Ibrahim, Oli, Betsy, Arnaud, Fil
Context: In December ('23) We were having issues confirming that the damping, OSEMs, electronics and model were working (or rather, which wasn't working).
I have more thorough details elsewhere but in short:
- There was initial weirdness in setting offsets and exciting the different degrees of freedom
- Fil and I checked that all OSEMs were healthy by driving excitations to each one at the coil driver level (ensuring that the test stand was working)
- Arnaud was invoked to help with TFs for the BBSS (we couldn't get these to work prior)
- There was a lot more "fixing" and confirming involving excitations, damping, input filters, OSEMs, OLV setting, test stand electronics, and even getting into X1. I have notes on all this elsewhere but this is not the scope of this alog.
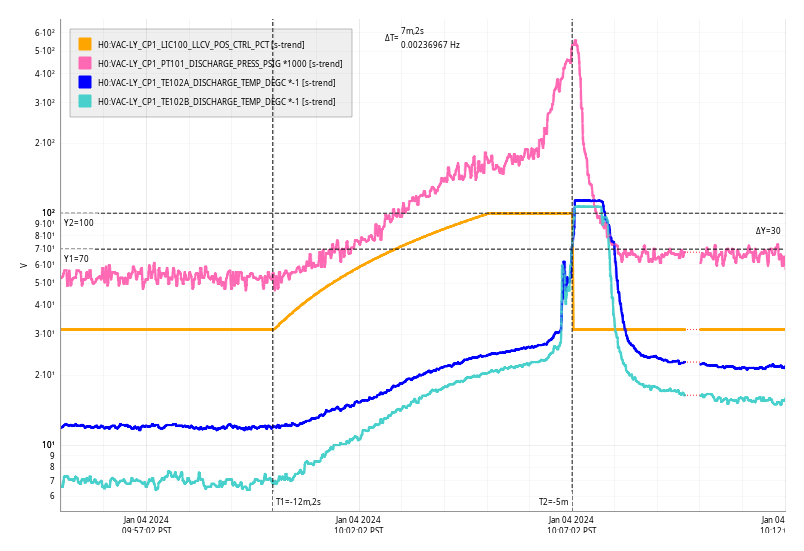
Eventually, we were able to go through Jeff and Oli's alog 74142. Here is what was found:
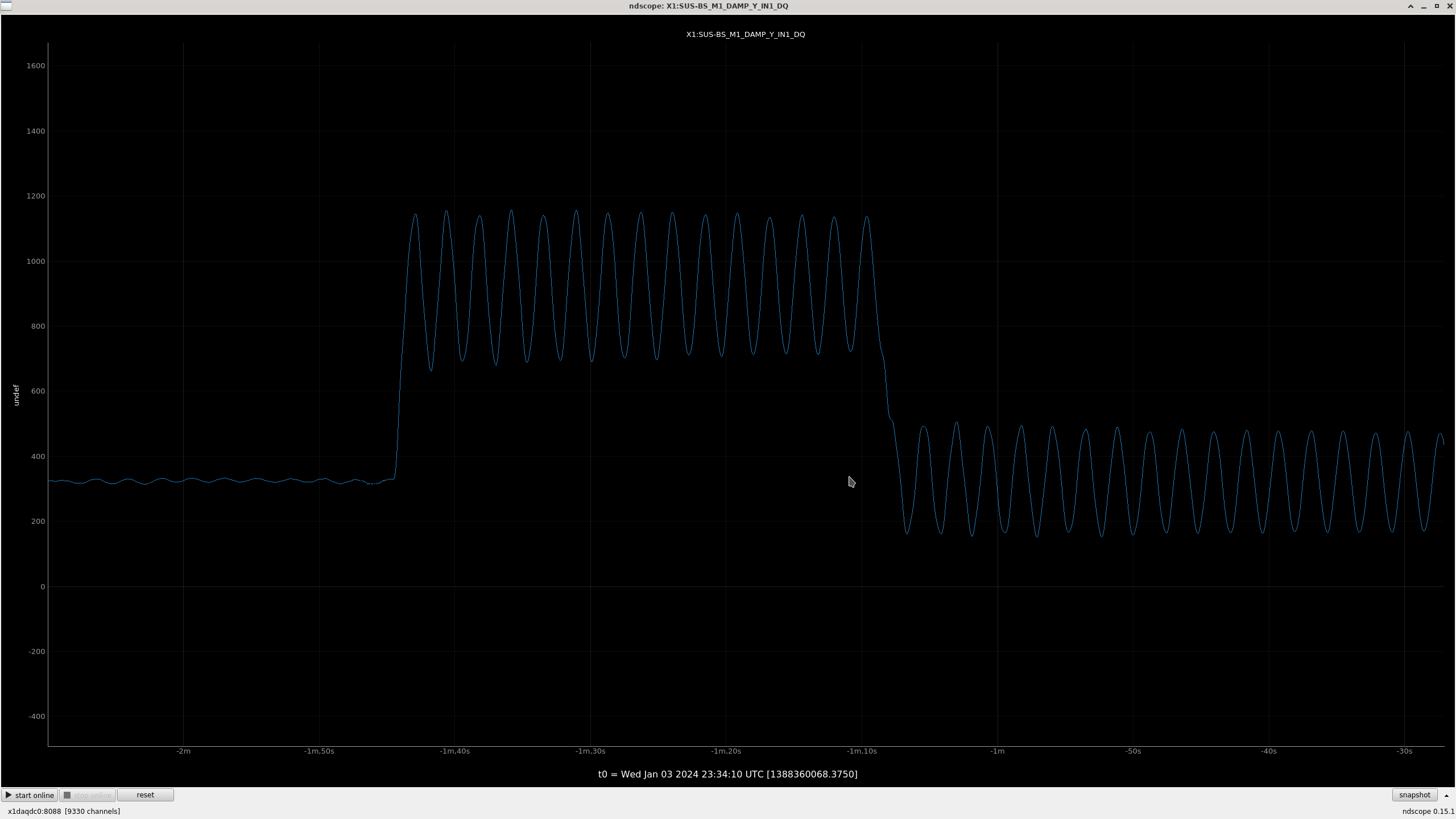
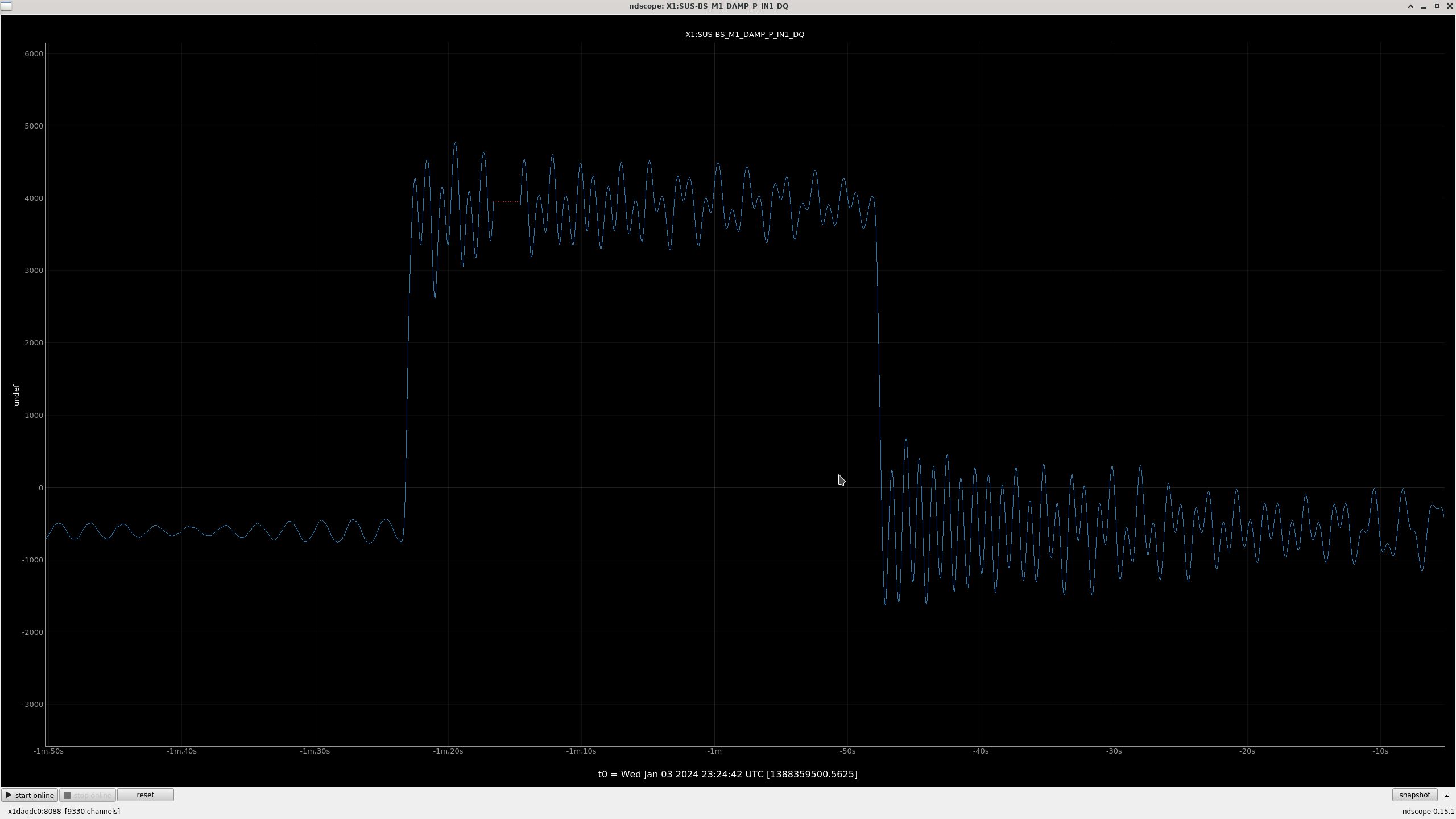
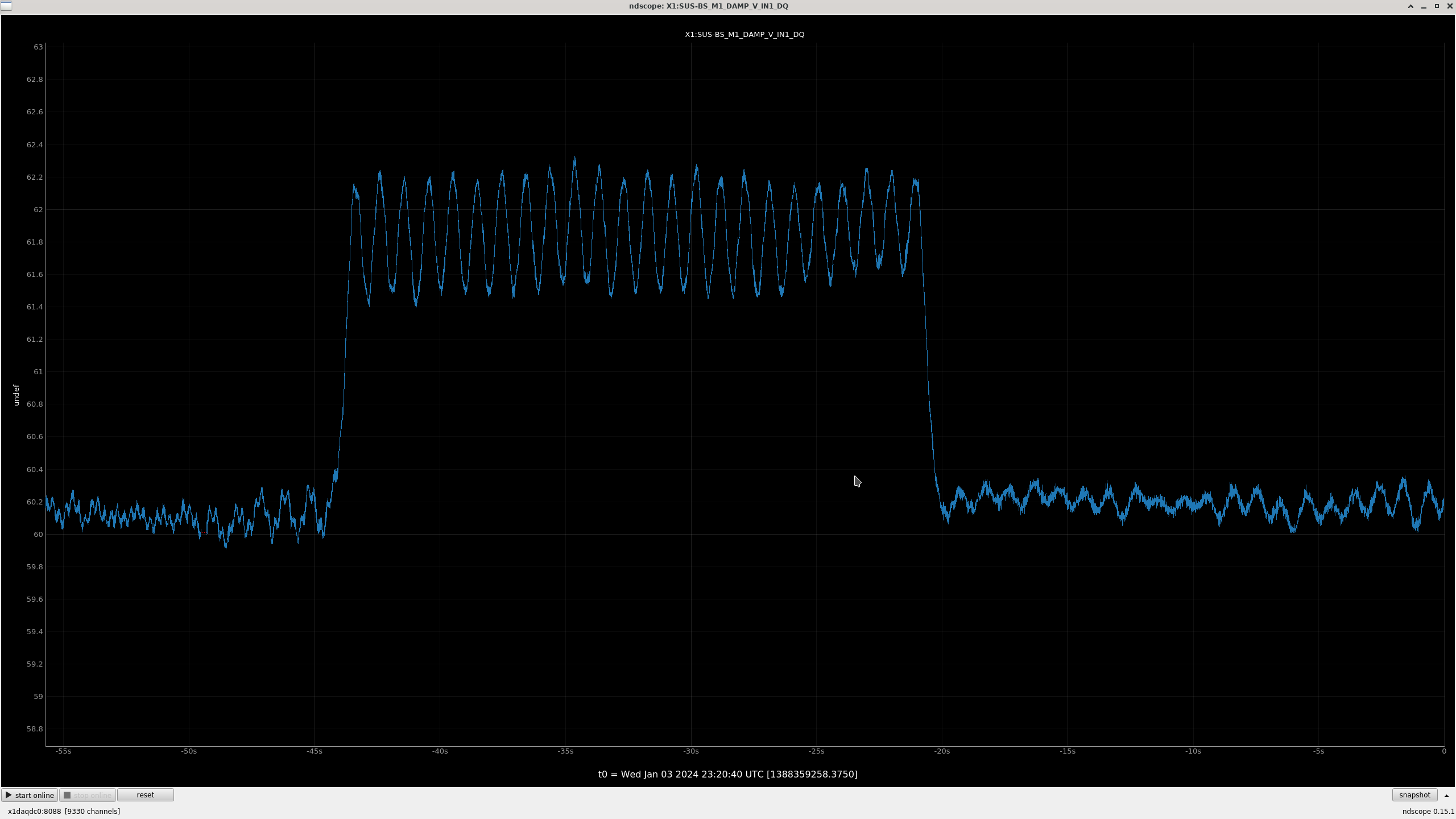
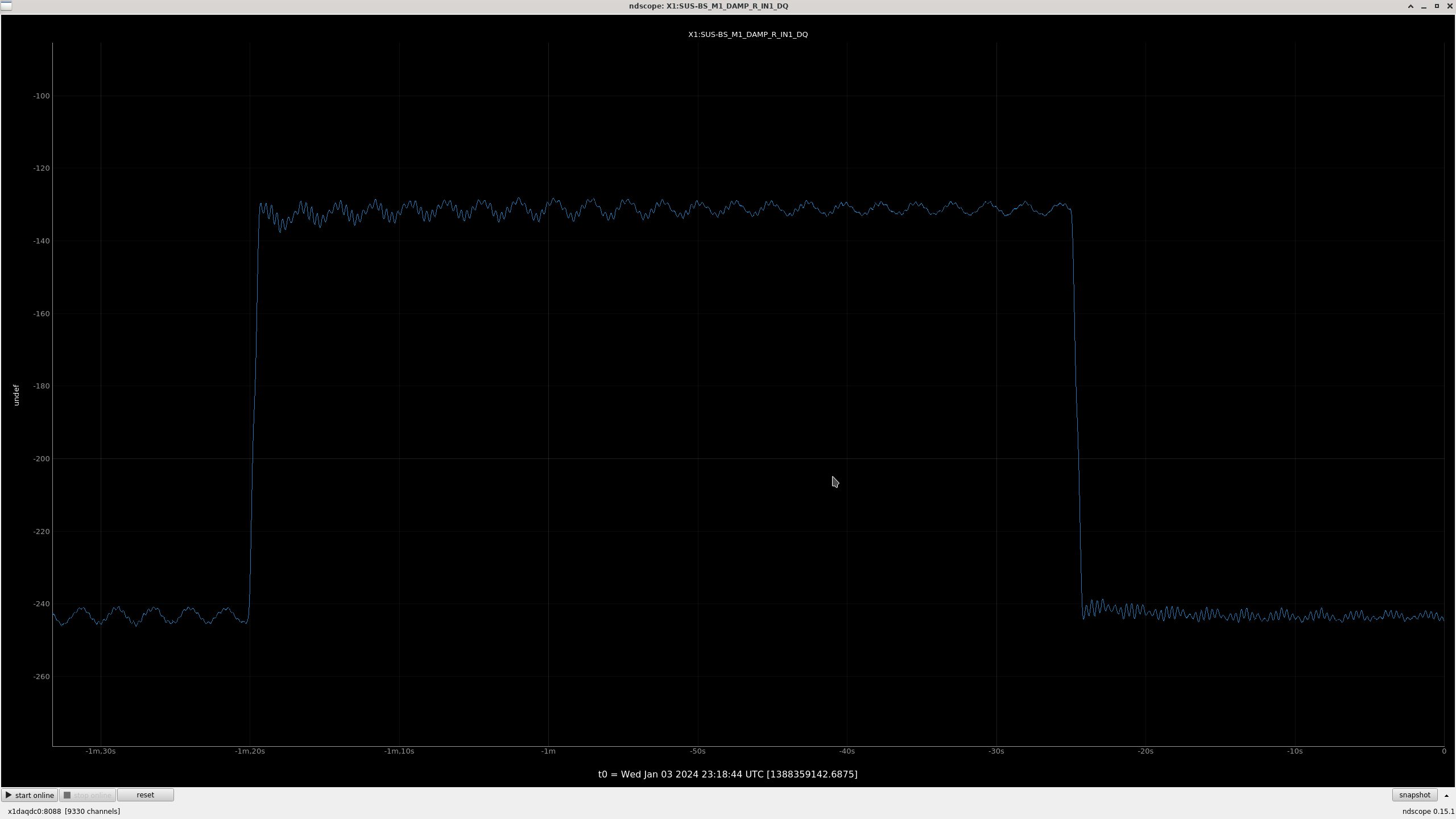
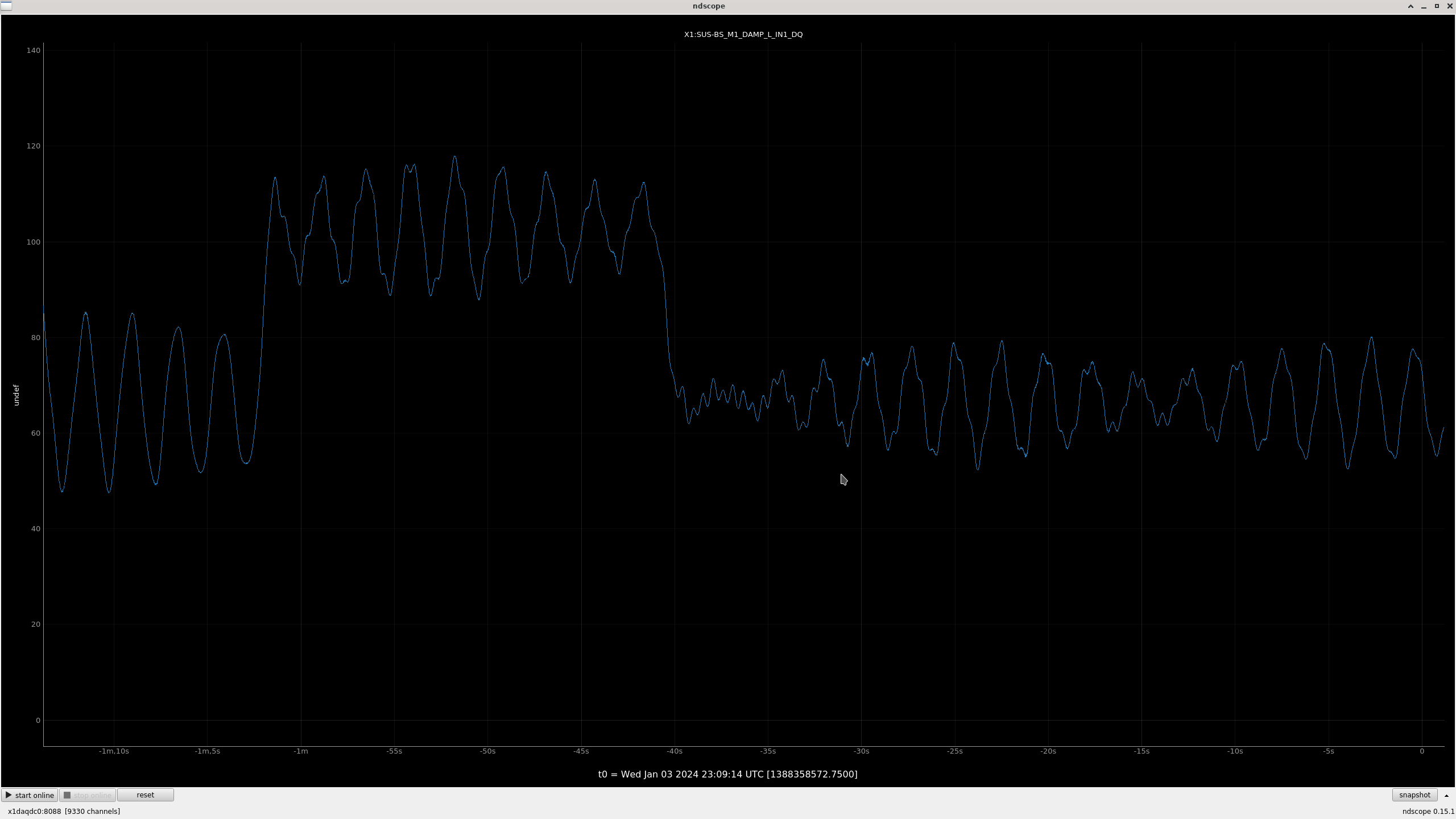
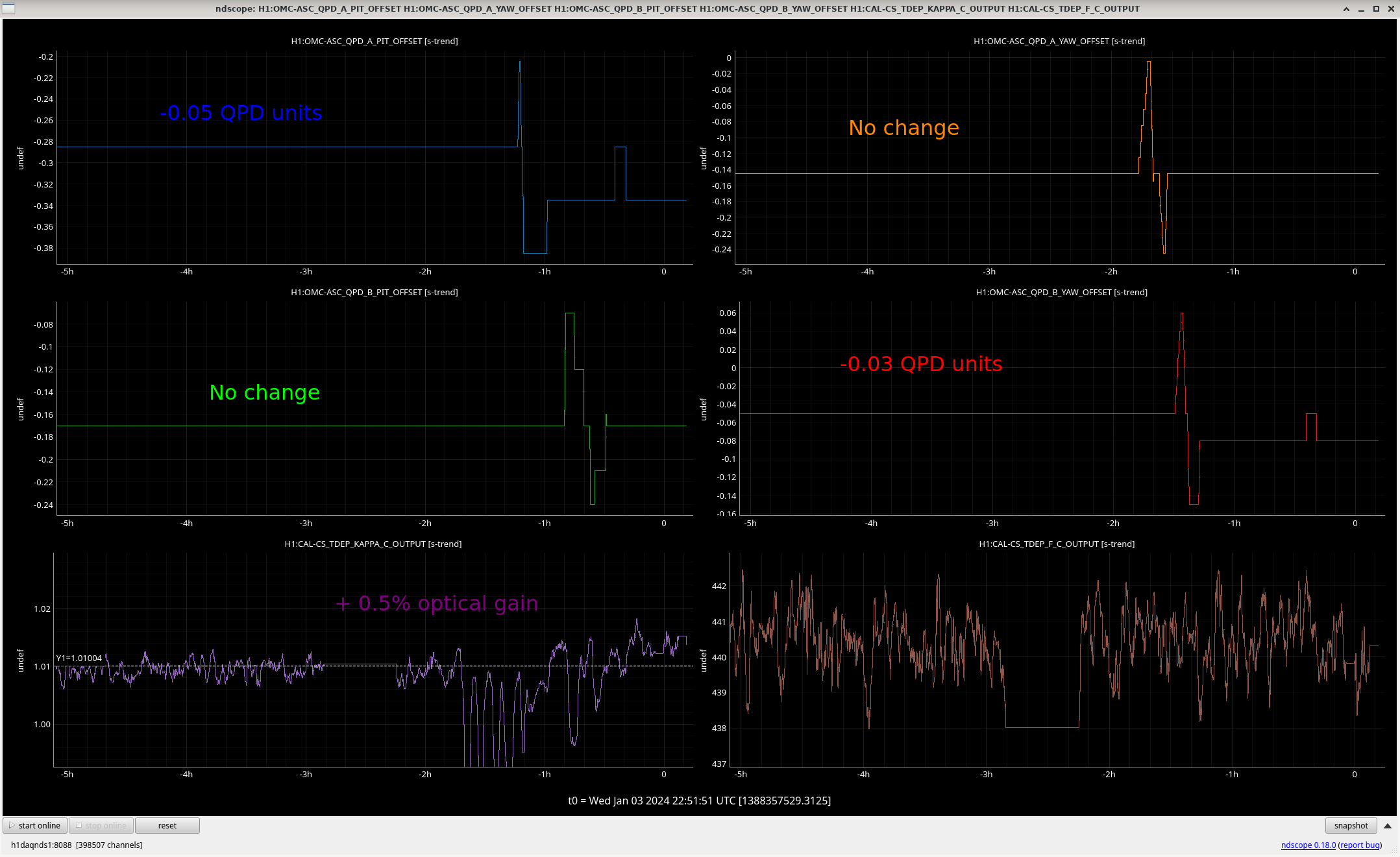
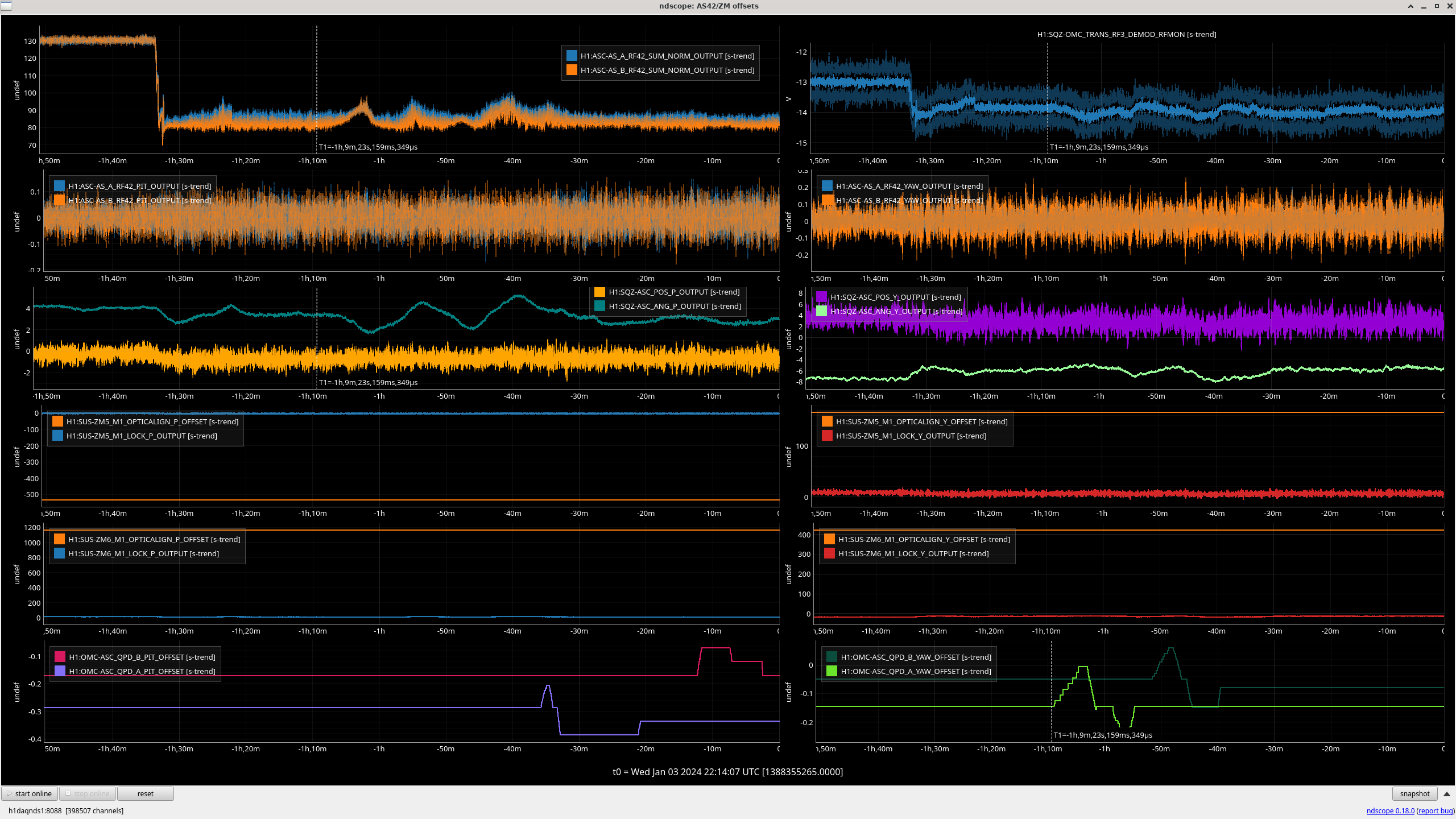
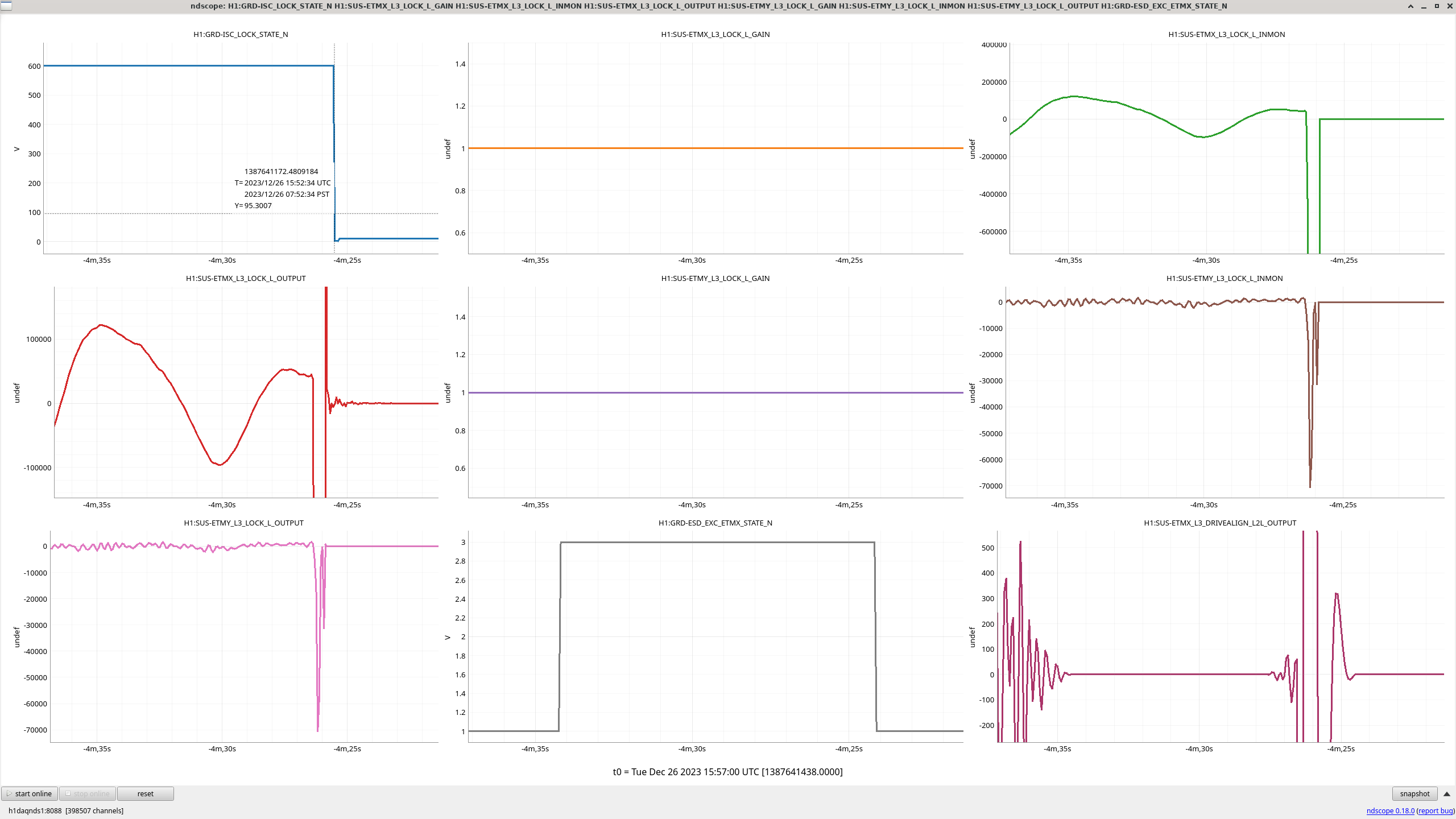
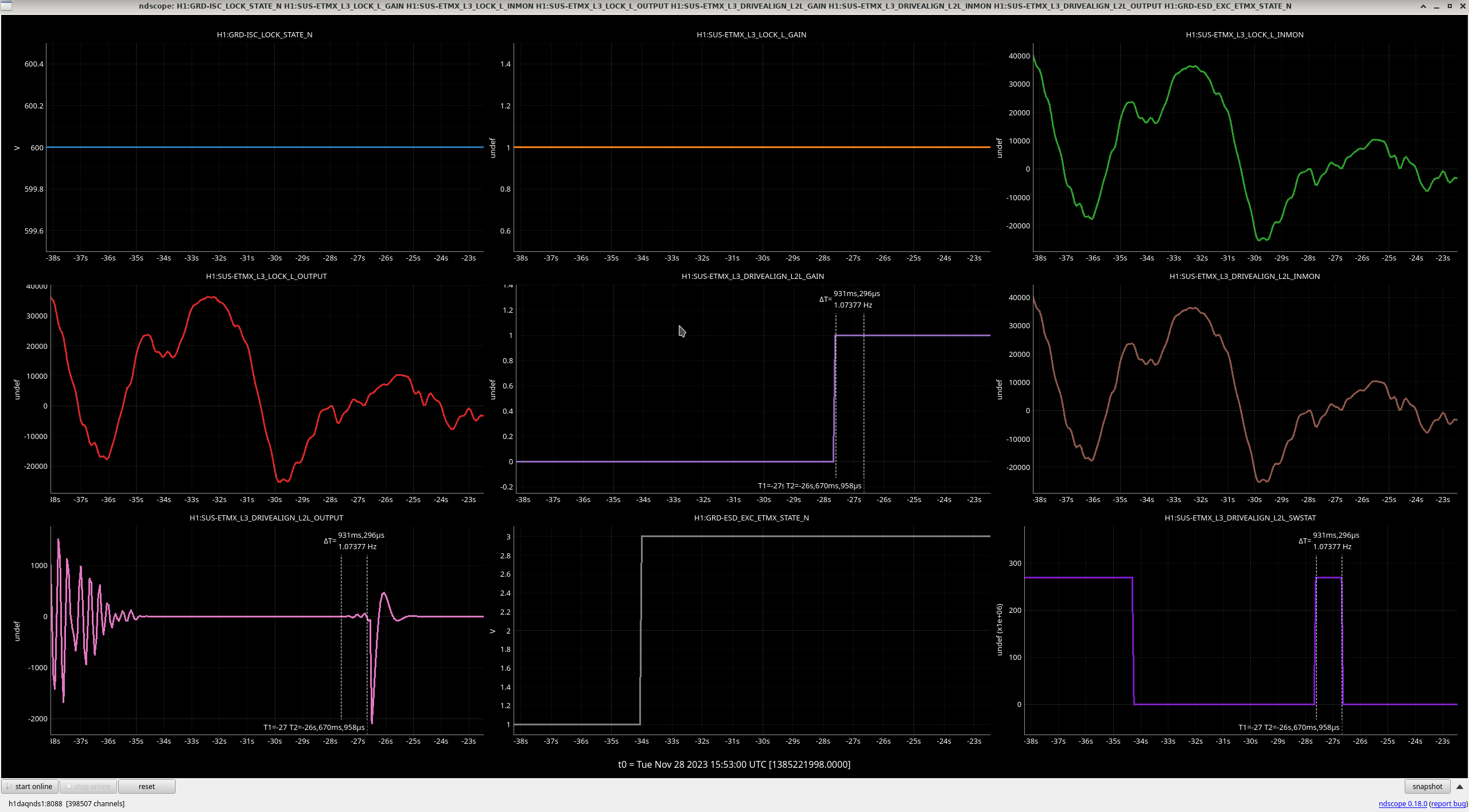
All "crude push around offsets" in the test bank yielded positive drives in the damp channels. These are the ndscope screenshots. Different offsets were needed to make the offset change more apparent in the motion (such as with L). A minimum of 1,000 was arbitrarily chosen and was usually enough.
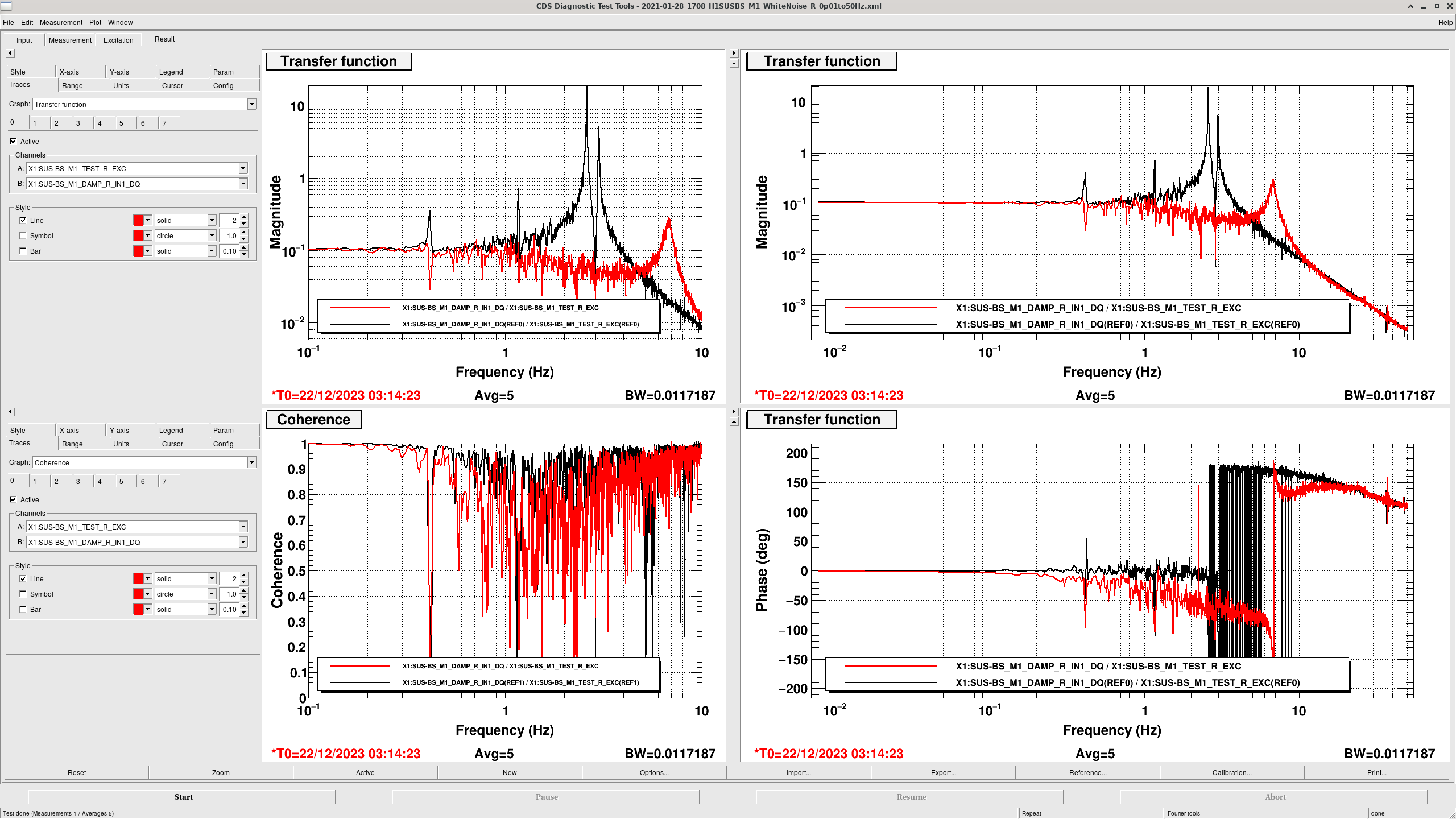
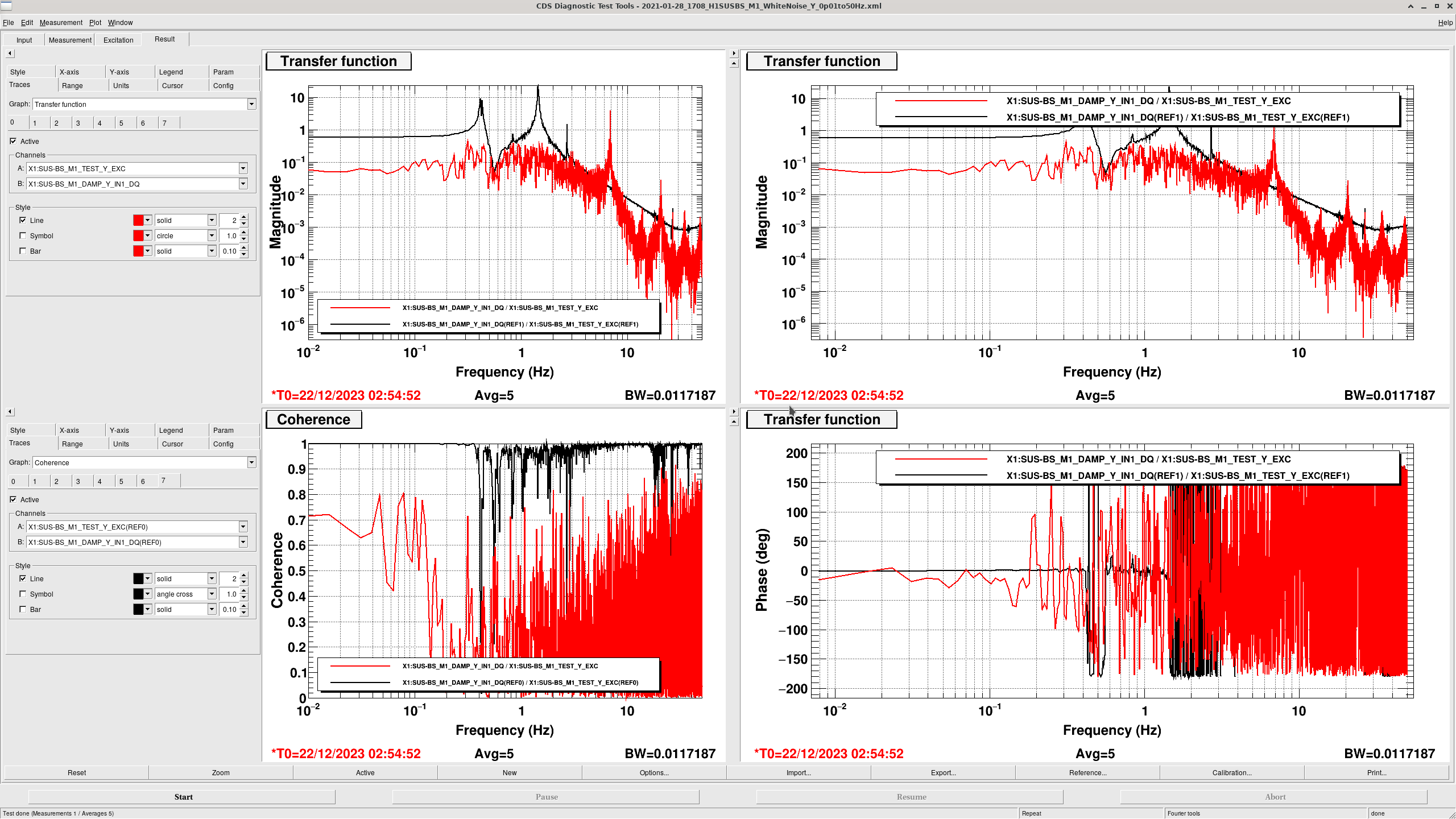
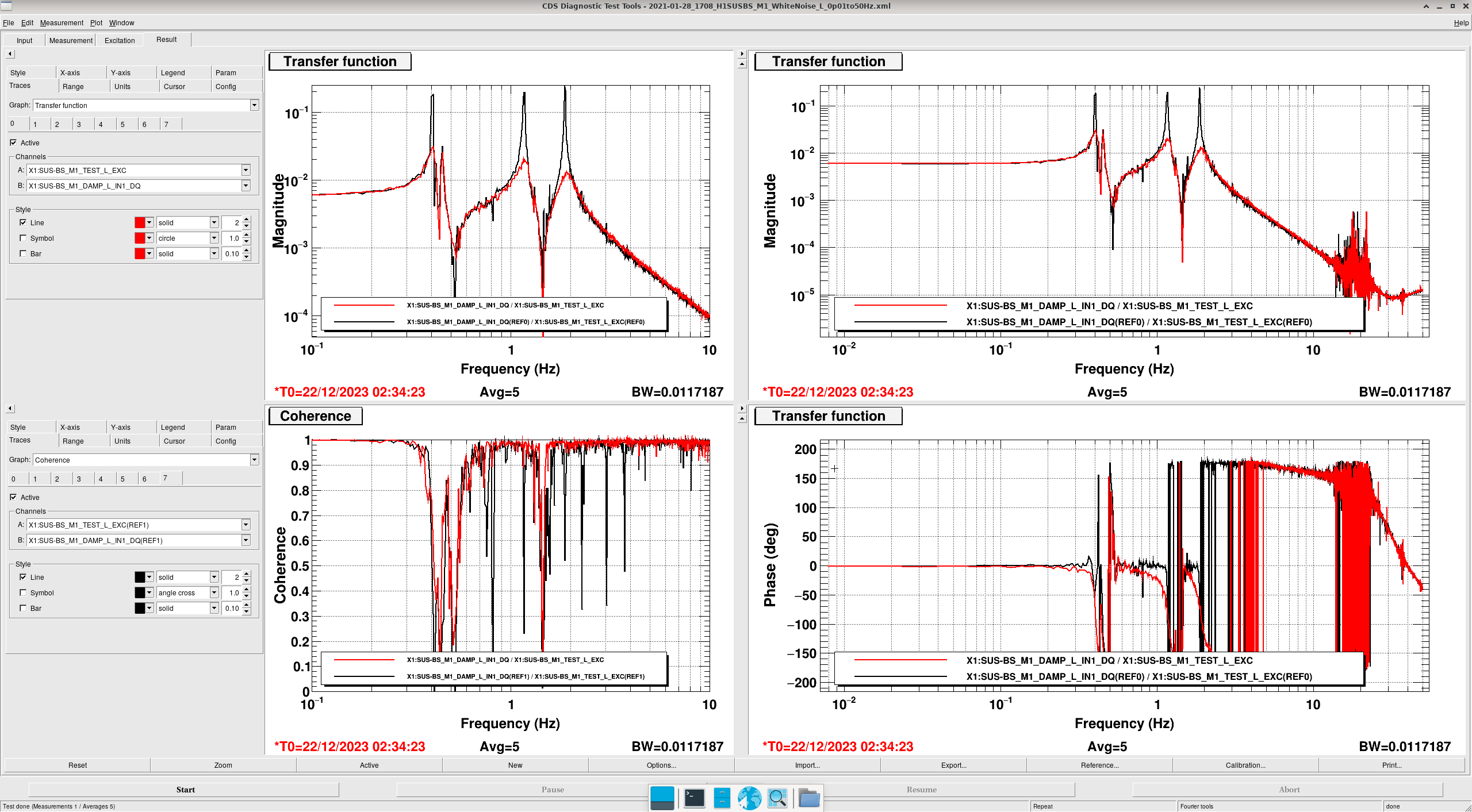
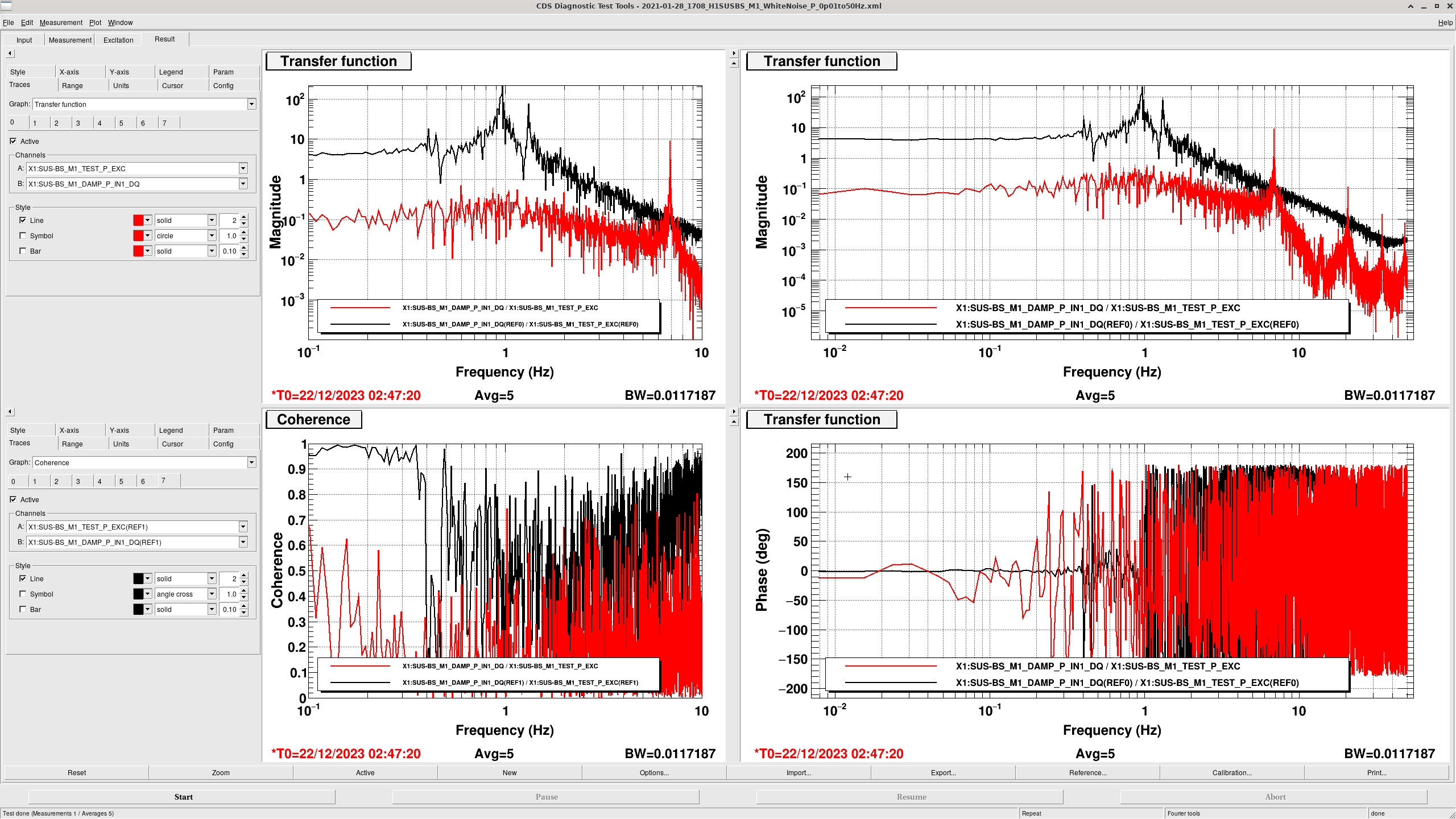
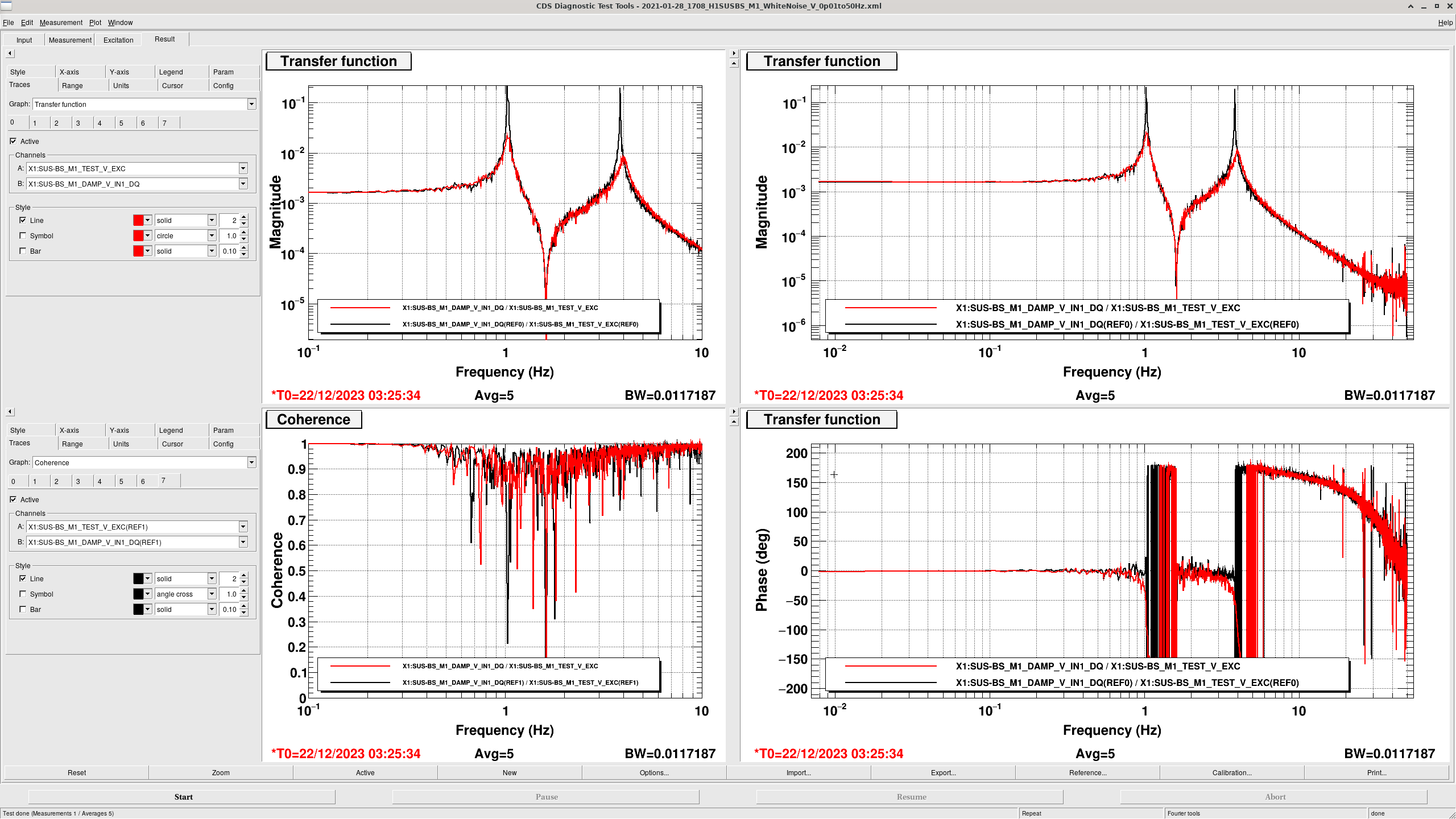
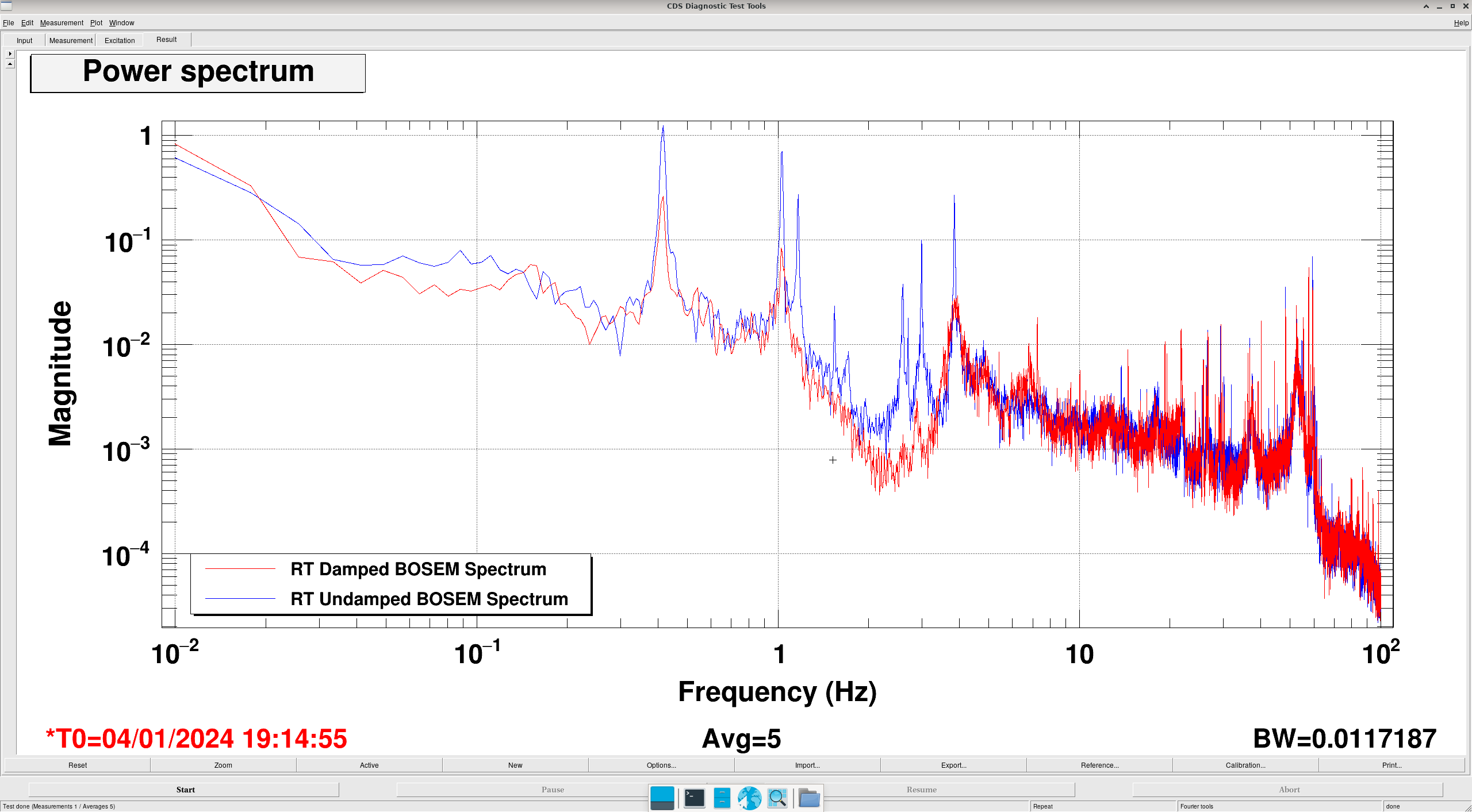
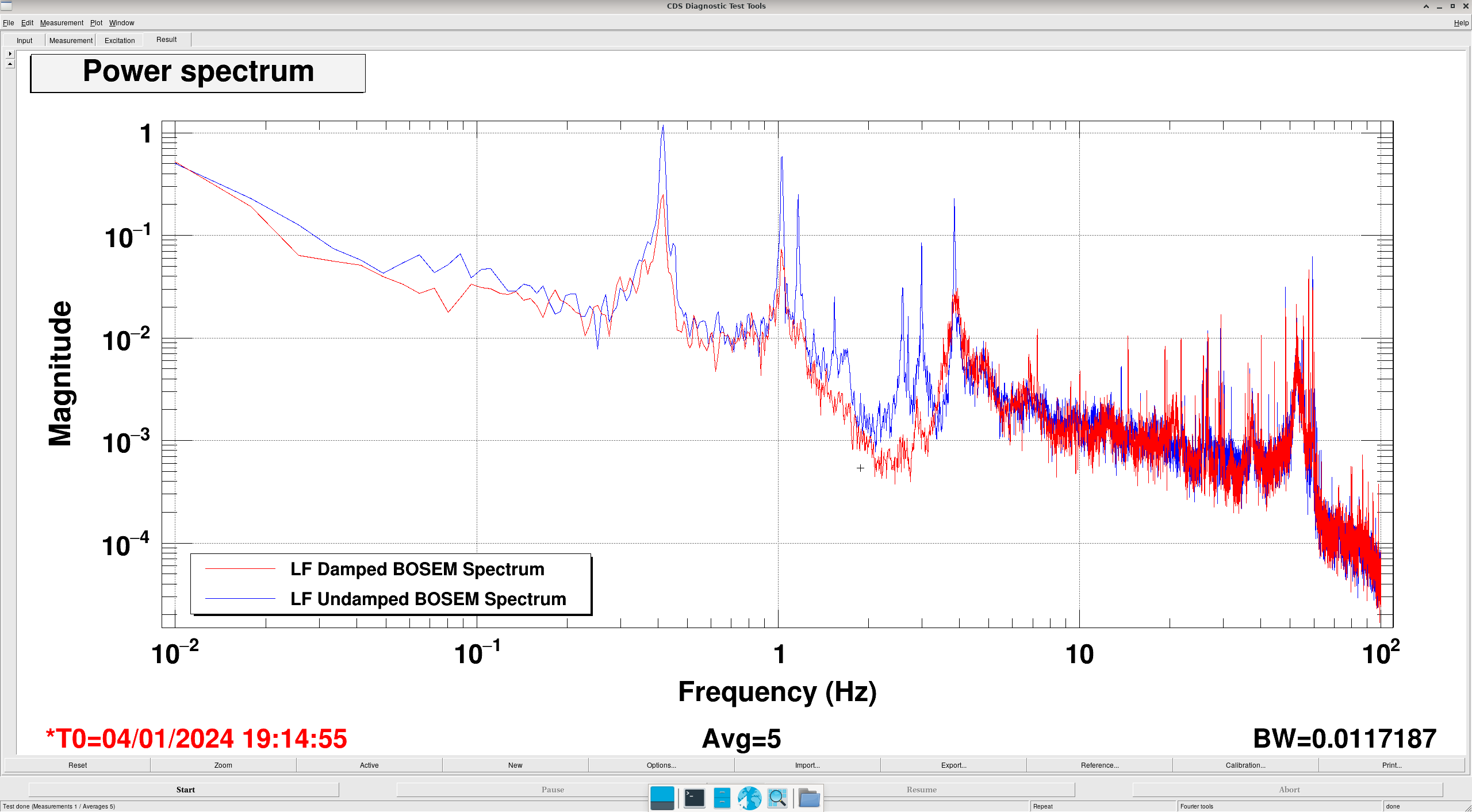
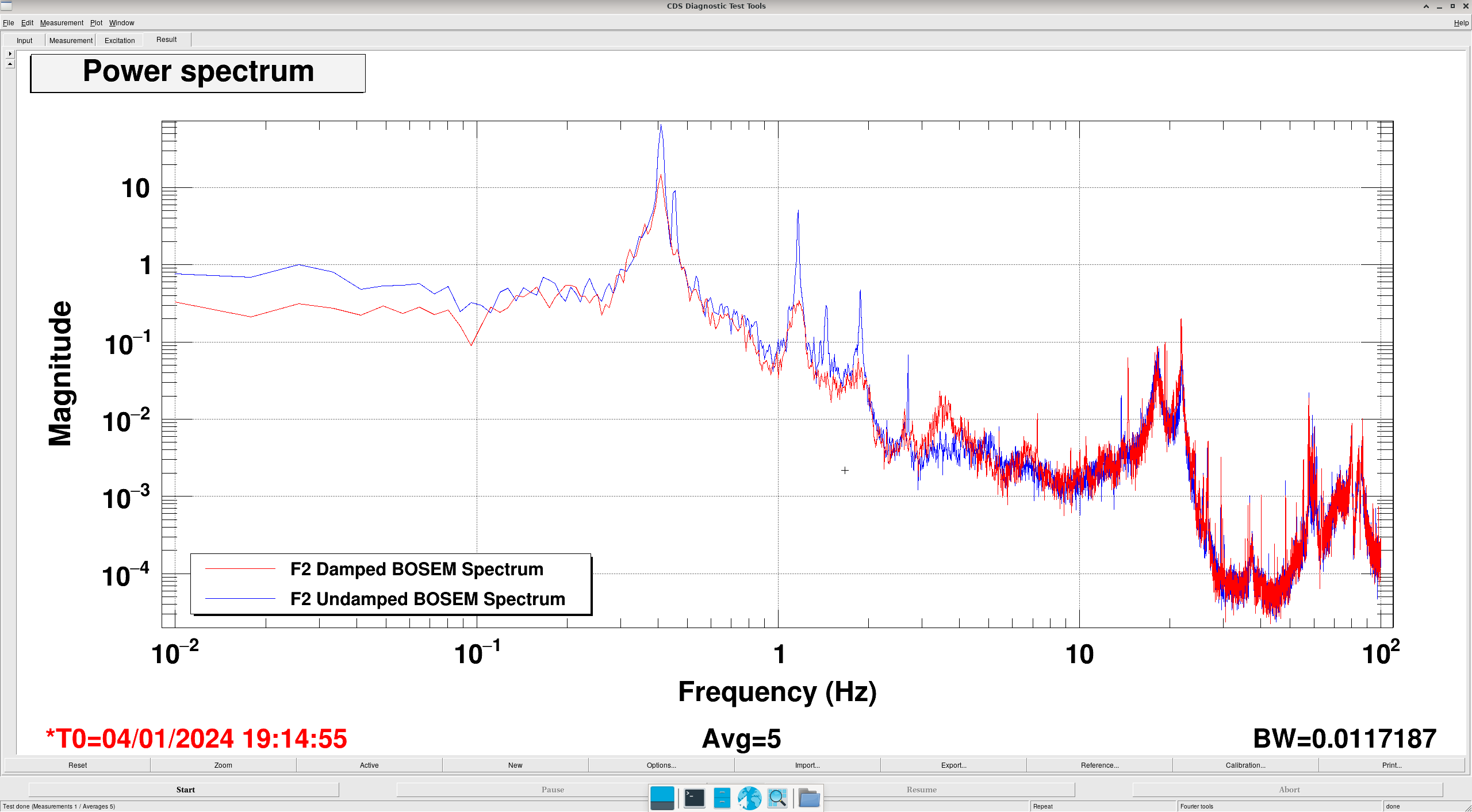
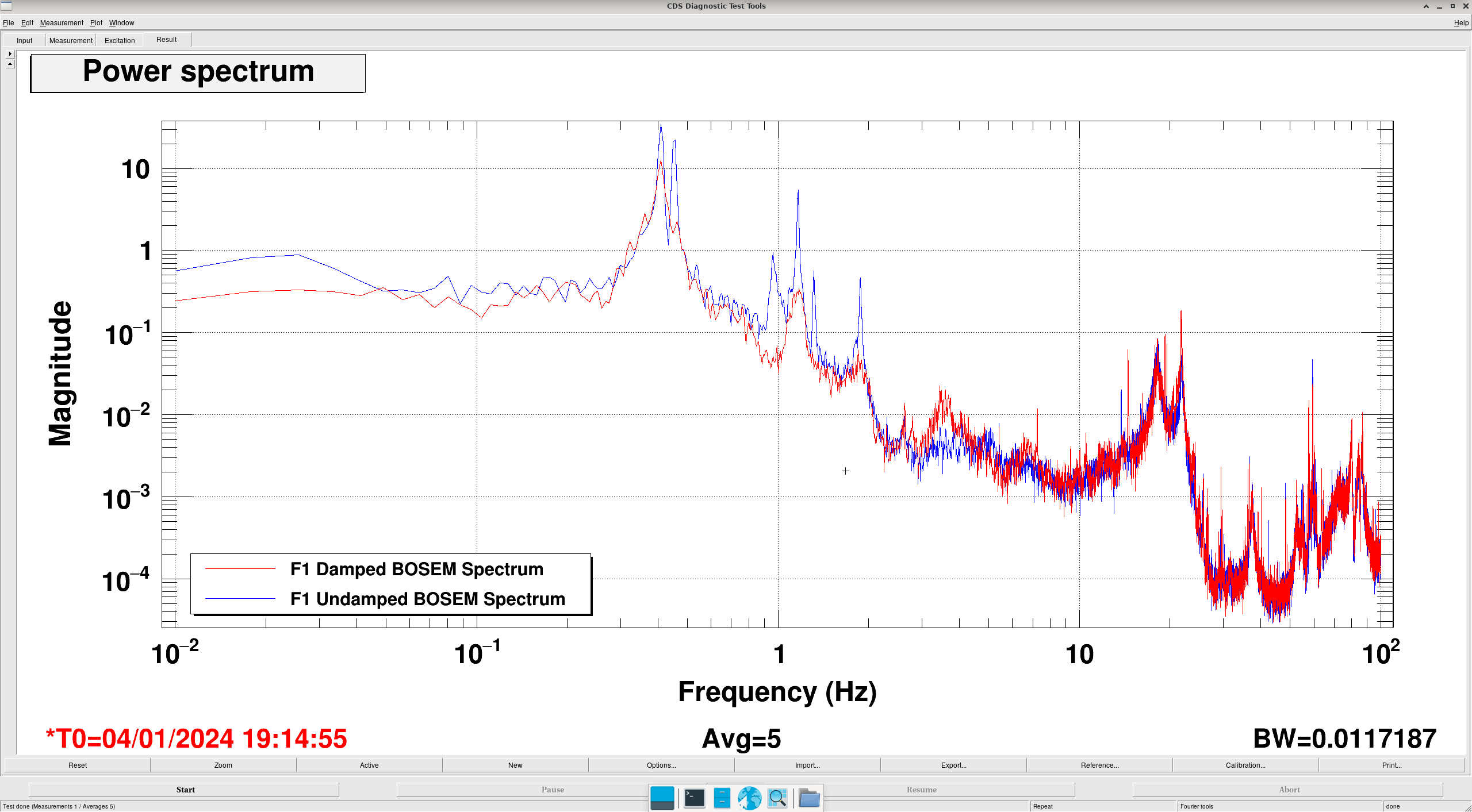
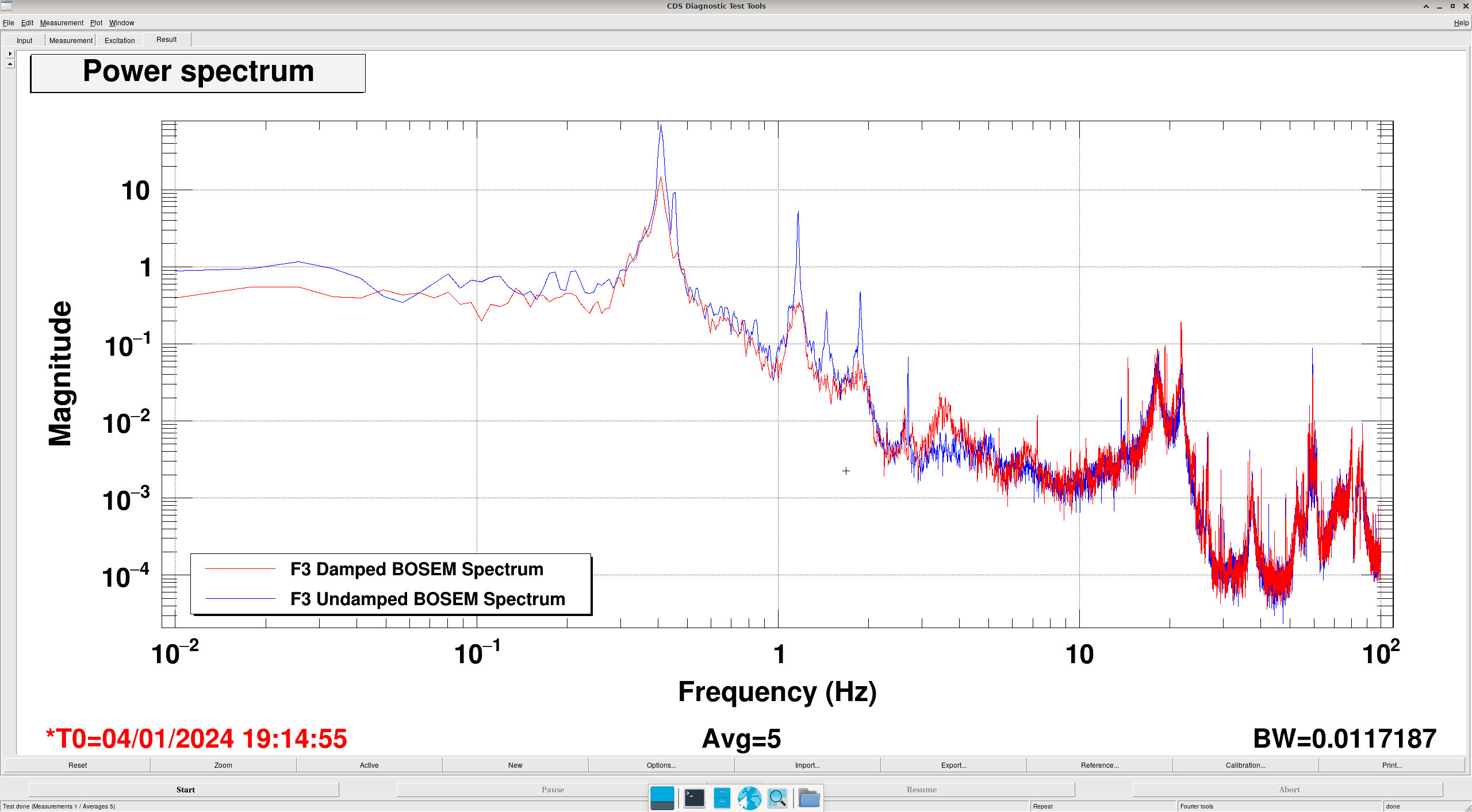
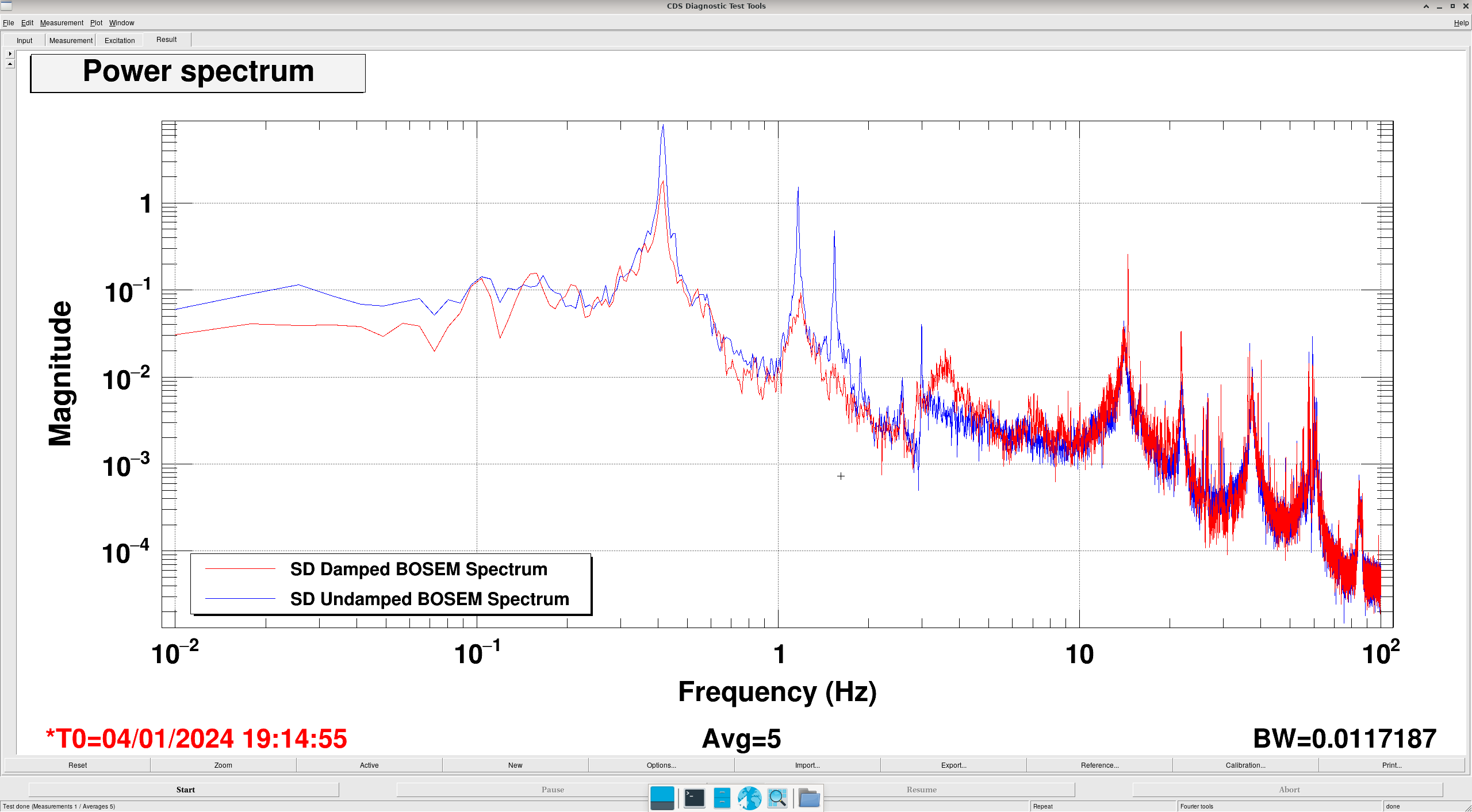
Transfer Functions: where it gets interesting... (DTT Screenshots)
In these DTTs, each reference (black) are the transfer functions without the damping, while the red traces are with the damping.
All "translation" degrees of freedom (L, V, T) showed correct damping, peak location and resonance
All "rotation" degrees of freedom (P, R, Y) showed completely incorrect damping, usually showing shifted peaks to the right (higher freq).
In trying to figure out why this is, we asked:
- Could it be any culprit OSEMs? If so, then the damping would not have shown as cleanly for L, which uses the same 3 OSEMs (F1, F2, F3) as P.
- Could it be the electronics? Fil and I checked the coil drivers and confirmed through exciting a sine wave that this is unlikely the case. This will be re-confirmed with the new transfer function findings.
- A small idea could indicate satellite box configurations could be misbehaving but again, the satellite boxes which serve certain OSEMs show both working and erroneous behavior.
- E.G. RT and LF show good matching peaks and damping in Vertical but not in Roll, despite both being hooked up to the same electronics throughout.
- Could it be the OSEM polarities? These were confirmed to be correct.
- Plus, if so, then we would see more differences with the OSEM offset scopes taken above perhaps?
- E.G. Coil output for SD with positive offset was still positive despite a -1G polarity correction, indicating that the math is right here. Using SD as an example because it's only used in T.
- Could it be that multiple polarities are wrong at the same time in such a was as to distort the results in this Translation vs. Rotation way?
- E.G. LF and RT are set with opposing polarities so the output gains have 1G and -1G respectively. Since V works, but not Roll, I think that this rules out polarity issues?
- Will reconfirm polarities time permitting.
- Could it be the model? Some BP filters? I do not know. There have been, as said, a whole host of details left out leading into this transfer function reading, so a thorough troubleshooting, re-testing would need to happen to confirm - the only untouched things are:
- The DTT Template used
- The BS Model provided by Jeff and Oli in alog 74142.
- Confirmed that the matrices in EUL2OSEM are set correctly as far as sign notations and OSEM to DoF combos. Sums are net 0 for rotations and are net positive/negative for translations (which seems intuitive).
(In)conclusion:
It seems that whenever the OSEMs push in the same direction, everything goes as planned, hence why all translation damping works. When we ask the OSEMs to push in opposing directions with respect to one another though, they seem to freak out. This seems to be the prime "discovery" of finally getting the transfer functions.
This is the "for now" update - will keep trying to find out why until expertise becomes available.