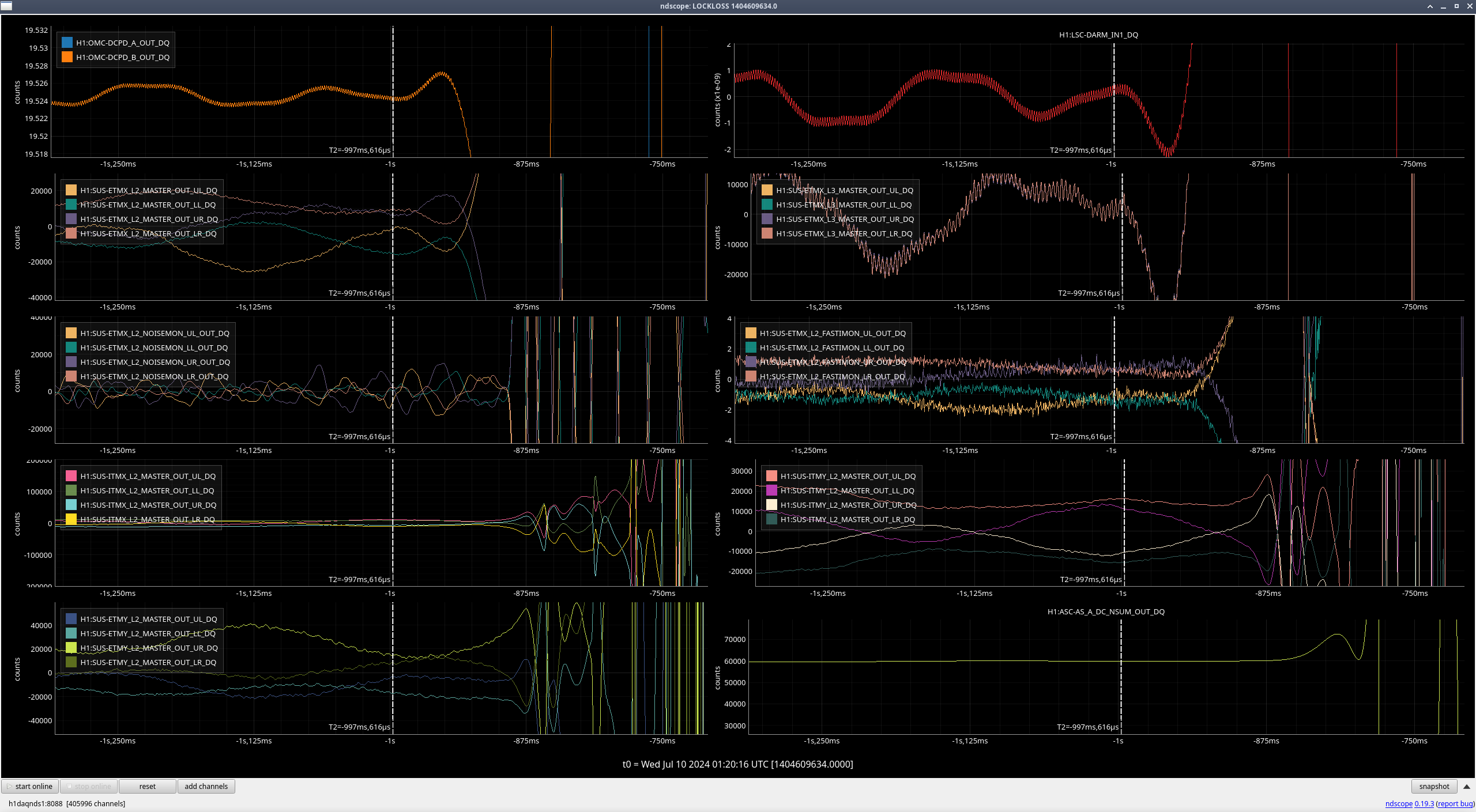
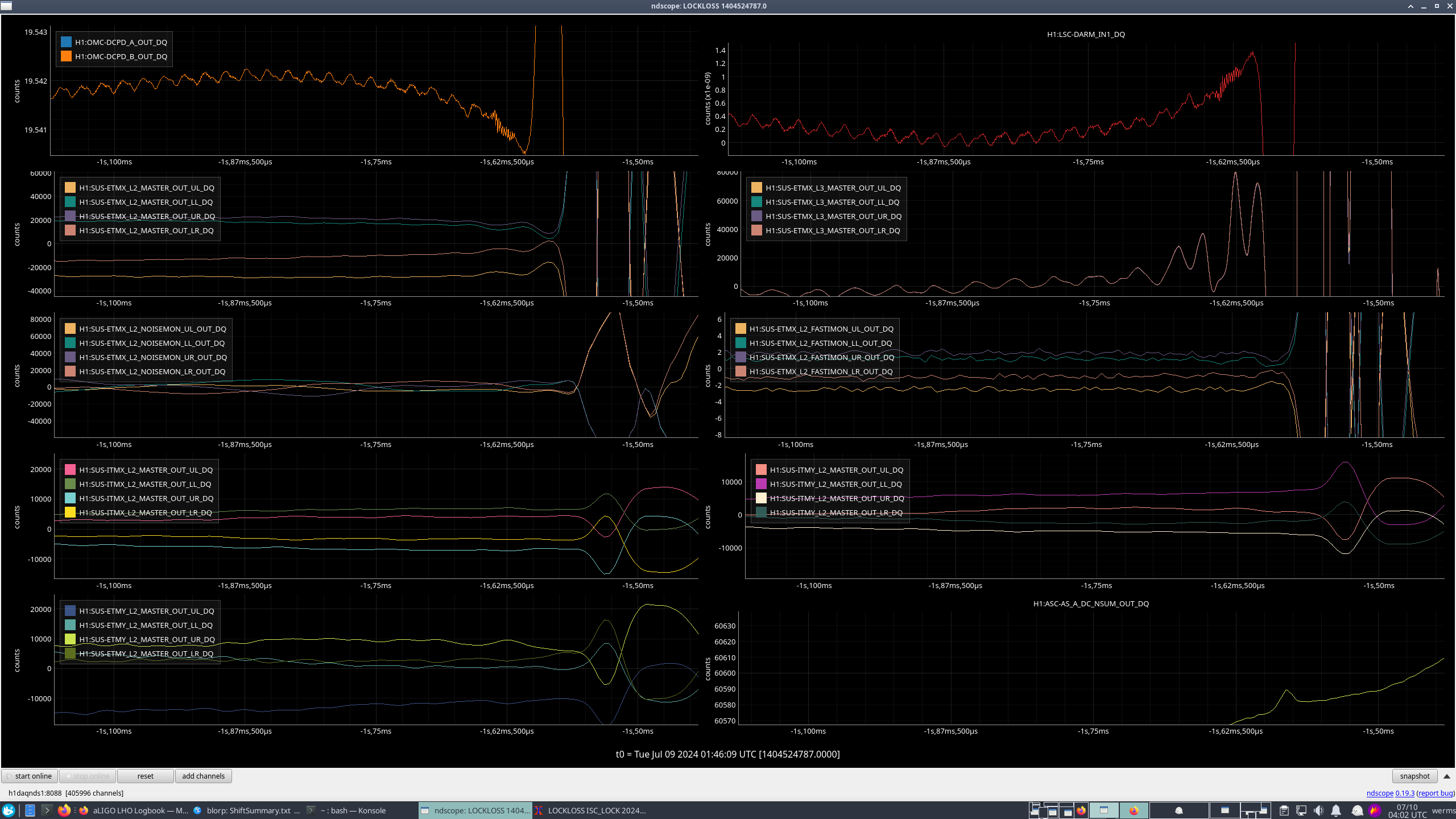
oli.patane@LIGO.ORG - posted 20:41, Tuesday 09 July 2024 - last comment - 22:07, Tuesday 09 July 2024(78988)
Lockloss
Currently not sure of cause, but the lockloss was a lot smoother/less sudden than most other locklosses, which I thought was interesting. I think EX L3 sees it first (the little jolt right after the cursor and before it dips down), but there aren't any saturations or glitches that happen before the lockloss like we tend to see in a lot of other locklosses.
03:00 Observing
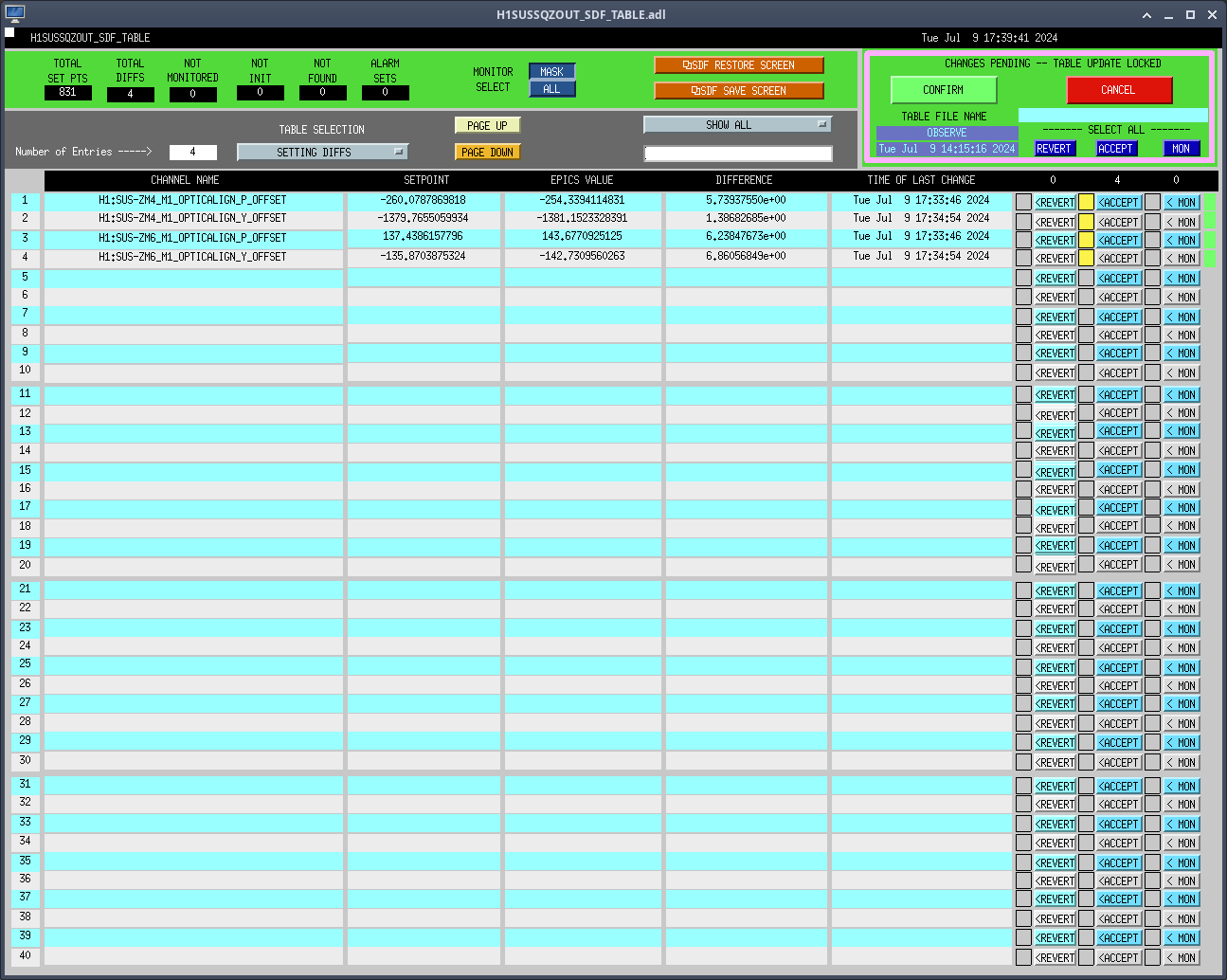
07/10 00:29 UTC I took us out of Observing to tune the squeezer since we have now been locked for over three hours.
00:39UTC New opticalign offsets accepted in sdf, back to Observing
TITLE: 07/09 Day Shift: 1430-2330 UTC (0730-1630 PST), all times posted in UTC
STATE of H1: Observing at 146Mpc
INCOMING OPERATOR: Oli
SHIFT SUMMARY: Relock after maintenance day was fairly straight forward, aside from needing to run the baffle align scripts to get light in the xarm. This was maybe expected since EX tripped during DAC card work. Once the IFO was up, there was some excess noise ~25-60Hz, but things are now starting to improve in that area. Our range is still lower than usual, but it's still increasing.
Lock acquisition notes:
LOG:
| Start Time | System | Name | Location | Lazer_Haz | Task | Time End |
|---|---|---|---|---|---|---|
| 16:08 | SAF | LVEA | LVEA | YES | LVEA IS LASER HAZARD | 15:47 |
| 14:56 | FAC | Tyler | VPW | n | Forklifting package to VPW | 15:16 |
| 15:09 | FAC | Kim | EX | n | Tech clean | 16:24 |
| 15:09 | FAC | Karen, Nelly | EY | n | Tech clean | 16:10 |
| 15:23 | CDS | Fil | EY | n | Unplug picomotors | 16:19 |
| 15:29 | SAF | Ryan C | LVEA | yes | Transition LVEA to laser safe | 15:48 |
| 15:30 | PCAL | Francisco | EX | YES | PCAL meas. | 16:46 |
| 15:36 | ISC | Jennifers | CR | n | IMC alignment | 17:22 |
| 15:42 | VAC | Travis | MX, EX | - | Turbo tests | 18:36 |
| 15:52 | PSL | Jason, Ryan S | LVEA - PSL | local | PSL alignment from PMC | 18:59 |
| 15:55 | CC | Ryan C | Ends | - | Dust monitor checks | 16:58 |
| 16:11 | FAC | Karen, Nelly, Kim | FCES | n | Tech clean | 16:46 |
| 16:17 | FAC | Tyler | LVEA, mids | n | FAMIS checks | 16:52 |
| 16:19 | FAC | Chris | EY, EX | n | Hepa filter swaps in fan room | 18:49 |
| 16:22 | ISC | Keita | LVEA | n | Look at HAM6 racks | 16:37 |
| 16:24 | SEI | Jim | FCES | n | SEI GS13 investigation | 17:49 |
| 16:55 | CDS | Fil | EX | n | Unplug picomotors | 17:54 |
| 16:58 | PCAL | Francisco | PCAL lab | local | PCAL meas wrapup | 18:34 |
| 16:59 | CC | Ryan C | LVEA, FCES | n | Dust monitor tests | 17:36 |
| 17:08 | FAC | Karen, Kim, Nelly | LVEA | n | Tech clean | 18:27 |
| 17:11 | - | Rick, SURFs | LVEA | n | Tour the SURF students | 18:49 |
| 18:16 | SEI | Jim | LVEA | n | Setup L4Cs under HAM3 | 18:24 |
| 18:30 | CDS | Marc, Erik | EX | n | Swap card for sus ex | 19:08 |
| 18:59 | - | Ryan C | LVEA | n | Sweep | 19:13 |
| 20:57 | CC | Ryan C | LVEA | n | Turn off DM5 | 20:57 |
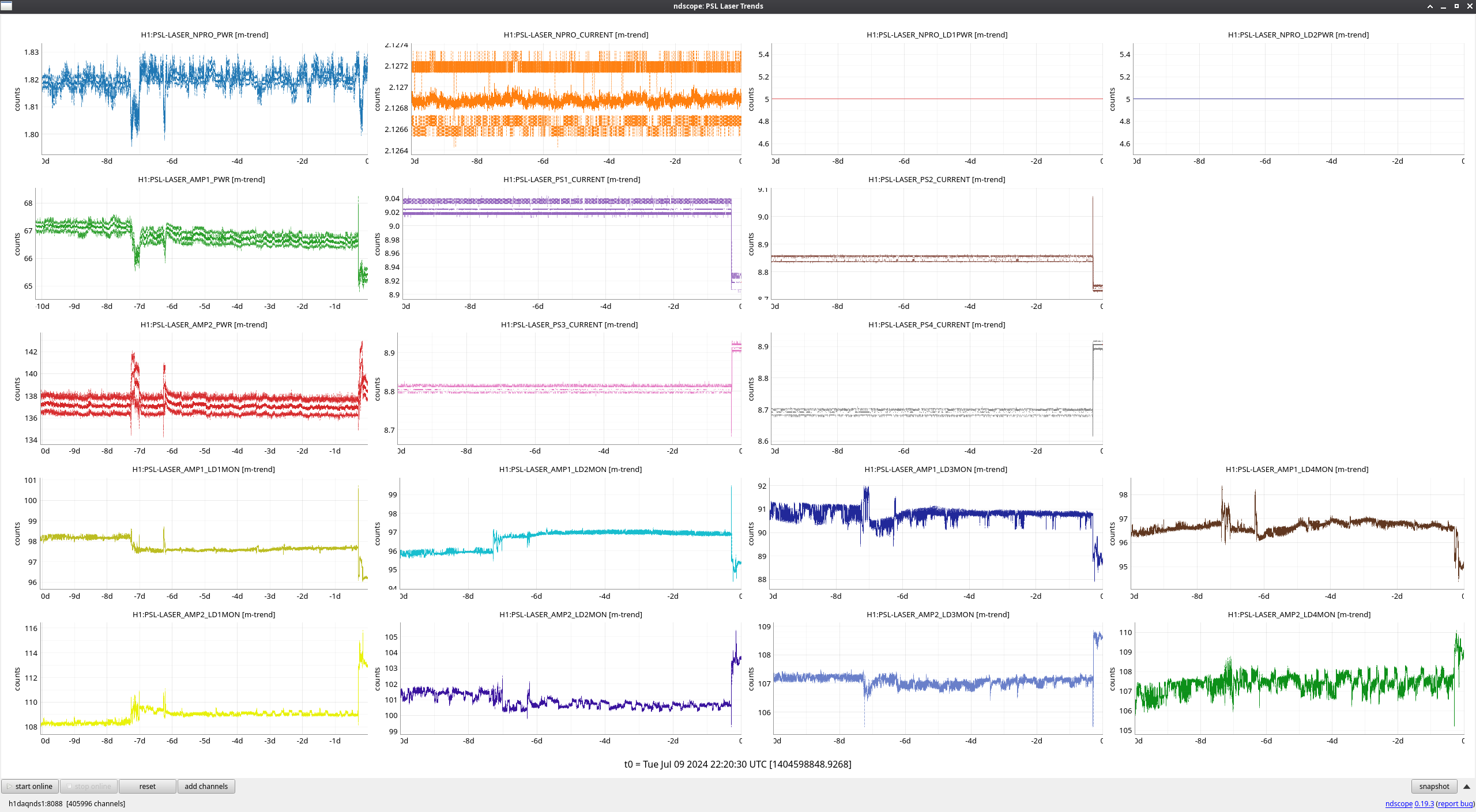
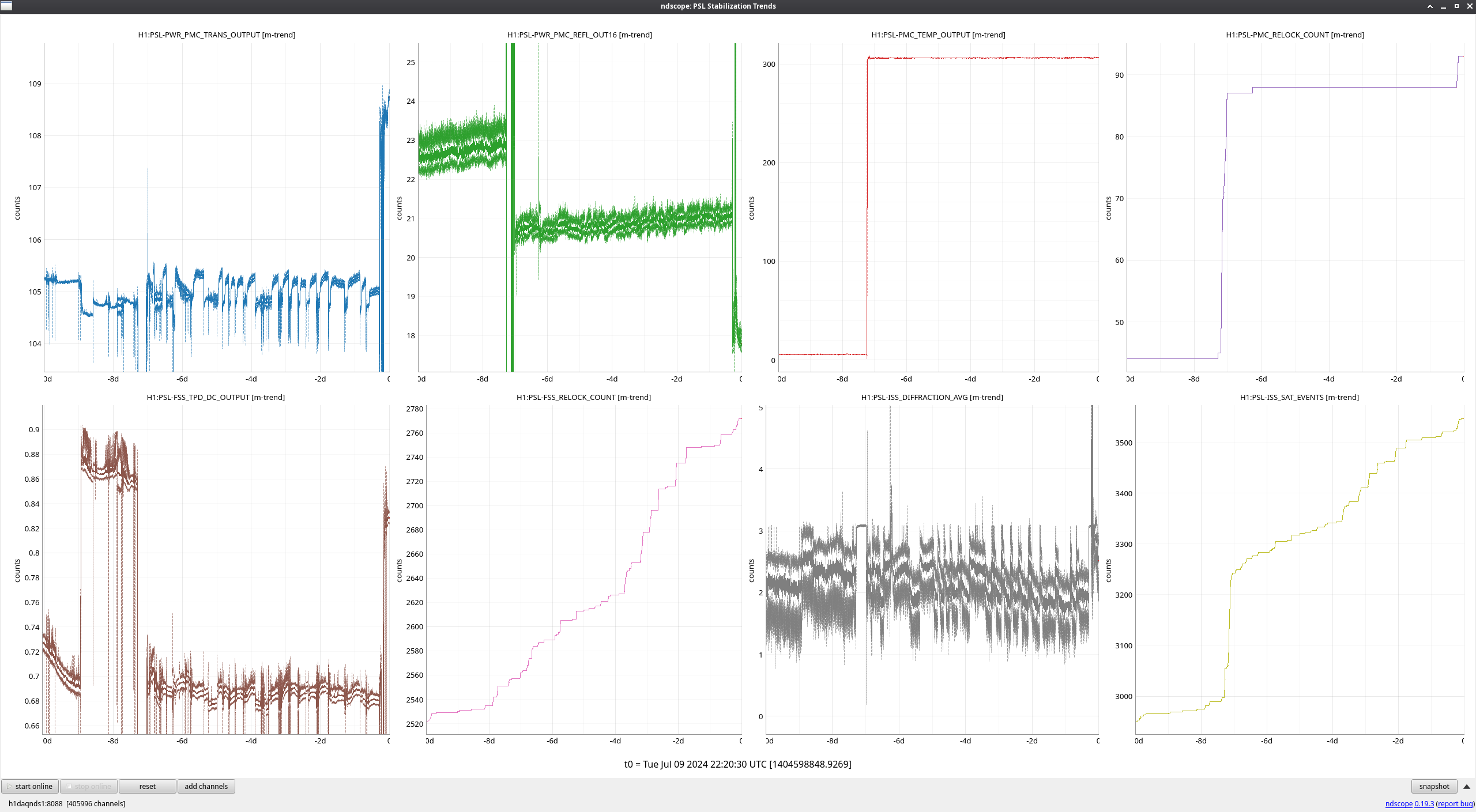
FAMIS 21007
Work done in the enclosure today and last week (including PMC swap and adjustments needed as a result) all show up clearly on this week's trends.
I still see a very slight increase in PMC REFL since last week's PMC swap, which we also saw with the old PMC and informed us about its increasing cavity loss, but now that we've made things a bit more stable, we'll keep an eye on it. PMC REFL was able to get at least a few watts lower than before the PMC swap, so that's promising.
TITLE: 07/09 Eve Shift: 2300-0800 UTC (1600-0100 PST), all times posted in UTC
STATE of H1: Observing at 146Mpc
OUTGOING OPERATOR: TJ
CURRENT ENVIRONMENT:
SEI_ENV state: CALM
Wind: 7mph Gusts, 5mph 5min avg
Primary useism: 0.07 μm/s
Secondary useism: 0.05 μm/s
QUICK SUMMARY:
Detector Observing at 147Mpc and has been locked for almost 2 hours.
J. Oberling, R. Short
Today we worked to better optimize the PSL's stabilization systems (PMC, FSS, ISS) after last week's PMC swap.
PMC
We found PMC Refl at ~21 W this morning, when we had left it ~23 W at then end of maintenance last week. The drop is due to the enclosure settling after having the environmental controls on for almost 7 hours (this is normal behavior). PMC Refl had been drifting between 20 W and 21 W since settling down after our incursion, and we did not see a sharp increase over the last week as we had been seeing with the previous PMC. This is good news, but we will continue to monitor this as the slow increase in PMC Refl took place over many weeks.
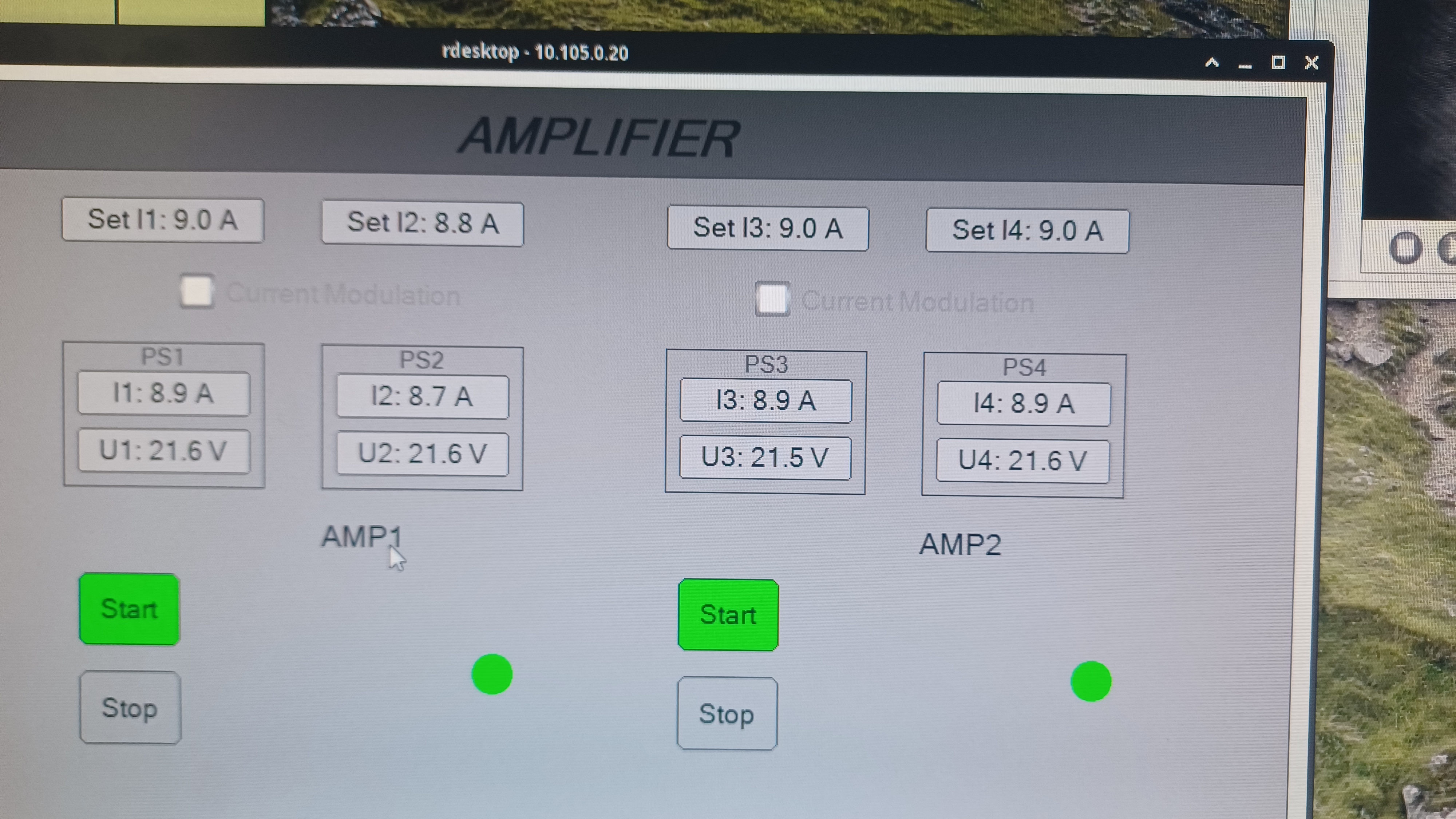
We began by adjusting the operating currents of the PSL pump diodes, as these have a large affect on the output beam quality; this work was done with the ISS OFF. We had adjusted these while PMC Refl for the old PMC was increasing, so it made sense that they would be off with the new PMC. We found that this PMC really likes Amp1 to be pumped less and Amp2 to be pumped more. In the end we had PMC Trans at ~108 W and PMC Refl at ~17.8 W. The pump diode currents are shown in the first picture and given here:
With these pump diode currents Amp1 is outputting ~65.5 W and Amp2 is outputting ~138.0 W (Amp1 output down a little while Amp2 is unchanged). Interesting note, lowering the pump diode currents for Amp1 (and therefore lowering its output power) did not have a large affect on the output power of Amp2, and increasing the pump diode currents for Amp2 did not have a large affect on its output power but did have a large affect on PMC Refl (0.1 A changes resulted in PMC Refl changes of 1.0 W or more).
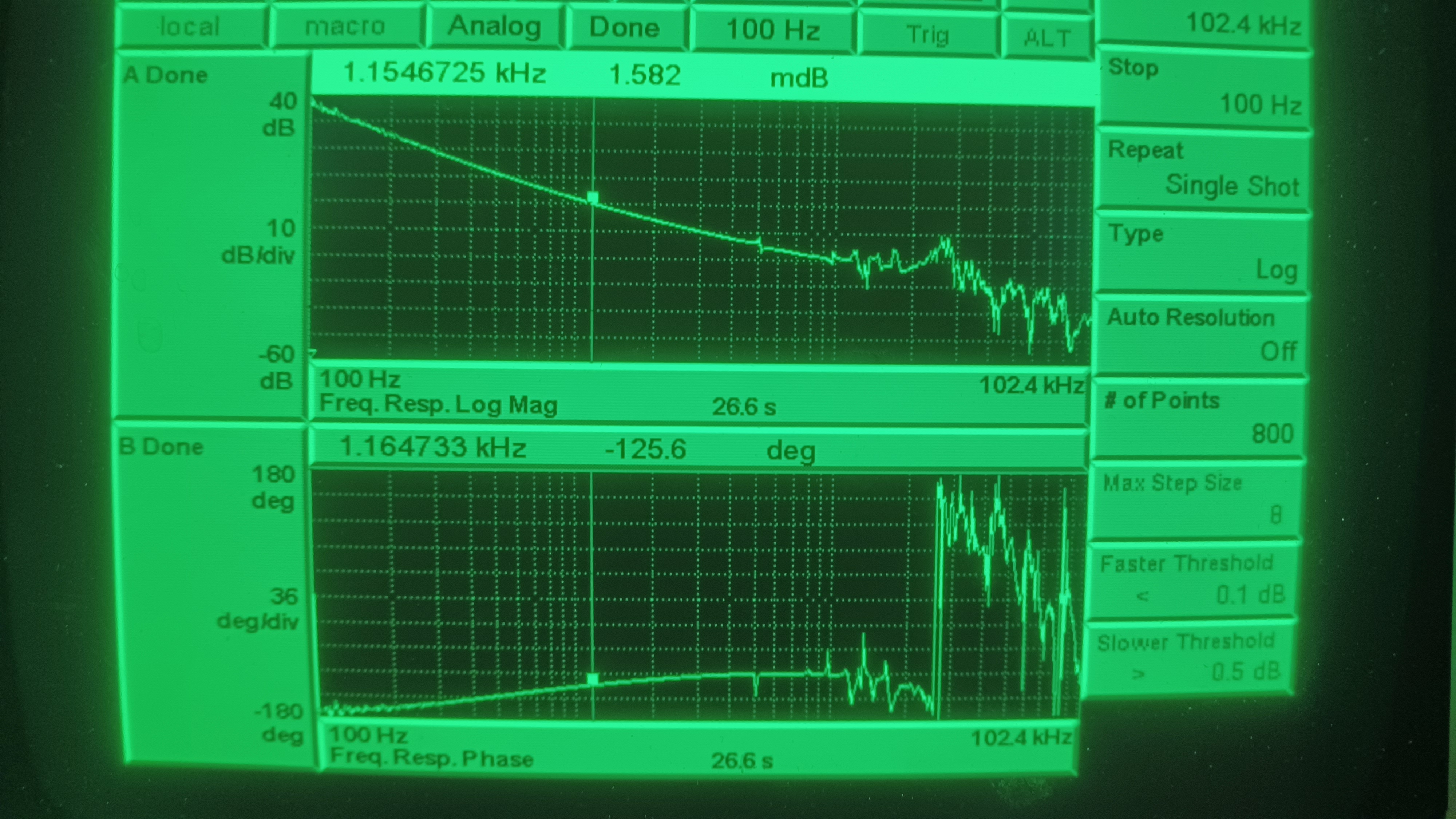
We then went to the LVEA and took a TF of the PMC, results shown in the 2nd picture. UGF is ~1.15 kHz and phase margin is 54.4 degrees. Also, with the enclosure environmental controls OFF the TF is much smoother than the first one we took after the swap (with the environmental controls still ON). Good to see things looking better here. This done we went into the enclosure to tune the ISS and FSS. In discussion with Jenne we decided to wait on tweaking the mode matching lenses until we have done a PMC sweep to see what our mode content looks like.
ISS
We opened up the ISS box to tweak the power on the two ISS PDs. The ISS likes the PDs to output 10 VDC, so the ISS box's internal half-wave plate was adjusted until PDB (which usually reads a little higher) was outputting roughly 10 V. The alignment on each PD was tweaked; PDB was well aligned but PDA was a little off. After tweaking the alignment both PDs read closer to the same value than they have in a while (the BS that splits the light to both ISS PDs isn't an absolutely perfect 50/50), so that's a nice improvement. The final PD voltage values are:
This done, we shut the ISS box and moved on to the FSS.
FSS
The FSS tune up was done with the ISS ON and diffracting ~3% (RefSignal set to -1.99 V); this is done to keep measured power levels stable and helps to speed up the alignment (hard to align an AOM when the power is jumping around). As usual we began by taking a power budget of the FSS beam path, using our 3W-capable Ophir stick head:
We then set about tweaking the beam alignment to increase both the single- and double-pass diffraction efficiencies, as these are both regularly above 70%. There was a change in power state between the initial power budget and our adjustments. We tweaked the HWP WP05, which controls the input polarization of the FSS (WP05 is used in combo with PBS01 to set horizontal polarization w.r.t. the table), and upon re-checking the FSS input power it had "increased" to 292.8 mW. We've seen this with these little Ophir stick heads before. Their small size is very convenient for fitting into tight spaces, like found in the FSS beam path, but they come with drawbacks. They aren't the most stable in the world, and they are VERY angle of incidence dependent; we usually have to spend some time aligning the stick head to the beam to ensure it is as perpendicular as we can get. My guess is this is what happened here, we thought we had it perpendicular when we did not. We confirmed our FSS In and AOM in powers made sense and moved on with the alignment. We tweaked the AOM alignment to increase the single-pass diffraction efficiency, tweaked mirror M21 to improve the double-pass diffraction efficiency, and ensure we were not clipping on the FSS EOM (provides the 21.5 MHz PDH sidebands for locking the RefCav). Our final power budget:
We did have to move the EOM a little to re-center its input and output apertures on the beam. We then adjusted mirrors M23 and M47 (these are our picomotor equipped mirrors) to align the beam to the RefCav using our alignment iris (use M23 to the front of the iris, M47 to the back) and locked the RefCav. The picomotors were used to tweak up the beam alignment into the RefCav; we started with an initial TPD of ~0.63 V and ended with a TPD of 0.793 V. The beam alignment on the RefCav RFPD was then checked and tweaked, and we took locked and unlocked voltages for a visibility measurement:
The visiblity here is a little lower than its norm, which generally hangs out in the lower-80% range (last couple of FSS tune ups had visibility around 83%). Best guess here is a combo of mode matching changes (some evidence of the output mode of this PMC being slightly different from the old) and not quite tweaked up alignment (hard to get the alignment really good while in the enclosure with environmental controls on). Seems there may be some room for mode matching improvement to the RefCav, as both the visibility and TPD are lower than we've usually see after a tune up. Power in the FSS beam is also a little lower than usual (generally around 300 mW, as seen above it's closer to 290 mW now), which also contributes to this. This being the best we could do with what we currently have in the time alloted, we left the enclosure. We'll probably have to do some remote alignment tweaks to both the PMC and RefCav at a later date, once the enclosure is at a better thermal equilibrium. We left the enclosure ACs running for ~15 minutes to bring the enclosure temperature down to its usual ~71.4 degF temperature (as measured by the Table South temperature sensor), and then put everything in Science mode and left the LVEA.
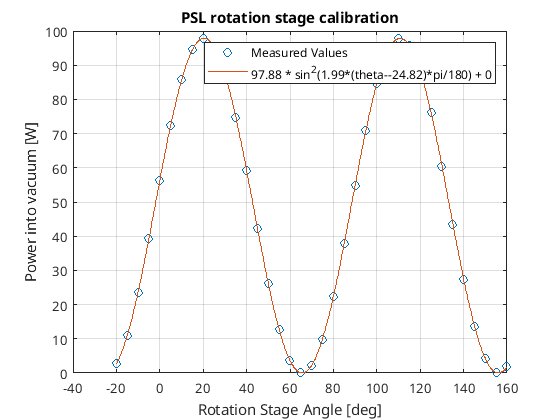
Once back in the control room we turned the ISS back ON. It was already diffracting close to 2.5% so we left the RefSignal alone. Watchdogs were re-enabled and Ryan performed a rotation stage calibration, and we handed things off to TJ for IFO recovery. This closes WP 11947.
We will continue to monitor PMC Refl with this new PMC over the coming weeks.
Following our work in the PSL enclosure this morning (alog from Jason soon to come), I calibrated the PSL rotation stage since the output of the new PMC had again changed slightly.
The process this time had just a couple of hiccups (steps taken listed in alog74597). For starters, the MoveRotationStage.py script had somehow had its contents deleted last week and was robo-committed to svn that way, so I needed to revert it to the previous revision. Also, I'm not sure how I haven't noticed this before, but Jason pointed out while the rotation stage was stepping through each angle, the maximum power out did not line up exactly with one of the preset angles on the stage, so the maximum power stated by the script is not accurate. I'll think about how to rework thse scripts to produce a more accurate calibration curve.
| Power in (W) | D | B (Minimum power angle) | C (Minimum power) | |
| Old Values | 102.488 | 1.990 | -24.801 | 0.000 |
| New Values | 97.882 | 1.990 | -24.818 |
0.000 |
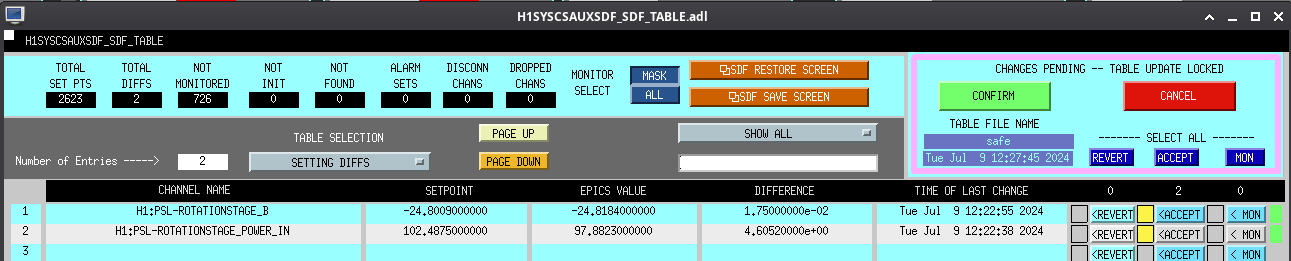
J. Kissel WP 11969 The attached screenshot shows the MEDM screen interface for the new routing of the h1iopomc0's ADC0 signals reading out copies of the OMC DCPD A and B ADC voltage at 524 kHz (see discussion of front-end -model implementation in LHO:78956). From the sitemap, pull down the "OMC" menu (circled in neon green) and select a new screen link "DCPD TEST" (arrow-ed in magenta) That opens up the black overview screen which shows the ADC input matrix and the link to the filterbanks (circled in light blue). That link opens up the screen on the far right of screenshot which displays - read only versions of the primary DCPD A0 and B0 524 kHz banks. - read only version of the PI DOWNCONV SIG filter 524 kHz bank. - The new A1, B1, and A2, B2 filter banks. You can see these screens are already populated in the configuration I want to test first. These settings are all initialized, monitored, and accepted in the SDF settings.
Maintenance completed just after noon. Ryan and Jason then ran a calibration with the PSL rotation stage and then I started an initial alignment.
We are moving onto DC readout now.
WP 11971
The following cables were disconnected at the feedthrough:
1. H1:ISC-X9-82 (EX)
2. H1:ISC-X10-82 (EY)
Cables are for the in-vacuum picomotors. Picomotors are not used. A shortening plug was installed on the each flange (all pins tied to backshell, backshell tied to chamber ground via mounting screws). Will monitor DARM, PEM ESD VMON,and FScan for improvements.



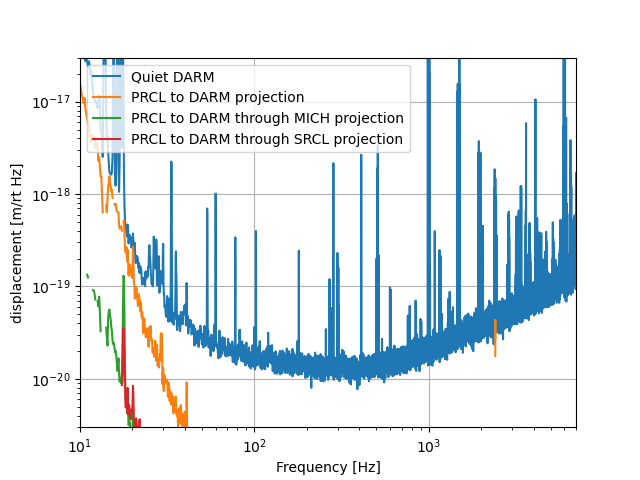
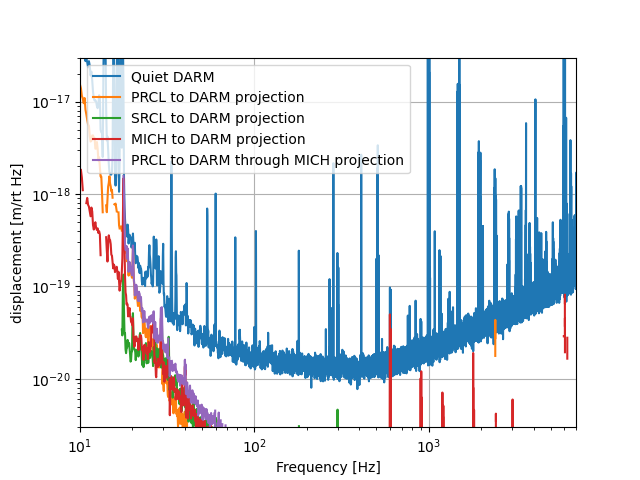
We've consistently seens PRCL coherence with DARM that is higher than MICH and SRCL, and the coupling doesn't seem to be reduced well by decoupling PRCL from SRCL and MICH (see 77416 and 77289). Here are some plots based on old LSC injections made when OM2 was cold, on May 9th. Using the PRCL excitation, I've made an exess power projection to DARM, SRCL and MICH. Then using the MICH (or SRCL) excitation I've projected where the PRCL contribution to MICH (or SRCL) noise that's from PRCL should be in DARM. Both are much lower than the PRCL projection to DARM, indicating that this PRCL projection isn't a double counting of MICH and SRCL noise, and confirming that we won't be able to reduce the PRCL to DARM noise by improving the decoupling of PRCL from SRCL and MICH.
Camilla has taken a more recent set of these injections 78782, so I will try to run this script for those injections. I'd expect to get a similar result. Camilla has now taken measurements to implement a PRCL feedforward.
These measurements and script can be found at /ligo/home/sheila.dwyer/Noise/PRCL/PRCL_projection
We cannot make a reasonable assessment of energy deposited in HAM6 when we had the pressure spikes (the spikes themselves are reported in alogs 78346, 78310 and 78323, Sheila's analysis is in alog 78432), or even during regular lock losses.
This is because all of the relevant sensors saturate badly, and the ASC-AS_C is the worst in this respect because of heavy whitening. This happens each and every time the lock is lost. This is our limitation in configuration. I made a temporary change to partly mitigate this in a hope that we might obtain useful knowledge for regular lock losses (but I'm not entirely hopeful), which will be explained later.
Anyway, look at the 1st attachment, which is the trend at around the pressure spike incident at 10W (other spikes were at 60W, so this is the mildest of all). You cannot see the pressure spike because it takes some time for the puffs of gass molecules to reach the pirani.
Important points to take:
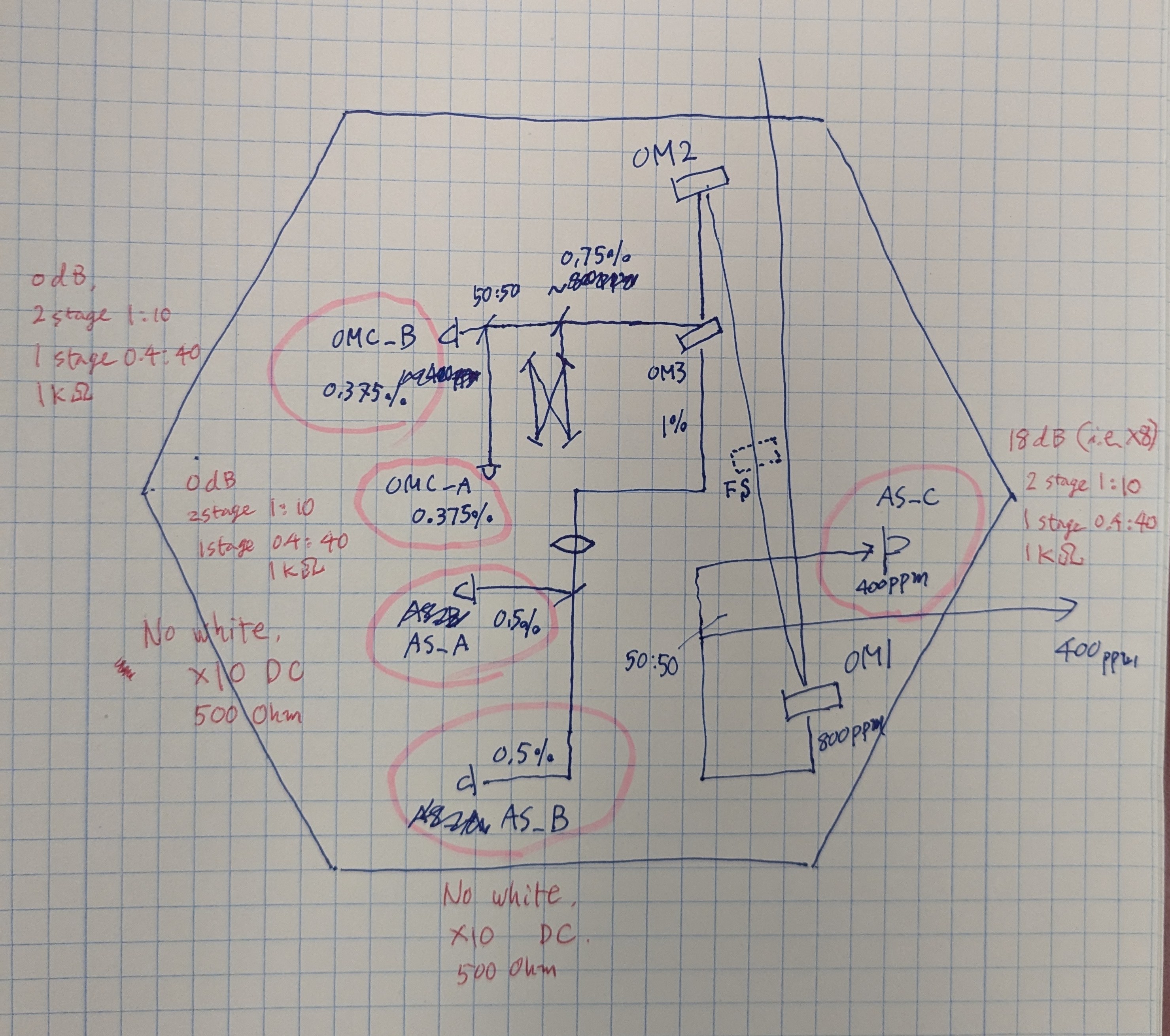
This is understandable. Look at the second attachment for a very rough power budget and electronics description of all of these sensors. QPDs (AS_C and OMC QPDs) have 1kOhm raw transimpedance, 0.4:40 whitening that is not switchable on top of two stages of 1:10 that are switchable. WFSs (AS_A and AS_B) have 0.5k transimpedance with a factor of 10 gain that is switchable, and they don't have whitening.
This happens with regular lock losses, and even with 2W RF lock losses (third attachment), so it's hard to make a good assessment of the power deposited for anything. At the moment, we have to accept that we don't know.
We can use AS_B or AS_A data even though they're railed and make the lower bound of the power, thus energy. That's what I'll do later.
(Added later)
After TJ locked the IFO, we saw strange noise bump ffrom ~20 to ~80 or so Hz. Since nobody had any idea, and since my ASC SUM connection to the PEM rack is an analog connection from the ISC rack that also has the DCPD interface chassis, I ran to the LVEA and disconnected that.
Seems like that wasn't it (it didn't get any better right after the disconnection), but I'm leaving it disconnected for now. I'll connect it back when I can.
In a hope to make a better assesment of the regular lock losses, I made the following changes.
My gut feeling is that these things still rail, but we'll see. I'll probably revert these on Tuesday next week.

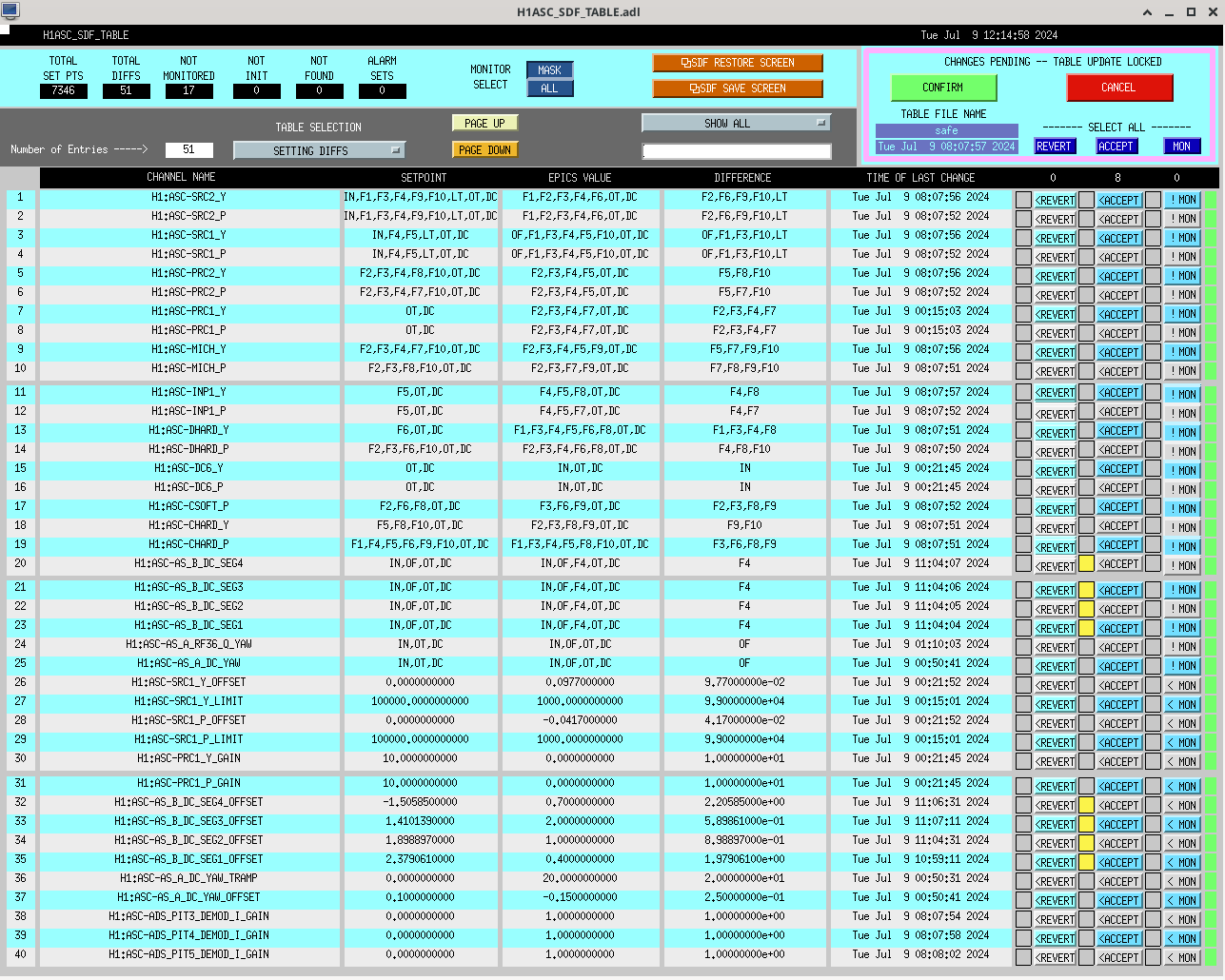
SDF screenshot of accepted values.
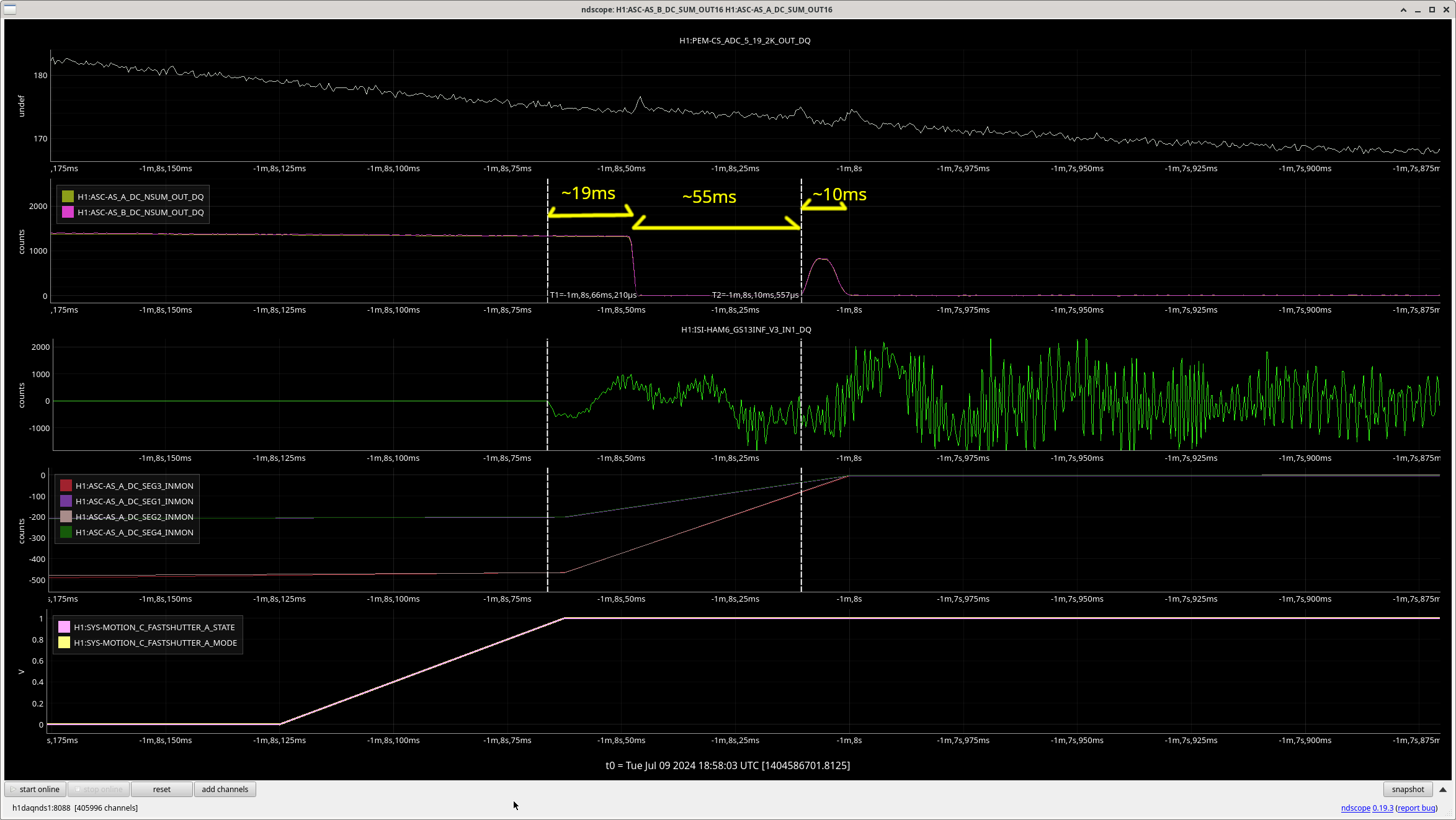
Low voltage operation of the fast shutter: It still bounces.
Before we started locking IFO, I used available light coming from IMC and closed/opened the fast shutter using the "Close" and "Open" button on the MEDM screen. Since this doesn't involve the trigger voltage crossing the threshold, this only seems to drive the low voltage output of the shutter driver which is used to hold the shutter in closed position for a prolonged time.
In the attached, the first marker shows the time the shutter started moving, witnessed by GS-13.
About 19ms after the shutter started moving, the shutter is fully shut. About 25 ms after the shutter was closed, it started opening, got open or half-open for about 10ms and then closed for good.
Nothing was even close to railing. I repeated the same thing three times and it was like this every time.
Apparently the mirror is bouncing down or maybe moving sideways. During the last vent we haven't taken the picture of the beam on the fast shutter mirror, but it's hard to imagine that it's close the the end of the mirror's travel.
I thought that it's not supposed to do that. See the second movie in G1902365, even though the movie is capturing the HV action, not the LV, it's supposed to stay in the closed position.
ASC-AS_C analog sum signal at the back of the QPD interface chassis was put back on at around 18:30 UTC on Jul/11.
Unfortunately, I forgot that the input range of some of these PEM ADCs are +-2V, and so the signal still railed when the analog output of ASC-AS_SUM didn't (2V happens to be the trigger threshold of the fast shutter), so this was still not good enough.
I installed 1/11 resistive divider (nominally 909Ohm - 9.1k) on the output of the ASC-AS_C analog SUM output on the chassis (not on the input of the PEM patch panel) at around 18:30 UTC on Jul/12 2024 while IFO was out of lock.
WP11970 h1susex 28AO32 DAC
Fil, Marc, Erik:
Fil connected the upper set of 16 DAC channels to the first 16 ADC channels and verified there were no bad channels in this block. At this point there were two bad channels; chan4 (5th chan) and chan11 (12th chan).
Later Marc and Erik powered the system down and replaced the interface card, its main ribbon cable back to the DAC and the first header plate including its ribbon to the interface card. What was not replaced was the DAC card itself and the top two header plates (Fil had shown the upper 16 channels had no issues). At this point there were no bad channels, showing the problem was most probably in the interface card.
No DAQ restart was required.
WP11969 h1iopomc0 addition of matrix and filters
Jeff, Erik, Dave:
We installed a new h1iopomc0 model on h1omc0. This added a mux matrix and filters to the model, which in turn added slow channels to the DAQ INI file. DAQ restart was required.
WP11972 HEPI HAM3
Jim, Dave:
A new h1hpiham3 model was installed. The new model wired up some ADC channels. No DAQ restart was required.
DAQ Restart
Erik, Jeff, Dave:
The DAQ was restarted soon after the new h1iopomc0 model was installed. We held off the DAQ restart until the new filters were populated to verify the IOP did not run out of processing time, which it didn't. It went from 9uS to 12uS.
The DAQ restart had several issues:
both GDS needed a second restart for channel configuration
FW1 spontaneously restarted itself after running for 9.5 minutes.
WP11965 DTS login machine OS upgrade
Erik:
Erik upgraded x1dtslogin. When it was back in operation the DTS environment channels were restored to CDS by restarting dts_tunnel.service and dts_env.service on cdsioc0.
Tue09Jul2024
LOC TIME HOSTNAME MODEL/REBOOT
09:50:32 h1omc0 h1iopomc0 <<< Jeff's new IOP model
09:50:46 h1omc0 h1omc
09:51:00 h1omc0 h1omcpi
09:52:18 h1seih23 h1hpiham3 <<< Jim's new HEPI model
10:10:55 h1daqdc0 [DAQ] <<< 0-leg restart for h1iopomc0 model
10:11:08 h1daqfw0 [DAQ]
10:11:09 h1daqnds0 [DAQ]
10:11:09 h1daqtw0 [DAQ]
10:11:17 h1daqgds0 [DAQ]
10:11:48 h1daqgds0 [DAQ] <<< 2nd restart needed
10:14:02 h1daqdc1 [DAQ] <<< 1-leg restart
10:14:15 h1daqfw1 [DAQ]
10:14:15 h1daqtw1 [DAQ]
10:14:16 h1daqnds1 [DAQ]
10:14:24 h1daqgds1 [DAQ]
10:14:57 h1daqgds1 [DAQ] <<< 2n restart needed
10:23:07 h1daqfw1 [DAQ] <<< FW1 spontaneous restart
11:54:35 h1susex h1iopsusex <<< 28AO32 DAC work in IO Chassis
11:54:48 h1susex h1susetmx
11:55:01 h1susex h1sustmsx
11:55:14 h1susex h1susetmxpi
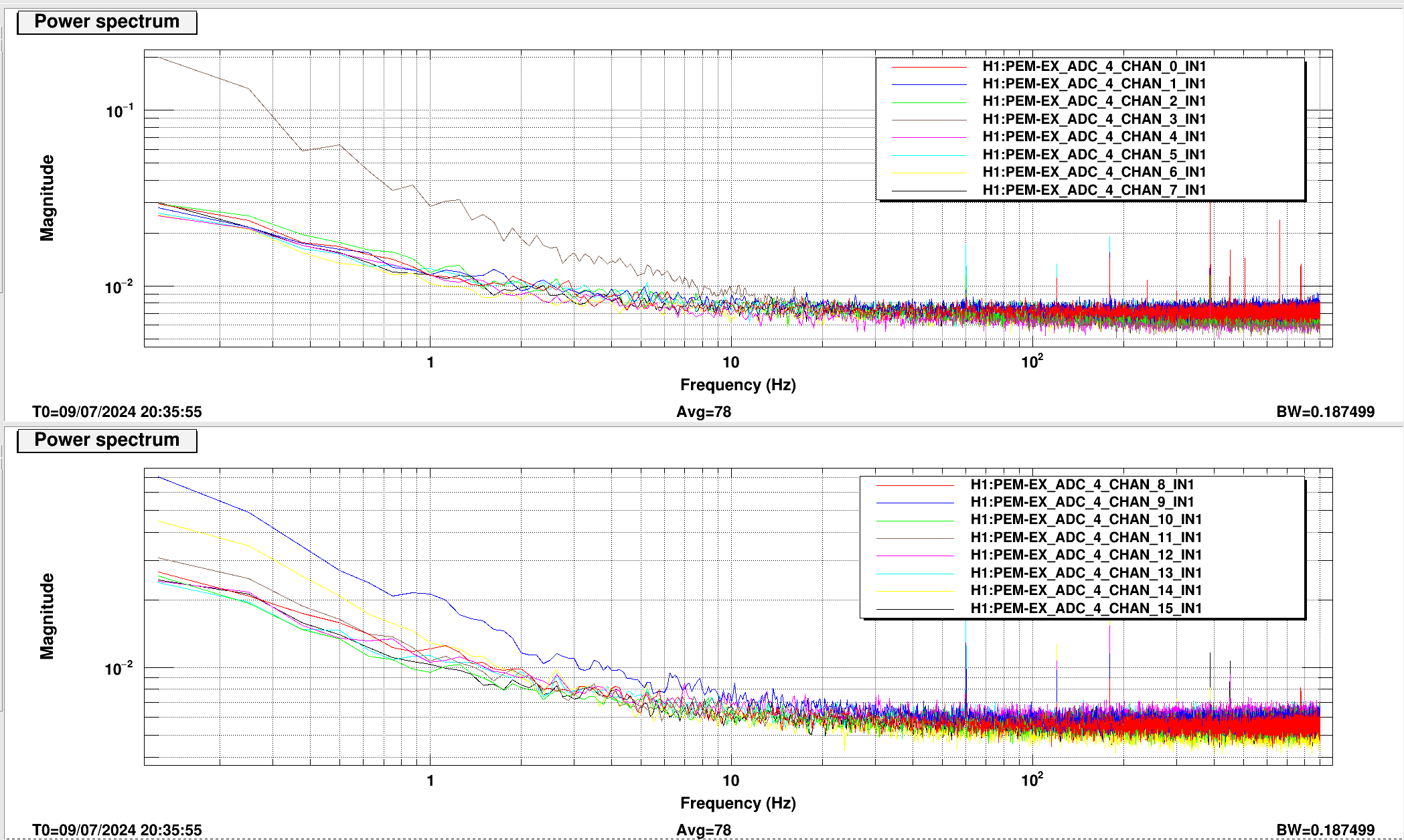
Power Spectrum of channels 0 through 15. No common mode issues detected.
Channel 3 & 9 are elevated below 10Hz
It is unclear if these are due to the PEM ADC or the output of the DAC. More testing is needed.
New plot of first 16 channels, with offsets added to center the output to zero. When offsets were turned on, the 6Hz lines went away, I believe these were due to uninitialized DAC channels. This plot also contains the empty upper 16 channels on the PEM ADC chassis as a noise comparison with nothing attached to the ADC. Channel 3 is still noisy below 10Hz.
New plot of second 16 channels (ports C & D), with offsets added to center the output to zero. This plot also contains the empty lower 16 channels on the PEM ADC chassis as a noise comparison with nothing attached to the ADC. Channel 3 is still noisy below 10Hz, signifying this to be an ADC issue, not necissarily a DAC issue. These plots seem to imply that the DAC noise desnity while driving zero volts is well below the ADC noise floor in this frequency range.
Lockloss @ 07/09 01:46UTC after 8.5 hours locked
02:57 UTC Observing
Bruco ran for last night's 159MPc range (instructions from Elenna), using command below. Results here.
python -m bruco --ifo=H1 --channel=GDS-CALIB_STRAIN_CLEAN --gpsb=1404222629 --length=1000 --outfs=4096 --fres=0.1 --dir=/home/camilla.compton/public_html/brucos/GDS_CLEAN_1404222629 --top=100 --webtop=20 --plot=html --nproc=20 --xlim=7:2000 --excluded=/home/elenna.capote/bruco-excluded/lho_DARM_excluded.txt
Can see:
There are several interesting things at around 30Hz (and around 40Hz) in this BRUCO, which might all be related to some ground motion or accoustic noise witness.
several channels related to HAM2 motion like MASTER_H2_DRIVE. Around 38-40 Hz BRUCO picks out lots of HAM2 channels, and seems to preffer HAM2 over any other chamber. It might be worth doing some HAM2 injections.
This time that Camilla chose was after the PSL alignment shift, but before we moved the beam on PR2 last Friday.


05:06 Observing