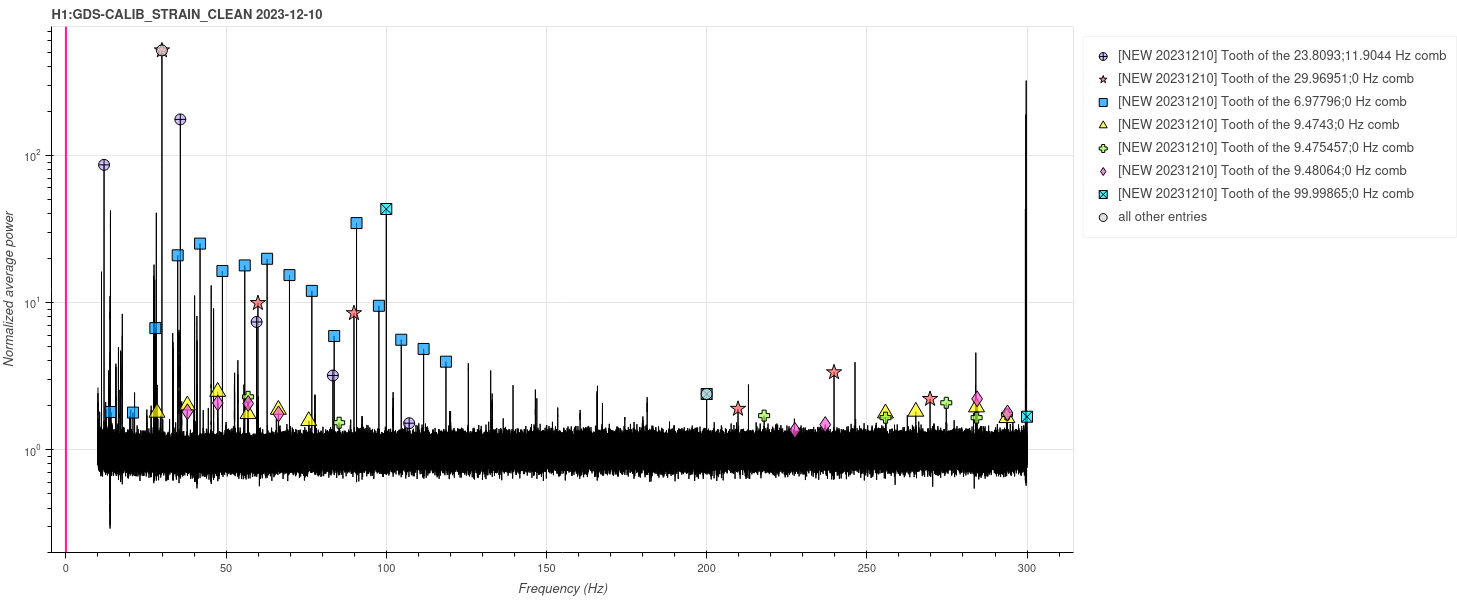
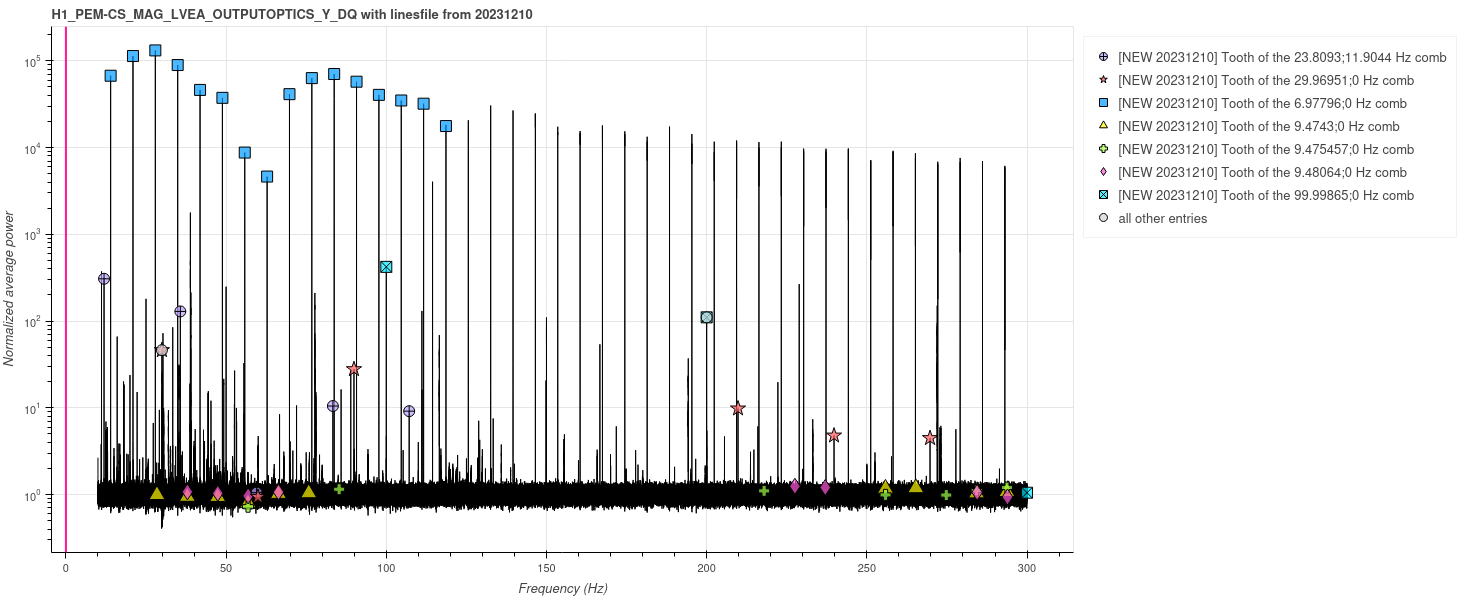
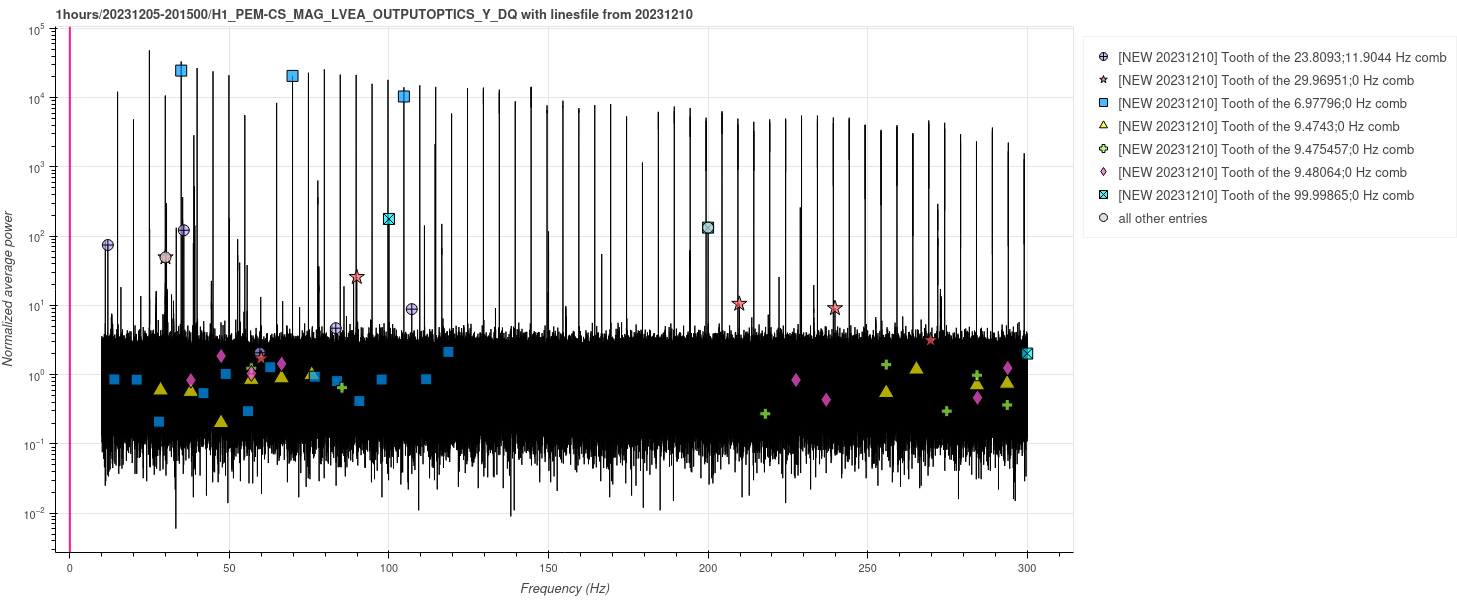
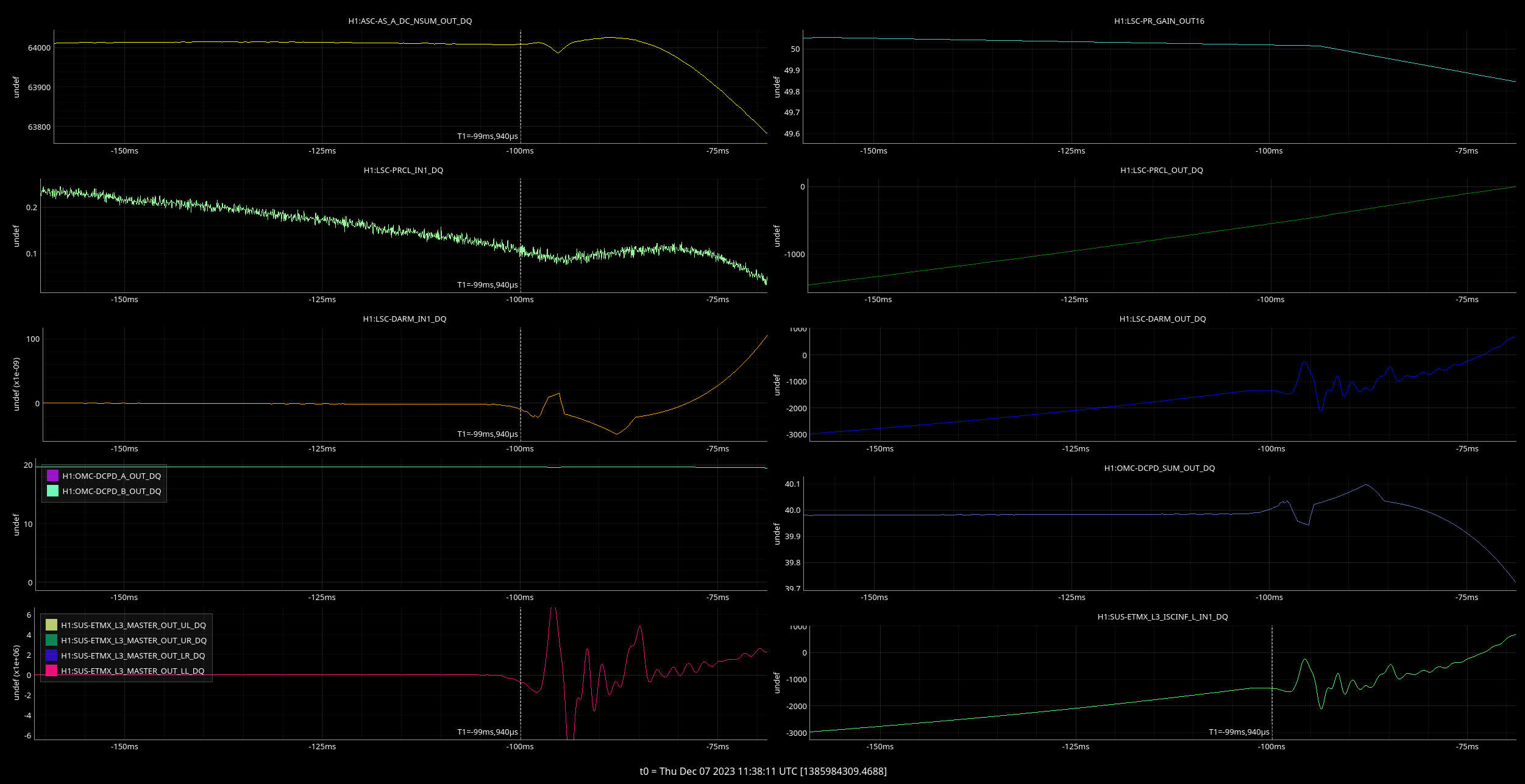
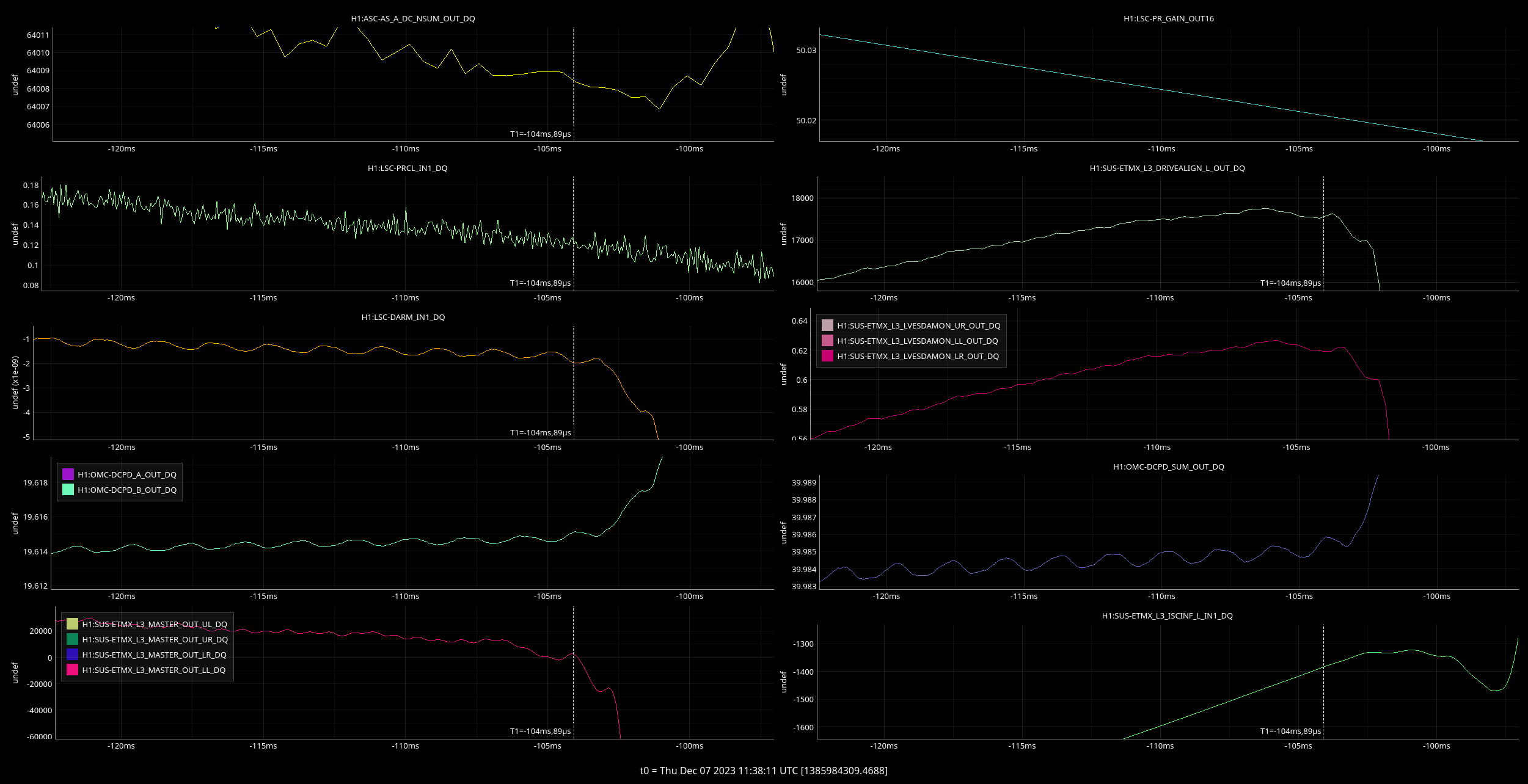
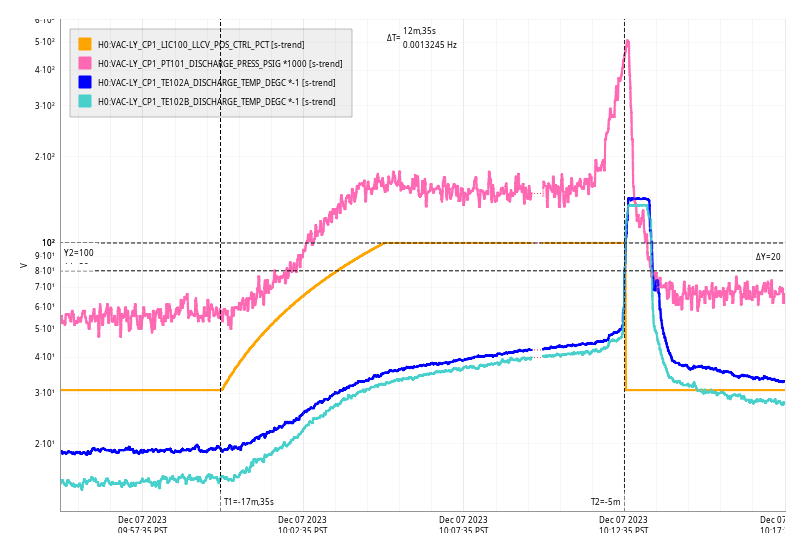
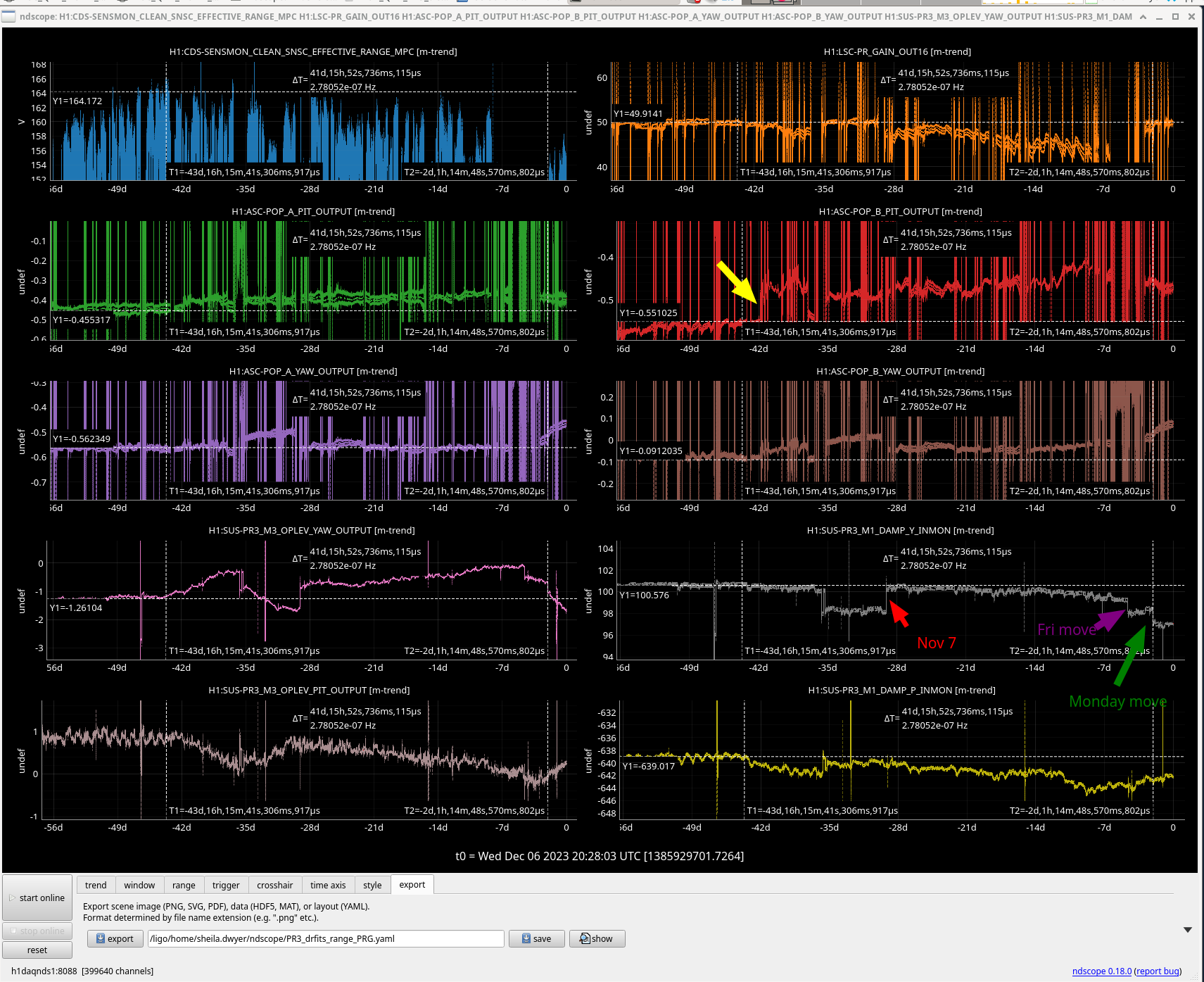
corey.gray@LIGO.ORG - posted 16:46, Thursday 07 December 2023 - last comment - 17:27, Thursday 07 December 2023(74668)
Thurs EVE Ops Transition
TITLE: 12/08 Eve Shift: 00:00-08:00 UTC (16:00-00:00 PST), all times posted in UTC
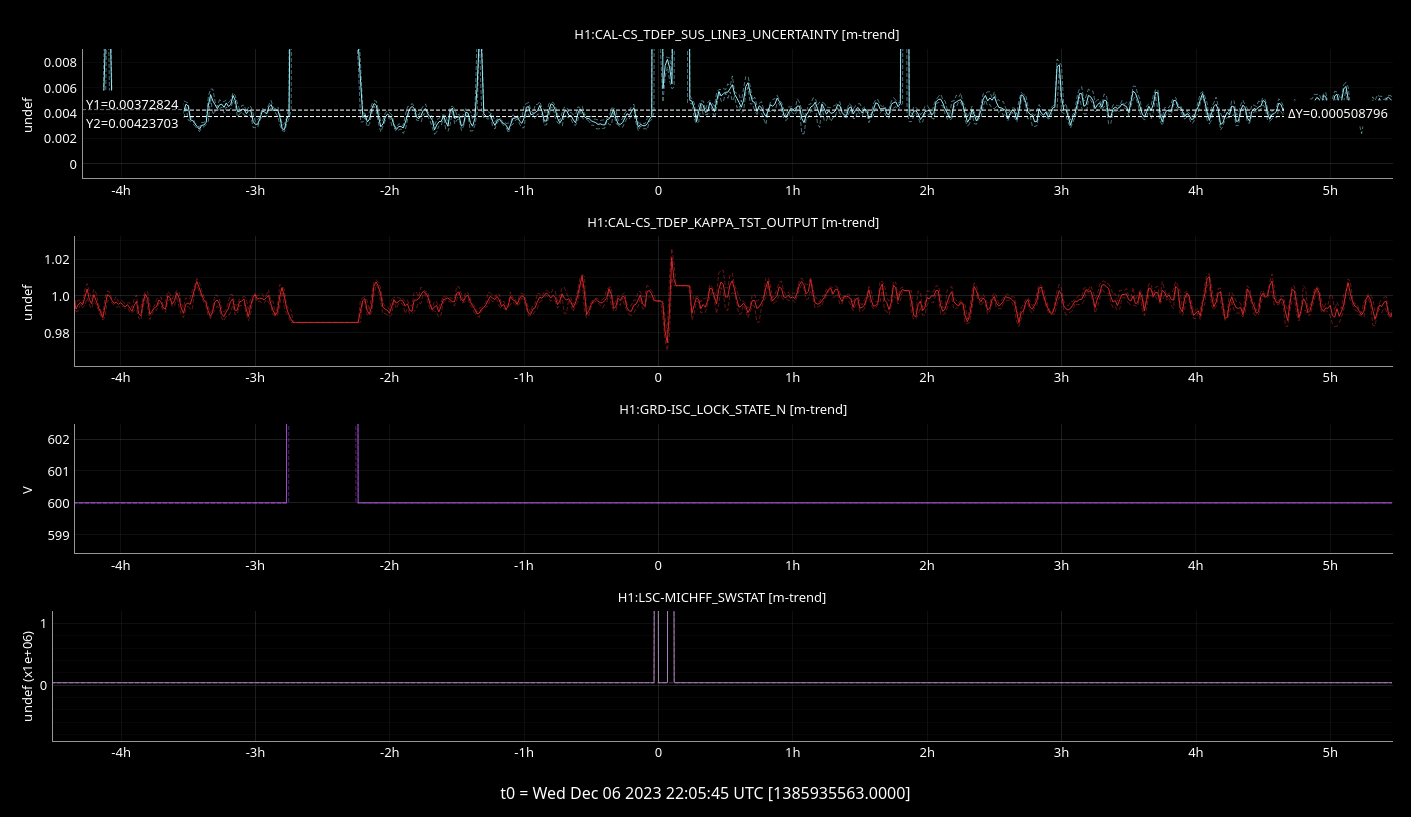
STATE of H1: Observing at 156Mpc
OUTGOING OPERATOR: TJ
CURRENT ENVIRONMENT:
SEI_ENV state: CALM
Wind: 16mph Gusts, 11mph 5min avg
Primary useism: 0.05 μm/s
Secondary useism: 0.45 μm/s
QUICK SUMMARY:
H1's been locked almost 3hrs. Violins are a little rung up (have the IY5 gain at -0.01). Microseism is lower than it was 24hrs ago and it looks like the day's wind storm have calmed---TJ took SEI_CONF to WINDY after being in USEISM for the last couple weeks.
Robert is currently making adjustments to CER AC units.
Comments related to this report
- 0020utc L1 had a power outage an hour ago.
- 0123 H1 had a lockloss from a M5.8 EQ around the Solomon Islands in the south pacific which ended our lock at 3.5+hrs.