Since PMC is so sensitive to acoustic noise I was curious if PMC added additional contributions to the sqz phase noise. So, I did the same SQZ phase noise budget analysis that was done in O3. The explanation and the methodology can be found in P2200287 chapter 6.3.1 onward.
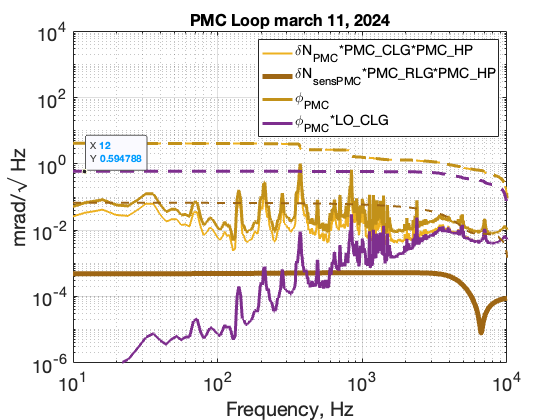
PMC noise contribution to sqz phase noise is 0.59 mrad. There's no need to put extra efforts into damping the cavity unless people are annoyed that it loses lock everytime we use some of the motorized half wave plate.
The FWHM and FSR of the PMC was measured by Vicky at MIT. They are 175MHz and 713 MHz respectively. We didn't repeat this measurement after the installation because the LVEA was too loud and the finesse is high for s-pol (4070).
The Vpp calibration for the PMC is 2.22 Vpp/FWHM. This was measured after the PMC was installed. In order to fit the transfer function I had to multiply a factor of 1.5. Vicky mentioned the PMC PZT is very nonlinear so my V/Hz calibration could be off. If that's true then the PMC trace needs to be multiplied by a factor of 1.5.
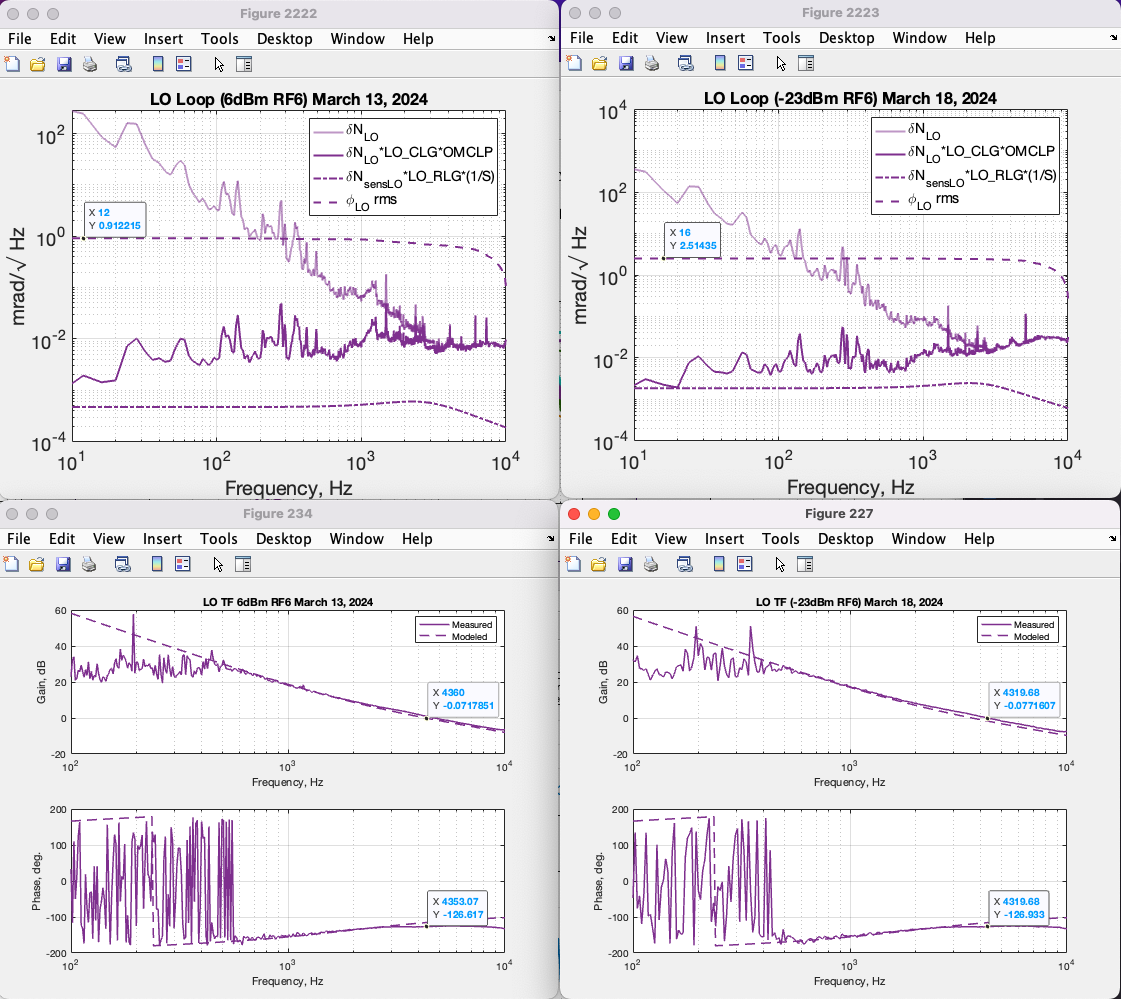
I had to multiply a factor of 0.33 to the CLF and LO loop in order to fit the transfer function. Even after using the new VCO V to Hz calibration that Daniel measrued. I suspect the Vpp/rad calibration was over estimated due to RLF. If that's true then the LO and CLF traces shown in this alog needs to be multiplied by a factor of 0.33.
The PZT driver for the PMC is the same as in the SHG and the OPO
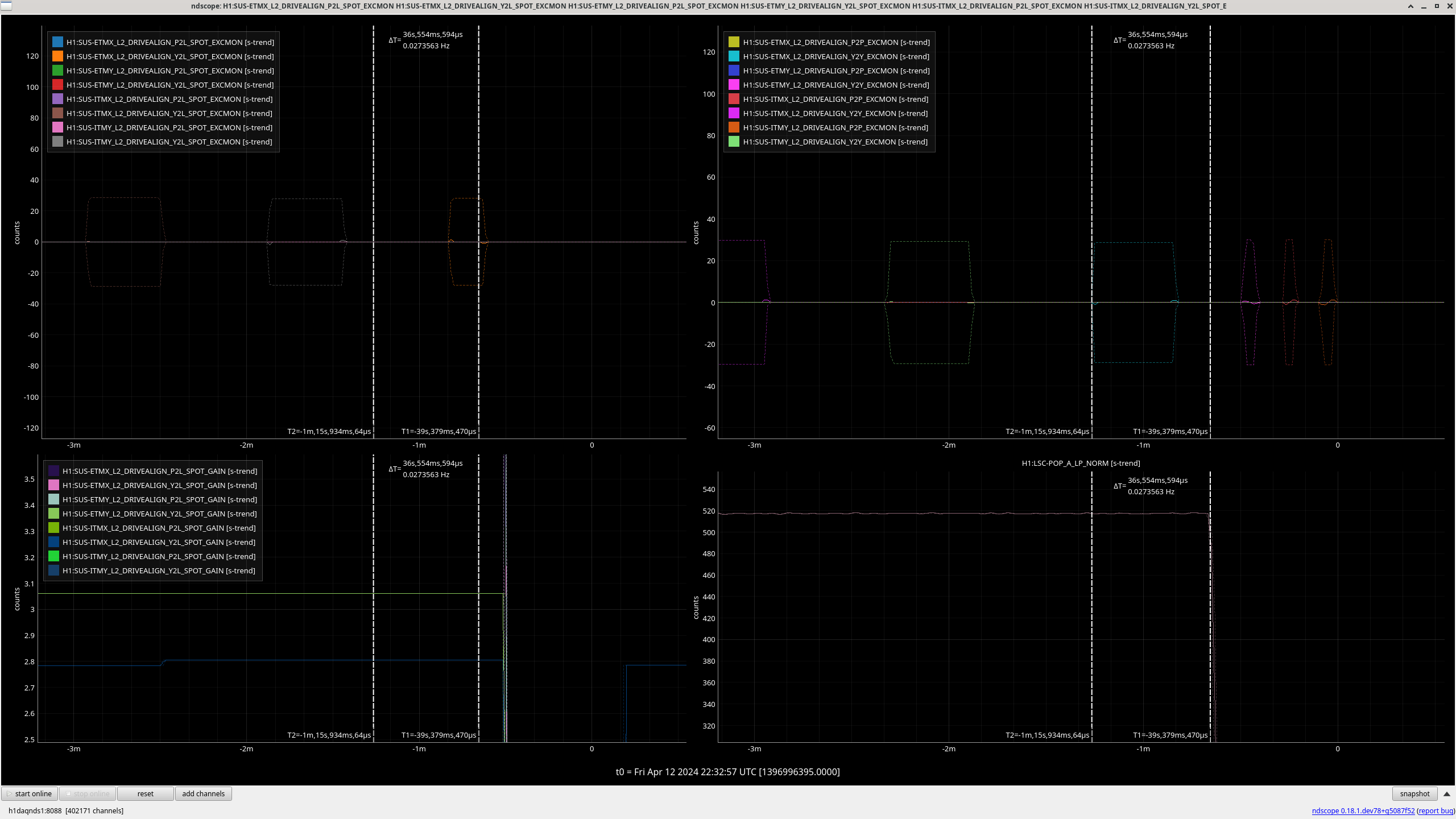
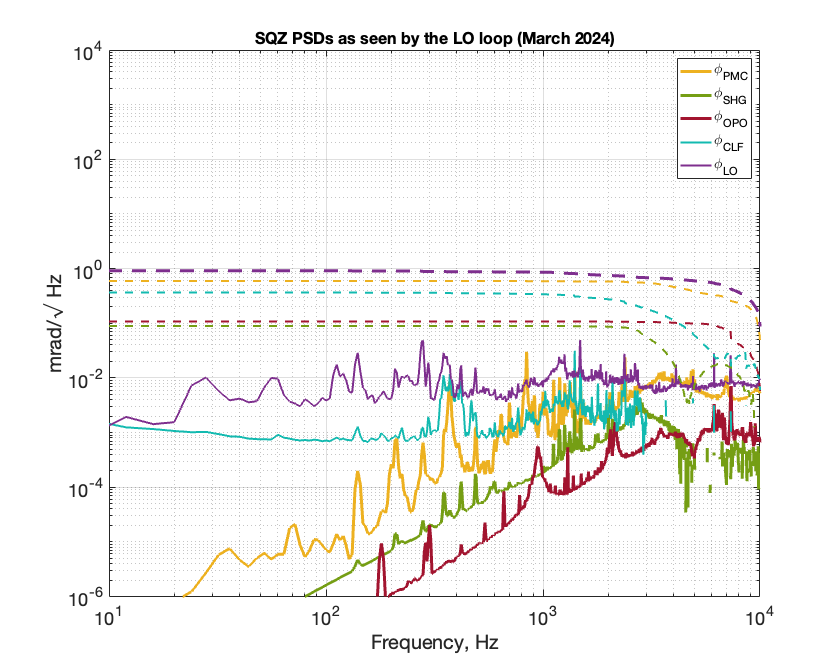
This plot shows overall noise contributions to the sqz angle from all the sqz loops. The data were taken in between 11-18 March 2024 (pre O4b). The rms from different loops are added in quadrature to get sqz phase noise. I don't have filter cavity red lengthnoise data handy but a rough calculation from Dhruva's measurement back in February last year the lengthnoise should be sitting at 0.3 mrad/sqrt(Hz) at a 100Hz. If the rms scales the same way that's 3 mrad added in quadrature with the rest of the noise contributions.
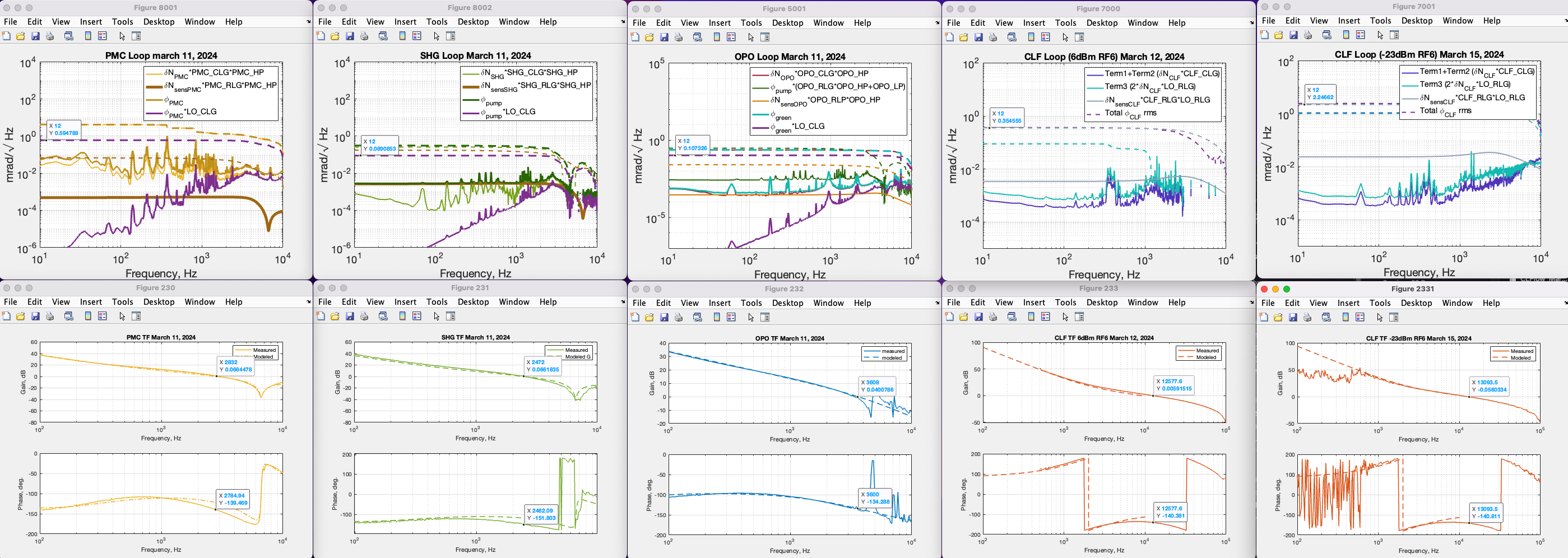
This screenshot shows more details analysis from PMC, SHG, OPO, CLF (6dBm and -23dBm) along with the transfer functions and sensing noise.
A separate screenshot for LO loop, low and high CLF power, with the transfer functions and sensing noise.
The table below lists all the noise contribution from sqz loops to sqz angle. Until we achieve a single digit % loss these numbers are negligible. The major contribution to sqz angle pahse nosie still comes from the IFO control signal sidebands. I didn't remeasure the TTFSS noise so I used the in-loop rms number from last year.
| SQZ phase noise |
Low CLF (mrad) |
high CLF (mrad) |
| TTFSS (phi laser) |
0.03 |
0.03 |
| PMC |
0.59 |
0.59 |
| SHG |
0.089 |
0.089 |
| OPO |
0.11 |
0.11 |
| CLF |
2.25 |
0.37 |
| LO |
2.5 |
0.91 |
| FC |
2.6 |
2.6 |
| total |
4.294359207 |
2.844999297 |