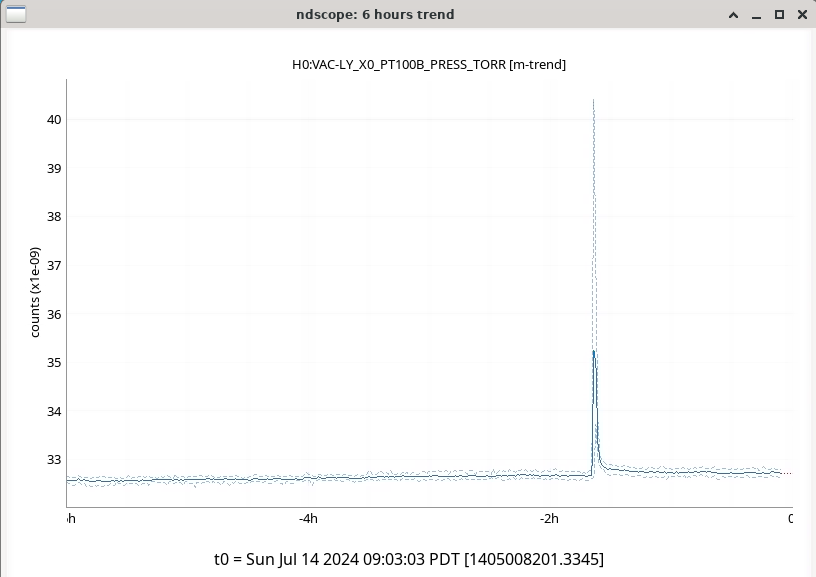
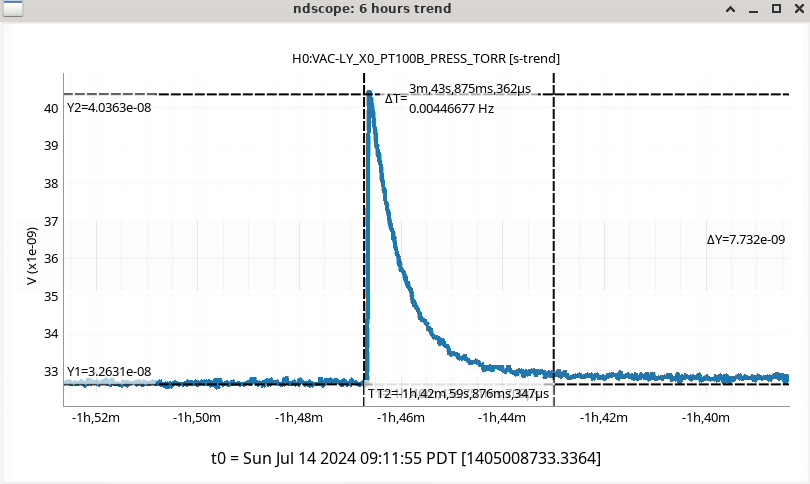
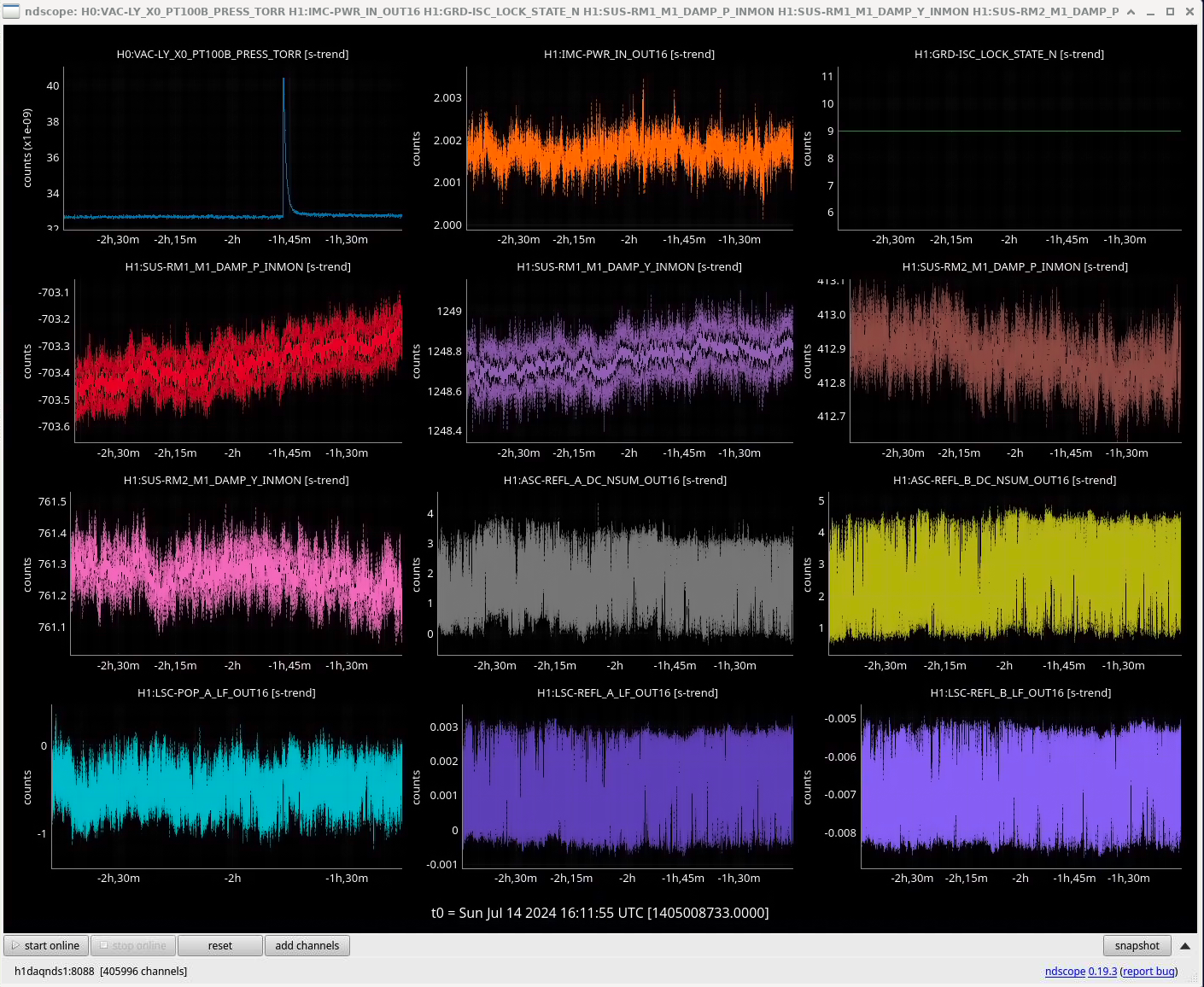
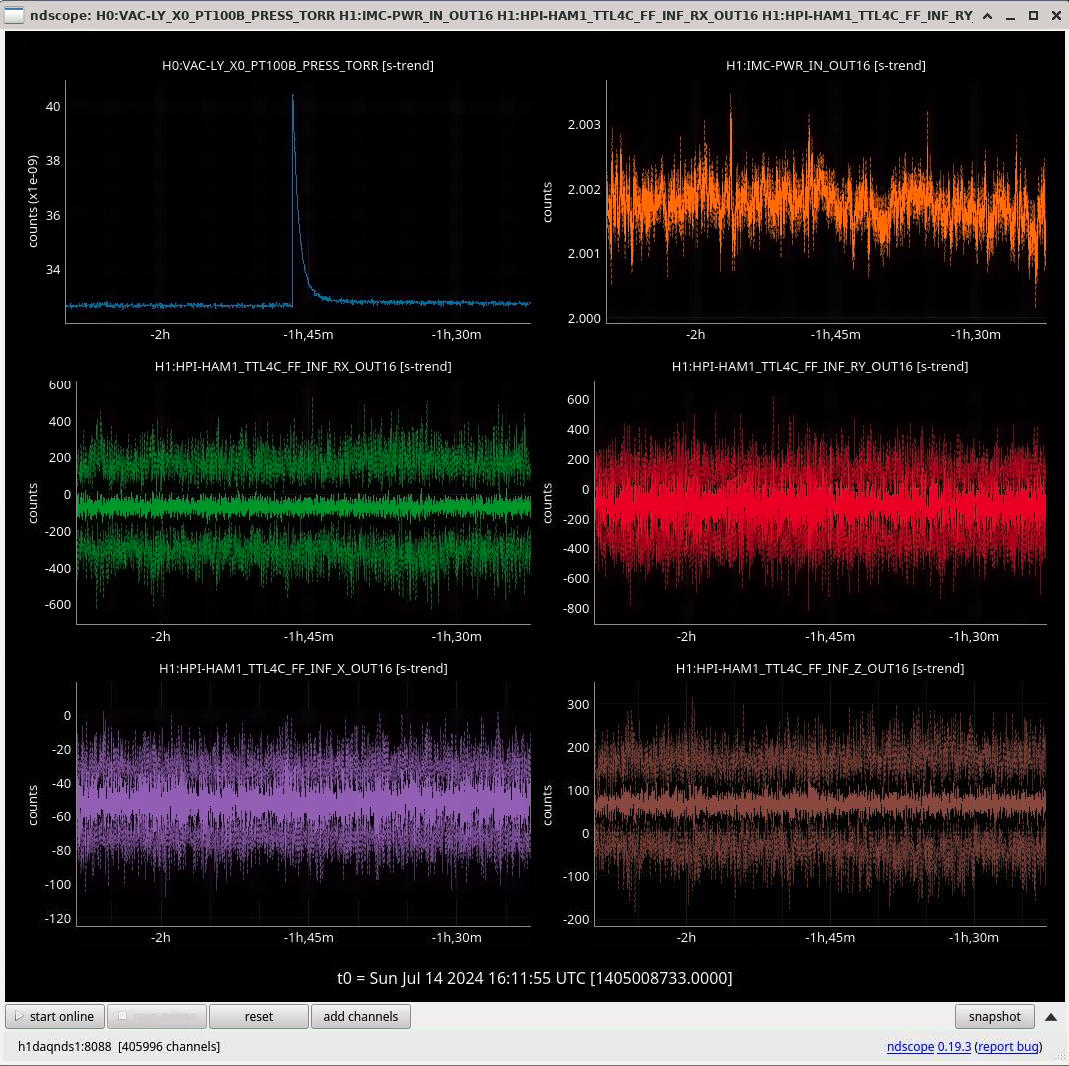
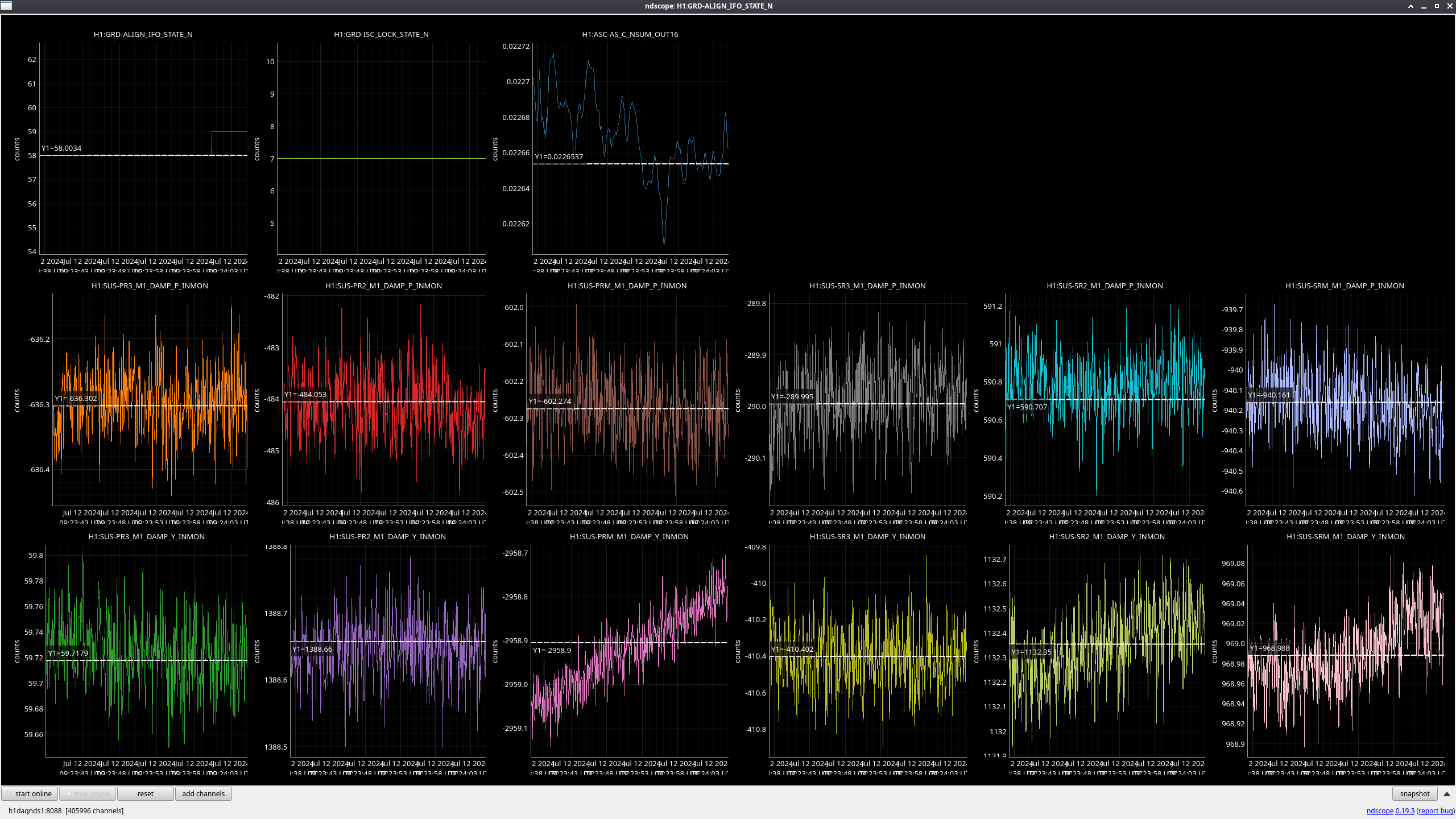
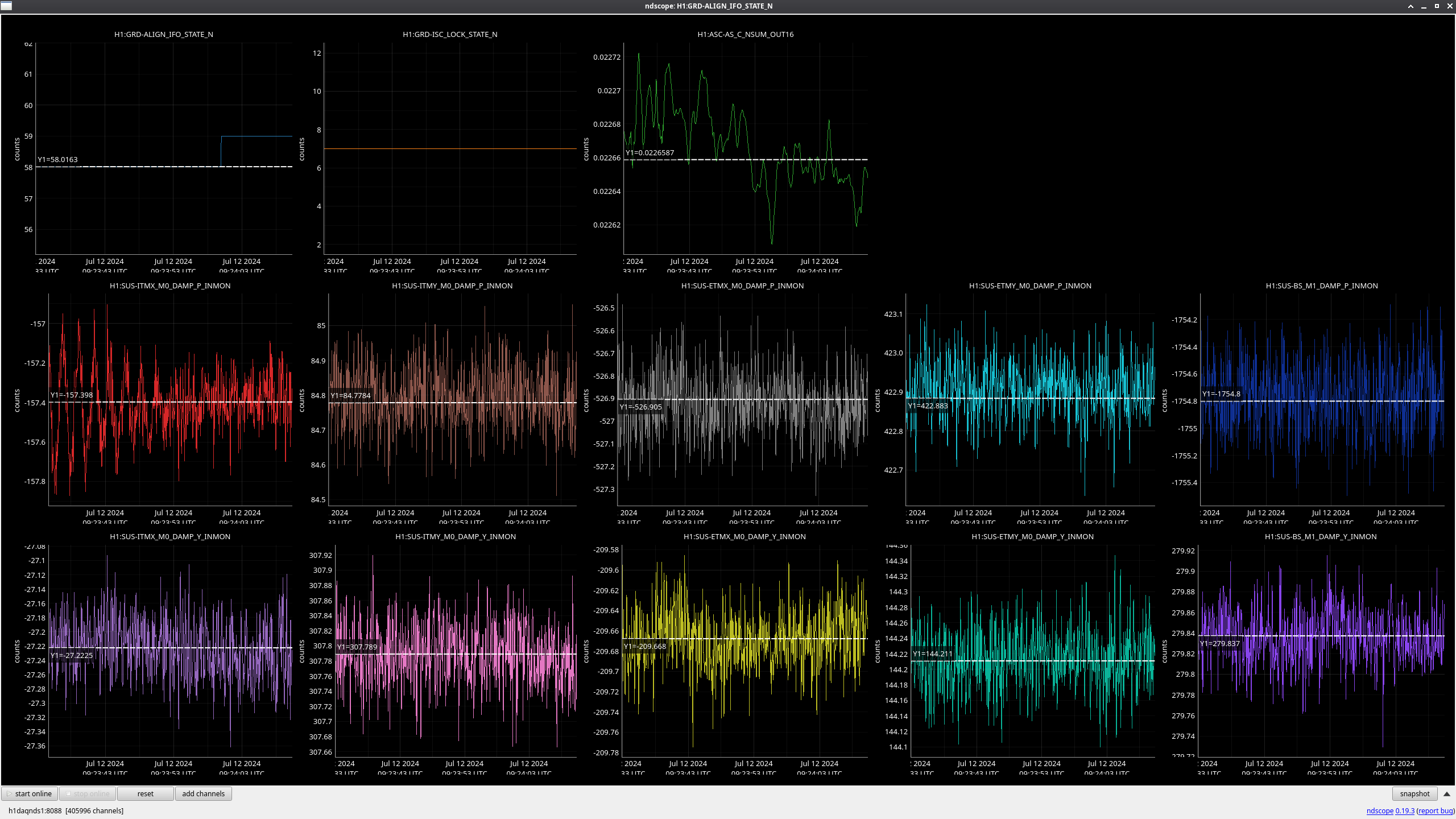
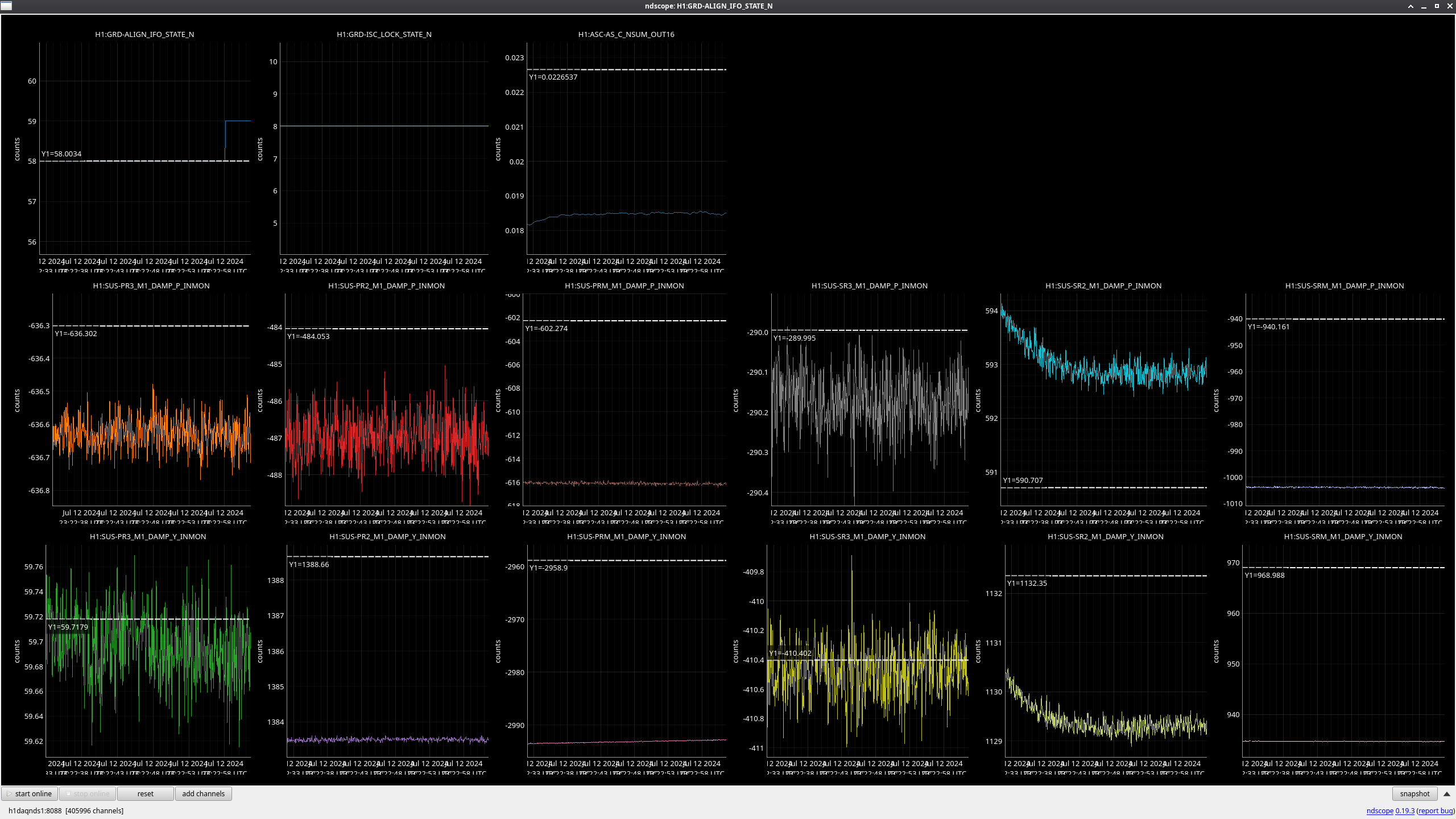
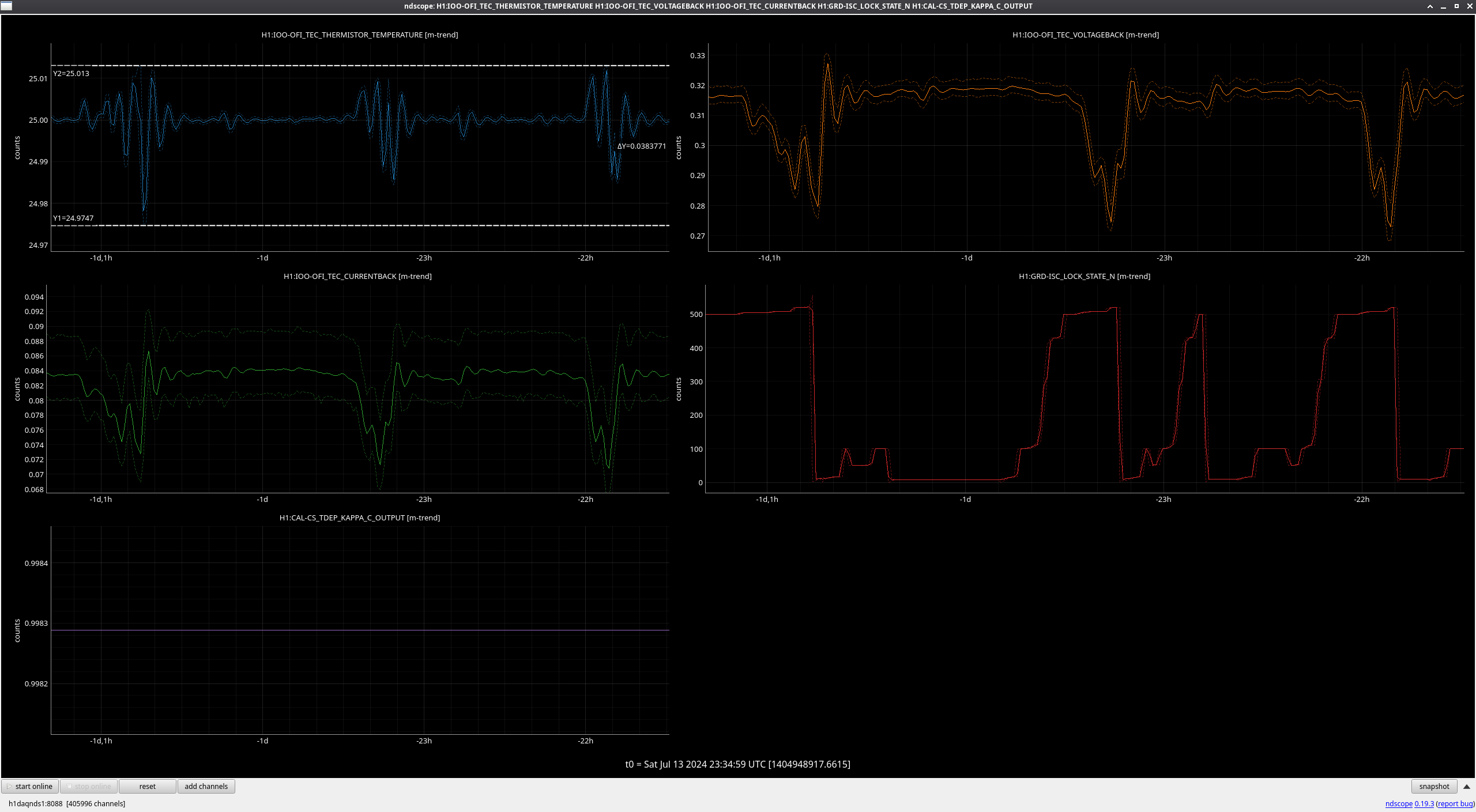
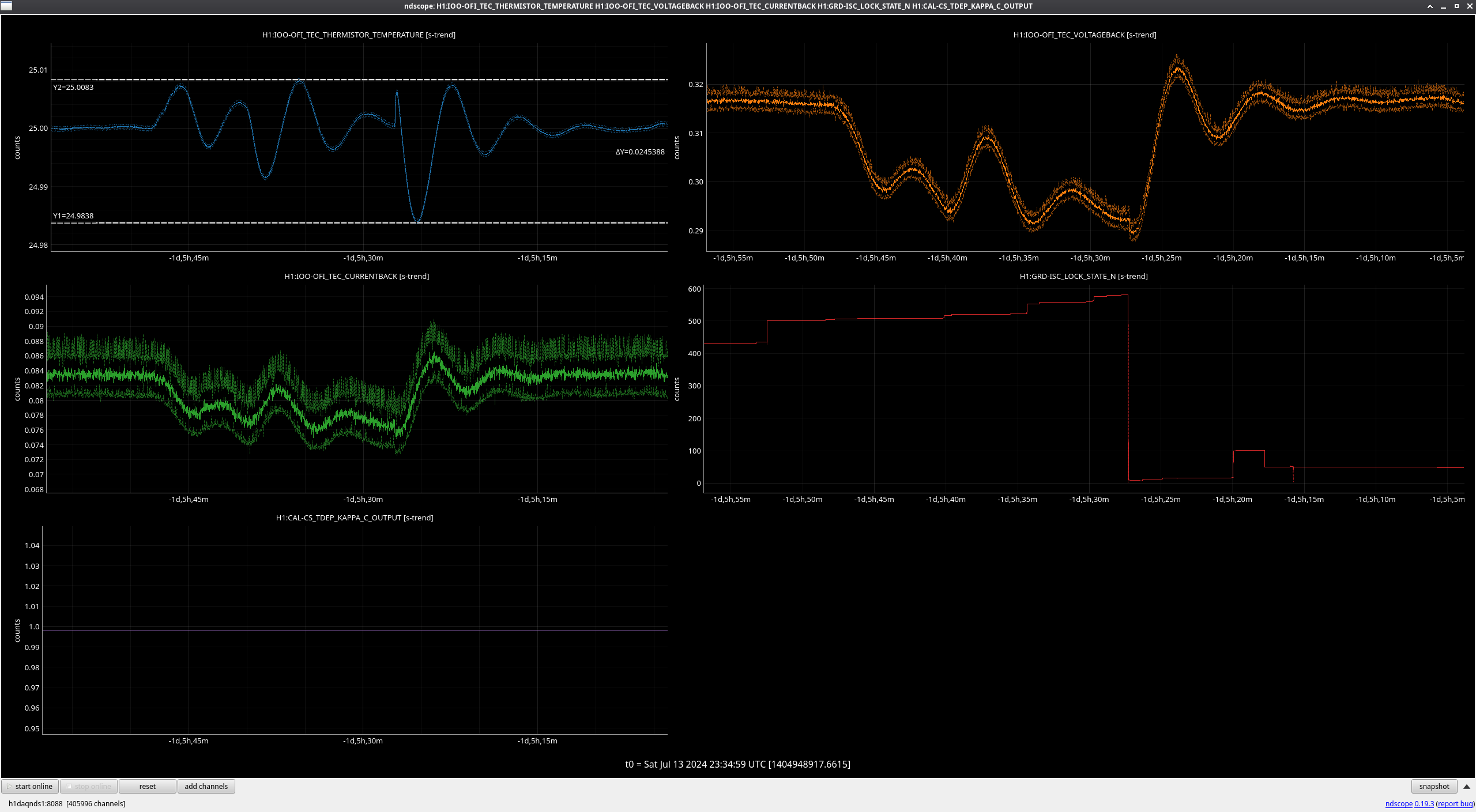
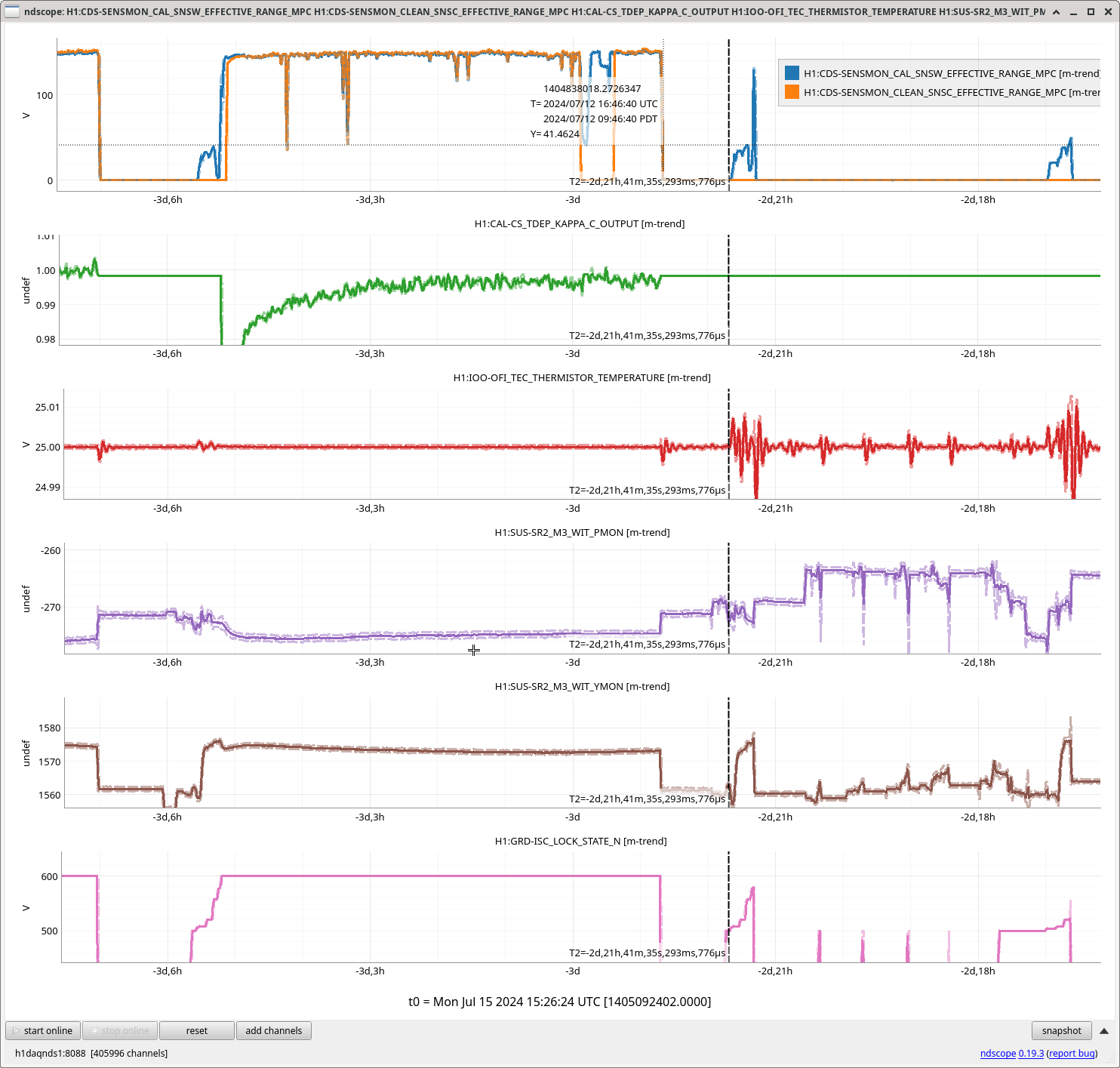
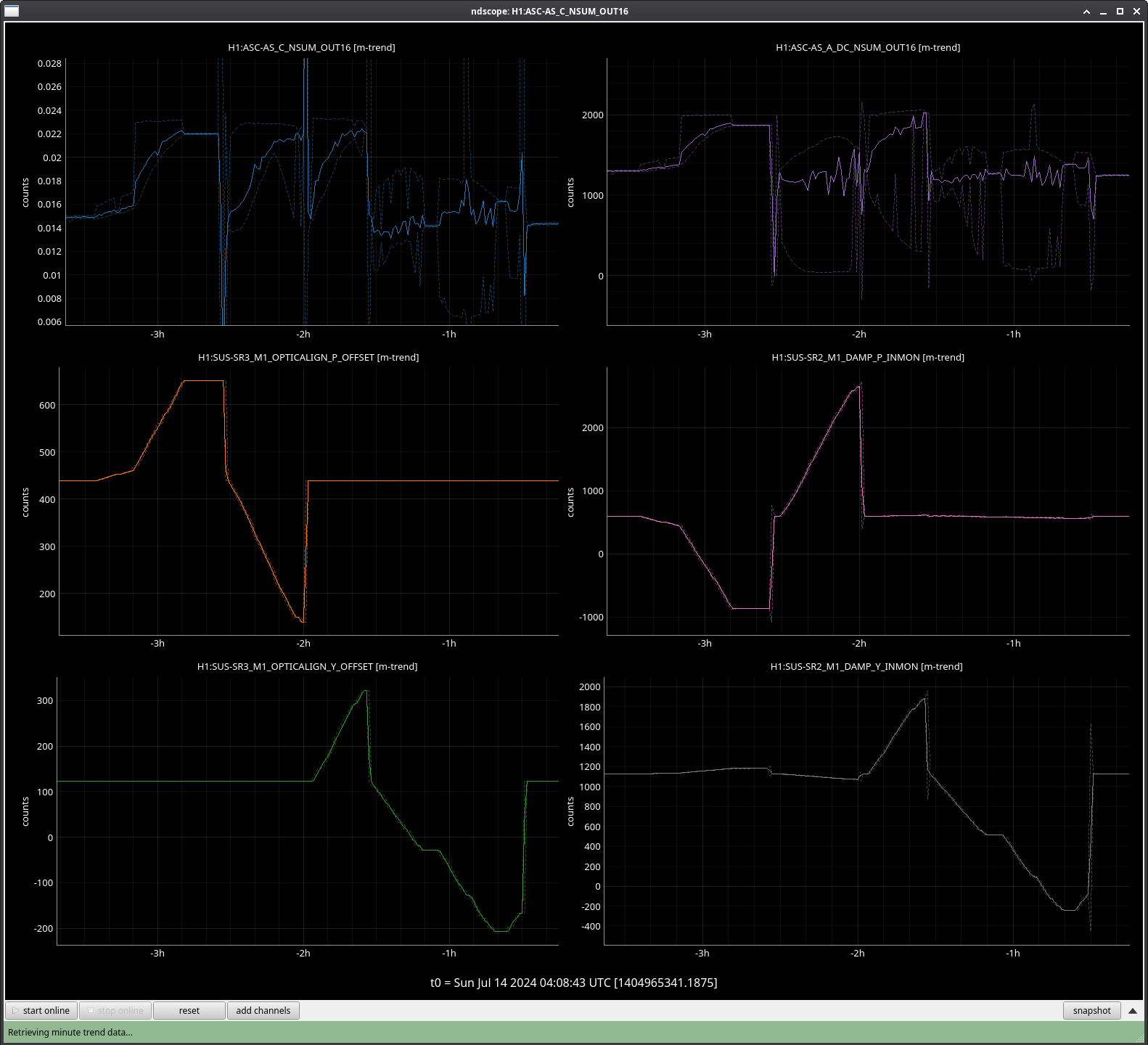
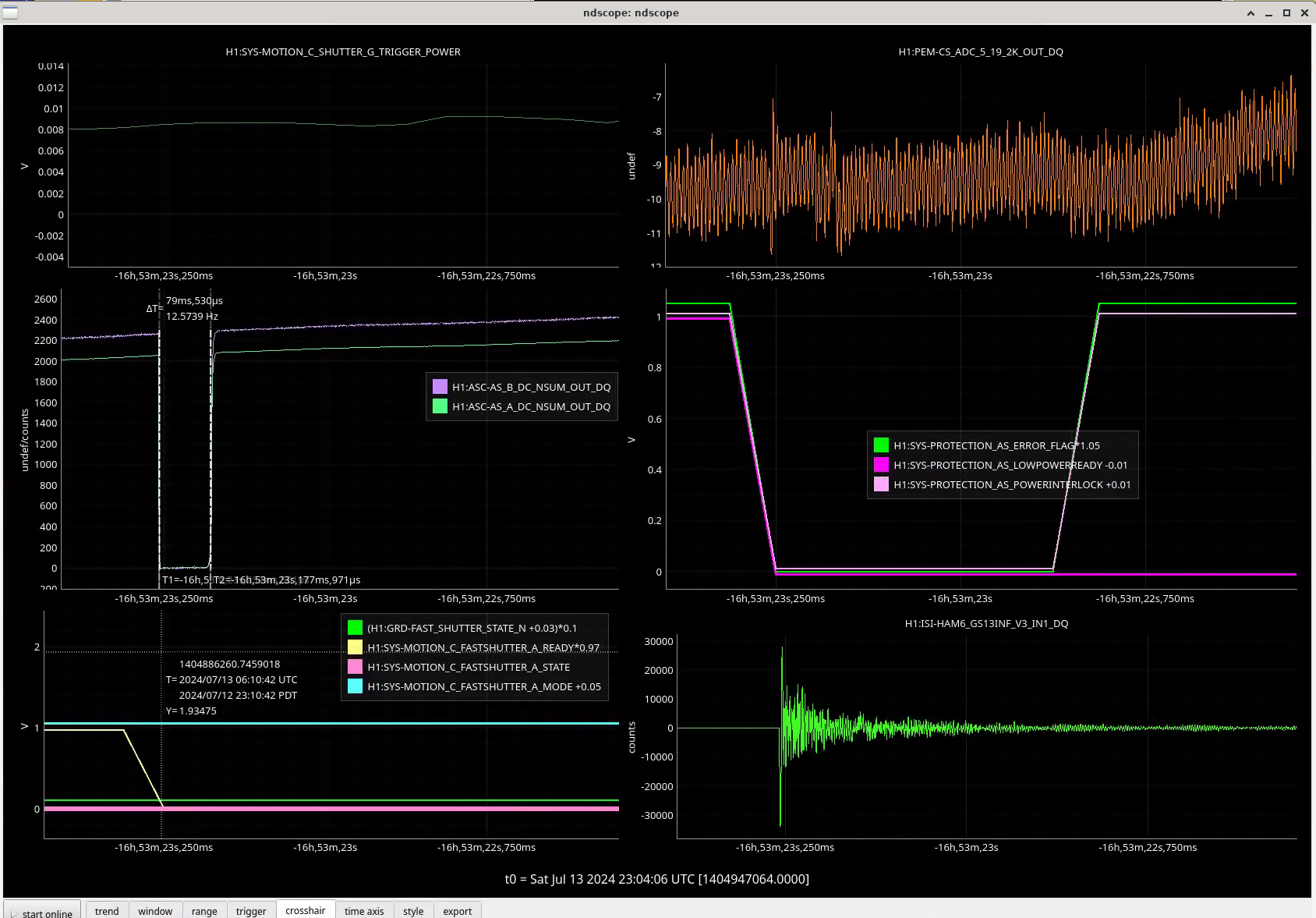
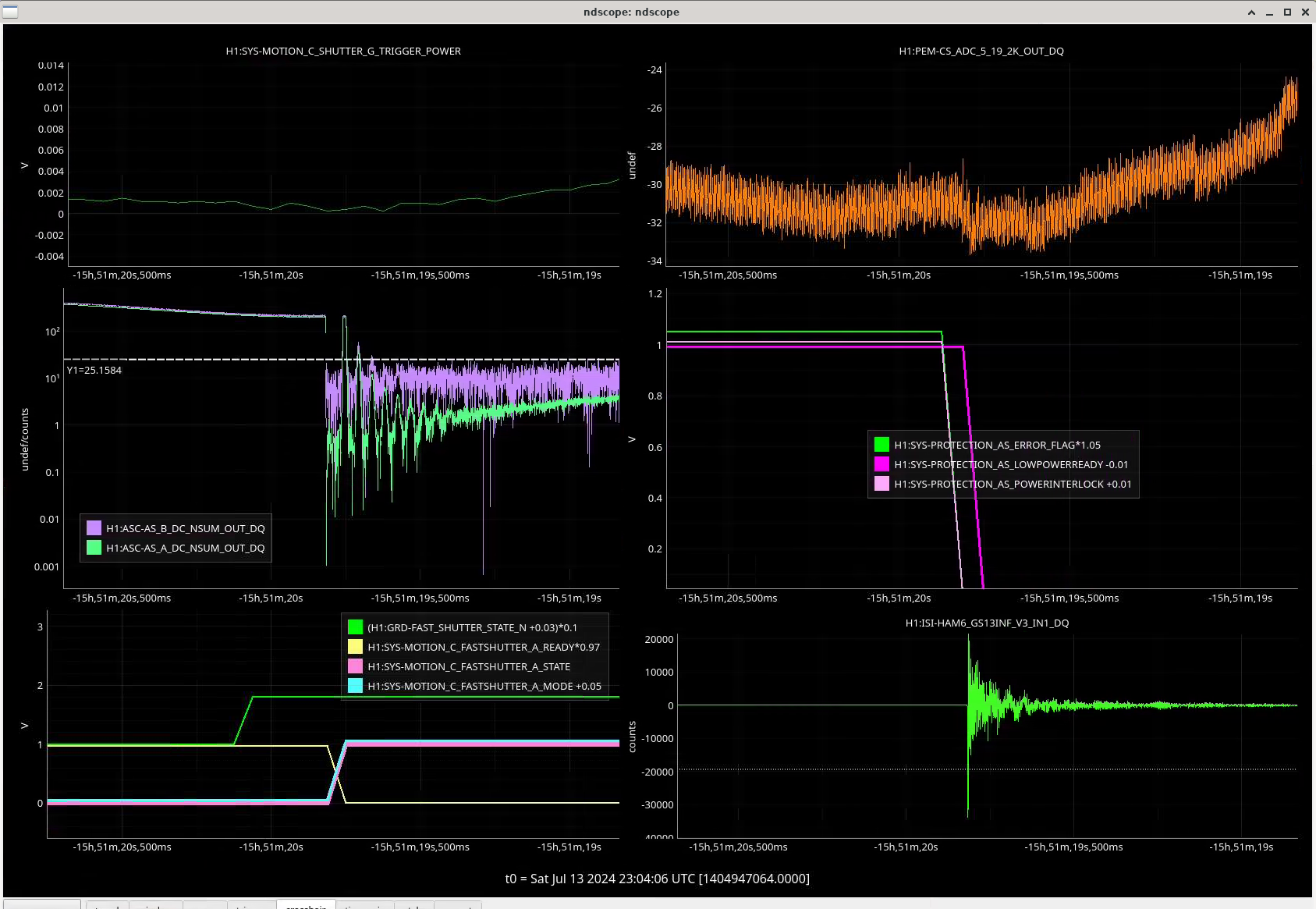
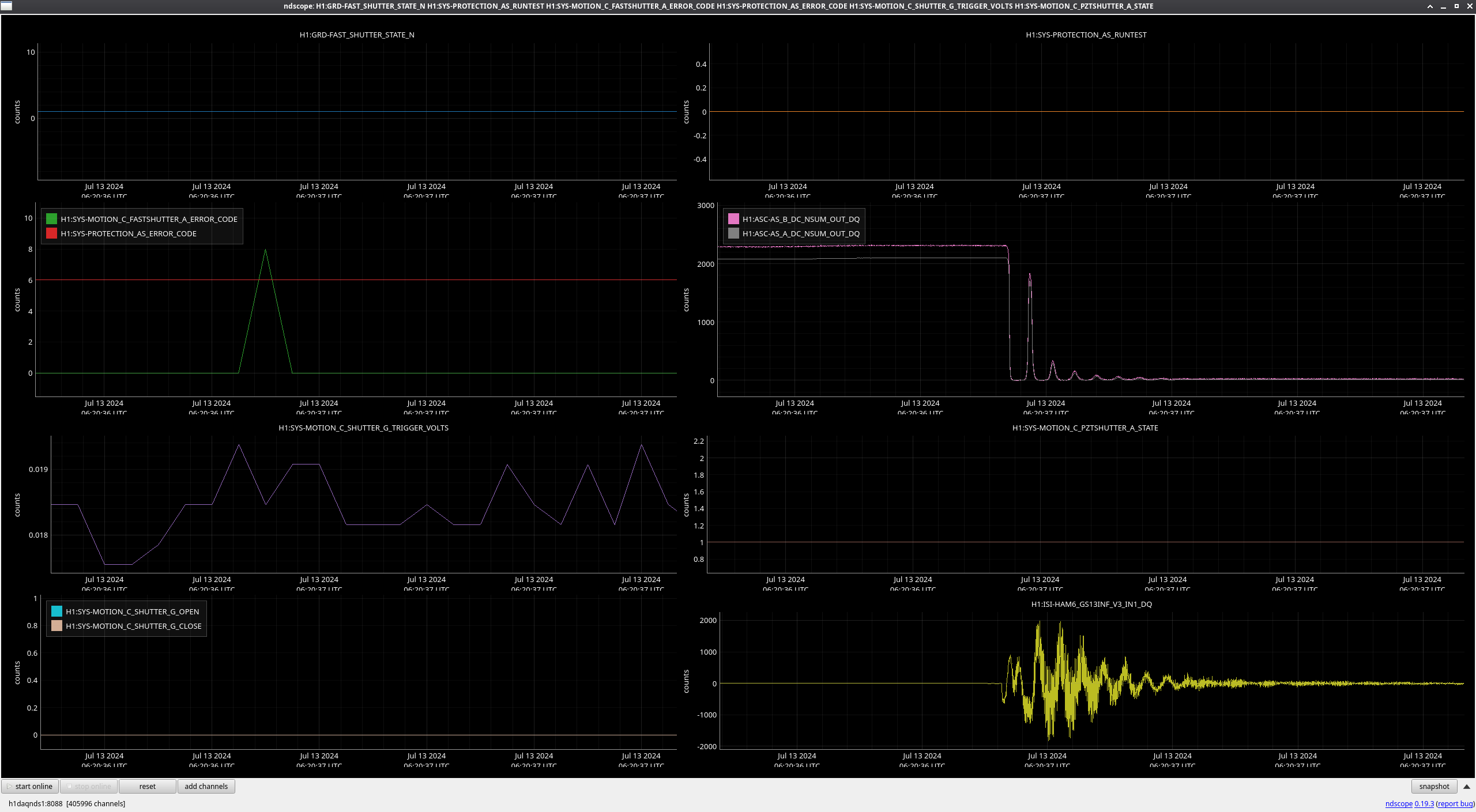
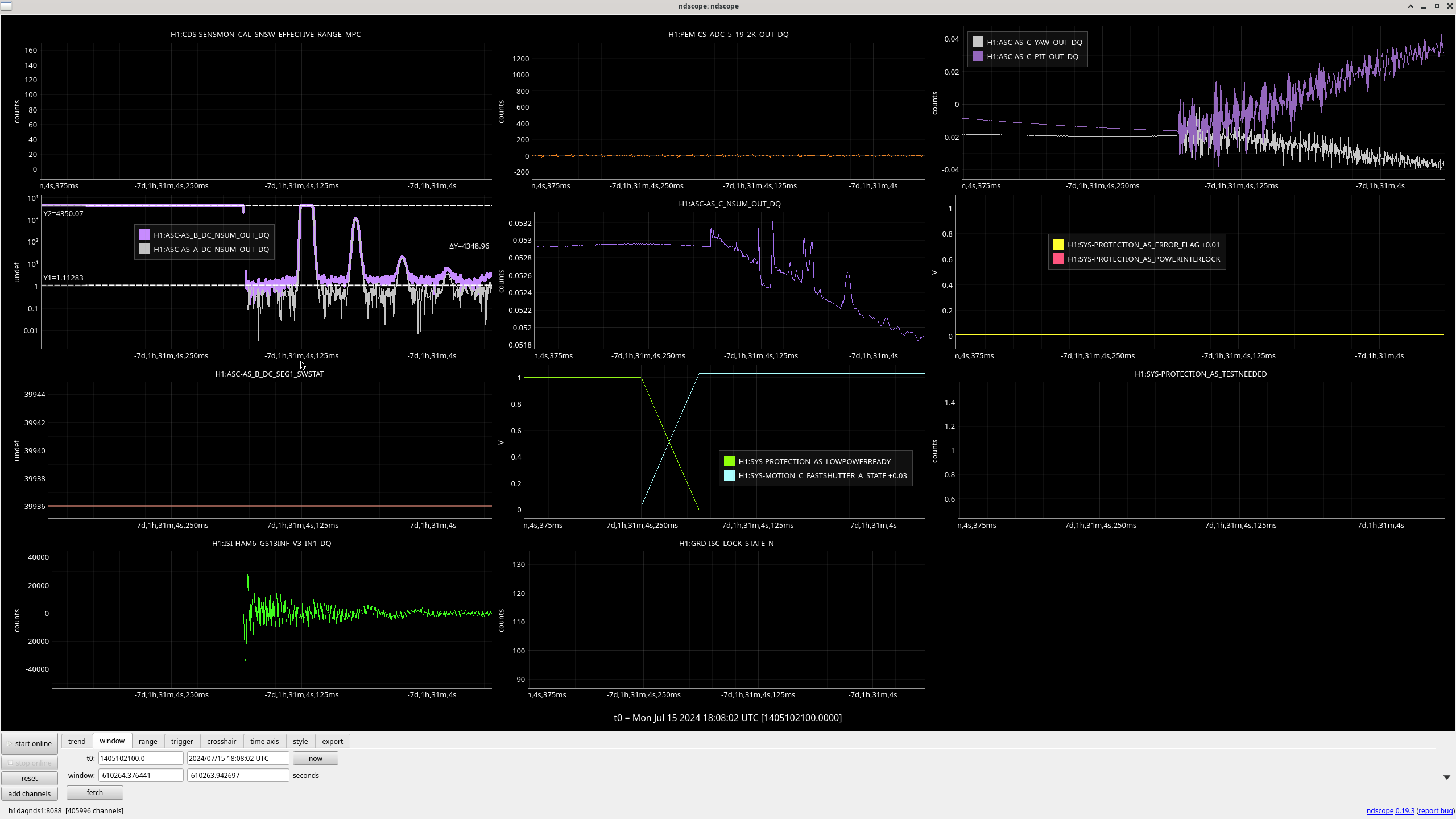
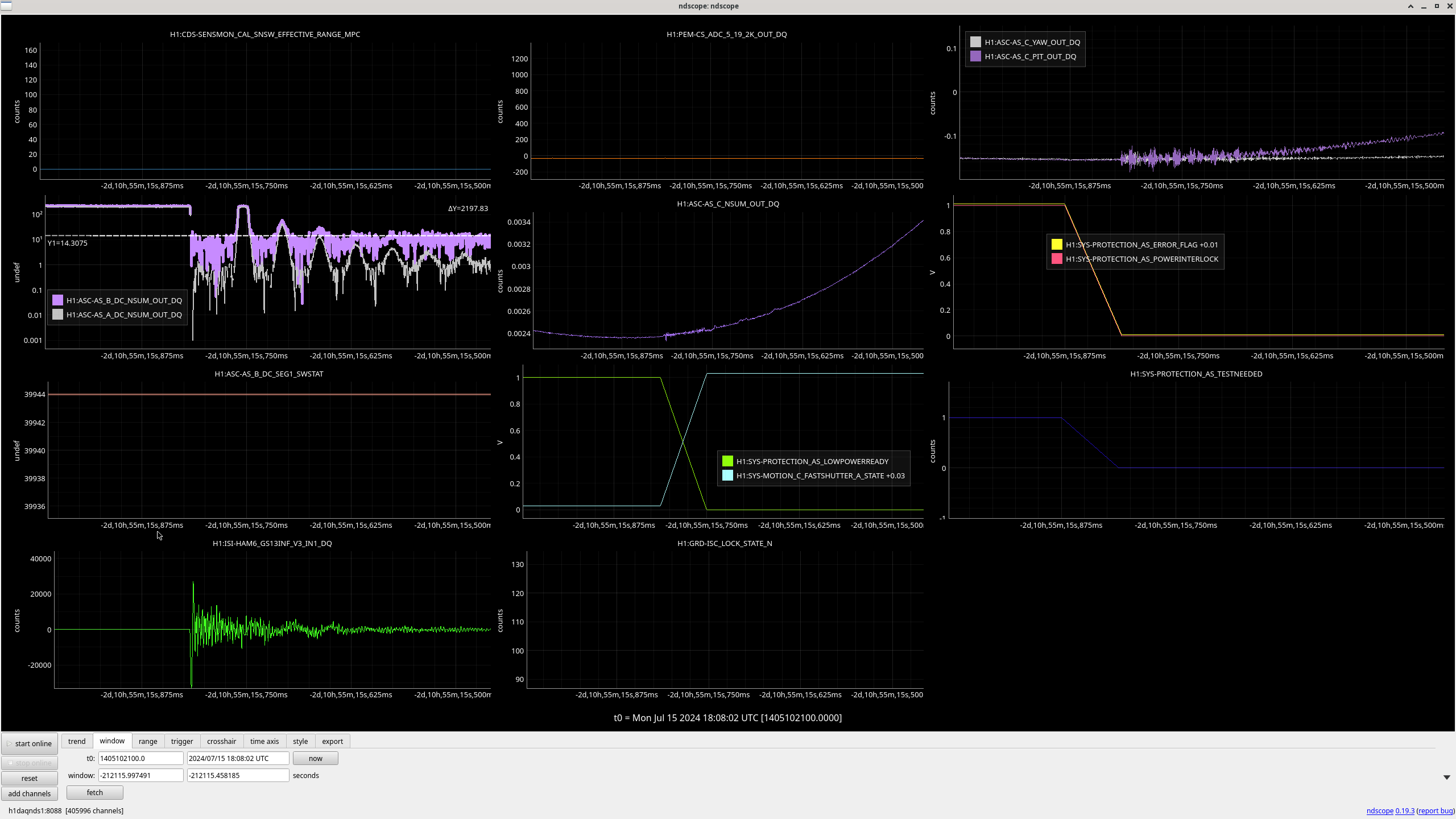
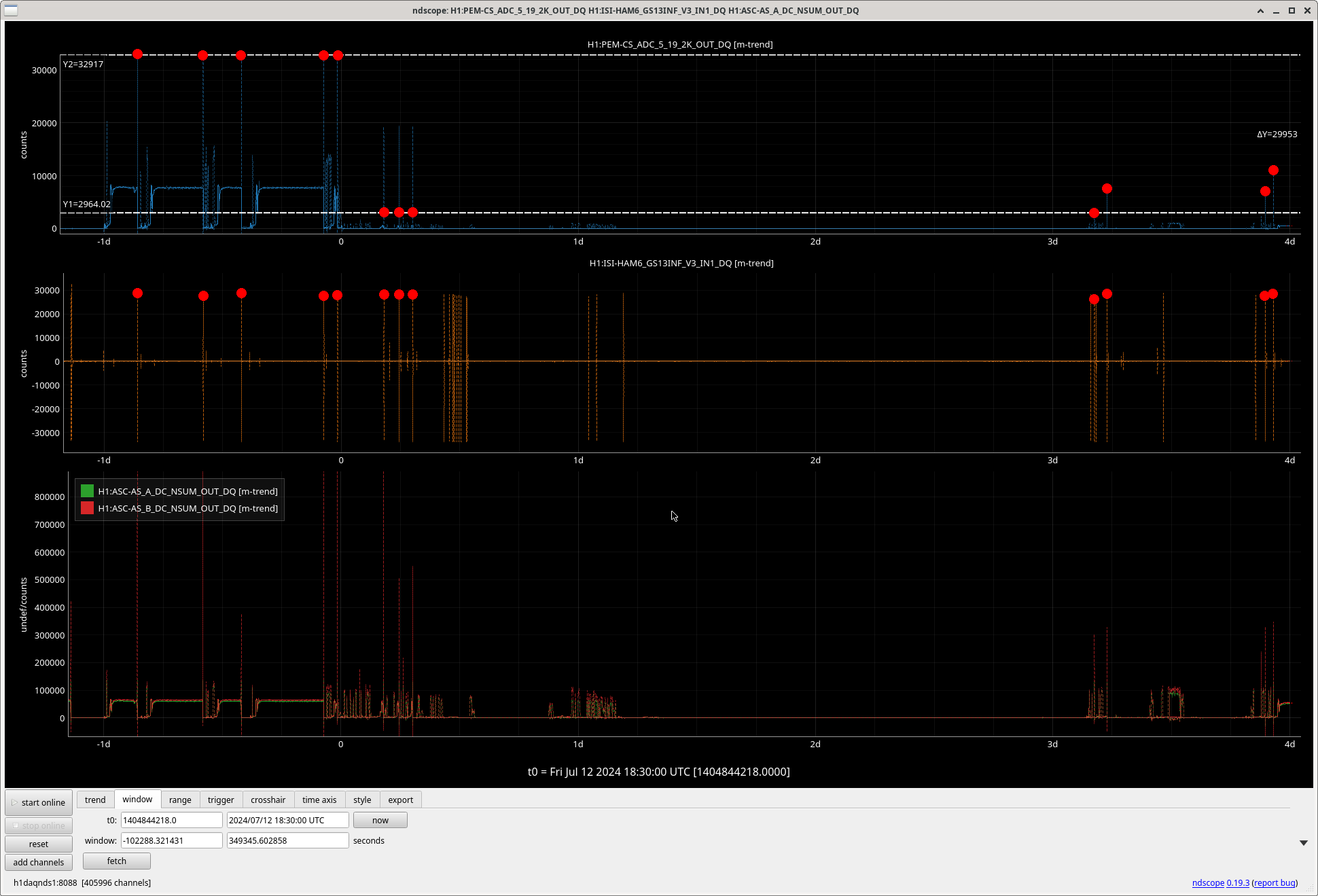
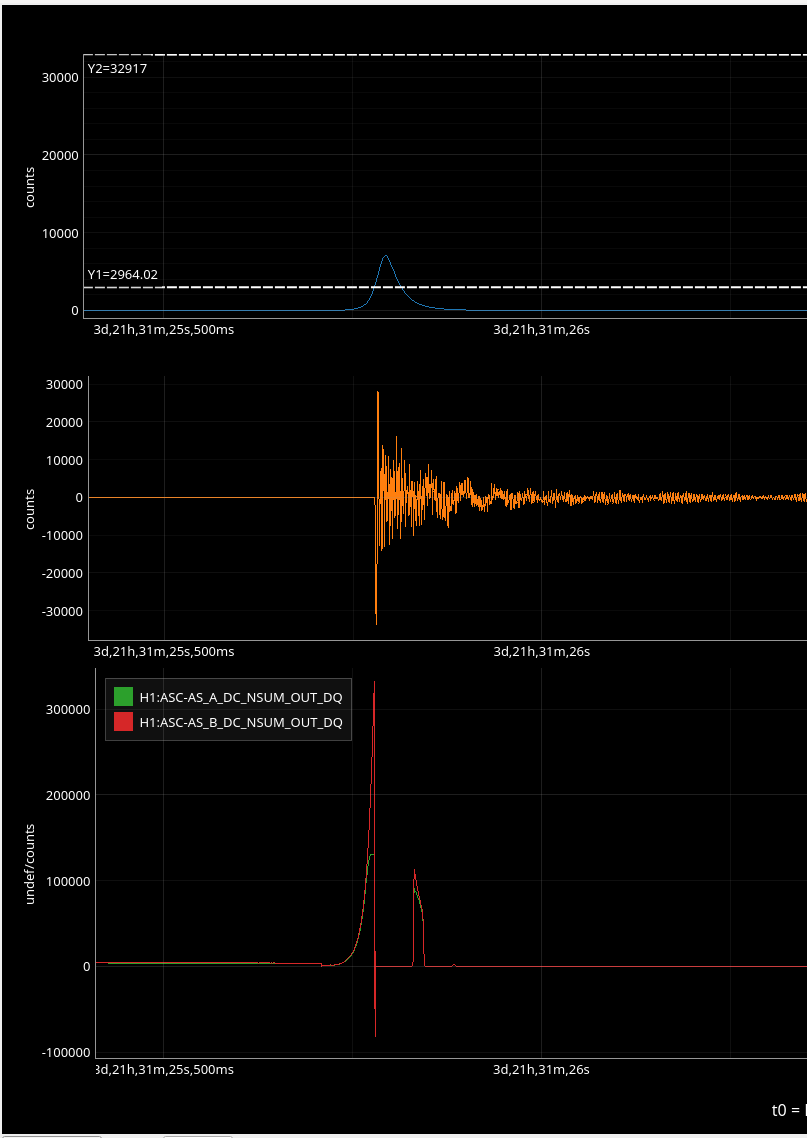
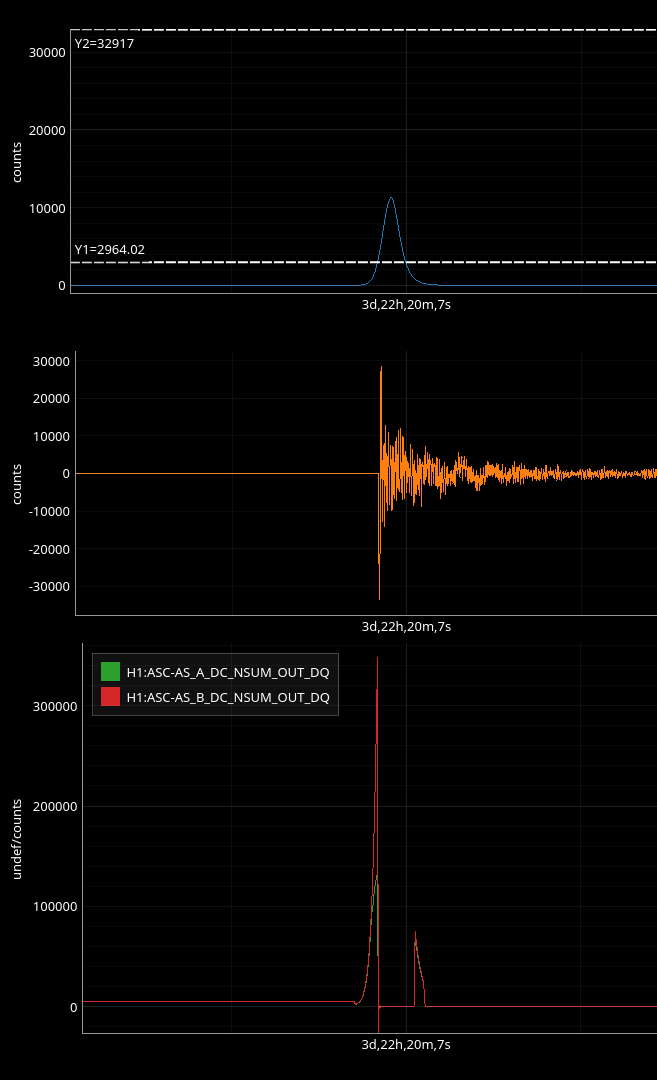
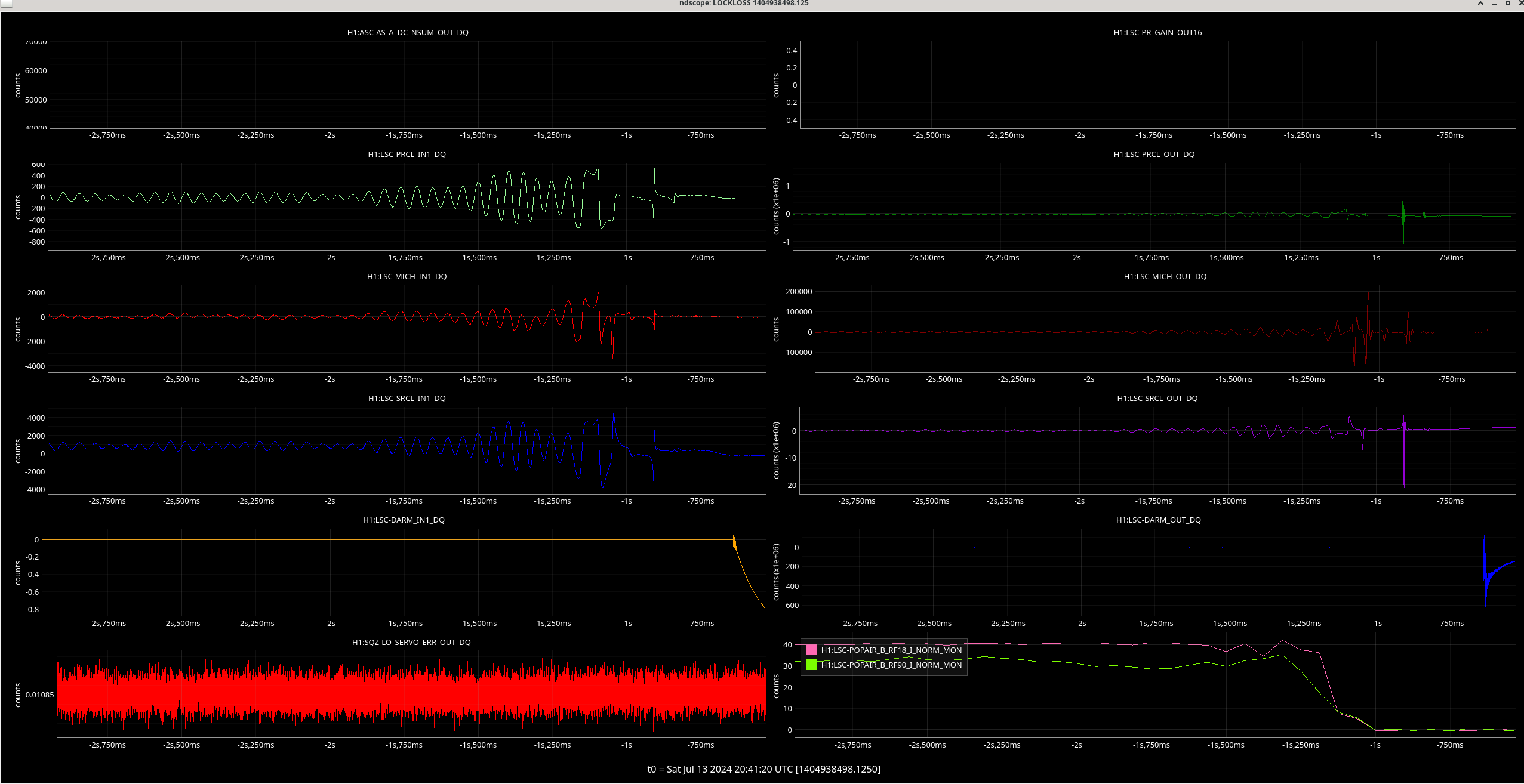
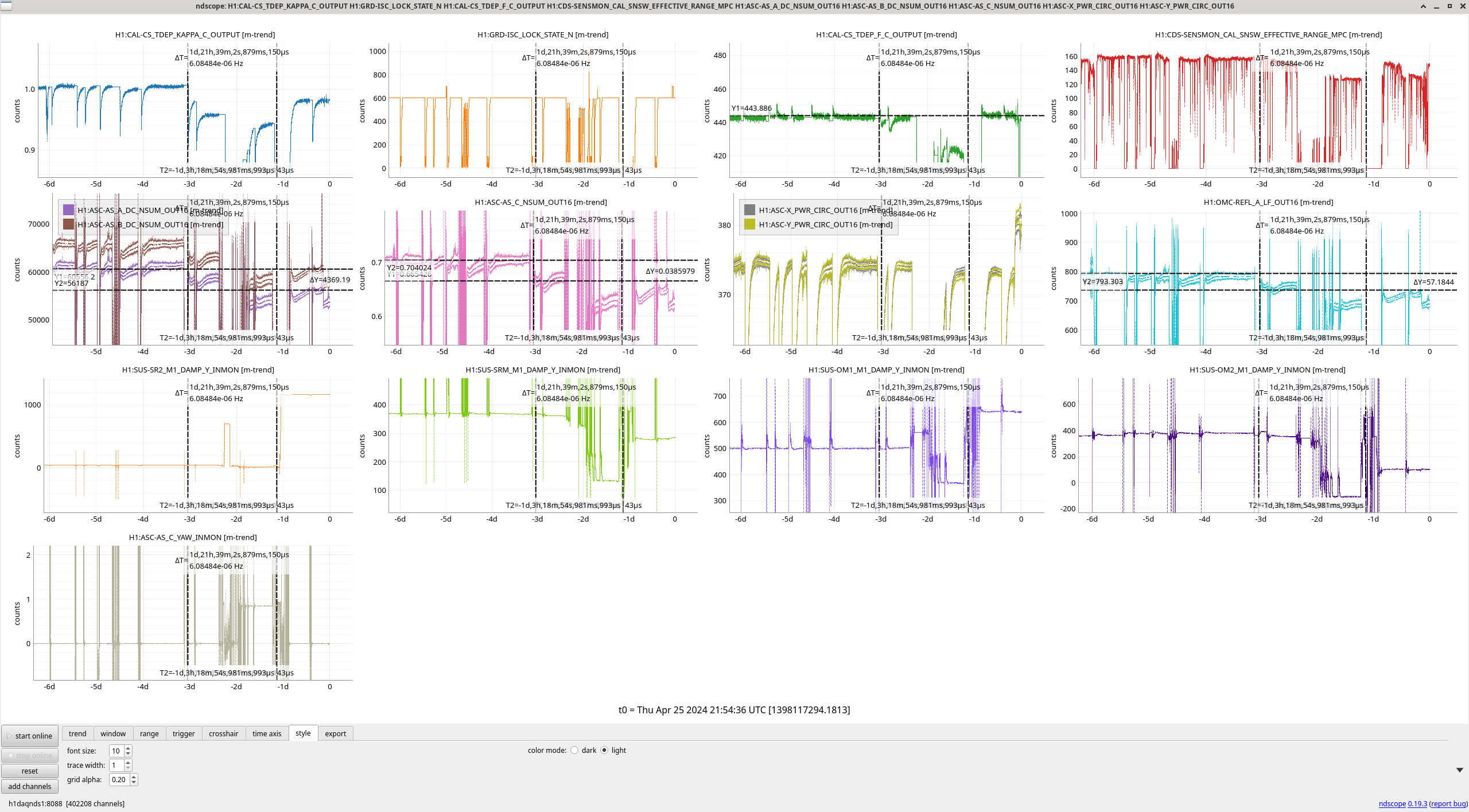
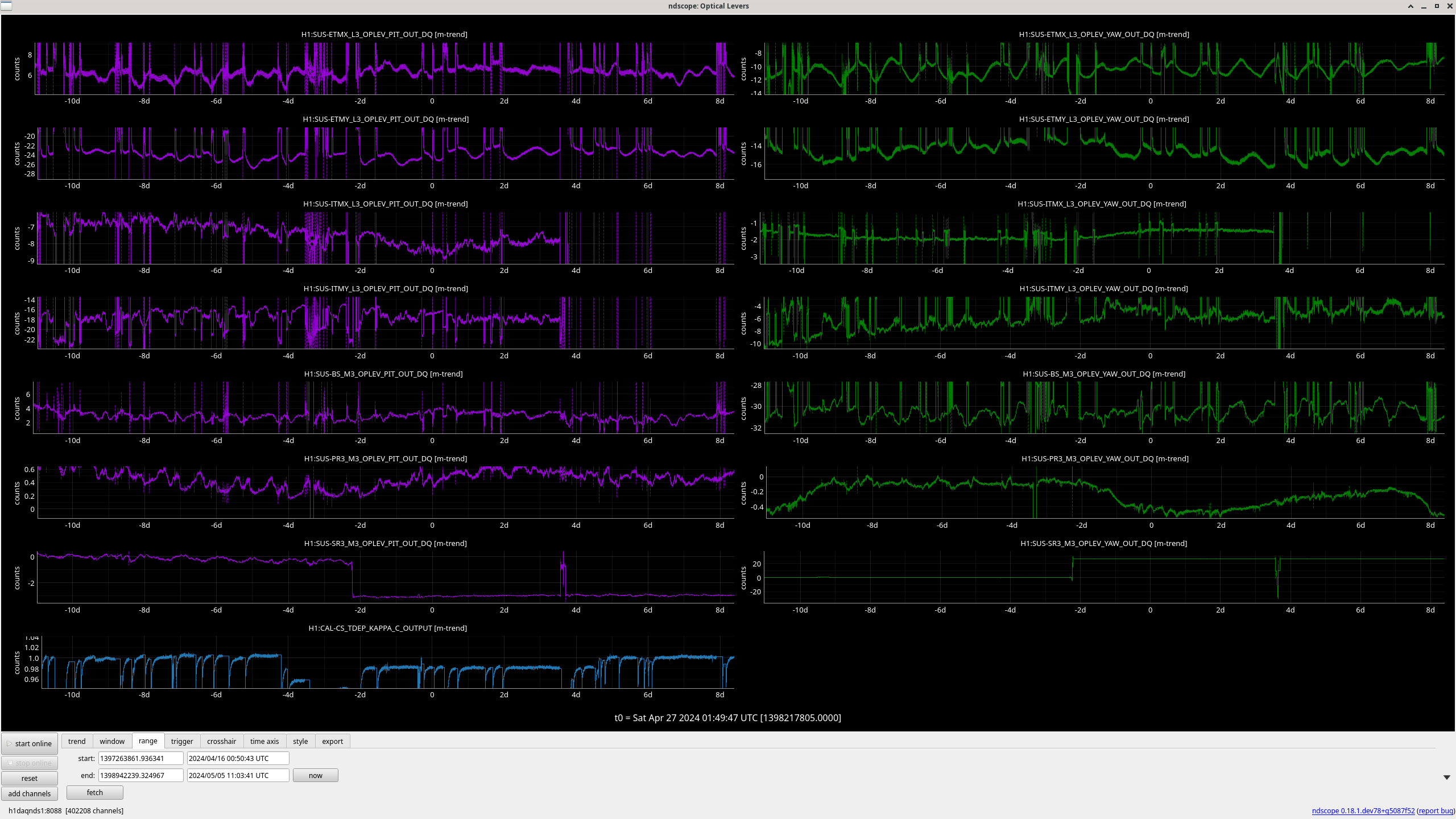
In the observing stretch that started Monday around 8 pm, there was a drop in optical gain (by 4%), and power at AS port PDs (4% drop in AS_A sum, AS_B sum, AS_C sum, and OMC REFL). There not at that time any change in circulating power in the arms, PRG, coupled cavity pole, or alignment of suspensions (shown are SR2, SRM, OM1+2, but we have also looked at many other suspension, ISI and HEPI related channels for this time 77382 ). This time is shown by the first vertical cursor in the attachment.
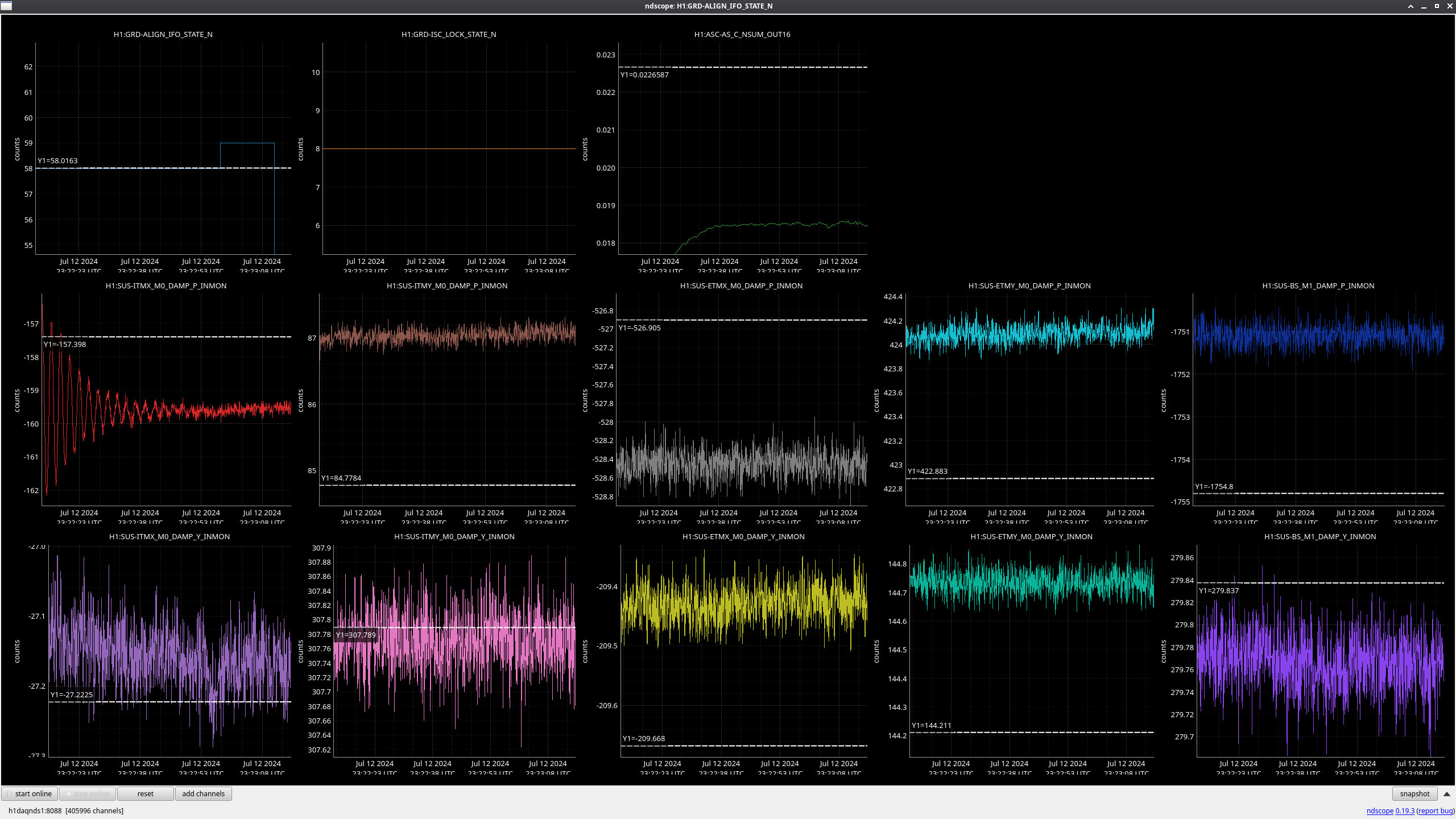
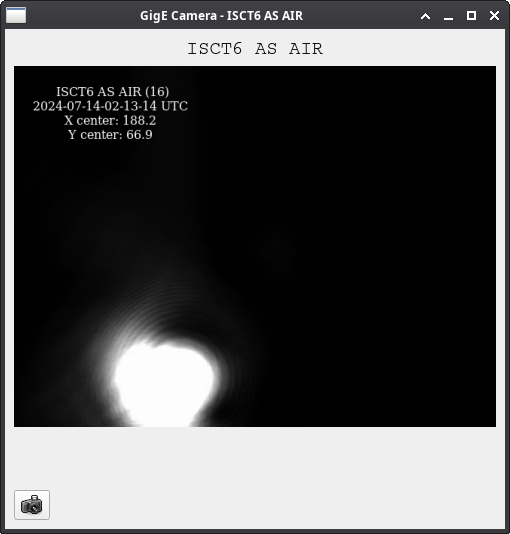
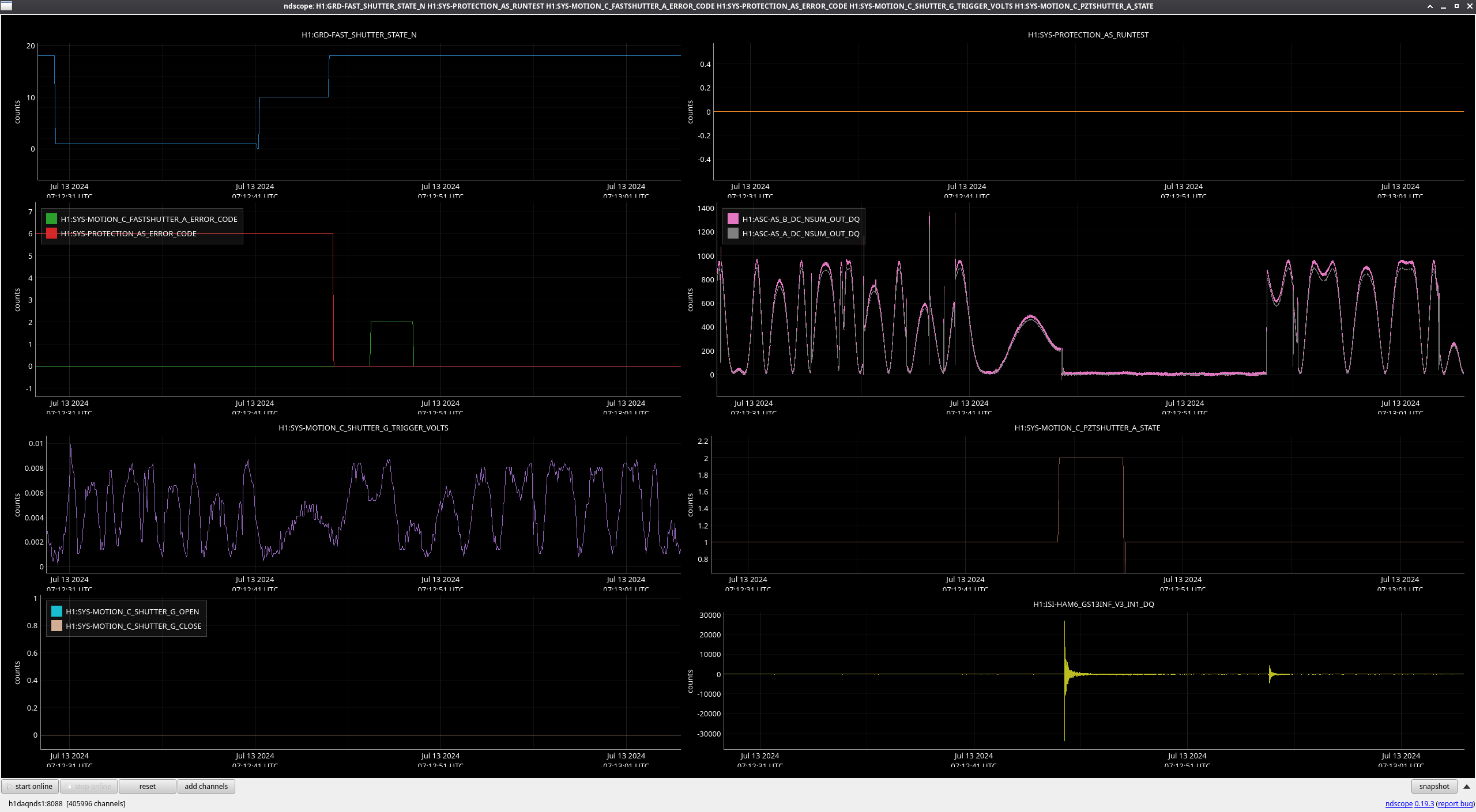
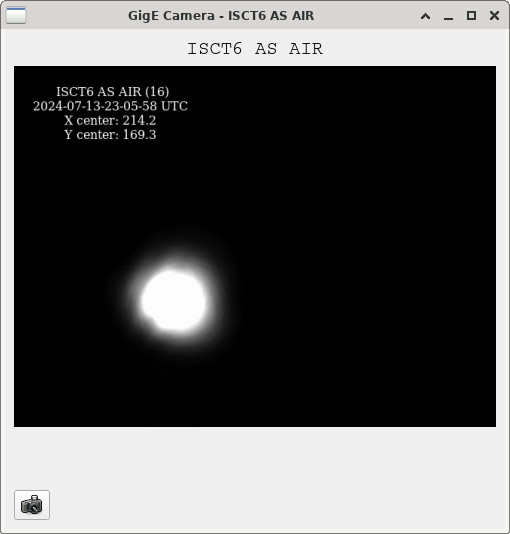
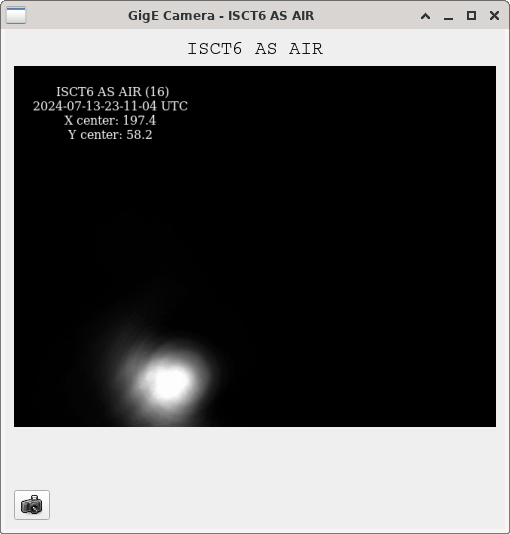
We were unable to relock the interferometer after that Monday evening lock (a new lockloss type appeared early Tuesday morning, 77359), and after the maintence window we were uable to lock with difficulties powering up (77363) and an AS camera imagine that had lobes whenever the beam was well centered on AS_C. We locked that evening by adding large offsets to AS_C's set point, (77368). This is the cause of the large alignment shifts seen in the screenshot on Tuesday evening to Wed morning, which allowed us to lock the IFO but created a large scatter shelf and resulted in a lower coupled cavity pole, and lower optical gain, and we did not have much squeezing that night.
We do not think that Tuesday maintence activities are the cause of our problems, although some of the Tuesday work has been reverted (77350 77369).
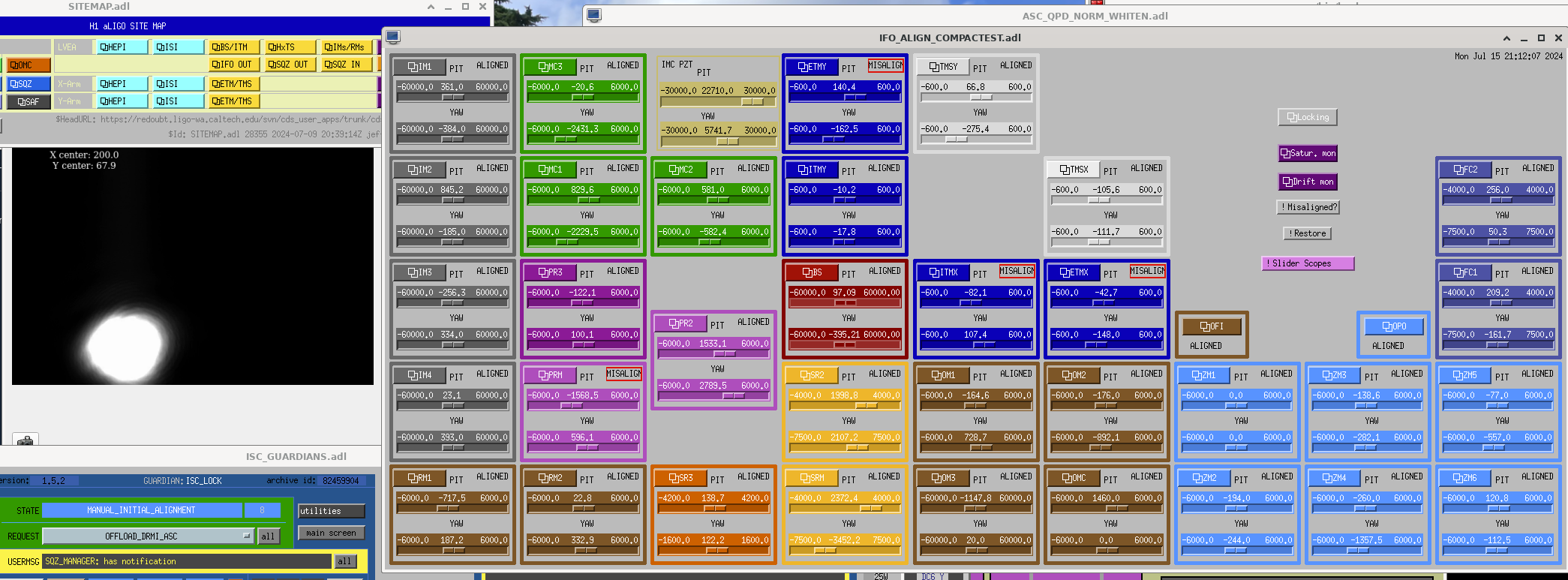
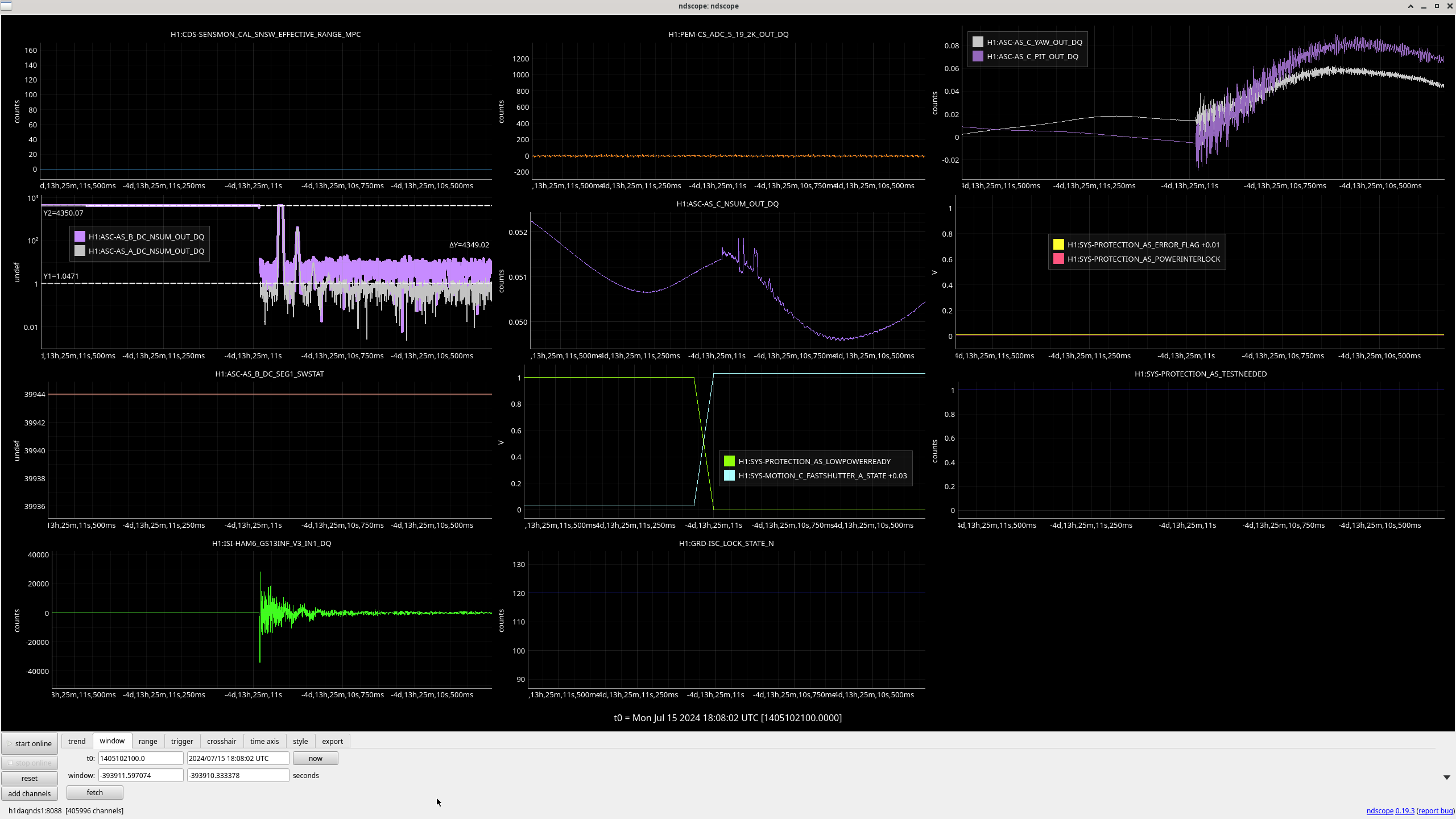
Yesterday we spent much of the day with SRY locked, single bounce or using the squeezer beam reflected off SRM to investigate our AS port alignment. 77392, We are able to recover the same throughput of a single bounce beam to HAM6 by moving the alignment of SR2 + SR3 by a huge amount 77388, which also produced a round looking beam on the AS camera. We haven't since tried to explore this aperture, to see if we could have also recovered this thoughput with a pitch move, for example. We also saw that the squeezer beam does not arrive in HAM6 with a good transmission when injected with the alignment used previously, but that we could recover good transmission to HAM6 by moving ZM5 by 150-200 urad, in pitch or yaw. With this shift in SRC axis, and squeezer alignment we were able to relock and not have the large scattering issues we had Tuesday night.
Today's time was spent recovering from a seemingly unrelated problem in the SQZ racks, and some commissoning aimed at recovering our previous (165Mpc) sensitivity with this new alignment. This will continue during tomorow's commissoning time.
additional related information:
- (no SQZ, HWS, OFI voltmons) 77374
- Move of SQZ beam in lock to get squeezing: 77400
- OFI transfer functions: 77391
- other suspension health checks: 77383
- dark offset script: 77362
- SRM and SR2 beam positions after the shift: 77443
- Further look at powers on HAM6 PDs: 77441
- AS port fringe wrapping worse than Summer 2023: 77452