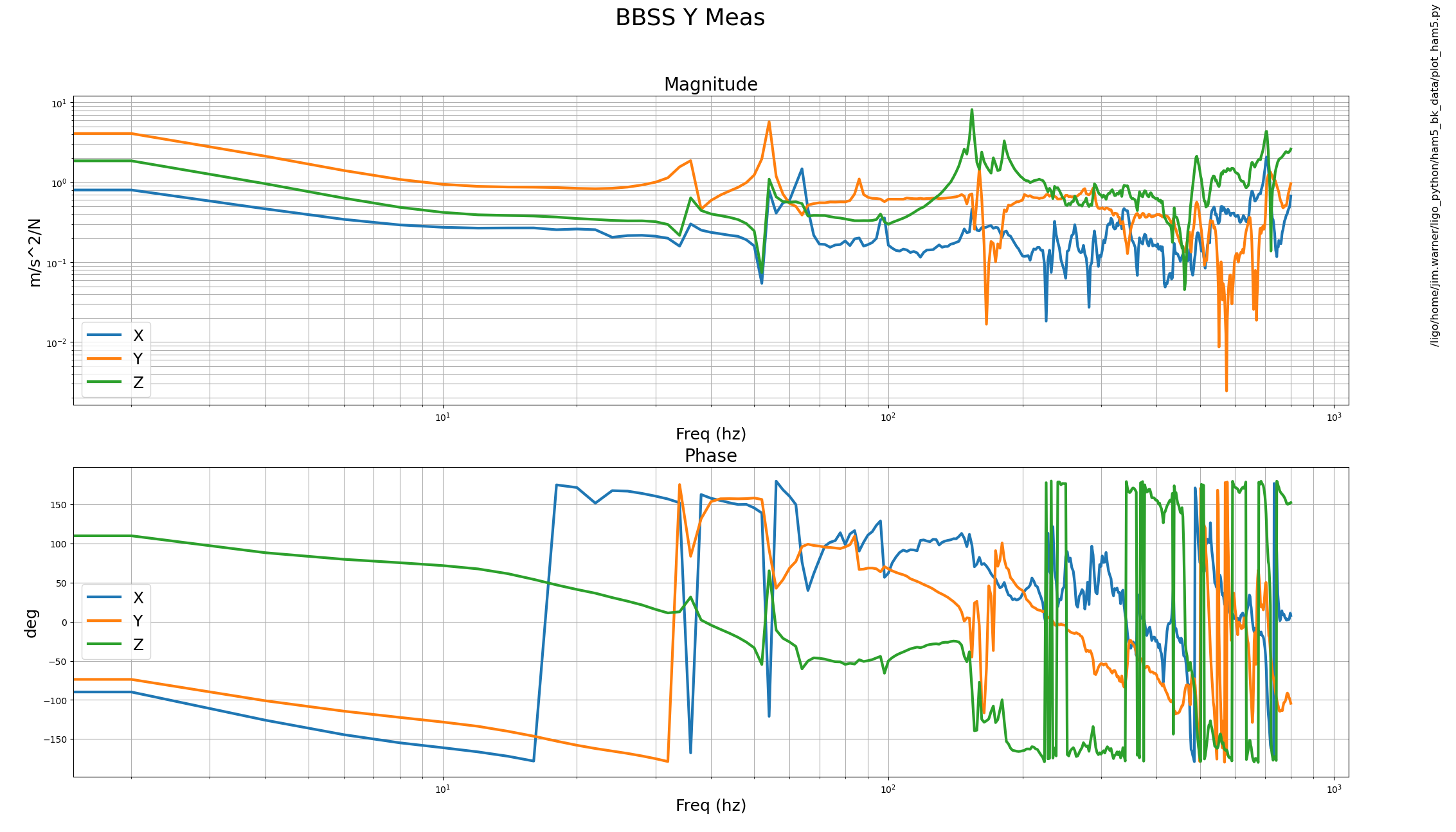
Test results for structure no. 06, Configuration:- OM0
Attachment01 shows the transfer function results along with individual osem results, compared against the model
Attachment02 shows the top to top transfer function measurement results for all 6 dof and attachment03 is the zoomed in version of the same.
L, P, T and Y dof looks fine, although there is a slight frequency shift at Yaw. However the magnitude for R dof is slightly lower than the model and V dof has cross coupling from R which needs further work.
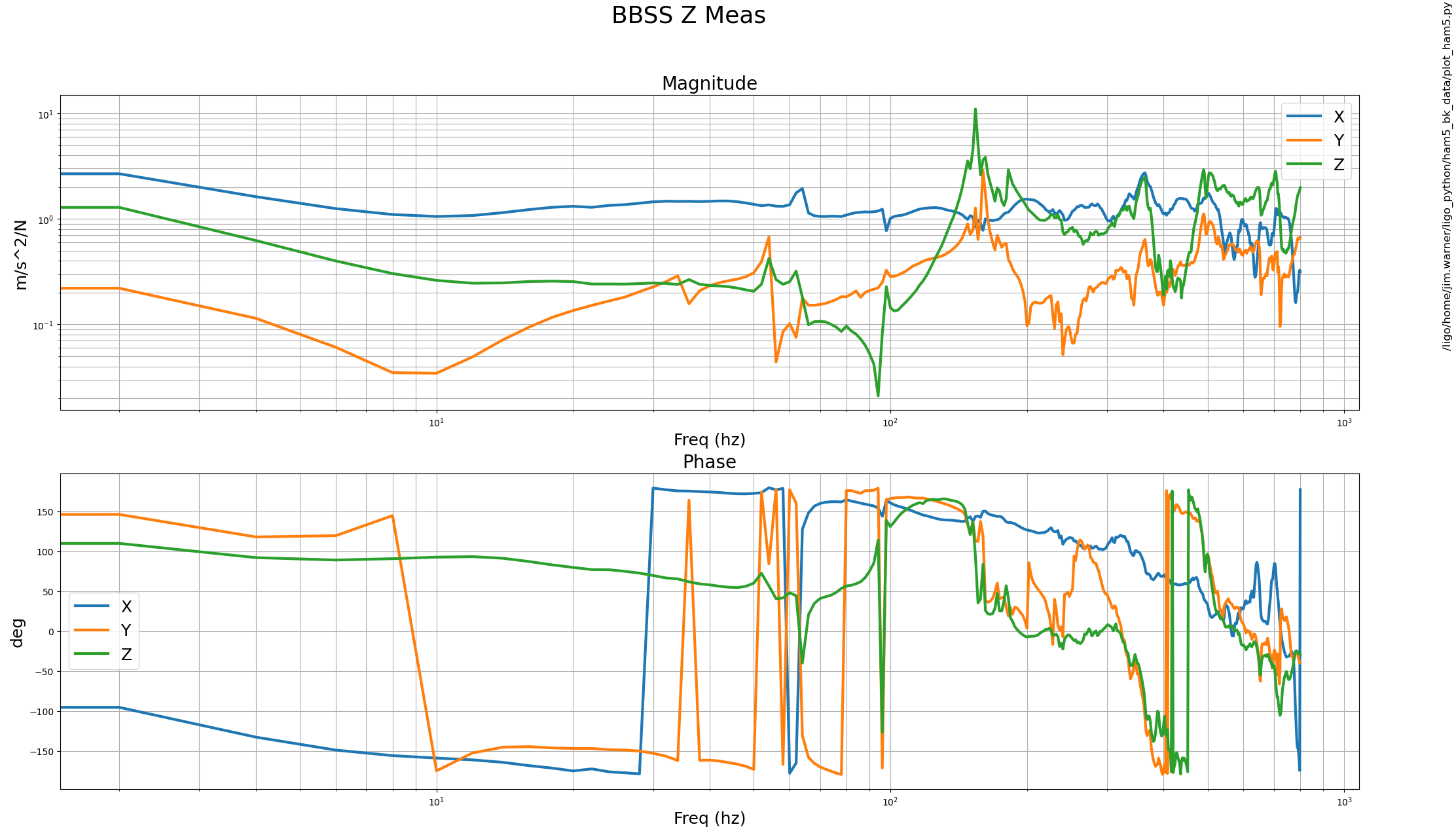
Test results for structure no. 04, Configuration:- Freestanding
Attachment01 shows the transfer function results along with individual osem results, compared against the model.
Attachment02 shows the top to top transfer function measurement results for all 6 dof. Overall the suspension looks healthy. V and Rdof in this case has given us a lot of trouble and after a lot of fine tuning (of the suspended chain, bosems, flags etc) we have been able to bring the results as close as possible to the model. The black trace on V dof was measured with flags at an angle with respect to the PD/LED of the bosem, once corrected the magnitude improve as seen in pin and orange trace.
Test results for structure no. 05, Configuration:- Freestanding
Attachment01 shows the transfer function results along with individual osem results, compared against the model
Attachment02 shows the top to top transfer function measurement results for all 6 dof and attachment03 is the zoomed in version of the same.
V and R dof needs some improvement which is currently ongoing. The rest of them looks healthy.
Test results for structure no. 09, Configuration:- Freestanding
Attachment01 shows the transfer function results along with individual osem results, compared against the model
Attachment02 shows the top to top transfer function measurement results for all 6 dof and attachment03 is the zoomed in version of the same.
The suspension looks healthy and I am happy with the transfer function results. The cross coupling at Vdof (which is common to all the HRTS) needs some attention, which is currently ongoing.

{kind=link}
{kind=link}