Jennie W, Sheila
Summary: We spent some time today resetting A2L gains, which make a large impact on our range. We are leaving the gains set in guardian to be the ones that we've found for 3 hours into the lock, but this will probably cost us about 5Mpc of range early in the lock.
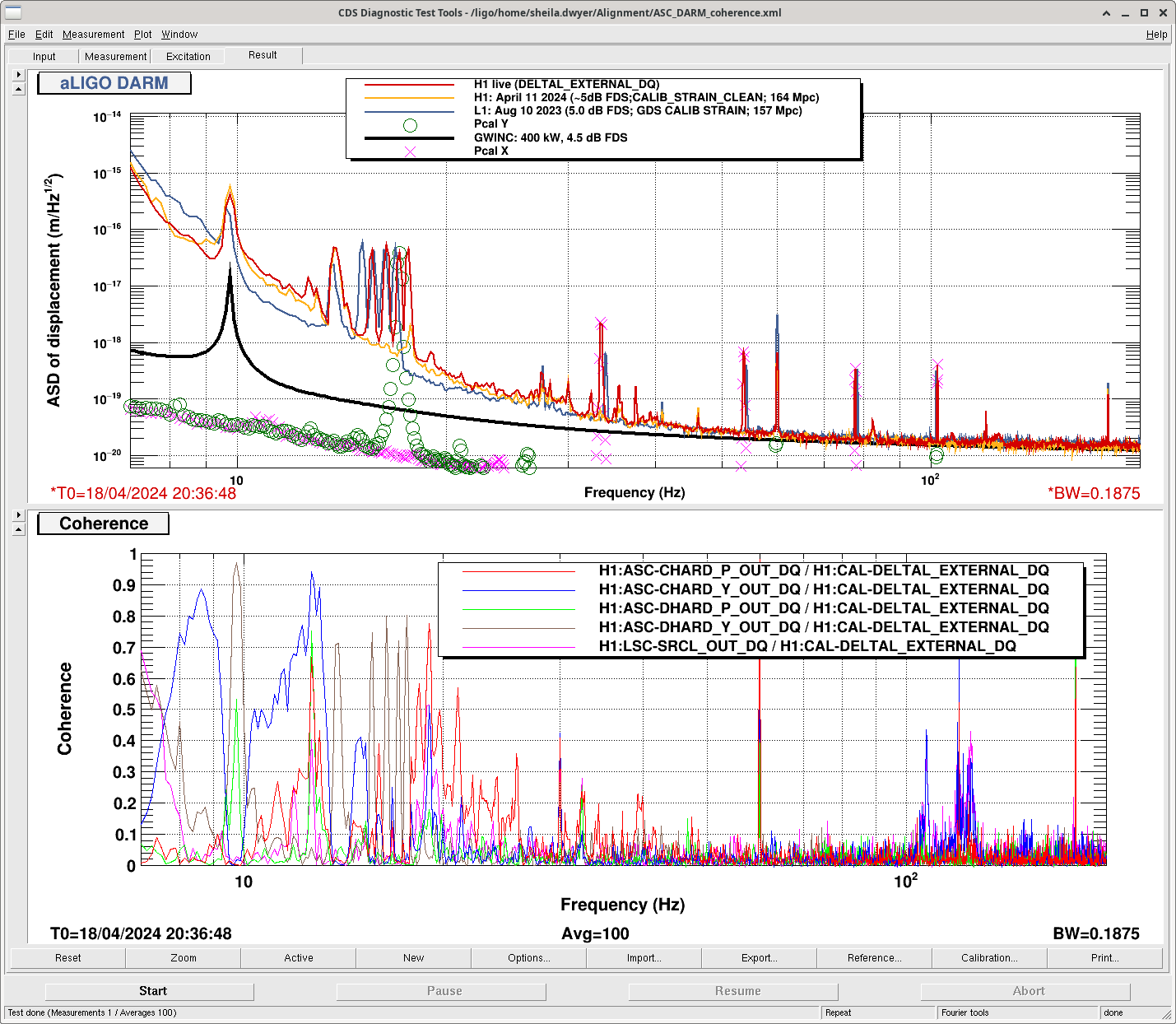
Overnight, our our low range was partially because the angle to length decoupling was poor (and partly because the squeezing angle was poor). We were running the angle to legnth decoupling script this morning when an EQ unlocked the IFO, and now we have re-run it with a not thermalized IFO.
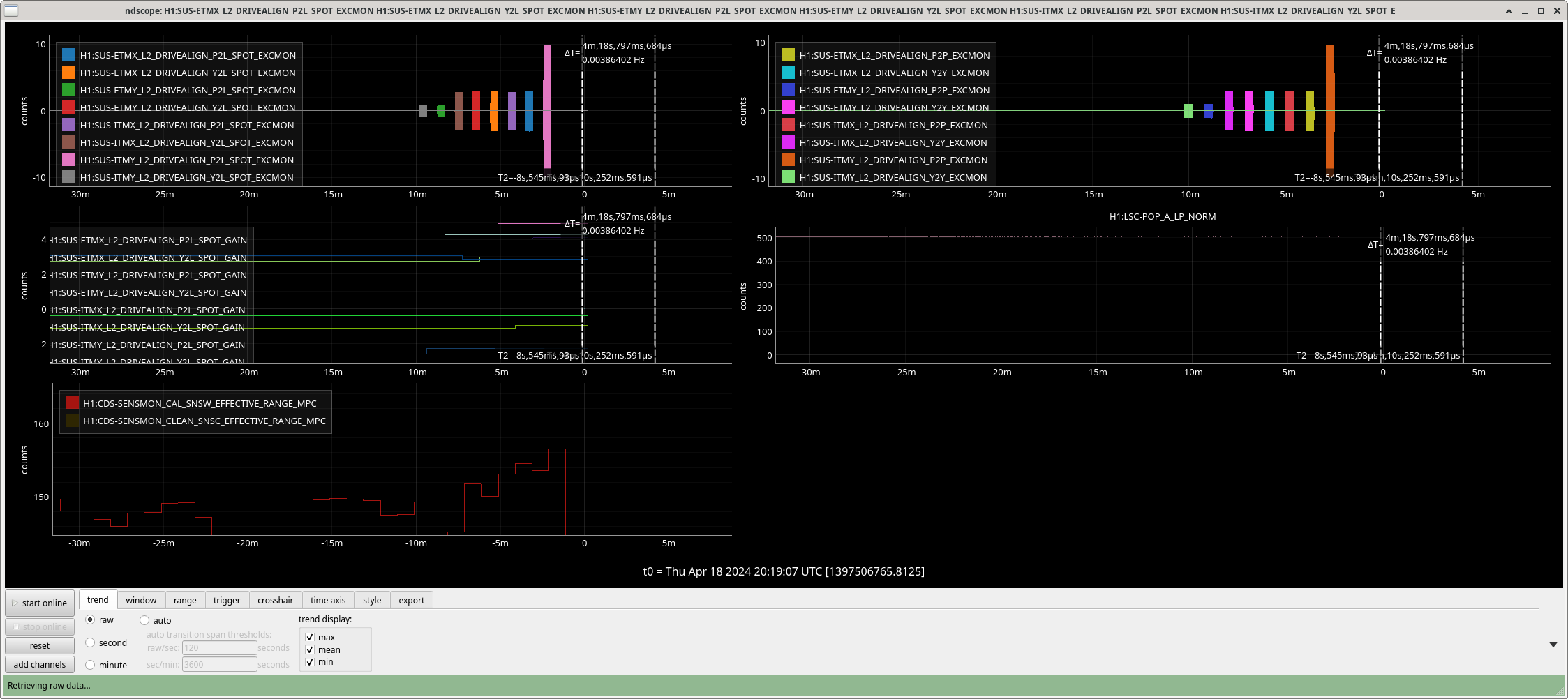
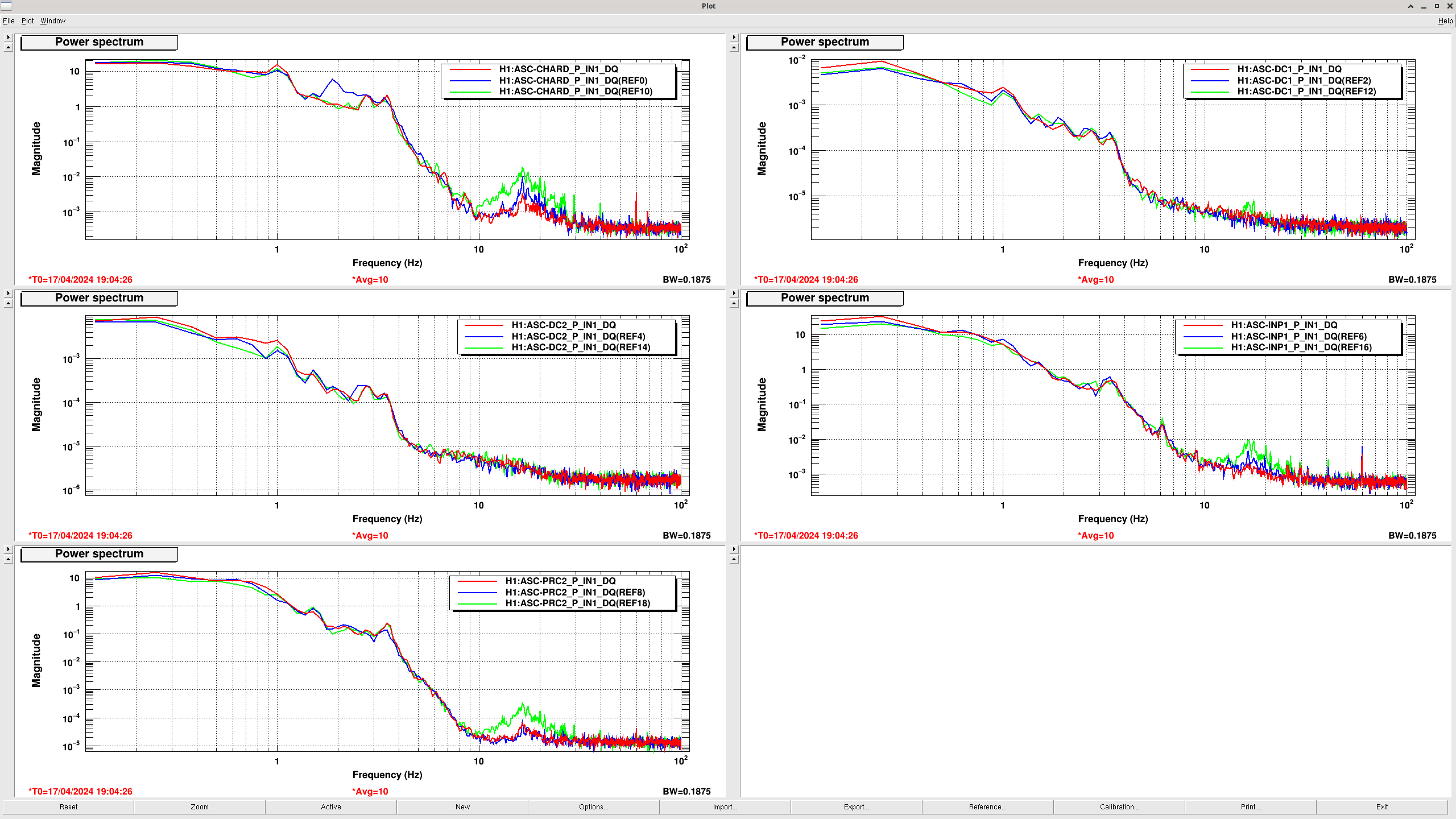
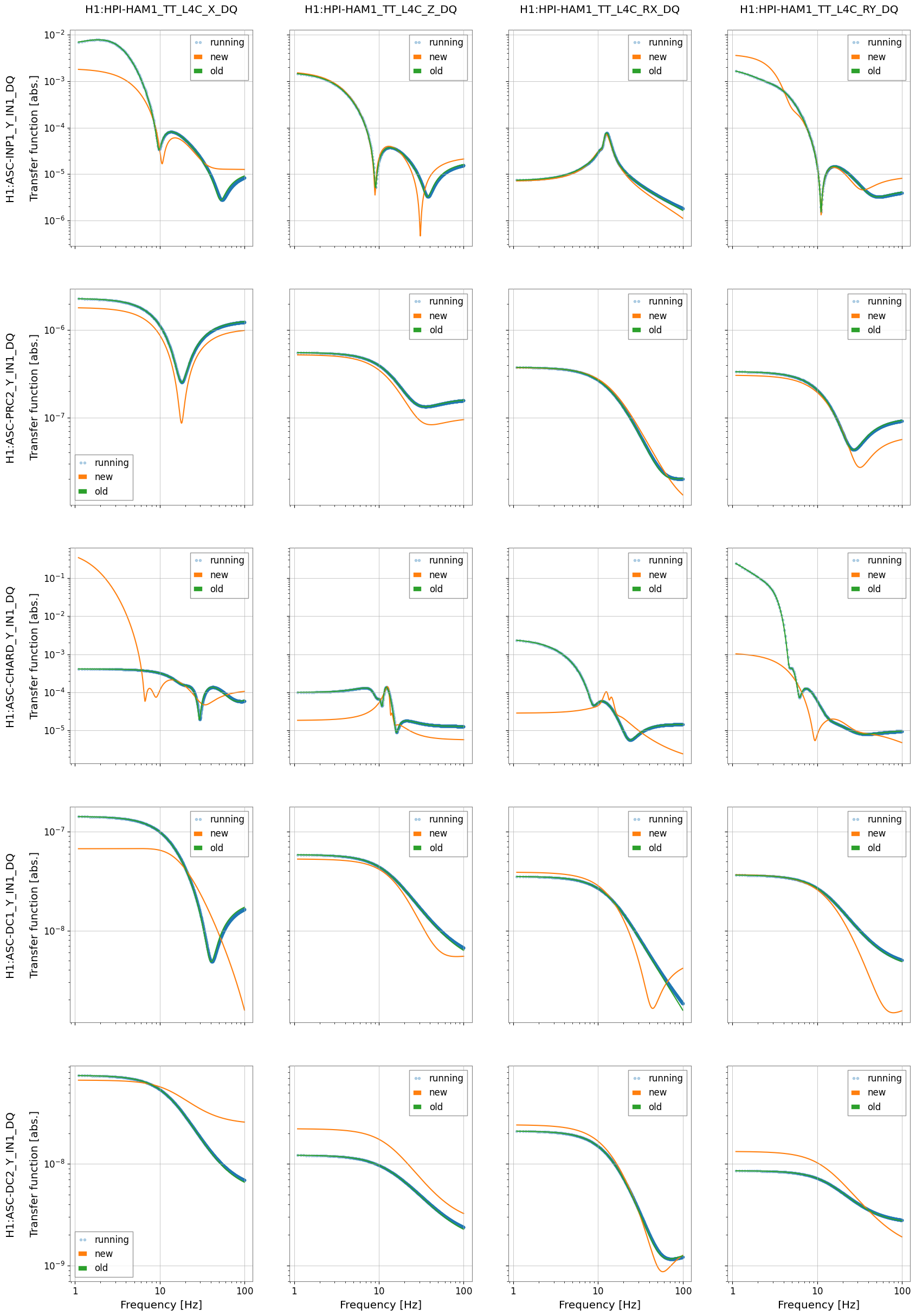
I manually changed the amplitudes for the A2L script again on a per optic bassis to get each A2L set in a first round, there was still significant CHARD P coherence. I've edited the run_all_a2L.sh script so that some degrees of freedom are run with amplitudes of 1, 3 or 10 counts excitations, this has now run and suceeded in tuning A2L for each DOF on each optic, this second round seems to have improved the sensitivity. We may need to tune these amplitudes each time we run a2L for now.
After our second round of A2L, the ASC coherences were actually worse than after only one round. We tried some manual tuning using DHARD and CHARD injections, but that didn't work well probably because we took steps that were too large.
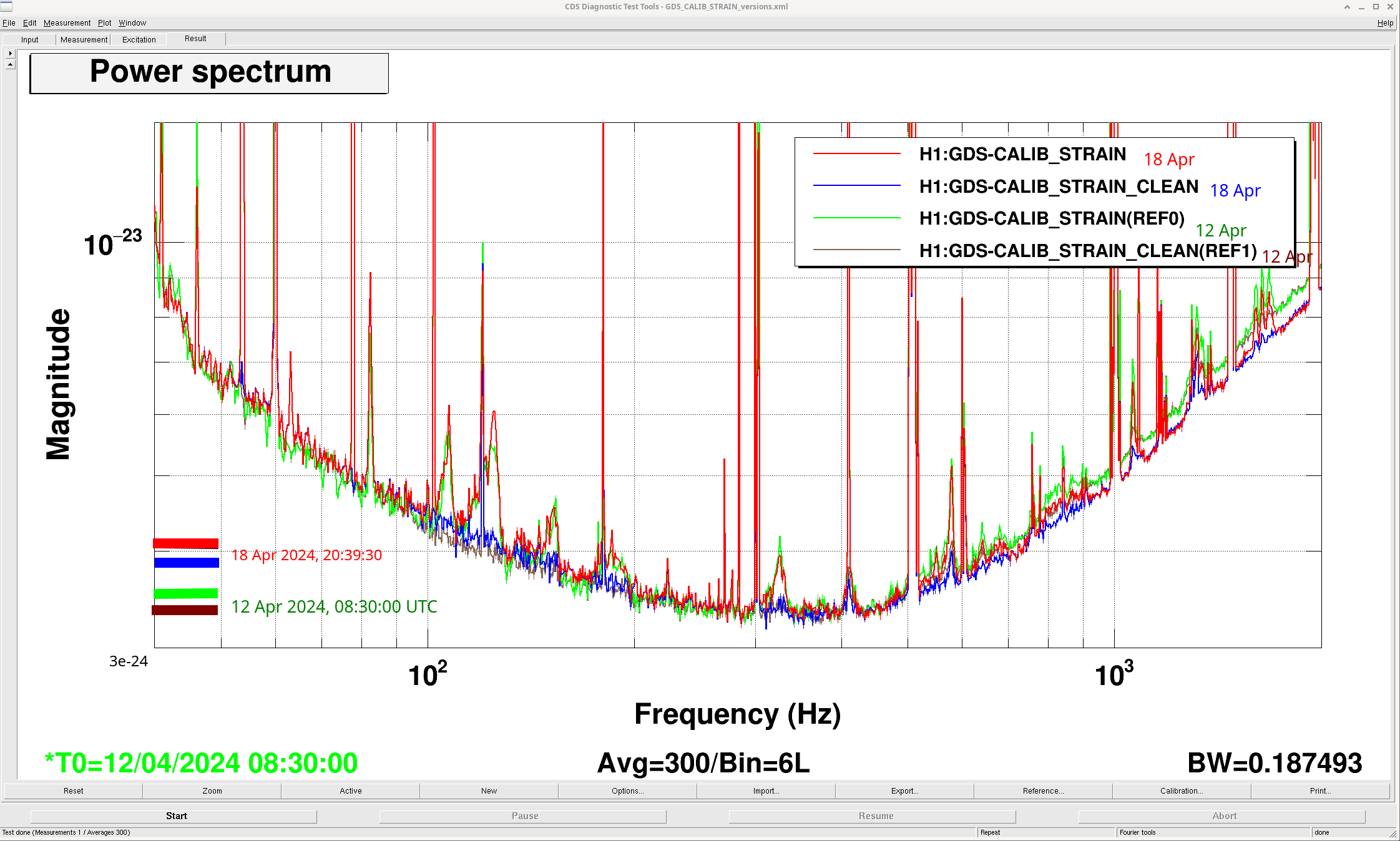
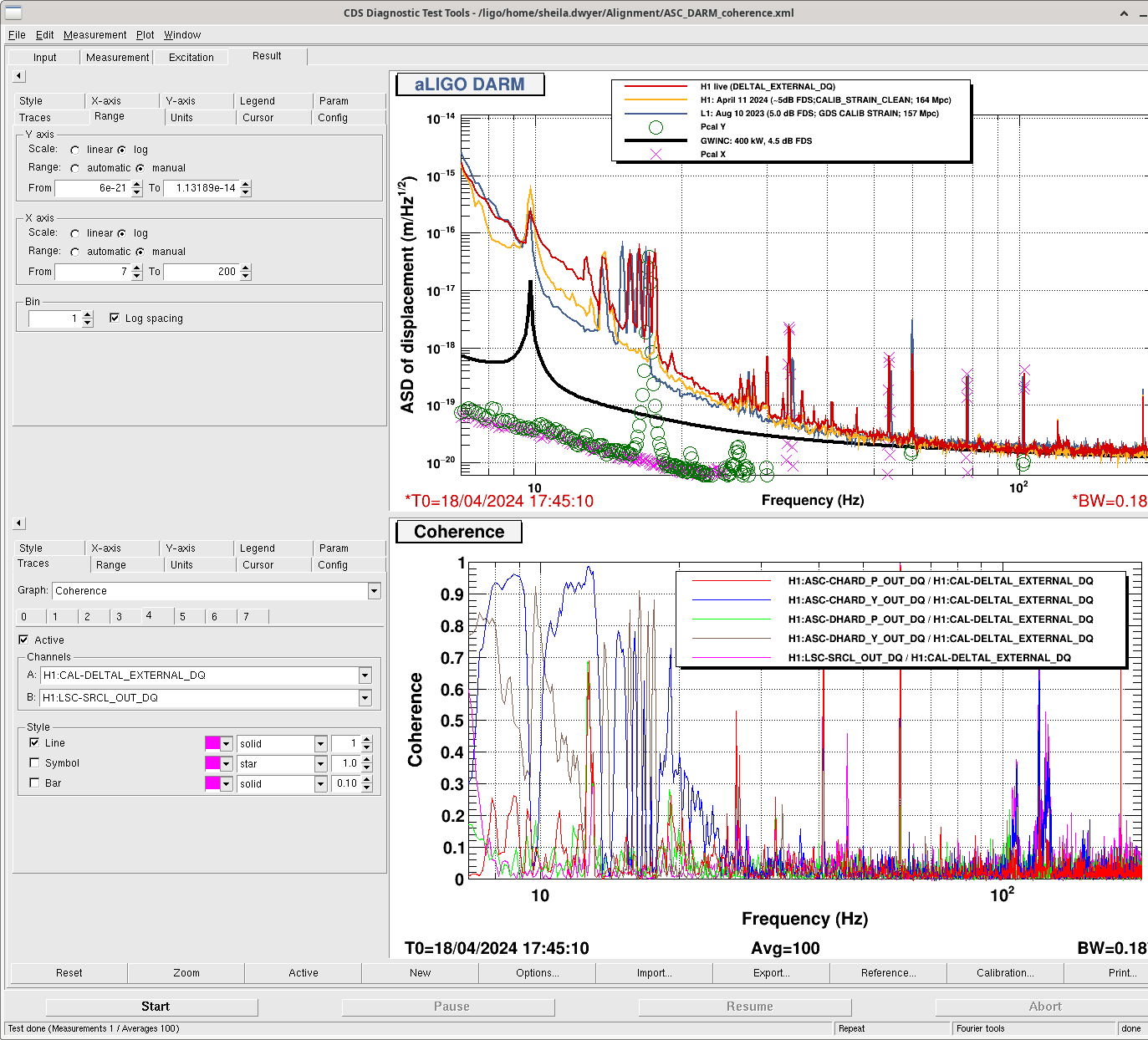
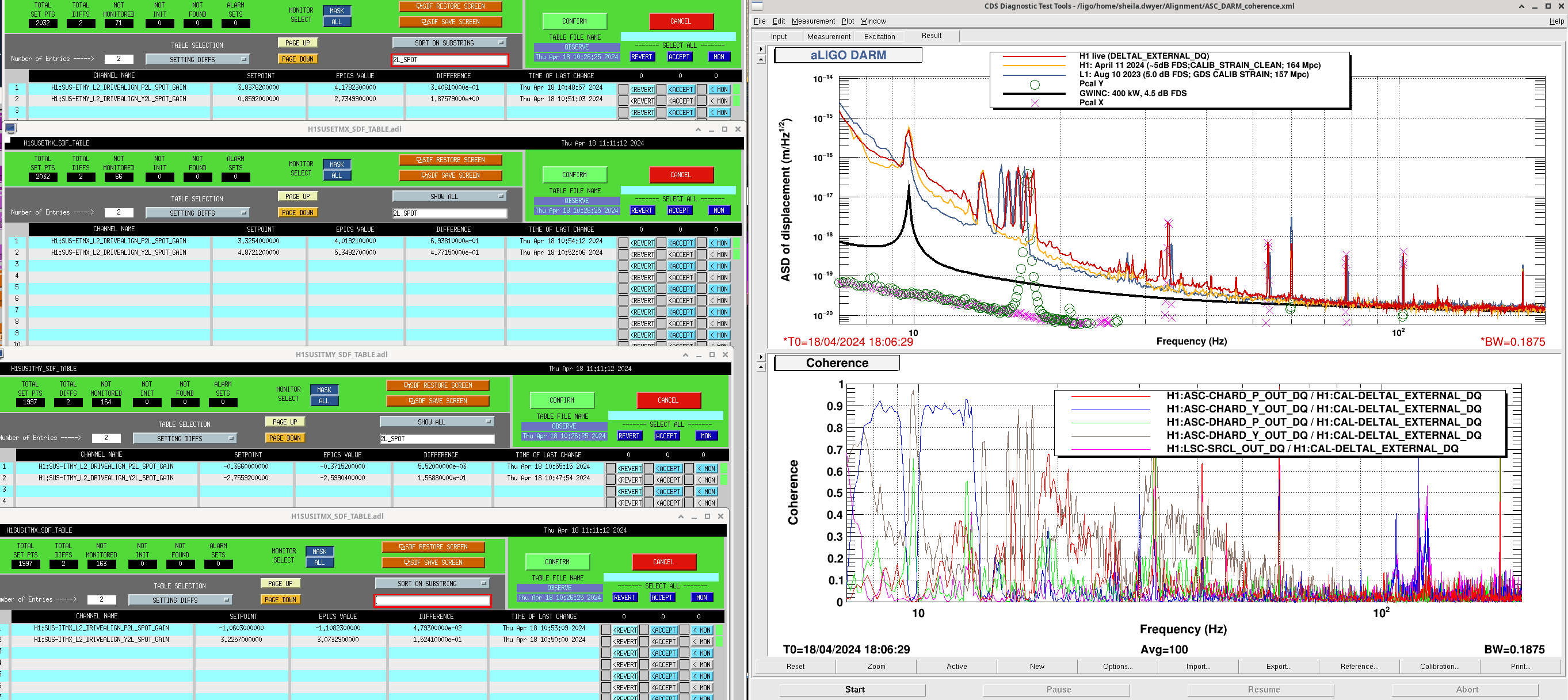
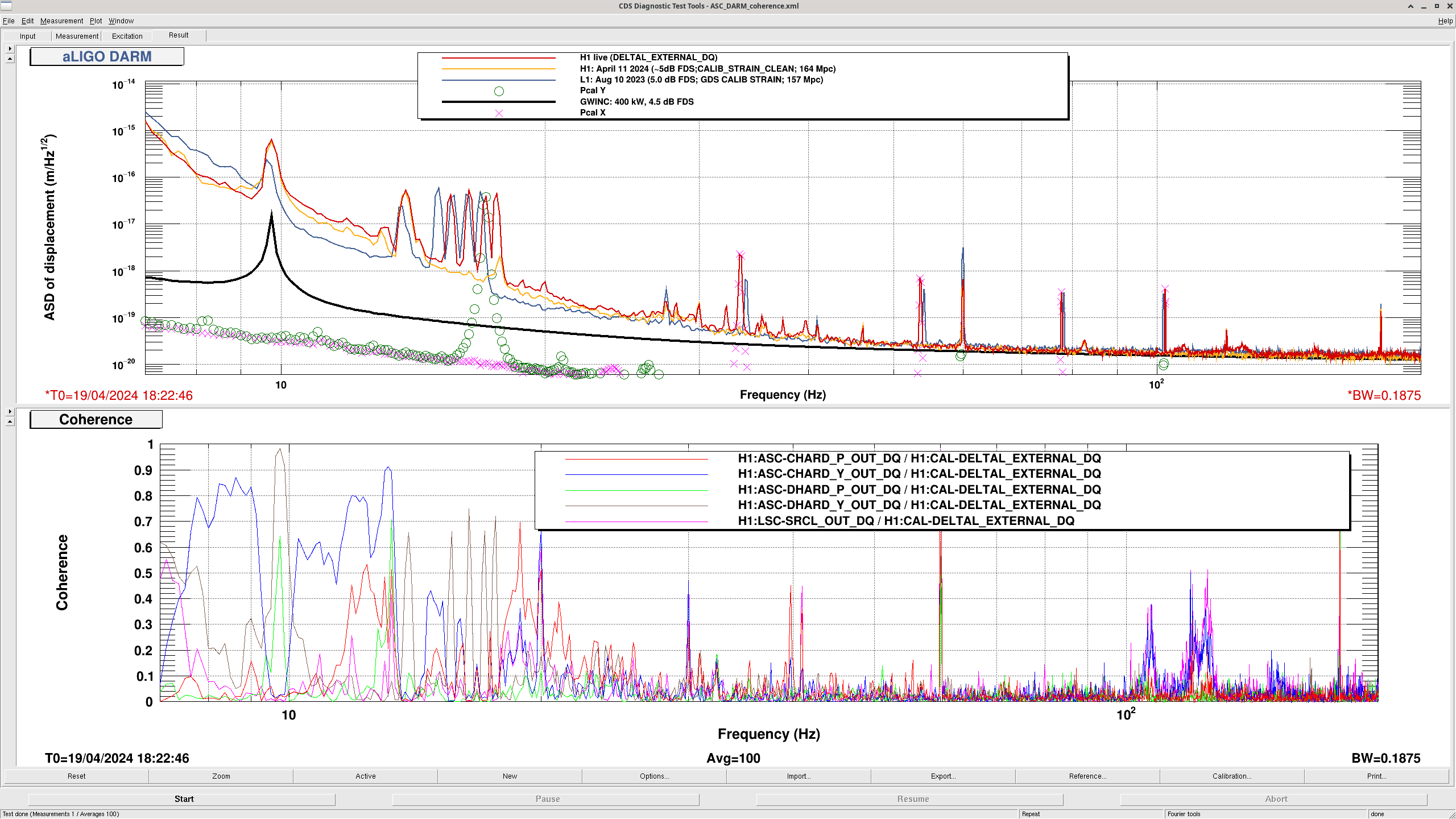
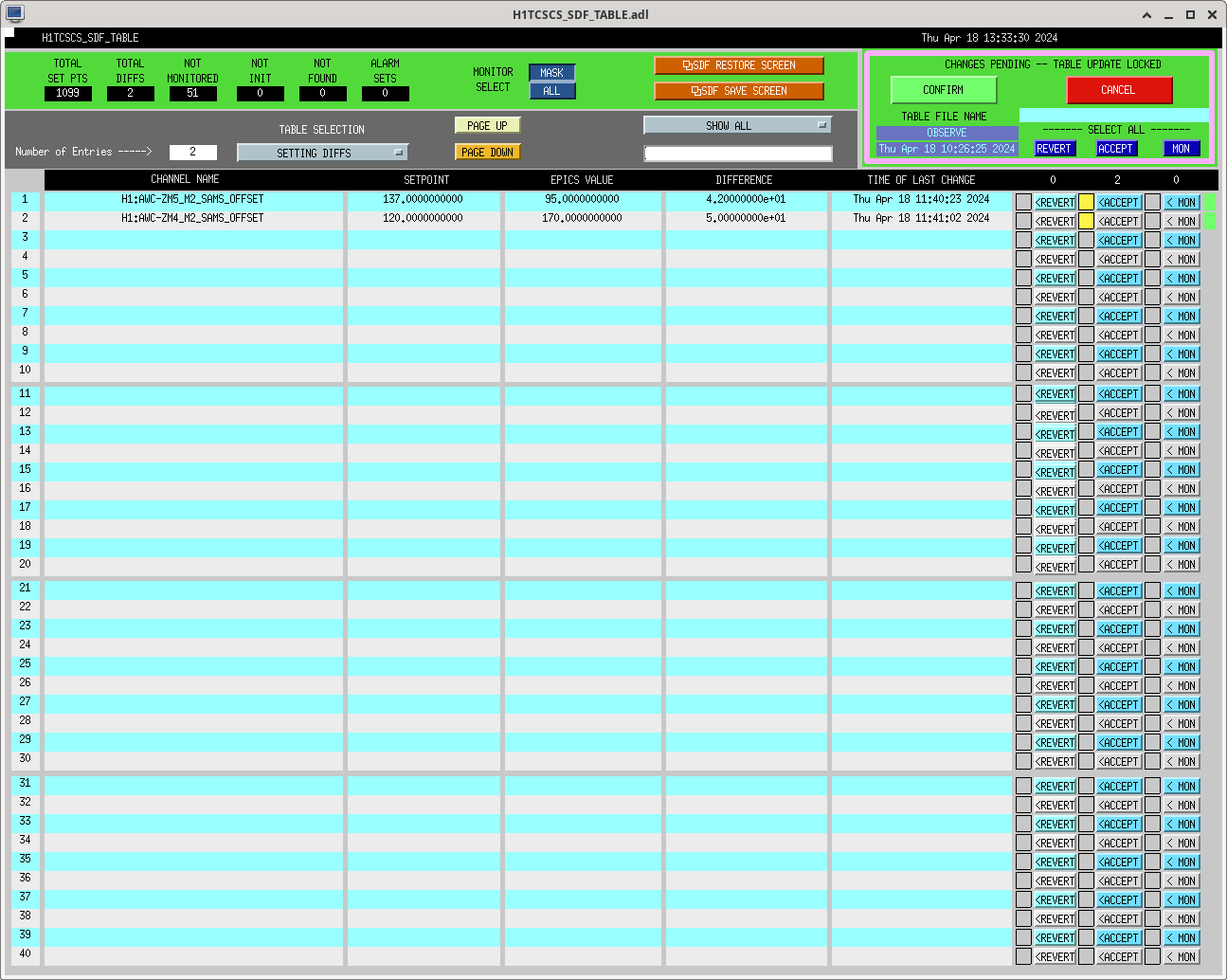
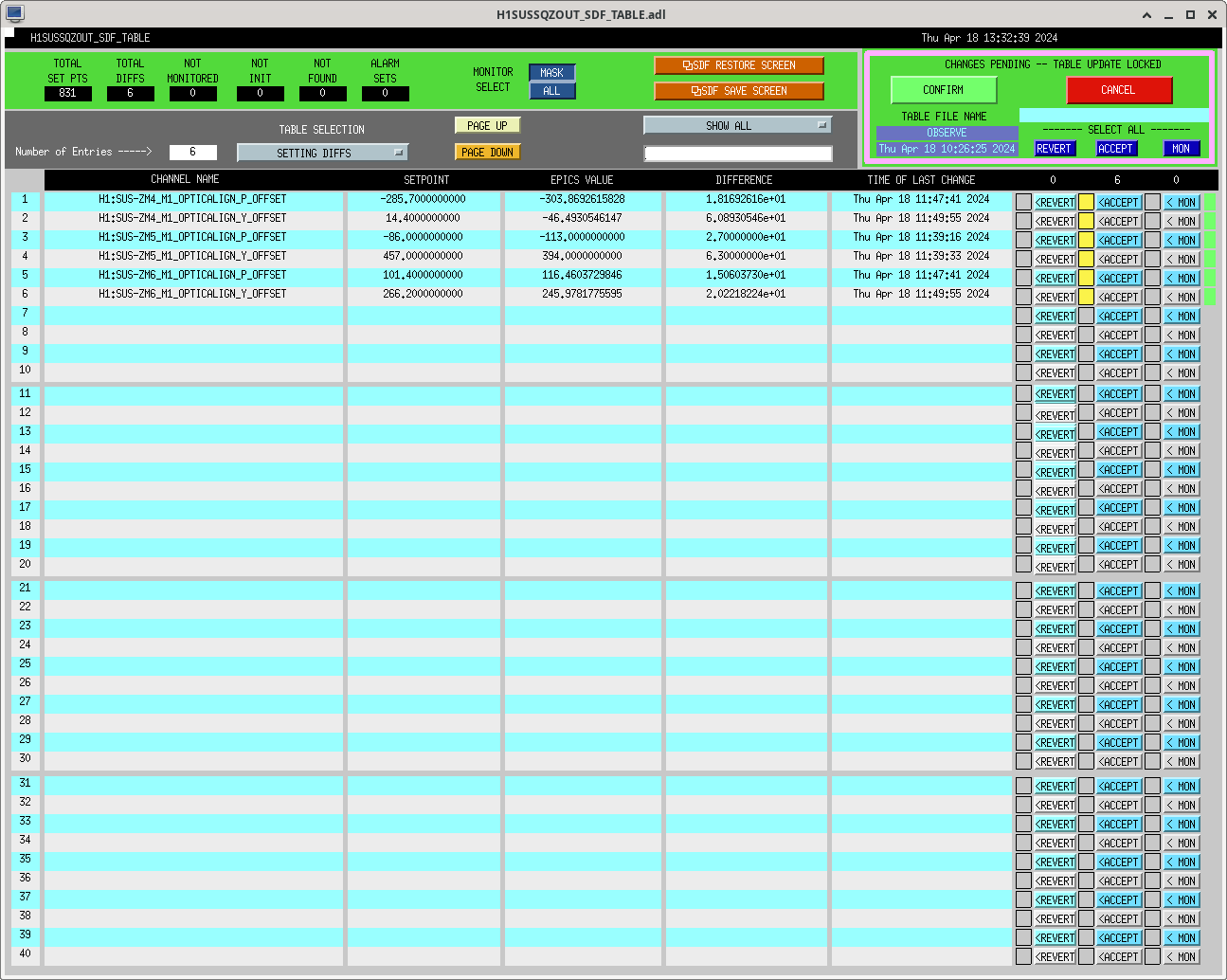
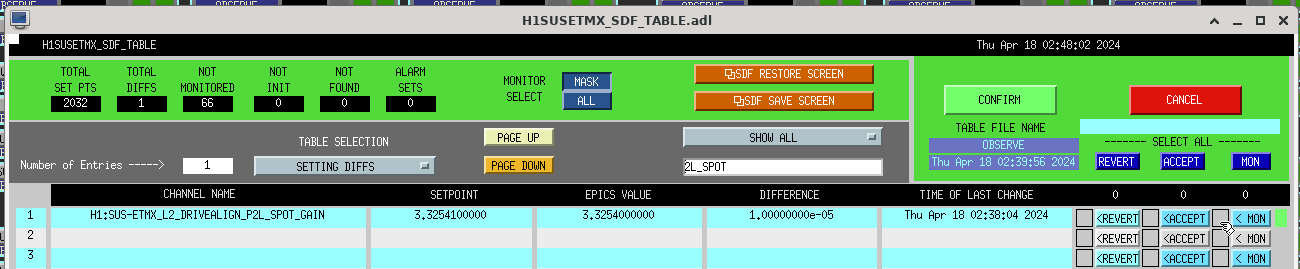
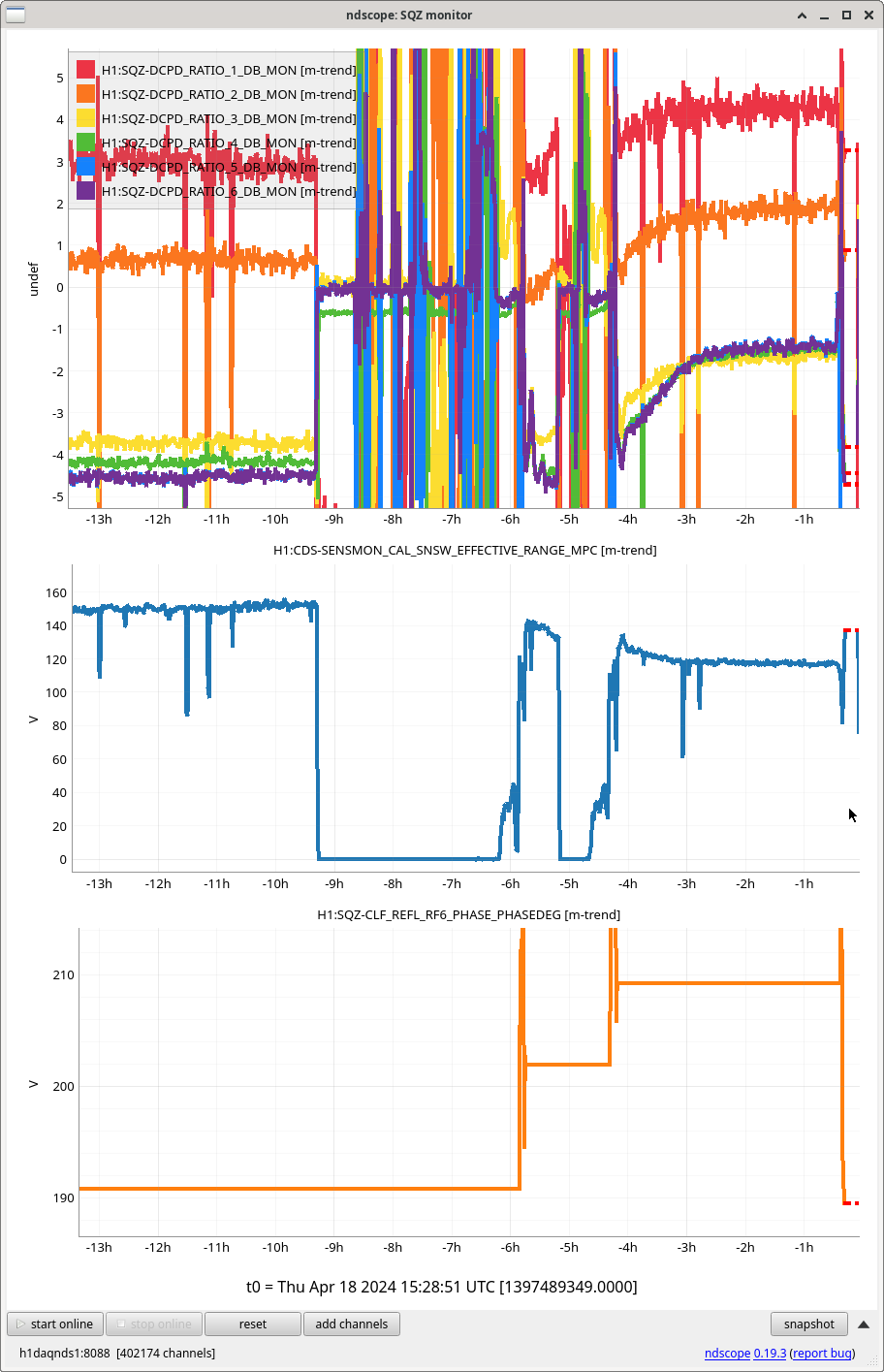
After the IFO had been locked and at high power for ~3 hours, we re-ran the A2L script again, which again set all 4 A2L gains, and impoved the range by ~5Mpc compared to the A2L settings early in the lock (see screenshot). I've accepted these in SDF and added them to LSCparams:
'FINAL':{
'P2L':{'ITMX':-0.9598, #+1.0,
'ITMY':-0.3693, #+1.0,
'ETMX':4.1126,
'ETMY':4.2506}, #+1.0},
'Y2L':{'ITMX':2.8428, #+1.0,
'ITMY':-2.2665, #+1.0,
'ETMX':4.9016,
'ETMY':2.9922 },#+1.0}
This means that the A2L probably won't be well tuned for early in the locks when we relock, which may cost us range early in the locks. In O4a we werw also using the camera servo, not ADS, and since we set the camera servo offsets to match ADS alignment early in the locks, we probably had less than optimal decoupling late in the lock stretches. This probably had less of an impact on range since these noises are contributing in the same frequency range as the ESD noise was in O4a.