Naoki, Corey, Vicky
Corey is taking it to OBSERVE without squeezing tonight.
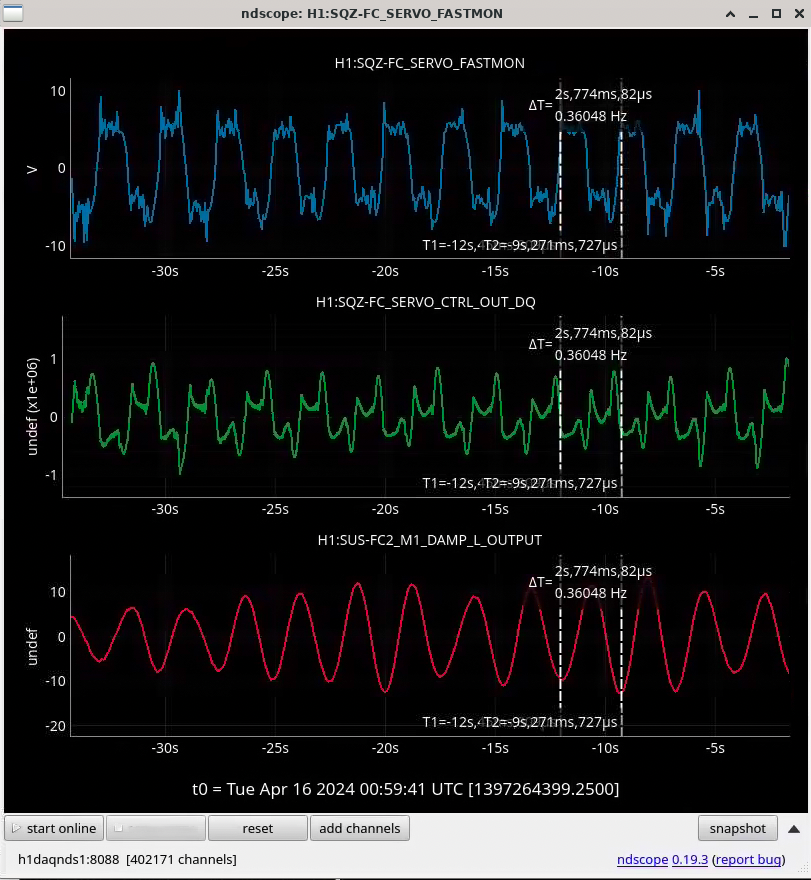
We traced down an issue to FC2 0.3-0.5 Hz oscillations, which maybe is worse right now due to wind. We think this excess FC2 motion is preventing FC from locking.
FC2 0.3-0.5 Hz oscillations screenshot - see the FC Green VCO control signal trying to lock and failing - at the same time, we can see the FC2_M1_L oscillations around 0.4 Hz, even with no control signals sent to FC2 SUS. So, seems like FCGS VCO is trying to track the FC2 L oscillations, but the real FC2 motion is too much for the FCGS VCO to hold lock, and this prevents further locking. Corey says perhaps this FC2 motion is extra bad right now due to the wind. I don't remember this issue in O4a. Without FC2 L motion calming down a bit, I don't think we can hold a stable FC lock.
So, we decided to go to Observe without SQZ tonight, at least until the wind calms down. Maybe could try SQZ later if wind calms down.
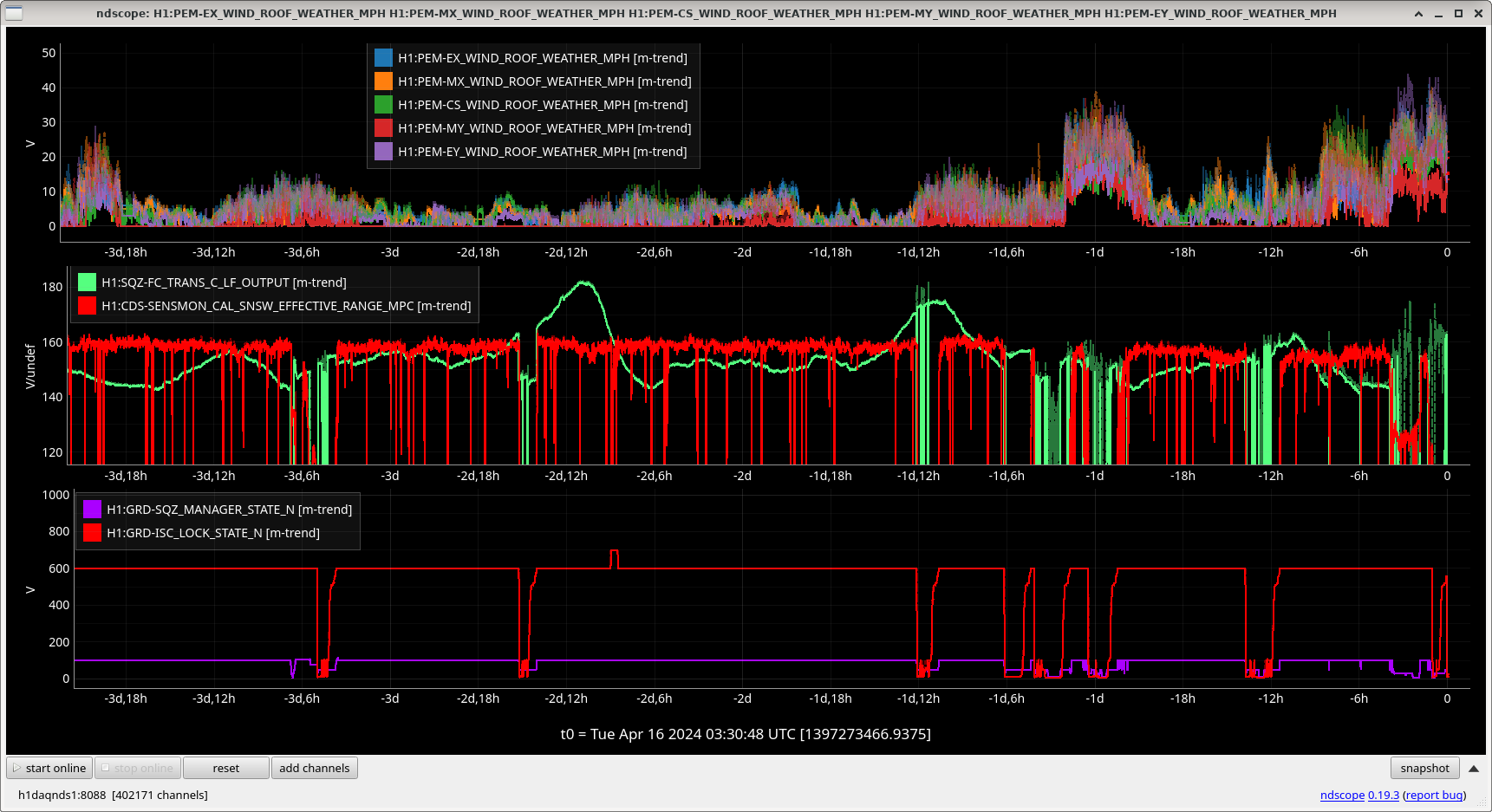
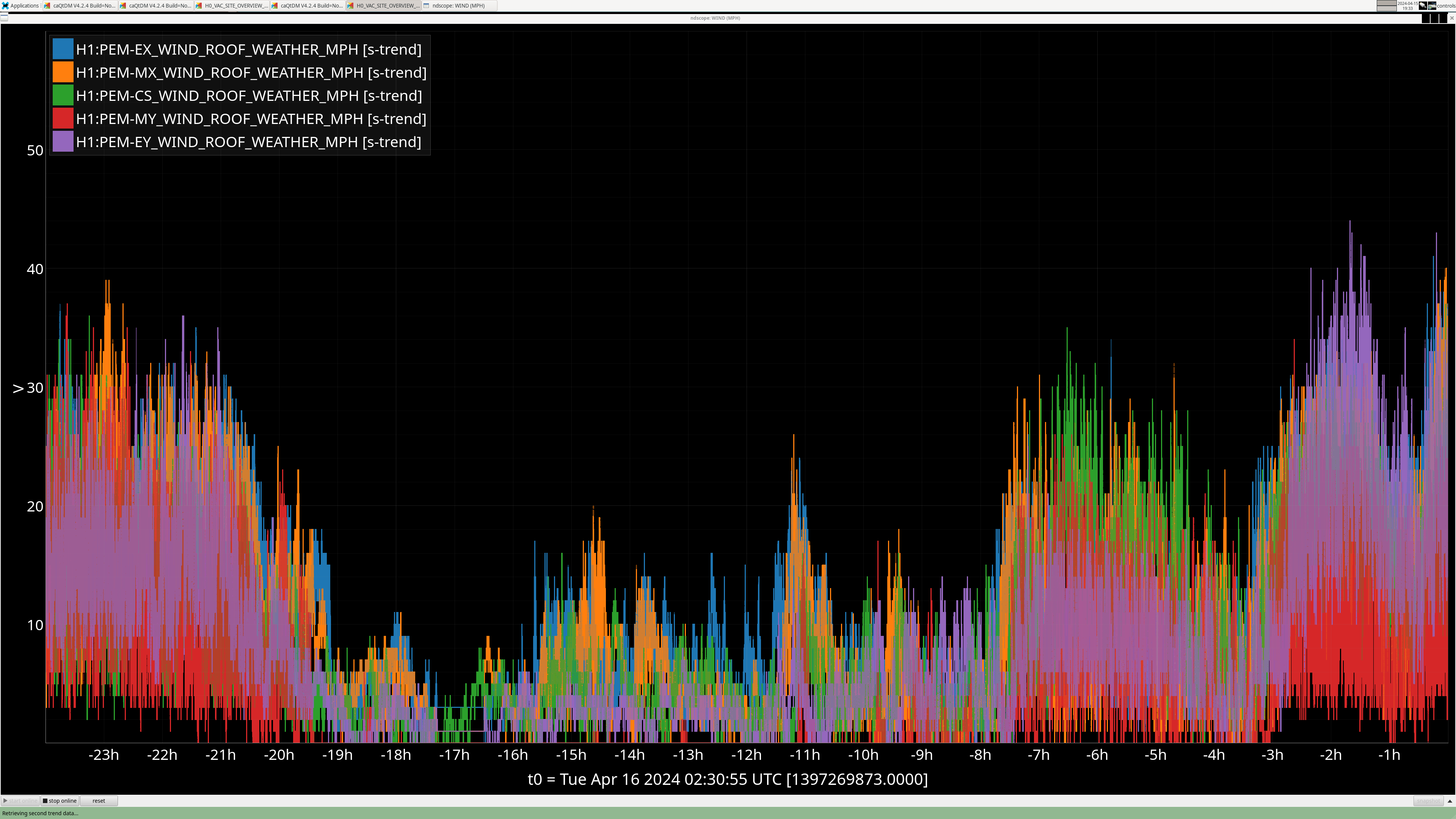
Edit: It seems FC has been struggling to lock with winds > 30-40 MPH these last couple days, see screenshot with FC locking and wind speeds.
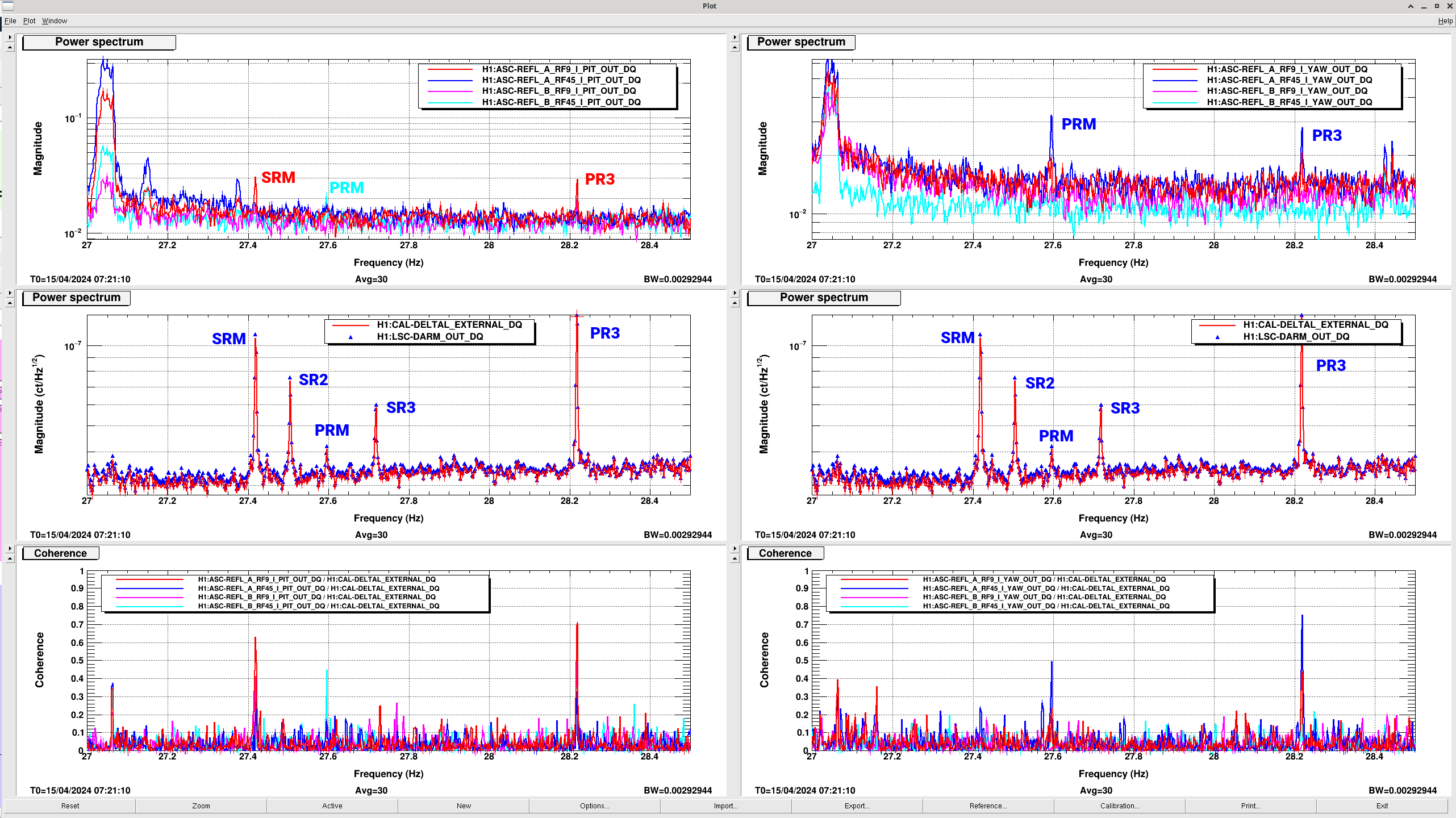
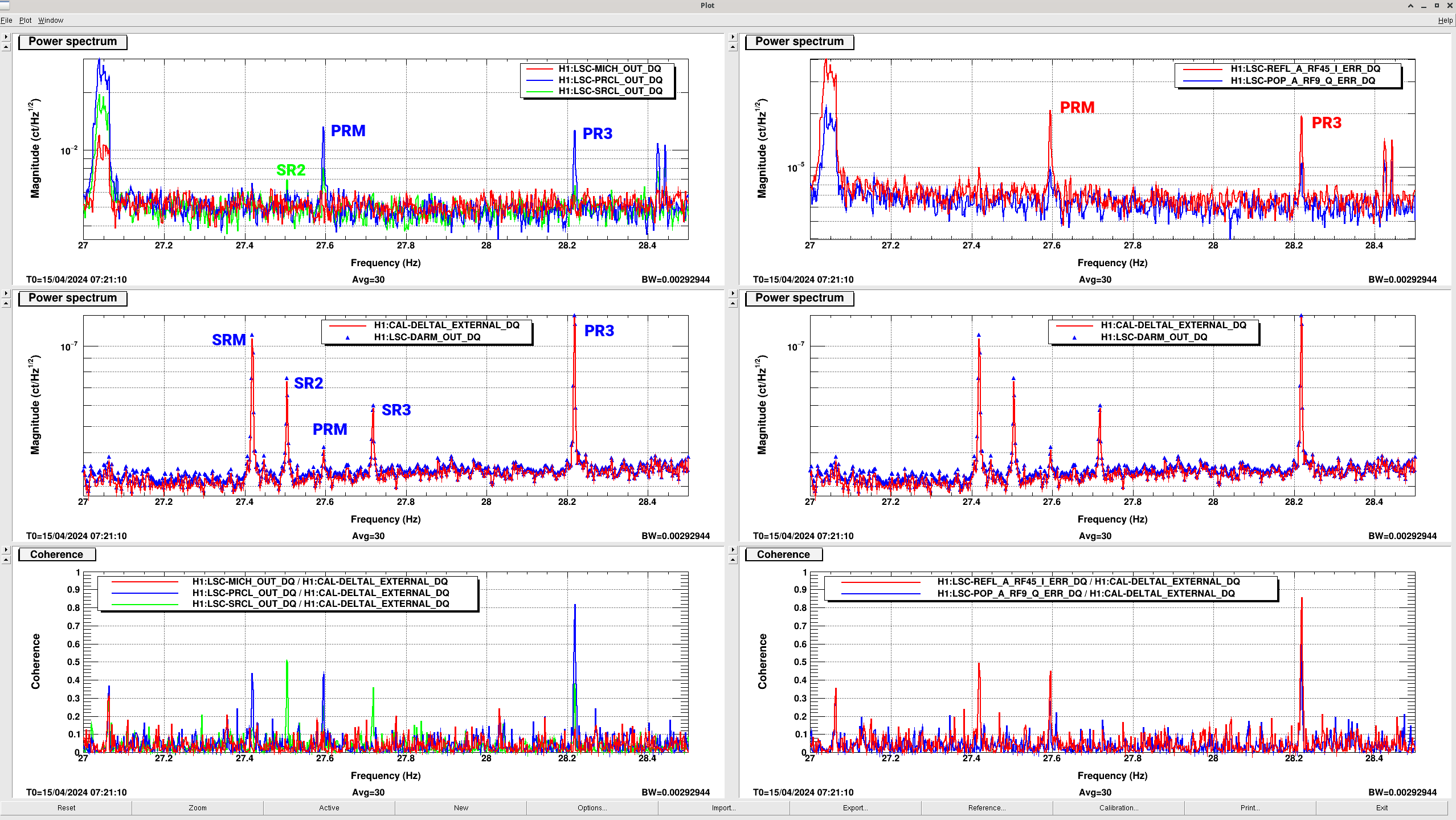
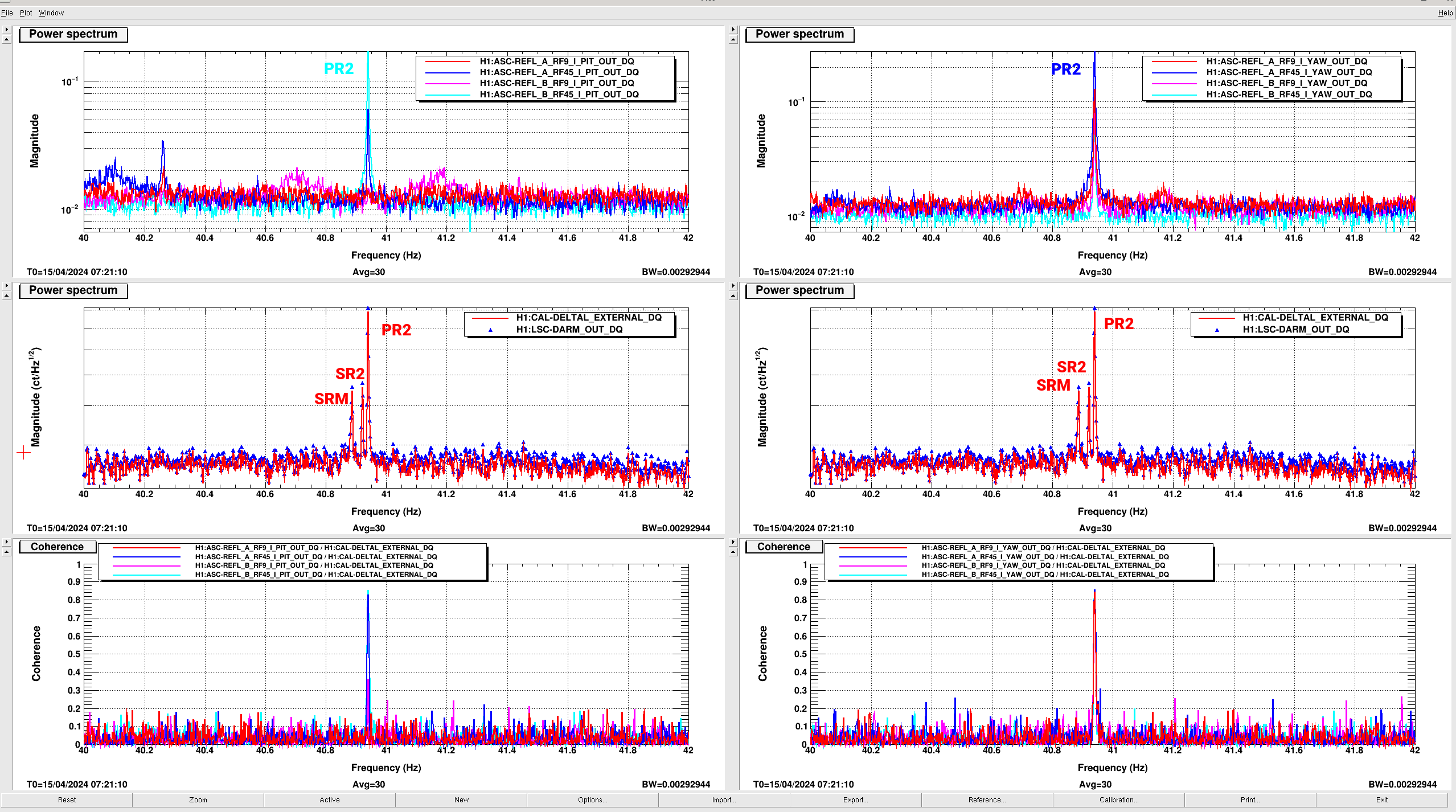
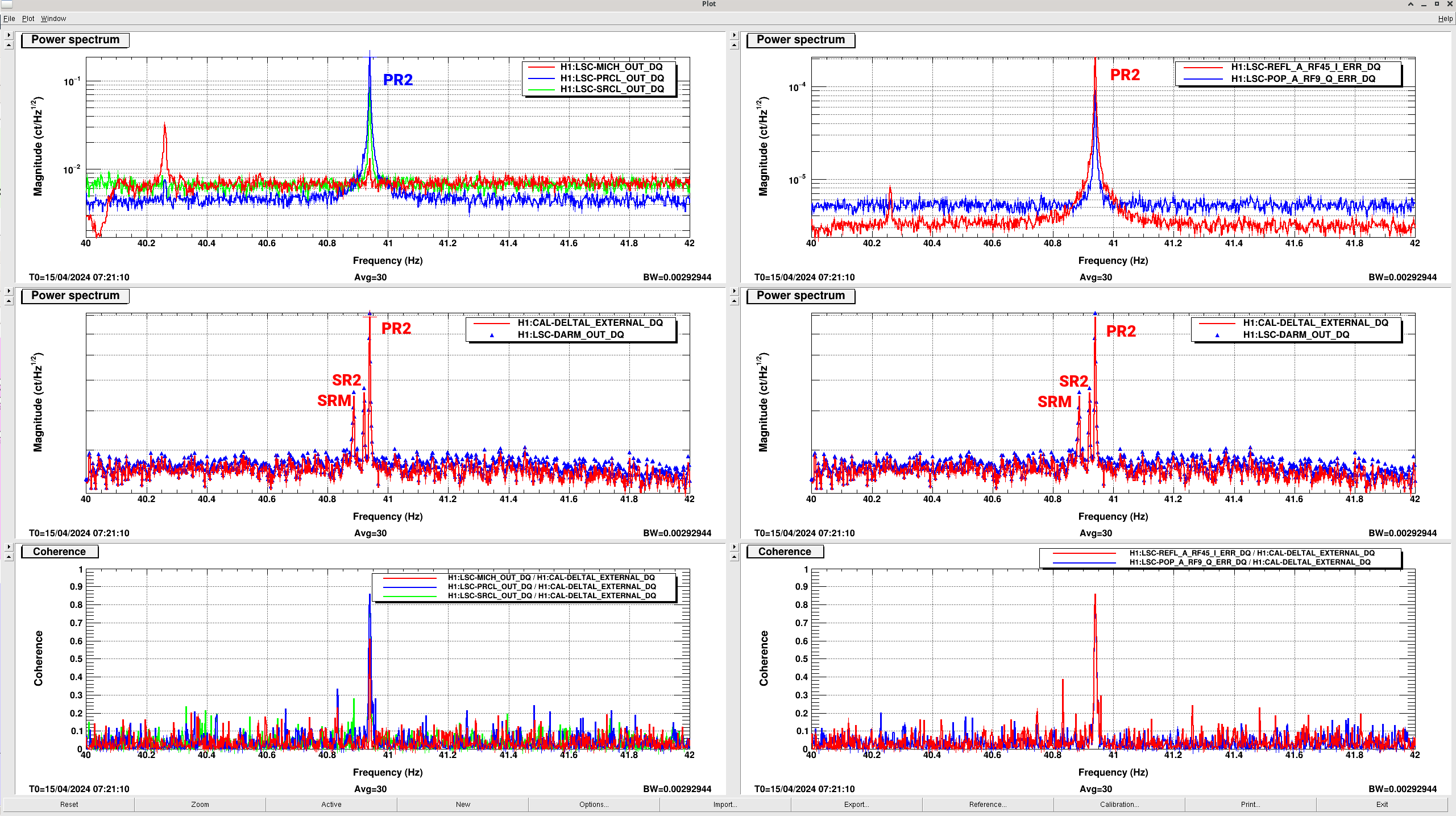


SRC wouldn't lock, but flashes looked good. Somehow, it looks like the changes I made switching from POP_A to AS_C got reverted (<a href="https://alog.ligo-wa.caltech.edu/aLOG/index.php?callRep=77113">alog77113</a>). As soon as I switched back to using AS_C with 0.005 and 0.004 thresholds it locked right up.
I'll also have to check on why this was reverted when I get in.