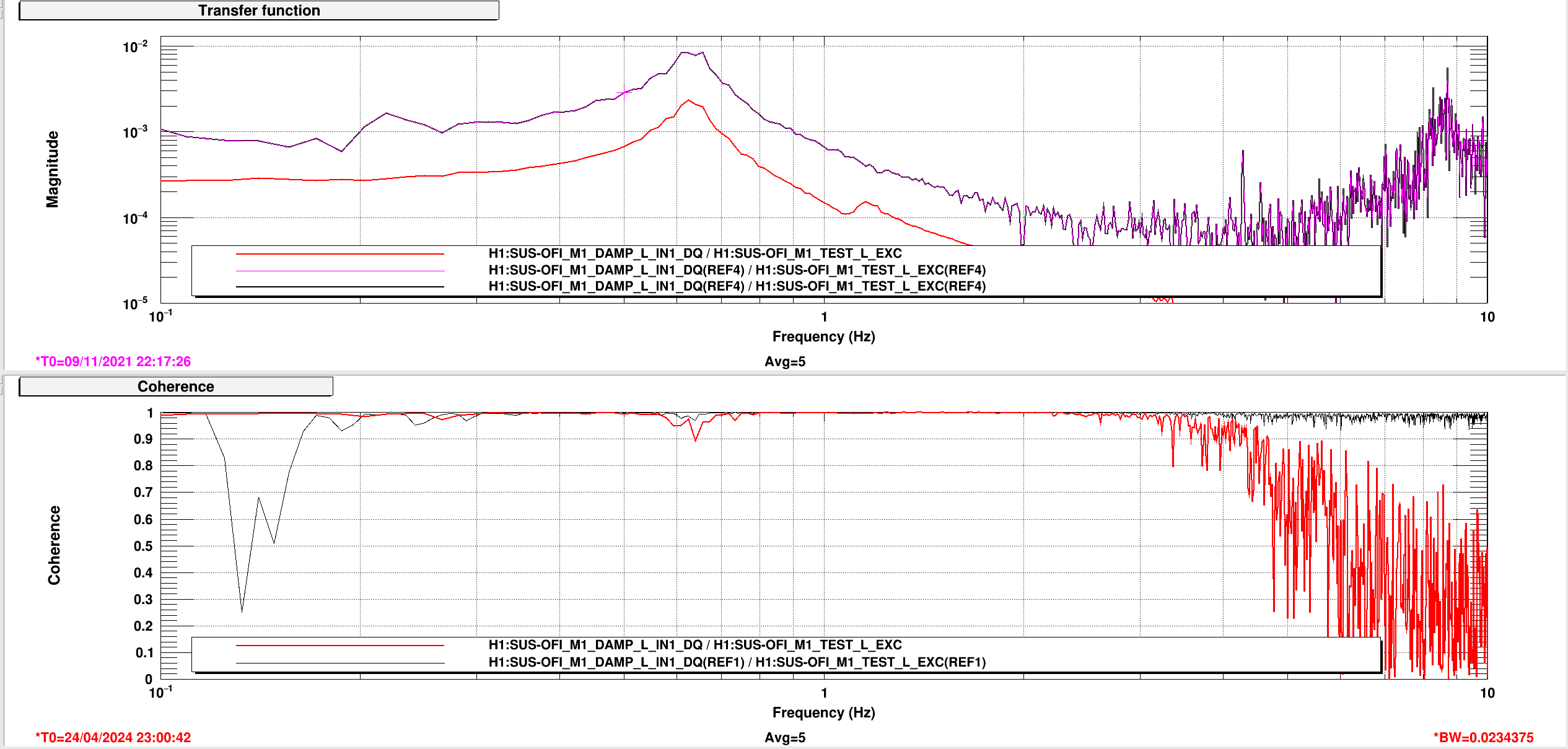
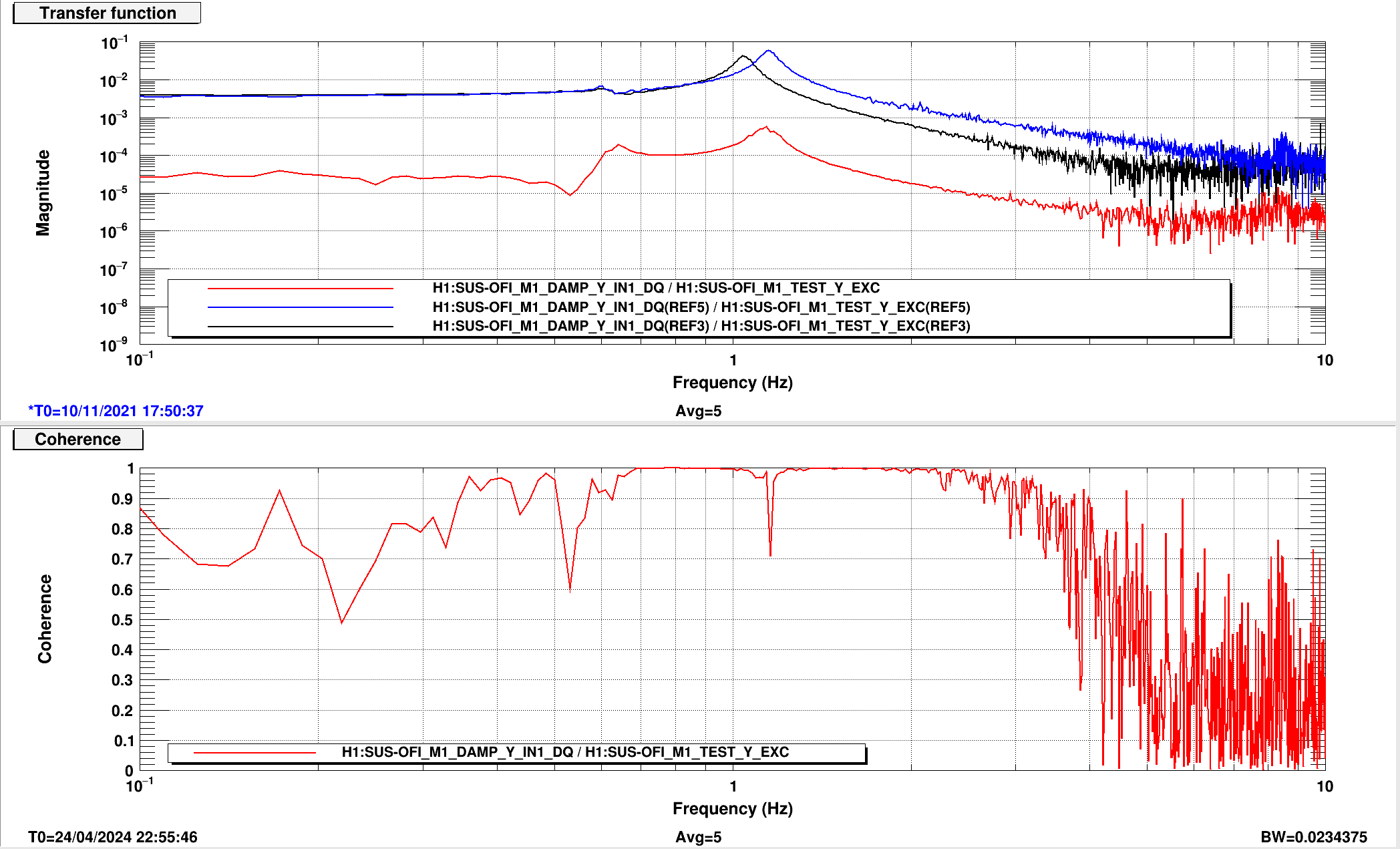
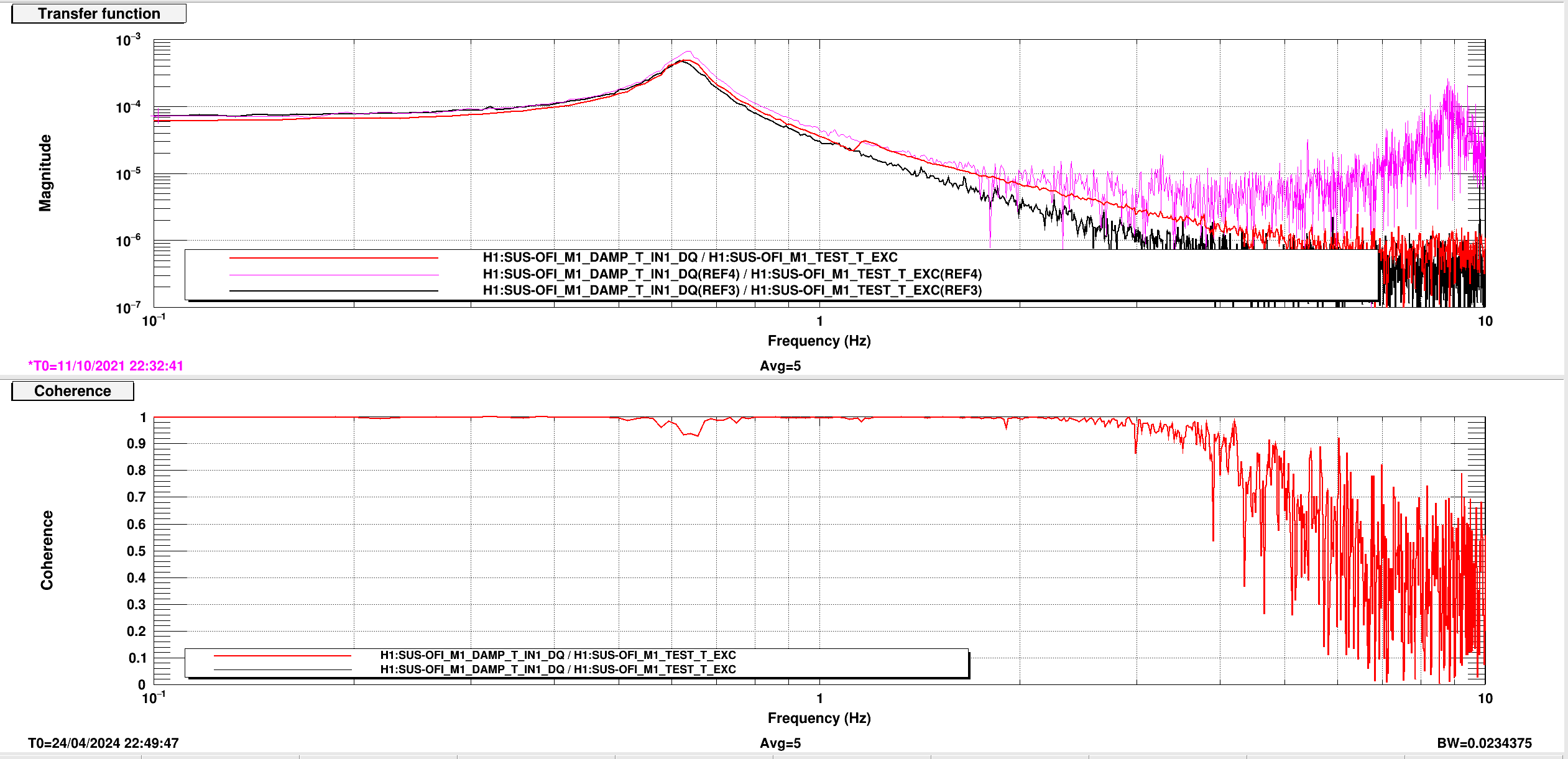
Tony, Nutsinee, Vicky
We re-aligned SQZ to the current IFO AS port alignment, got from basically no sqz at all, to ~4.5dB at the end.
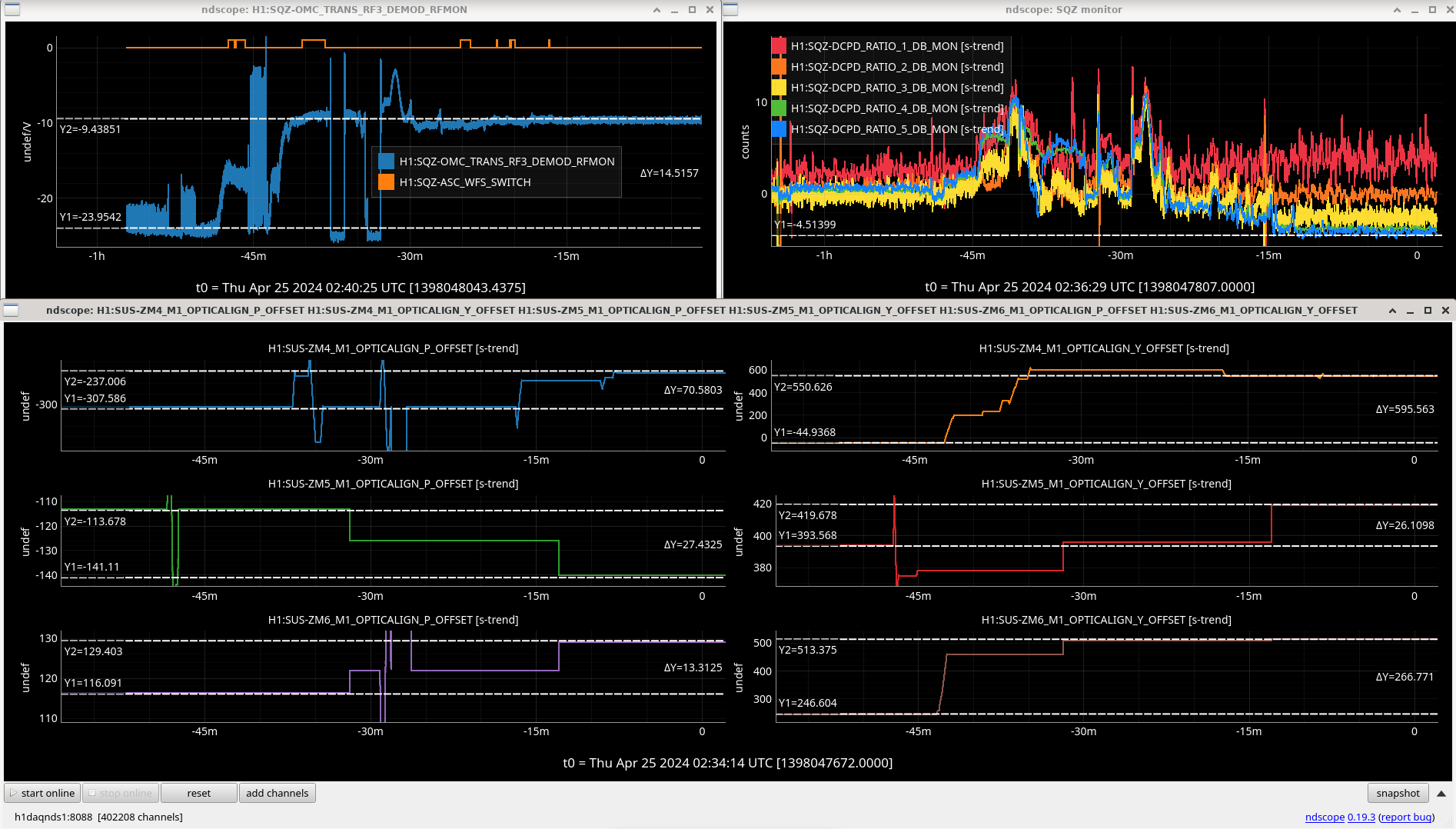
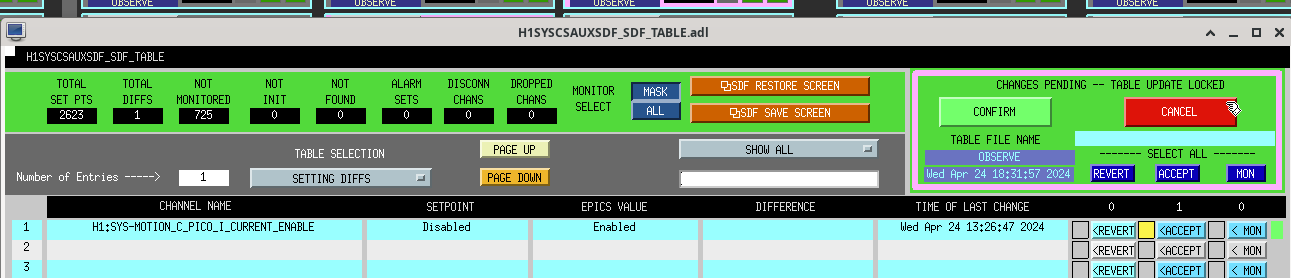
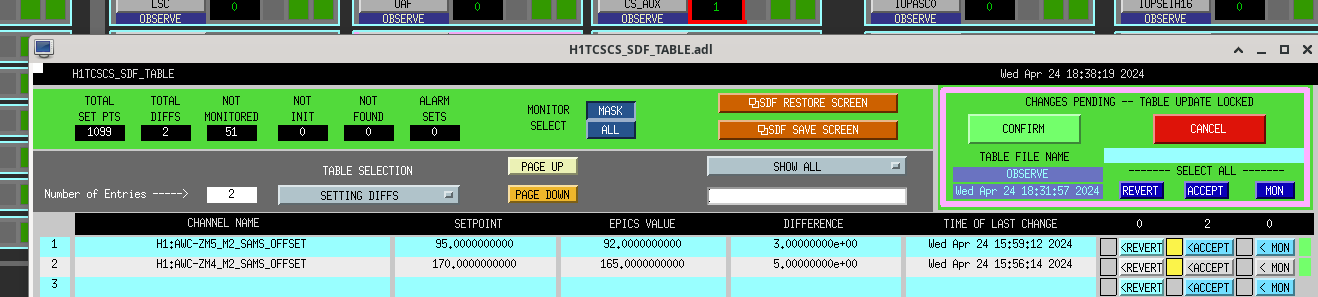
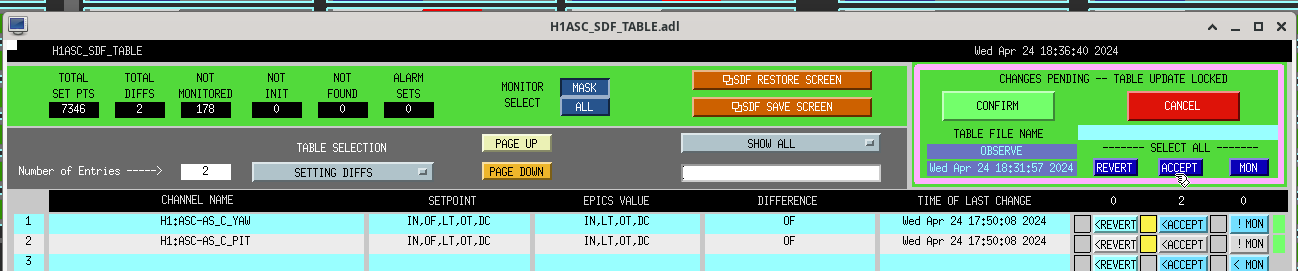
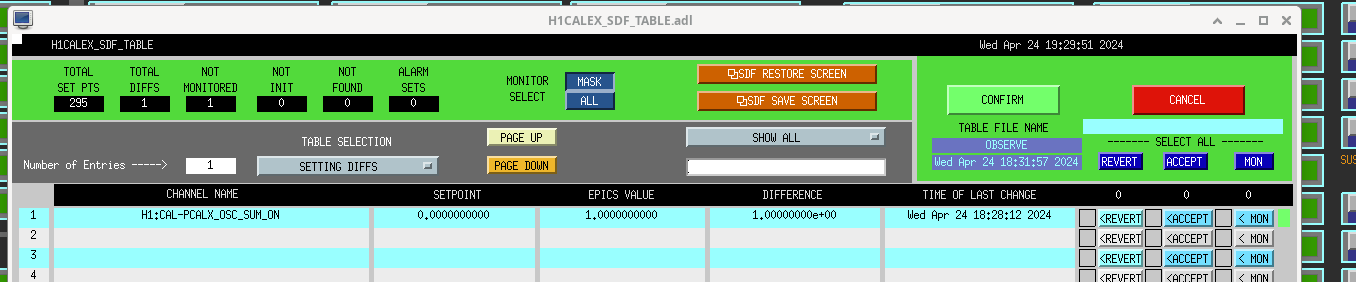
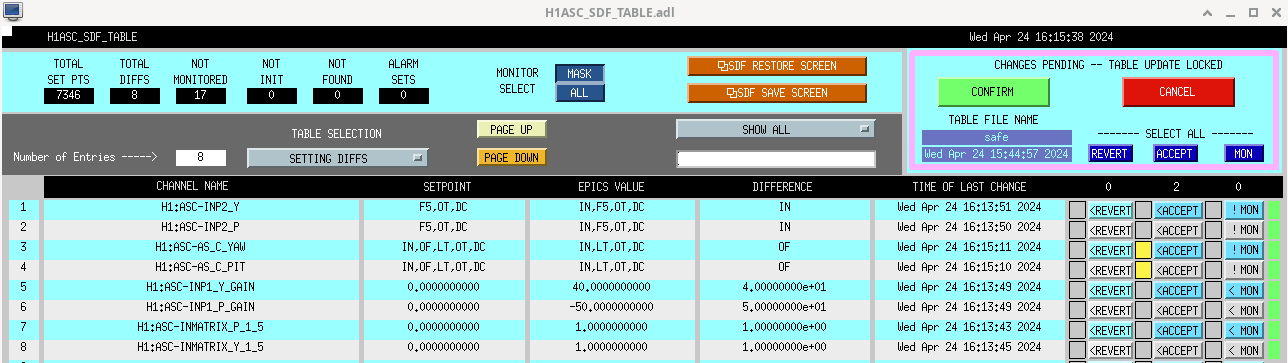
Screenshot. First I aligned ZM4 P/Y by ~hundreds counts to see a sqz signal again in transmission of OMC, then manually walked a bit with ZM6. Then I engaged AS42 ASC (zm5/6), which helped a bit to bring the alignment closer, but leaving ASC on for too long caused alignment to run away (so I cleared history on it and started over). I ran AS42 briefly a couple times until improvement to RF3 signal stopped, then offloaded, then some manual walks, then again. Could not use SCAN_ALIGNMENT (zm4/6) - it's range is way too big right now that LO loses lock, so we need to back off the scan range. Manually adjusted SQZ angle to maximize yellow 350 Hz / blue 1.7 kHz blrms.
Overall biggest slider moves were in YAW: ZM4_Y +600, ZM6_Y +270, secondarily ZM4_P +70.
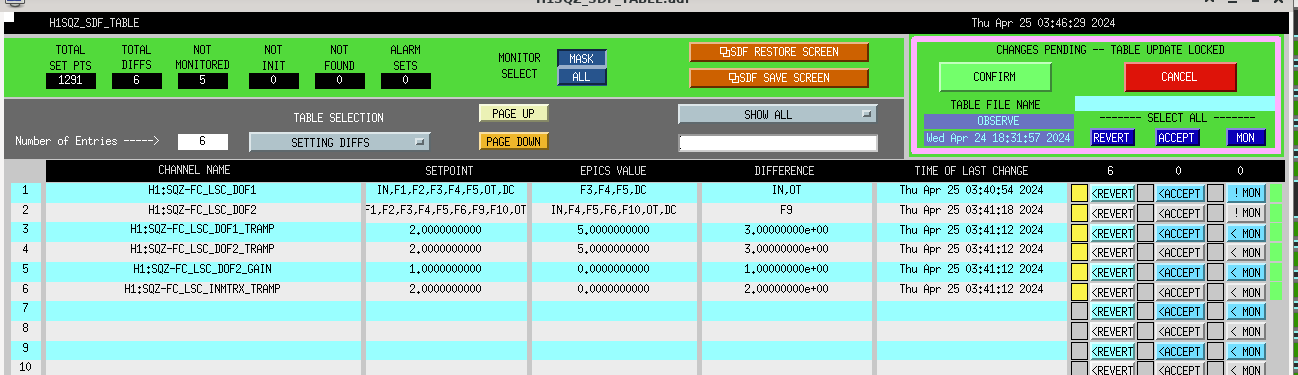
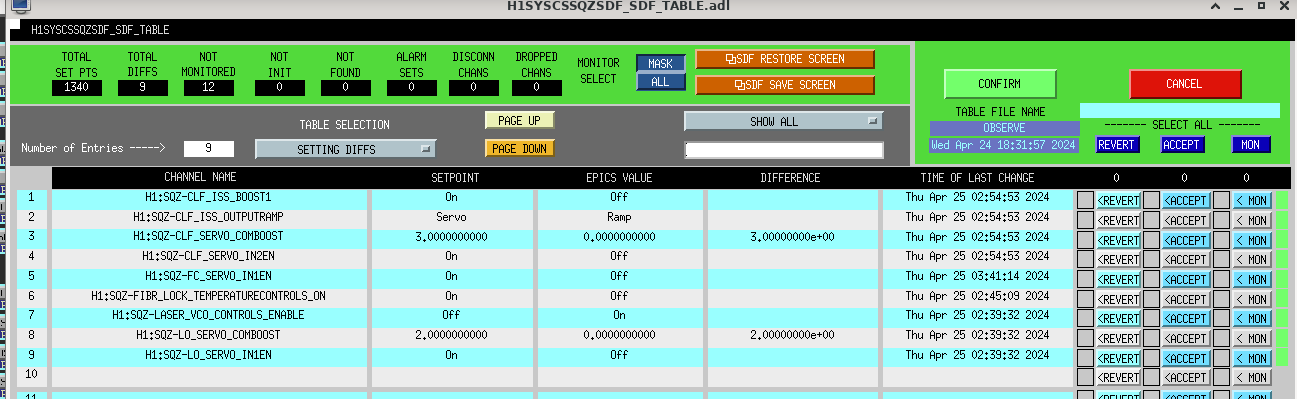
OMC_RF3_RFMON went from around -22 (noise floor around -25), to -10 at squeezing (ofc more with antisqz). SQZ went from basically totally misaligned to almost -4.5dB, with this series of manual walks and ASC attempts. On net, probably still broadly reducing noise with sqz vs. adding noise, so we decided to call it and accept SDFs on the ZMs, so Tony could go to observe.
Edit to add: Alignment and sqz angle are probably not that optimized still. Something interesting - when I first aligned and got something, squeezing needed an RF6 demod phase below 100 deg. When aligning more and with ASC help, the sqz angle moved back up to ~177 deg (where it is left now). Before, we had been operating at around 190-200 deg. Can add those trends here tomorrow. I'm a bit surprised how big much the sqz angle changed with alignment. Unsure if it's maybe a clue in tracking down why the sqz angle is drifting so much recently (for example if alignments, either sqz or ifo, are drifting and those drifts can be compensated in part by changing the sqz angle).