Louis, Sheila, Jenne
Today we tried a new DARM loop configuration. We are not implementing this for observing right now, we would need to retune feedforward and redo calibration before we could do that.
There is a new guardian state in ISC_LOCK, called NLN_ETMY. This state turns off feedforward and transitions DARM control to ETMY (L3,L2, L1), it can be used when we are in nominal low noise (but not necessarily from any states before LOWNOISE_ESD_ETMX). This was tested Tuesday morning and today, so it has worked twice.
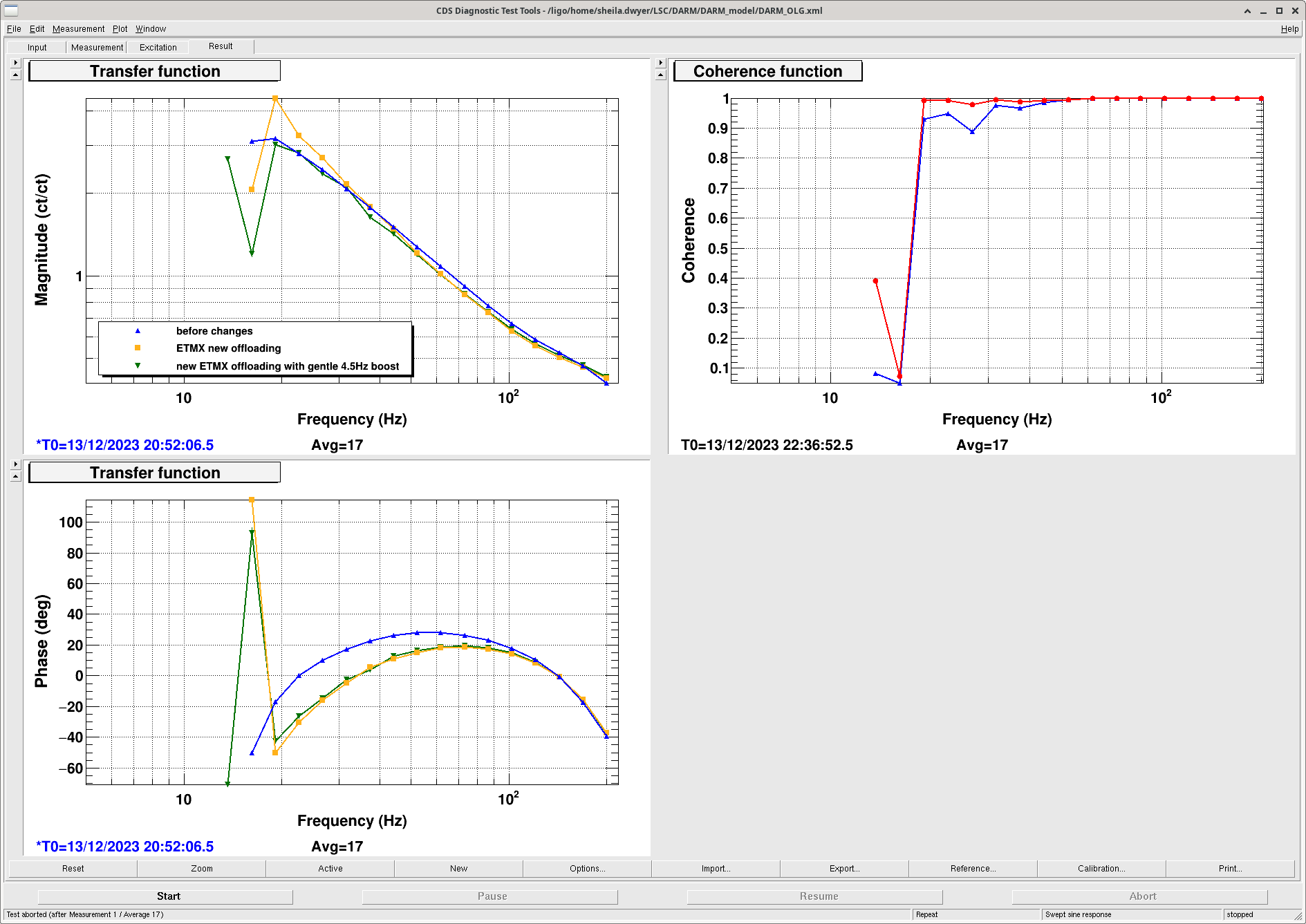
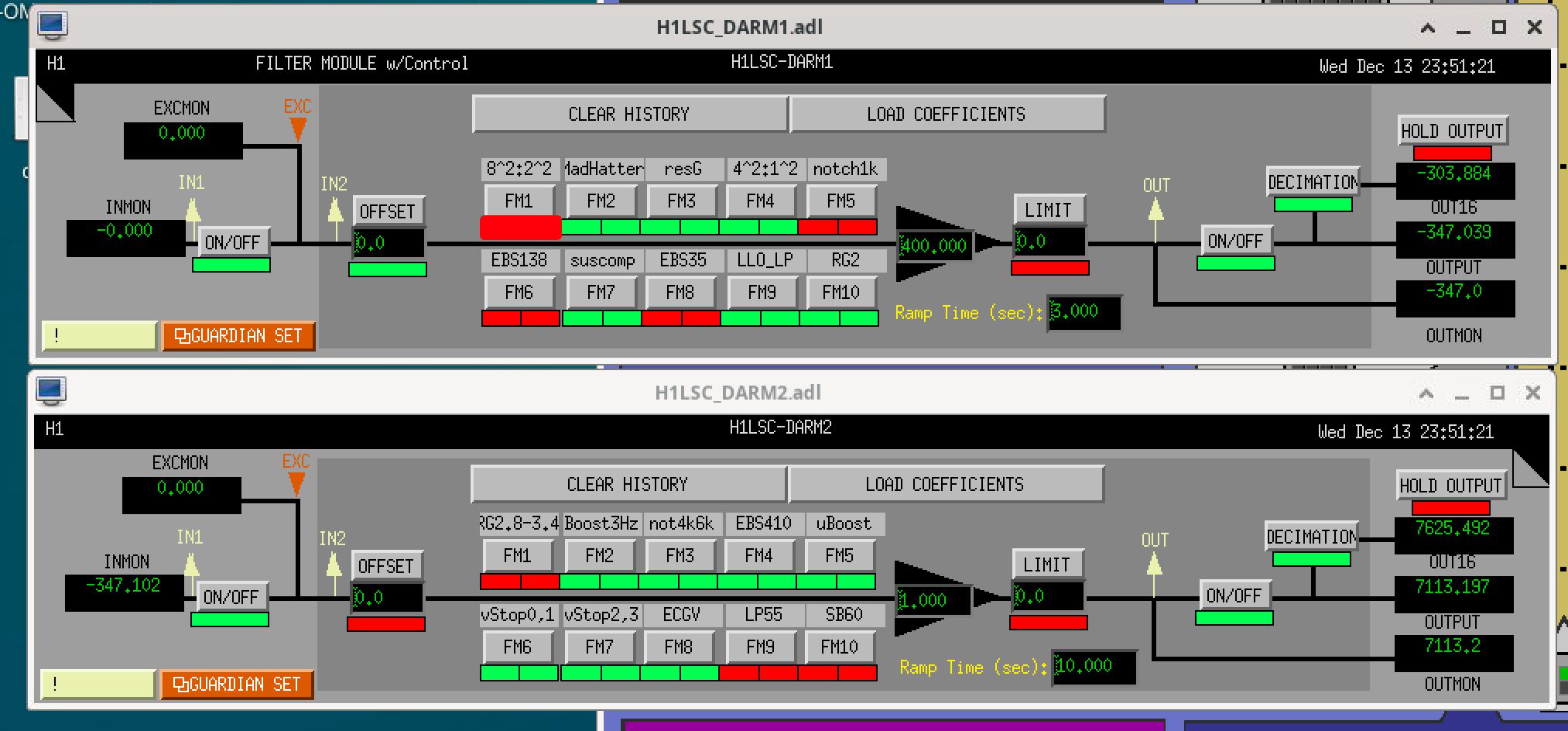
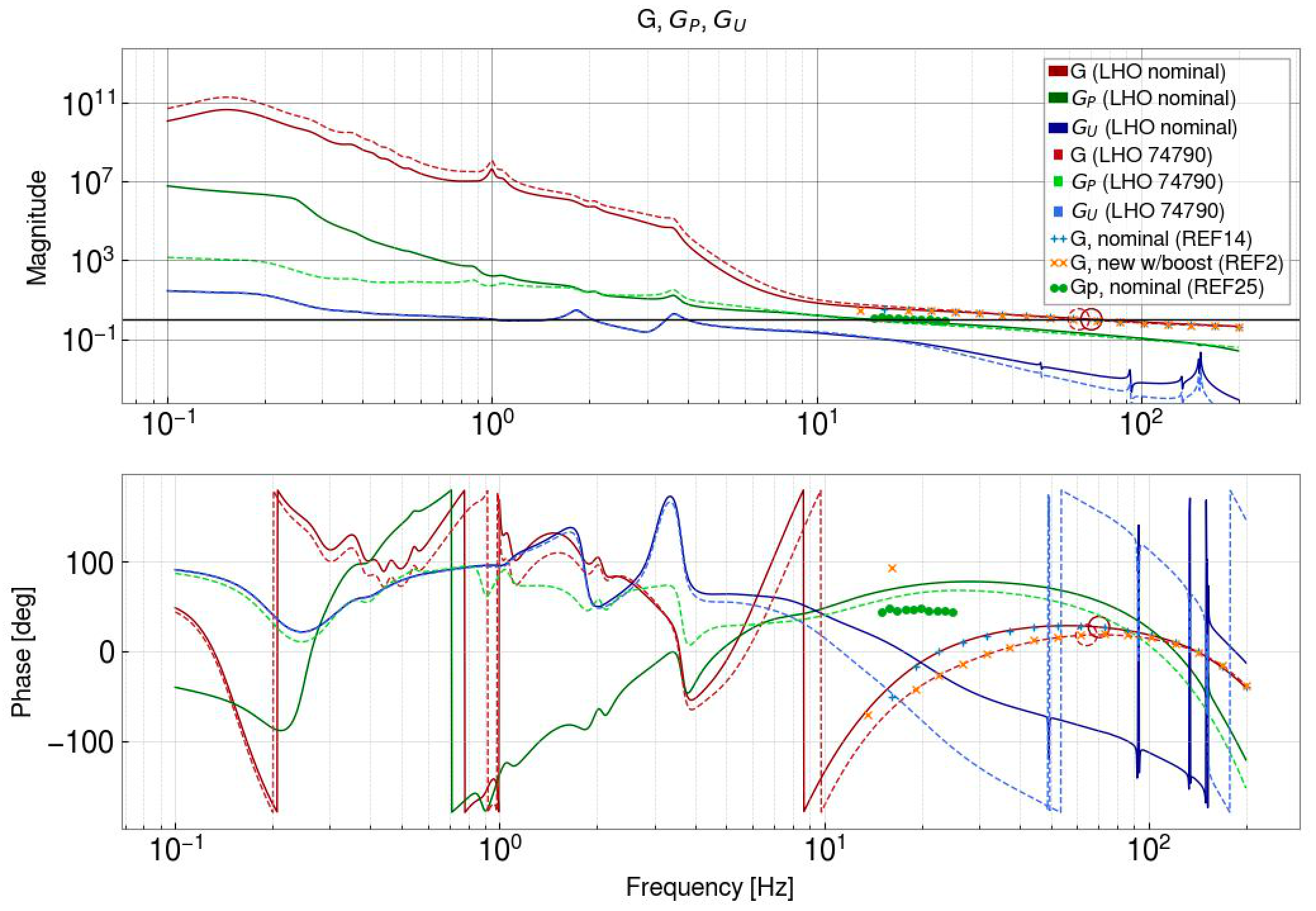
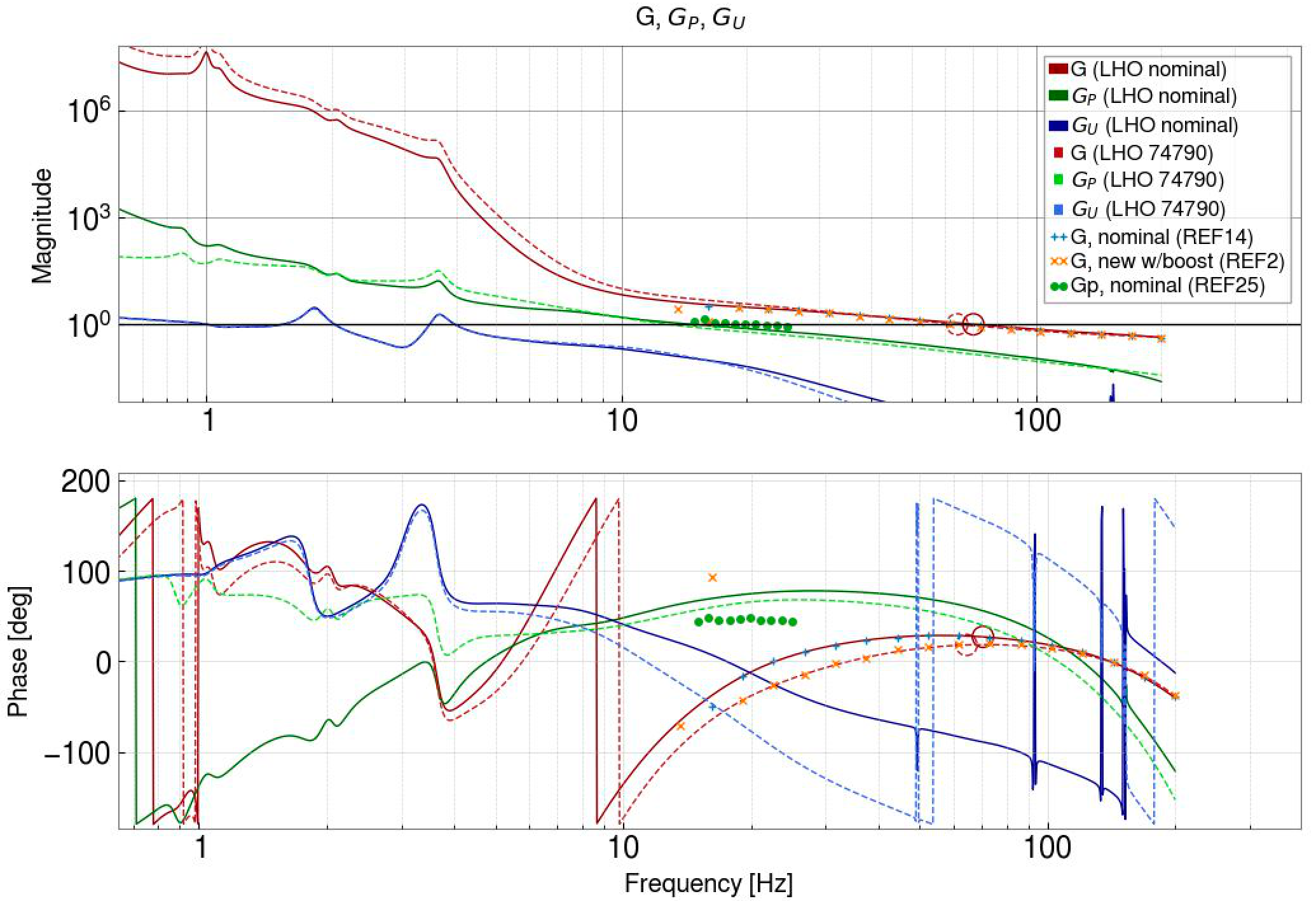
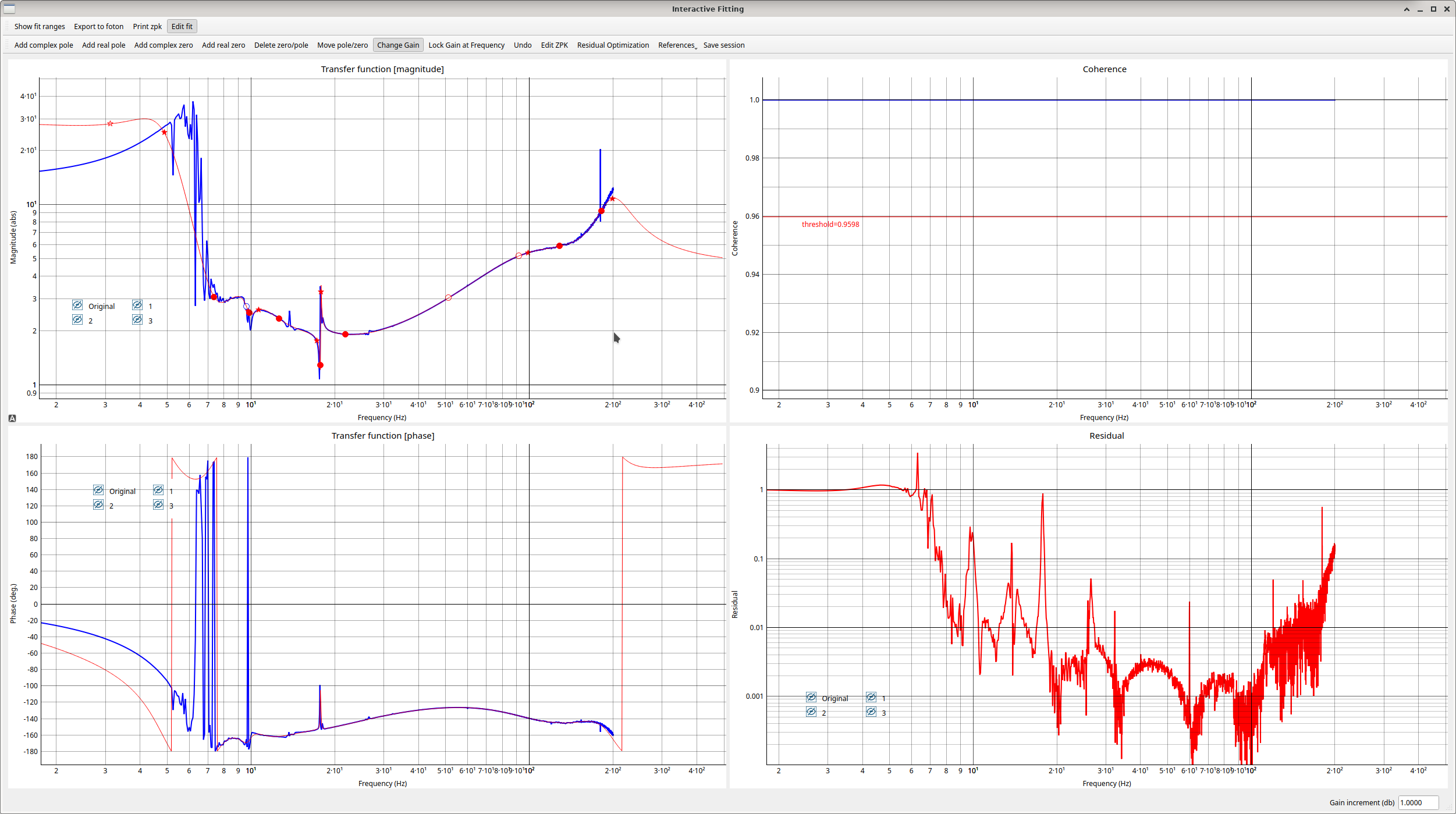
We set up a new configuration of filters for ETMX. Louis has been using pyDARM to model the DARM crossovers, and we will add more details about these new filters in a later alog. The first attached screenshot shows the configuration that we first transitioned to, without the new boost. This keeps the overall loop similar to our earlier configuration, the main differences are:
- we no longer have some low pass and high pass filters in L2 and L3 drivealign (these were left over from a DARM loop design of a very long time ago which wasn't implemented, but relied on a distributed control idea and we've struggled to get rid of them in the past.)
- The PUM plant inversion is also moved into L2 drivealign, and we have a crossover filter copied from LLO for the L2/L3 cross over. Now that we have removed the high pass and low pass and put our plant inversion in drivealign, it should be easier to make changes to this loop.
- The UIM filters are kept mostly the same, with the plant inversion from L2 copied to L1 to avoid making a change. We would like to change this so that we have more offloading to the UIM, but decided to make fewer changes at the same time today and come back to changing the UIM in the future (this should be easier to do now).
- Added a gentle 4.5Hz boost to the PUM designed by Gabriele, which reduces the drive to the ESD (which was our goal).
- removed a boost from the DARM filter bank. (Moving low frequency gain from the DARM filter bank to the PUM lock should reduce our ESD drive nonstationarity.)
Measurements:
- OLG: /ligo/home/sheila.dwyer/LSC/DARM/DARM_model/DARM_OLG.xml (ref 14 is previous configuration, ref 1 is the new configuration without the gentle pum boost, ref 2 is new configuration with the gentle pum boost) (1st screenshot)
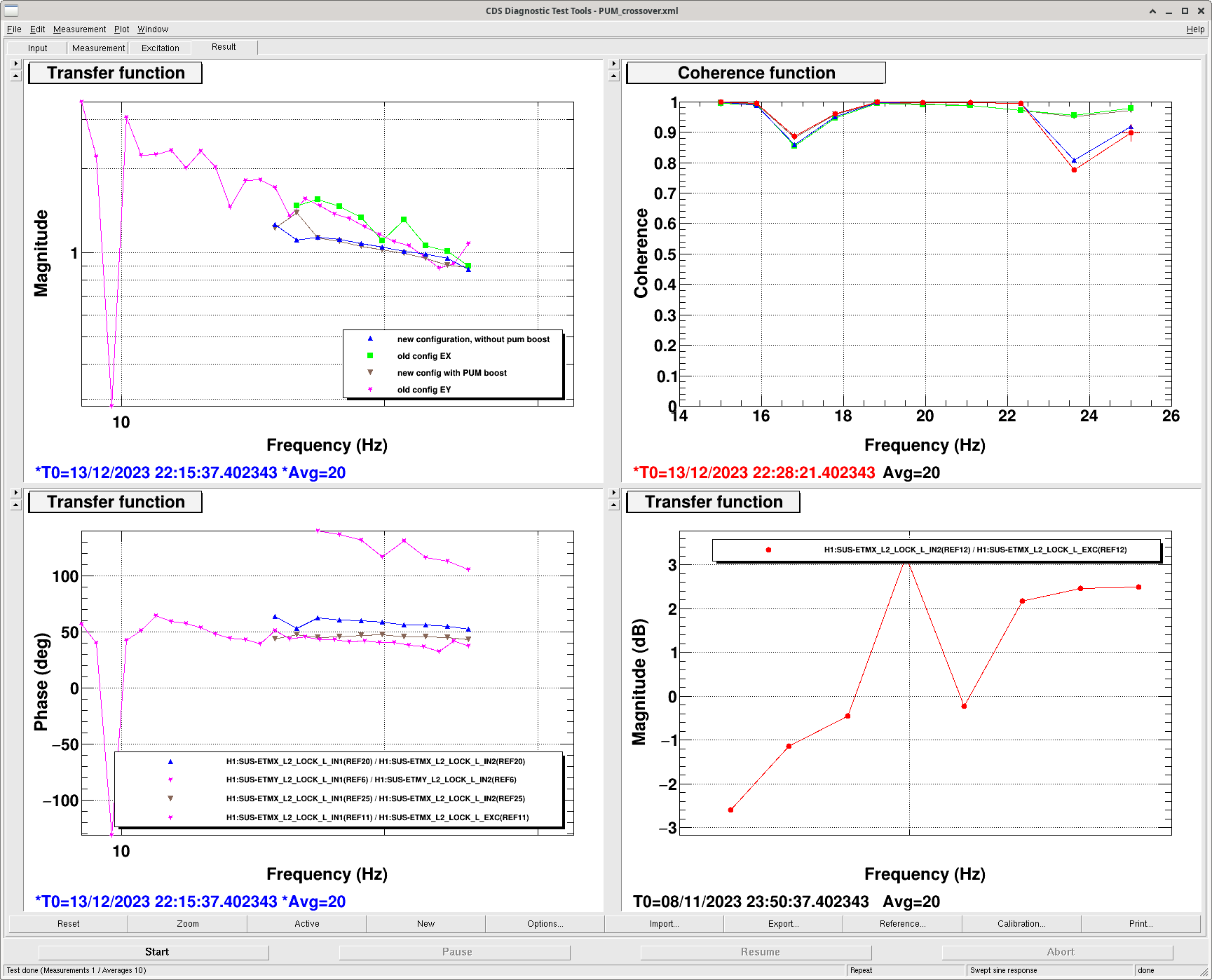
- PUM LOCK IN1/IN2: /opt/rtcds/userapps/trunk/lsc/h1/templates/DARM/PUM_crossover.xml (ref 20 new configuration without pum boost, ref 25 new configuation with pum boost).
- the UIM crossover template needs to be retuned with the filter changes, but we didn't have time for that today.
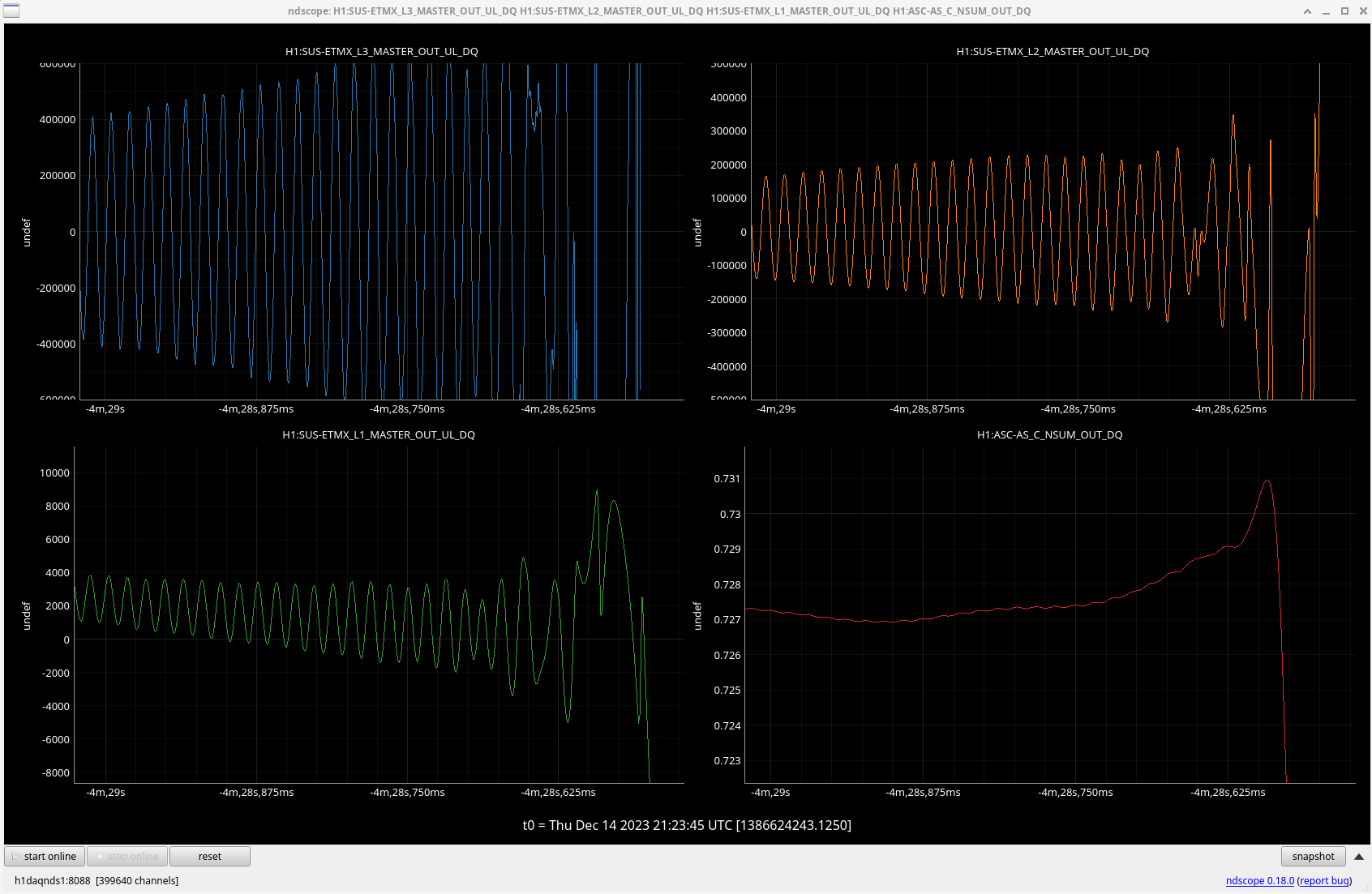
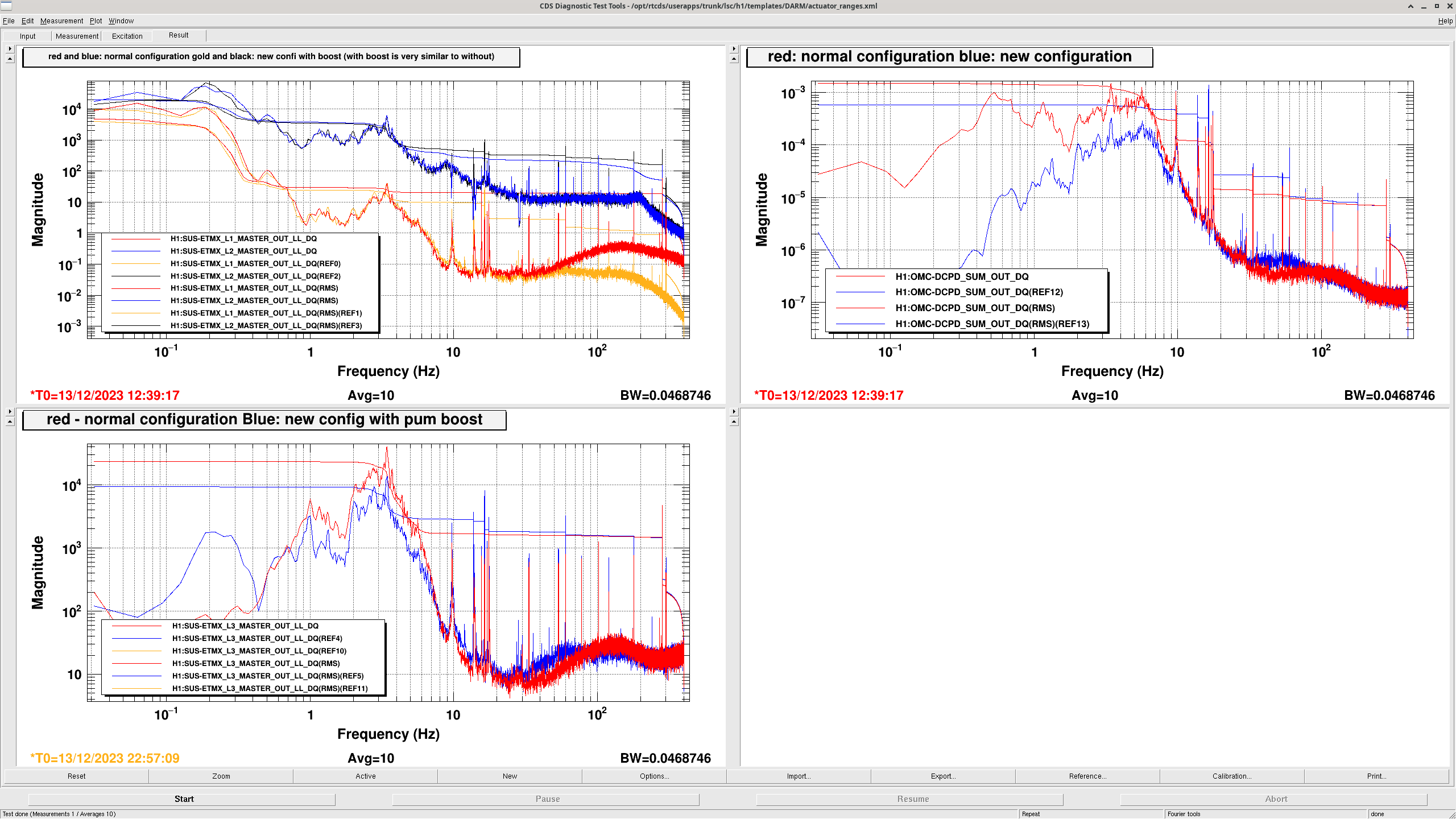
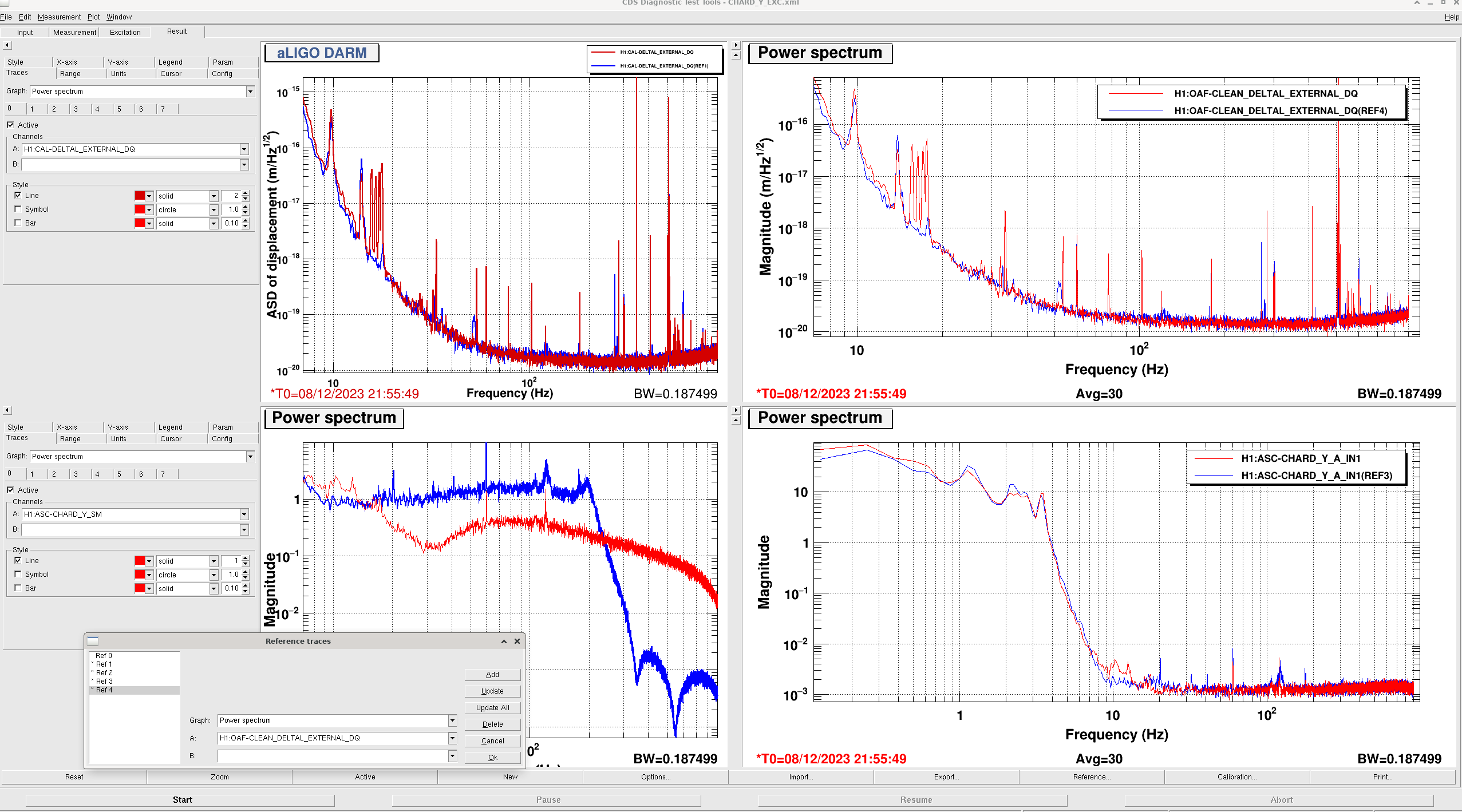
The last attachment shows spectra of the DAC counts for ETMX, and DCPD SUM. The new configuration with the boost on reduces the RMS counts on the ESD by a little more than a factor of 2 compared to the configuration we've been using (most of the improvement is from the additional boost). The new configuration also supresses DCPD sum more below 10Hz.
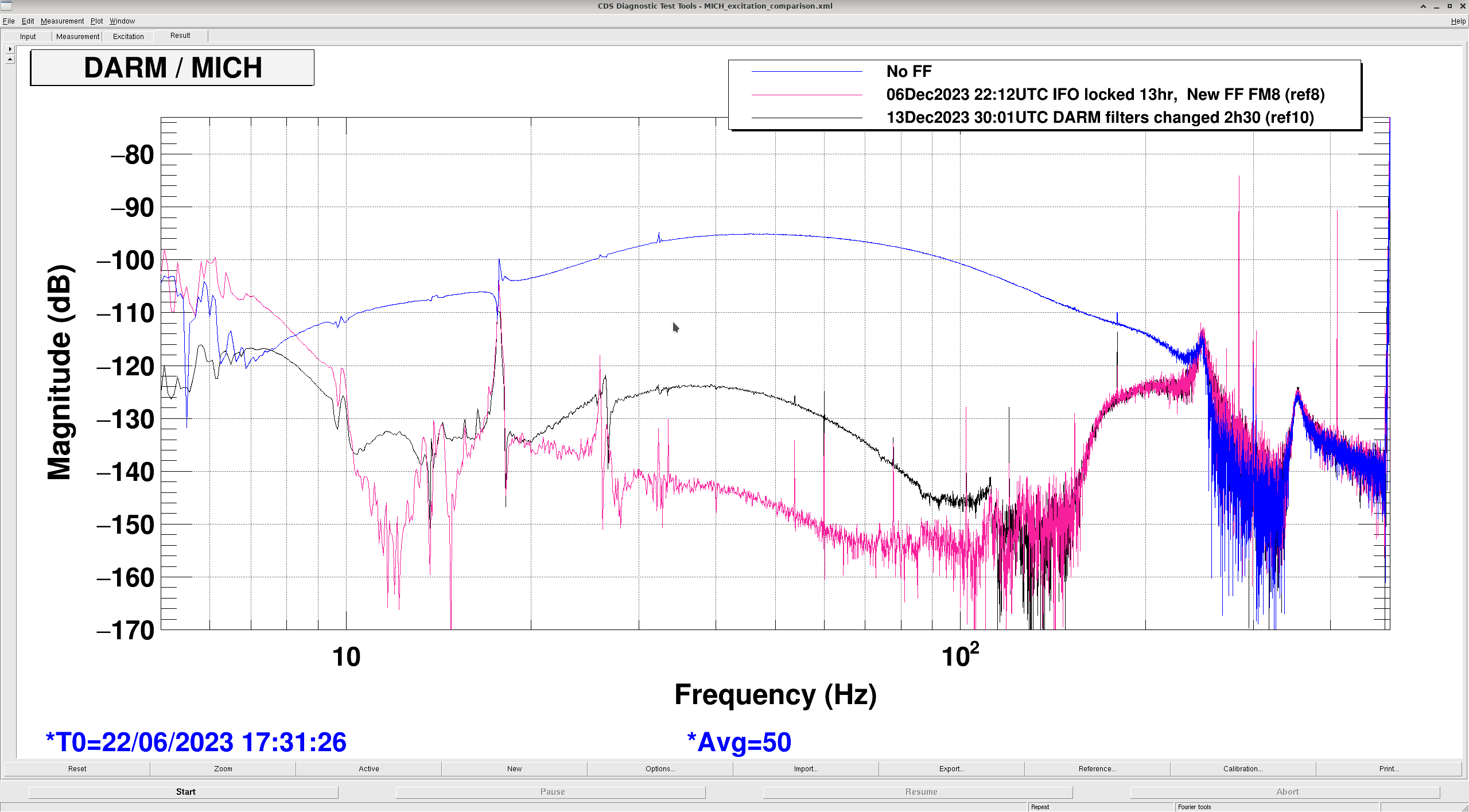
Camilla looked at the MICH FF with the new configuration and saw that it needs to be retuned, she took measurements that can be used to do that.
We lost lock as I was trying to semi-manually transition DARM control back to ETMY from this new configuration.