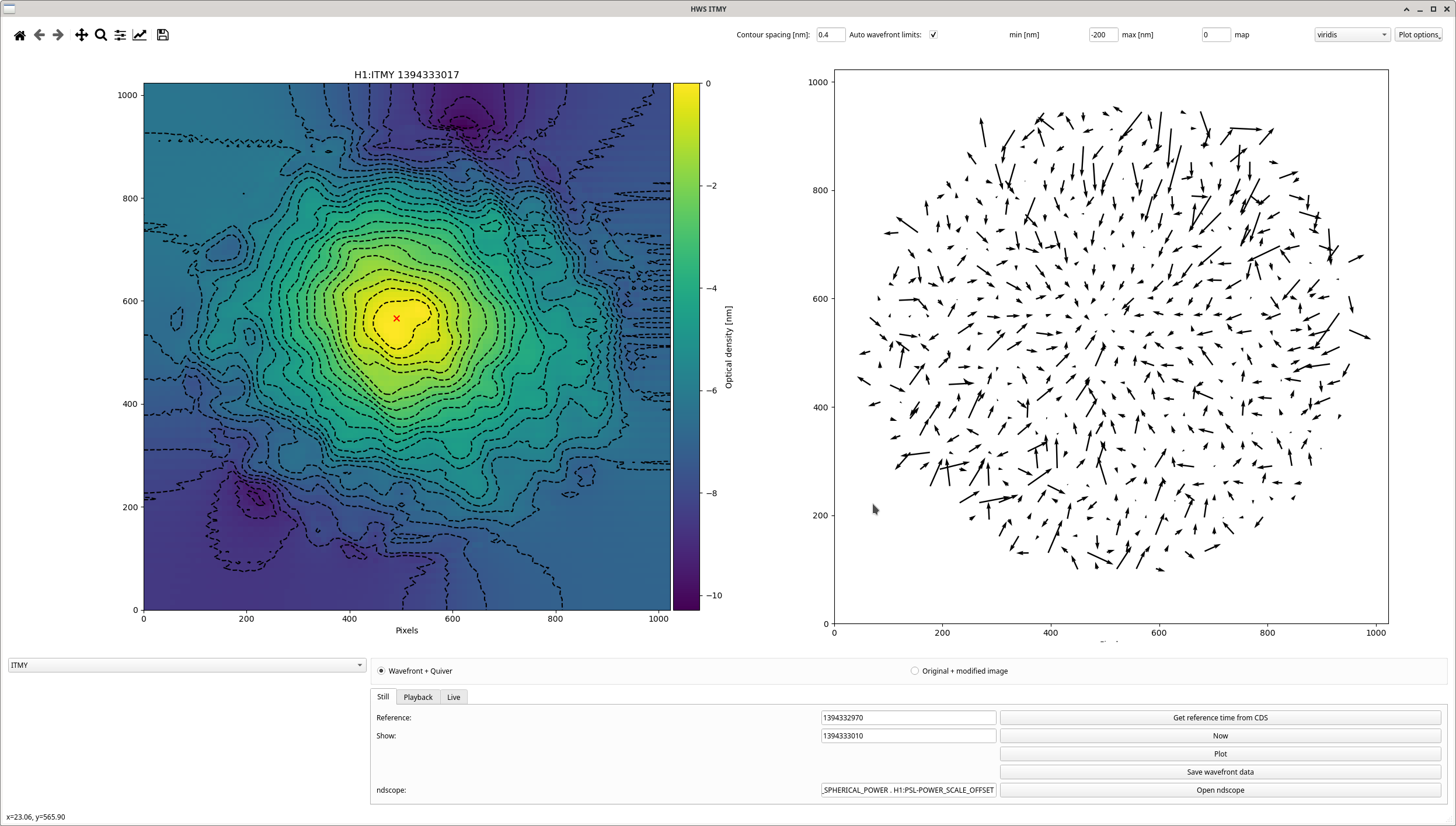
Last week when we locked the new OMC by hand I copy-pasted some guardian code into a shell, and found that there was a gain set and wait that were totally unnecessary. This inspired me to start reading through ISC_LOCK to look for other redundant waits. Here are my notes, I only got up to the start of LOWNOISE_ASC before I went totally cross-eyed.
Here are the notes I took, the ones in bold we can for sure remove.
Preparing for lock
Line 301-305 [ISC_LOCK, DOWN] Prcl UGF servo turn off (do we still do this?) no wait times but maybe unnecessary
Line 327 [PREP_FOR_LOCKING] Thermalization guardian (are we using this?)
Line 350-354 [PREP_FOR_LOCKING] Turn off CHARD blending, no wait times
Line 423 [PREP_FOR_LOCKING] turn off PR3 DRIVEALIGN P2P offset for PR3 wire heating
Line 719 [PREP_FOR_LOCKING] toggling ETM ESD HV if the output is low, seems redundant with line 445
Initial alignment
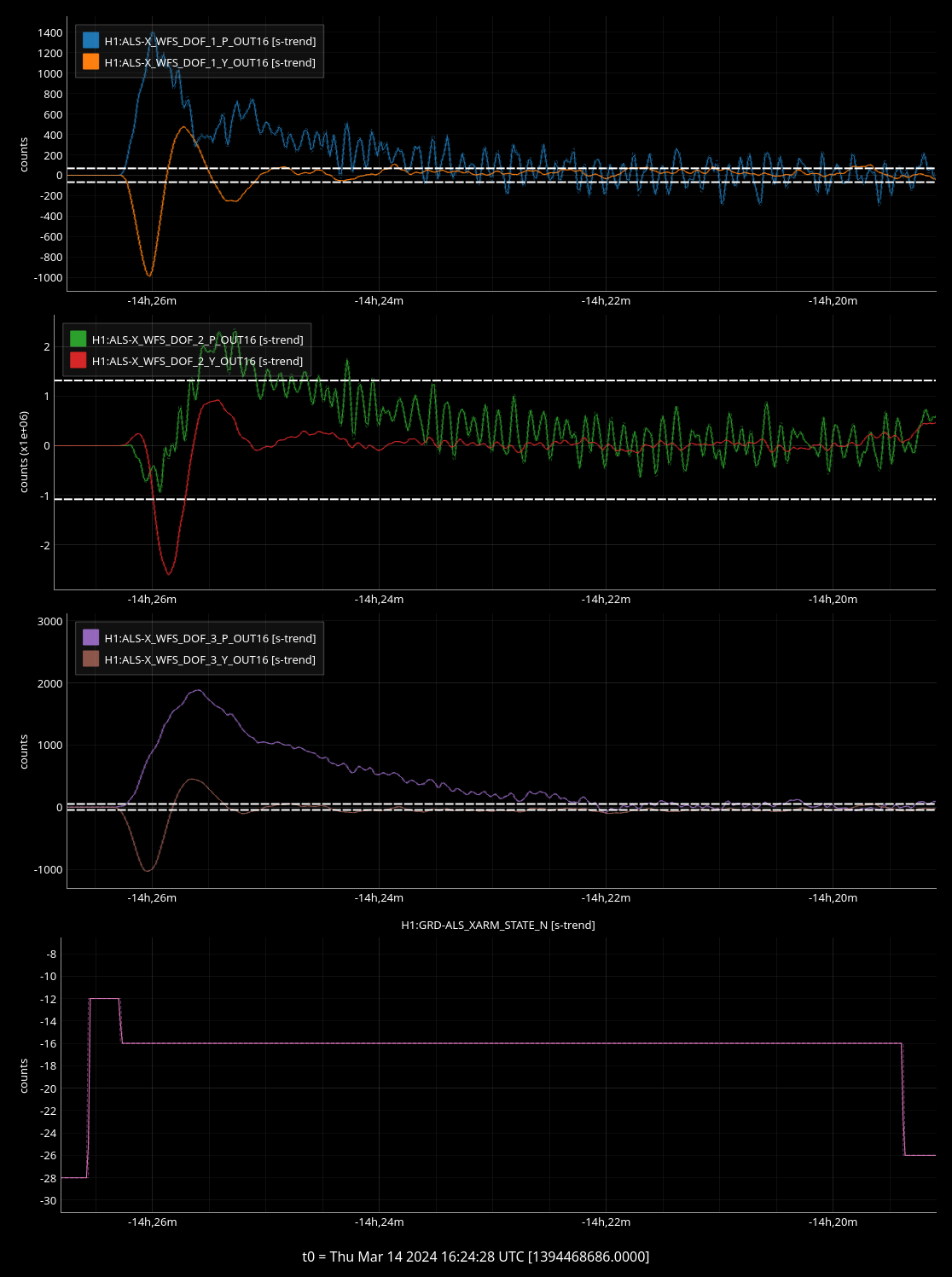
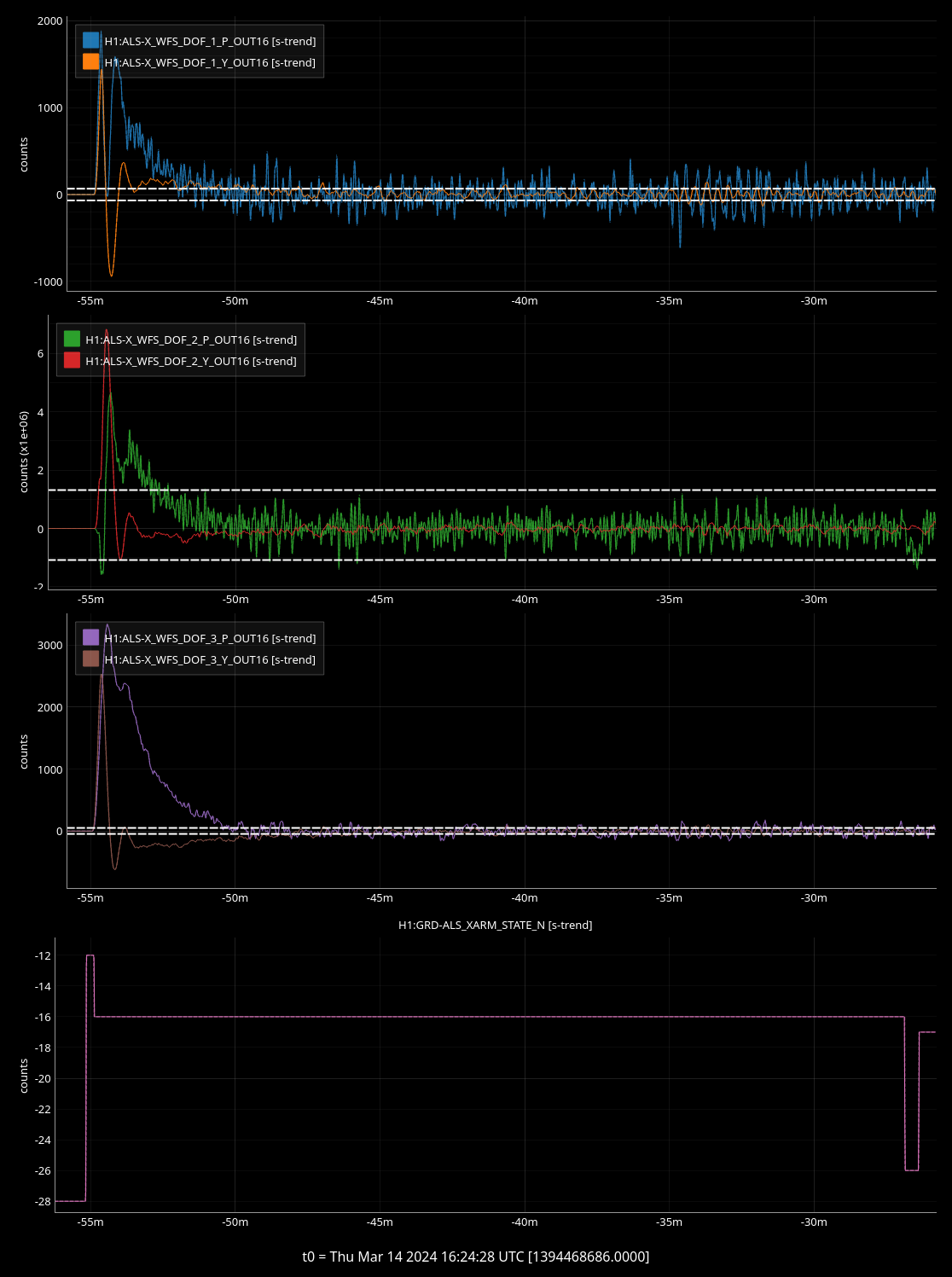
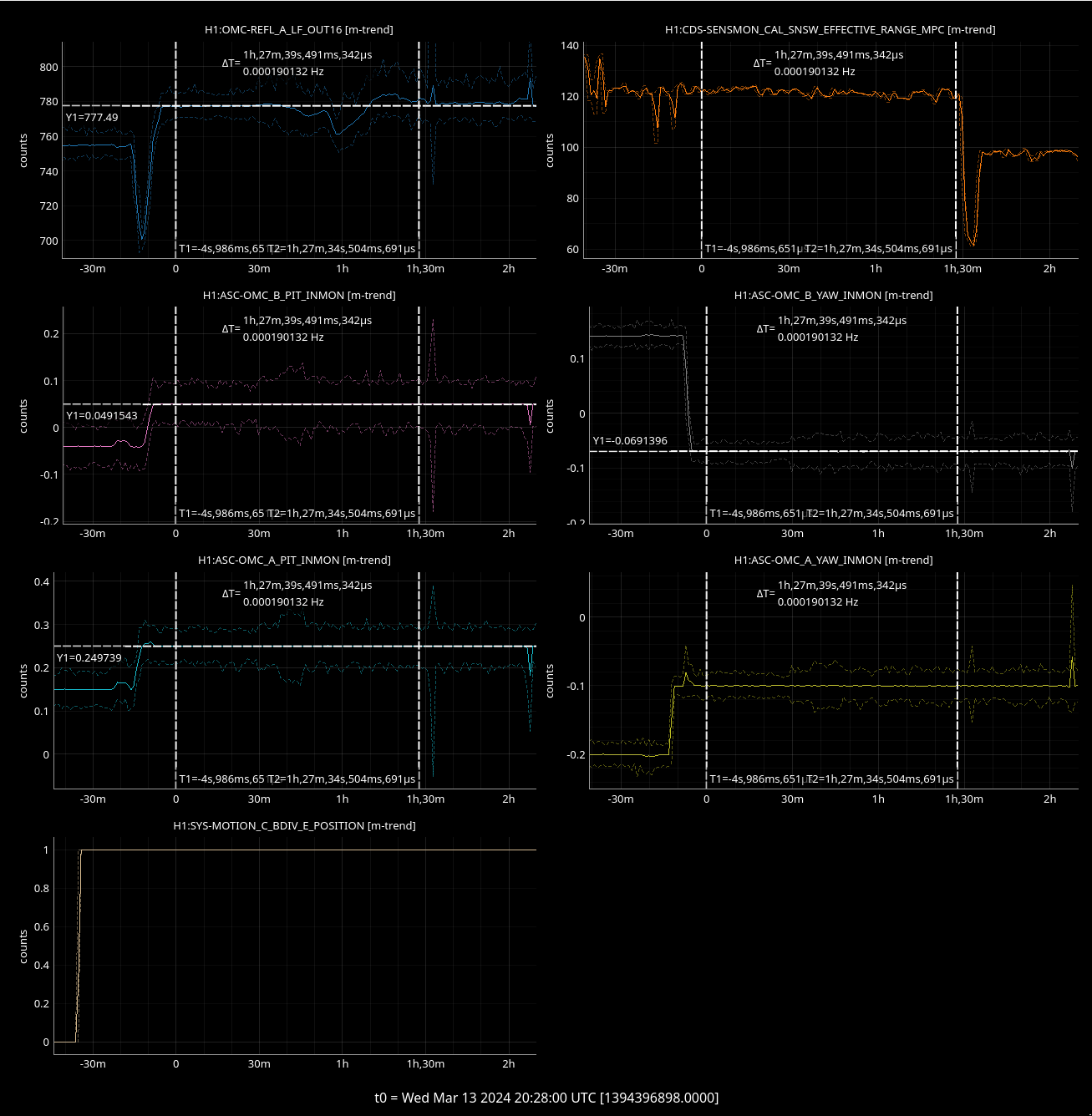
INITIAL_ALIGNMENT for the green arms only offloads a minute or 2 after it's visually converged. Initially I thought the convergence checker thresholds should be raised, but it's a 30 second average. Might make sense to reduce the averaging time?
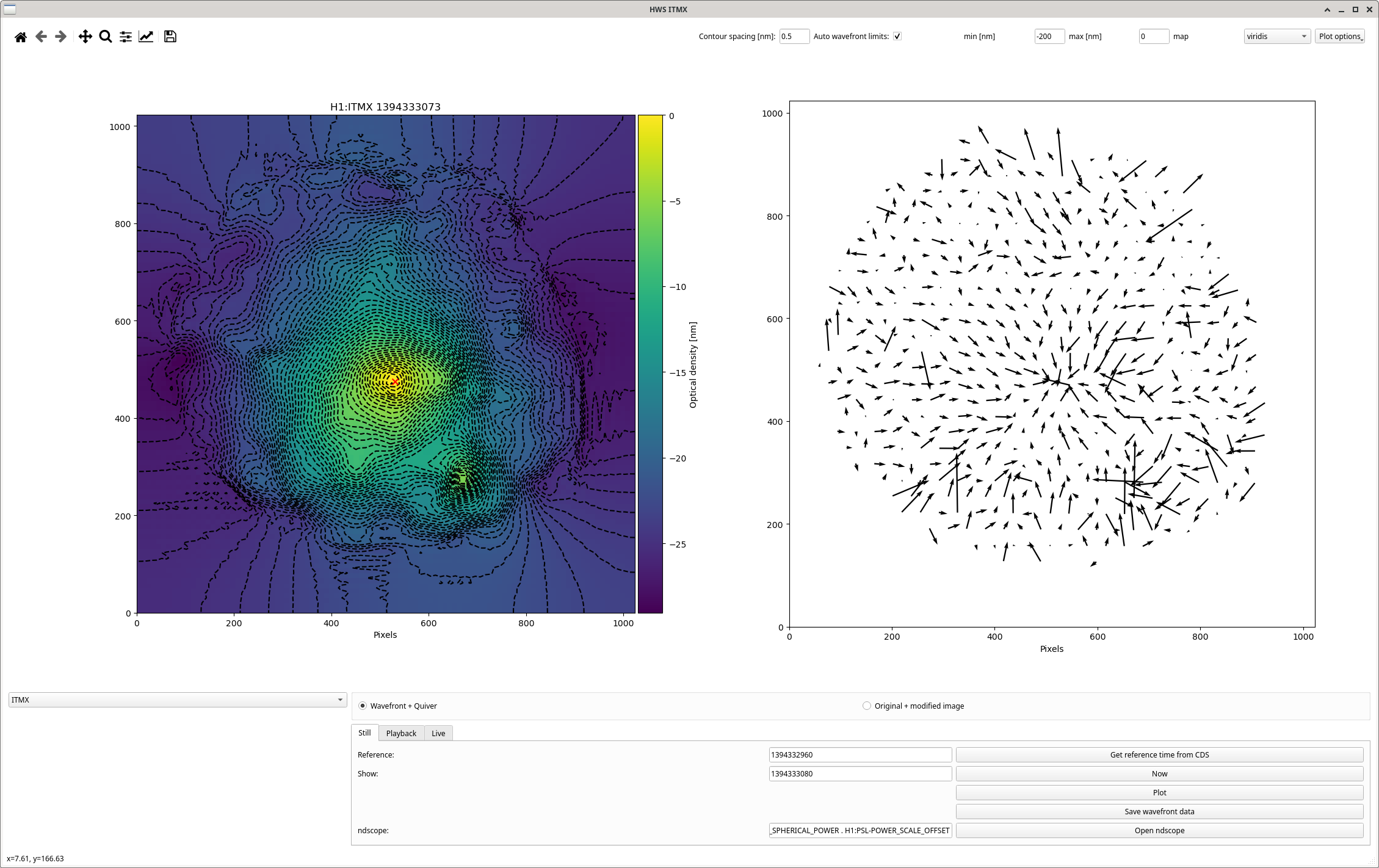
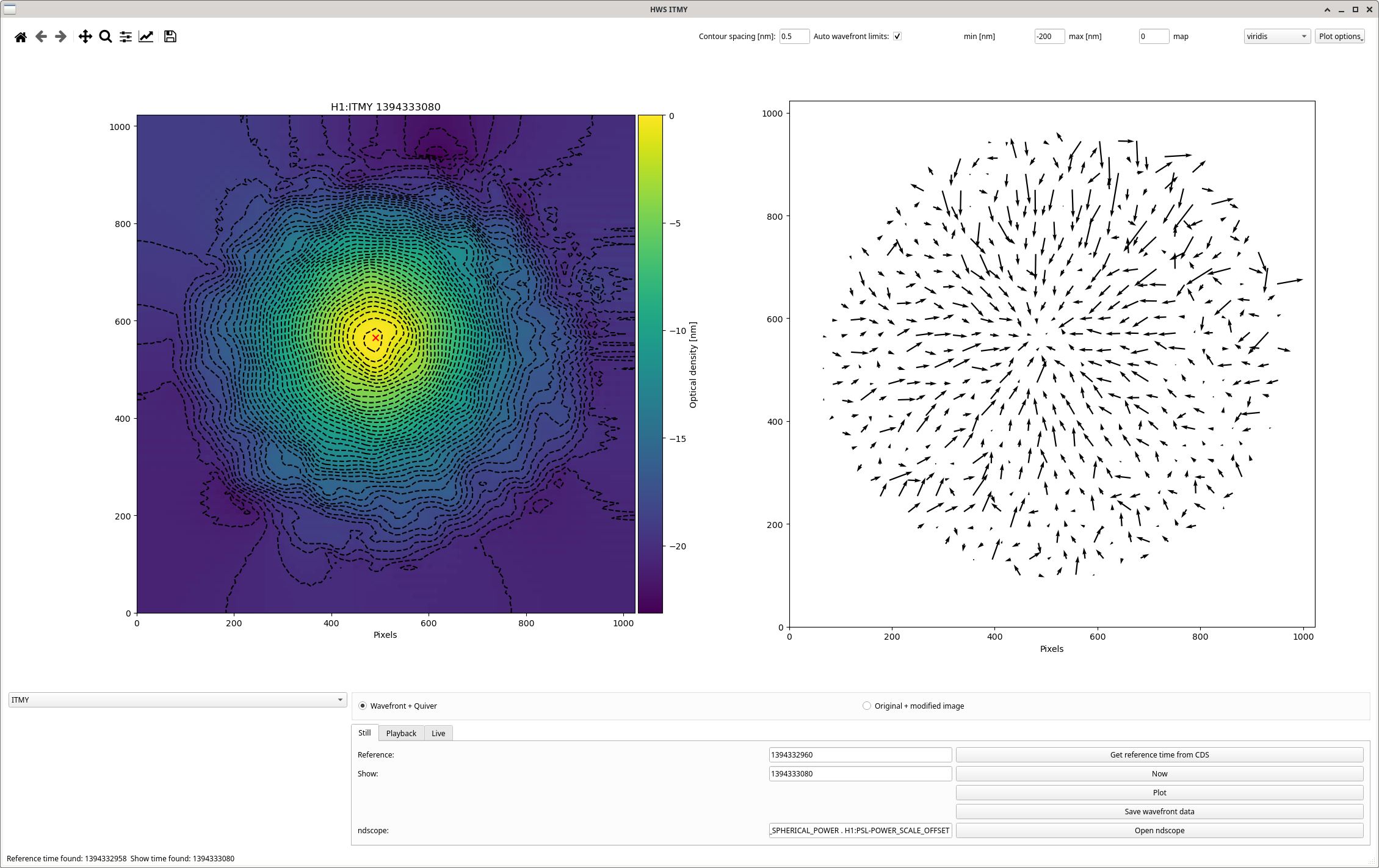
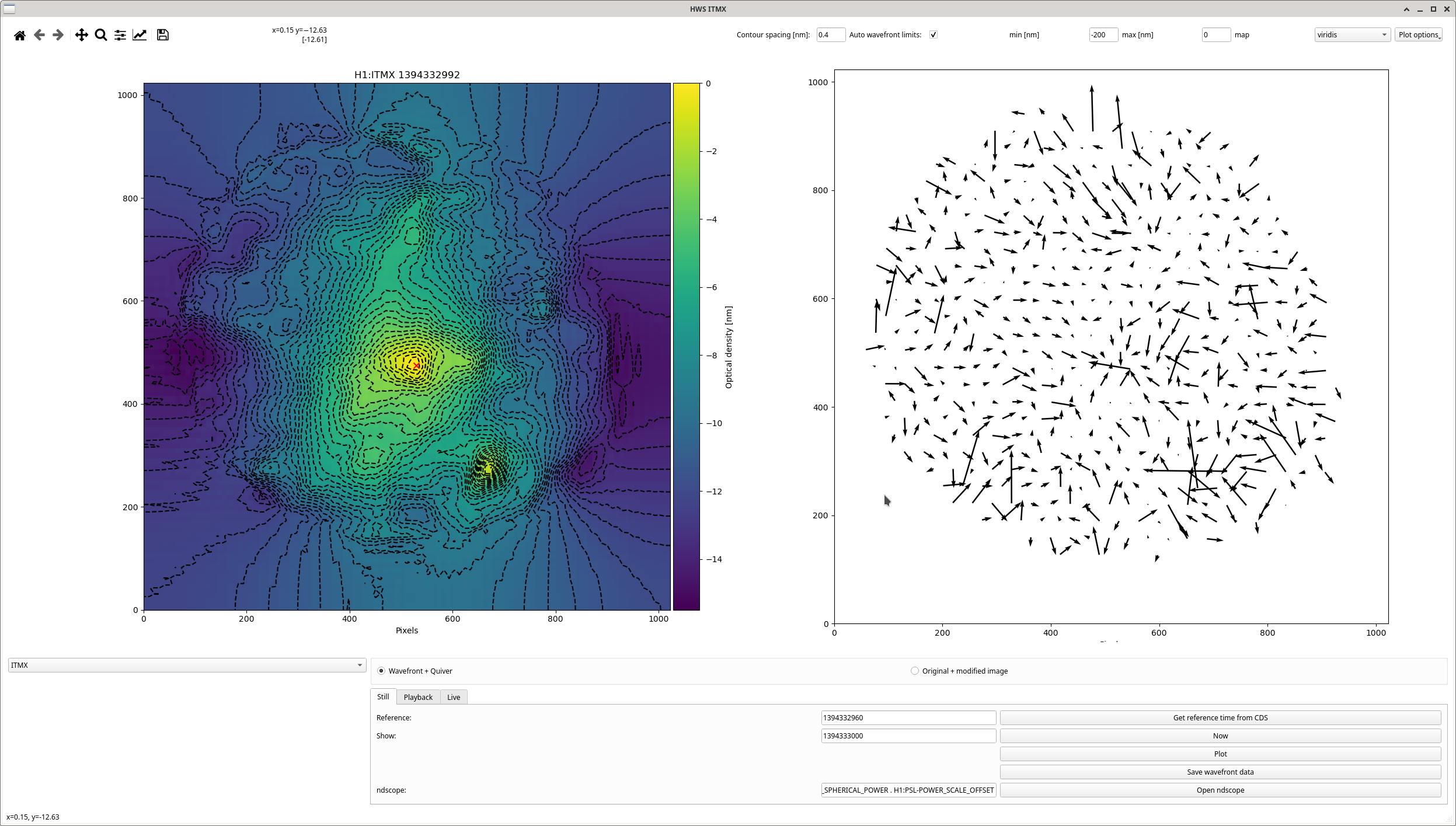
(2 screenshots attached for this one)
Arm Length Stabilization
ALS_DIFF [LOCK] Ramps DARM gain to 40, waits 5 seconds, ramps DARM gain to 400, waits 10 seconds. Seems long.
ALS_DIFF Line 179, waits 2* the DARM ramp time, but why?
ALS_DIFF [LOCK] Enegages boosts with a 3 second wait, engages boosts with another 10 second wait
ALS DIFF Line 191 wait timer 10 seconds seems unnecessary.
ALS_COMM [PREP_FOR_HANDOFF] line 90 5 second wait - maybe we could shorten this?
ALS_COMM [HANDOFF_PART_3] lines 170 and 179 - 2 and 5 second timers but I'm not sure I get why they are there
ALS_COMM's Find IR takes 5 seconds of dark data, has two hard coded VCO offsets in FAST_SEARCH, if it sees a flash it waits 5 seconds to make sure it's real, and then moves to FINE_TUNE_IR, taking 50 count VCO steps until the transmitted power is >0.65
Suggest updating the hard coded offsets (ALS_DIFF line 247) from [78893614, 78931180] to [78893816, 78931184] (second spot seems good, first spot needs a few steps)
ALS_DIFF's find IR has 3 locations saved in alsDiffParams.dat which it searches around. This list gets updated each time it finds a new spot, HOWEVER the search starts 150 counts away from the startin location and steps in in increments of 30. Seems like it would be more efficient to start 30 below the saved offset?
ISC_LOCK [CHECK_IR] line 1206 has a 5 second wait after everything is done which could probably be reduced?
Power- and dual- recycled michelson locking
PRMI locking - a bunch of 1 second waits idk if they are needed?
ISC_DRMI line 627/640 [PRMI_LOCKED] self.timer['wait']=1 seems maybe unnecessary?
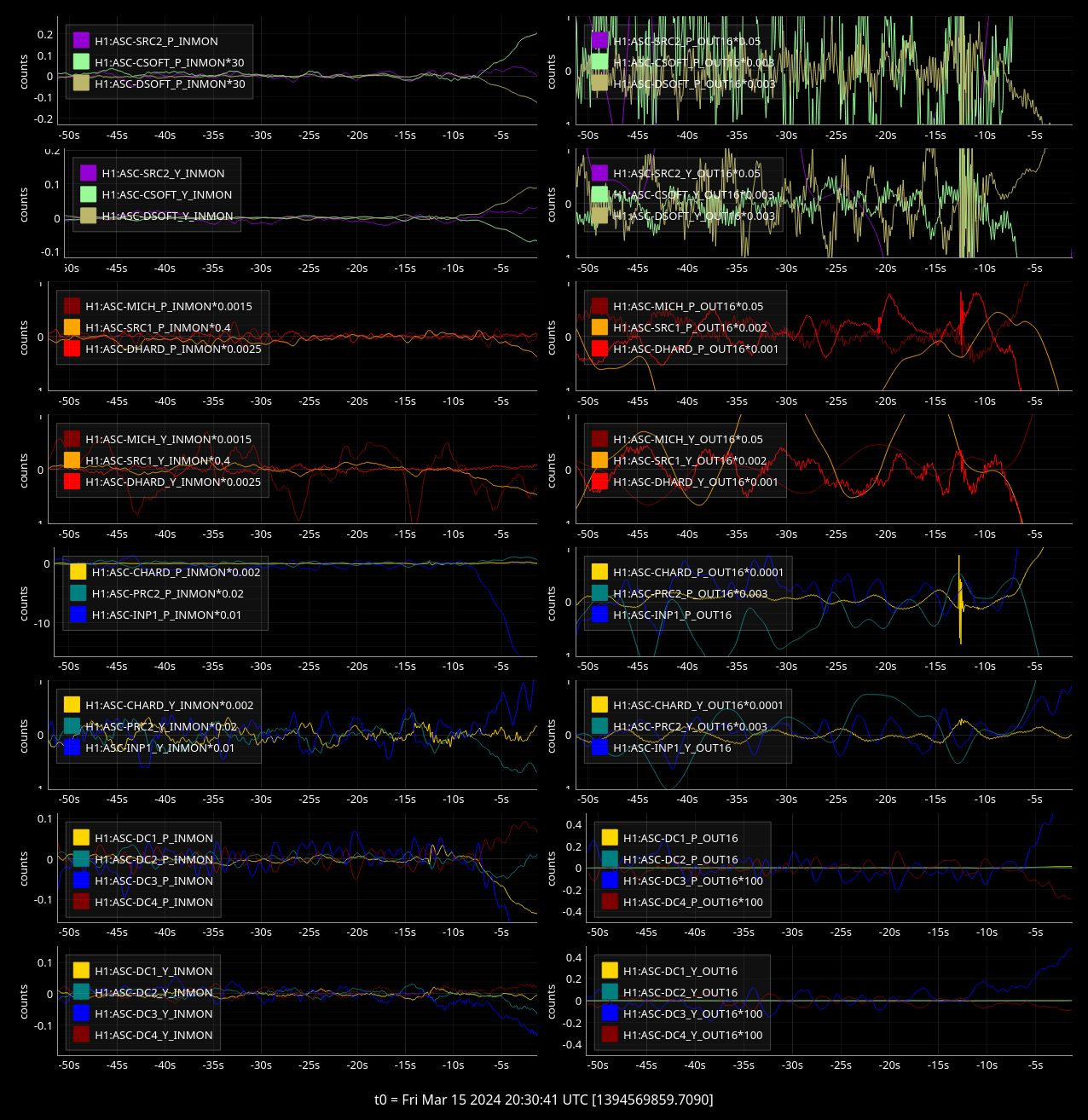
ISC_DRMI line 746, 748 [ENGAGE_PRMI_ASC] - MICH P and Y ASC ramps on with a 20 second timer, but wait = false, but this seems long anyway?
ISC_DRMI line 762/765/768 [ENGAGE_PRMI_ASC] self.timer['wait'] = 4... totally could remove this?
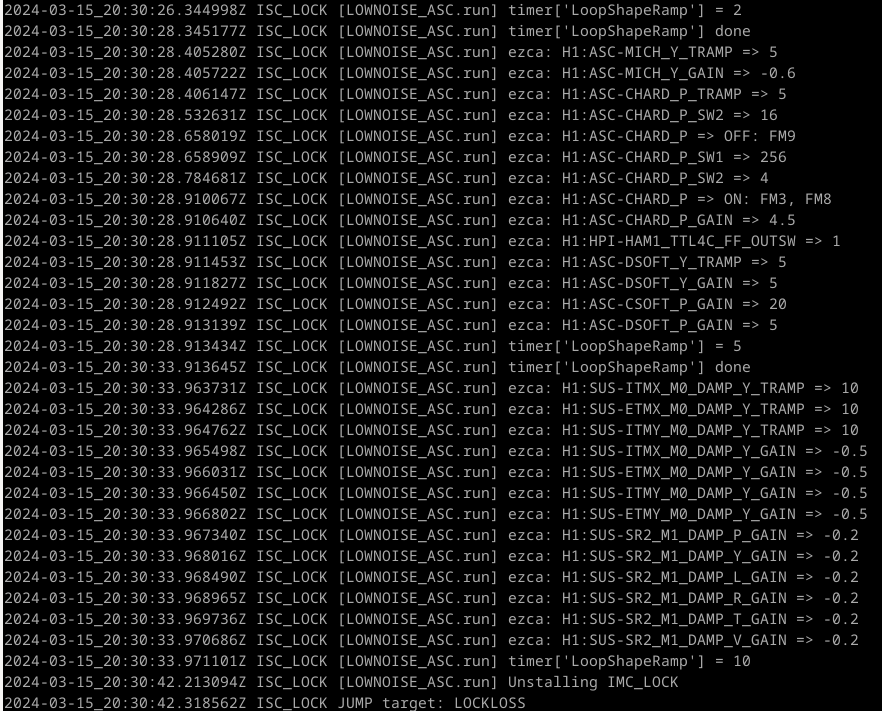
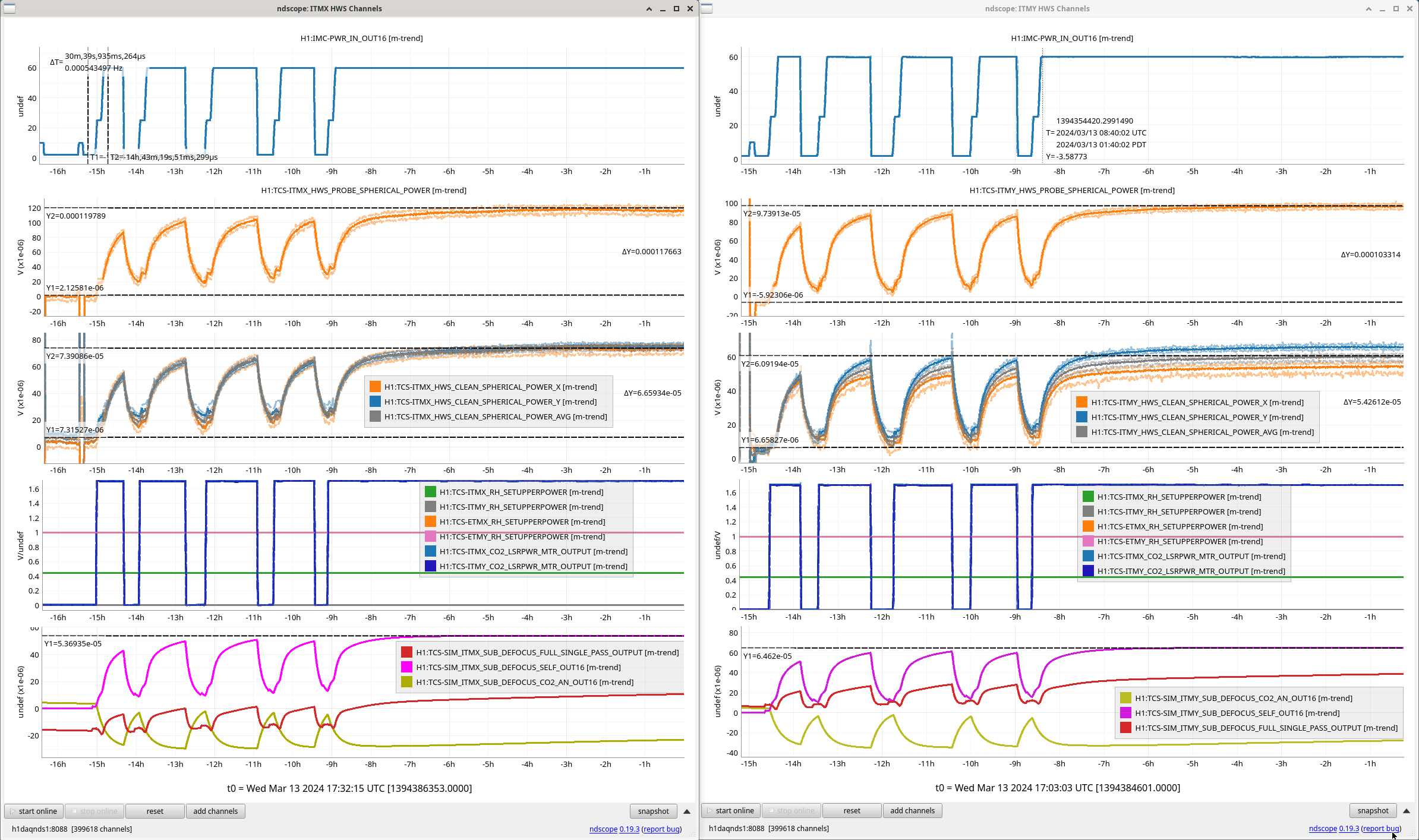
ISC_DRMI [PRMI_TO_DRMI] line 835 - wait timer of 4 seconds (but I don't think it actually waited 4 seconds, see third attached screenshot, so maybe I dont know what time['wait'] really means!!!
When doing the PRMI to DRMI transition it first offloads the PRMI ASC, does the PRMI_TO_DRMI_TRANSITION state, then runs through the whole DOWN state of ISC_DRMI which takes ~25 seconds? maybe there can be a quicker way to do this
In ISC_DRMI there's a self.caution flag which is set as True if AS_C is low, and has 10 second waits after ASC engagements and a *90 second* wait before tirning on the SRC ASC. Might be worthwhile to to replace this with a convergence checker since it might not be needed that we wait for a minute and a half if we are already well algined
Line 1845 ISC_LOCK [CHECK_AS_SHUTTERS] 10 second wait for...? This happens after the MICH RSET but before the FAST SHTTER is reqested to READY
Lines 1837/8 and 1865 redundant?
Line 1870 wait timer 2 seconds after AS centering + MICH turned back on but why
Line 1887 - straight up 10 second wait after increasing MICH gain by 20dB
CARM offset
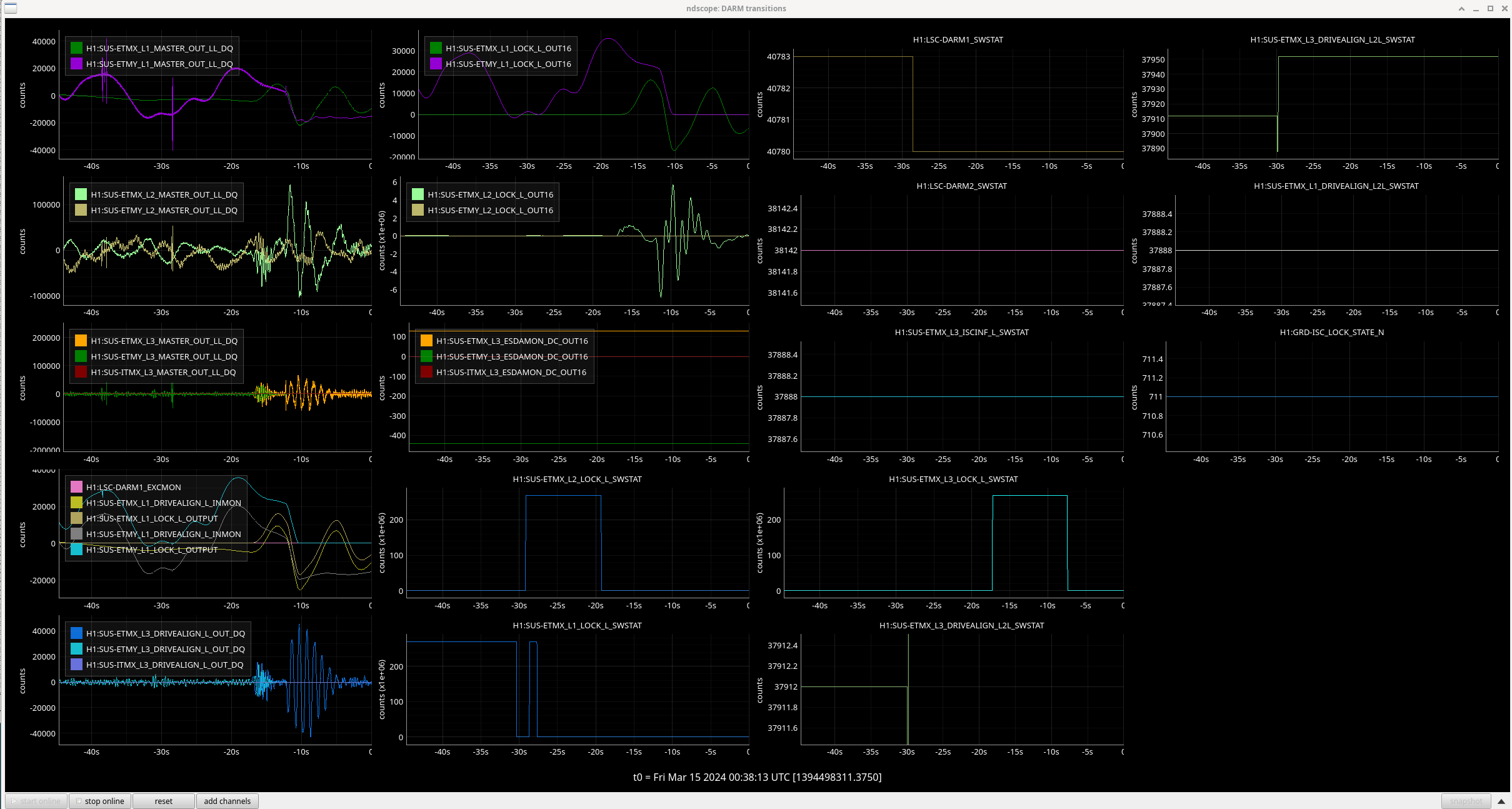
Line 2119 [CARM_TO_TR] time.sleep(3) at the end of this state not clear what we're waiting for
Line 2222 [DARM_TO_RF] self.timer['wait'] = 2 that used to be 1
Line 2235 [DARM_TO_RF] another 2 second timer?
Line 2314 [DHARD_WFS] 20 second timer to turn DHARD on, but maybe we should just go straight to convergence checking once the gains are ramped on?
Line 2360 [PARK_ALS_VCO] 5 second wait after resetting the COMM and DIFF PLLs
Line 2406 [SHUTTER_ALS] 5 second wait followed by a 1 second sleep after the X arm, Y arm, and COMM are taken to shuttered
Line 2744 [CARM_TO_ANALOG] 2 second wait when REFLBIAS boost turned off but before summing node gain (A IN2) increased?
Line 2753 [CARM_TO_ANALOG] 5 second wait after summing node gain increased
Line 2760 [CARM_TO_ANALOG] 2 second wait after enabling digital CARM antiboost?
Line 2766 [CARM_TO_ANALOG] 2 second wait after turning on analog CARM boost
Line 2772 [CARM_TO_ANALOG] 2 second wait after raming the REFL_DC_BIAS gain to 0, actually maybe this one makes sense.
Full IFO
There are a ton of waits during the ASC engagement but I think usually the convergence checkers are the limit to time spent in the state.
Line 3706 [ENGAGE_SOFT_LOOPS] 5 second wait after everything has converged?
Line 3765 [PREP_DC_READOUT_TRANSITION] 3 second wait after turning on DARM boost but shouldn't it be 1 second?
Line 3816 [DARM_TO_DC_READOUT] 10 second wait after switching DARM intrix from AS45 to DC readout, might be excessive
Line 3826/7 [DARM_TO_DC_READOUT] - DARM gain is set to 400 (but it's already 400!) and then there is a 4 second wait, these two lines can for sure be removed!
Line 3834 [DARM_TO_DC_READOUT] - 5 second wait after turning ramping some offsets to 0 BUT the offsets ramp much more quickly than that!
Power up
line 4033 [POWER_10_W] 30 second wait after turning on some differential arm ASC filters but actually, never mind I don't think it actually does this wait
Line 4299 [REDUCE_RF45_MODULATION_DEPTH] we have a 30 second ramp time to ramp the modulation depths, maybe this could be shorter?
Line 4614 [MAX_POWER] 20 second thermal wait could be decreased?
Line 4641 [MAX_POWER] 30 second thermal wait could be decreased??
Line 4645 [MAX_POWER] 30 second thermal wait for the final small step could be devreased?
Lownoise stuff
line 4463/4482 [LOWNOISE_ASC] 5 second wait after we turn off RPC gains that were already off
line 4490 [LOWNOISE_ASC] 10 second wait after CHARD_Y gain lowered, but it looks to have stabilized after 5 seconds so I think we can drop this to 5.
honestly a lot of waits in lownoise_asc so I ran out of time to check them all for necessity