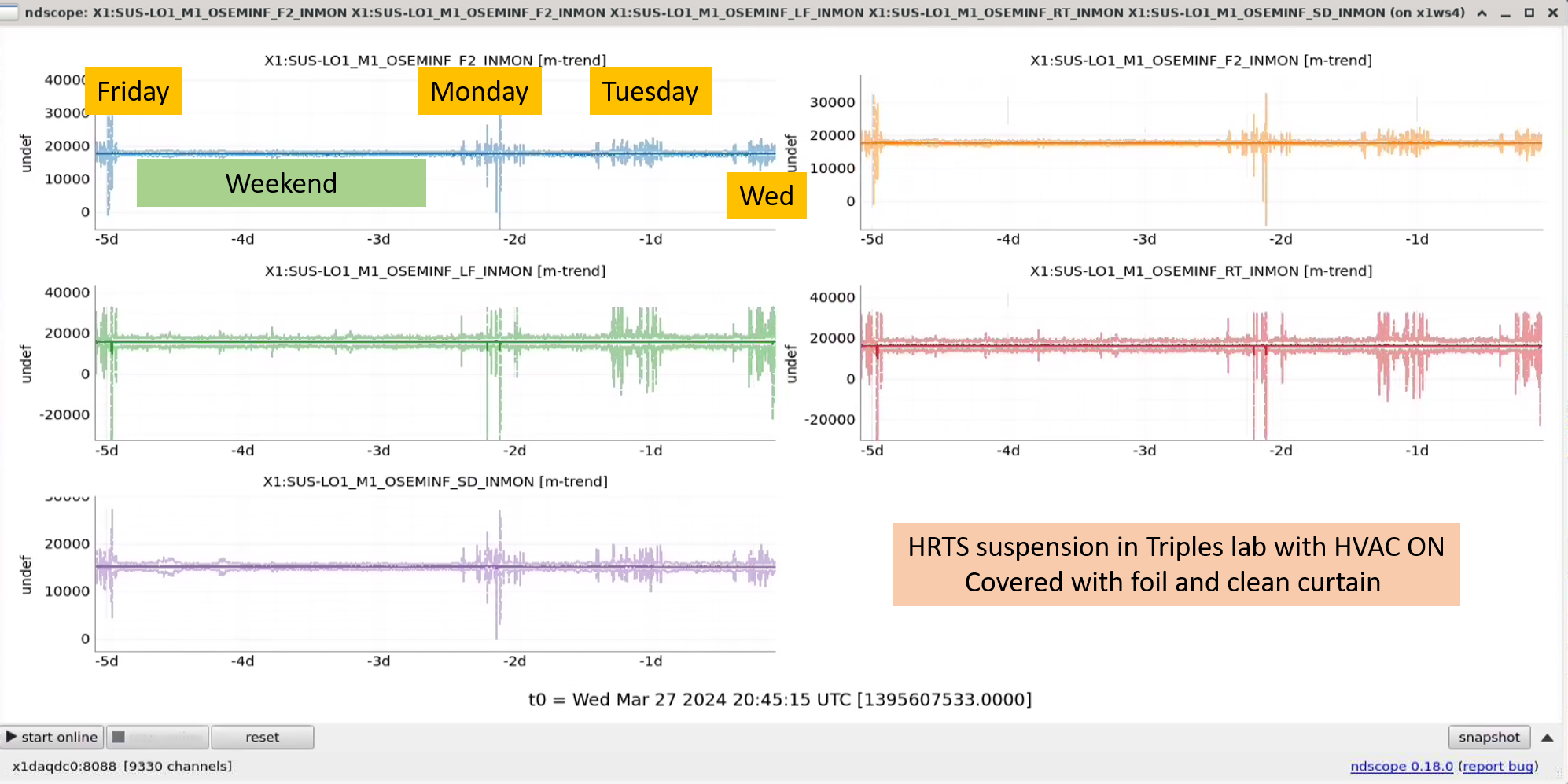
Jennie W, Jenne
Yesterday, on advice from Sheila to we are trying to decouple the alignment changes to IM1, IM3, IM4, PRM and PR2 in this entry from any changes we may be making to the jitter coupling.
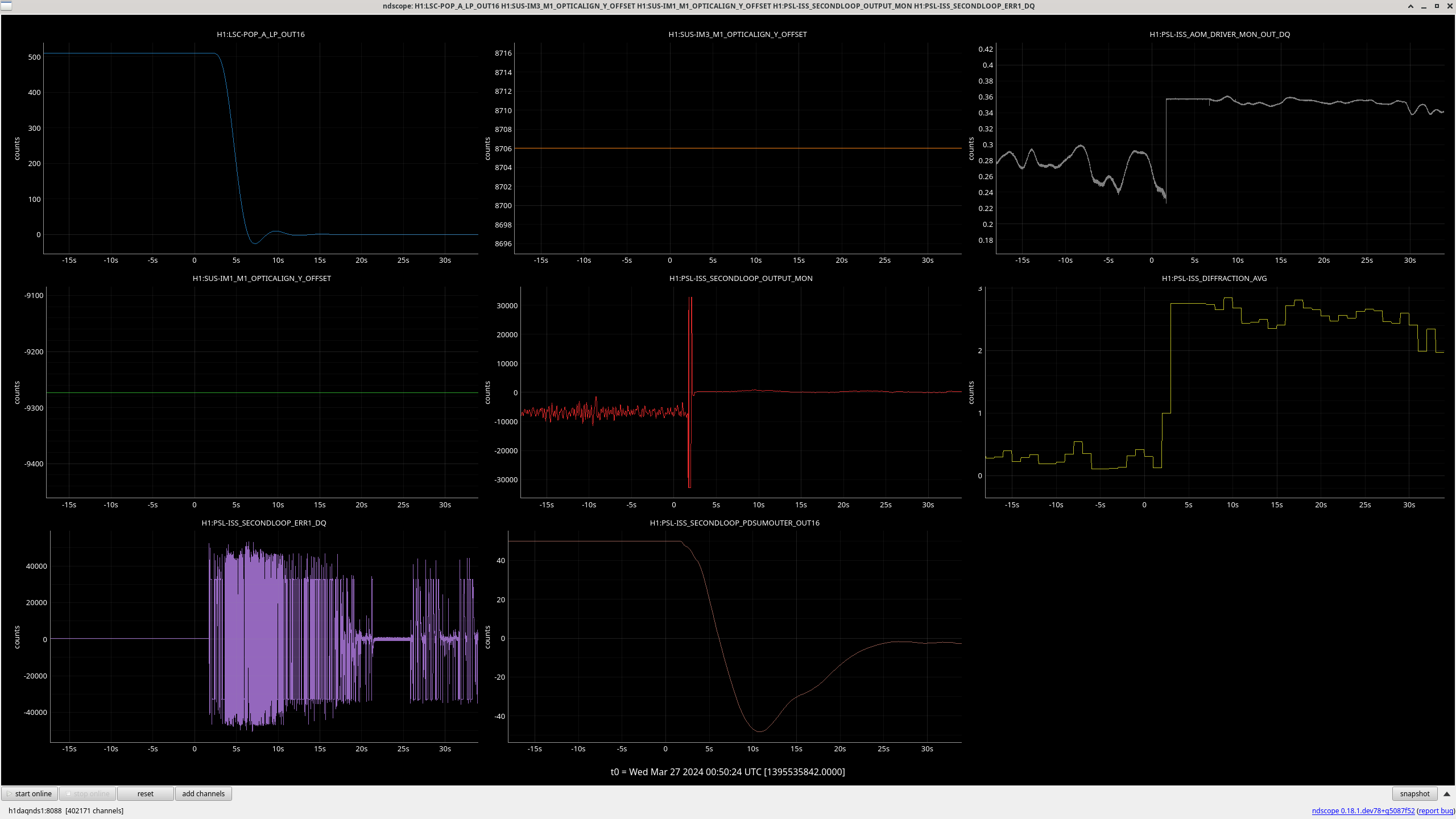
So the plan is to move just PRM to the place Gabriele and I had moved it to. This was about 284 counts on SUS-PRM_M1_DAMP_INMON on 22:44:25 UTC on 2024-03-21 when we had being making these changes.
Firstly I did this on the alignment sliders and then realised this is compensated for by camera servo YAW1 which changes the PRM to keep the spot on the BS constant so we need to actually change the camera servo offset to move the PRM.
Jenne has turned on ADS lines but we will remain on camera servos for this test and tweak the ASC-CAM_YAW1_OFFSET which will move PRM.
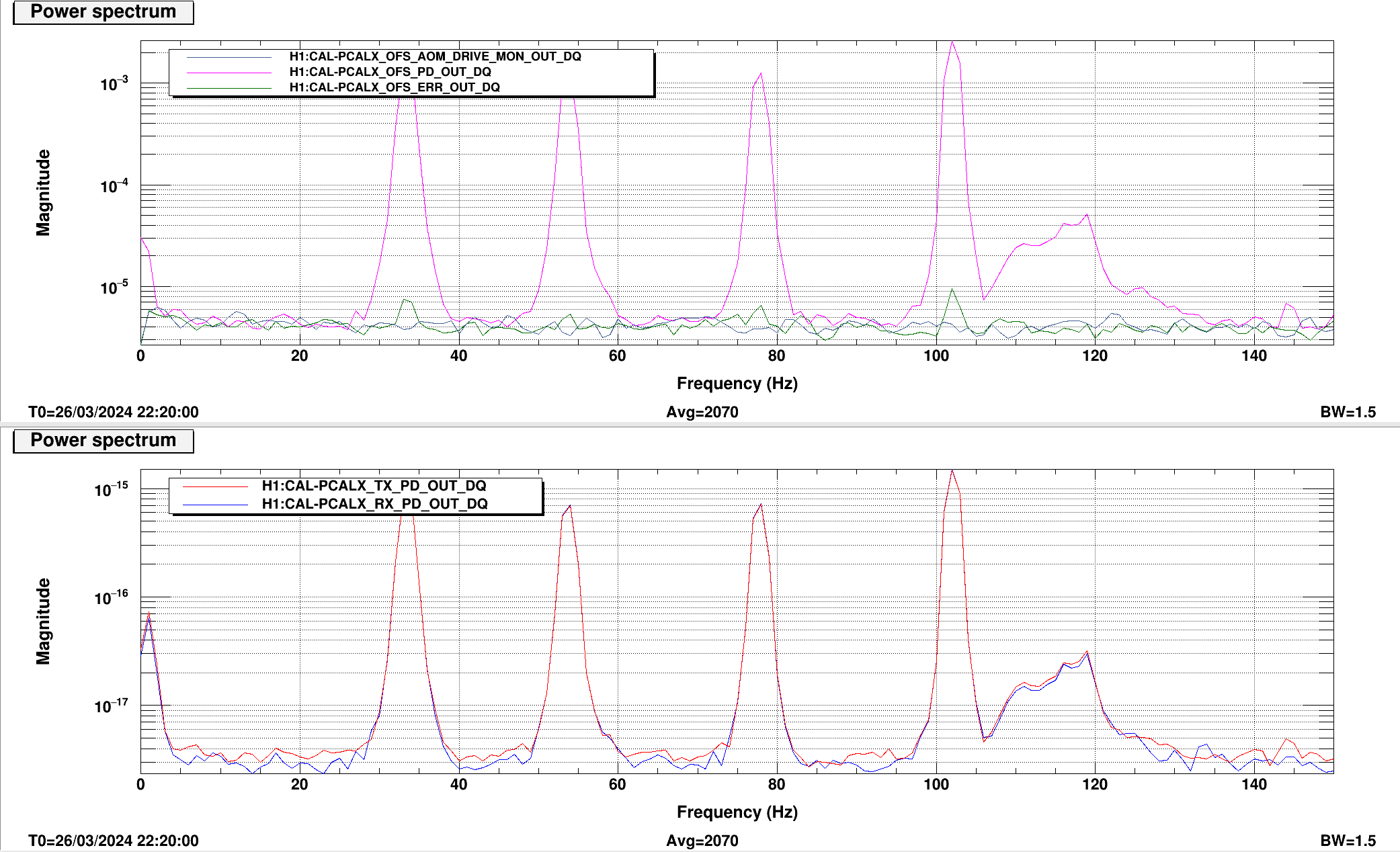
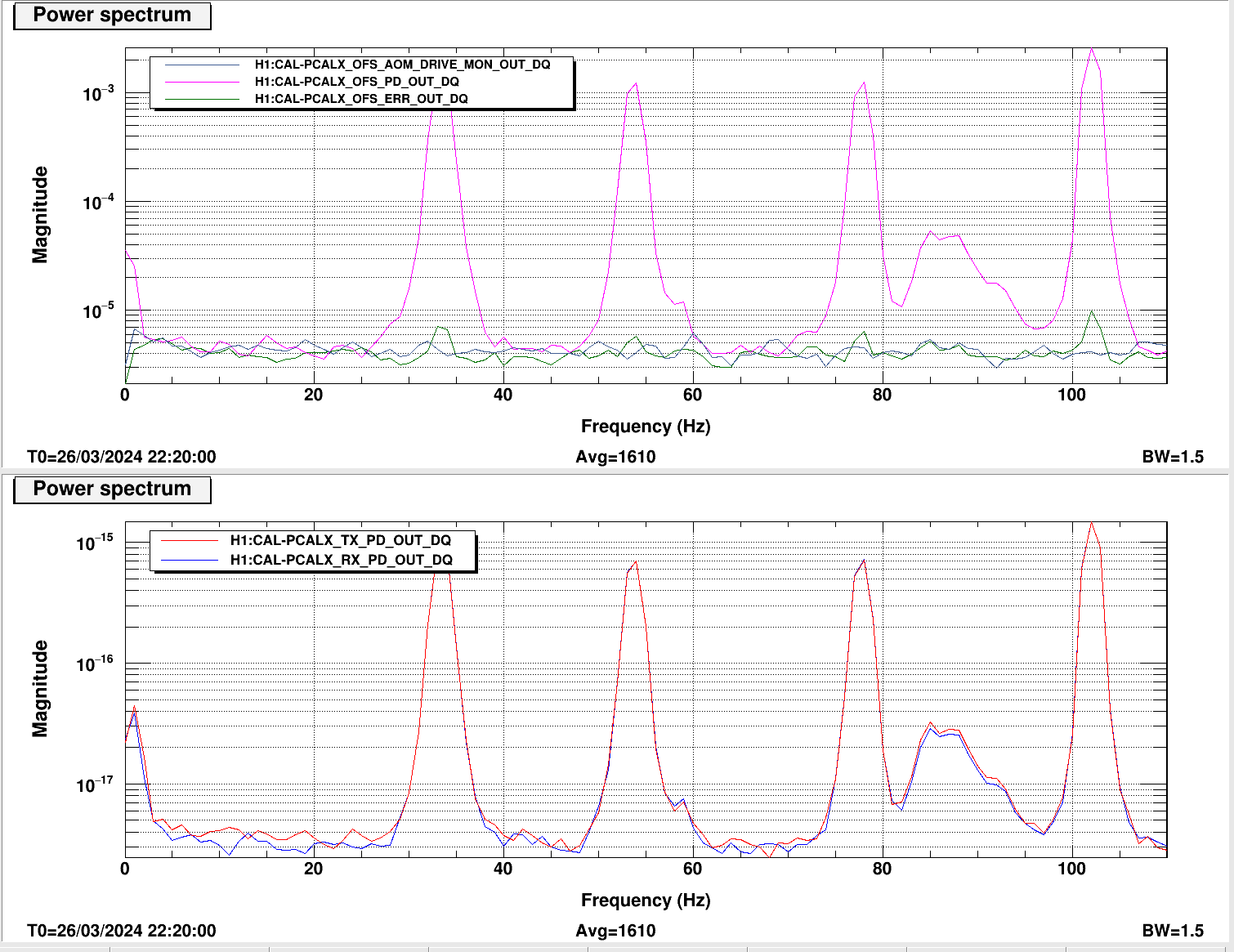
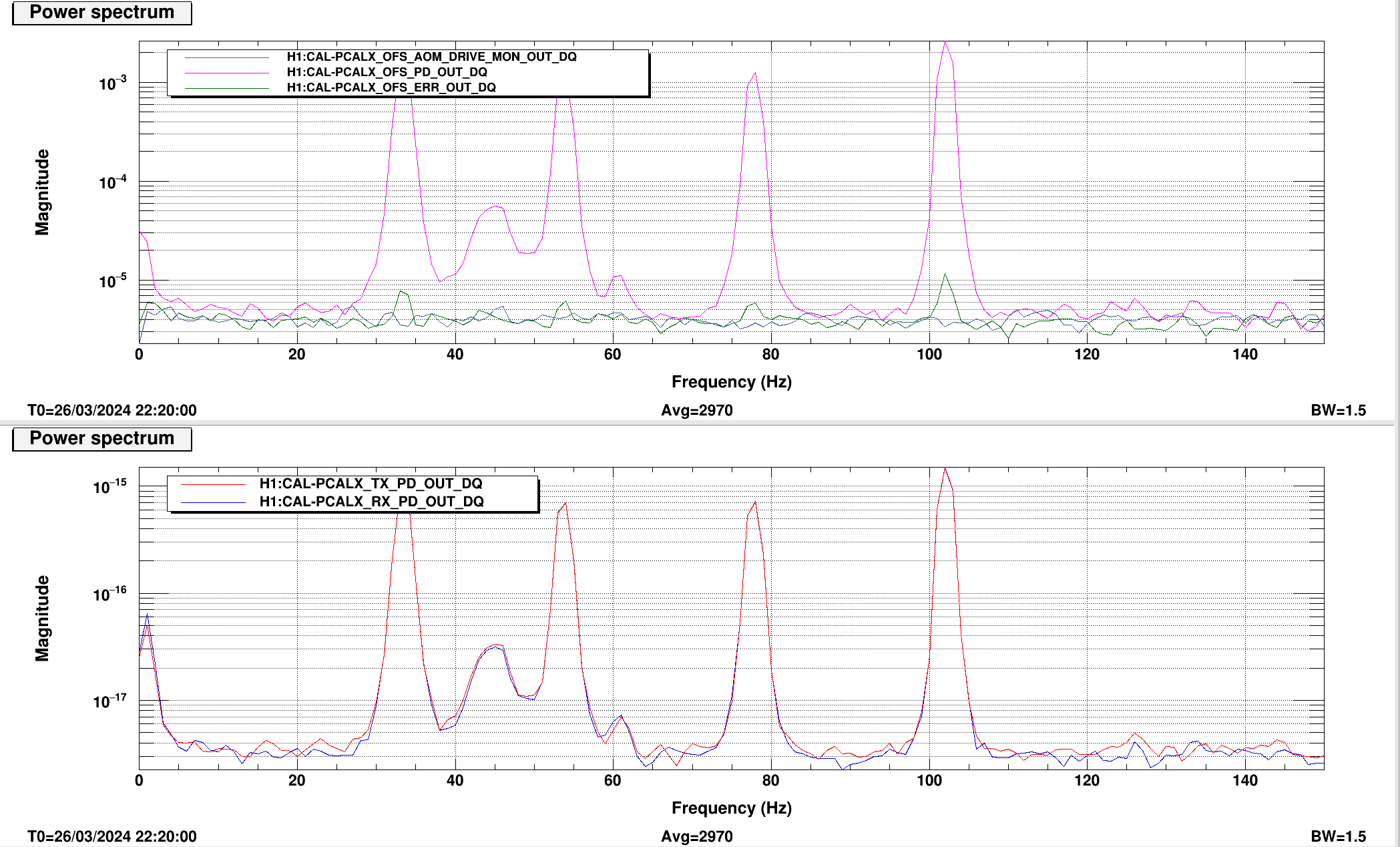
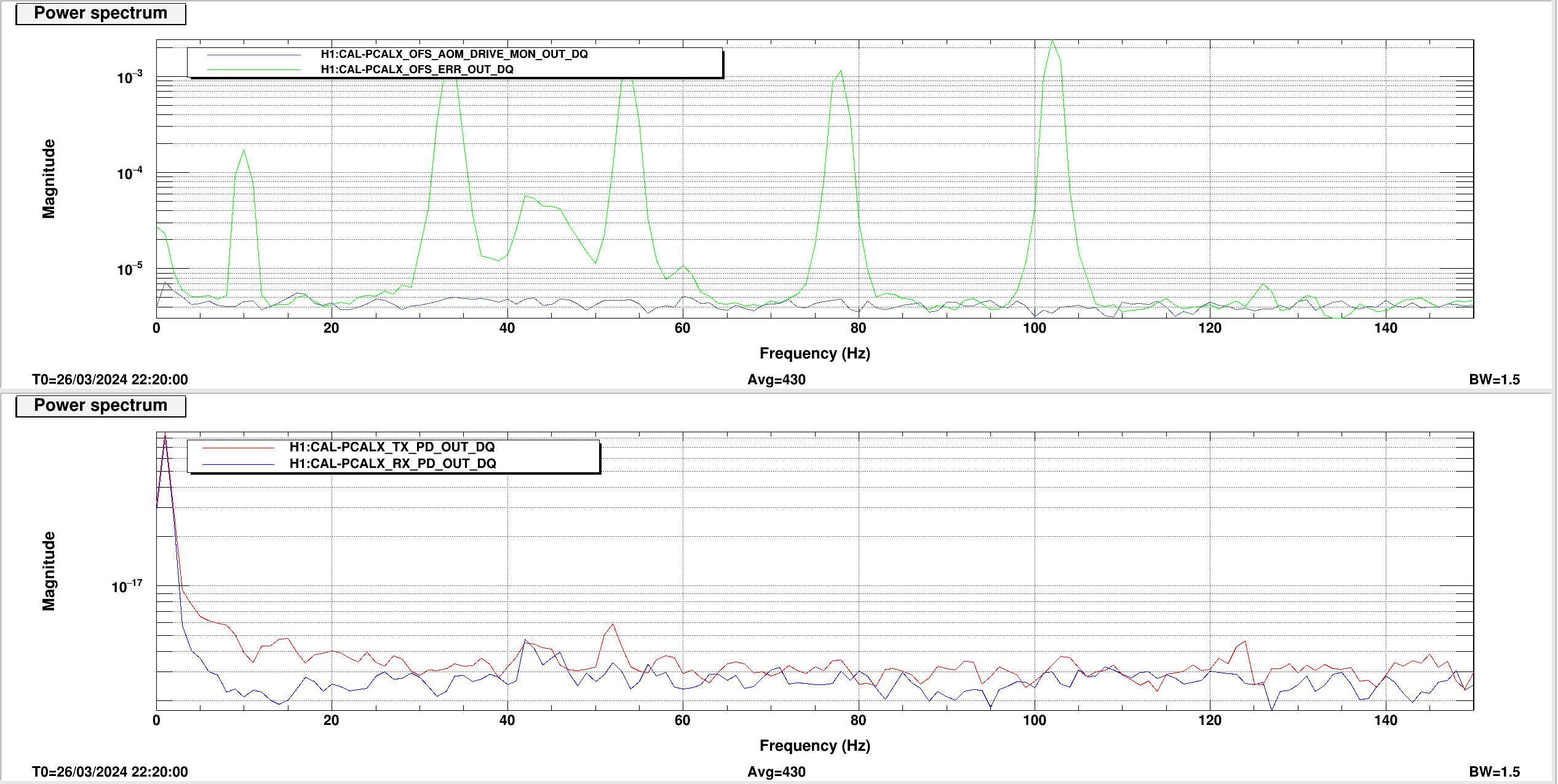
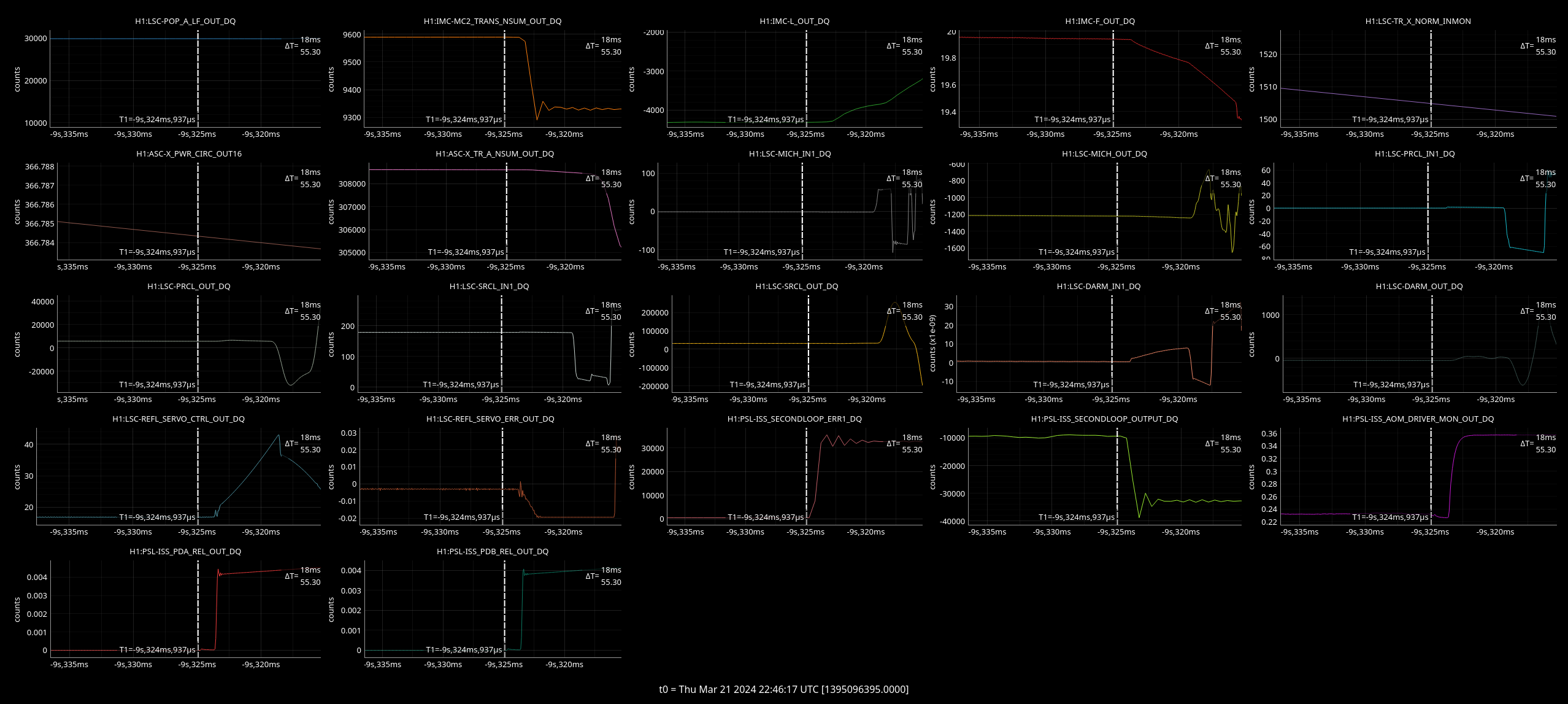
We checked the PR2 A2L gain first by injecting lines on PR2 in OSC8 in both and yaw, as Annamaria suggested we would need to check the spot wasn't moving too much on PR2. See first image.
Previous example of tuning A2L gains for PR2 (and I think the last time it was done) are here.
We took a spectrum and changed the A2L gains in SUS-PR2_M3_DRIVEALIGN_Y2L_GAIN to minimise our injected lines in LSC-PRCL_IN1 as these lines did not change much in DARM as we changed the gain.
These were mimimised at P2L gain of -0.31 and Y2L at -7.3 (nominal gain are -0.61 for P2L and -7.4 for Y2L so only the pitch gain changed substantially). Template for this is saved in /ligo/home/jennifer.wright/Documents/Noise_DARM/20240326_PR2_dither.xml.
Then I checked the jitter coupling by doing injections using the noise budget templates in:
/ligo/gitcommon/NoiseBudget/aligoNB/aligoNB/H1/couplings/IMC_PZT_{P,Y}_inj.xml after taking a background measurement in each case with the injection off.
We inject into either IMC-PZT-PIT_EXC for pitch and IMC-PZT-YAW_EXC for yaw measurements.
The P measurements are saved in /ligo/home/jennifer.wright/Documents/Noise_DARM/20240326_IMC_PZT_P_inj_start.xml
Took Y measurements (no injection and injection) without squeezing as somwething happened to squeezer and it is no longer injected. Saved in /ligo/home/jennifer.wright/Documents/Noise_DARM/20240326_IMC_PZT_Y_inj_start.xml
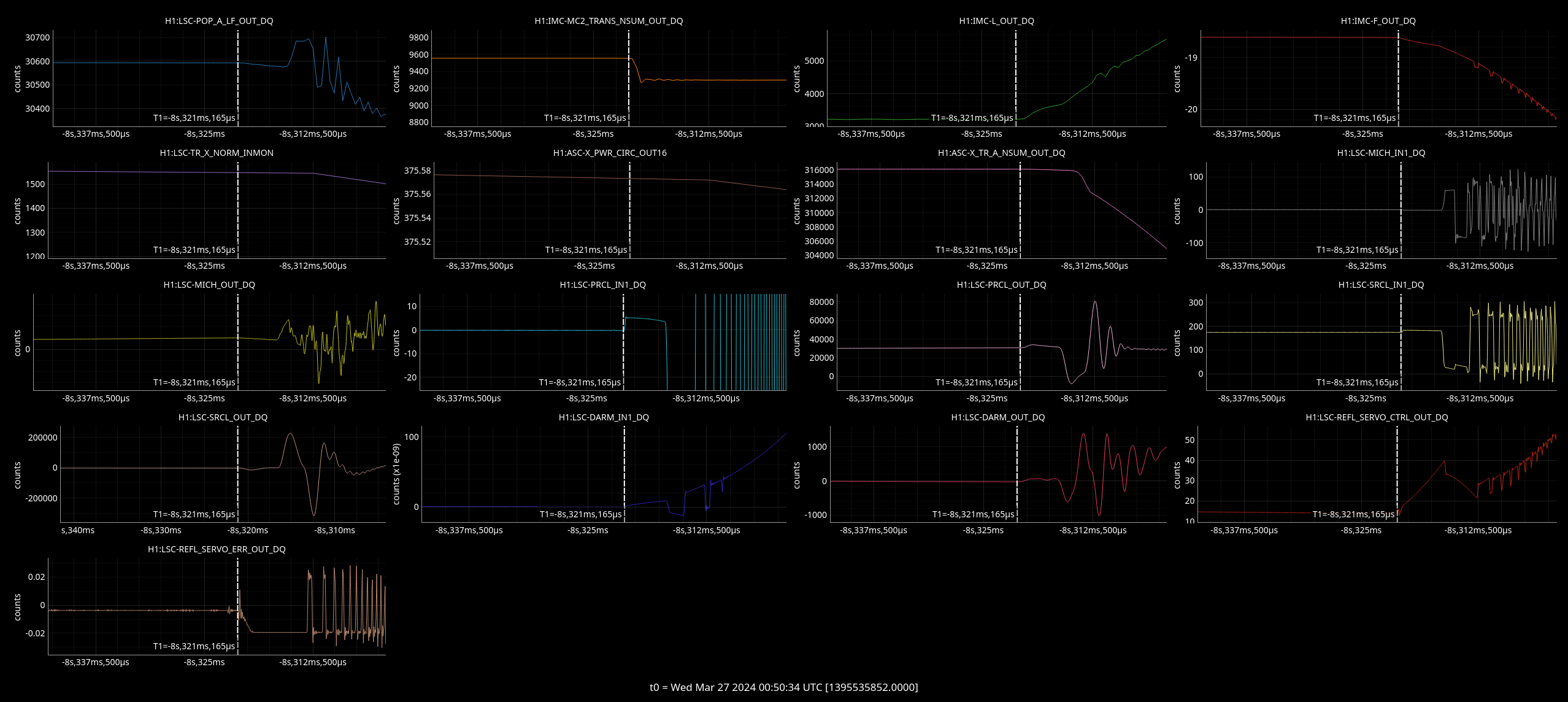
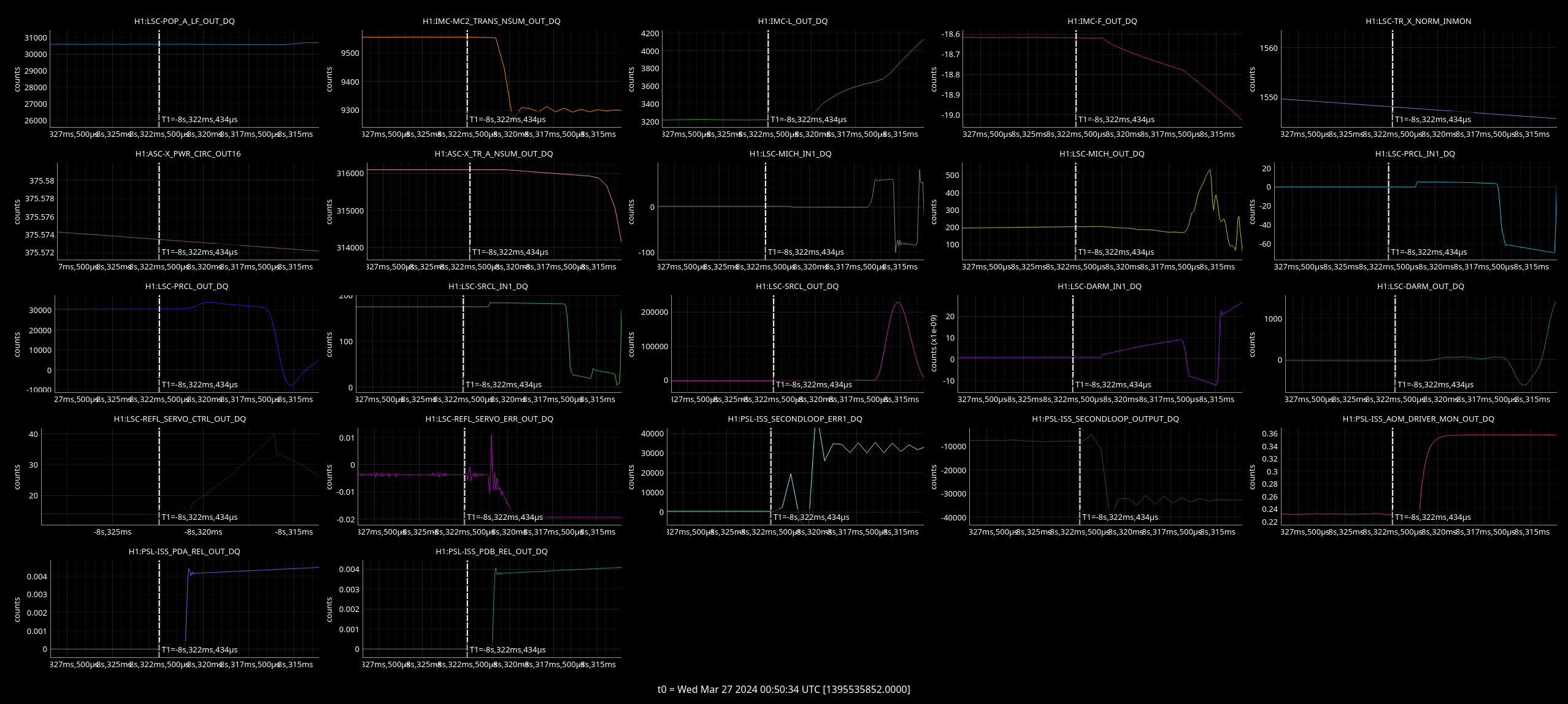
Moving PRM down in yaw (via camera offset) made build-ups worse but more power on POP B and B. First cursor on plot shows this point.
Measurement Times:
PITCH DOF, no injection: 2024/03/26 23:08:40 UTC
PITCH DOF, injection: 2024/03/26 23:12:22 UTC
YAW no injection: 2024/03/26 23:22:18 UTC
YAW injection: 2024/03/26 23:33:45 UTC
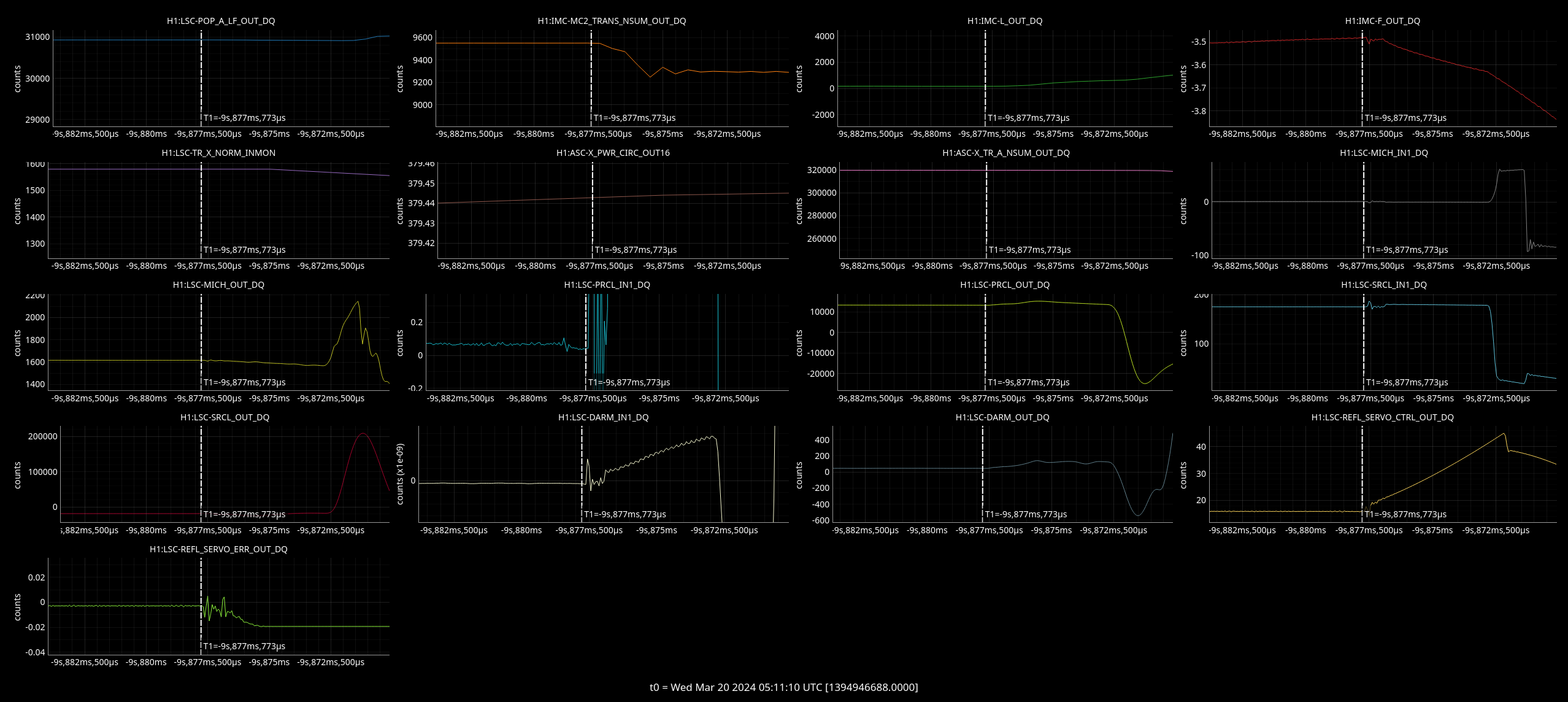
Plots
Top left - dark red is DARM with injection on, yellow is background with inj off.
Top right - blue is cleaned DARM with injection off, red is with injection on.
Bottom left - green and brown are two jitter witness channels with no injection, red and blue are these same two channels with the same injection on.
Bottom right - green and brown are two jitter witness channels with no injection, red and blue are these same two channels with the same injection on.
Made jitter better slightly on IMC-WFS_B_I_YAW.
Could not easily improve A2L coupling on PR2 here. Tried running the dither template for PR2 again and changhing the gains but nominal gains was close to optimal where P2L has -0.61 and Y2L has -7.4.
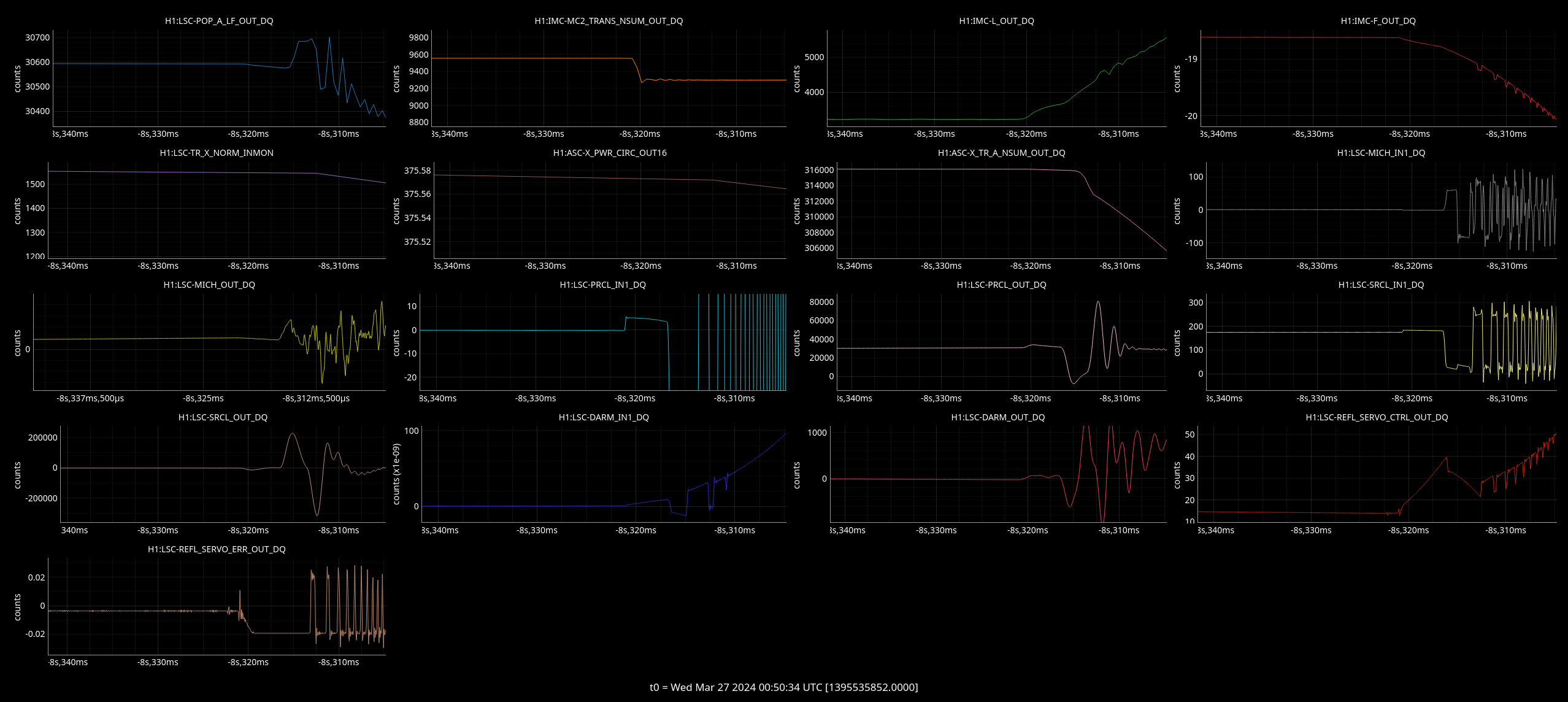
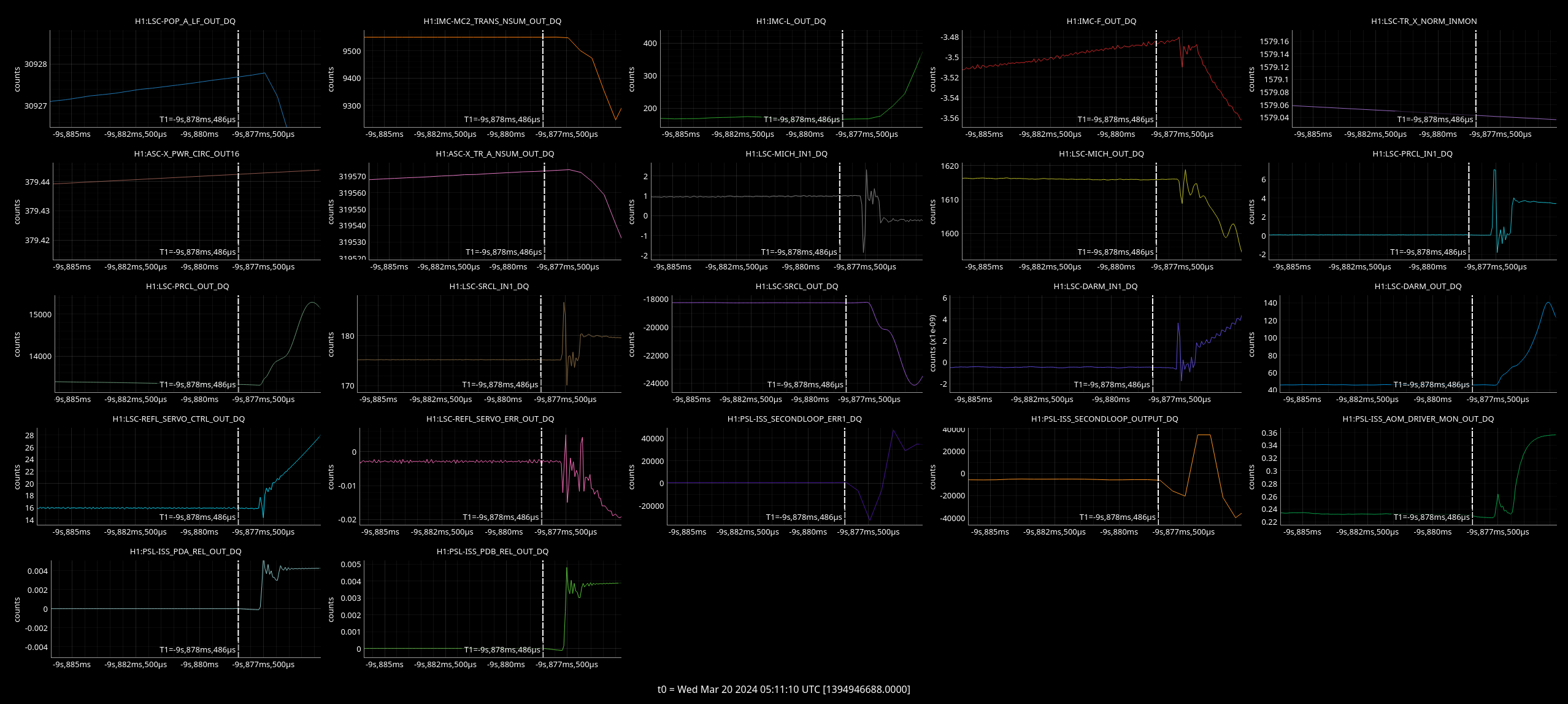
But took jitter references again just for yaw degree of freedom. For plots:
Measurement Times:
YAW DOF No injection: 26/03/2024 23:59:10 UTC
YAW DOF Injection: 27/03/2024 00:02:15 UTC
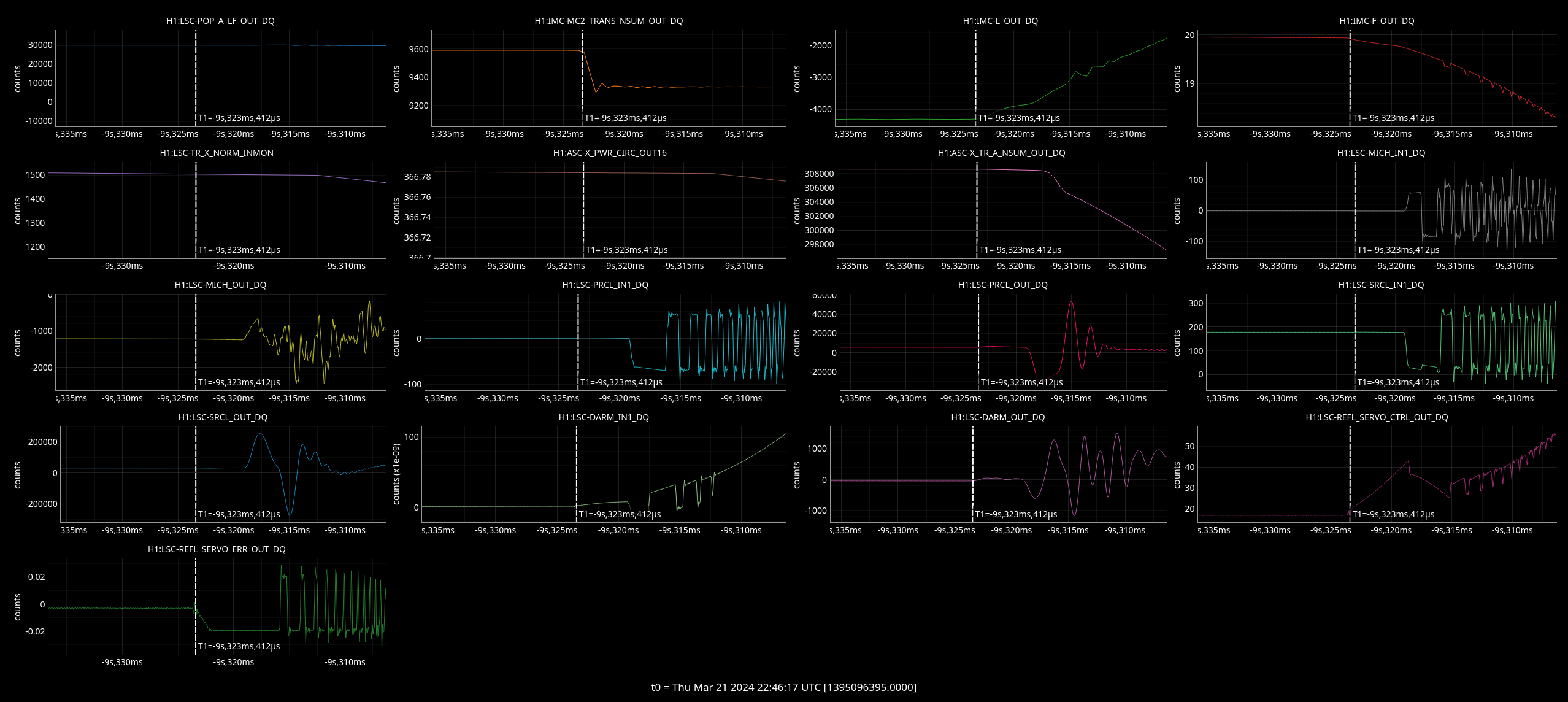
Plots
Top left - dark red is DARM with injection on, yellow is background with inj off.
Top right - blue is cleaned DARM with injection off, red is with injection on.
Bottom left - green and brown are two jitter witness channels with no injection, red and blue are these same two channels with the same injection on.
Bottom right - green and brown are two jitter witness channels with no injection, red and blue are these same two channels with the same injection on.
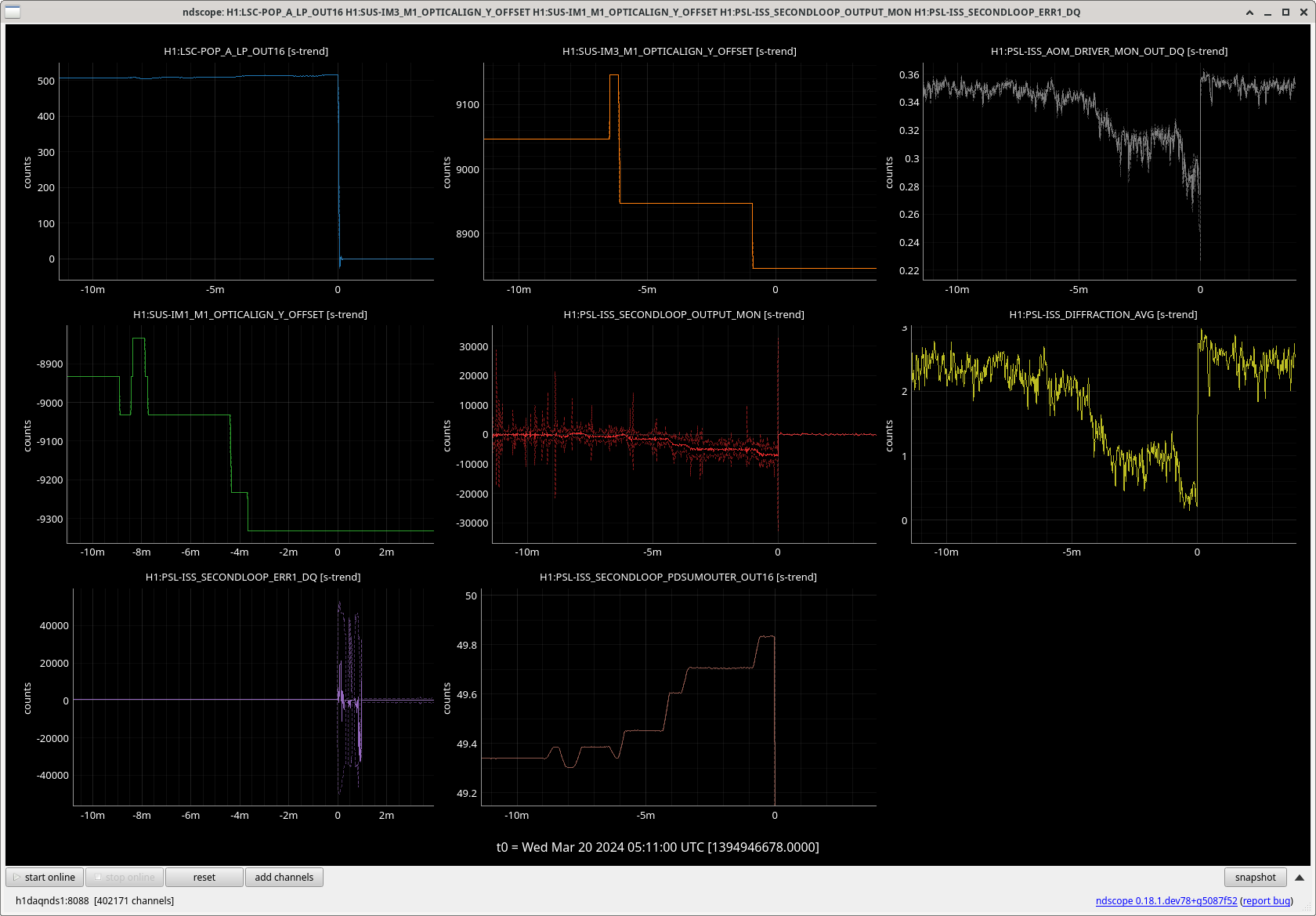
After I had reverted the changes on PRM, Jenne did some IM1 and IM3 yaw steps detailed here (of about 20 counts on sliders instead of the 200 counts Gabriele and I were doing before).
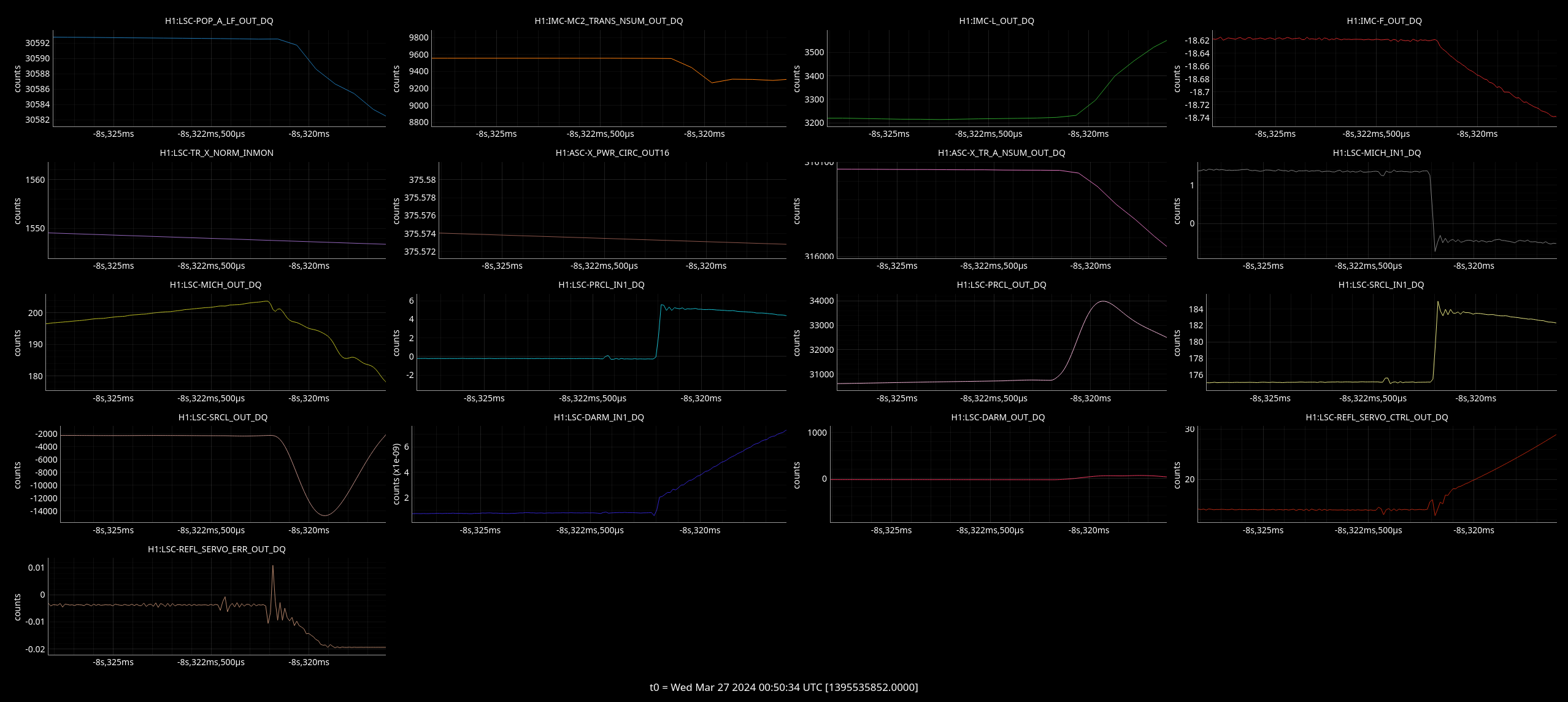
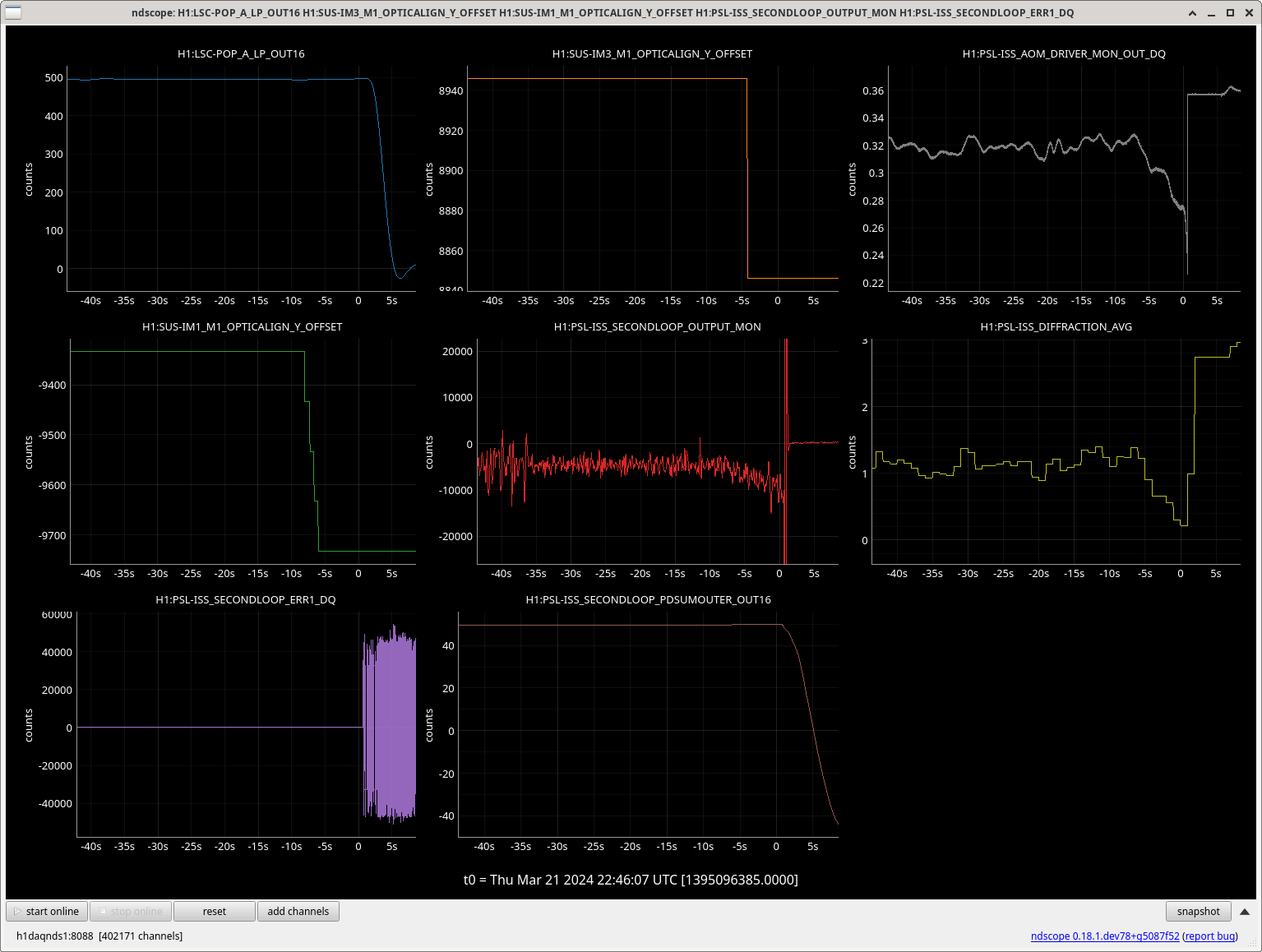
From this image where first cursor is PRM change and second cursor is IM1 and 3 change; we can see that when IM1 and 3 were being changed, the PRM was pulled to the same place as I had moved it to but this time it made the build-ups better.
Jenne and I conclude that this alignment change is thus not just the PRC being re-aligned but some input clipping or pointing.
Also in Gabriele and I's moves we only moved YAW after aligning pitch and so this may also make a difference.
These YAW moves in IM1 and 3 also unlocked the IFO so we need to look closer into why this happens (Jenne suggests some fast loop is running away), but I think this YAW alignment is something we should move towards maybe with other changes to make sure all the loops stay stable.
Just to clarify we reverted all the A2L gain changes and alignment changes after we lost lock.