It seems earthquakes causing similar magnitudes of movement on-site may or may not cause lockloss. Why is this happening? Should expect to always or never cause lockloss for similar events. One suspicion is that common or differential motion might lend itself better to keeping or breaking lock.
- Lockloss is defined as H1:DRD-ISC_LOCK_STATE_N going to 0 (or near 0).
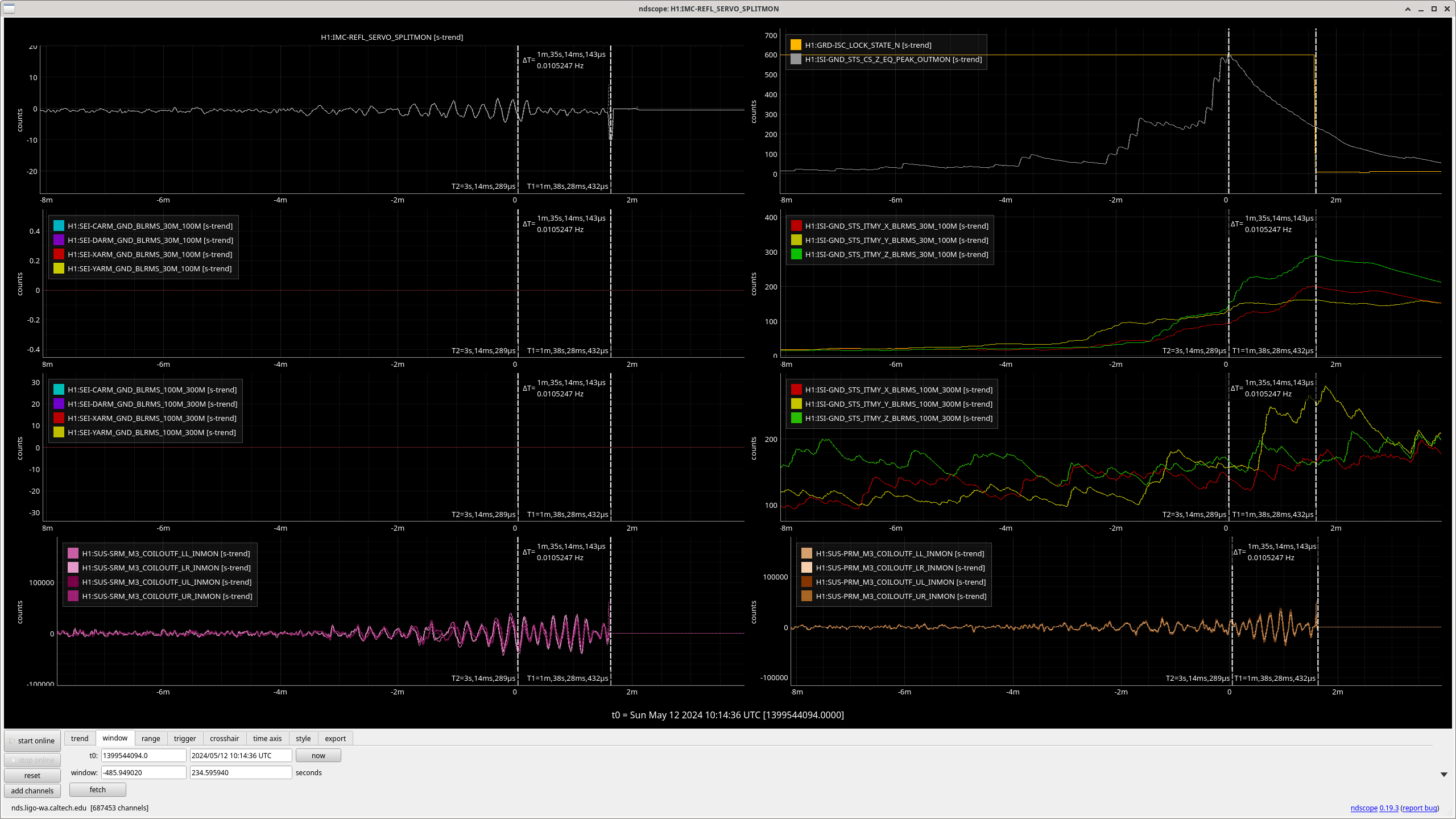
- I correlated H1:DRD-ISC_LOCK_STATE_N with H1:ISI-GND_STS_CS_Z_EQ_PEAK_OUTMON peaks between 500 and 2500 μm/s.
- I manually scrolled through the data from present to 2 May 2024 to find events.
- Manual, because 1) wanted to start with a small sample size and quickly see if there was a pattern, and 2) because I need to find events that caused loss, then go and find similarly sized events we kept lock.
- Channels I looked at include:
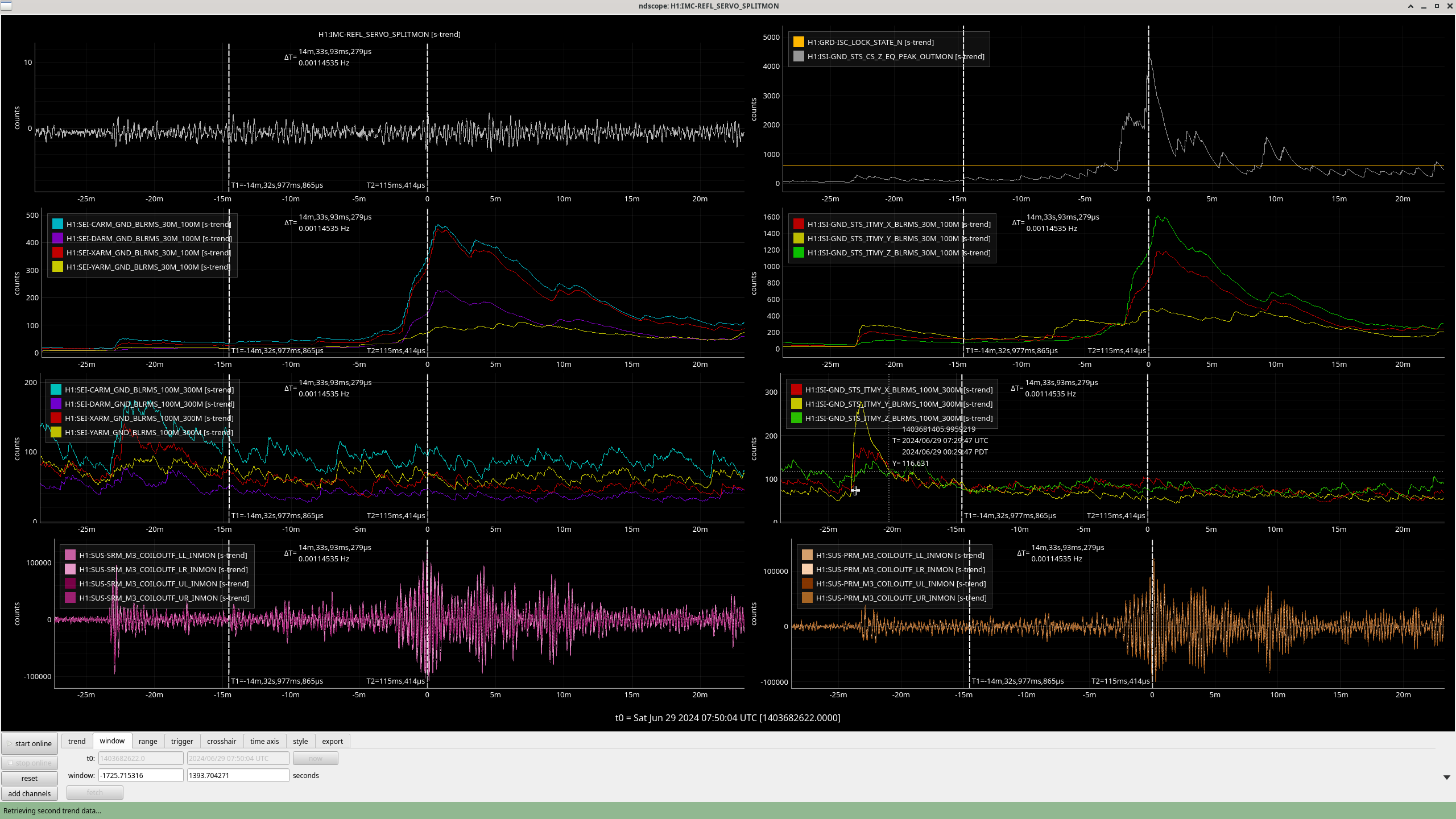
- IMC-REFL_SERVO_SPLITMON
- GRD-ISC_LOCK_STATE_N
- ISI-GND_STS_CS_Z_EQ_PEAK_OUTMON ("CS_PEAK")
- SEI-CARM_GNDBLRMS_30M_100M
- SEI-DARM_GNDBLRMS_30M_100M
- SEI-XARM_GNDBLRMS_30M_100M
- SEI-YARM_GNDBLRMS_30M_100M
- SEI-CARM_GNDBLRMS_100M_300M
- SEI-DARM_GNDBLRMS_100M_300M
- SEI-XARM_GNDBLRMS_100M_300M
- SEI-YARM_GNDBLRMS_100M_300M
- ISI-GND_STS_ITMY_X_BLRMS_30M_100M
- ISI-GND_STS_ITMY_Y_BLRMS_30M_100M
- ISI-GND_STS_ITMY_Z_BLRMS_30M_100M
- ISI-GND_STS_ITMY_X_BLRMS_100M_300M
- ISI-GND_STS_ITMY_Y_BLRMS_100M_300M
- ISI-GND_STS_ITMY_Z_BLRMS_100M_300M
- SUS-SRM_M3_COILOUTF_LL_INMON
- SUS-SRM_M3_COILOUTF_LR_INMON
- SUS-SRM_M3_COILOUTF_UL_INMON
- SUS-SRM_M3_COILOUTF_UR_INMON
- SUS-PRM_M3_COILOUTF_LL_INMON
- SUS-PRM_M3_COILOUTF_LR_INMON
- SUS-PRM_M3_COILOUTF_UL_INMON
- SUS-PRM_M3_COILOUTF_UR_INMON
- ndscope template saved as neil_eq_temp2.yaml
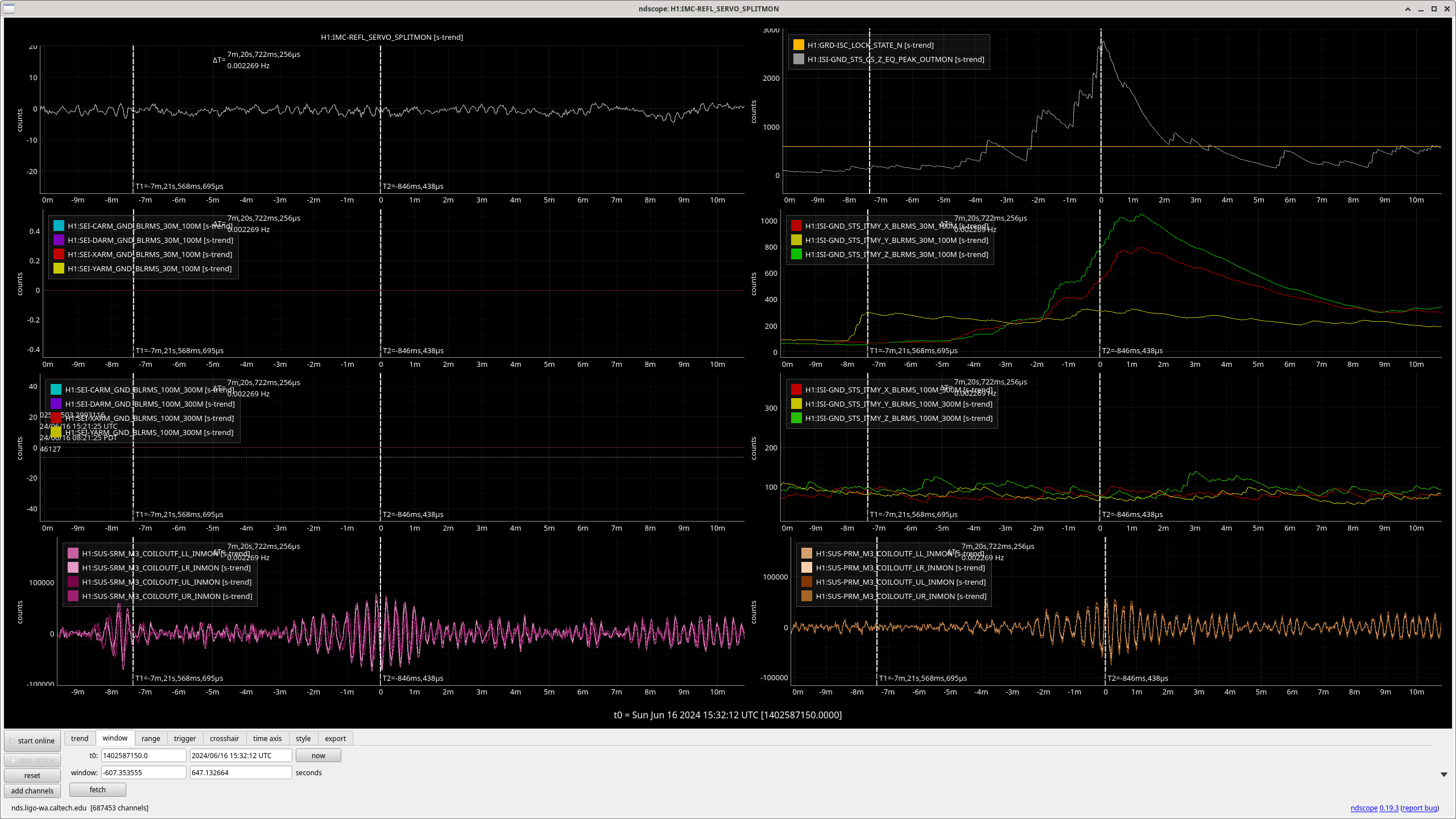
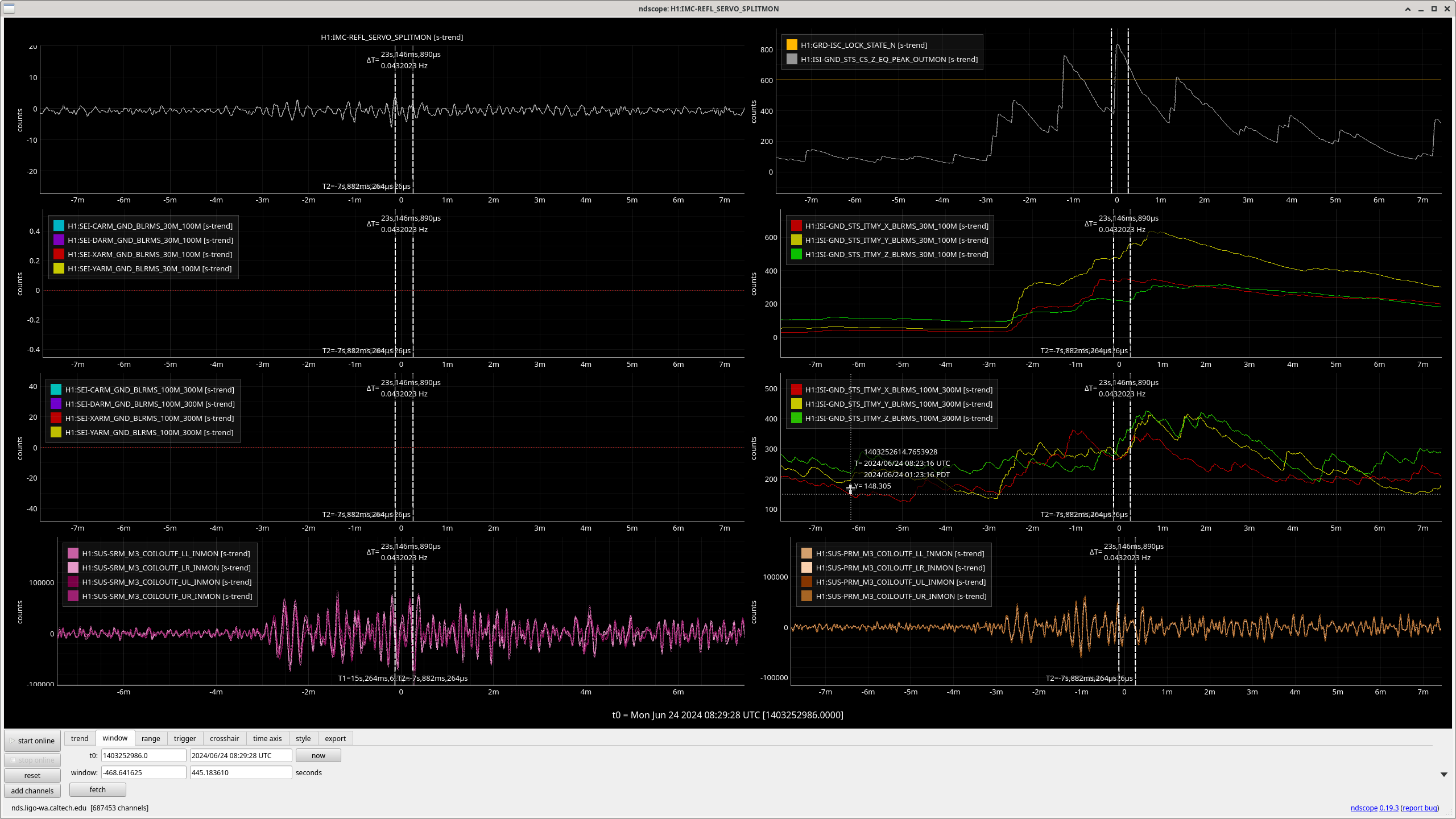
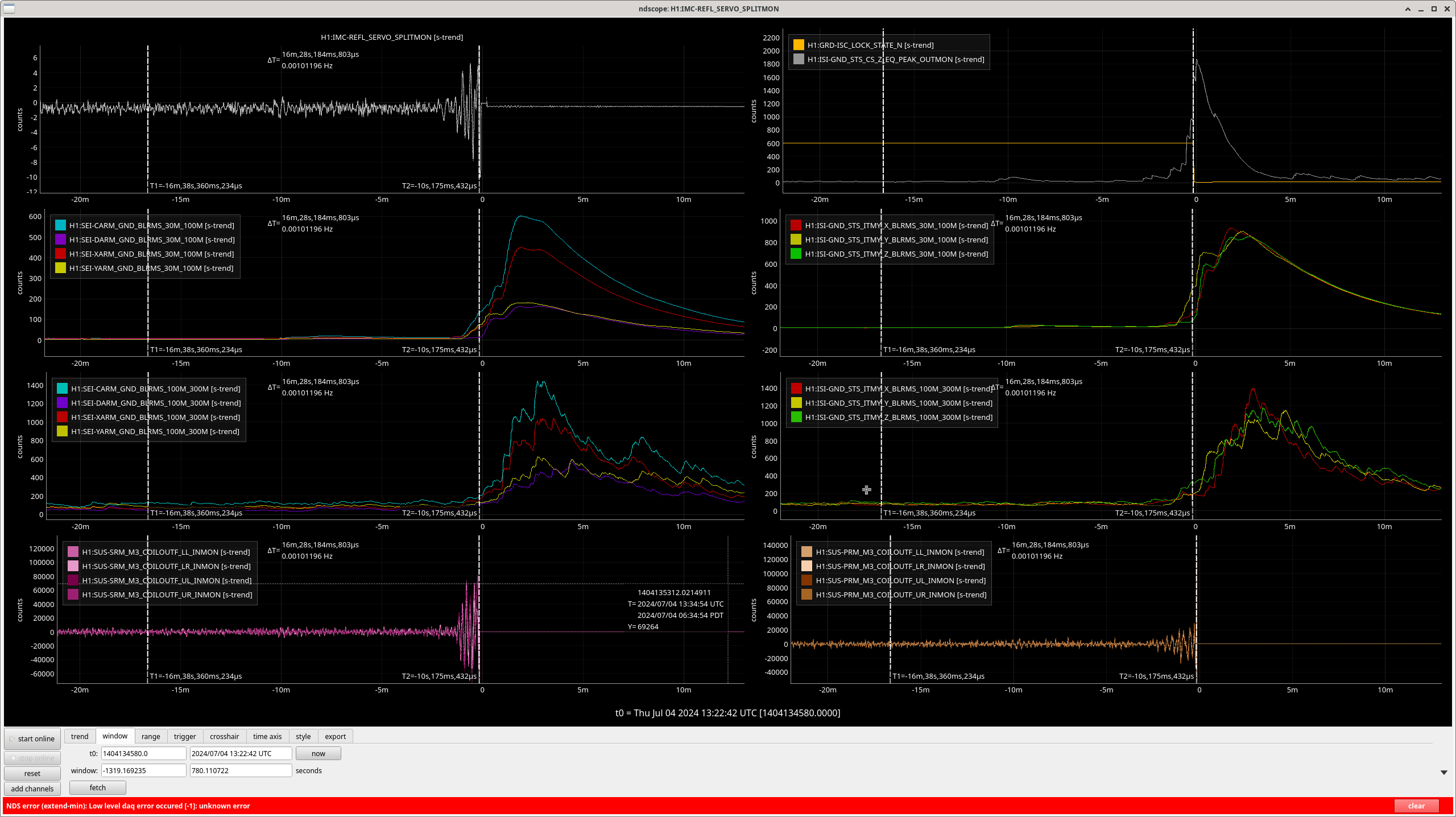
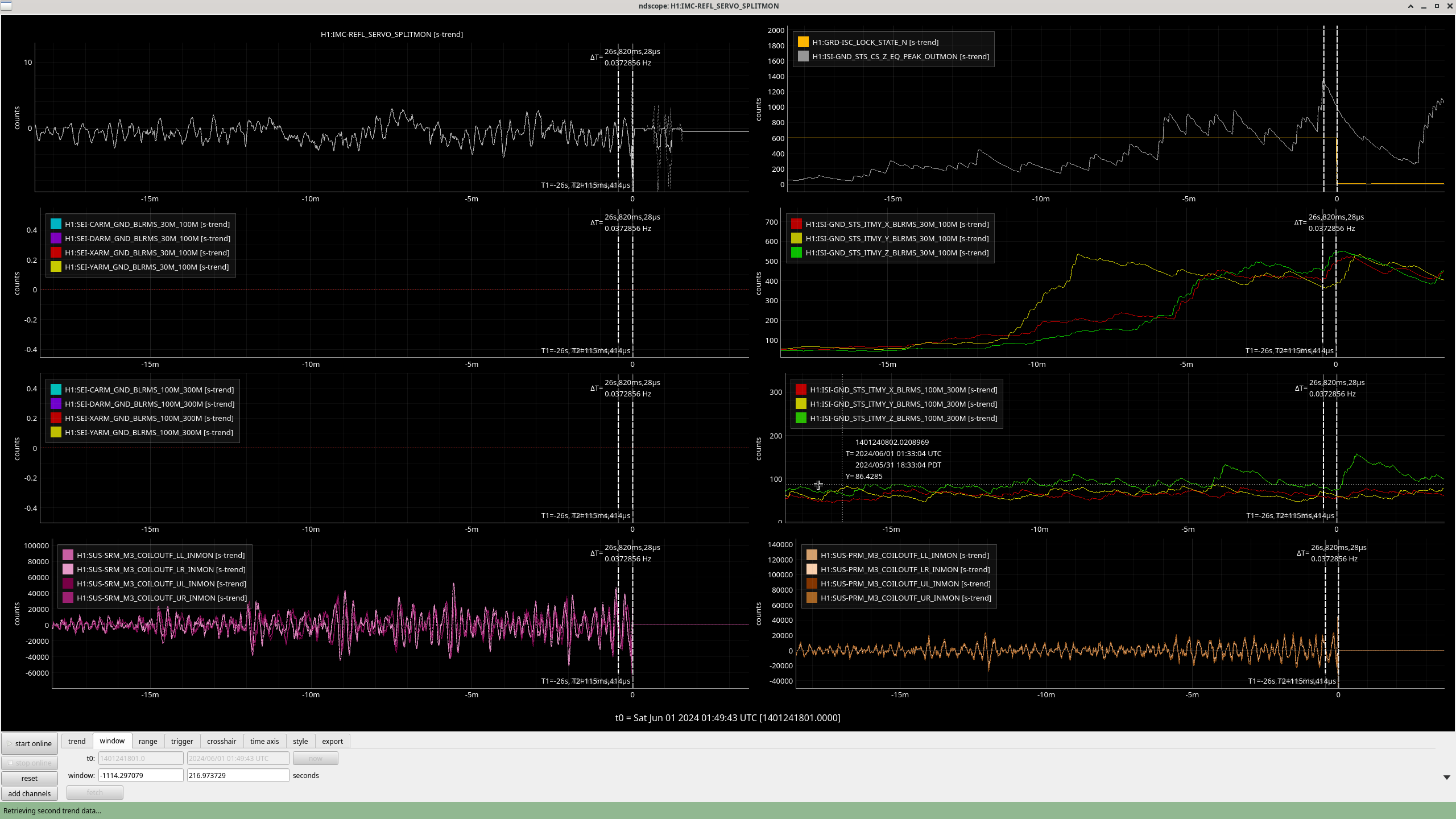
- 26 events; 14 lockloss, 12 locked (3 or 4 lockloss event may have non-seismic causes)
- After, usiing CS_PEAK to find the events, I, so far, used the ISI channels to analyse the events.
- The SEI channels were created last week (only 2 events captured in these channels, so far).
- Conclusions:
- There are 6, CS_PEAK events above 1,000 μm/s in which we *lost* lock;
- In SEI 30M-100M
- 4 have z-axis dominant motion with no motion or strong z-motion or no motion in SEI 100M-300M
- 2 have y-axis dominated motion with a lot of activity in SEI 100M-300M and y-motion dominating some of the time.
- There are 6, CS_PEAK events above 1,000 μm/s in which we *kept* lock;
- In SEI 30M-100M
- 5 have z-axis dominant motion with only general noise in SEI 100M-300M
- 1 has z-axis dominant noise near the peak in CS_PEAK and strong y-axis domaniated motion starting 4 min prior to the CS_PEAK peak; it too only has general noise in SEI 100M-300M. This x- or y-motion which starts about 4 min before the peak in CS_PEAK has been observed in 5 events -- Love waves precede Rayleigh waves, could be Love waves?
- All events below 1000 μm/s which lose lock seem to have a dominant y-motion in either/both SEI 30M-100M / 100M-300M. However, the sample size is not large enough to convince me that shear motion is what is causing lockloss. But it is large enough to convince me to find more events and verify. (Some plots attached.)


{kind=link}
There are several interesting things at around 30Hz (and around 40Hz) in this BRUCO, which might all be related to some ground motion or accoustic noise witness.
LVEAFLOOR accelerometer
several channels related to HAM2 motion like MASTER_H2_DRIVE. Around 38-40 Hz BRUCO picks out lots of HAM2 channels, and seems to preffer HAM2 over any other chamber. It might be worth doing some HAM2 injections.
This time that Camilla chose was after the PSL alignment shift, but before we moved the beam on PR2 last Friday.