oli.patane@LIGO.ORG - posted 18:47, Monday 08 July 2024 - last comment - 21:04, Tuesday 09 July 2024(78947)
Lockloss
Lockloss @ 07/09 01:46UTC after 8.5 hours locked
Lockloss @ 07/09 01:46UTC after 8.5 hours locked
Jennie W, Jenne, Keita, Sheila
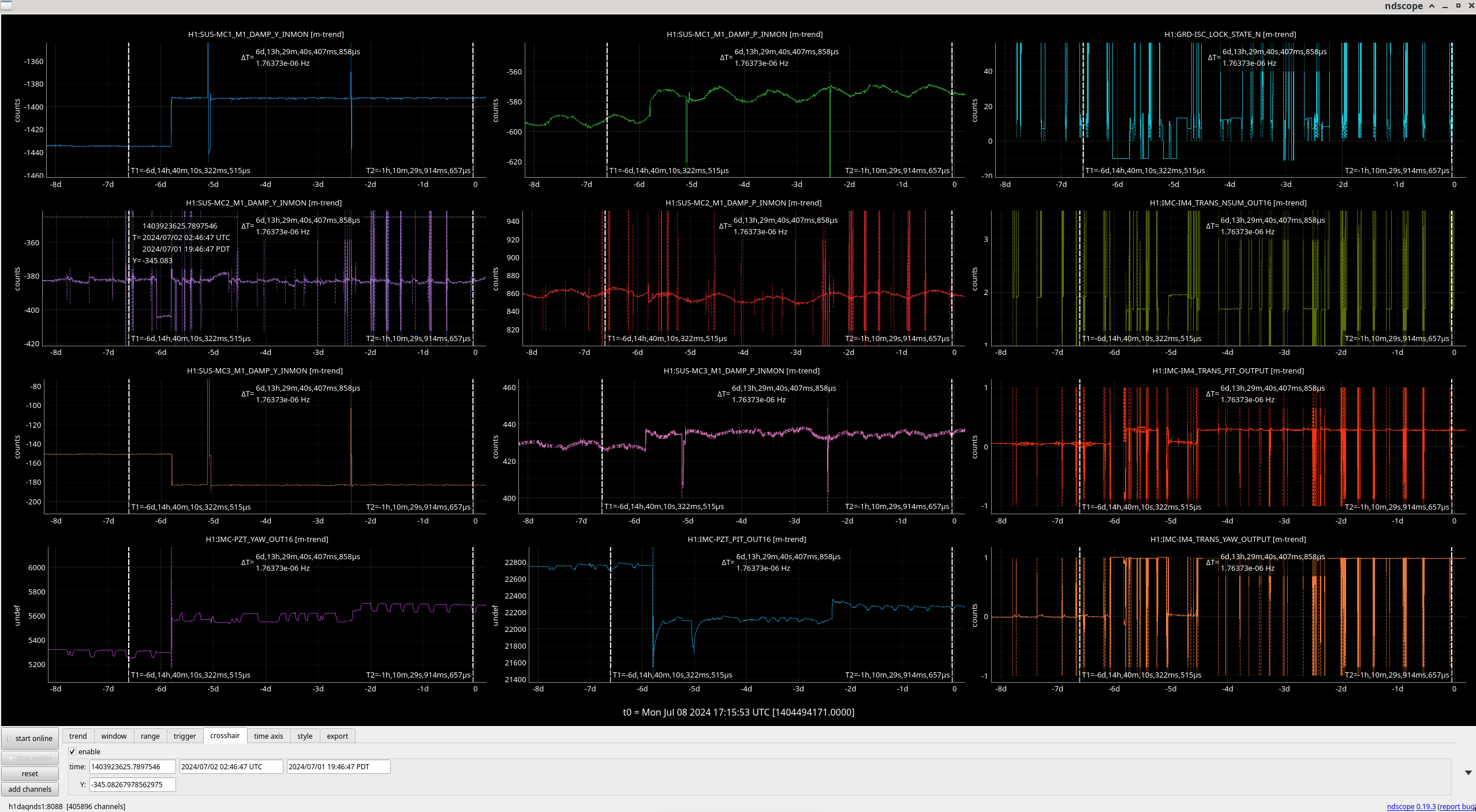
Summary: The input alignment was changed due to the PMC (pre-mode cleaner) swap last week. Sheila et. al. tried to recover this with IM3 moves but the IM4 TRANS QPD, our main alignment reference into the main IFO, is still off in yaw and so we will need to walk mirror or mirrors in the IMC (input mode cleaner) tomorrow to recover this.
The other option is to move something upstream in the PSL but this is harder to do as it involves moving in air steering mirrors and so is harder to reverse. This is plan B for another maintenance Tuesday.
Attached you can see how the MC mirrors changed before (first cursor) and after (second cursor) the PMC swap and Jenne tweaking the periscope mirror (first two plots in bottom row show positioning into IMC via the pitch and yaw of the upper PSL periscope mirror).
Plan: Move MC3 in yaw in order to change the output spot position in the IMC. We will do this with the ASC for the IMC running so the alignment loops for the angle of MC2 and the differential yaw between MC1 and MC3 will still run, but I will increase the gain value of these loops to its old value from December 2014 (0.25).
For future reference, the triangular cavity DOFs are discussed here: DCC LIGO-P1000135
And the MC in particular here: DCC LIGO-G1301131
TITLE: 07/08 Day Shift: 1430-2330 UTC (0730-1630 PST), all times posted in UTC
STATE of H1: Observing at 155Mpc
INCOMING OPERATOR: Oli
SHIFT SUMMARY:
Internet went down 15:09 UTC for what seemed like less than a minute. Cause: Automatic Switching from Boise Connection to Seattle.
Lockloss 15:11 UTC due to an earthquake.
https://ldas-jobs.ligo-wa.caltech.edu/~lockloss/index.cgi?event=1404486684
We moved PR3 back to it's previous position while in Input_Align.
Sheila is touching up the COMM And DIFF beat notes.
17:14 UTC Earthquake passed through and was not announced.
Comissioning started at 17:16 UTC
Nominal_Low_Noise reached at 18:31 UTC.
Observing reached at 18:32 UTC
LOG:
| Start Time | System | Name | Location | Lazer_Haz | Task | Time End |
|---|---|---|---|---|---|---|
| 16:08 | SAF | LVEA | LVEA | YES | LVEA IS LASER HAZARD | 10:08 |
| 15:02 | FAC | Tyler | Water Tank | N | Moving truck over to water tank | 15:12 |
| 15:28 | FAC | Karen | Optics Lab & VAC Prep | N | Technical Cleaning | 15:57 |
| 15:59 | ISC | Sheila | ICST1 | Yes | Aligning COMM and DIFF BeatNotes | 16:29 |
| 16:45 | FAC | Karen | Mid Y | N | Technical Cleaning | 17:45 |
| 16:53 | FAC | Kim | Mid X | N | Technical Cleaning | 17:42 |
| 17:26 | SQZ | Naoki | Ctrl Rm | N | Testing SQZr | 17:46 |
| 17:55 | PCAL | Francisco | PCAL Lab | Yes | PCAL Lab Upgrades | 20:59 |
| 18:12 | PRCL | Camilla | CRTL Rm | N | PRCL Measurement | 18:22 |
| 18:20 | OMC | Naoki | Ctrl Rm | N | Exciting OMC | 18:24 |
| 18:25 | SUS | Josh | Ctrl Rm | N | osem measurements | 18:30 |
TITLE: 07/08 Eve Shift: 2300-0800 UTC (1600-0100 PST), all times posted in UTC
STATE of H1: Observing at 154Mpc
OUTGOING OPERATOR: Tony
CURRENT ENVIRONMENT:
SEI_ENV state: CALM
Wind: 9mph Gusts, 4mph 5min avg
Primary useism: 0.02 μm/s
Secondary useism: 0.05 μm/s
QUICK SUMMARY:
Observing and Locked for almost 6 hours. Everything going well.
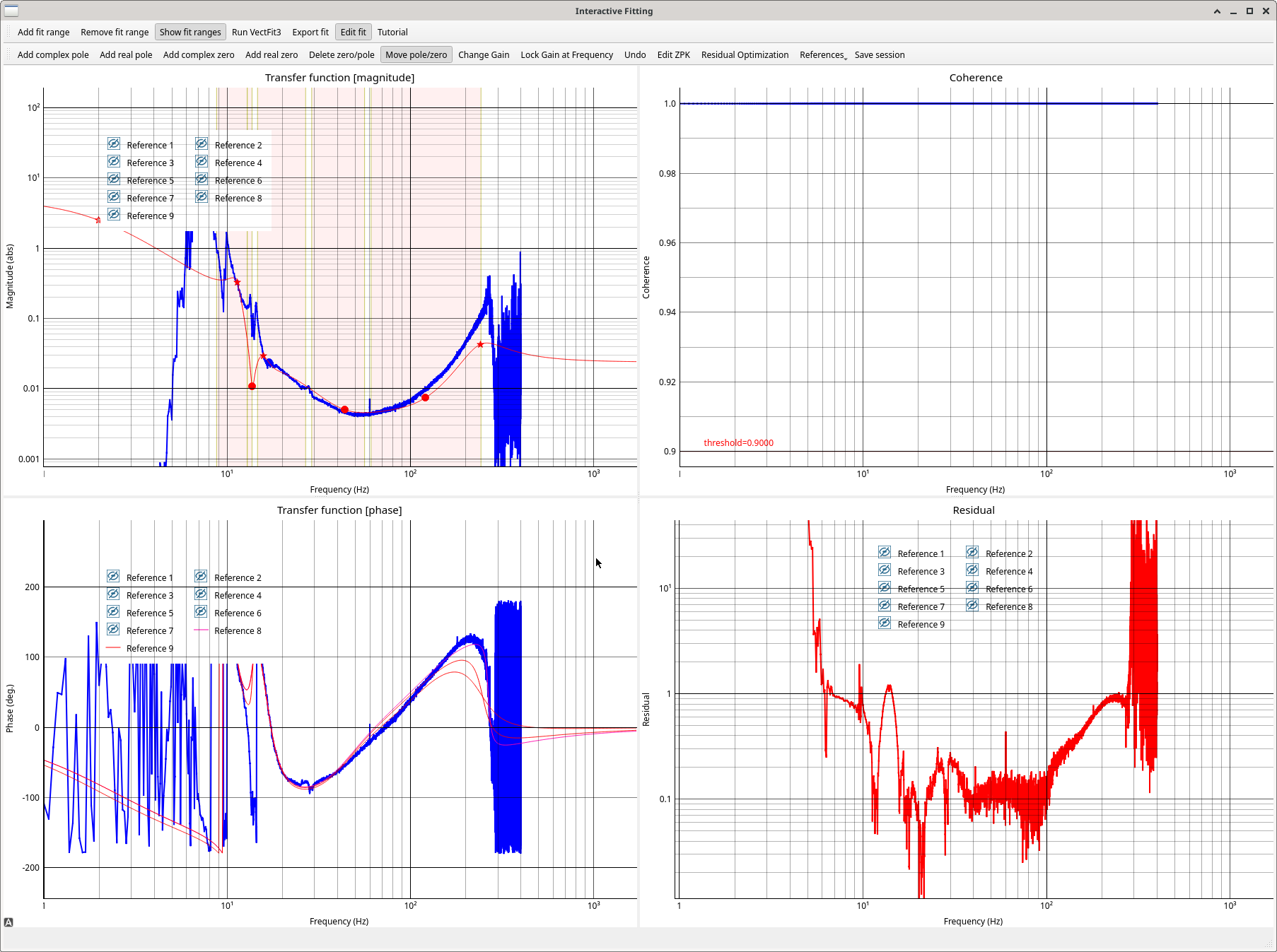
We made a PRCL excitation we should later be able to use to create a PRCL FF, saved in lsc/h1/scripts/feedforward/PRCL_excitation.xml and exported .txt files.
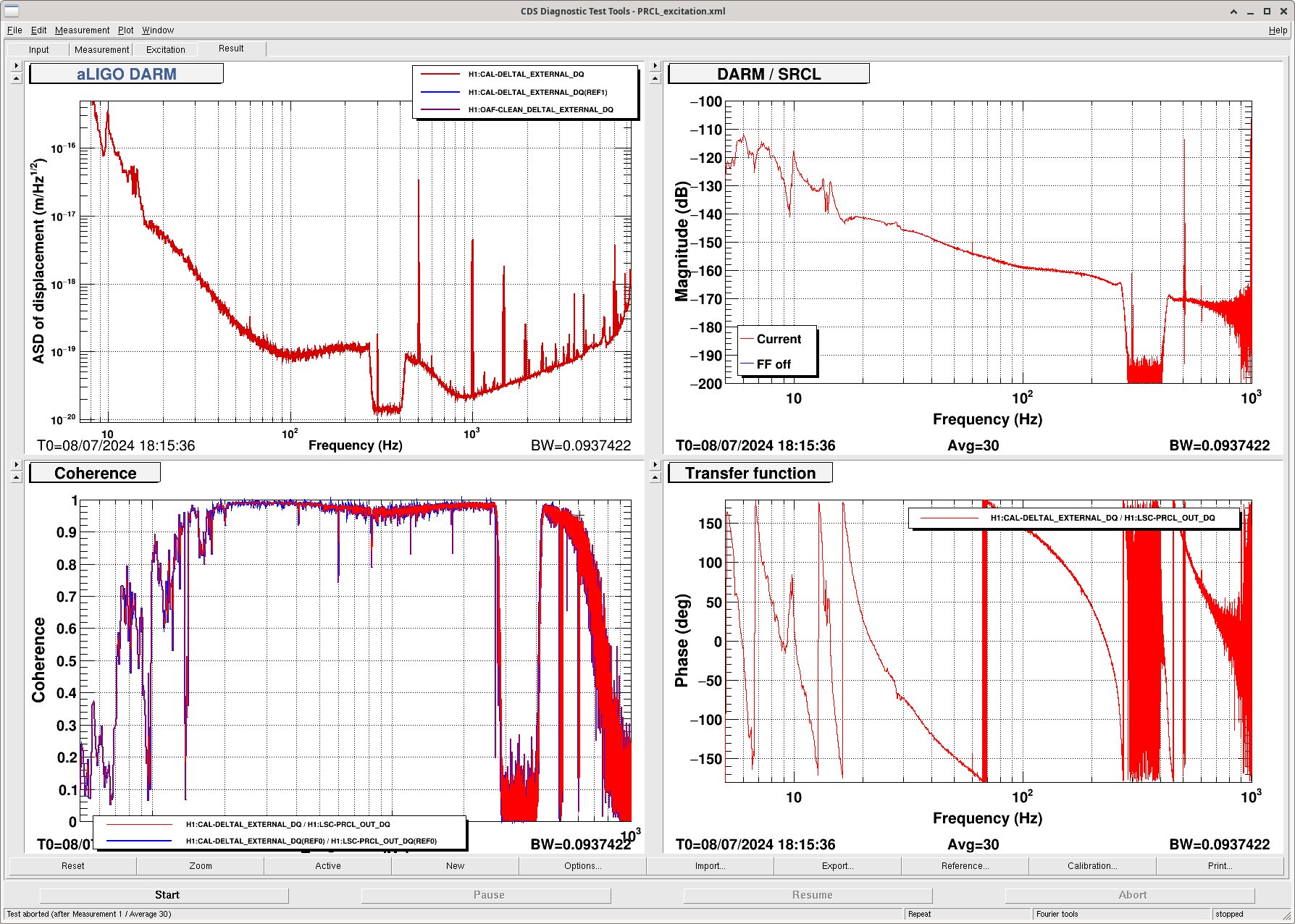
I didn't taken PRCLFF injections, but the same high pass is used in MICH as PRCL, both fed to ETMY, so I used the last MICHFF injections for this.
Used NotItter_PRCL_FF_PrepareData.ipynb and InteractiveFitting to make a first go at a PRCLFF fit. See attached. This is ready for h1lsc load coefficients and then will be in FM1 as 7-10-24.
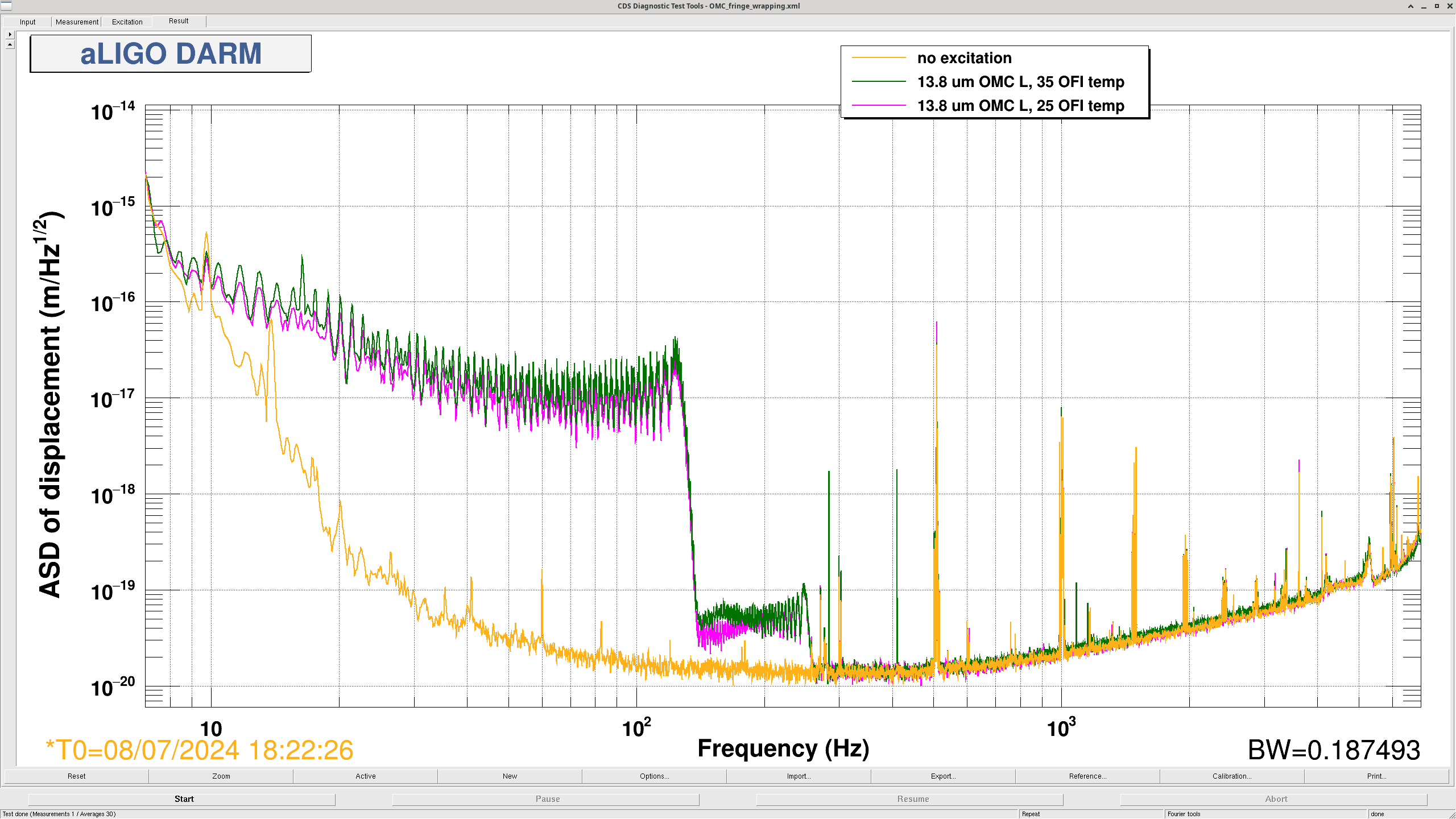
Naoki, Sheila
We did the OMC fringe wrapping measurement as Sheila did in 77452.
The template for OMC fringe wrapping is in /ligo/home/sheila.dwyer/OMC/OMC_fringe_wrapping.xml.
This time, we fixed the excitation on OMC L and changed the OFI temperature. The frequency of excitation is 0.65 Hz and amplitude is 13.8 um peak to peak on H1:SUS-OMC_M1_DAMP_L_IN1_DQ. The nominal OFI temperature is 25 and we changed it to 35. We waited for OFI witness temperature to reach the target value. We changed it back to 25 after the measurement.
As shown in the attachment, the OFI temperature of 25 looks slightly better than 35, but IFO was locked for only an hour and still thermalizing so we should repeat this measurement after thermalization.
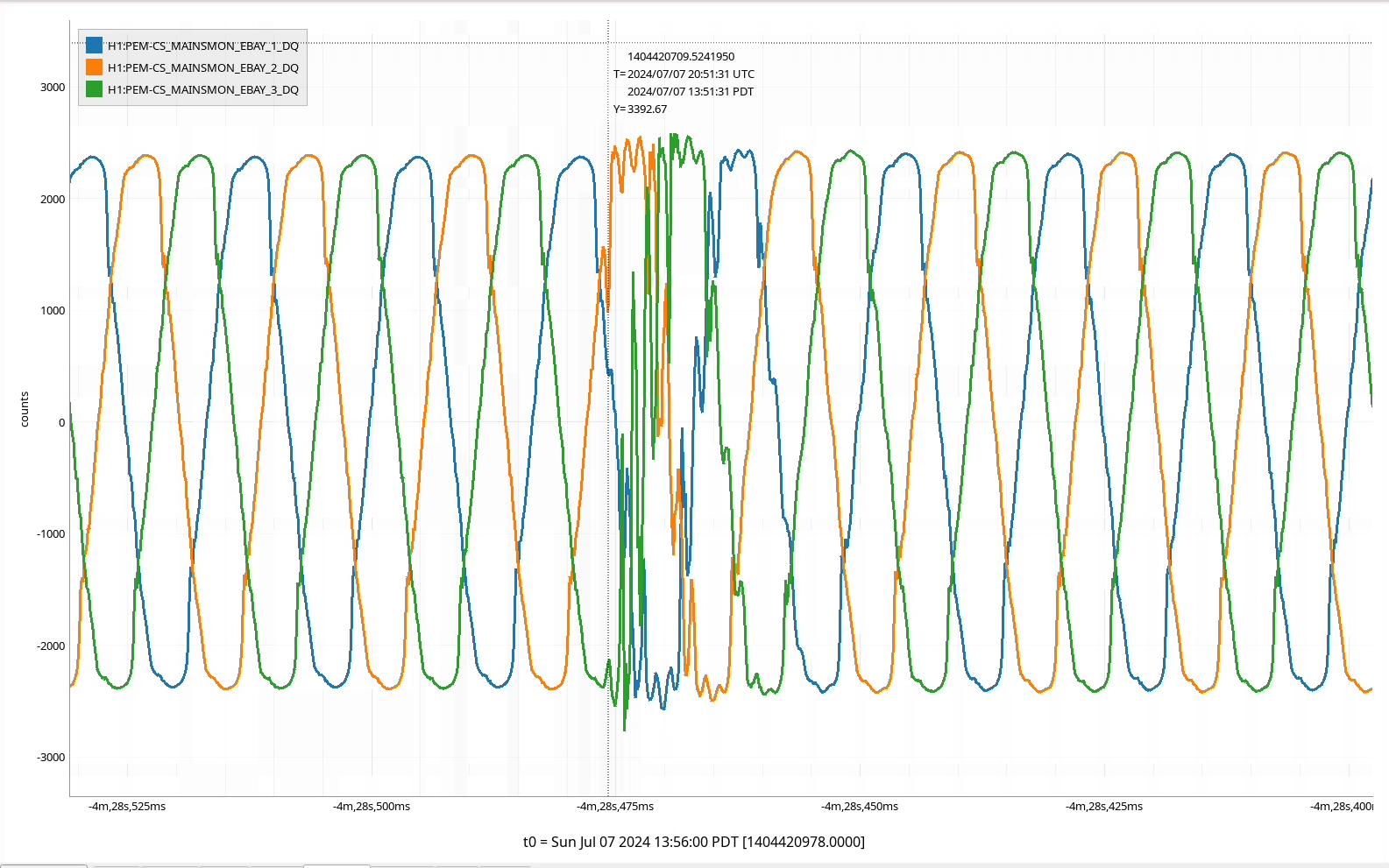
The MSR UPS unit went briefly into battery backup due to an input power problem at 13:51:31
It was only on battery power for 2 seconds before it switched back to facility power.
Attached plot shows the corner mains phases at GPS time 1404420709.52
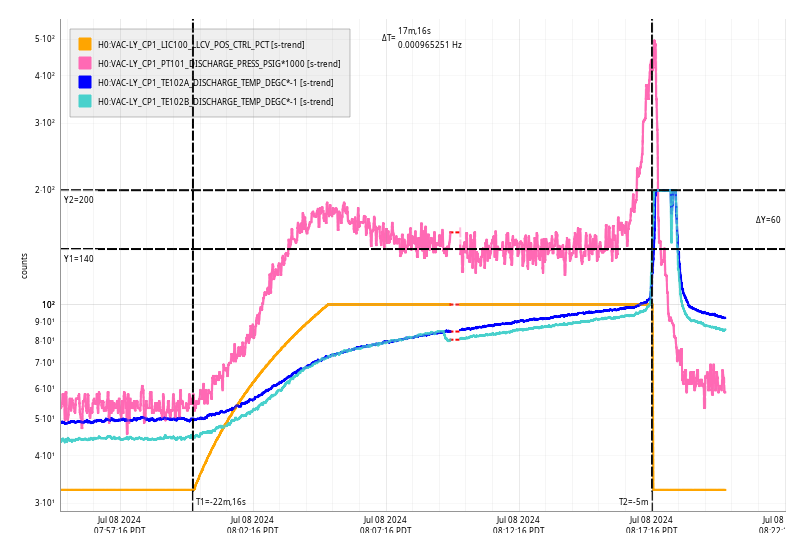
Mon Jul 08 08:17:16 2024 INFO: Fill completed in 17min 12secs
Gerardo confirmed a good fill curbside. Outside temps 30C (86F).
TITLE: 07/08 Day Shift: 1430-2330 UTC (0730-1630 PST), all times posted in UTC
STATE of H1: Observing at 155Mpc
OUTGOING OPERATOR: Ryan S
CURRENT ENVIRONMENT:
SEI_ENV state: SEISMON_ALERT
Wind: 5mph Gusts, 3mph 5min avg
Primary useism: 0.02 μm/s
Secondary useism: 0.05 μm/s
QUICK SUMMARY:
IFO Locked and Observing for 9 Hours.
everything seems to be functioning well.
Daniel, Nutsinee
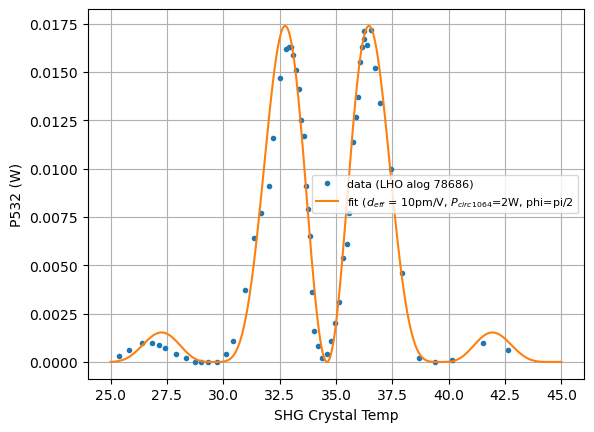
I was intrigued by the Twin Sisters Rock feature in the brand new spare SHG Terry and Karmeng put together so I did a little bit of digging. A quick summary is that we believe the Twin Sisters Rock feature were caused by the phase mismatch between the red and the green inside of the SHG cavity. We believe the dichroic coating of the SHG back mirror might be a suspect since the coating specifications can not be found. However, the phase mismatch doesn't neccessary explain the Mount Saint Helens in the 6 year-old SHG we are currently using.
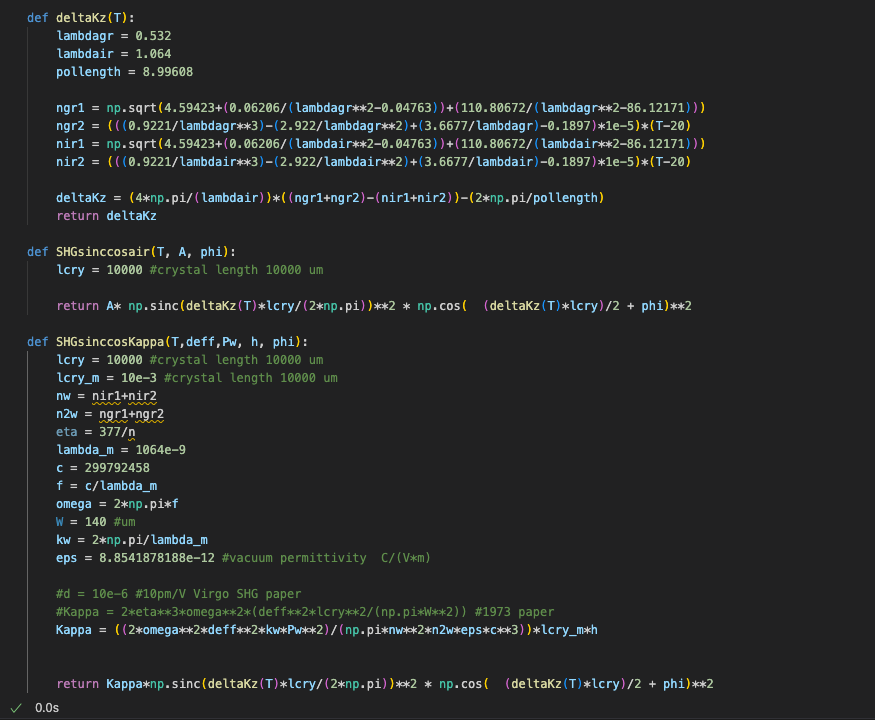
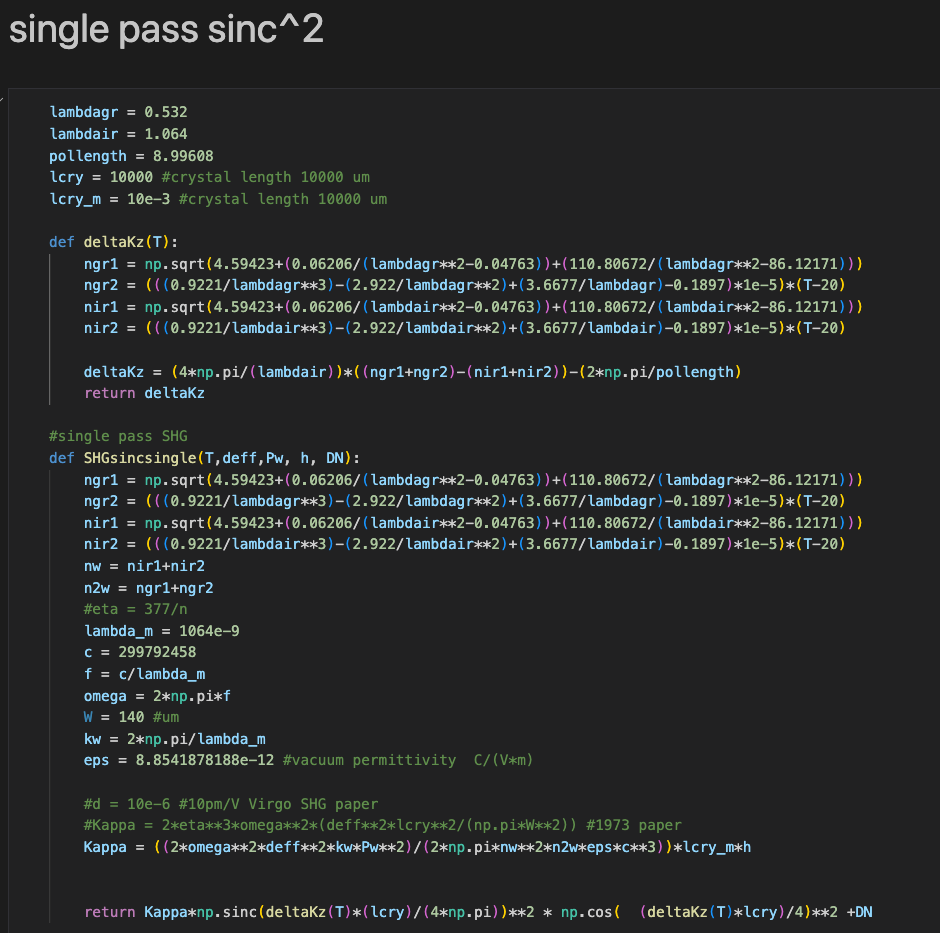
The equation used to fit the data came from Gonzalez, Nieh, and Steier 1973 equation1. The equation looks similar to the usual sinc^2 function we know and love except that it's taken the phase mismatch between 532 and 1064 and the air dispersion into account in the cos^2 term. This paper also shows that the experimental data doesn't necessary match the model (Fig.3). The problem is we have to related deltaK*l term to temperature. This was done using Kato and Takaoka 2002. This left us with K_0. The only unknown-ish term here is the nonlinear coefficient d_eff inside of K_0. We used d_eff = 10pm/V as suggested by Leonardi et al 2018. After I wasn't able to get a sensible result Daniel pointed out that unit in K_0 doesn't add up. We replaced K0 with equation1 from Arie et al 1997.
The function is also very sensitive to polling length of the crystal. Since we don't have the exact number of the polling length, we picked a polling length such that deltaK is 0 at 34.6 C (optimal phase match condition). The polling length we got was 8.99608um. I believe the crystal polling length according to Raicol is 9um.
The function in the end looks like this. I was able to fit Karmeng's Twin Sisters Rock using sensible parameters (d_eff = 10pm/V, circulated 1064 power of 2W, Boyed-Kleinman focusing parameter = 0.9, and a phase shift of Pi/2). Other variations of the spare SHG plots can be explained by shifting this phi variable.
We suspect the coating of the SHG back mirror might be to blame. None of the SHG plots found in SURF reports (Nathan Zhao, Andre Medina) look symmetric like they should.
The zip file of the python code is also attached.
If the coating is not to blame, I wonder if it's time we think about redesigning a SHG that is more tolerant to the assembly line errors.
For people who are too lazy to read the paper: The dispersion that matters is between the first path and the second path in the crystal. In a simple dual path system, green light will be generated in phase with the red light in the first path, then the two frequencies propagate in air towards the rear mirror, where they are reflected with potentially different phases, and then propagate back to the crystal. According to Gonzalez et al. the dispersion in air for 1064/532 is 27.4°/cm (double passed). Our SHG length is about 5 cm long with a 1 cm crystal. So, the in-air path is of order 4 cm. You need a 90° phase shift to explain the double peak. However, the phase difference of our mirror reflectivity is unknown.
Daniel Nutsinee
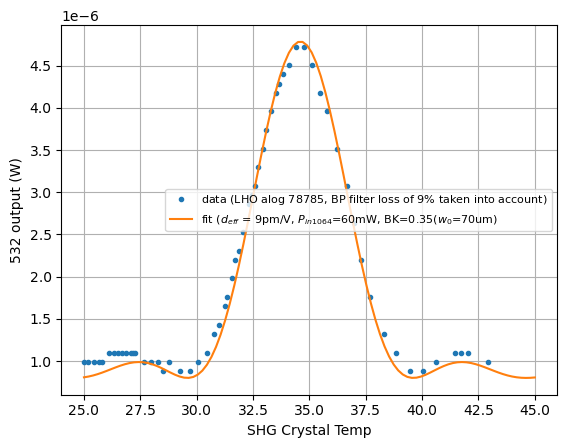
We futher fit a single pass measurements with following parameters:
d_eff = 9pm/V
input power = 60mW
Boyd-Klienman factor = 0.35 (corresponds to w0 = 70um according to Karmeng this is what he sent into the cavity)
The measured power was so low a dark noise is required to offset the model to fit the data correctly. This value is 0.8 uW.
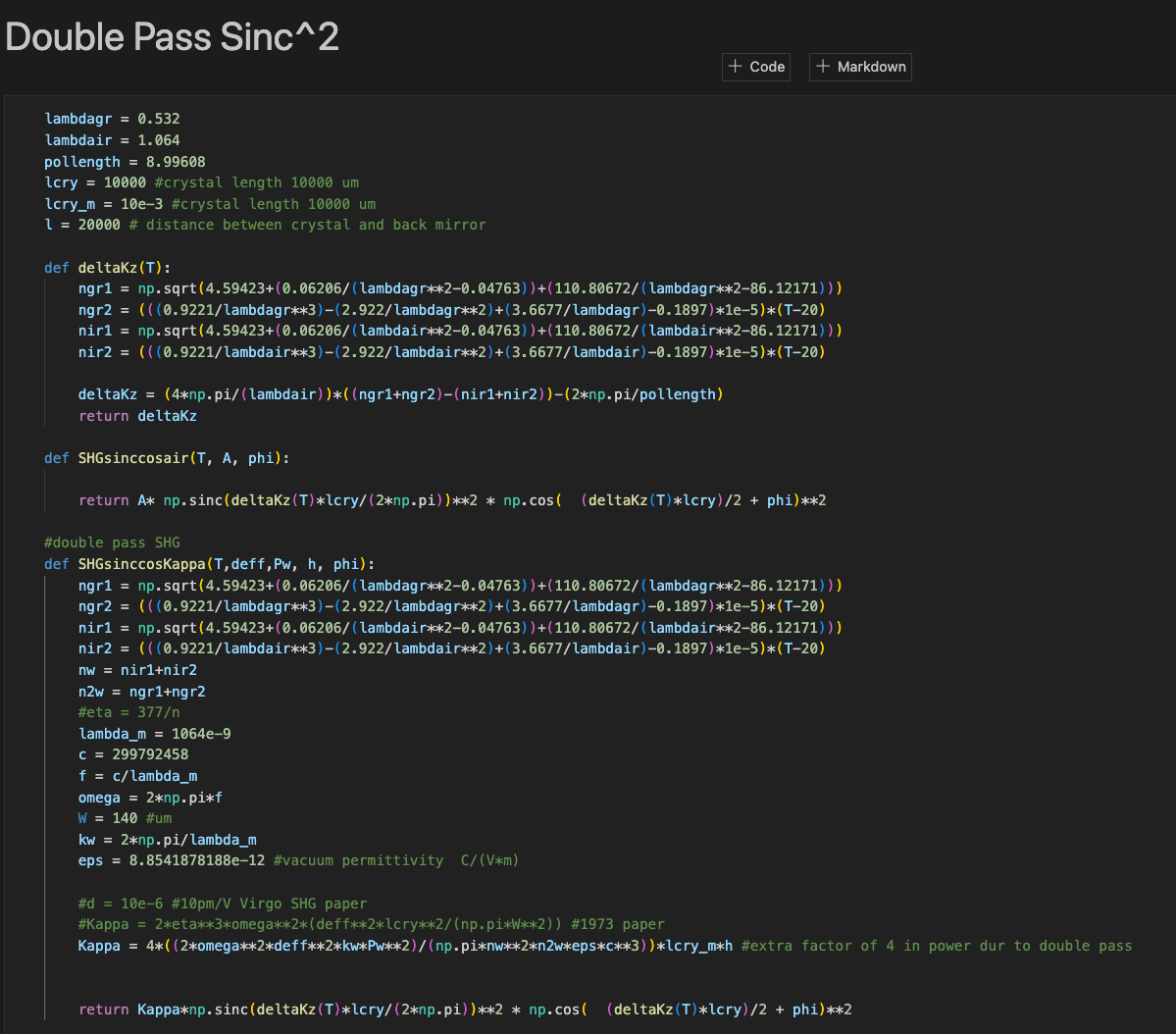
A factor of 1/2 has been added inside of sinc and cos term to convert from double pass to single pass. This agrees with Sheila's equation 3.14.
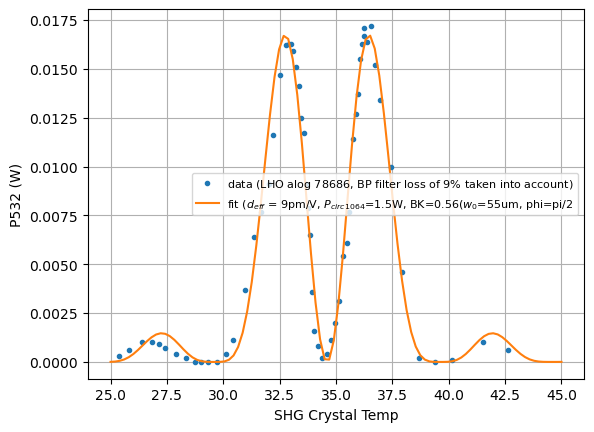
We also added a factor of 4 to the original function used to fit the double peak measurement to take into account the double pass (4 times the single pass power). A newly acquired Boyd-Klienman factor is 0.56 (corresponds to w0 = 55um, a beam waist dictates by the known cavity parameters). I recalculated circulated power taken into account loss measurement from the escape efficiency. The model suggests 1.7W. I managed to fit using 1.5W. We don't know the modulation depth used to generate the locking signal so this number can be wiggled around a bit. The facator of 4 can also be wiggled around a bit as we don't really know the green loss as it emerges from the cavity.
According to Karmeng the data was taken through a green Bandpass filter with 9% green loss. The data has been multipled by a factor of 1.09 to compensate for this loss.
In summary, our model fits both the Twin Sisters and the single pass measurements.
TITLE: 07/08 Eve Shift: 2300-0800 UTC (1600-0100 PST), all times posted in UTC
STATE of H1: Observing at 154Mpc
INCOMING OPERATOR: Ryan S
SHIFT SUMMARY: One lock loss during the shift. During reacquisition I moved PR3 a little bit to help the comm beat note. After an initial alignment it went straight up and we've been observing for 2.5 hours now.
LOG:
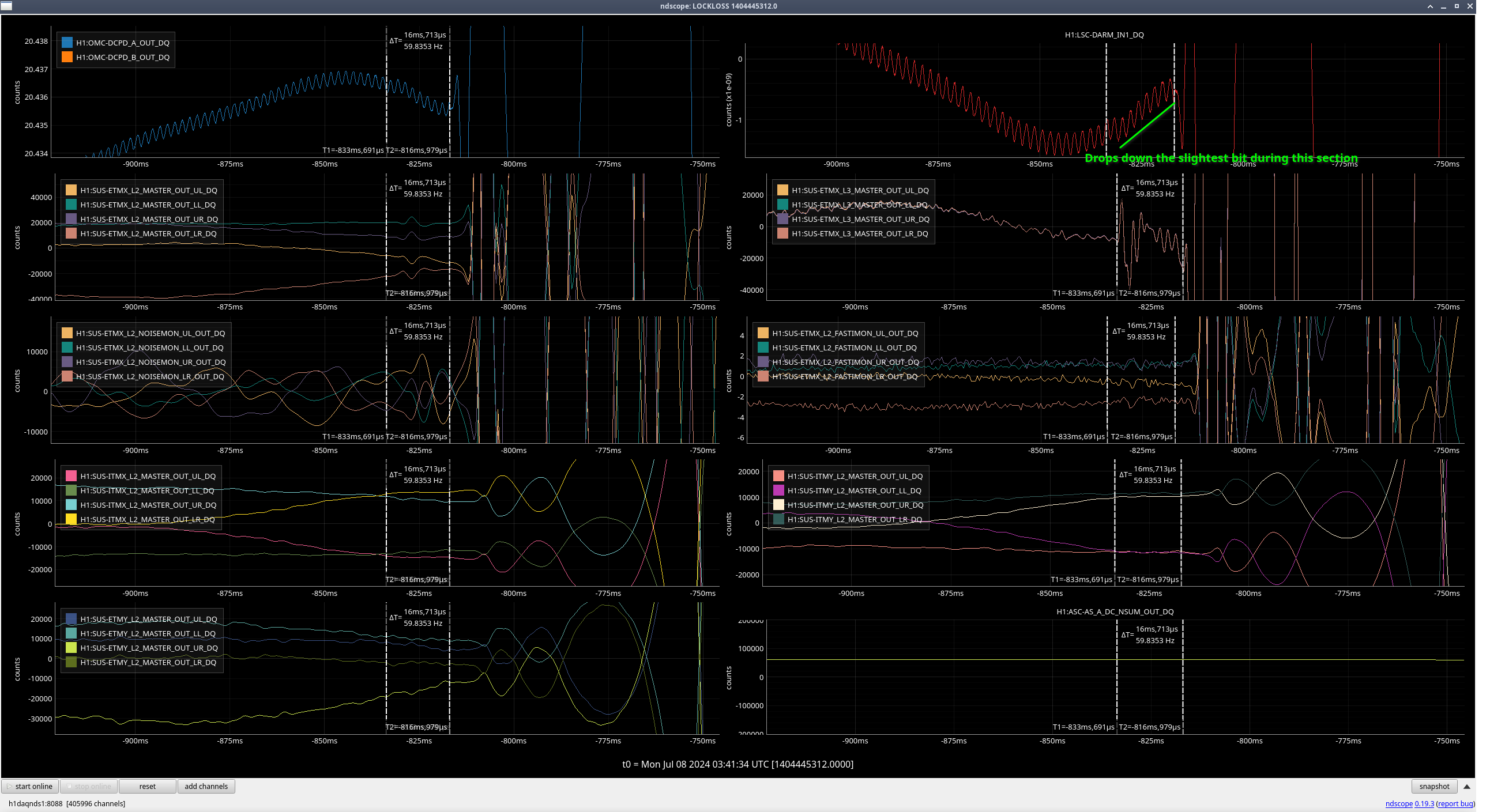
Lock loss 1404445312
5 hours and 42 mins seems like a standard lock for this week. LSC-DARM saw an odd wiggle before lock loss, normally I see an ETMX output that matches this but I didn't see that this time.
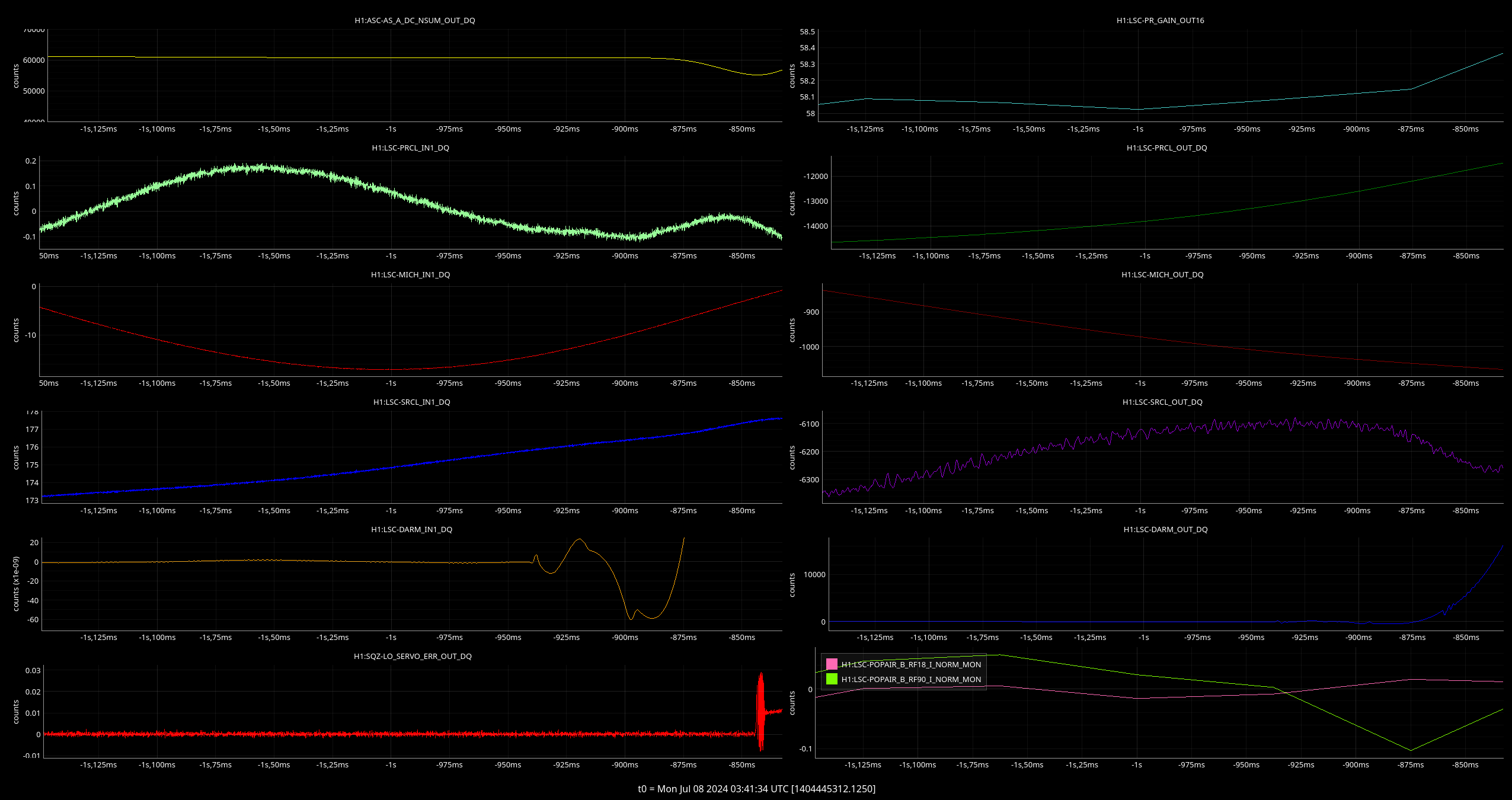
Back to Observing at 0528 UTC.
I ended up slightly moving PR3 P from -122.2 -> -121.6 and Y from 98.8 -> 98.6. This brought the beatnote up to around -14.5dBm, up from the -18 or so that I started at, and ALSX power moved up as well. when DRMI locked POP18 looks to be higher than it was the last handful of locks over the last few days. I ran through an initial alignment and then it went right up.
EX L3 does oscillate 16 ms before DARM sees the lockloss, although it might be possible that the slight drop (marked in green) is DARM seeing it??
I have replaced the original viewport covers so the LVEA is ready to go to laser safe.
At the last minute I finally found a beam on the MC baffle by HAM3. The beam is on the +X side of the baffle, near the hole for the viewport for the PRM camera. I will see if it moves with the CP when I return.
TITLE: 07/07 Day Shift: 1430-2330 UTC (0730-1630 PST), all times posted in UTC
STATE of H1: Aligning
INCOMING OPERATOR: TJ
SHIFT SUMMARY:
Similar shift to yesterday (except we're around 102degF!), with a 4-5hr lock and 2-3hr reacquisition (with rough locking for the first 90min).
(Since Observing time is precious, I didn't even think of running a calibration since L1 & V1 were UP all the times I could have run a calibration.)
Robert was onsite as well as JennyW for an RRT shift.
LOG:
Jennie Wright points out that the 19:34 lockloss 1404416083 has the glitch we've been seeing in DARM/length in the 100's ms before the lockloss 73818 73565. Her plot attached. Ianin Morton is preaping a lockloss tag for this: issue #219.
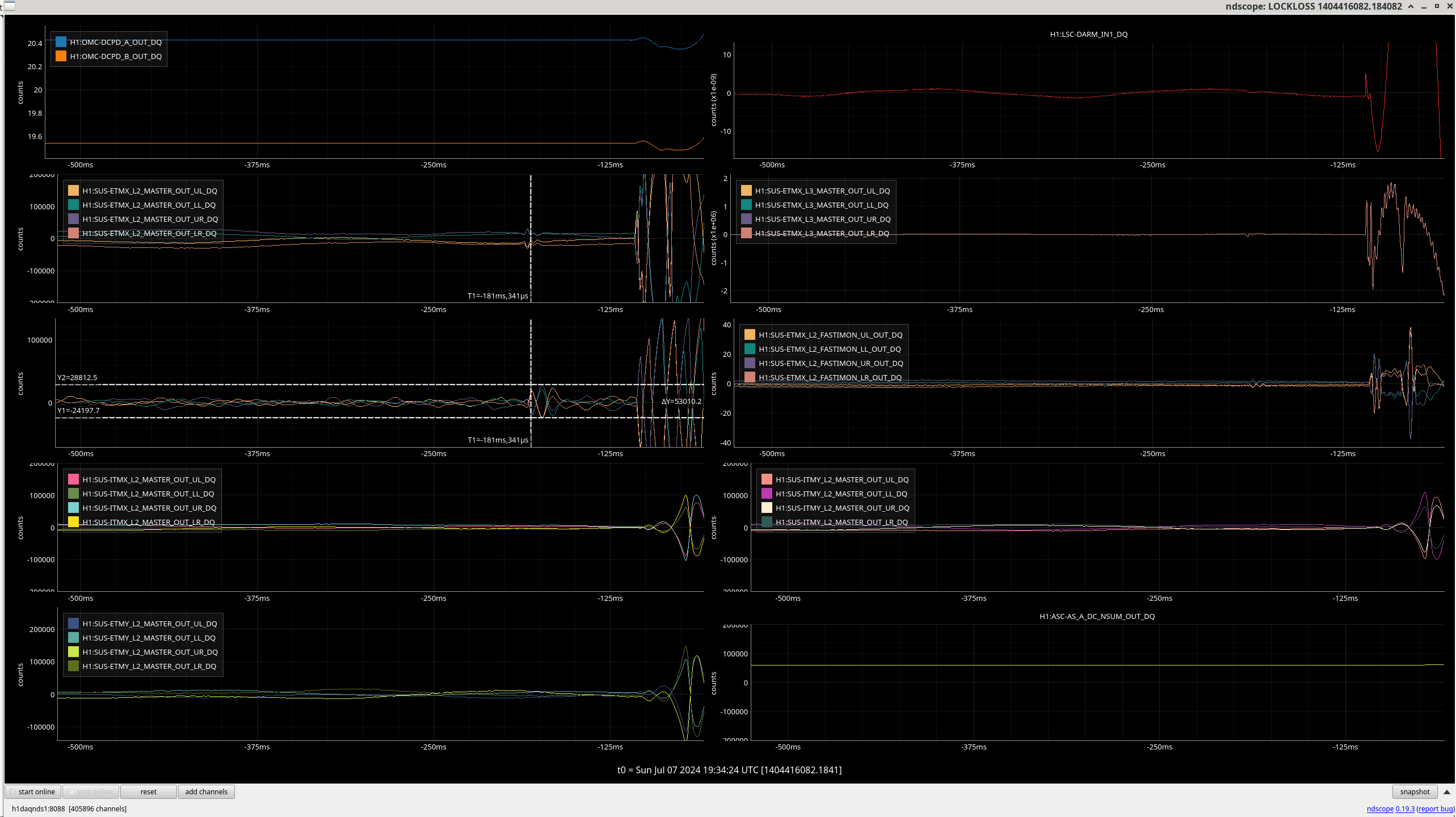
Lock loss 1404369750
Again, not seeing much of anything on any of the plots. Another 4-5 hour lock.
Hey so I had a quick squiz whether your locklosses might be PI related. The regularity of your lock lengths is very suspicious.
You had at least one lockloss from a ~80296 PI on July 5th just after 6am UTC.
Since then you have been passing through it, exciting it, but surviving the PI-Fly-By.
On those plots you will notice broader a feature that moves slowly up in frequency and excites modes as it passes (kinda vertical-diagonalish on those plots) that smells like the interacting optical mode to me.
Last couple of days you have lost lock when that feature reaches ~80306, where there's a couple of modes which grow a little in amplitude as the broad feature approaches.
It is hard for me to say which mechanical mode had the super high gain that would make you lose lock on the scale of seconds [because these modes would move wildly in frequency at LHO as I discuss in the link at the end of this line], but its in that ballpark,and I quote myself: avoid at all costs.
Please investigate if this is PI and whether you need to tweak up your TCS.
EDIT: Longer lock on the 8th makes me think 80kHz PIs are probably fine. Worth double checking carefully in the 20-25 kHz region since your mode spacing looks pretty high. It might be subtle to see in the PI plot on the lock pages since that aliases a lot of noise all over the place.
Thanks for pointing us to these PI locklosses out Vlad, Ryan also caught one of them in 78867, 78874.
The lockloss website for the July 5th 637UTC lockloss 1404196646 tags OMC_DCPD and can see elevated noise on the "PI Monitor" dropdown on the website too, maybe peaks at 15 and 30kHz.
Edit2: There are some elevated peaks at many frequencies before a lockloss I chose to look at, but nothing alarming enough. The largest peak change is something at 3619 Hz, which could be a red herring or aliased from a much higher frequency, but I don't know what that peak is.
State of H1: Observing at 157Mpc, locked for 6.5 hours.
Quiet shift so far except for another errant Picket Fence trigger to EQ mode just like ones seen last night (alog78404) at 02:42 UTC (tagging SEI).
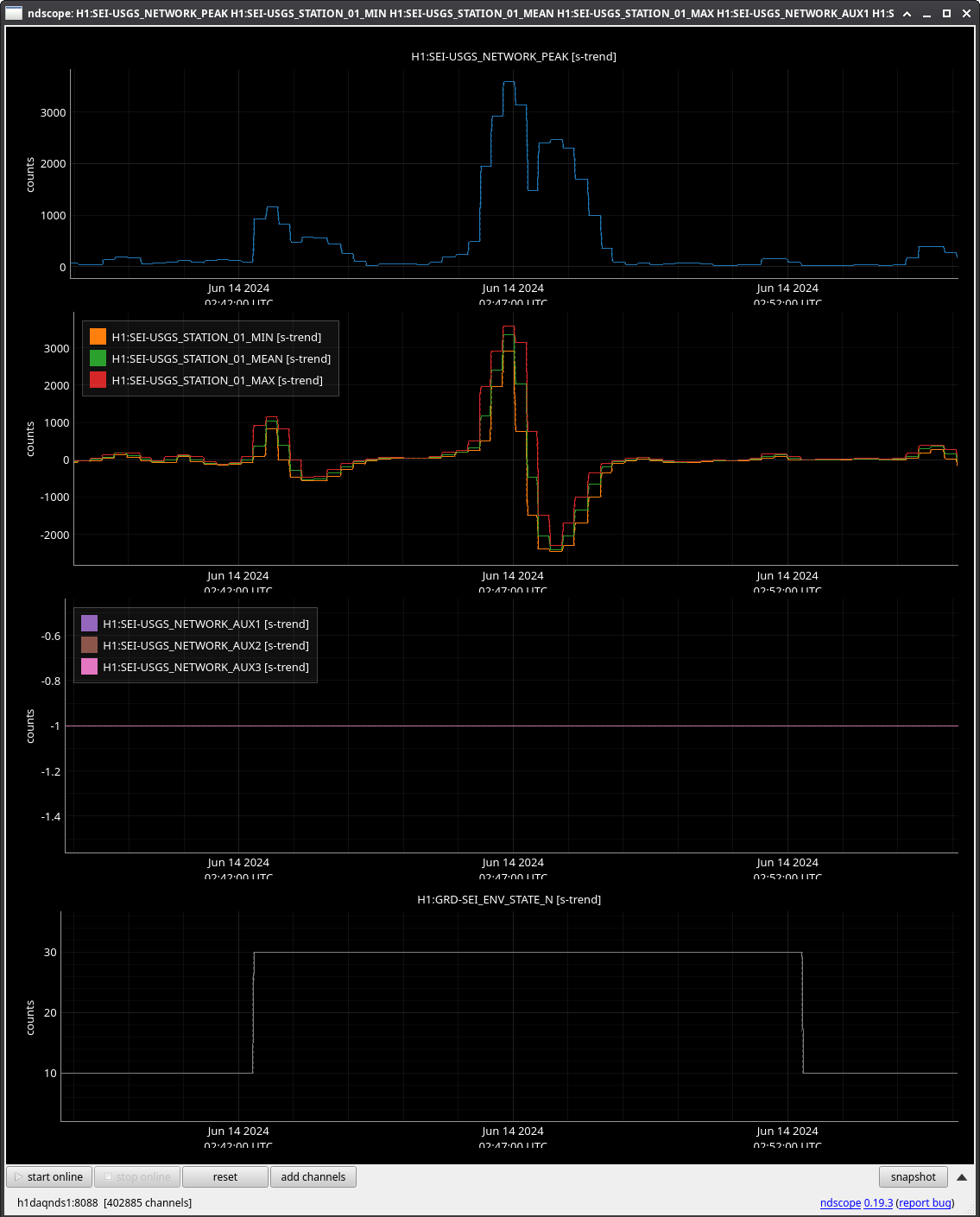
That's about two triggers in a short time. If the false triggers are an issue, we should consider triggering on picket fence only if there's a Seismon alert.
The picket fence-only transition was commented out last weekend on the 15th by Oli. We now will only transition on picket fence signals if there is a live seismon notificaition.
Thanks Jim,
I'm back from my vacation and will resume work on the picket fence to see if we can fix these errant triggers this summer.

02:57 UTC Observing
Seen by EX L3 first, and it looks to oscillate out of control almost? DARM gets a lot of quick scratchy noise right before it drops out