A PCAL EndX Station Measurement was done on April, the PCAL team(
Dripta B. & Tony S.) went to EndX with Working Standard Hanford aka WSH(PS4) and took an End station measurements.
The EndX Station Measurement was carried out according to the procedure outlined in Document LIGO-T1500062-v15, Pcal End Station Power Sensor Responsivity Ratio Measurements: Procedures and Log.
Measurement Log
First thing they should have done was take a picture of the beam spot before anything is touched!
Martel:
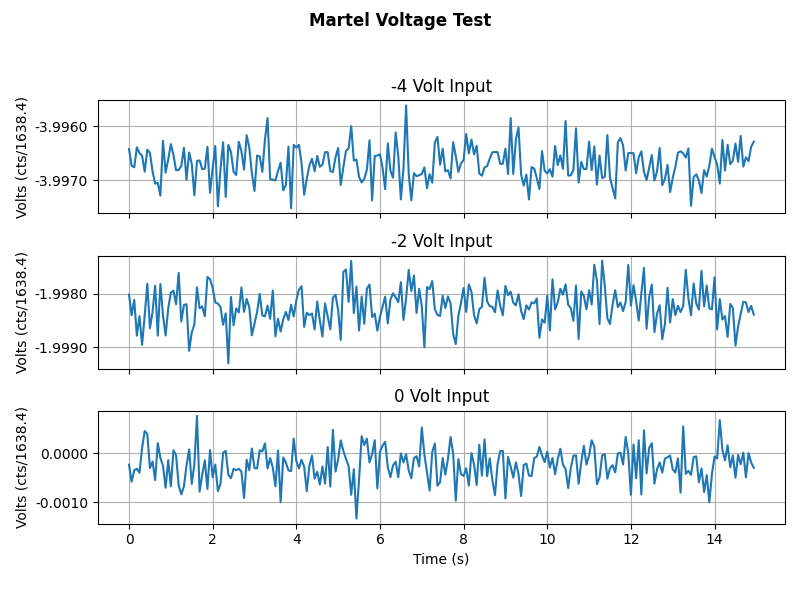
Martel Voltage source applies voltage into the PCAL Chassis's Input 1 channel. We record the GPStimes that a -4.000V, -2.000V anhttps://alog.ligo-wa.caltech.edu/aLOG/uploads/77467_20240427213103_SPot.jpgd a 0.000V voltage was applied to the Channel. This can be seen in Martel_Voltage_Test.png . We also did a measurement of the Martel's voltages in the PCAL lab to calculate the ADC conversion factor, which is included on the above document.
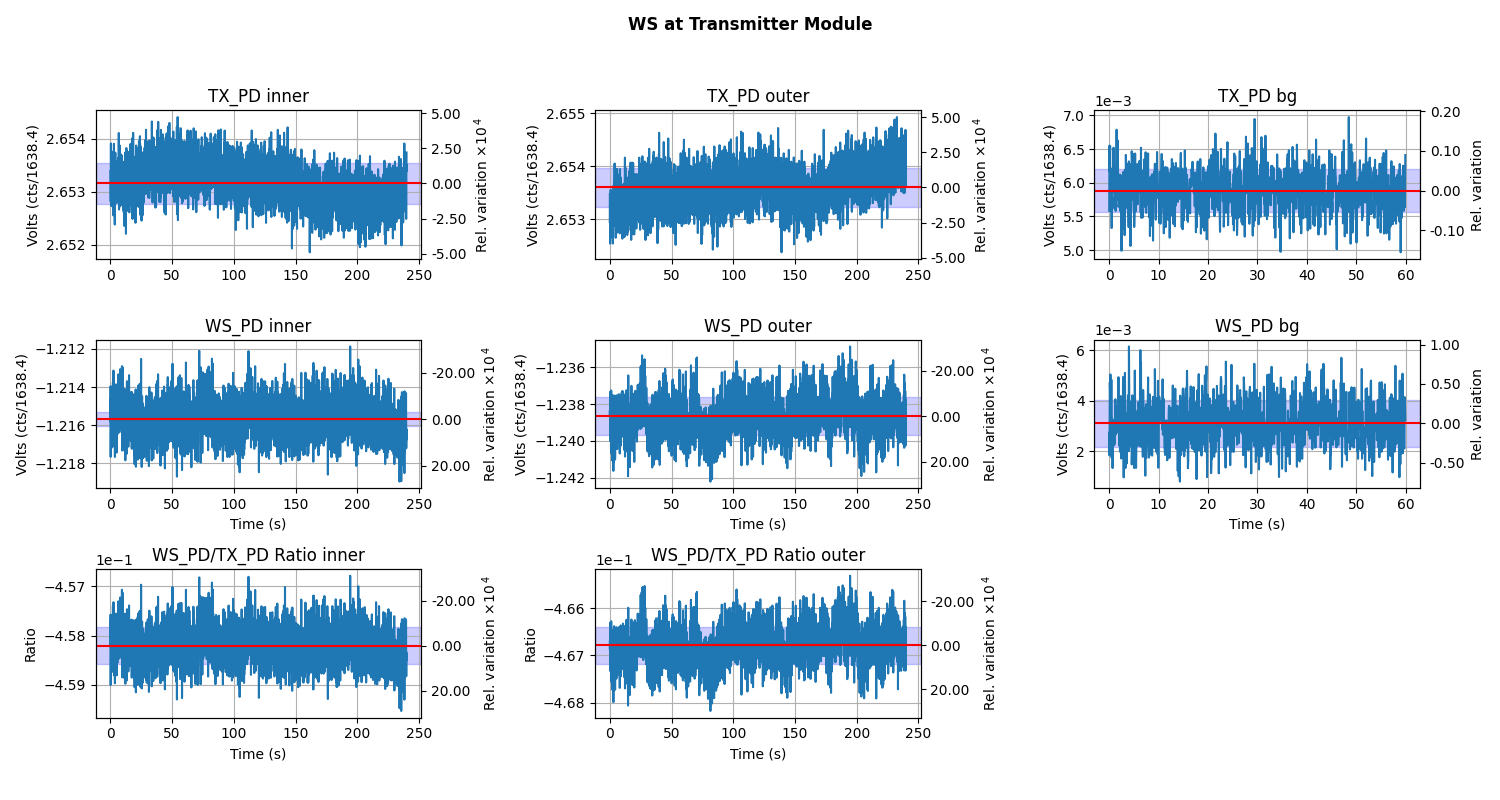
Plots while the Working Standard(PS4) is in the Transmitter Module during Inner beam being blocked, then the outer beam being block, followed by the background measurment: WS_at_TX.png.
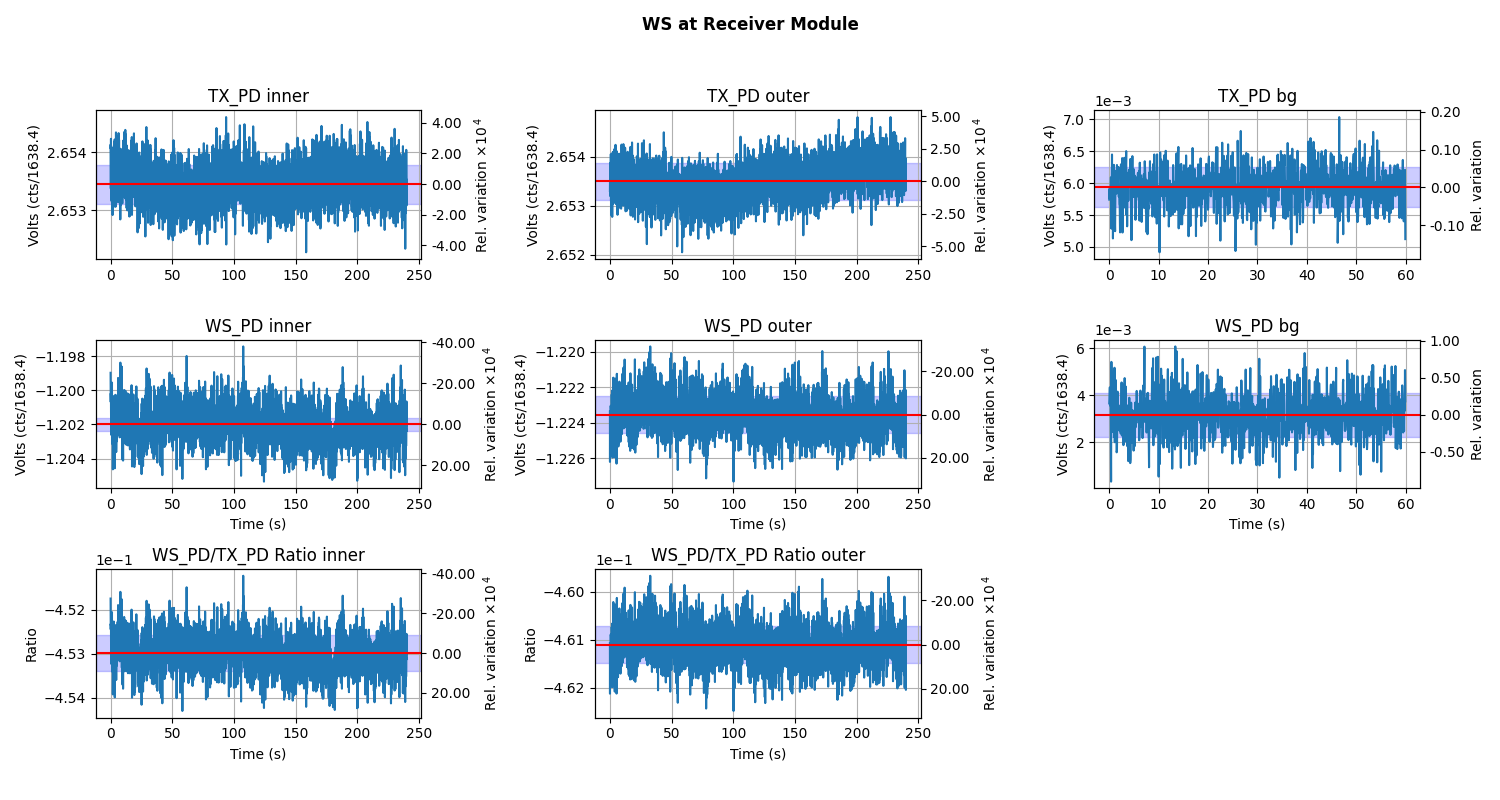
The Inner, outer, and background measurement while WS in the Receiver Module: WS_at_RX.png.
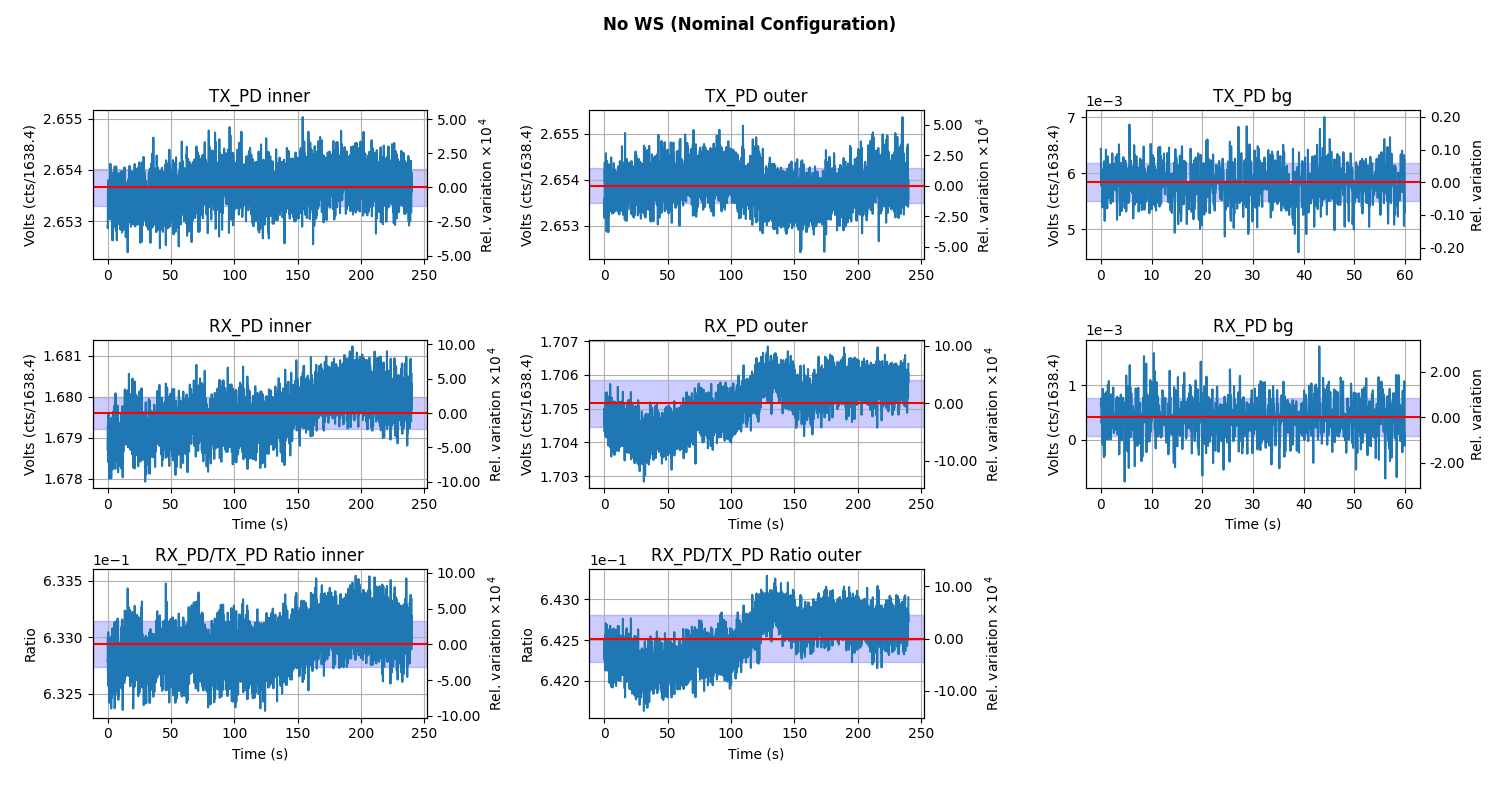
The Inner, outer, and background measurement while RX Sphere is in the RX enclosure, which is our nominal set up without the WS in the beam path at all.: TX_RX.png.
The last picture is of the Beam spots after we had finished the measurement.
All of this data is then used to generate LHO_EndX_PD_ReportV2.pdf**** which is attached, and a work in progress in the form of a living document.
All of this data and Analysis has been commited to the SVN :
https://svn.ligo.caltech.edu/svn/aligocalibration/trunk/Projects/PhotonCalibrator/measurements/LHO_EndX/
PCAL Lab Responsivity Ratio Measurement:
A WSH/GSHL (PS4/PS5)FrontBack Responsivity Ratio Measurement was ran, analyzed, and pushed to the SVN.
The analysis of this measurement produces 4 PDF files which we use to vet the data for problems.
raw_voltages.pdf
avg_voltages.pdf
raw_ratios.pdf
avg_ratios.pdf
Obligitory BackFront PS4/PS5 Responsivity Ratio:
PCAL Lab Responsivity Ratio Measurement:
A WSH/GSHL (PS4/PS5)BF Responsivity Ratio measurement was ran, analyzed, and pushed to the SVN.
The analysis of this measurement produces 4 PDF files which we use to vet the data for problems.
AlphaTrends
raw_voltages2.pdf
avg_voltages2.pdf
raw_ratios2.pdf
avg_ratios2.pdf
This adventure has been brought to you by Dripta B. & Francisco L.
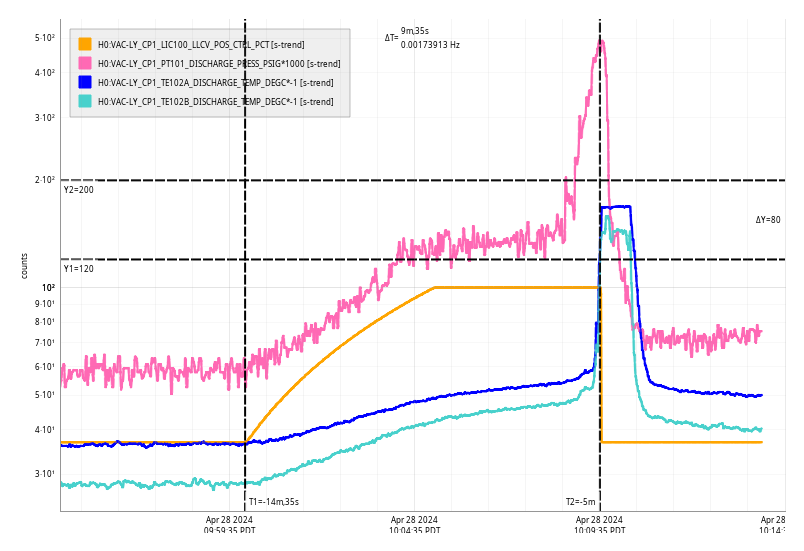
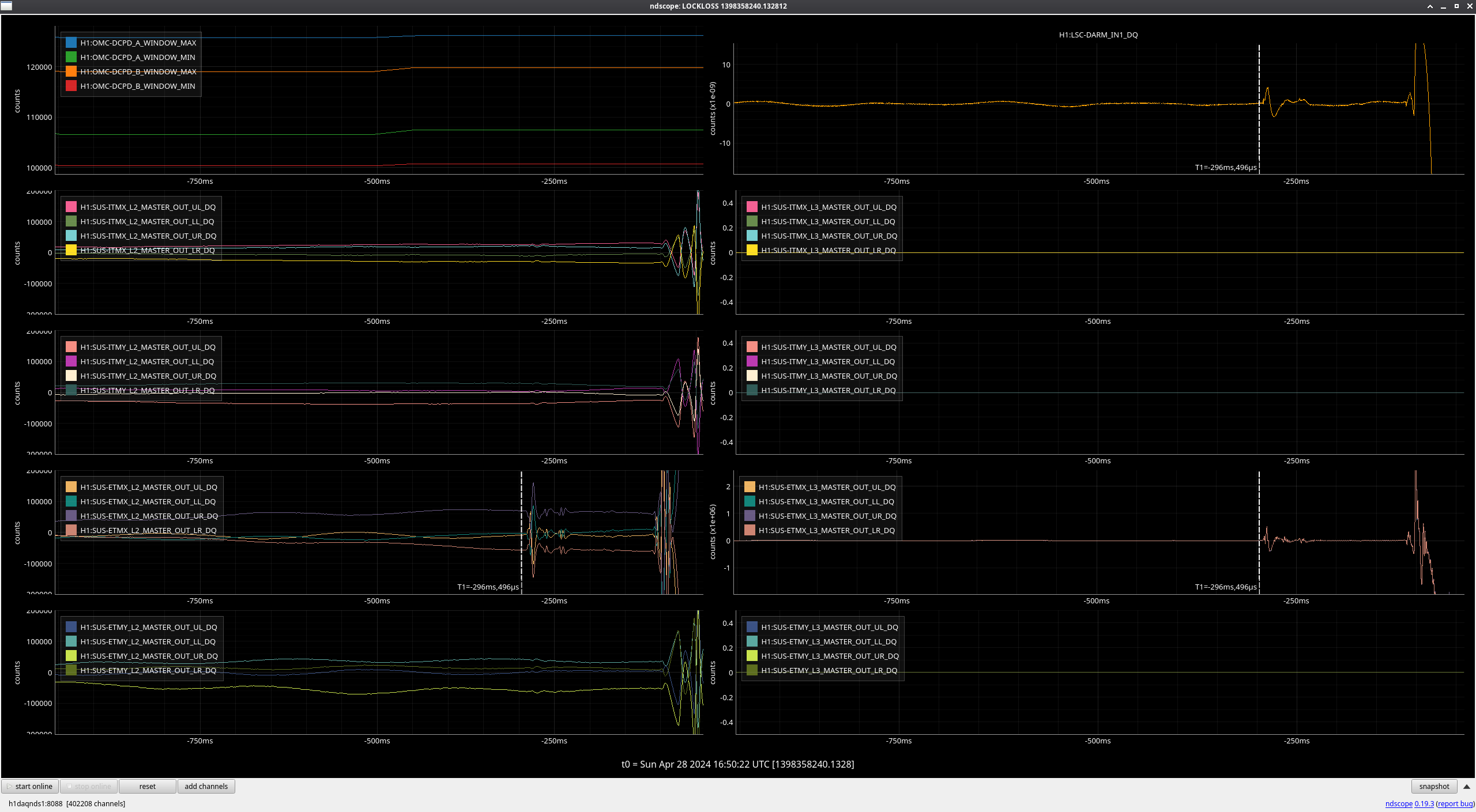
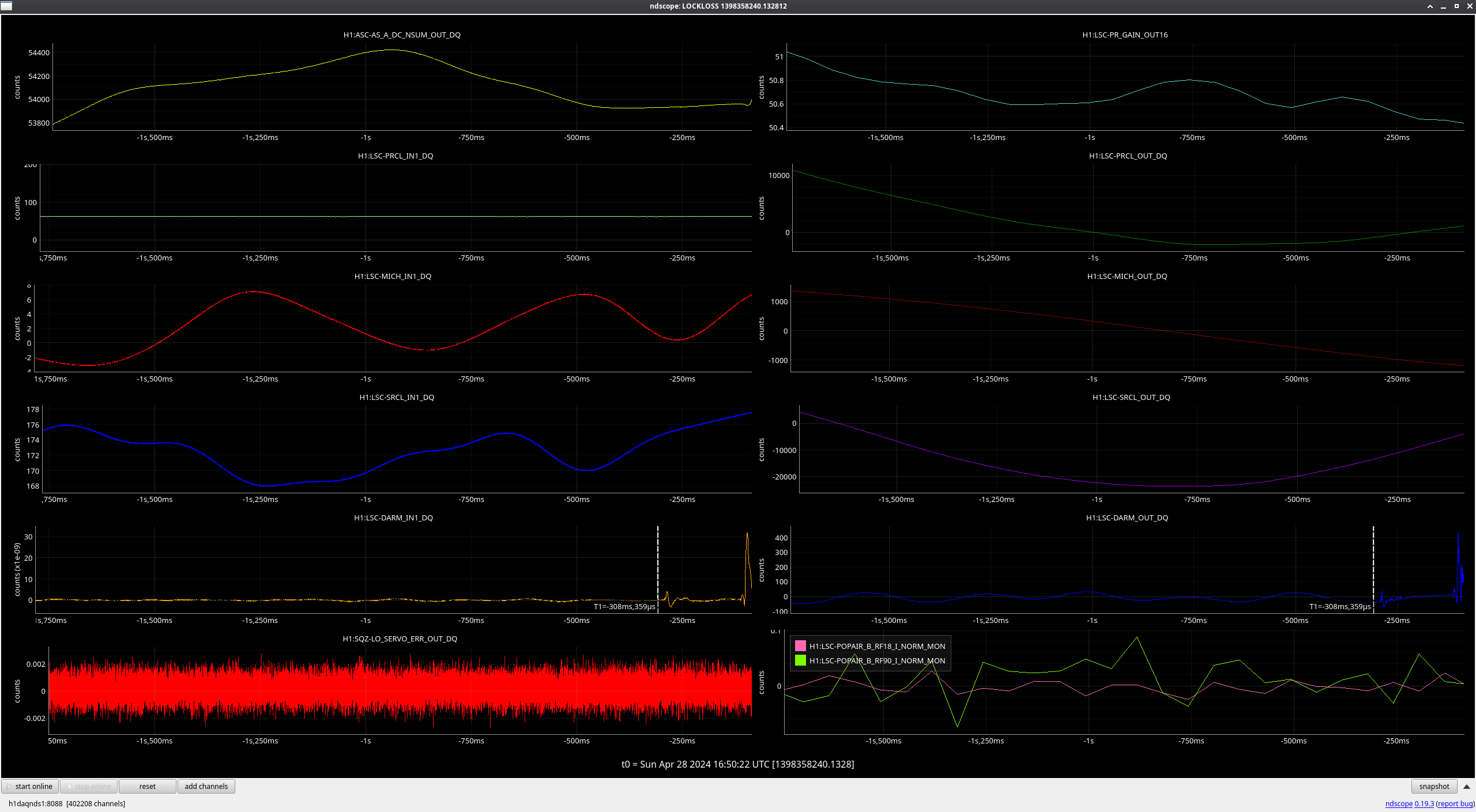
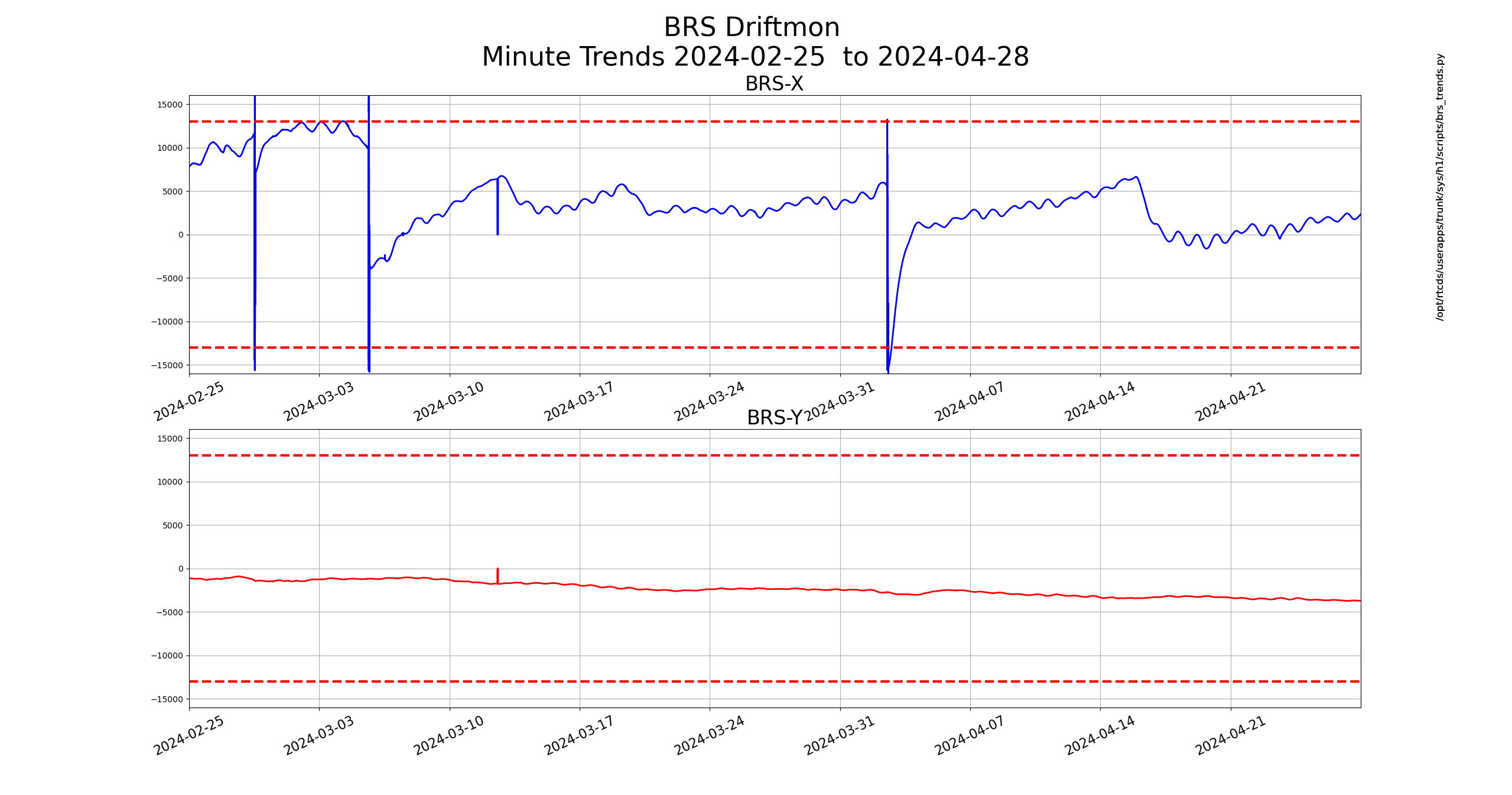



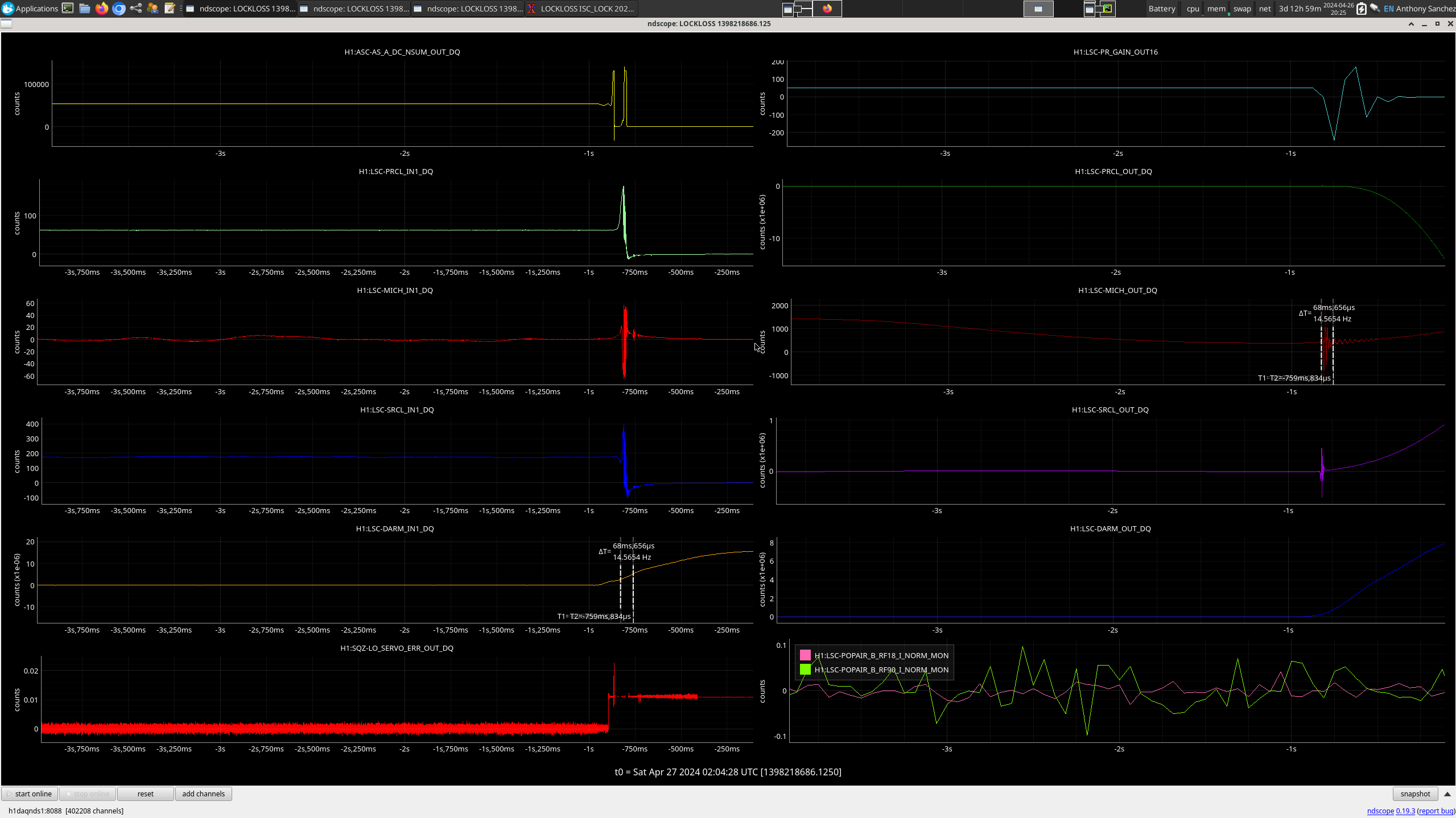
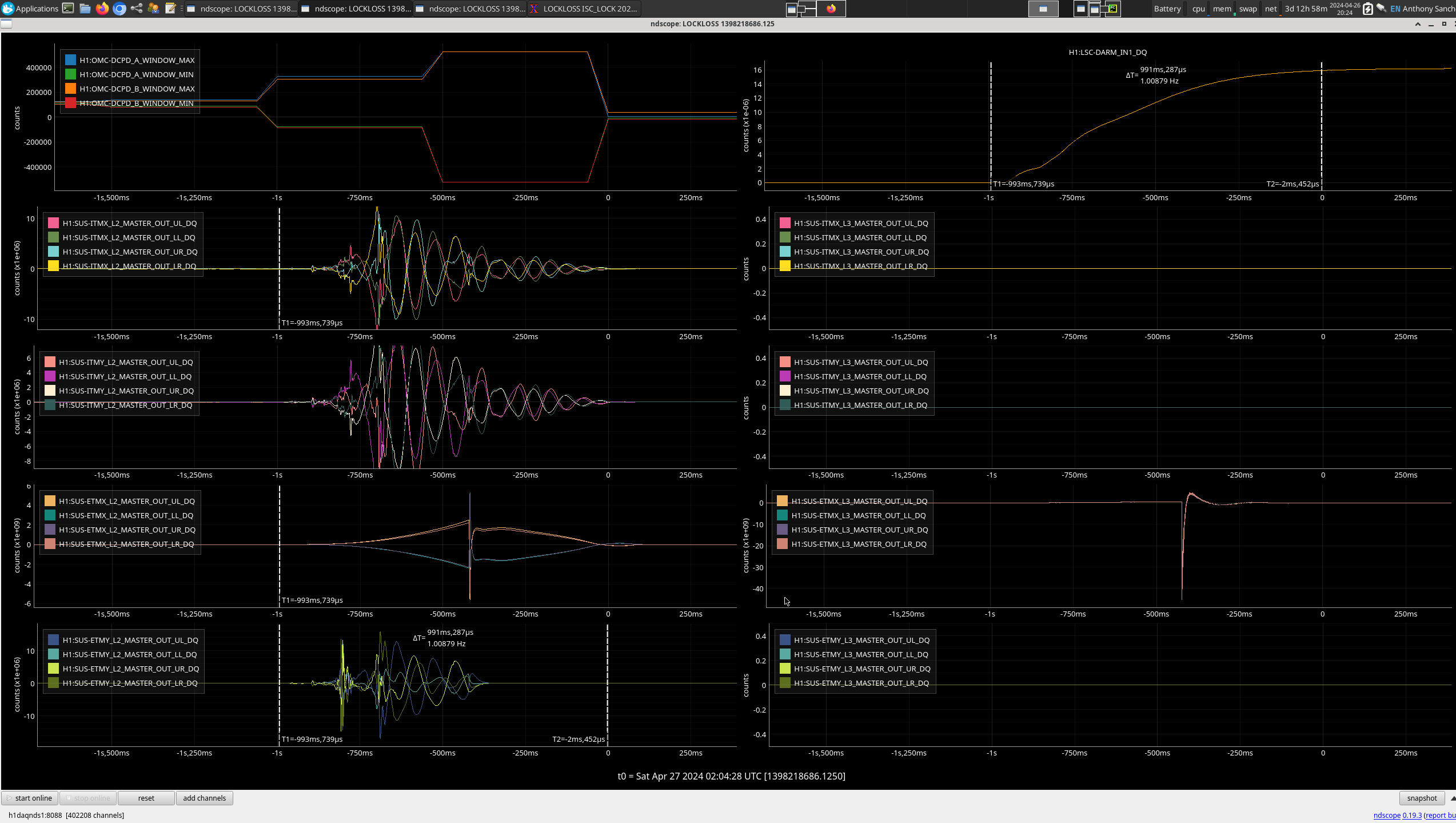
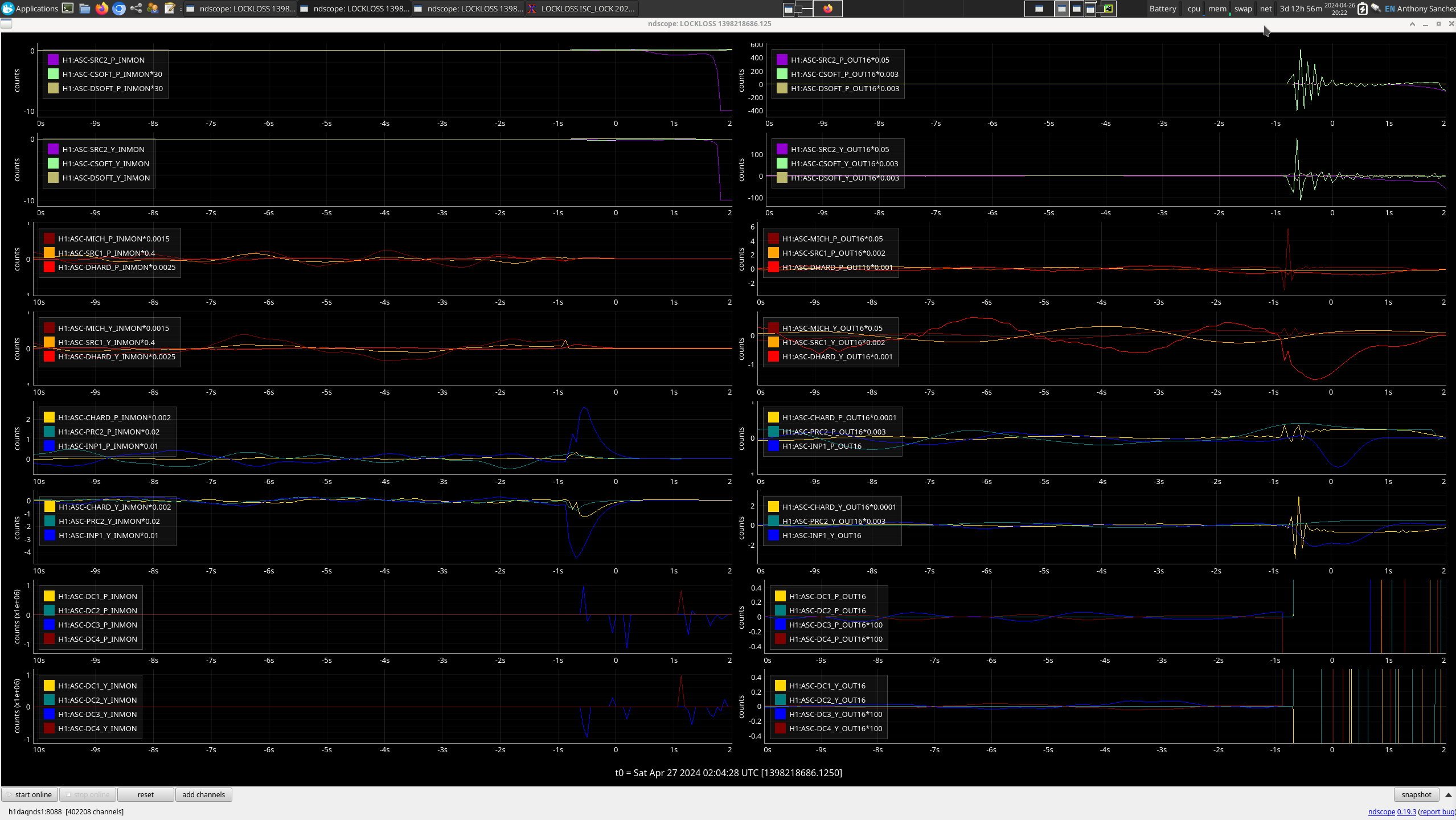
FRS31079
Thank you for this summary. I will go dig in the code to see what is happening.
On first glance: the array of data should never be empty on an update, but somehow it is happening some times. I will add a failsafe (or an assert) so that the code can handle this exception and hopefully be more robust.