austin.jennings@LIGO.ORG - posted 00:00, Monday 18 December 2023 - last comment - 14:39, Tuesday 19 December 2023(74856)
Sunday Eve Shift Summary
TITLE: 12/18 Eve Shift: 00:00-08:00 UTC (16:00-00:00 PST), all times posted in UTC
STATE of H1: Observing at 159Mpc
INCOMING OPERATOR: Ryan C
SHIFT SUMMARY:
- Following the EQ lockloss from earlier, H1 is back to NLN @ 0:16/OBSERVE @ 0:36 (SQZ was having trouble tuning the sqz angle due to commissioner changes, but Naoki reverted these changes so we should have no further issue)
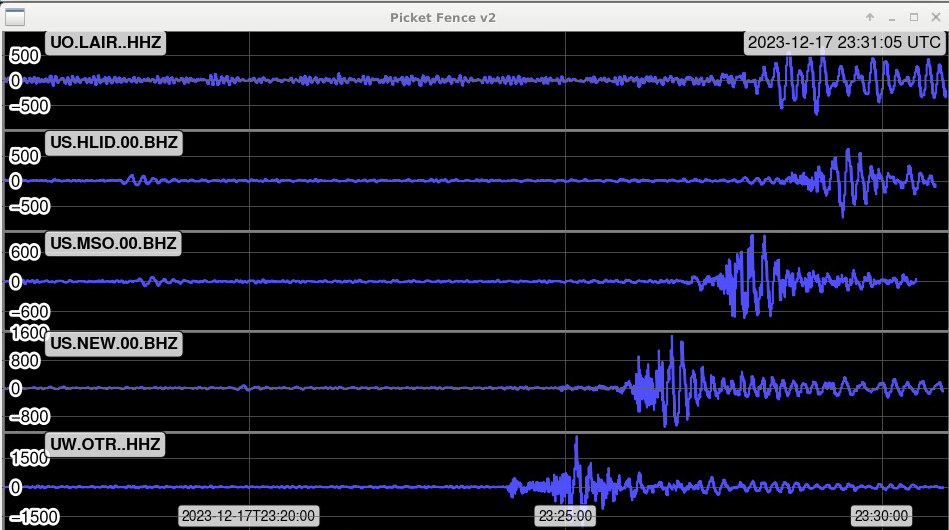
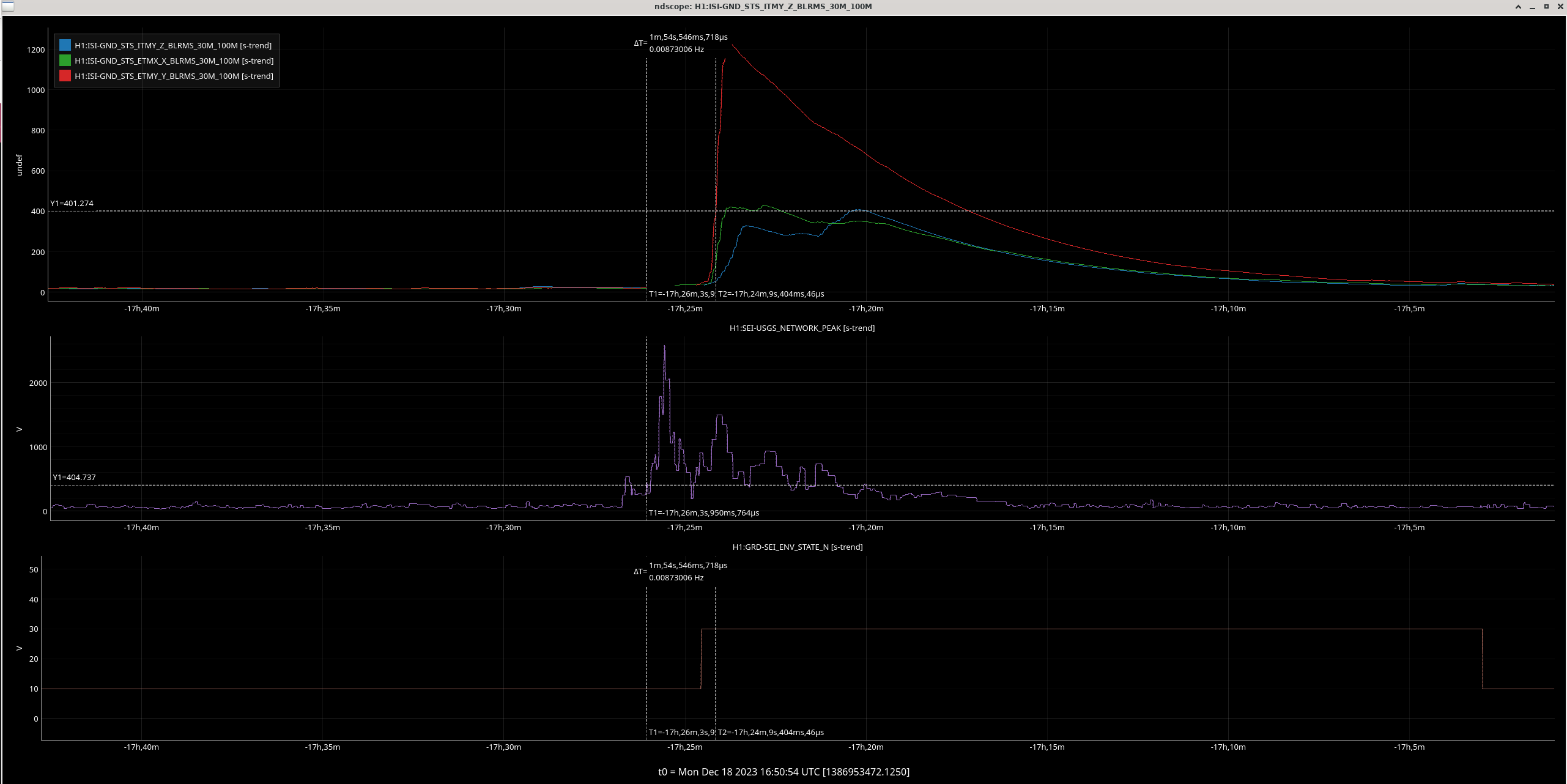
- 0:29 - inc 4.9 EQ from Mexico
- Back to CALM @ 0:50
- Other than the EQ it was an uneventful night, nothing else to report
LOG:
No log for this shift.

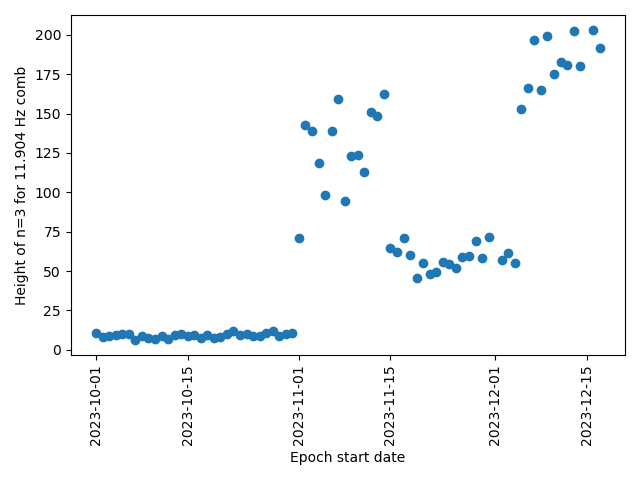


The trouble of SQZ happened after I changed the ADF servo flag in sqzparams to False. I wanted to see SQZ drift without ADF servo, but FC IR kept unlocking after this change so I reverted it. I am not sure why FC IR got unstable without ADF servo.
We found this was due to incorrect logic in SQZ_MANAGER. If the use_sqz_angle_adjust flag is false, the node never arrives at True and goes down to SQZ_READY_IFO, unlocked FC after 120s, thinking that it's failing to reach IR_LOCKED. Edit in svn 26967.