Jeff K, Dave B, Oli P
All of the optics (except OFIS, OPOS, and HXDS) were originally built with a DACKILL that will only trip if all of that suspension's Watchdogs trip. This has resulted in some problems (74545, 74622). Because of this, there has been a push to update the logic for each suspension to have an OR instead of an AND, so that the IOP DACKILL trips as soon as any one of the stages trips.
The Watchdogs for these suspensions also rely on an outdated BLRMS to figure out if the stages are saturating, and people have been wanting this to be updated since 2017(FRS9392). This update to the watchdogs would remove the need for a USER DACKILL, so now is a perfect opportunity to do both at the same time! Suspension models created after 2019 (OFIS, OPOS, HXDS, and the new HXTS) were originally made with the updated watchdogs and without the USER DACKILL, and we haven't had any issues. The changes that we made line up with what was done for these previously changed models.
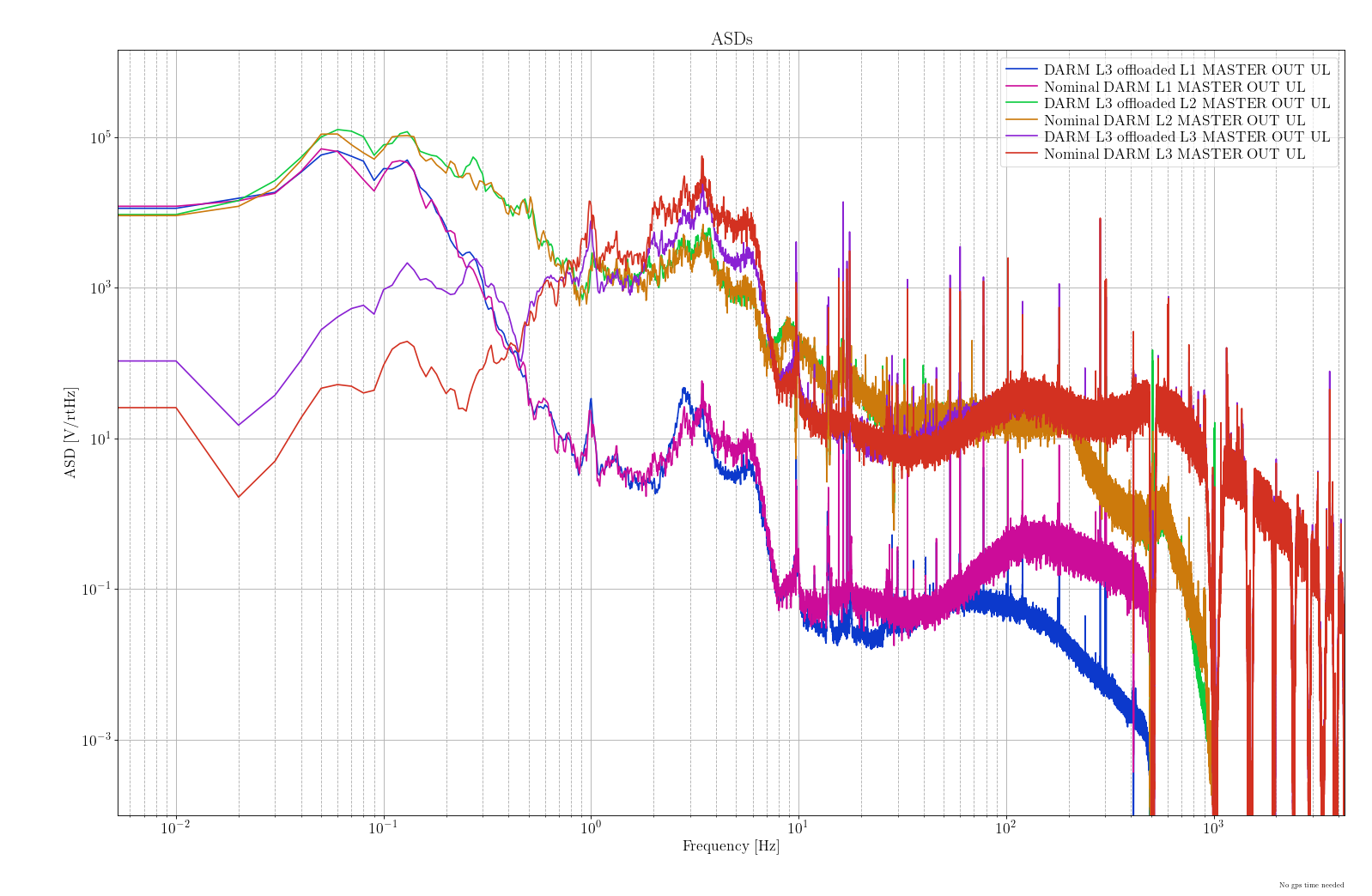
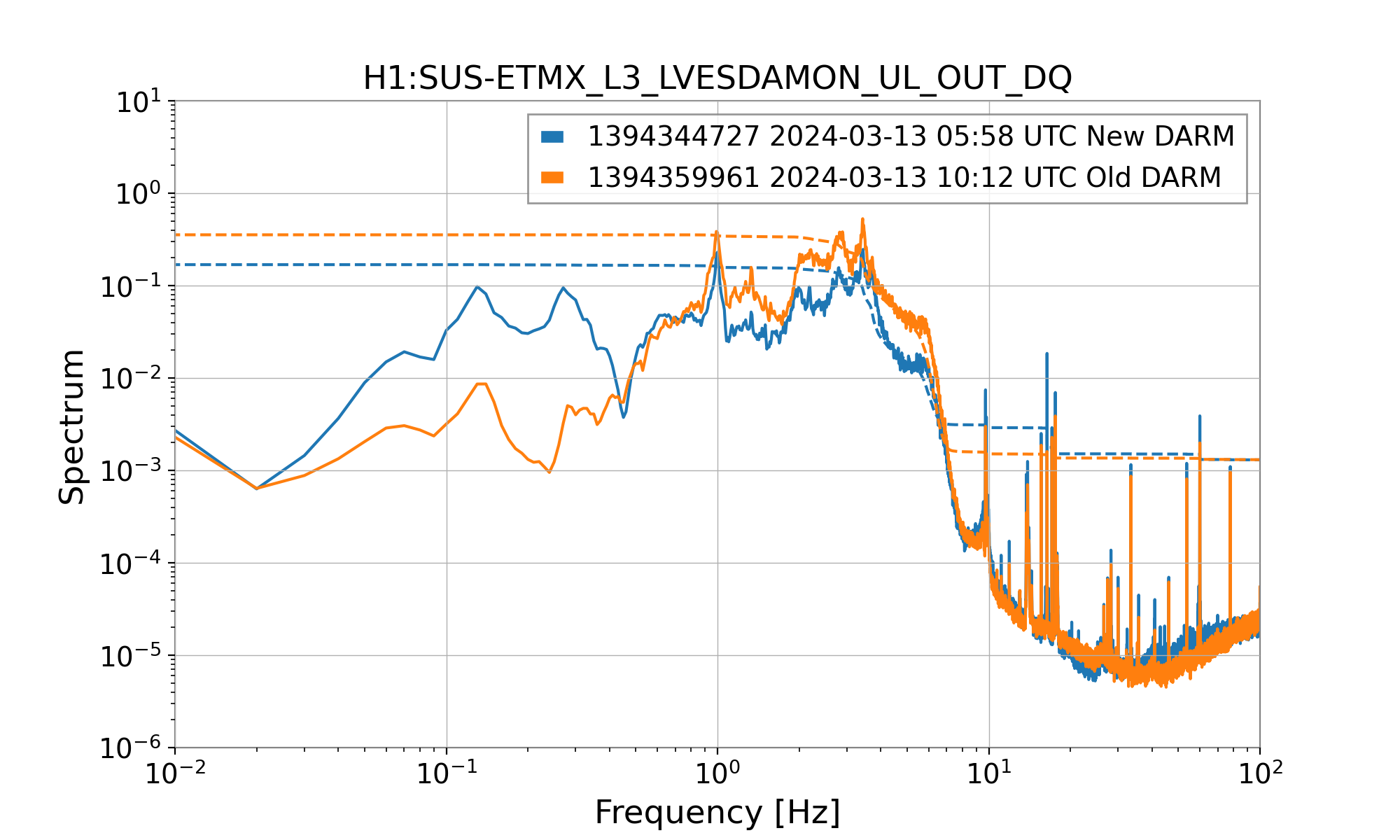
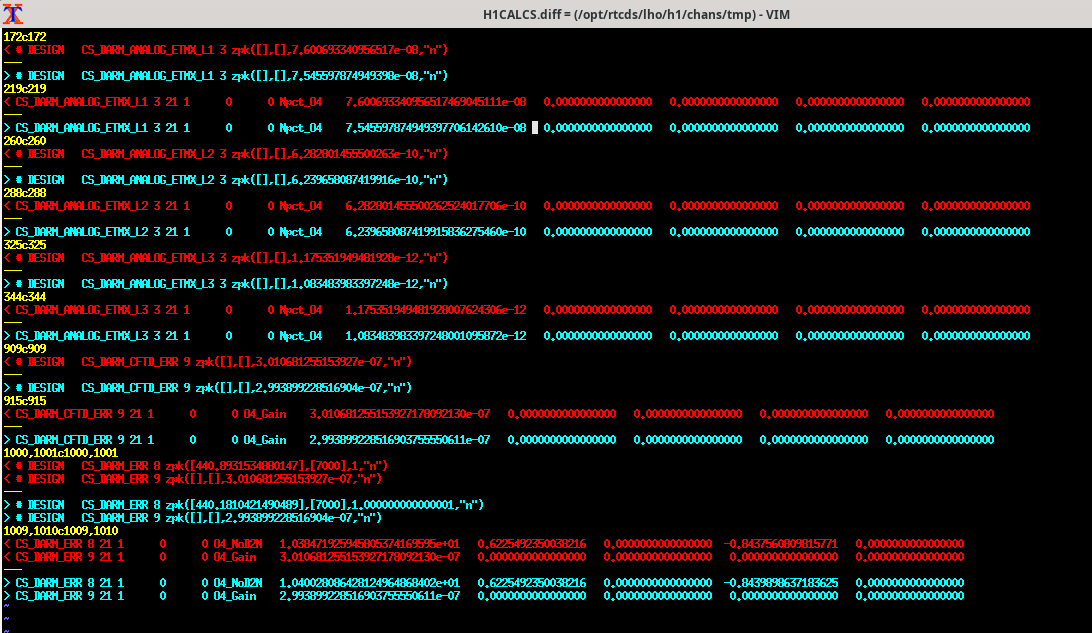
Today we updated the models for the ETMs and TMSs(76305), and we will gradually be updating all of the models.
Changes made:
QUAD MASTER and TMTS Master sus models (QUAD_MASTER.mdl, TMTS_MASTER.mdl):
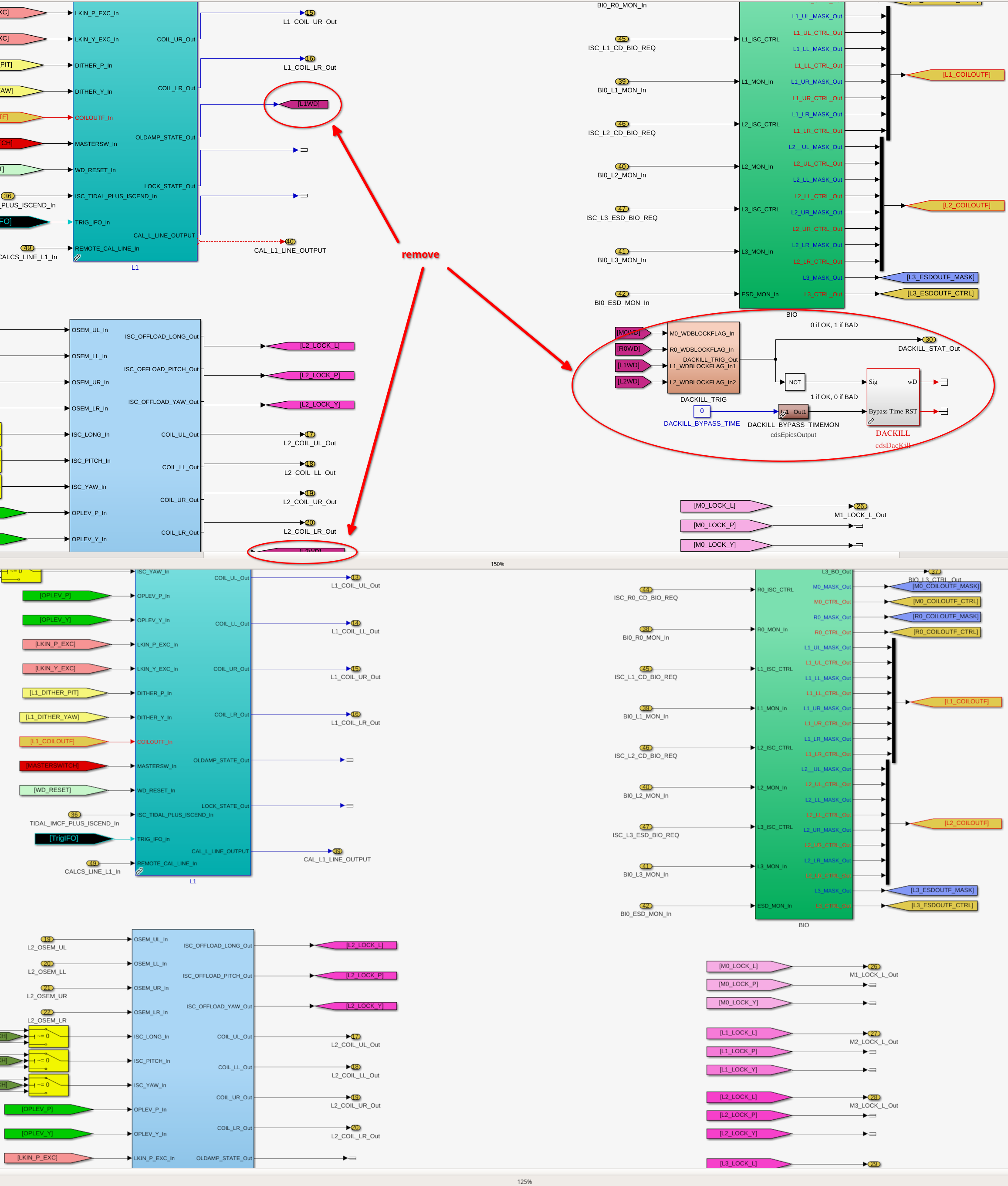
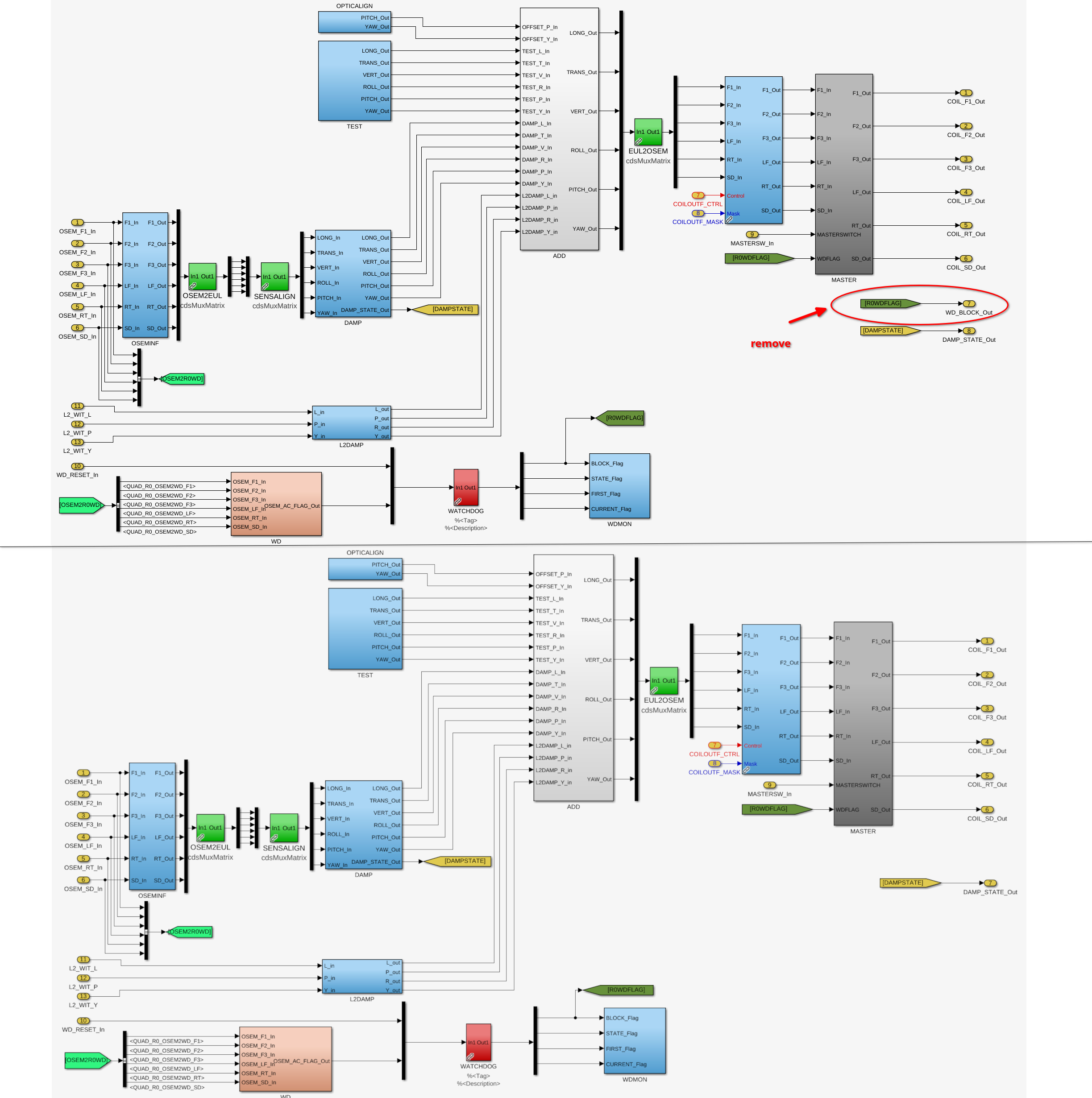
- Top level: Removed USER DACKILL and WD block output flags(attachment1)
- Inside each block with watchdogs: removed the watchdog flags that connect the WD RMS to the DACKILL(attachment2)
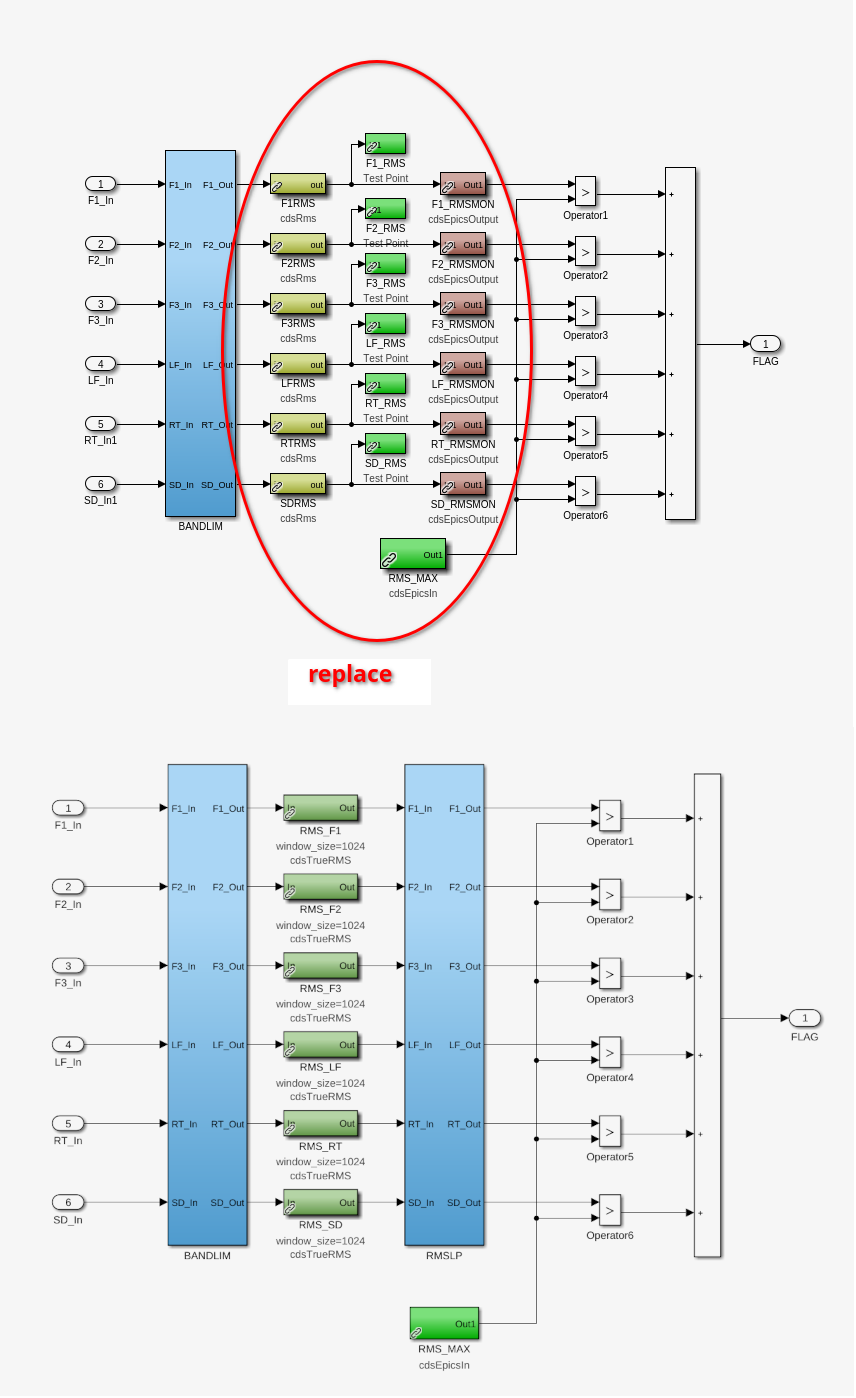
- Inside each WD block within stage blocks: swapped the old WD BLRMS block with the better BLRMSLP block(attachment3)
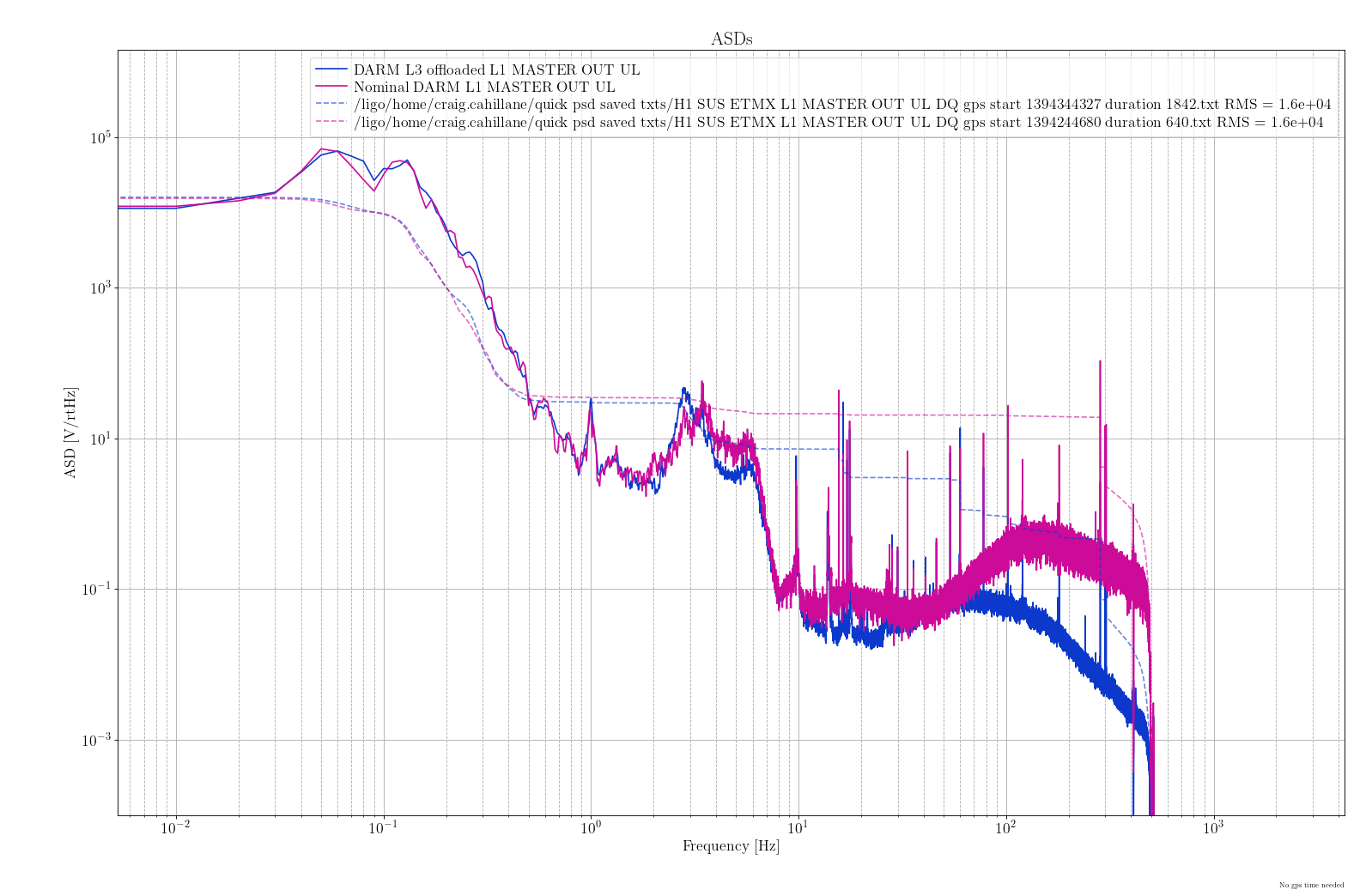
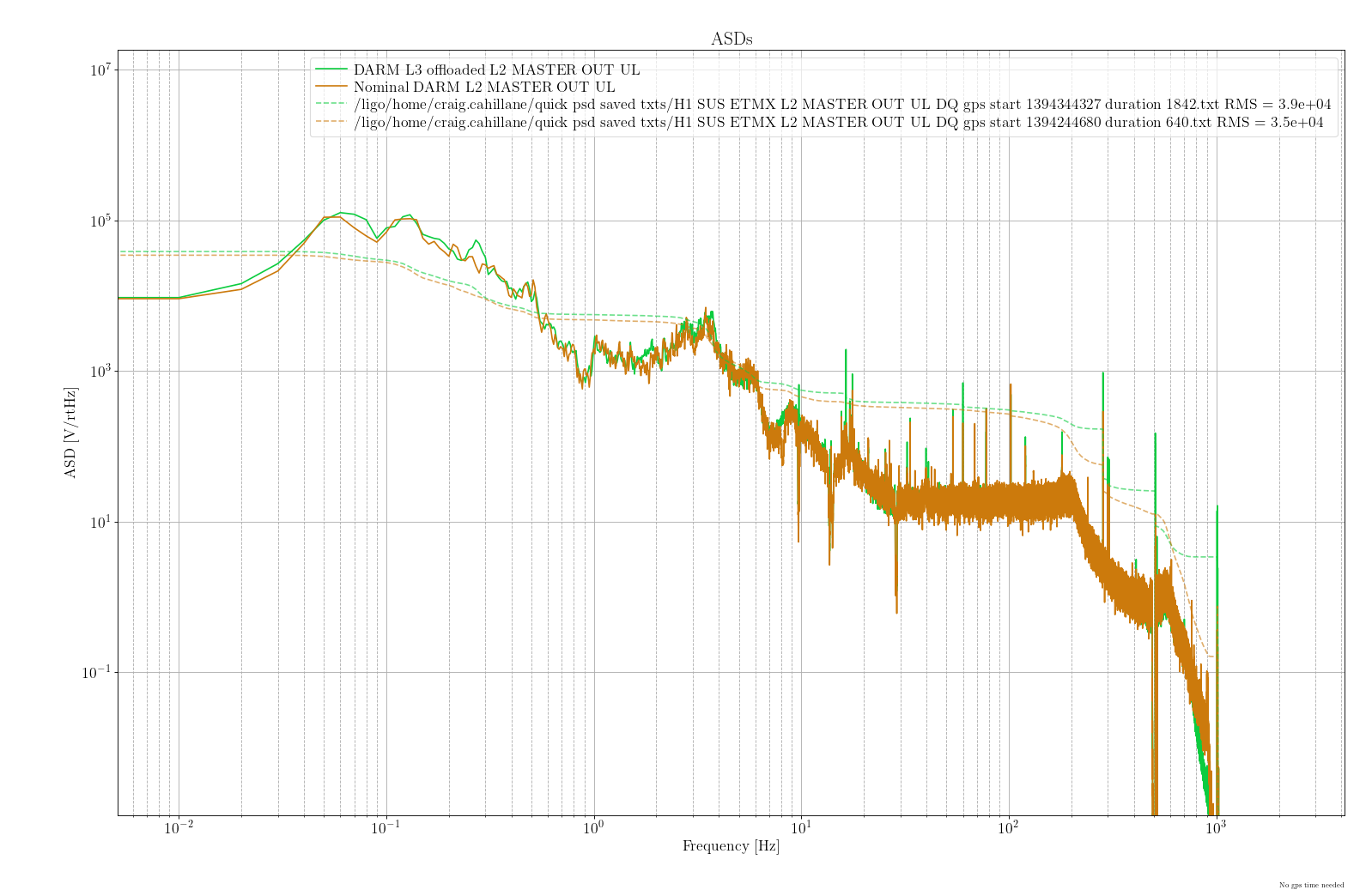
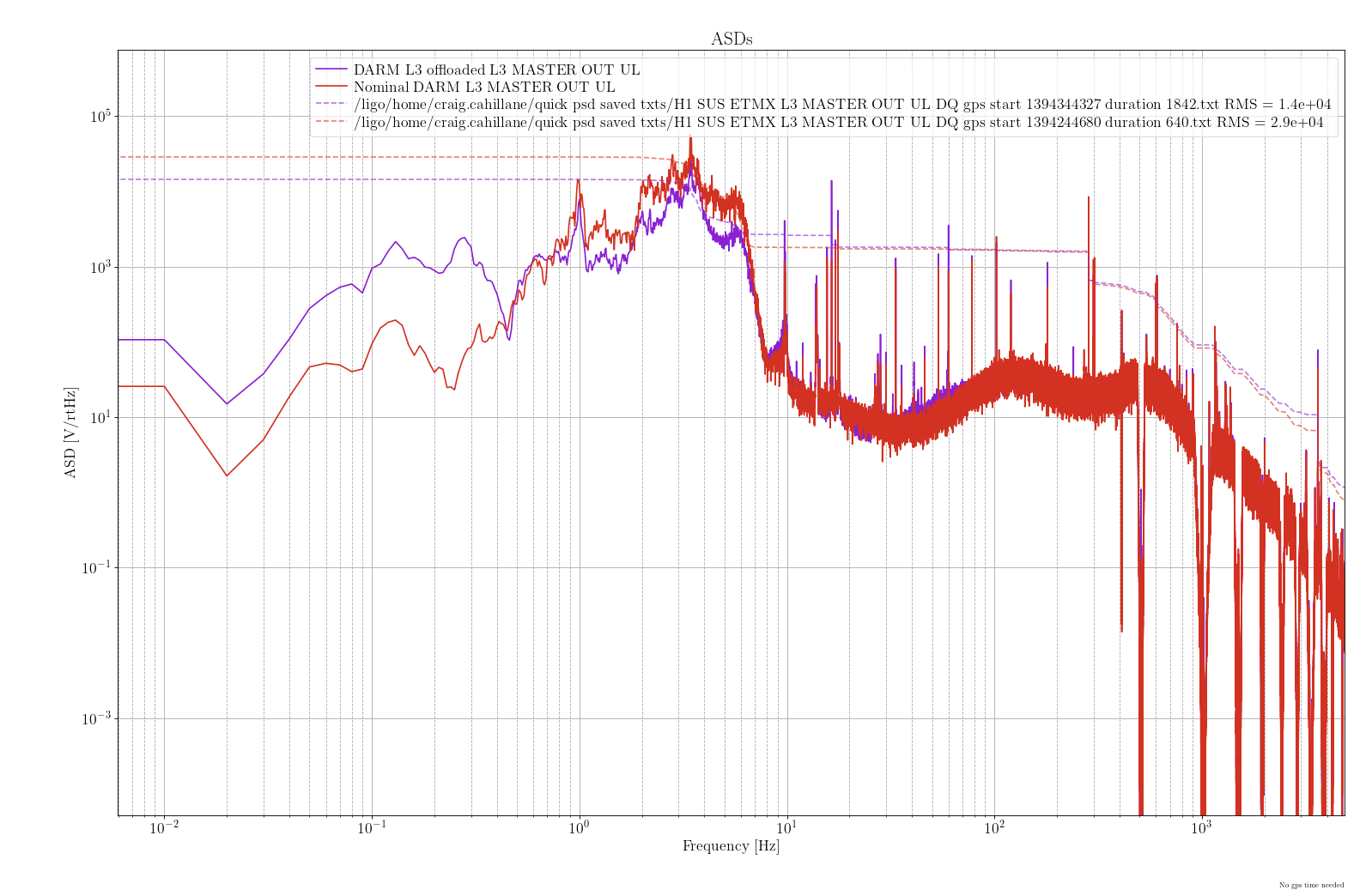
Individal sus models (h1susetmx.mdl, h1susetmy.mdl, h1sustmsx.mdl, h1sustmsy.mdl):
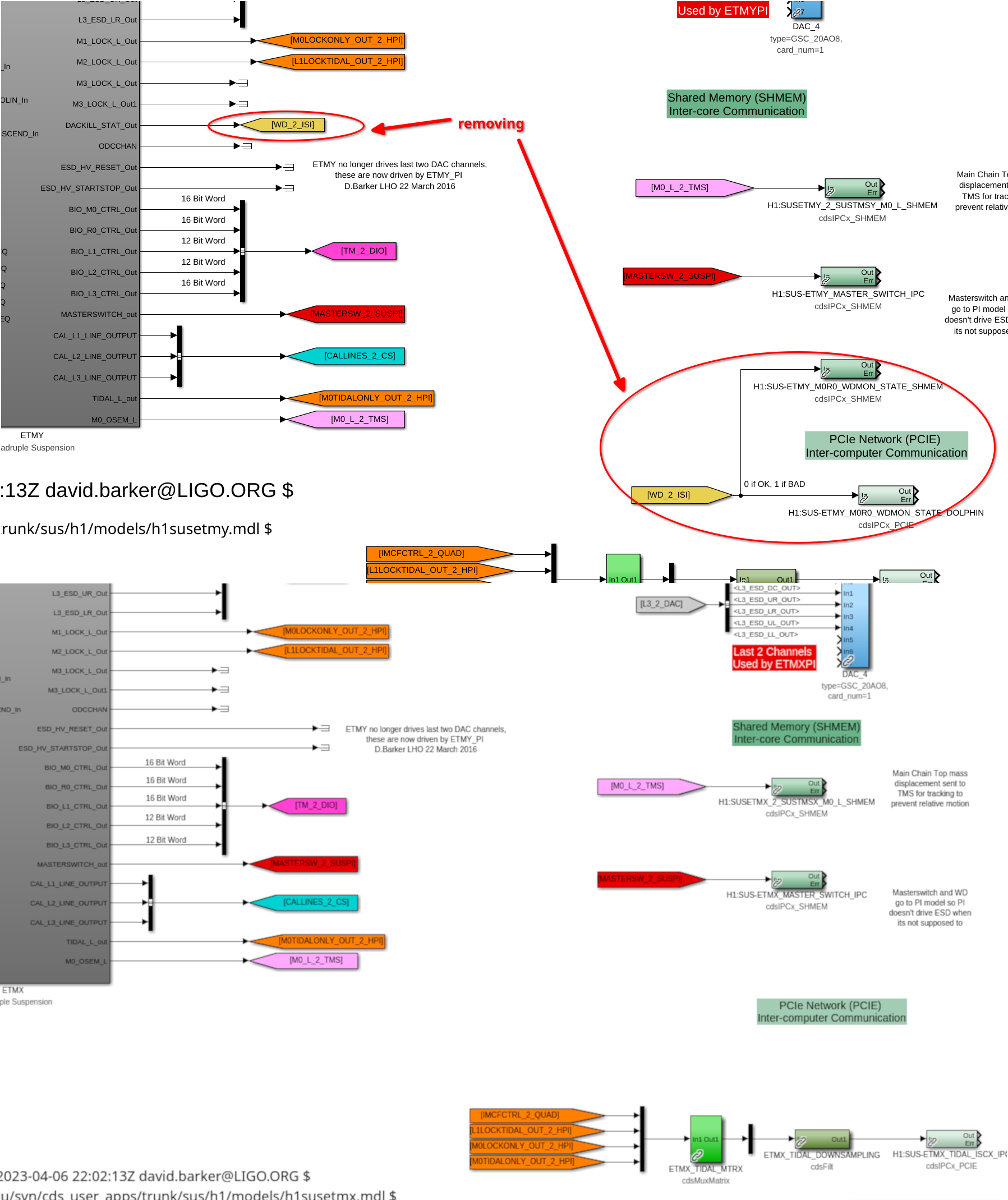
- Removed top level WD_2_ISI output flags and connection of WD_2_ISI out to ISI model(attachment4)
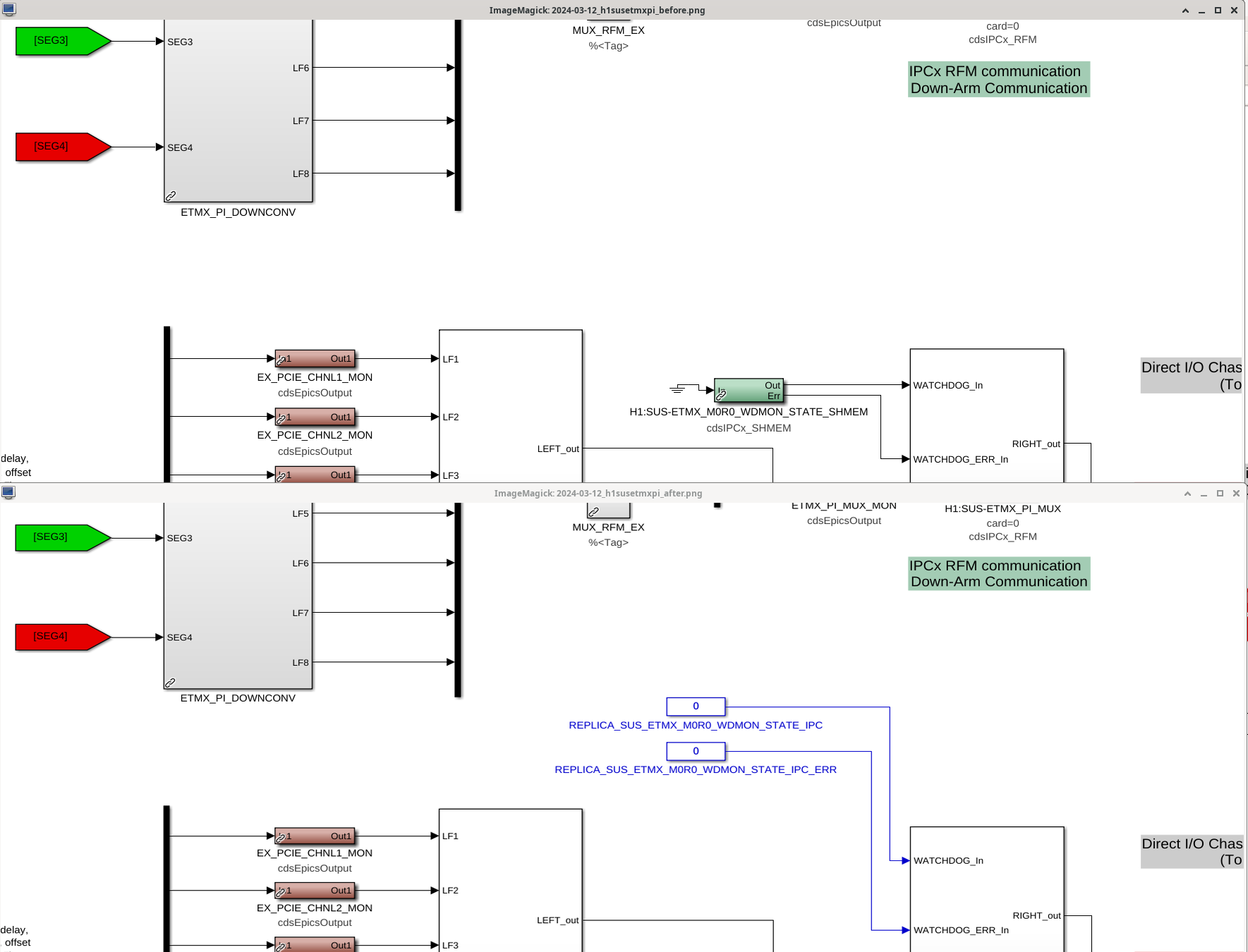
Individual sus pi models(h1susetmxpi.mdl, h1susetmypi.mdl):
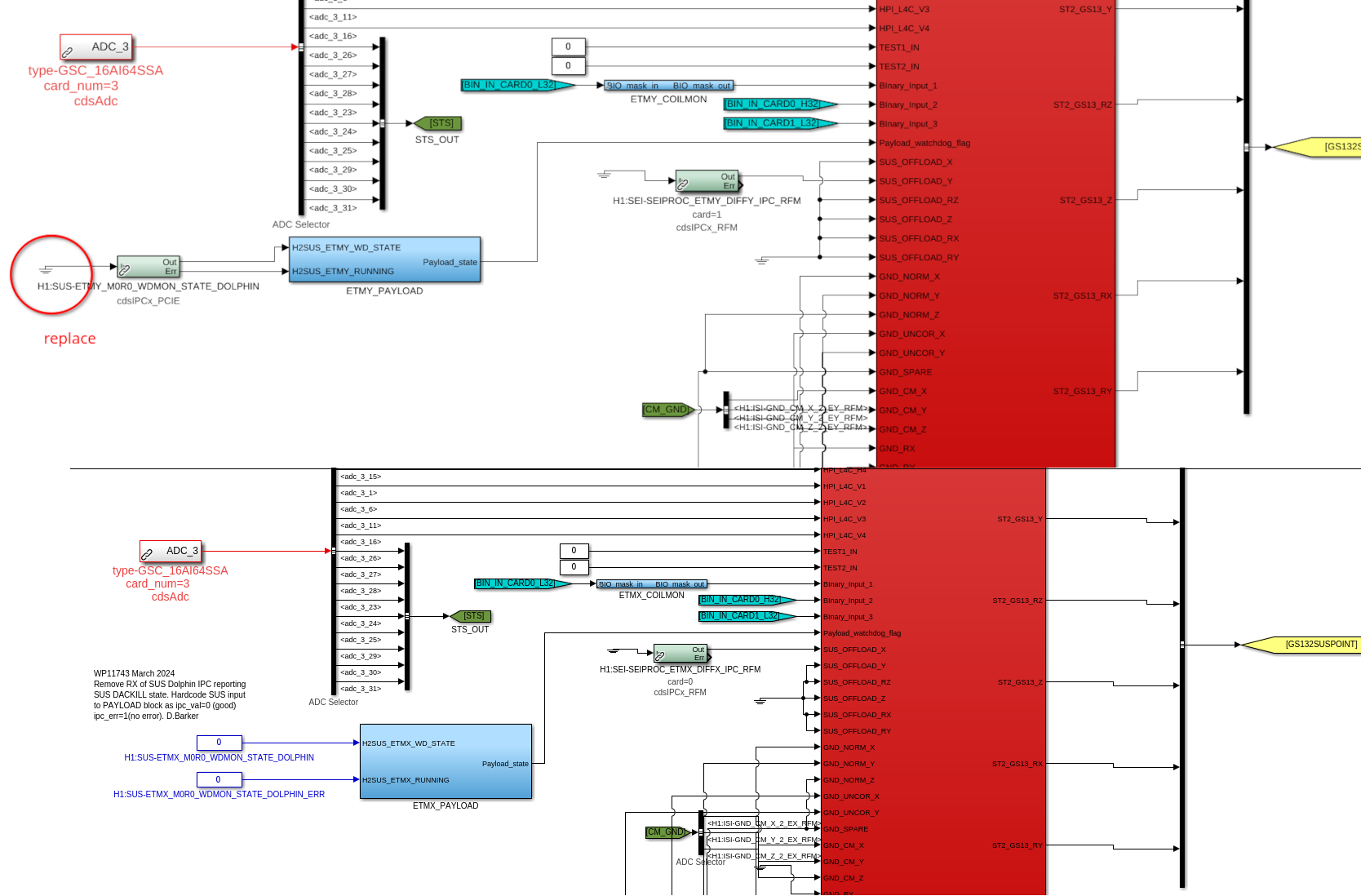
- Found out during installation of these updated models that a WD value that we had removed in the individual models went out to the pi models. The sus pi models were updated to include constants as inputs in lieu of the removed WD values(attachment5)
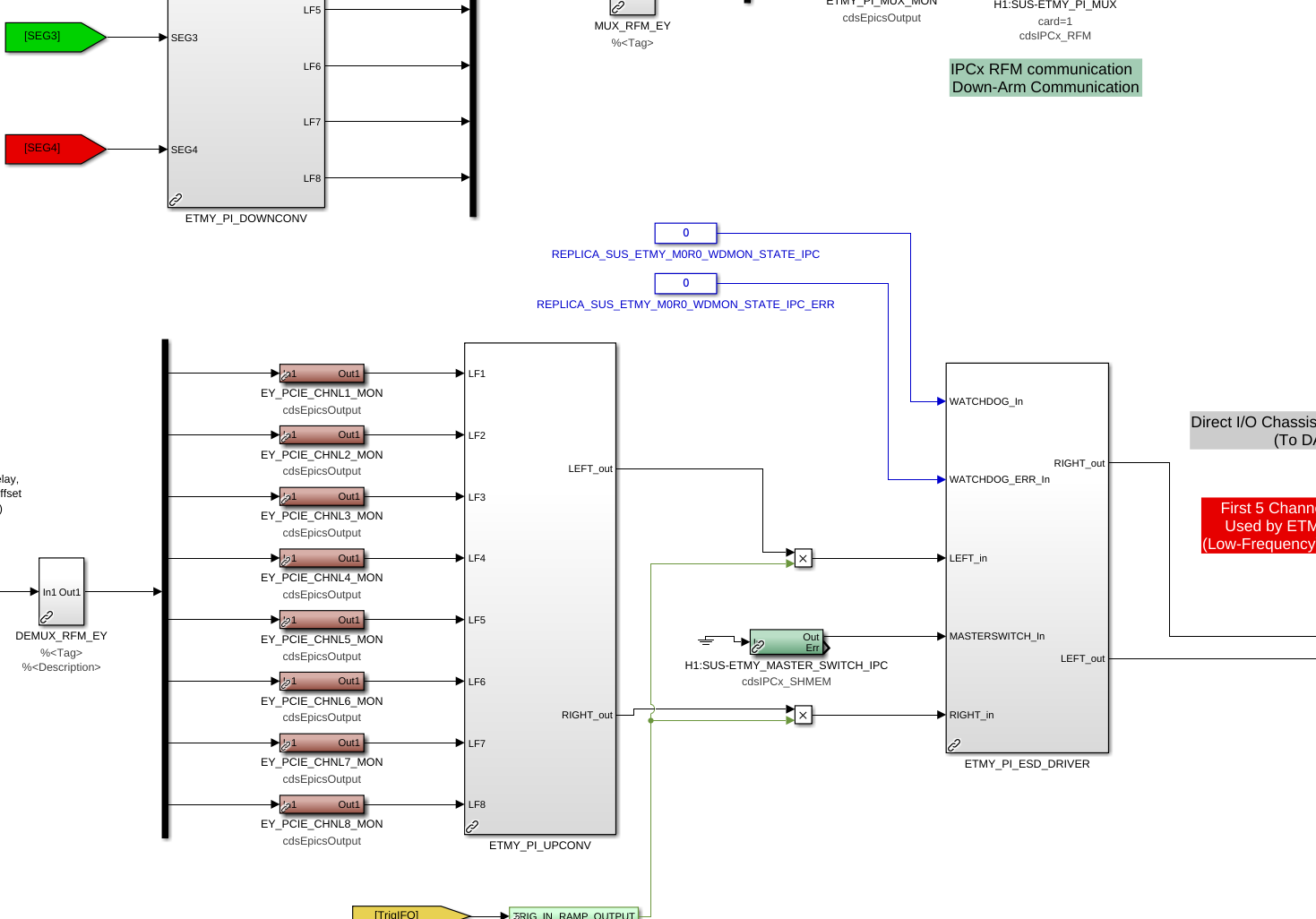
ISI QUAD models (h1isietmx.mdl, h1isietmy.mdl):
- Since the USER DACKILL connects to dolphin, we also changed the ISI QUAD inputs that feed into SUSWD_2_PAYLOAD from ground to both be 0 for WDMON_STATE_DOLPHIN and WDMON_STATE_DOLPHIN_ERR respectively(WDMON_STATE_DOLPHIN_ERR needs to be 1 because it later gets inverted)(attachment6)
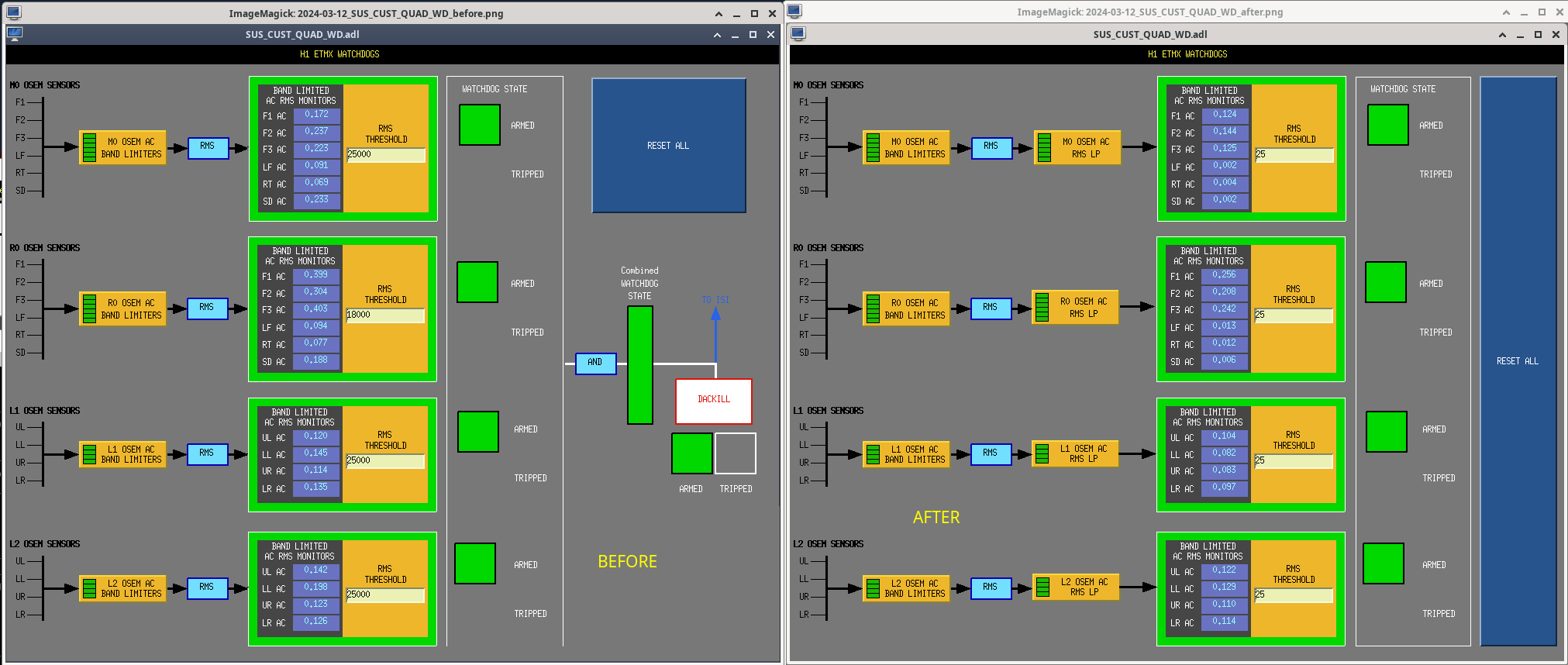
Changes to medms (ETMs,TMSs adl files):
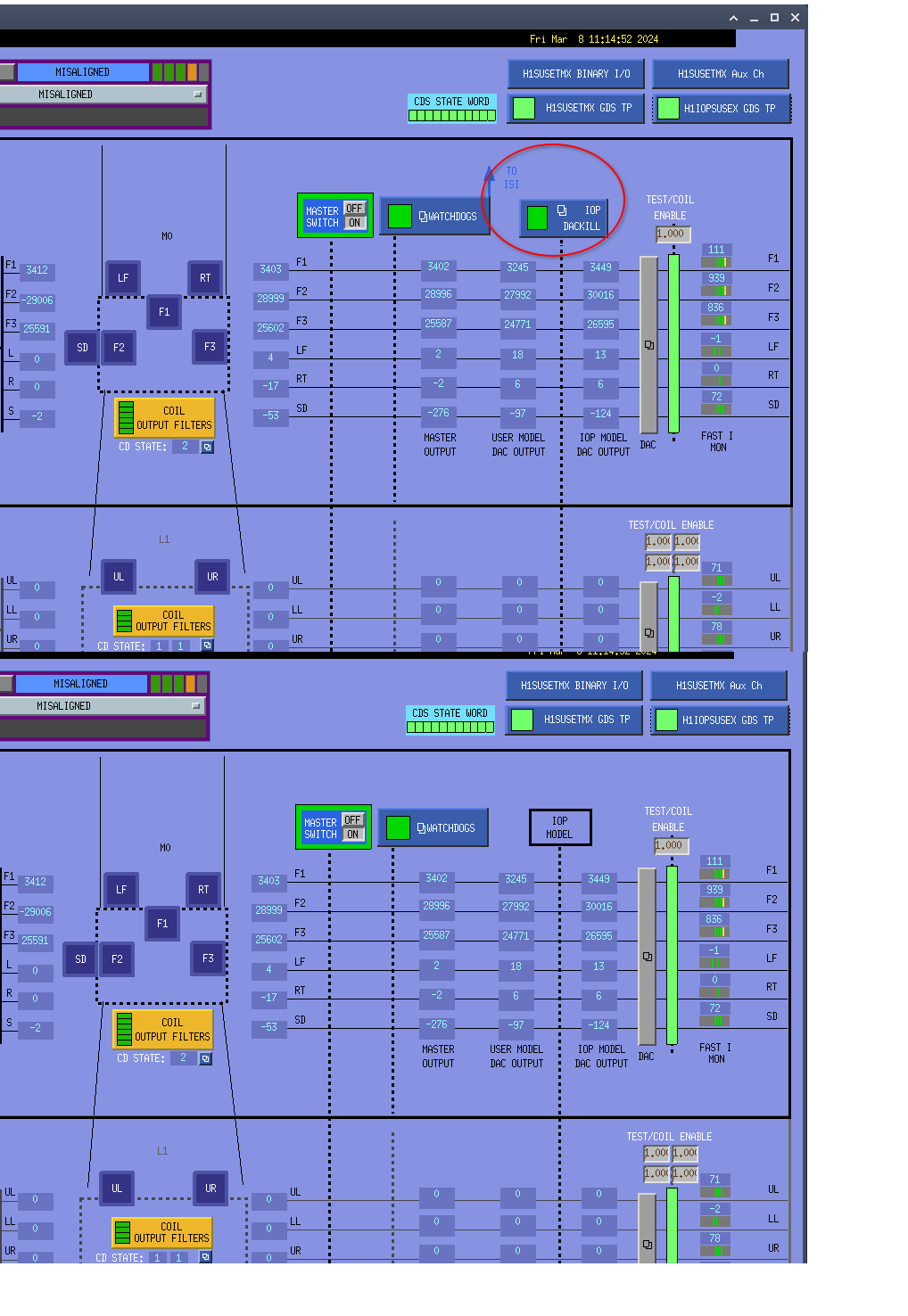
- Removed the IOP DACKILL button on suspension medm and TO ISI arrow(attachment7)
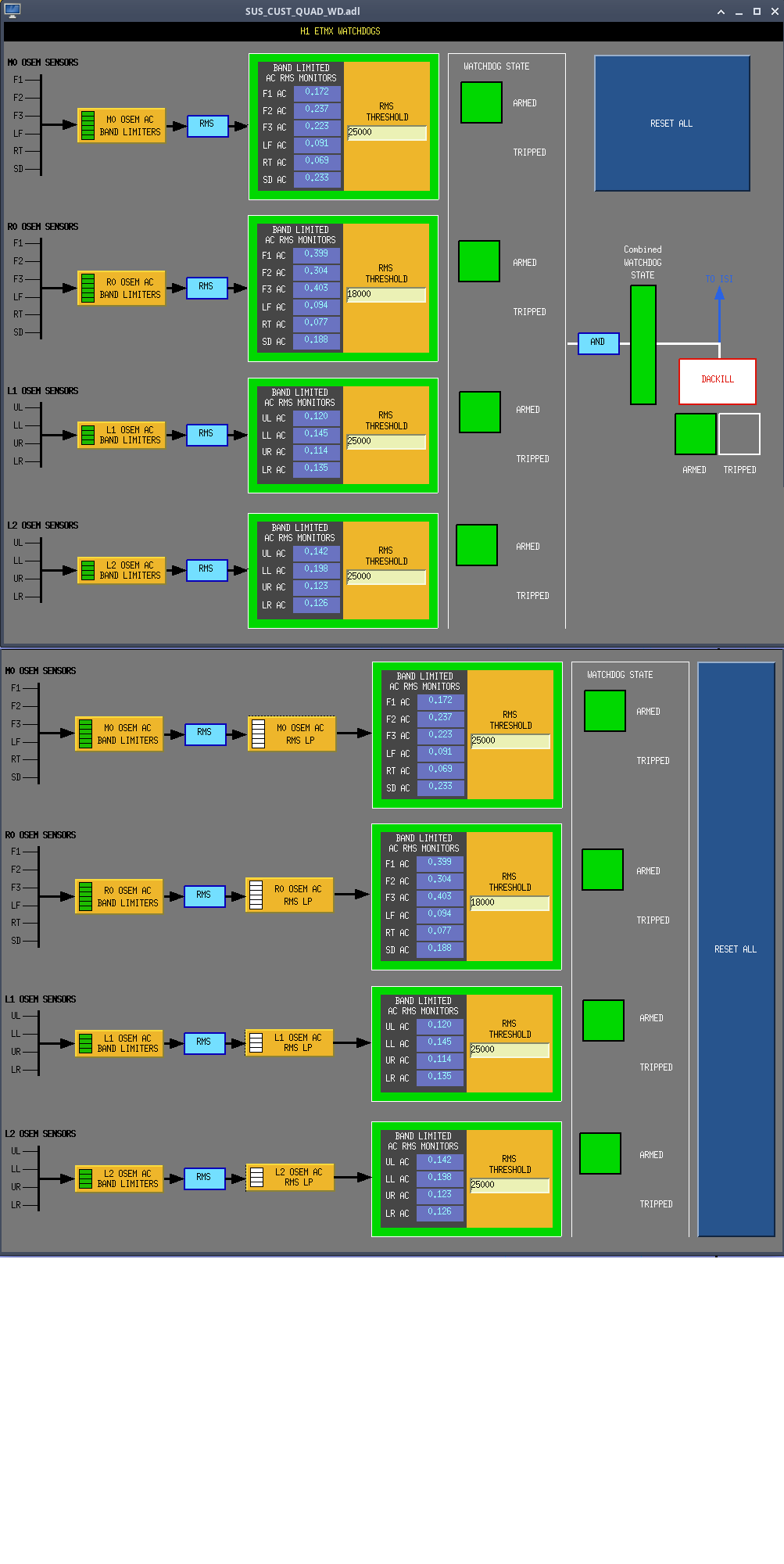
- Inside the watchdog subscreens: added in the filter banks for the low pass and removed the diagrams showing the USER DACKILL logic(attachment8).
All changes have been committed to svn.



{kind=link}
{kind=link}