TITLE: 03/18 Day Shift: 15:00-23:00 UTC (08:00-16:00 PST), all times posted in UTC
STATE of H1: Commissioning
INCOMING OPERATOR: Corey
SHIFT SUMMARY:
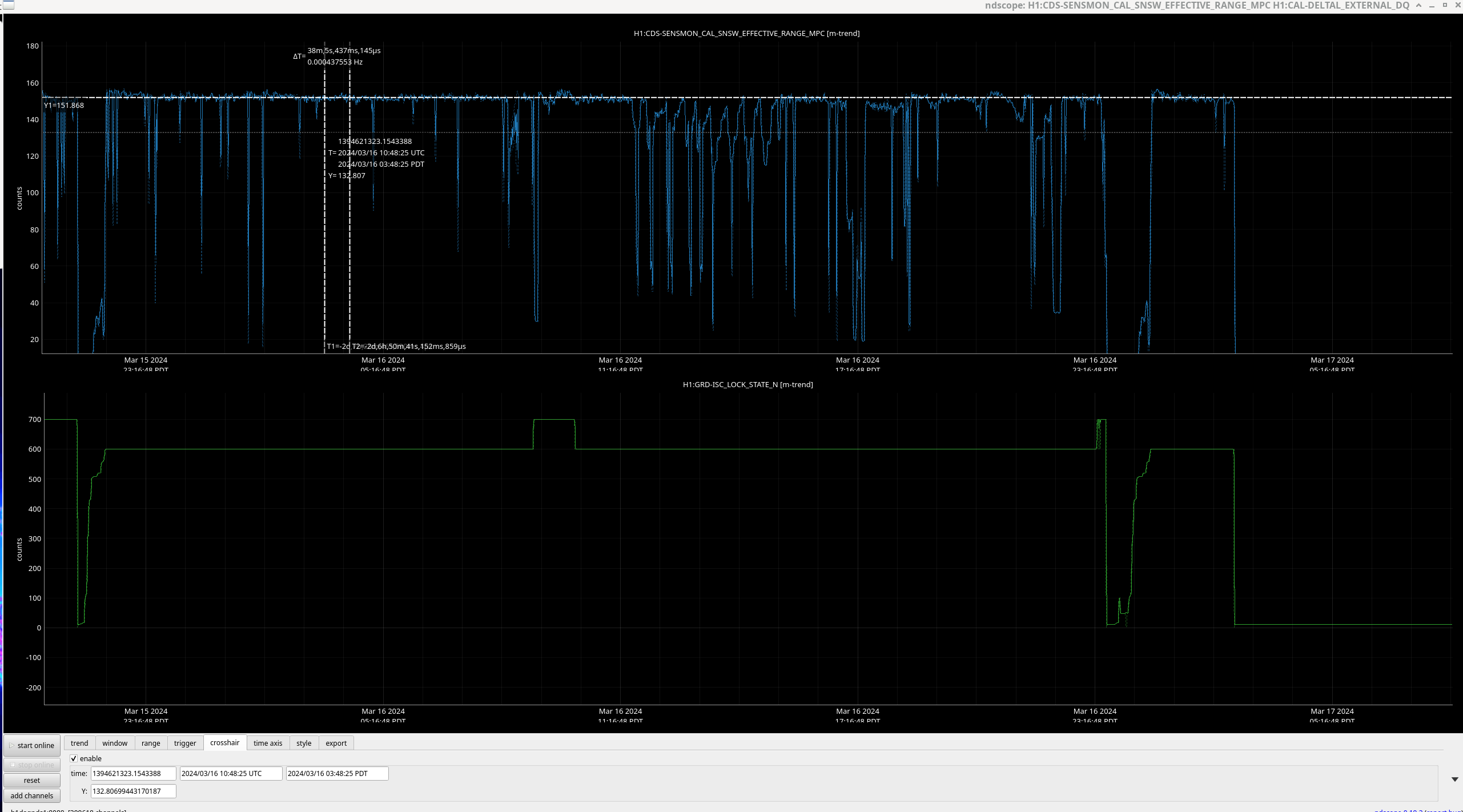
IFO is in NLN and COMISSIONING (3hr 45 min lock)
16:10(ish) UTC - Began Initial Alignment (couldn’t lock DRMI)
16:30 UTC - Initial Alignment Complete
16:51 UTC - NLN Reached
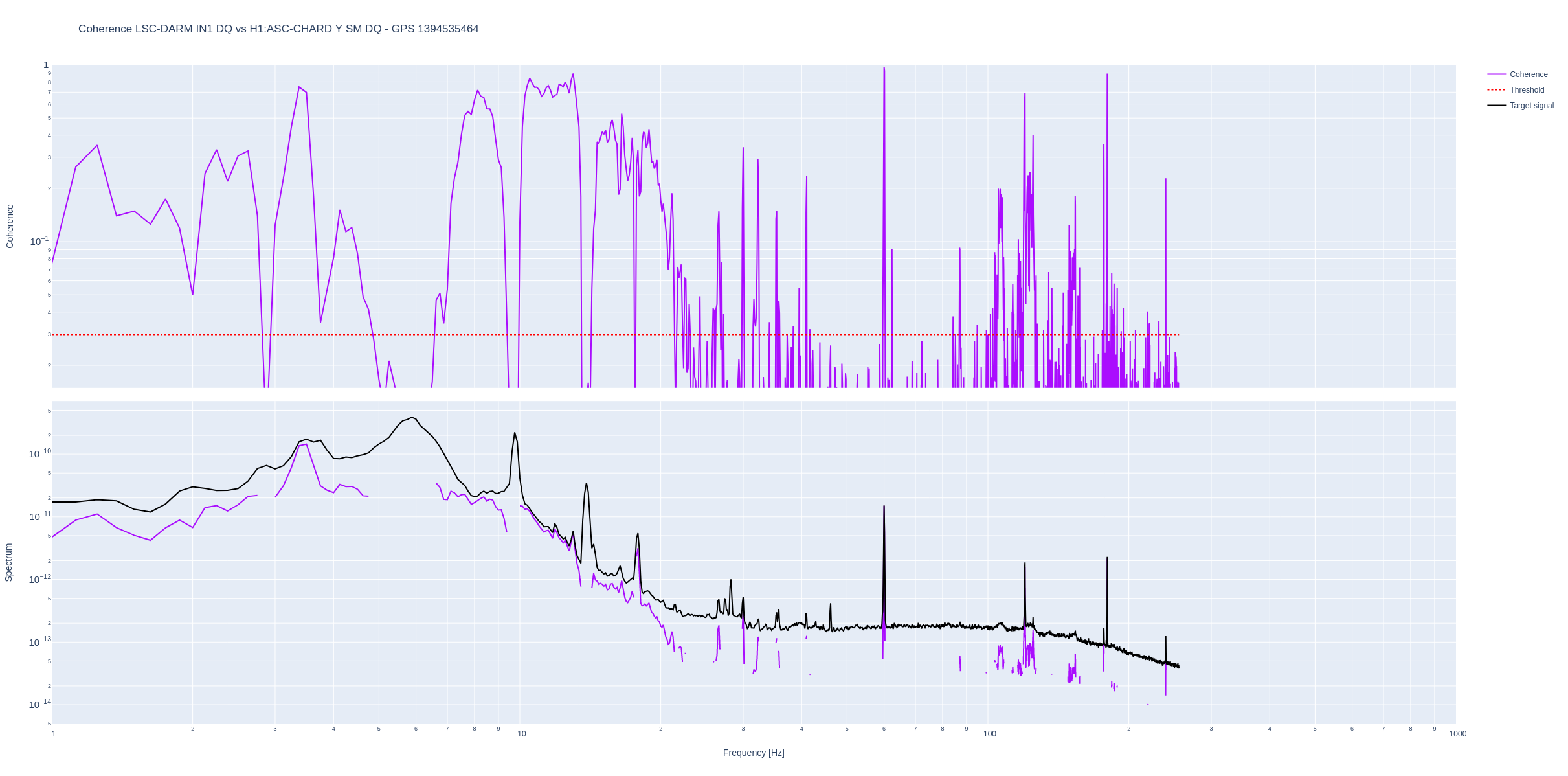
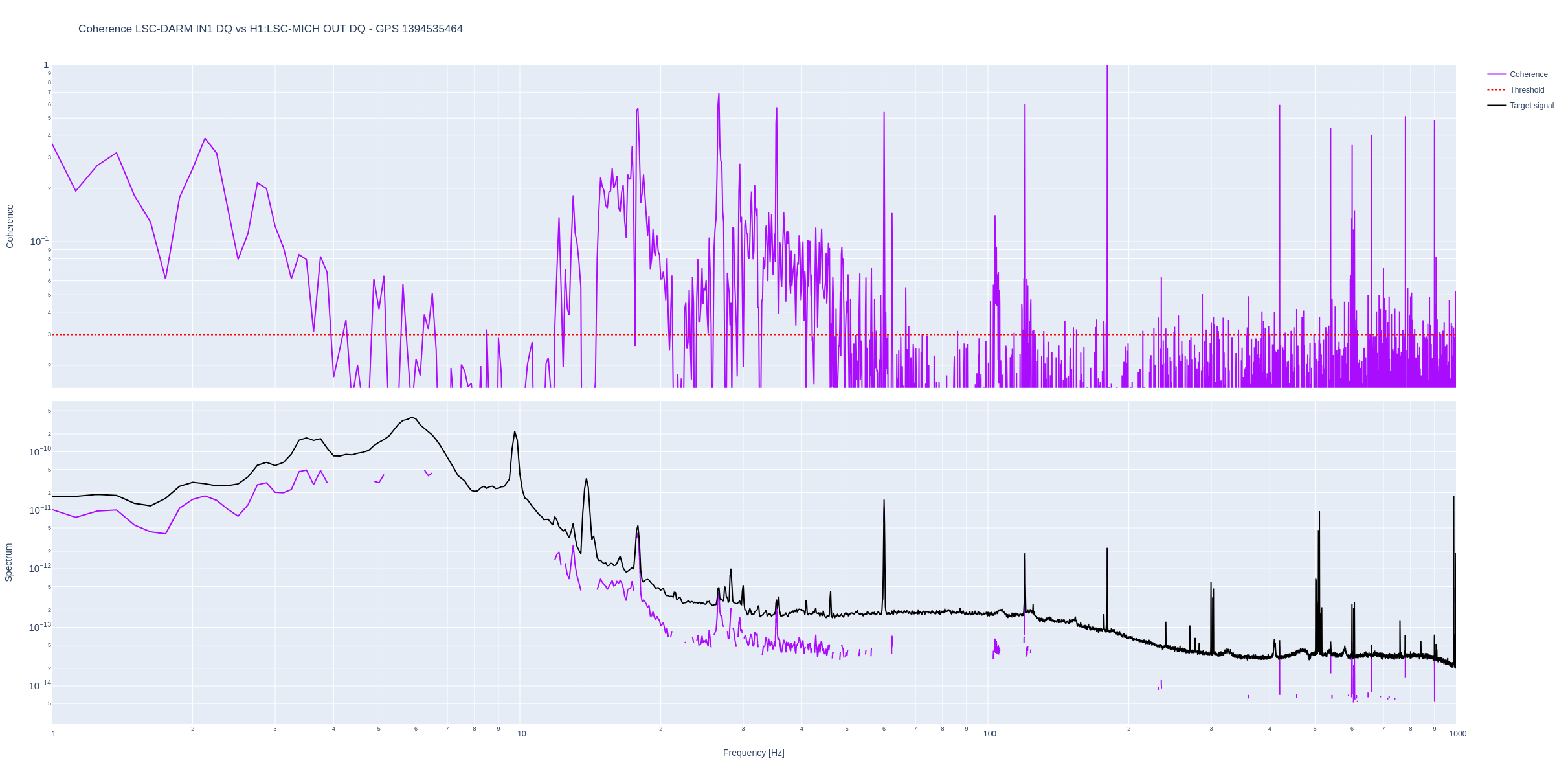
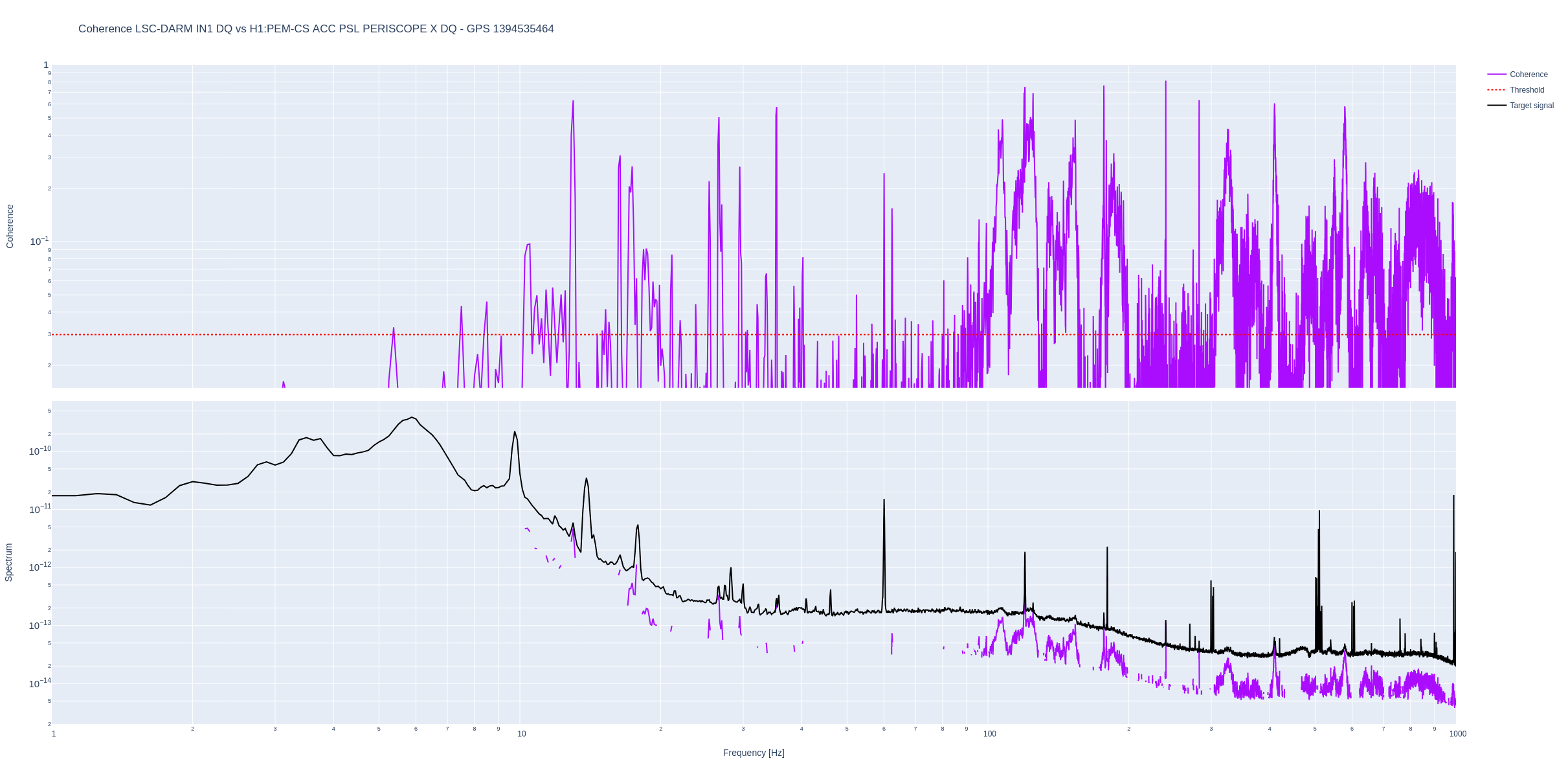
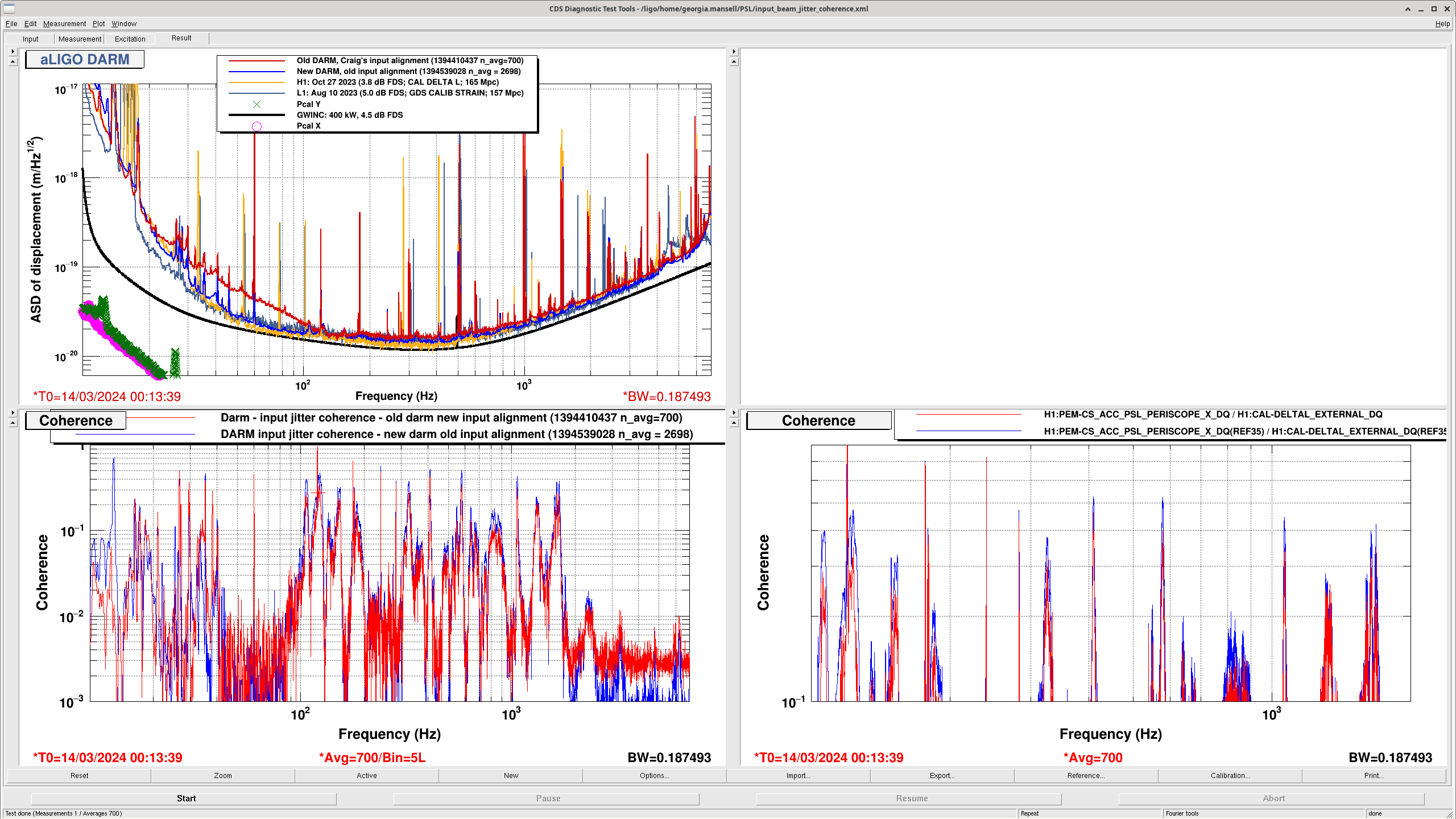
HAM7 Watchdog Story
17:04 UTC - ISI HAM7 WD Tripped - initially assumed due to Nutsinee’s work in LVEA.
17:20 UTC - Nutsinee out - claims to have been very stealthy and to not have caused the trip - her measurements started 1 minute after the trip.
17:35 UTC - HAM7 WD Untripped (was investigating separate issue)
18:36 UTC - HAM7 WD investigation where Jim and Nutsinee attempted to go in and recreate the trip but nothing tripped - interesting..
EX ISI WD Trip Weirdness Story
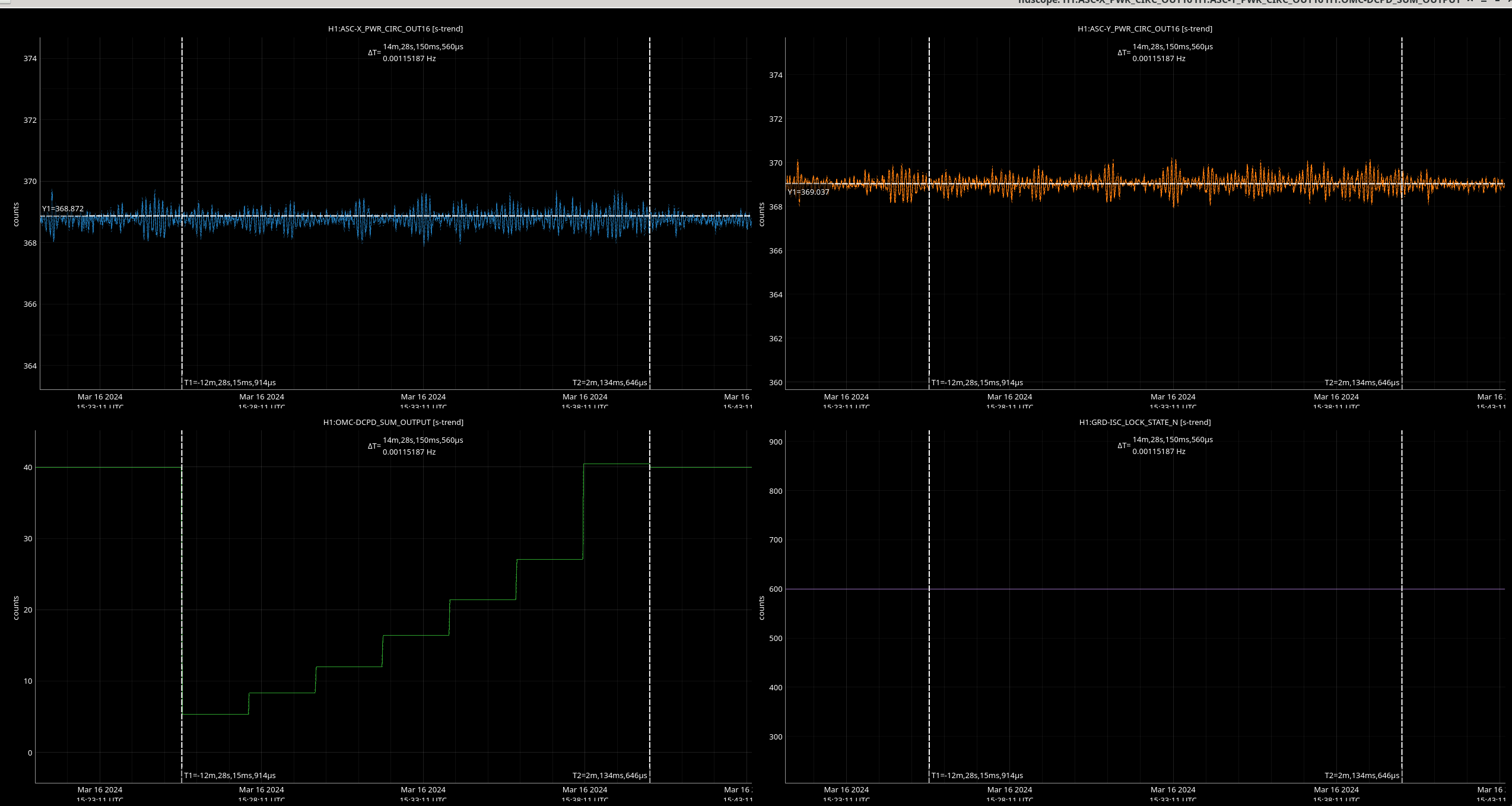
17:12 UTC DCPD Lockloss, appears to have kicked HEPI 200 microns in the horizontal in <4s - somebody should investigate the TIDAL signal.
17:12 UTC - ISI ETMX WD Tripped (Stage 1 and 2) due to the aforementioned HEPI kick (according to Jim) - no vehicles nor personnel there so reason unknown - WD untripped - happened 2s after lockloss and did not CAUSE lockloss.
ITMX IOP Down & Reboot Story
17:20 UTC - IOP for ITMX is down dave noticed
17:23 UTC - Fil is taking a look
17:26 UTC - Rebooting SEIB3 rack (adjacent to what Fil was working on so may have been that).
17:33 UTC - IOP rebooted and WDs reset -0 will take a few minutes because HEPI went down and as it goes up, it rings up the T240s - estimated 3-4 minutes until fully untripped and models are back
17:44 UTC- HEPI Back, commencing relock
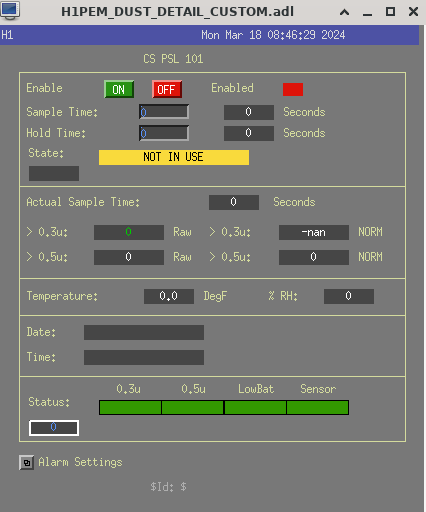
PSL RM (101) Dust Monitor Story
15:30 UTC - Dave restarting dust monitors
17:21 UTC - Dust Monitor 101 not back - not getting data, someone may have forgotten to plug it in according to Dave
18:38 UTC - Ryan S informed of the PSL101 Laser RM dust monitor not receiving data - might go in to investigate tomorrow.
19:13 UTC - NLN Reached
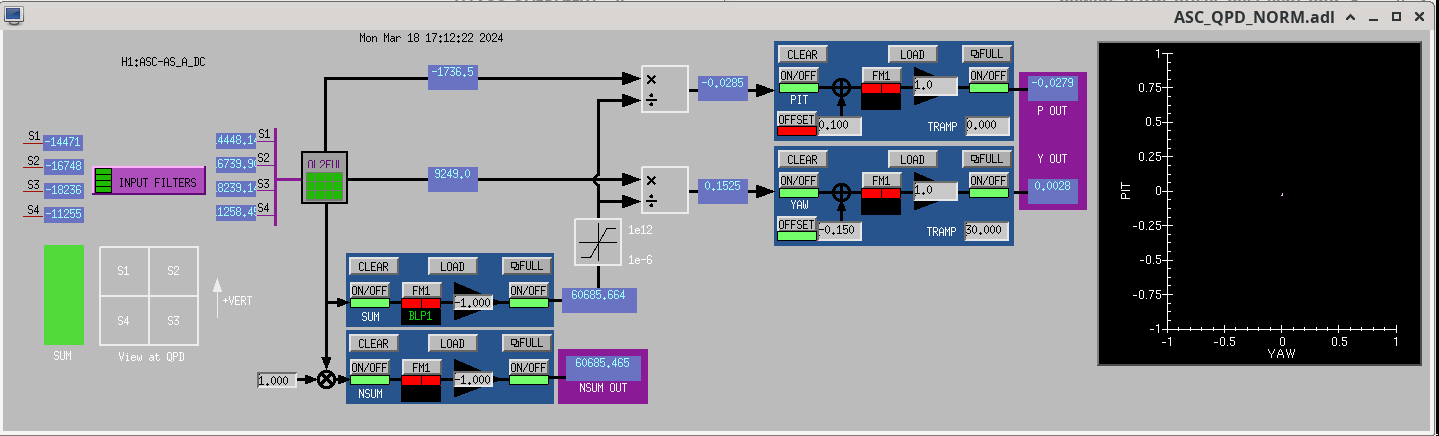
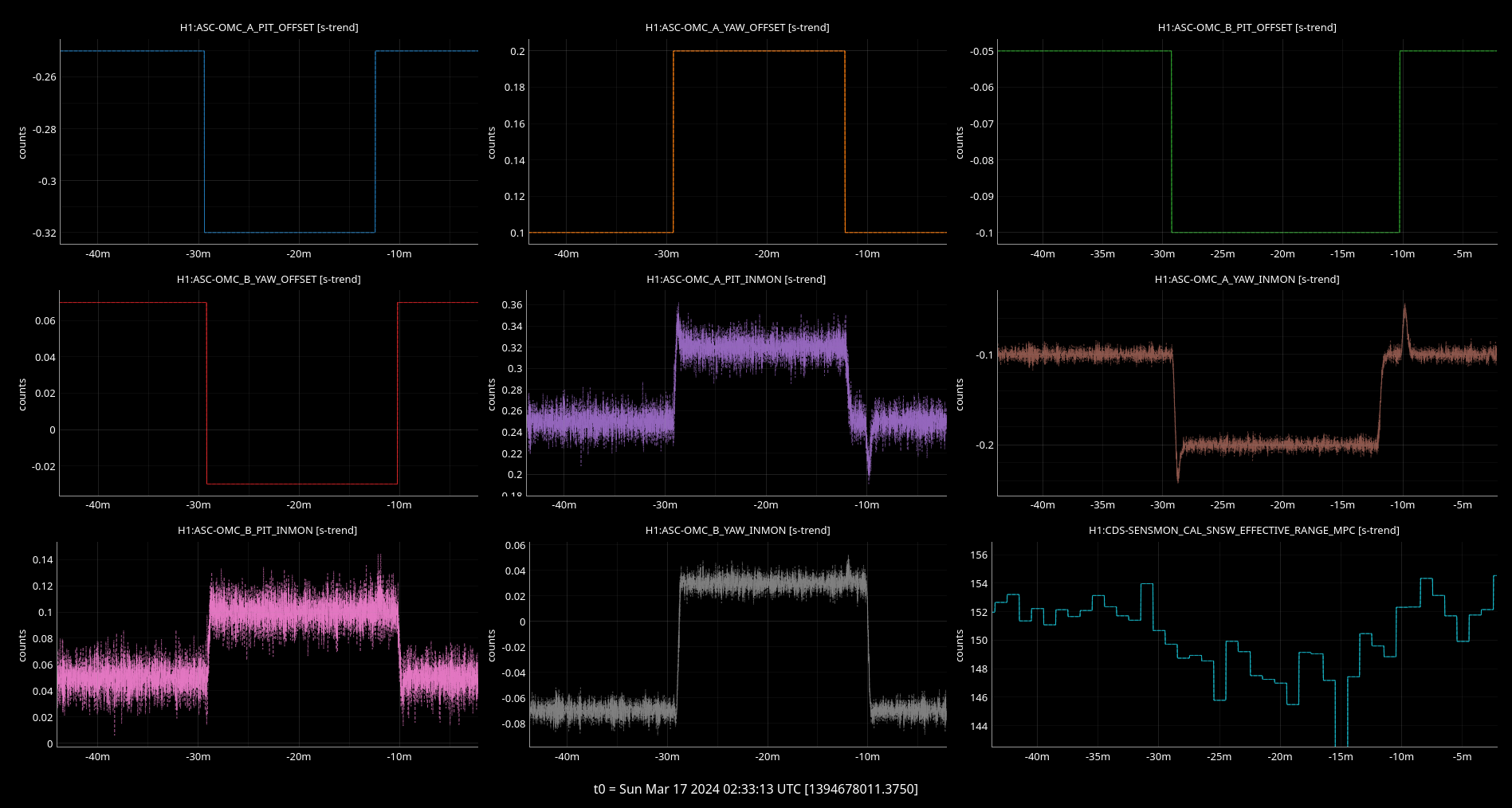
19:13 UTC - Turning on SQZ Angle Adjust
LOG:
| Start Time |
System |
Name |
Location |
Lazer_Haz |
Task |
Time End |
| 15:11 |
FAC |
Karen |
Optics Lab |
N |
Tecnical Cleaning |
15:40 |
| 15:39 |
FAC |
Karen |
MY |
N |
Technical cleaning |
16:39 |
| 16:08 |
PCAL |
Tony/Dripta/Daiki/Francisco |
Optics Lab |
N |
Responsivity measurement |
17:30 |
| 16:58 |
SQZ |
Nutsinee |
LVEA |
Local |
SQZ Test |
17:35 |
| 17:10 |
EE |
Fil |
CER |
N |
BSC Interface Chassis Diagnostics |
18:10 |
| 17:39 |
FAC |
Kim |
MX |
N |
Technical Cleaning |
18:39 |
| 18:19 |
SQZ |
Jim, Nutsinee |
LVEA |
N |
Tripping HAM7 |
18:36 |
| 19:00 |
PCAL |
Tony/Francisco |
Optics Lab |
N |
Getting a laser off integrating spheres |
20:00 |
| 20:49 |
FAC |
Tyler |
EX |
M |
Escort to EX |
21:49 |