anthony.sanchez@LIGO.ORG - posted 23:48, Thursday 25 April 2024 (77434)
Hepi Pump Trends - Monthly
Images attached to this report
TITLE: 04/26 Eve Shift: 23:00-07:00 UTC (16:00-00:00 PST), all times posted in UTC
STATE of H1: Observing at 148Mpc
CURRENT ENVIRONMENT:
SEI_ENV state: CALM
Wind: 23mph Gusts, 20mph 5min avg
Primary useism: 0.03 μm/s
Secondary useism: 0.15 μm/s
QUICK SUMMARY:
Quite night up until we had SuperEvent S240426s Candidate at 3:15 UTC
4:57 UTC Dropped out of Observing due to the Squeezer getting unlocked. Ground motion was low but the wind has been slightly elevated.
5:00 UTC Back into Observing after the SQZ subsystem relocked it's self.
Betsy, TJ, Rahul
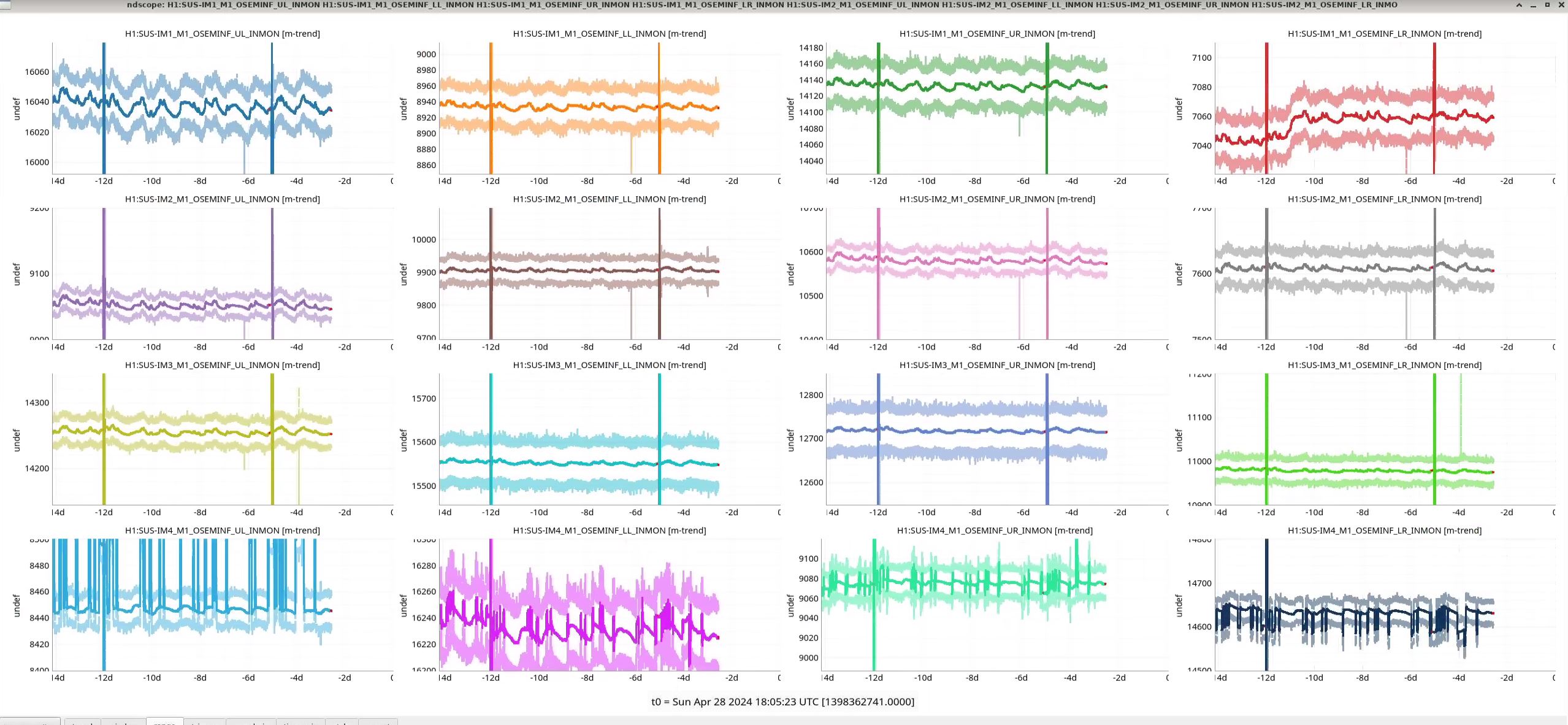
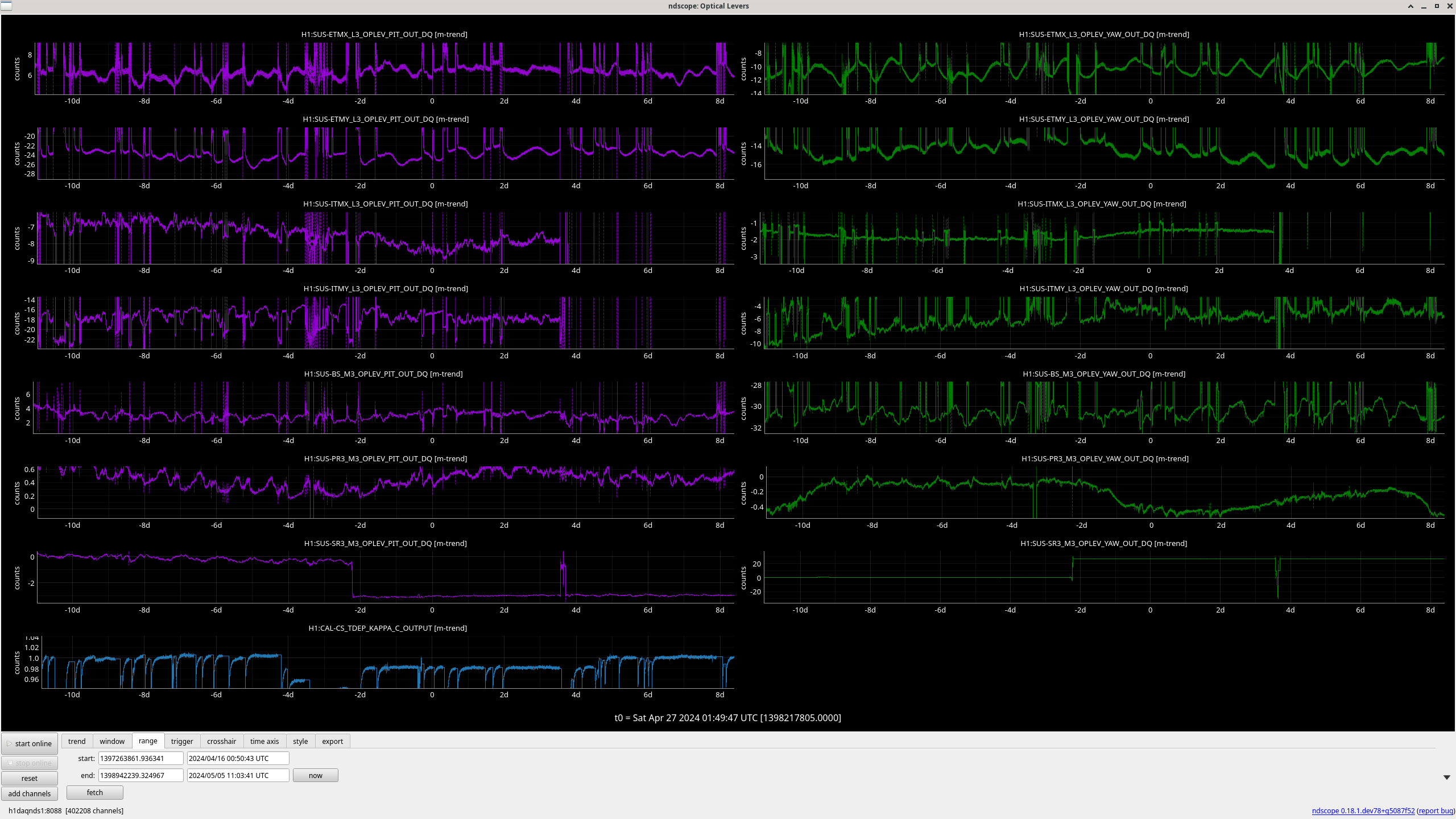
This afternoon I trended the inmons of IM1-4 to look for any signs of suspension drifting after they (IM1-2) were moved (and then reverted to nominal) this Tuesday (LHO alog 77347). Attached below is the ndscope plot for the last 2 weeks and they look fine to me (IM1 LR and UL bosems showed movement but that was 12 days ago - possibly slider changes - see J Kissel's alog 77211).
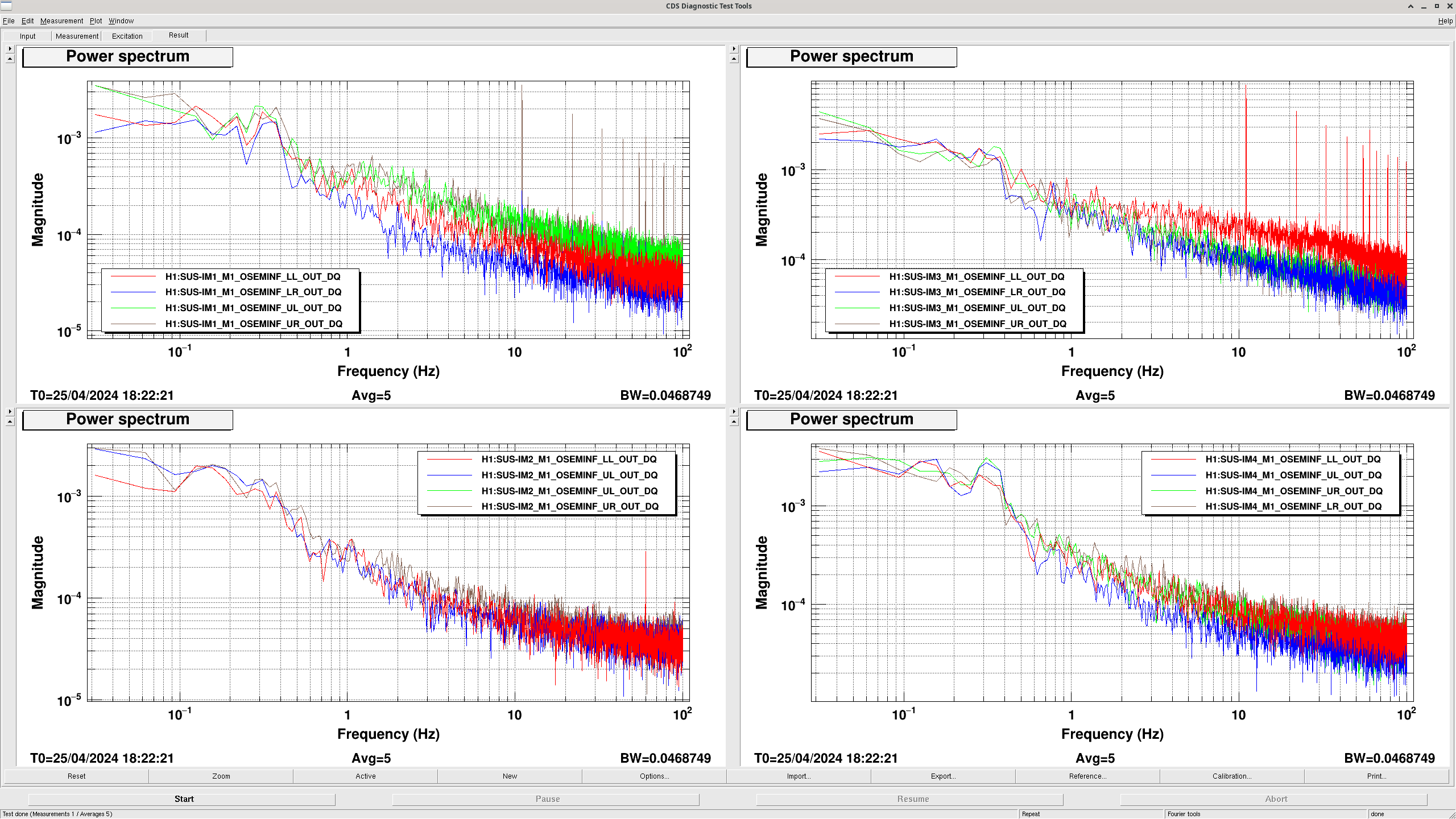
I also took their osem spectra and they look fine.
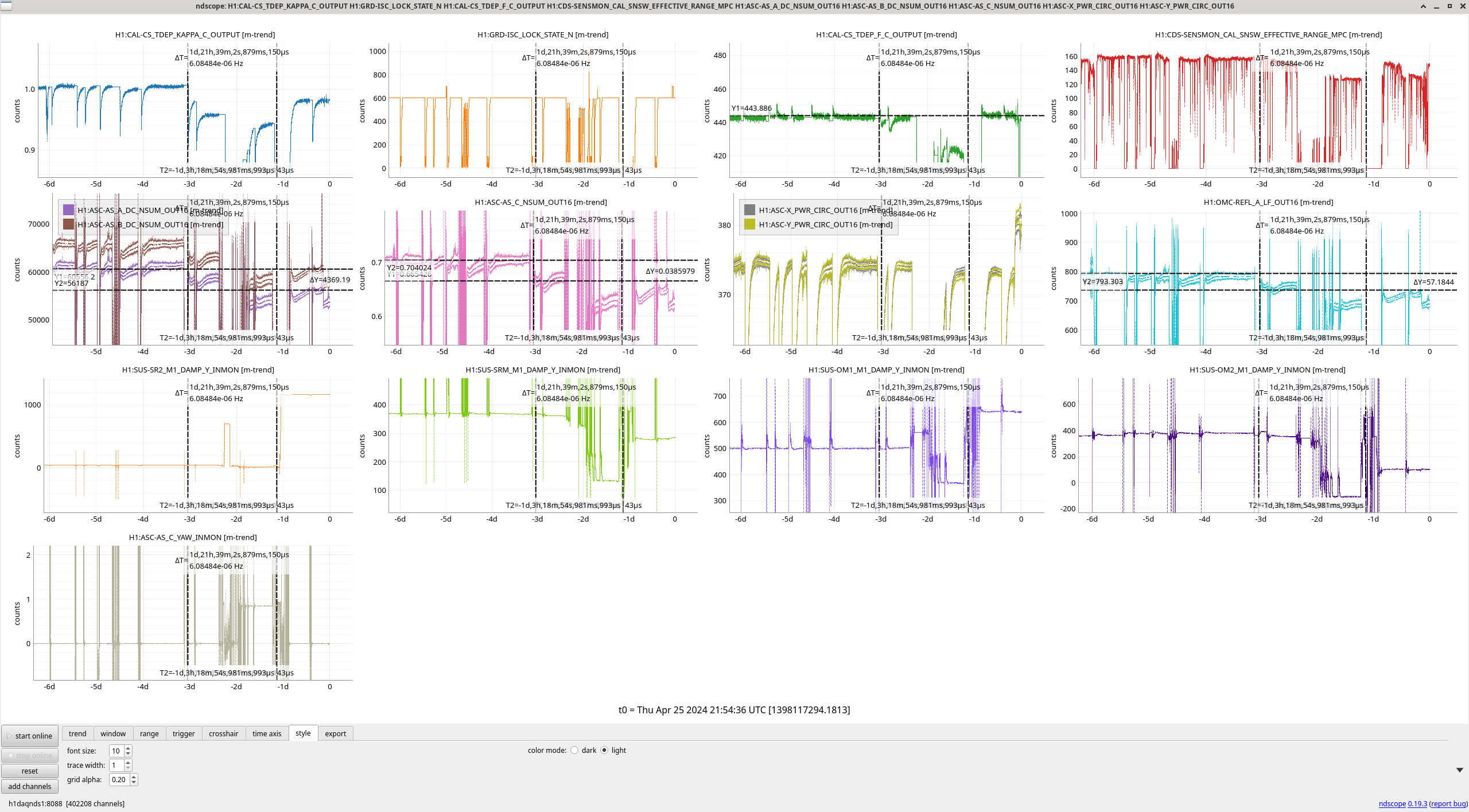
In the observing stretch that started Monday around 8 pm, there was a drop in optical gain (by 4%), and power at AS port PDs (4% drop in AS_A sum, AS_B sum, AS_C sum, and OMC REFL). There not at that time any change in circulating power in the arms, PRG, coupled cavity pole, or alignment of suspensions (shown are SR2, SRM, OM1+2, but we have also looked at many other suspension, ISI and HEPI related channels for this time 77382 ). This time is shown by the first vertical cursor in the attachment.
We were unable to relock the interferometer after that Monday evening lock (a new lockloss type appeared early Tuesday morning, 77359), and after the maintence window we were uable to lock with difficulties powering up (77363) and an AS camera imagine that had lobes whenever the beam was well centered on AS_C. We locked that evening by adding large offsets to AS_C's set point, (77368). This is the cause of the large alignment shifts seen in the screenshot on Tuesday evening to Wed morning, which allowed us to lock the IFO but created a large scatter shelf and resulted in a lower coupled cavity pole, and lower optical gain, and we did not have much squeezing that night.
We do not think that Tuesday maintence activities are the cause of our problems, although some of the Tuesday work has been reverted (77350 77369).
Yesterday we spent much of the day with SRY locked, single bounce or using the squeezer beam reflected off SRM to investigate our AS port alignment. 77392, We are able to recover the same throughput of a single bounce beam to HAM6 by moving the alignment of SR2 + SR3 by a huge amount 77388, which also produced a round looking beam on the AS camera. We haven't since tried to explore this aperture, to see if we could have also recovered this thoughput with a pitch move, for example. We also saw that the squeezer beam does not arrive in HAM6 with a good transmission when injected with the alignment used previously, but that we could recover good transmission to HAM6 by moving ZM5 by 150-200 urad, in pitch or yaw. With this shift in SRC axis, and squeezer alignment we were able to relock and not have the large scattering issues we had Tuesday night.
Today's time was spent recovering from a seemingly unrelated problem in the SQZ racks, and some commissoning aimed at recovering our previous (165Mpc) sensitivity with this new alignment. This will continue during tomorow's commissoning time.
additional related information:
Adding some trends, which have otherwise been mentioned. The optiocal levers and top mass osems suggest that there hasn't been any shift in the PRC, Michelson, or arms. There was also not a shift in alignment of the SRC in the first low optical gain lock on the 22nd, that alignment didn't shift until the manual move of the SRC in the recovery effort.

Camilla notes that the OFI temperature controler had unusual behavoir in the Tuesday relocking attempts: 78399
comparisons of single bounce throughputs: 77441
TITLE: 04/25 Eve Shift: 23:00-07:00 UTC (16:00-00:00 PST), all times posted in UTC
STATE of H1: Observing at 146Mpc
OUTGOING OPERATOR: TJ
CURRENT ENVIRONMENT:
SEI_ENV state: CALM
Wind: 23mph Gusts, 15mph 5min avg
Primary useism: 0.04 μm/s
Secondary useism: 0.12 μm/s
QUICK SUMMARY:
H1 has been locked for 10 hours, and now Observing.
Were are expecting to stay locked through out the night.
TITLE: 04/25 Day Shift: 15:00-23:00 UTC (08:00-16:00 PST), all times posted in UTC
STATE of H1: Observing at 146Mpc
INCOMING OPERATOR: Tony
SHIFT SUMMARY: Commissioning most of the day to understand our squeezer and IFO issues from the last few days. We are basically back into the same place we were last night. Tomorrow there will be some more commissioning time to help tune us to this new IFO alignment.
LOG:
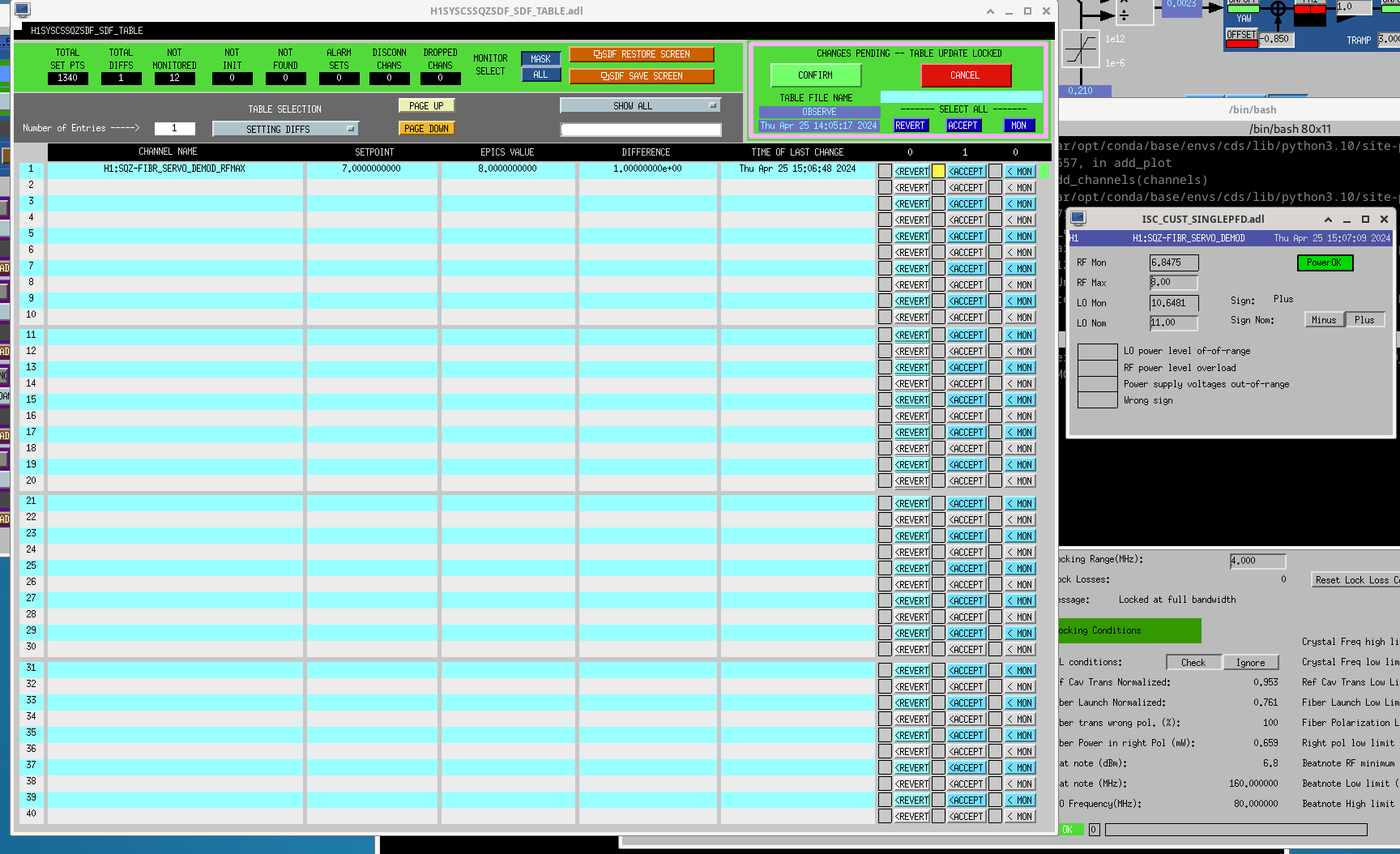
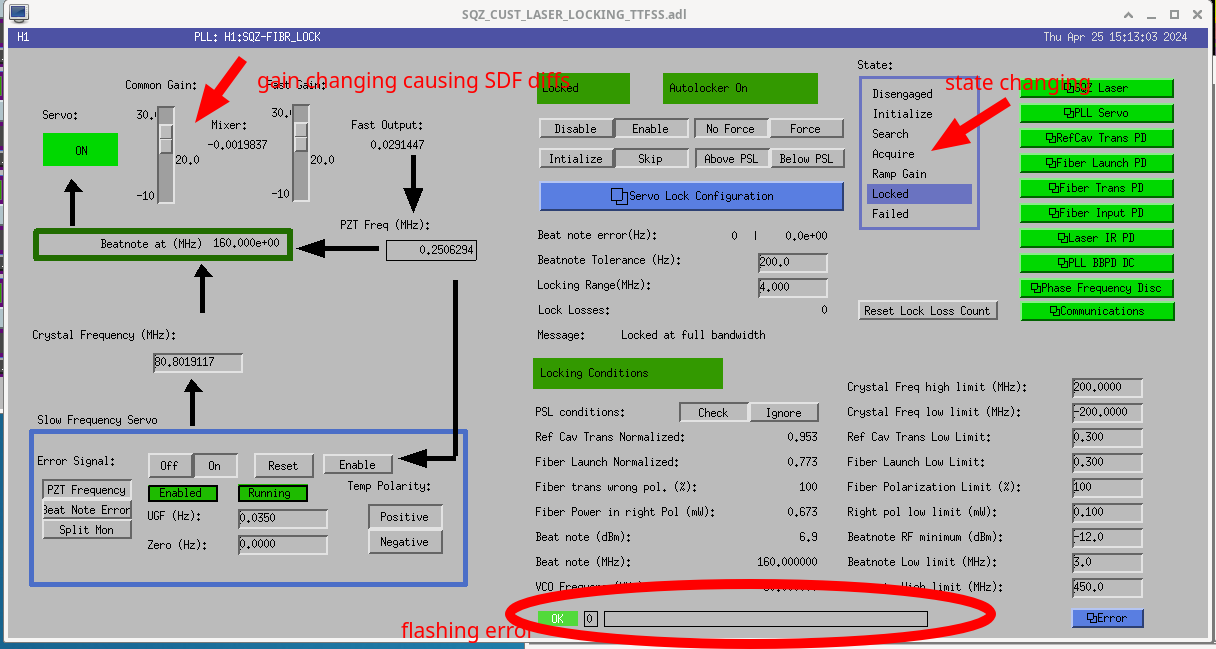
After replacement of the SQZ FSS beatnote chassis this morning, there is a little more RF power on the demod. There is an error message in the beckhoff logic for the TTFSS that was intended to identify times when the noise eater is oscillating. If the demod RF goes above RFMax the screen shows an error message that flashes extremely quickly (red circle on screenshot attached), the state machine will go back to Acquire, and the FSS servo board common gain will toggle between 17 and 20 dB, which is what causes the SDF to knock us out of observe.
We've increased RFmax for the demod so this shouldn't happen.
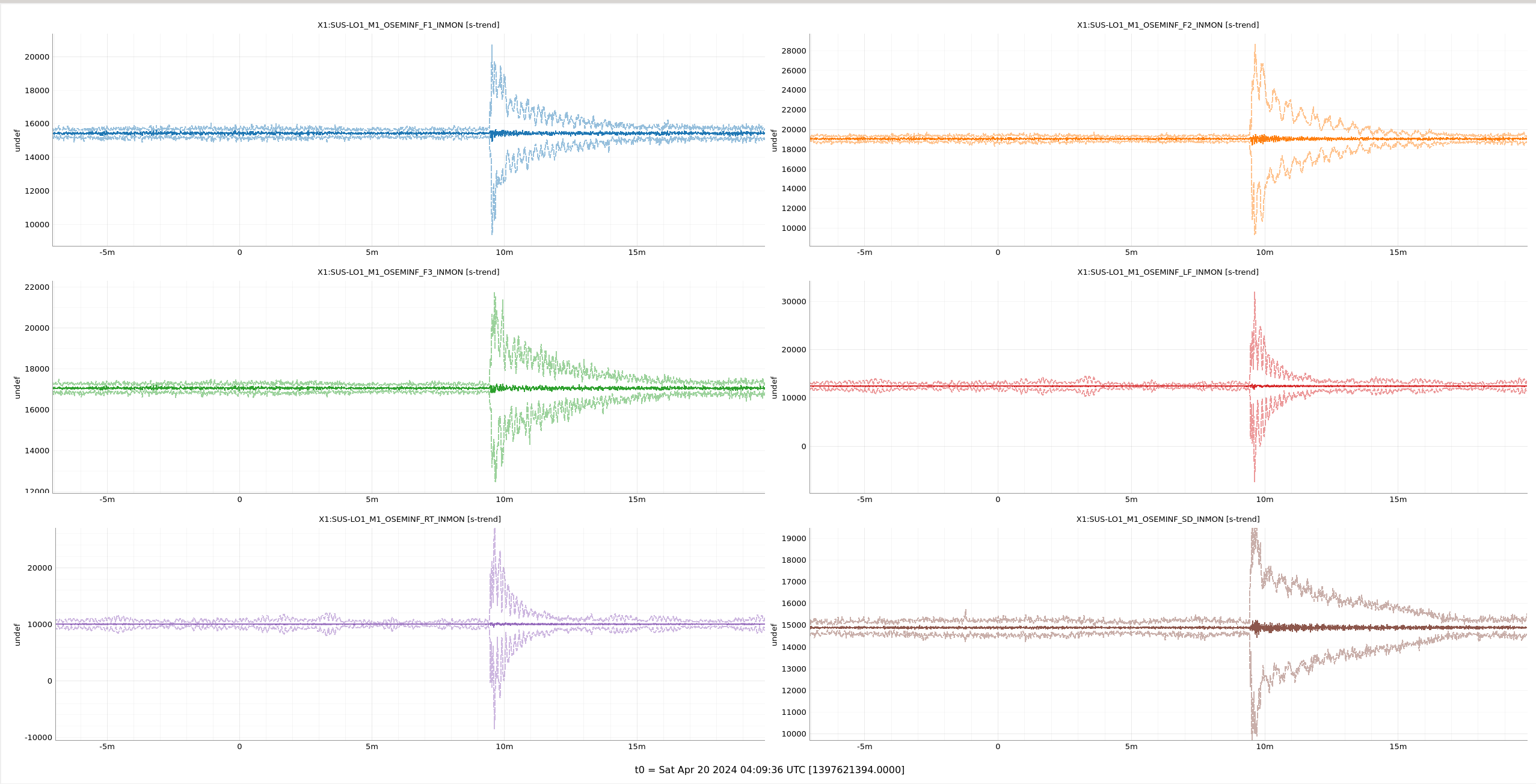
Rahul and I trended back the current HRTS build that we're testing this weeks' BOSEM channels (in the triples lab in the staging building) to see if it saw the in-town 2.8 earthquake from saturday. Sure enough it did as this suspension is very sensitive.
We took a little bit extra bit of time to tune our squeezing and take a few more measurements to understand our recent IFO woes, but we are now back to an observing state at 145Mpc.
Now that we've got some updated alignment and other configuration changes to the IFO this week, I wanted to check in on the jitter cleaning. It looks like it's still working fine.
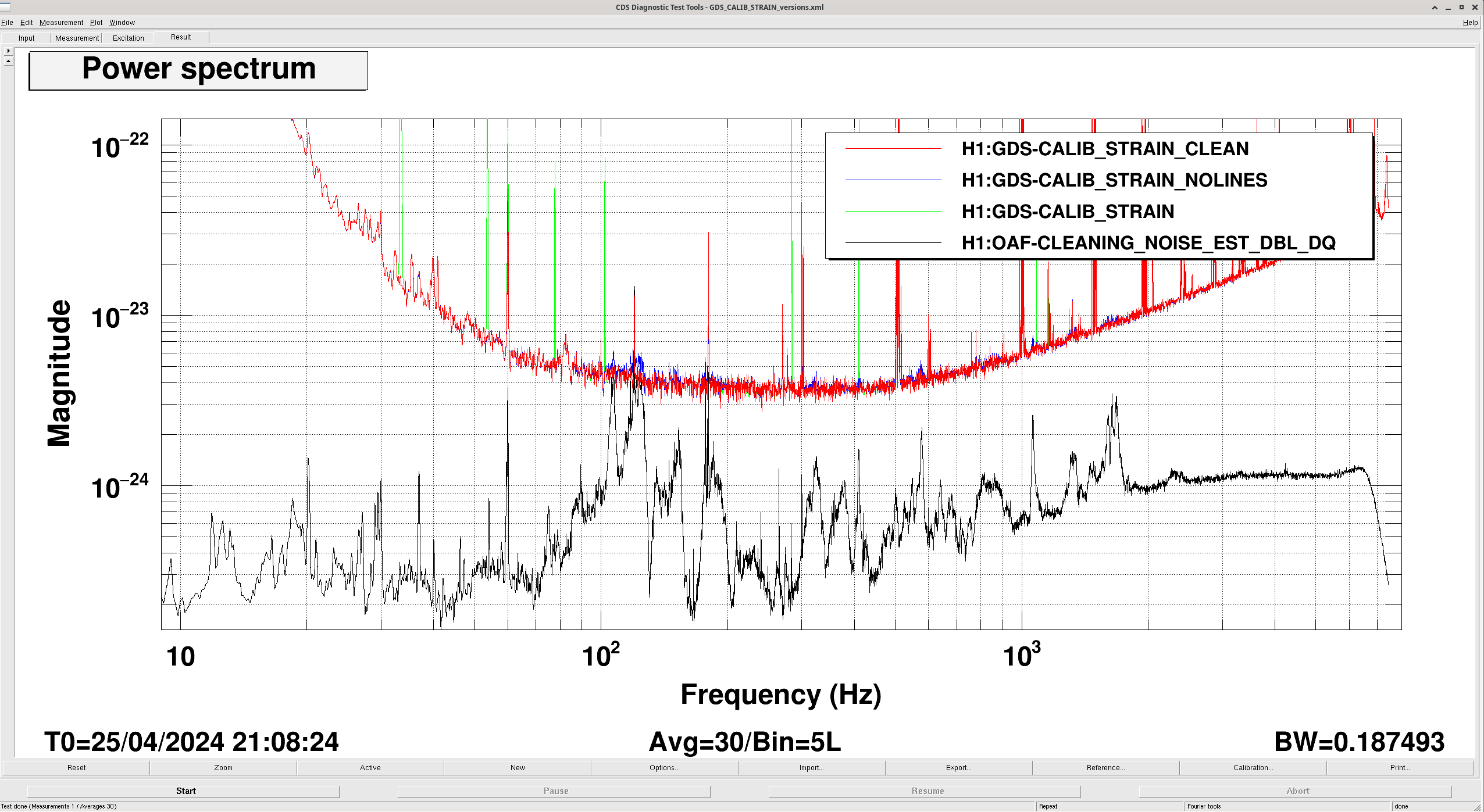
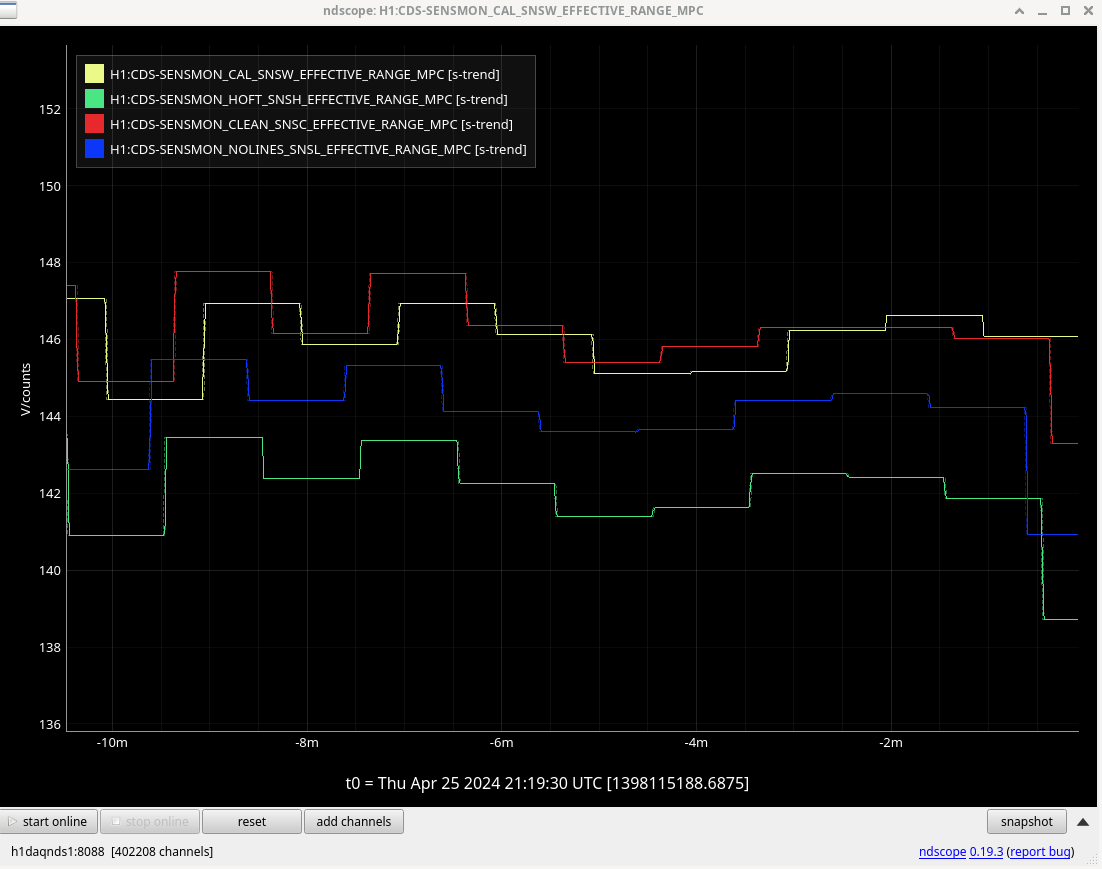
So, the fact that our GDS-CALIB_STRAIN_CLEAN range is about the same as our CAL-DELTAL_EXT range (instead of the CLEAN looking higher than CAL-DELTAL range) is likely more due to the time dependent calibration factors, and not due to problems with cleaning. Tuesday night, the jitter 'cleaning' was adding noise, when we were clipping a beam somewhere. However now that we're no longer clipping, the input jitter coupling is back to about how it was.
The first attachment shows the working cleaning in spectral form, and the second attachment shows it in the range channel time series with colors roughly matching.
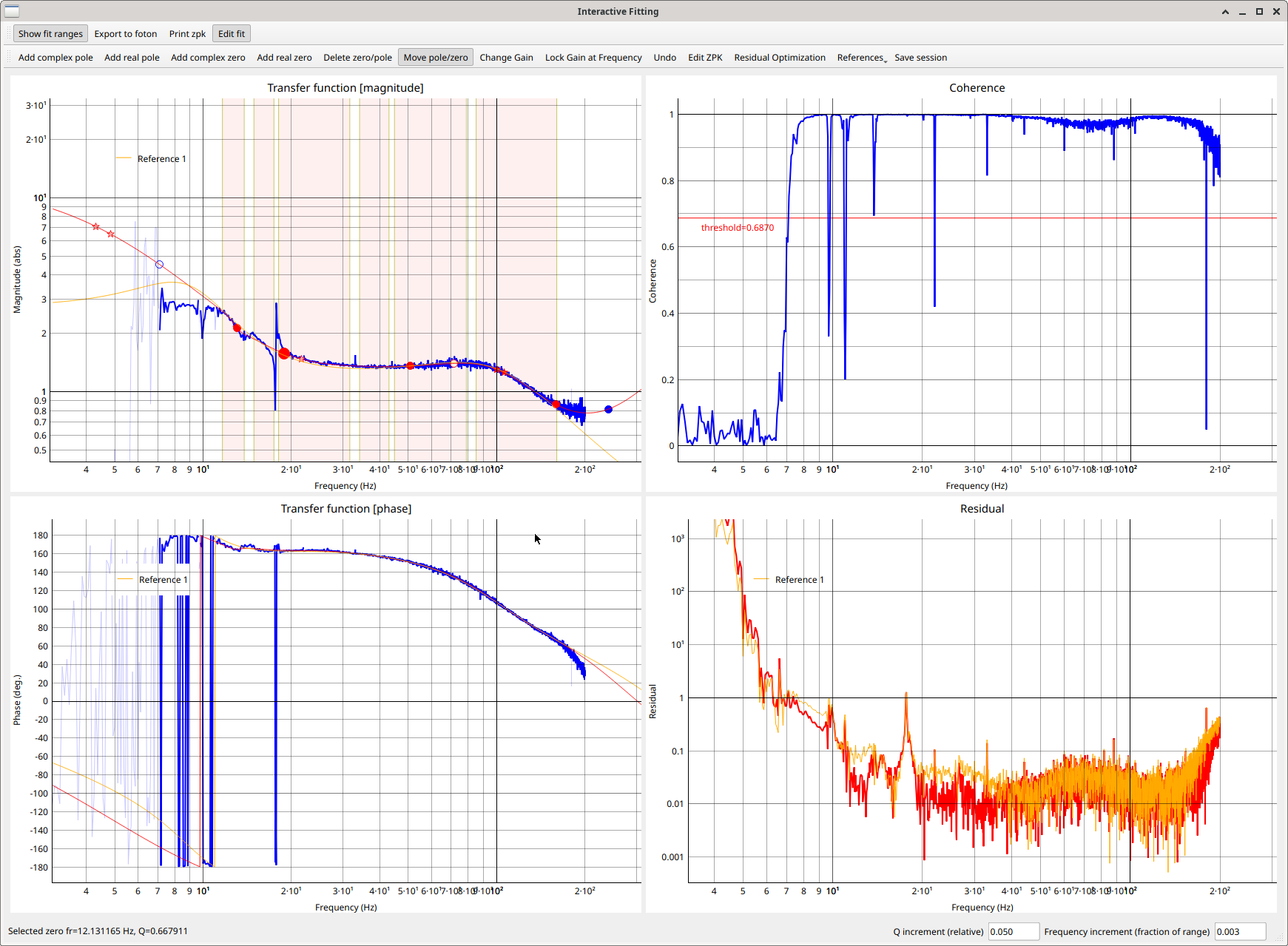
In 77236, Gabriele found the ETMY L2 DRIVEALIGN L2L filter bank has a "L2L3LP" engaged that might be making it harder for us to fit the LSC FF. Today we re-measured the LSC FF, not interatively, with both FF's off and the "L2L3LP" filter off.
Nothing changed but we hope to refit the feedforward and implement them later. When installed, we would need to turn "L2L3LP" filter off after the ISC_LOCK states have been transitioned back to ETMX (77240).
All code saved to /opt/rtcds/userapps/release/lsc/h1/scripts/feedforward/
Struggling to fit these.
I have a MICHFF (pasted below) that's a factor of 10 worse than usual (plot attached). We may need to try to put this in and measure iterativly next week.
zpk([-6.816742648521258+i*81.77990170298034;-6.816742648521258-i*81.77990170298034;-77.88634028587184+i*89.33349468557826;-77.88634028587184-i*89.33349468557826;-718.113182677264+i*694.9426298748548;-718.113182677264-i*694.9426298748548;900.2096672125509+i*1208.040185682559;900.2096672125509-i*1208.040185682559;44.6571105273674;-170.8240187509259;-448.0004789051675;-596.150964242976],[-7.116688087177324+i*81.29900739837851;-7.116688087177324-i*81.29900739837851;-310.9419719288208+i*548.6326527169308;-310.9419719288208-i*548.6326527169308;-27.13254150394529;-30.48270823801881;-135.6924431195733;-151.8787517615438;-191.3877206479833;-2313.589507955138;-2602.376933025248;-2783.911401801387],-3.94153891134724)
Somethings wrong with the SRCL data I exported (even after re-exporting), plot attached. Data prepared using NotItter_LSC_FF_PrepareData.ipynb
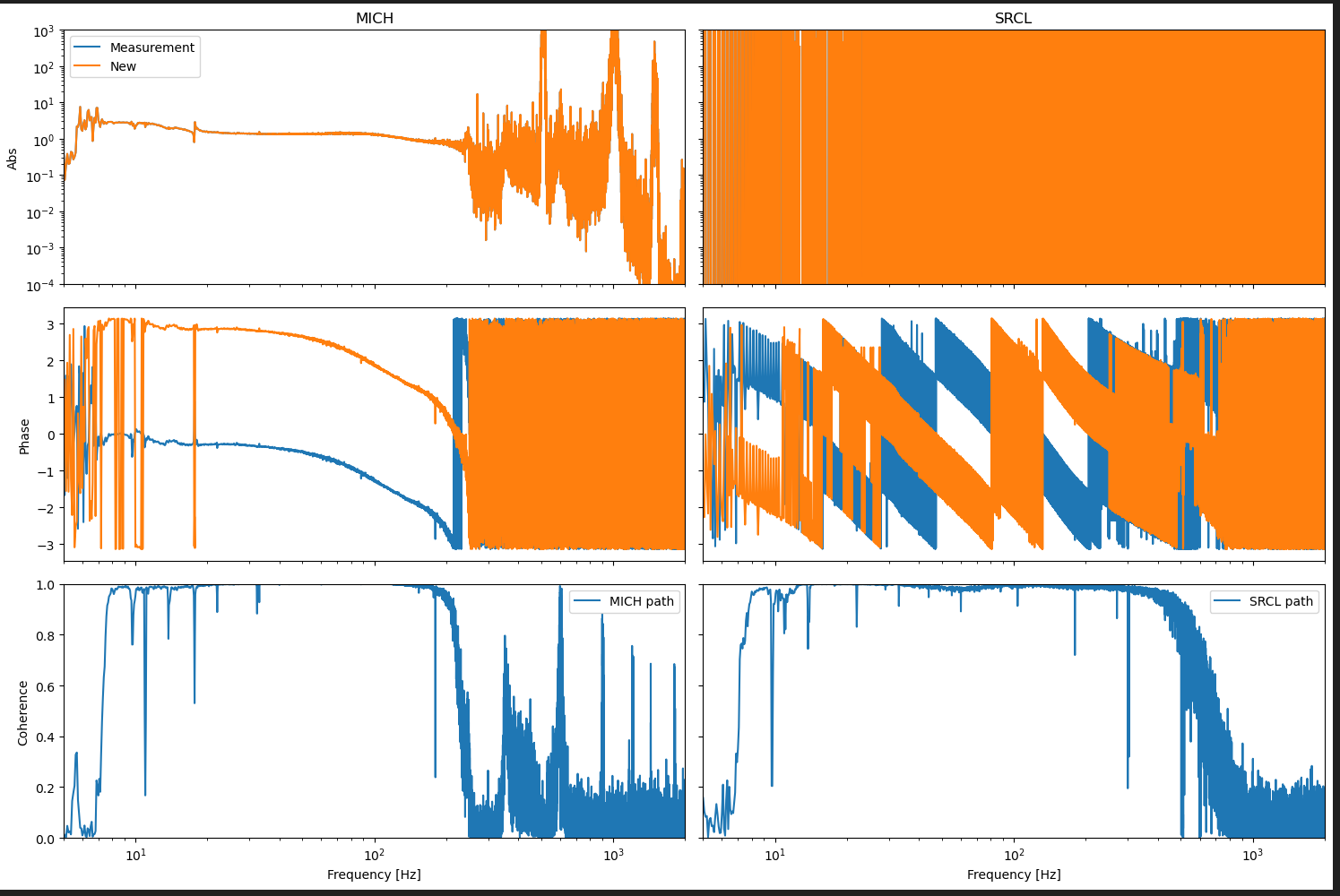
Gabriele found that the SRCL data was fine if (DELTA_L / SRCLFF_IN2) was exported but that the SRCLFF was even harder to fit than previously. We have taken TFs in 77542 to try to understand why.
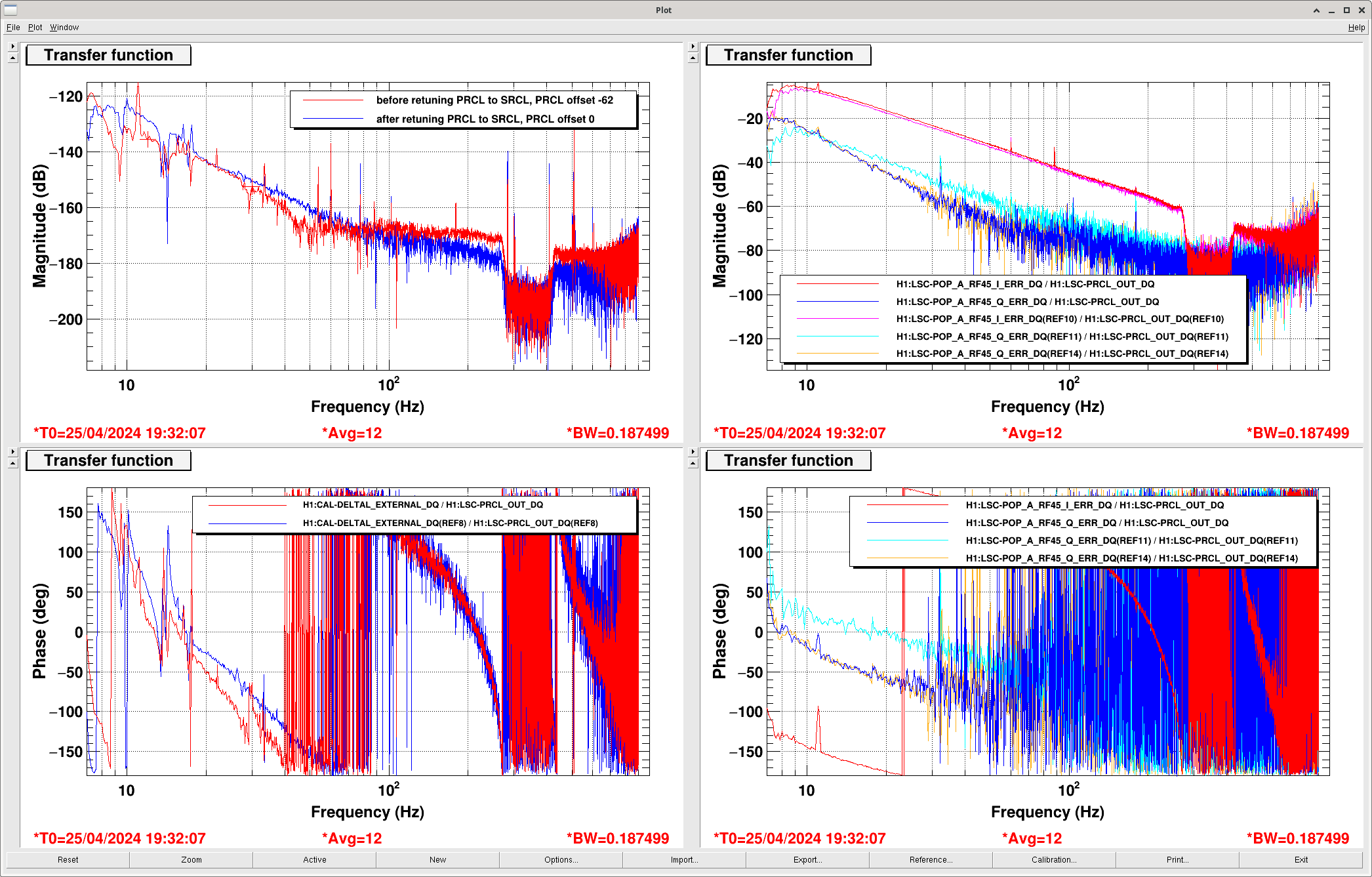
We'd like to retune LSC feedforward after yesterday's big alignment shift, but before doing that we want to phase POP45 and retune the LSC input matrix element that cancels PRCL in the SRCL signal.
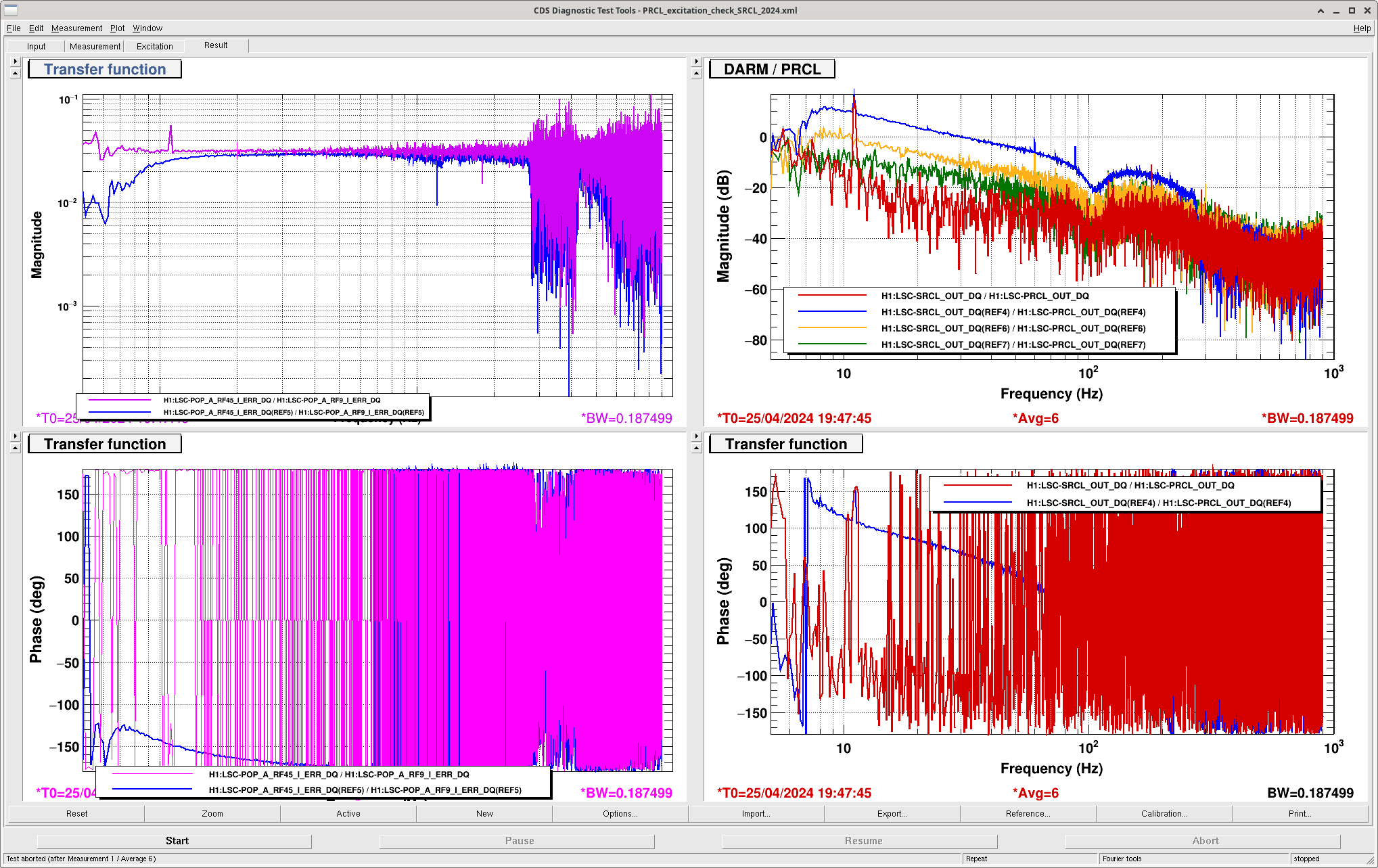
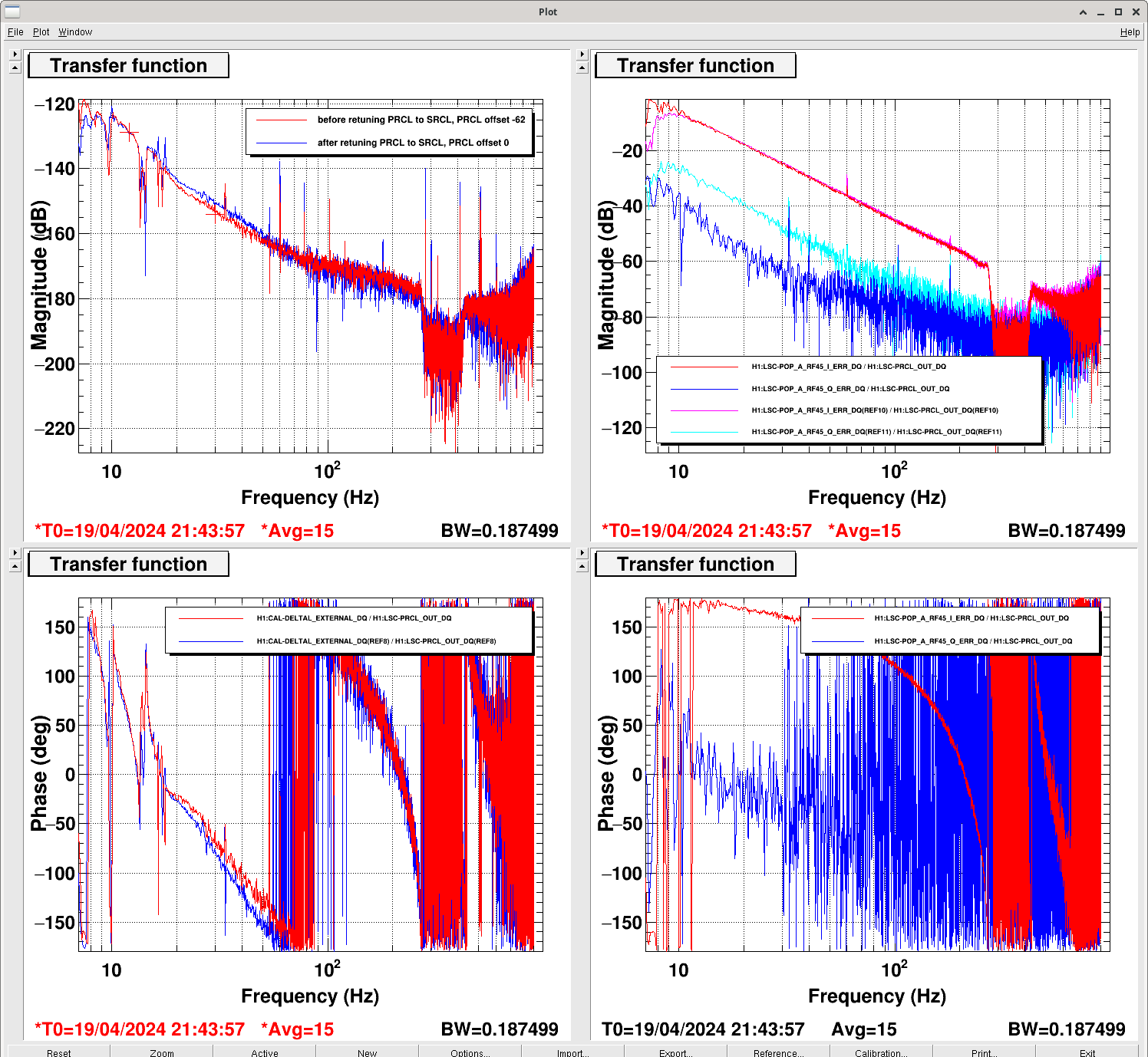
Injecting a PRCL signal and trying to minimize the signal in POP 45 Q suggests that we need to change our phase from 8 degrees to 12 (similar to last week's conclusion that we needed to move to 11 deg). The decoupling of PRCL from Q is not as effective as it was last Friday The second attachment shows that I checked the OLGs of MICH and SRCL before and after, and as expected they don't change much.\
After this phasing, the transfer function from POP45I/ POP 9I measured with a PRCL excitation is -0.03192. This means that POP 9I to SRCL input matrix element should be 0.1185 = (-3.712*-0.003192) The third screenshot shows the PRCL to SRCL transfer function before this change in blue, and after in red, so this reduced the PRCL signal in the SRCL error signal by more than a factor of 10.
After this I looked at some coherences during no SQZ time, we do still have LSC coherence at a similar level as last night, but not worse than in Jennie W's plot from last night. Camilla is now running measurements that can be used to fit LSC feedforward. We will leave these settings in place for tonight since it's not making things worse, and hopefully try new feedforward filters in the morning. I've added the new POP9I to SRCl elemement in lscparams, and accepted the phase change in OBSERVE.snap and safe.snap
Naoki and I left PSAMs at 8.8/-0.67 in 77268, and yesterday afternoon 77389 we changed them in a test that we reverted. But last night a 3am, the offsets didn't change but the PSAMs strain readbacks changed. The PSAMs actually changed as this can be seen in the alignment readback sensors. Plot attached
Did some strange electronics issue happen with SQZ last night that also impacted the TTFSS: 77418
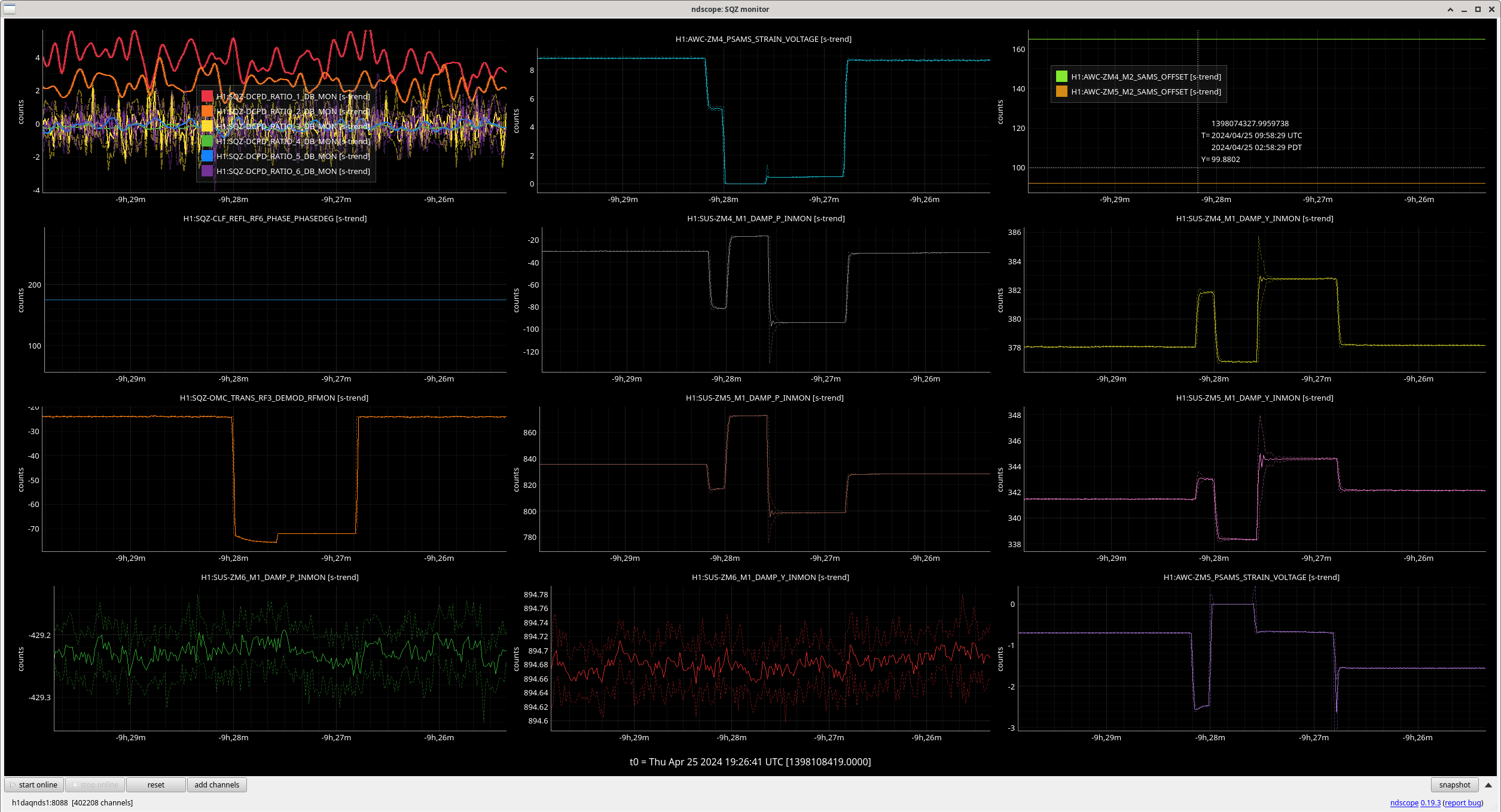
After suggestion from Richard, it seems like lots of things in H1-SQZ-R1 saw a glitch at 9:58UTC (2:58amPT), plot attached. This may have been caused by or related to the SQZT0 - Laser Locking Fiber Beat Note Chassis power regulator board failure: 77418, 77403.
As the PSAMS have hysterisis, when ZM5 turned back from 0V to it's noimnal, the strain volatge readback chanegd from -0.6V to -1.5. We reverted it back to -0.6V.
ZM2 PSAMS changed less than 1%.
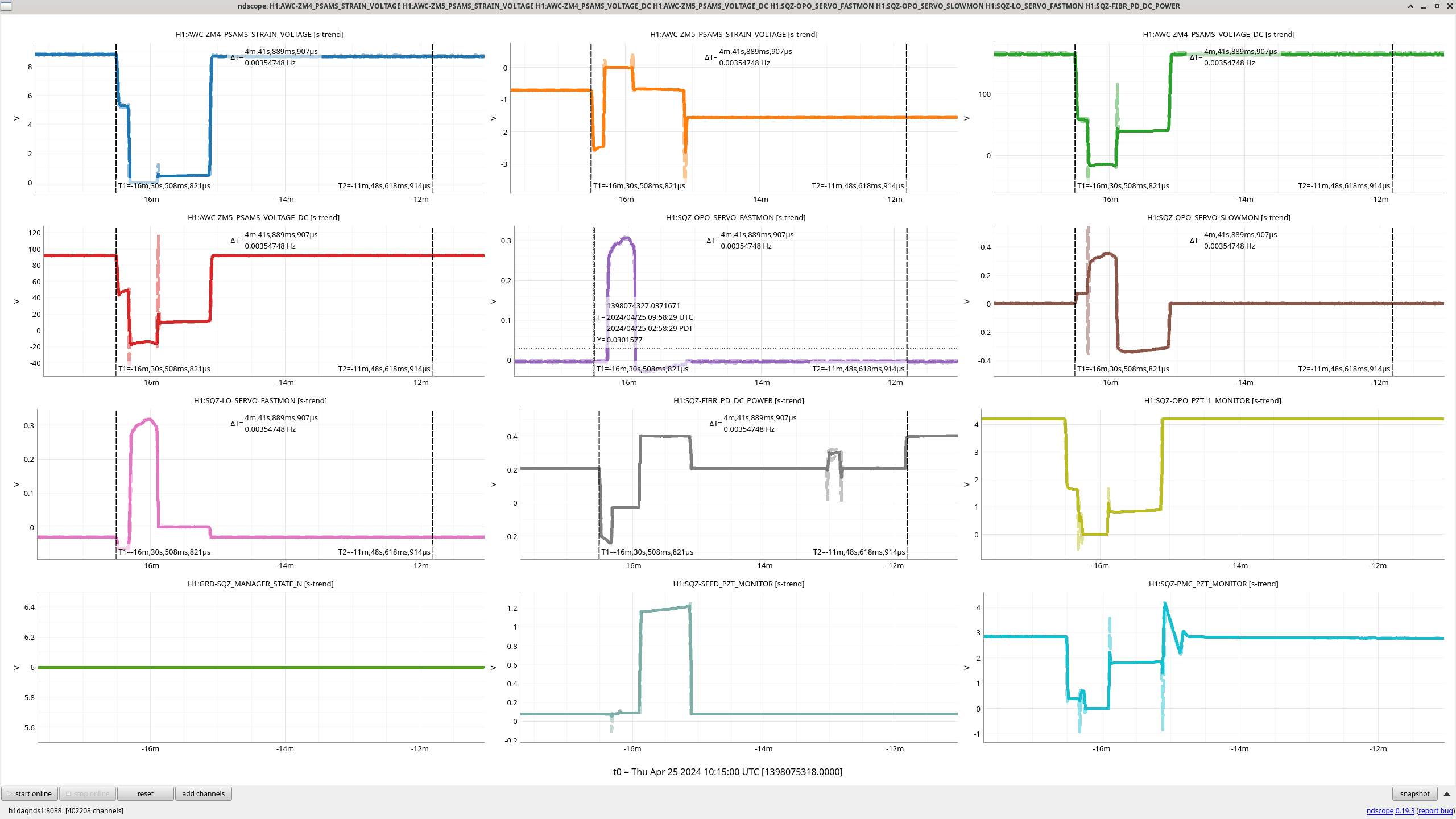
This starts FRS Ticket 31062.
WP 11832
While troubleshooting TTFSS (alog 77403), Sheila and Camilla found issues with the D2300329 Laser Locking Fiber Beat Note Chassis. Unit was replaced with spare. SQZ team reports outputs back to nominal.
Removed unit had power regulator board D100217 failed. Output capacitor C7 was shorting +15V rail to ground. Power regulator board replaced.
Installed Chassis S2300259
Removed Chassis S2300258
Jennie W, Sheila
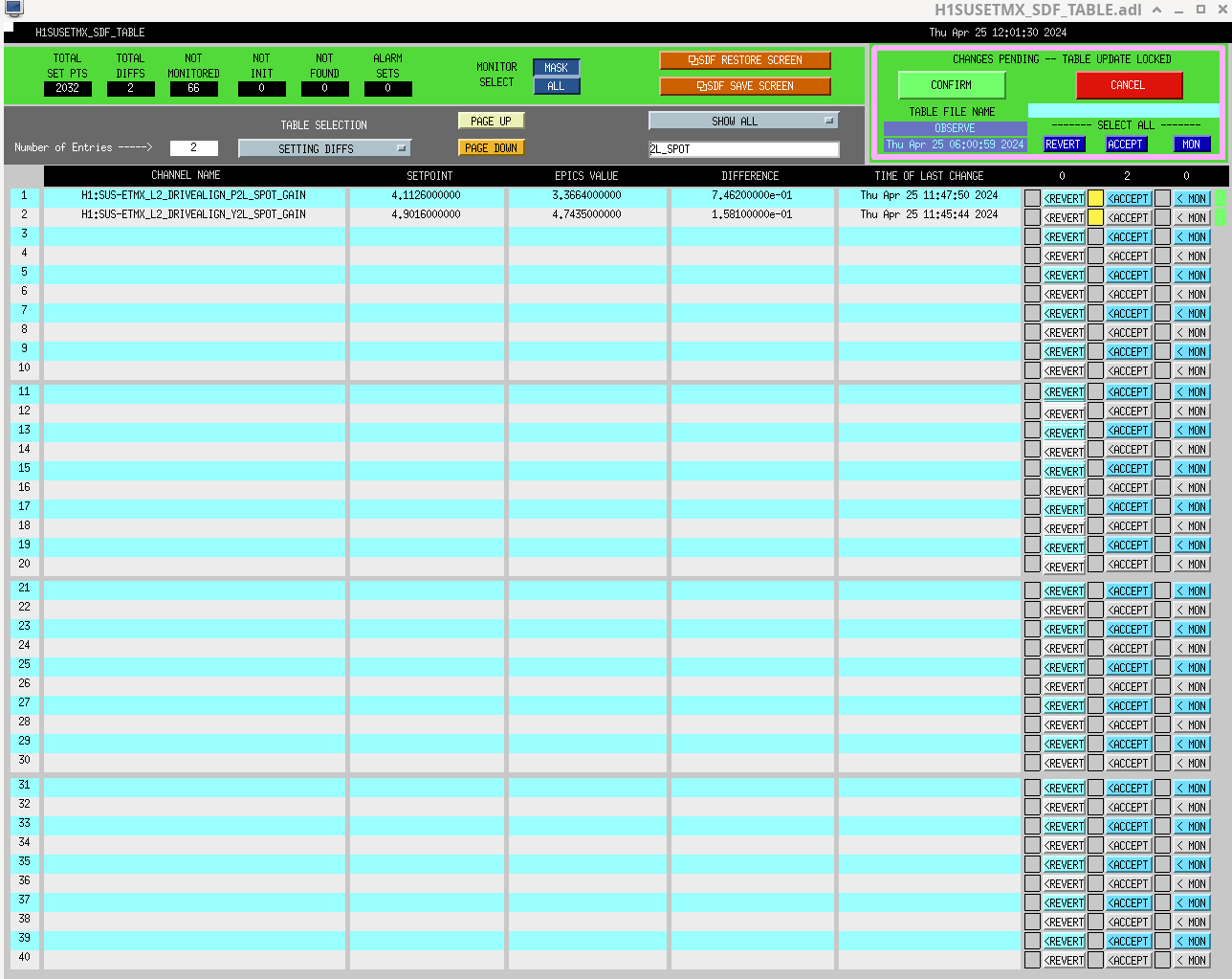
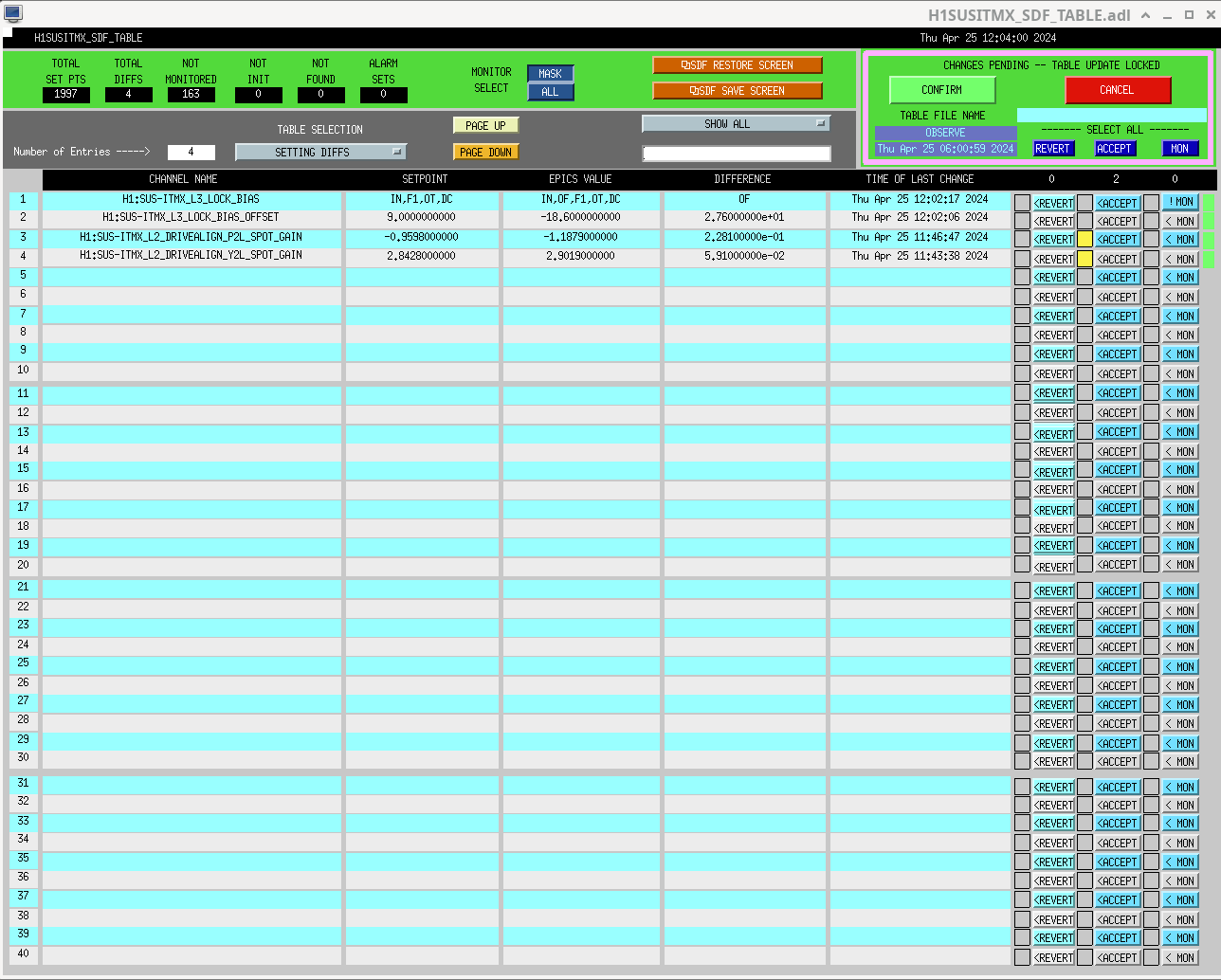
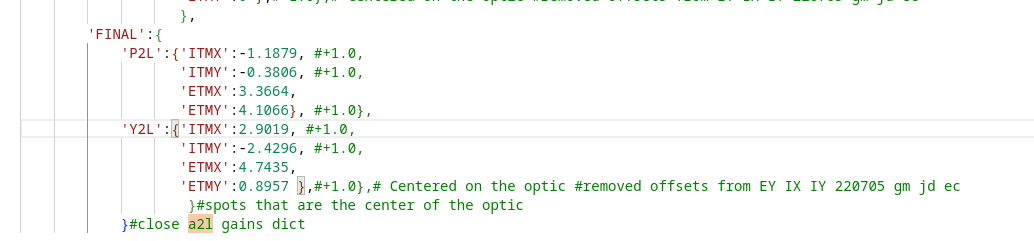
Now we have our camera servo offsets that we found on the 17th tuned in we ran the A2L script again. The code is
userapps/isc/h1/scripts/run_all_a2l.sh
I saved these values in lscparams.py in userapps/isc/h1/guardian/ and accepted the sdfs in OBSERVE.snap.
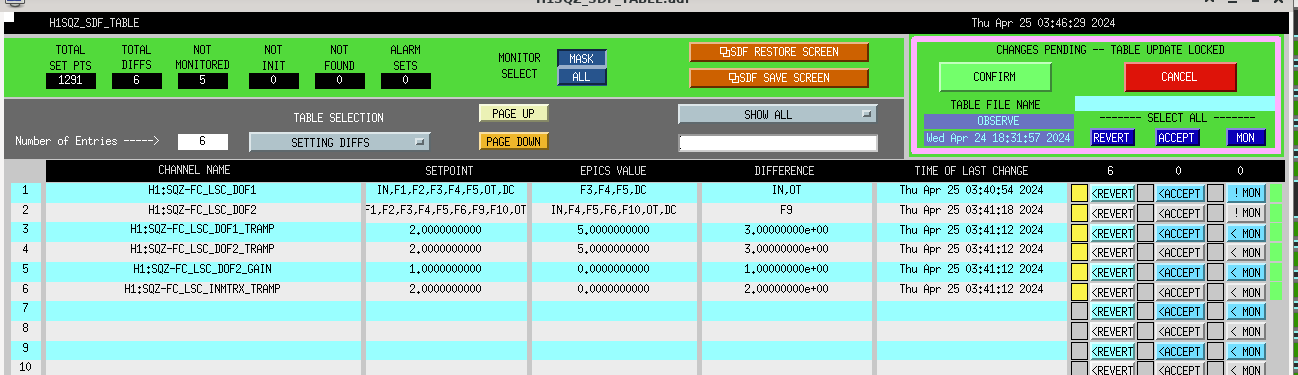
H1 called for assistance as the SQZer lost lock and has been struggling to relock, its been stuck waiting for the TTFSS to lock, it says "Check crystal frequency, can try 45MHz" which is a notification I haven't seen before and I can't find any reference in the WIKI. I'm calling out for SQZ help
I got ahold of Jenne, who suggested following alog 70050 which I did not notice that DIAG_MAIN was also complaining about. Doing this which is reseting the ISS did not help this TTFSS issue. Also at Jennes suggestion I'm going to try and get us into observing without SQZing
Back into observing with NO_SQUEEZING at 11:09 UTC, I followed the WIKI. I forgot that I also had to edit the IFO node to add to the exclude list to get us back into observing ( we should add this to said WIKI page). I reverted the attached SDF diffs
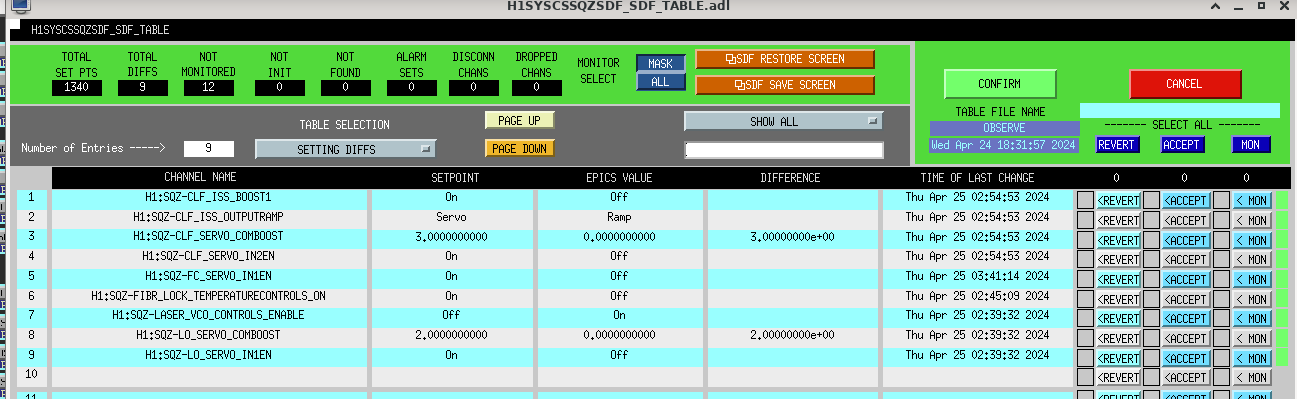
The usual trick of manually moving the crystal frequency to find the beatnote (suggested by the error message Ryan reports above) doesn't work in this case. The attached screenshot shows that at about 3 am the power on the FSS PD nearly doubled, but the fiber power, polarization, and power out of the squeezer laser didn't change. We lost the beatnote at that time (BEATnote strength drops to -40dBm. Moving the laser frequency around doesn't change this.
Note that I thought I could move the laser frequency while we were in observing without squeezing, because the crystal frequency is not monitored in SDF. However changing this changes other things which are monitored, and did temporarily knock us out observing. Some automation brought us back to observing quickly enought that I didn't notice the first time and so did this twice.
Vicky, Sheila, Camilla. Went SQZ_MANAGER to DOWN which cleared any wrong sdfs that had been reverted. The H1:SQZ-FIBR_SERVO_DEMOD_RFMON should not be this low (-40dB), even in old TTFSS issues (75337). We tried touching everything on the TFFSS screen to no avail. We tried changing polarization into "to beatnote" fiber. Turning down this power dropped the H1:SQZ-FIBR_PD_DC_POWER form 0.4 to 0.3. Rather than halving it. Going out to check powers on SQZT0.
On SQZT0 Sheila and I found that even with the PSL fiber unplugged and SQZ beam blocked, H1:SQZ-FIBR_PD_DC_POWER reported power.
Fil replaced the D2300329 Fiber Beat Note Box with our spare. This solved our TTFSS issues. It appears something in the power supply for the box had failed. Details in 77418.
Sheila, Jennie W
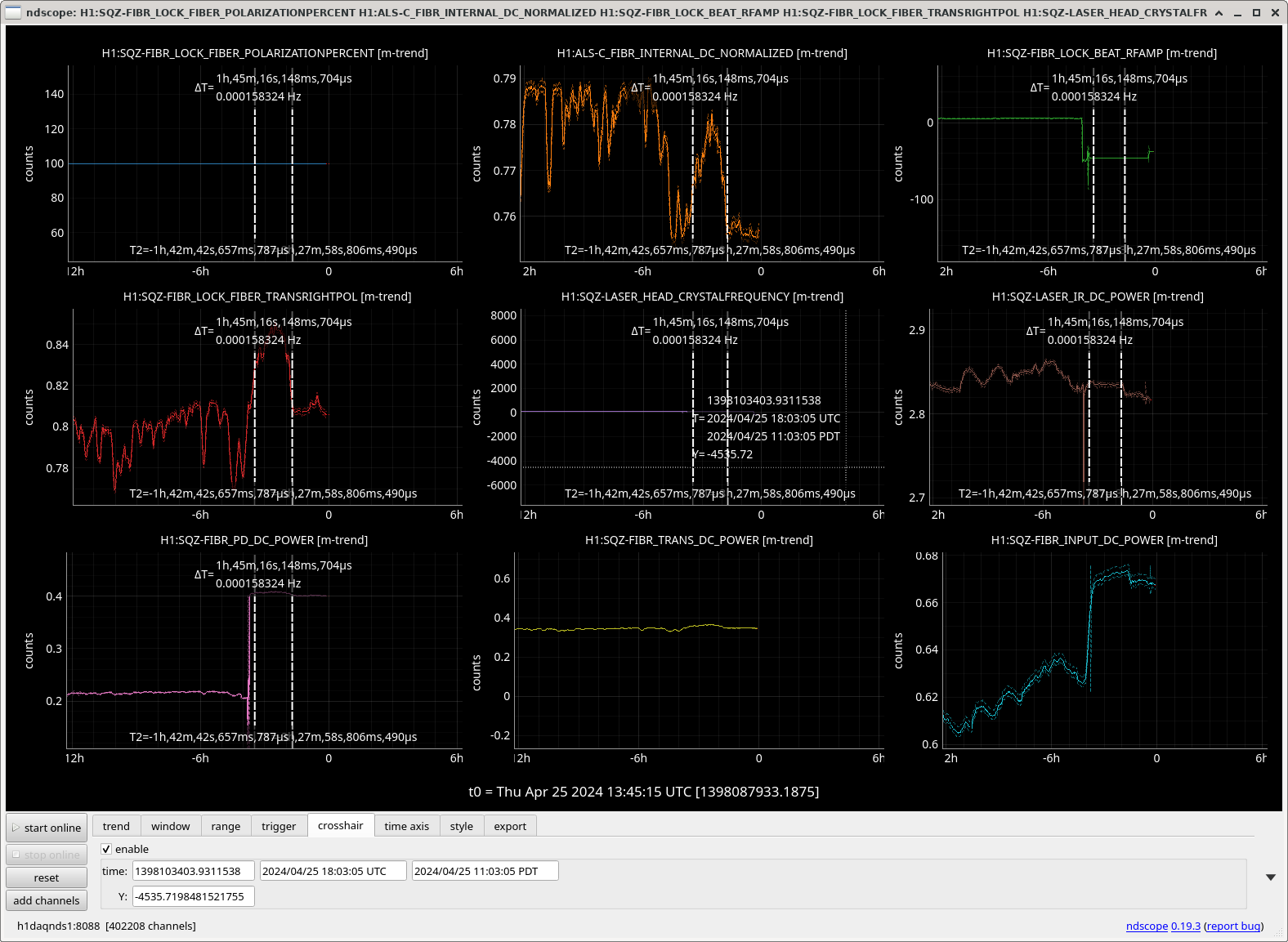
Sheila noticed our range was really high in the lock at 14:51 UTC on the 17th April.
All camera offsets are the same from the good range time (16:19:53 UTC) on the 17th (left cursor) compared to a lock from last night at 2024/04/24 13:20:30 UTC (right cursor).
The offsets for these currently (second cursor) are not in lsc_params and since we had better build-ups on the 17th (first cursor), we should fix these offsets and see if we can optimise A2L gains again in the next commissioning window after the IFO range is recovered.
The best build-ups were immediately after this good time when we changed the PIT2 and YAW3 but this made the range worse.
We looked at this again today and realised the camera offsets had been set back to their former values from before our changes to PIT2 and YAW3 on April 17th when the cameras servo guardian went through state 405 (TURN ON CAMERA FIXED OFFSETS). Then we realised we may have forgotten to reload the camer servo guradian when we made these changes so we took reloaded it then took it to DITHER ON state, then to CAMERA SERVO ON and now we have CAM PIT2 OFFSET = -173 and CAM YAW3 OFFSET = -349.5 as is set in lsc_params.
FIXED ISSUE
{kind=link}